
Pneumonia Detection from Chest X-ray Images Based on Convolutional Neural Network

Abstract
:1. Introduction
2. Related Work
3. Background
4. Materials and Methods
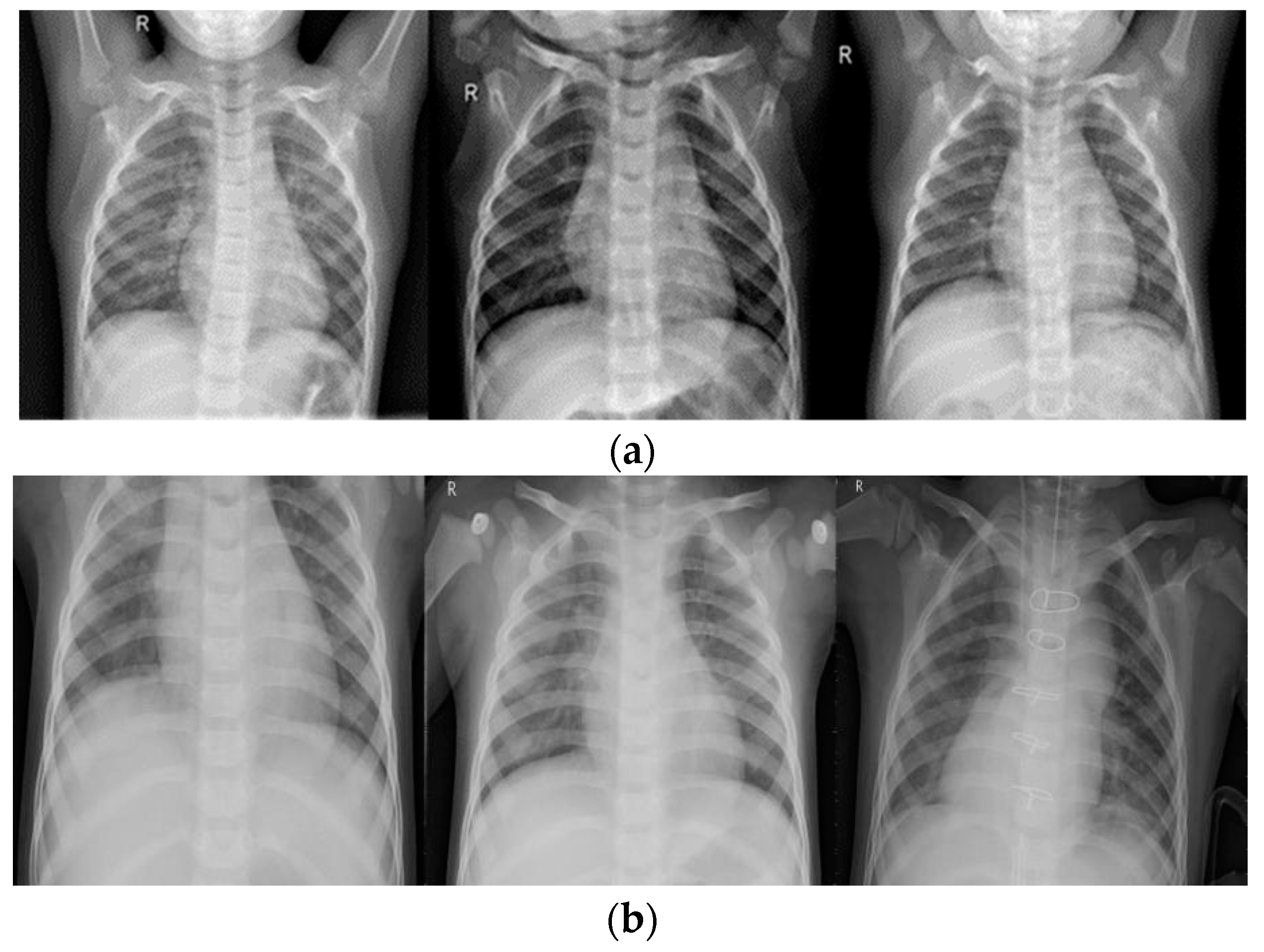
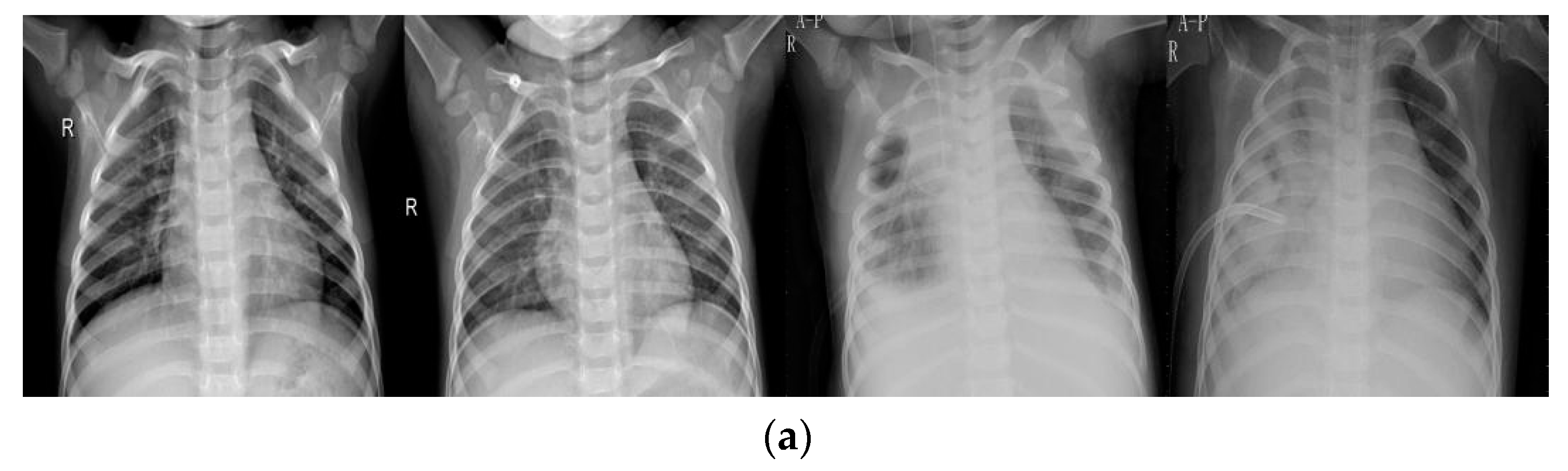
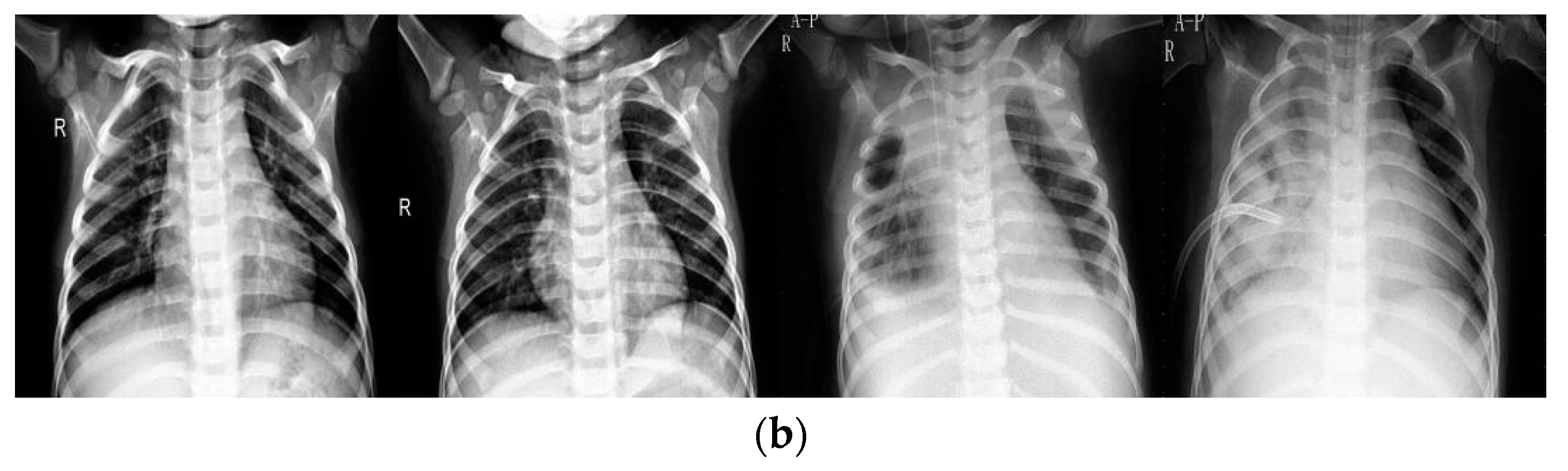
4.1. Data
4.2. Methods
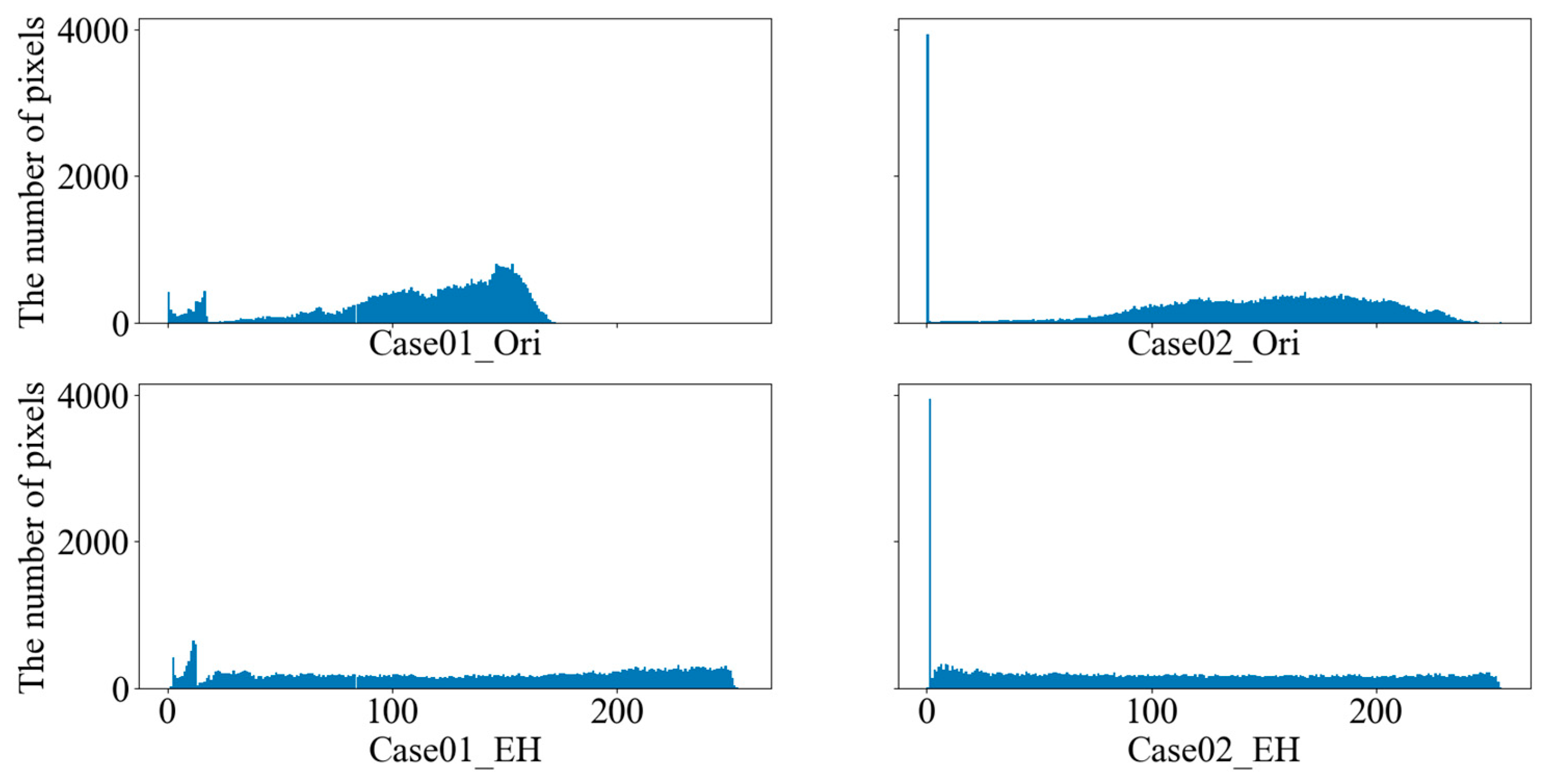
4.2.1. Data Pre-Processing
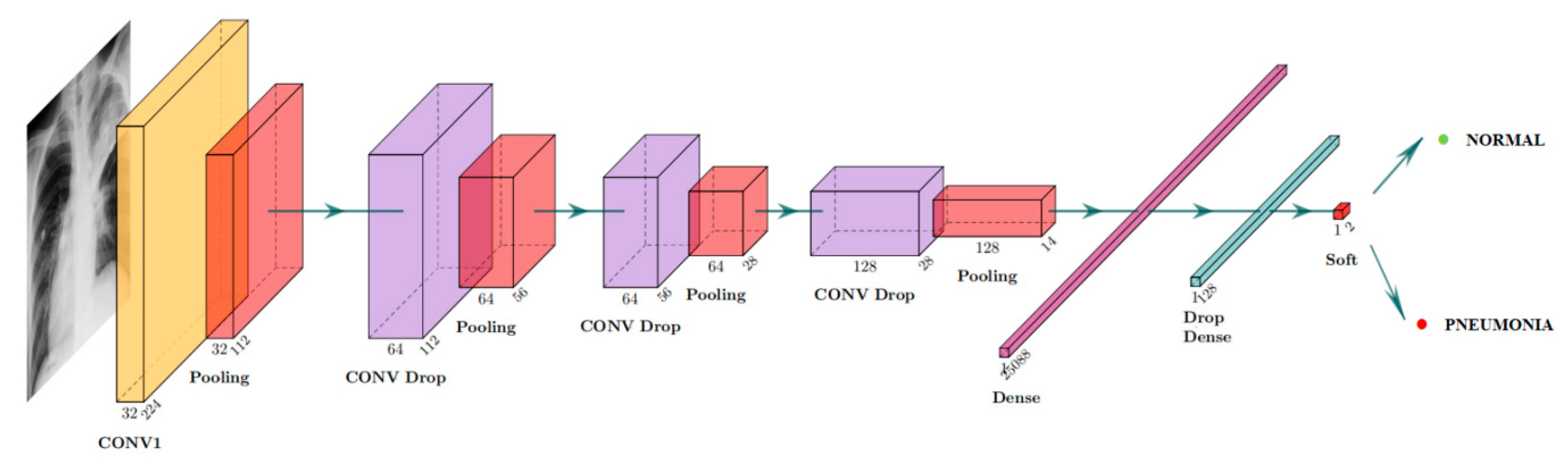
4.2.2. Proposed Network
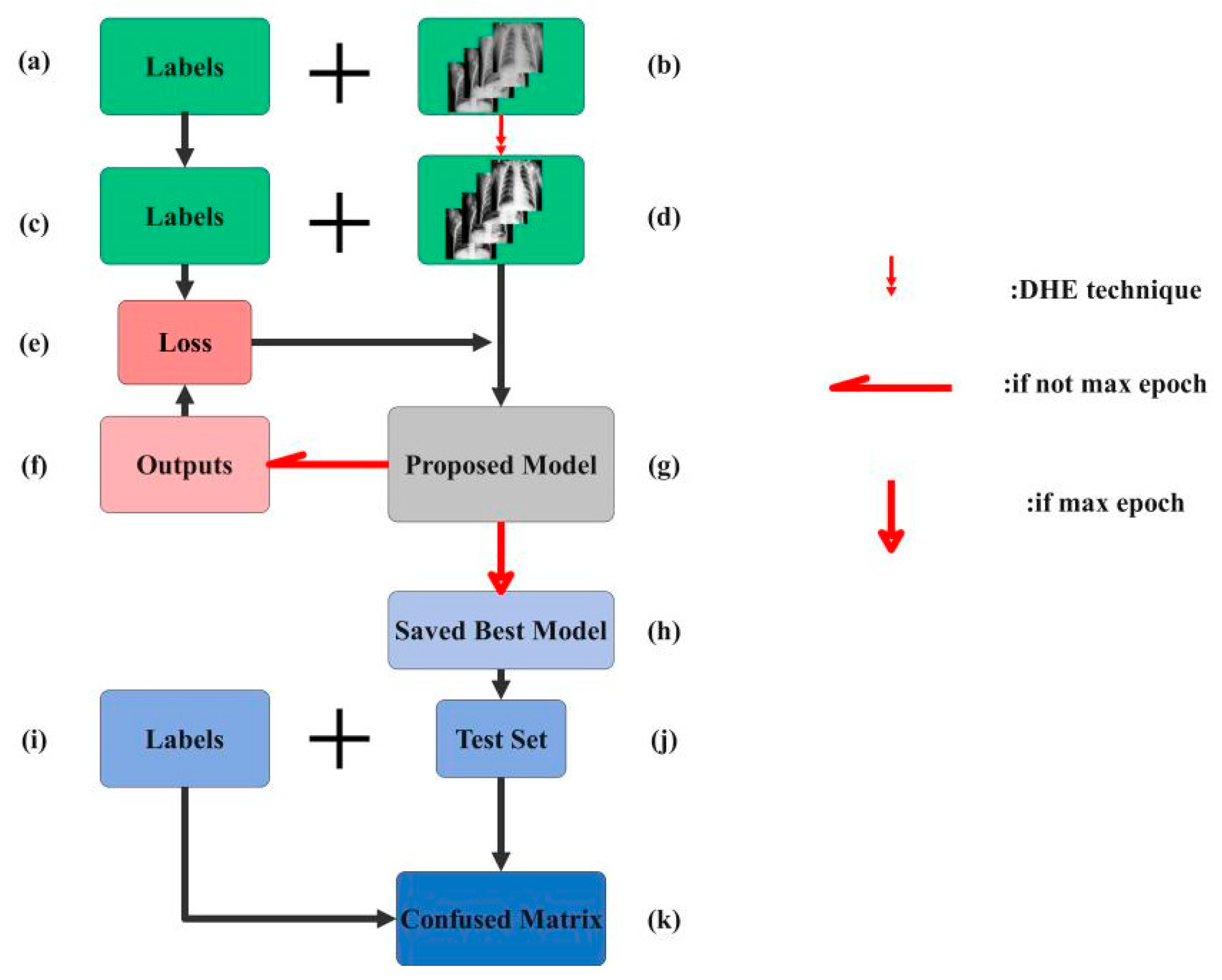
4.3. Training Process
4.3.1. Classification Evaluation Metrics
4.3.2. Proposed CNN Model
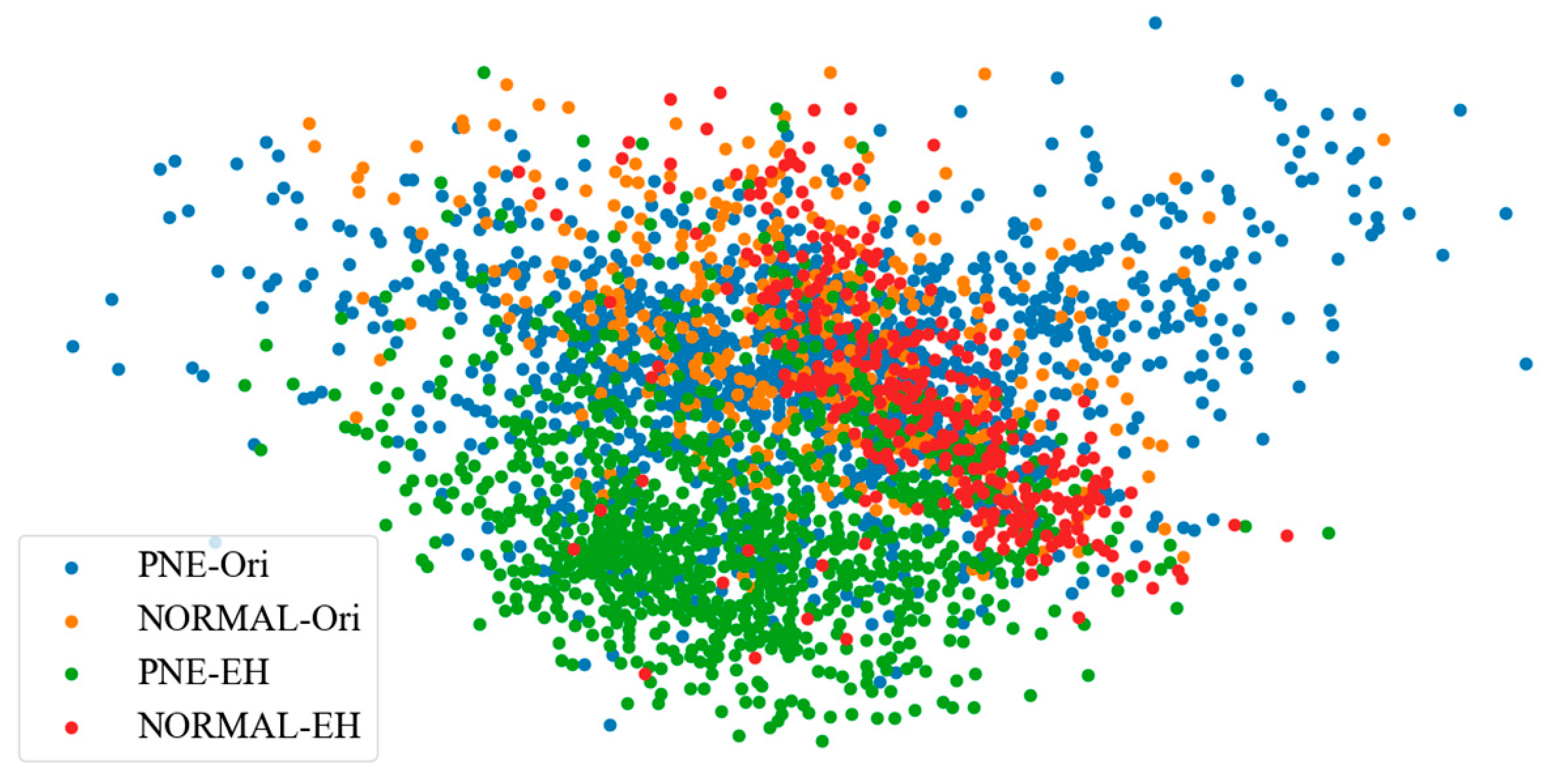
4.3.3. t-SNE Visualization
5. Experiments and Results
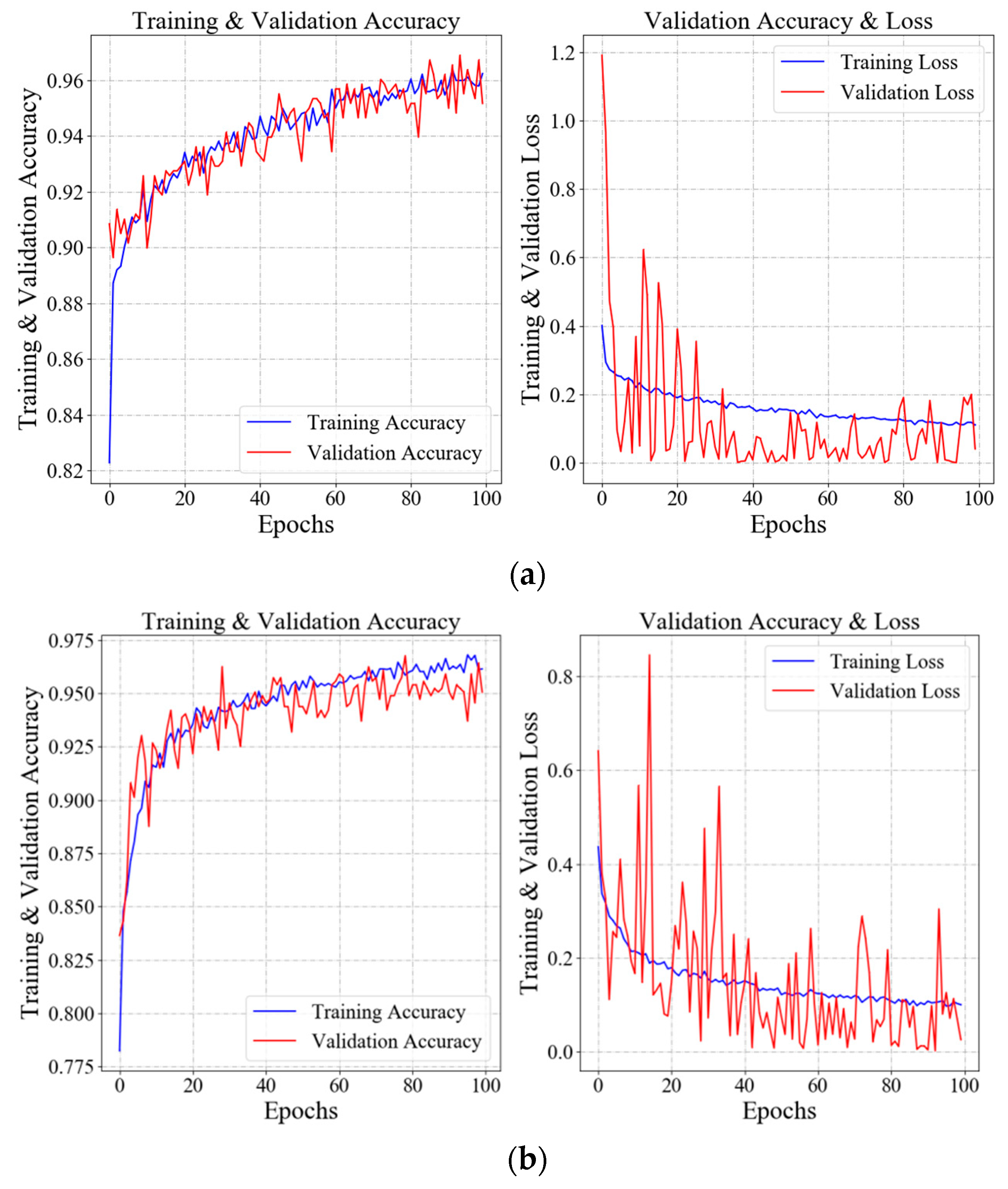
5.1. Experiments
5.2. Results
5.2.1. Comparison of Different Models and Different Shapes
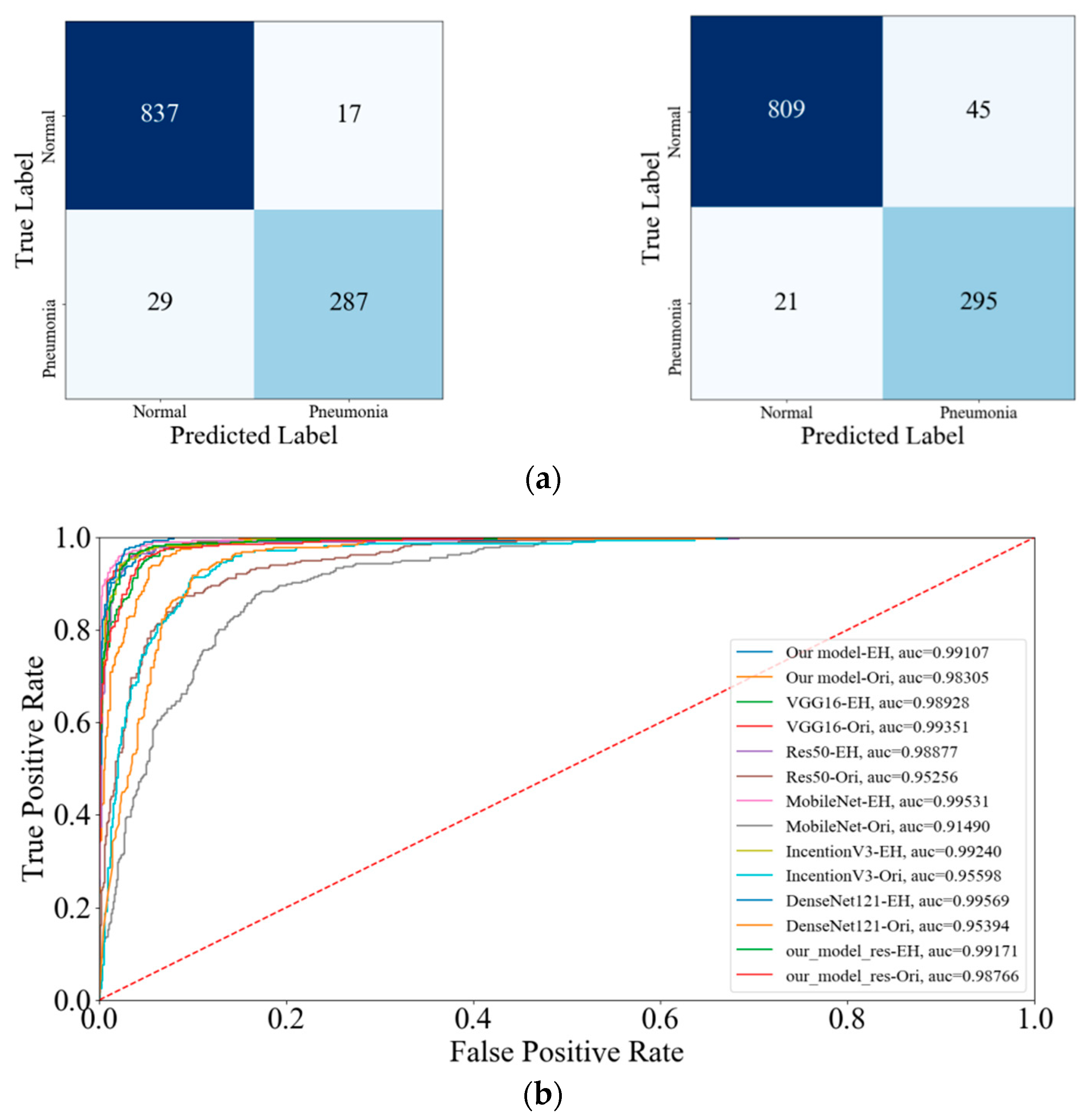
5.2.2. Confusion Matrix and ROC
5.2.3. Other Evaluations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UNICEF. Available online: https://data.unicef.org/topic/child-health/pneumonia/ (accessed on 22 March 2018).
- Prina, E.; Ranzani, O.T.; Torres, A. Community-acquired pneumonia. Lancet 2015, 386, 1097–1108. [Google Scholar] [CrossRef]
- Tilve, A.; Nayak, S.; Vernekar, S.; Turi, D.; Shetgaonkar, P.R.; Aswale, S. Pneumonia Detection Using Deep Learning Ap-proaches. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–8. [Google Scholar]
- Periselneris, N.J.; Brown, S.J.; José, R.J. Pneumonia. Available online: https://www.medicinejournal.co.uk/article/S1357-3039(20)30049-9/fulltext (accessed on 23 April 2021).
- Le, W.T.; Maleki, F.; Romero, F.P.; Forghani, R.; Kadoury, S. Overview of machine learning: Part 2. Neuroimaging Clin. N. Am. 2020, 30, 417–431. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Jeelani, H.; Martin, J.; Vasquez, F.; Salerno, M.; Weller, D. Image quality affects deep learning reconstruction of MRI. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 357–360. [Google Scholar]
- Chlemper, J.S.; Caballero, J.; Hajnal, J.; Price, A.N.; Rueckert, D. A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans. Med. Imaging 2017, 37, 491–503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 25–30 June 2017; pp. 636–644. [Google Scholar]
- Liang, G.; Zheng, L. A transfer learning method with deep residual network for pediatric pneumonia diagnosis. Comput. Methods Programs Biomed. 2020, 187, 104964. [Google Scholar] [CrossRef] [PubMed]
- Jain, R.; Nagrath, P.; Kataria, G.; Kaushik, V.S.; Hemanth, D.J. Pneumonia detection in chest X-ray images using convolutional neural networks and transfer learning. Measurment 2020, 165. [Google Scholar] [CrossRef]
- Verma, D.; Bose, C.; Tufchi, N.; Pant, K.; Tripathi, V.; Thapliyal, A. An efficient framework for identification of Tuberculosis and Pneumonia in chest X-ray images using Neural Network. Procedia Comput. Sci. 2020, 171, 217–224. [Google Scholar] [CrossRef]
- Ayan, E.; Unver, H.M. Diagnosis of Pneumonia from Chest X-Ray Images Using Deep Learning. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; pp. 1–5. [Google Scholar]
- Elshennawy, N.M.; Ibrahim, D.M. Deep-pneumonia framework using deep learning models based on chest X-ray images. Diagnostics 2020, 10, 649. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Kang, G.; Cheng, K.; Zhang, N. Attention-Guided Convolutional Neural Network for Detecting Pneumonia on Chest X-Rays. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4851–4854. [Google Scholar]
- Guo, X.; Yuan, Y. Triple ANet: Adaptive Abnormal-aware Attention Network for WCE Image Classification. In Proceedings of the 19th International Conference on Application of Concurrency to System Design (ACSD 2019), Aachen, Germany, 23–28 June 2019; pp. 293–301. [Google Scholar]
- Baltruschat, I.M.; Nickisch, H.; Grass, M.; Knopp, T.; Saalbach, A. Comparison of Deep Learning Approaches for Multi-Label Chest X-Ray Classification. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nahid, A.-A.; Sikder, N.; Bairagi, A.K.; Razzaque, A.; Masud, M.; Kouzani, A.Z.; Mahmud, M.A.P. A Novel Method to Identify Pneumonia through Analyzing Chest Radiographs Employing a Multichannel Convolutional Neural Network. Sensors 2020, 20, 3482. [Google Scholar] [CrossRef] [PubMed]
- Odaibo, D.; Zhang, Z.; Skidmore, F.; Tanik, M. Detection of visual signals for pneumonia in chest radiographs using weak supervision. 2019 SoutheastCon 2019, 1–5. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Isa, I.S.; Sulaiman, S.N.; Mustapha, M.; Karim, N.K.A. Automatic contrast enhancement of brain MR images using Average Intensity Replacement based on Adaptive Histogram Equalization (AIR-AHE). Biocybern. Biomed. Eng. 2017, 37, 24–34. [Google Scholar] [CrossRef]
- Acharya, U.K.; Kumar, S. Particle swarm optimized texture based histogram equalization (PSOTHE) for MRI brain image enhancement. Optik 2020, 224, 165760. [Google Scholar] [CrossRef]
- Wadud, M.A.A.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. In Proceedings of the 2007 Digest of Technical Papers International Conference on Consumer Electronics, Las Vegas, NV, USA, 10–14 January 2007; pp. 1–2. [Google Scholar]
- Delong, E.R.; Delong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Varalakshmi, P.; Yuvaraj, G.; Dhanasekaran, K.; Samannan, K. Diminishing fall-out and miss-rate in the classification of lung diseases using deep learning techniques. In Proceedings of the 2018 Tenth International Conference on Advanced Computing (ICoAC), Chennai, India, 13–15 December 2018; pp. 373–376. [Google Scholar]
- Stephen, O.; Sain, M.; Maduh, U.J.; Jeong, D.-U. An Efficient Deep learning approach to pneumonia classification in healthcare. J. Healthc. Eng. 2019, 2019, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Y.; Zhou, Q.; Chen, X.; Lu, H.; Zhao, Y. Multi-attention Network for Thoracic Disease Classification and Localization. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1378–1382. [Google Scholar]
- Xu, S.; Wu, H.; Bie, R. CXNet-m1: Anomaly detection on chest X-rays with image-based deep learning. IEEE Access 2019, 7, 4466–4477. [Google Scholar] [CrossRef]
- Kermany, D.; Zhang, K.; Goldbaum, M. Large Dataset of Labeled Optical Coherence Tomography (OCT) and Chest X-ray Images. Available online: https://data.mendeley.com/datasets/rscbjbr9sj/2 (accessed on 11 May 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Trainable Parameters |
|---|---|
| VGG16 | 134,263,489 |
| Res-50 | 23,628,673 |
| Xception | 20,808,425 |
| DenseNet121 | 6,948,609 |
| Our model | 3,341,121 |
| MobileNet | 3,207,425 |
| Methods | Setting |
|---|---|
| Resize | |
| Normalization | |
| Rotation Range | |
| Zoom Range | 0.2 |
| Weight_Shift_Range | 0.1 |
| Height_Shift_Range | 0.1 |
| Horizontal_Flip | True |
| Vertical_Flip | True |
| Parameters | Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | 0.001 |
| Learning Rate Decay Per Epoch | 0.0001 |
| Batch Size | 16 |
| Hidden Layer Activation Function | ReLU |
| Classification Activation Function | Sigmoid |
| Accuracy | Precision | Recall | F1 Score | AUC | ||
|---|---|---|---|---|---|---|
| Our model | original | 0.9538 | 0.8764 | 0.9652 | 0.9187 | 0.9910 |
| enhanced | 0.9607 | 0.9441 | 0.9082 | 0.9258 | 0.9911 | |
| Our-model-Res | original | 0.9453 | 0.8481 | 0.9715 | 0.9056 | 0.9877 |
| enhanced | 0.9598 | 0.8899 | 0.9715 | 0.9289 | 0.9917 | |
| VGG-16 | original | 0.9479 | 0.8512 | 0.9778 | 0.9102 | 0.993 |
| enhanced | 0.9436 | 0.8511 | 0.9589 | 0.9018 | 0.9893 | |
| ResNet50 | original | 0.9496 | 0.9132 | 0.8987 | 0.9059 | 0.9825 |
| enhanced | 0.9427 | 0.8374 | 0.9778 | 0.9022 | 0.9888 | |
| MobileNet | original | 0.9453 | 0.8706 | 0.93670 | 0.9024 | 0.9839 |
| enhanced | 0.9547 | 0.8663 | 0.9842 | 0.9215 | 0.9953 | |
| Inceptionv3 | original | 0.9470 | 0.8567 | 0.9652 | 0.9077 | 0.9921 |
| enhanced | 0.9589 | 0.8895 | 0.9684 | 0.92723 | 0.9924 | |
| DenseNet121 | original | 0.9137 | 0.7694 | 0.9715 | 0.8587 | 0.9845 |
| enhanced | 0.9342 | 0.8041 | 1.0000 | 0.8914 | 0.9957 | |
| [14] | original | 0.9050 | 0.8910 | 0.9670 | 0.9270 | 0.9530 |
| [15]-Model 1 | Original | 0.8526 | 0.7500 | 0.9400 | 0.8900 | -- |
| [15]-Model 2 | Original | 0.9231 | 0.8700 | 0.9800 | 0.9400 | -- |
| [32]-Architecture 1 | Original | 0.9359 | -- | -- | -- | -- |
| [32]-Architecture 2 | Original | 0.9263 | -- | -- | -- | -- |
| [32]-Architecture 3 | Original | 0.9231 | -- | -- | -- | -- |
| [32]-Architecture 4 | Original | 0.9054 | -- | -- | -- | -- |
| [32]-Architecture 5 | Original | 0.9022 | -- | -- | -- | -- |
| Accuracy | Precision | Recall | F1 Score | AUC | ||
|---|---|---|---|---|---|---|
| 50 × 50 | original | 0.9547 | 0.8997 | 0.9367 | 0.9178 | 0.9886 |
| enhanced | 0.9589 | 0.8851 | 0.9747 | 0.9277 | 0.9948 | |
| 100 × 100 | original | 0.9325 | 0.8143 | 0.9715 | 0.8860 | 0.9903 |
| enhanced | 0.9529 | 0.8718 | 0.9684 | 0.9175 | 0.9926 | |
| 224 × 224 | original | 0.9538 | 0.8764 | 0.9652 | 0.9187 | 0.9910 |
| enhanced | 0.9607 | 0.9441 | 0.9082 | 0.9258 | 0.9911 | |
| 300 × 300 | original | 0.9291 | 0.8074 | 0.9684 | 0.8806 | 0.9875 |
| enhanced | 0.9556 | 0.8729 | 0.9778 | 0.9224 | 0.9888 |
| Accuracy | Precision | Recall | F1 Score | AUC | ||||
|---|---|---|---|---|---|---|---|---|
| MSE | original | 0.9564 | 0.8909 | 0.9557 | 0.9221 | 0.9872 | ||
| enhanced | 0.9556 | 0.8771 | 0.9715 | 0.9219 | 0.9929 | |||
| BCE | original | 0.9538 | 0.8764 | 0.9652 | 0.9187 | 0.9910 | ||
| enhanced | 0.9607 | 0.9441 | 0.9082 | 0.9258 | 0.9911 | |||
| Focal loss | original | 0.9479 | 0.8653 | 0.9557 | 0.9083 | 0.9884 | ||
| enhanced | 0.9573 | 0.9236 | 0.9177 | 0.9206 | 0.9899 | |||
| original | 0.9368 | 0.8253 | 0.9715 | 0.8924 | 0.9900 | |||
| enhanced | 0.9487 | 0.8657 | 0.9589 | 0.9099 | 0.9851 | |||
| original | 0.9043 | 0.7488 | 0.9715 | 0.8457 | 0.9869 | |||
| enhanced | 0.9145 | 0.7621 | 0.9937 | 0.8626 | 0.9932 | |||
| 2 | original | 0.9393 | 0.8375 | 0.9620 | 0.8954 | 0.9903 | ||
| enhanced | 0.9573 | 0.8800 | 0.9747 | 0.9249 | 0.9929 | |||
| original | 0.9308 | 0.9898 | 0.8167 | 0.9589 | 0.8821 | |||
| enhanced | 0.9538 | 0.8639 | 0.9842 | 0.9201 | 0.9936 | |||
| original | 0.8974 | 0.7311 | 0.9810 | 0.8378 | 0.9879 | |||
| enhanced | 0.9179 | 0.7709 | 0.9905 | 0.8670 | 0.9908 | |||
| 3 | original | 0.9111 | 0.7636 | 0.9715 | 0.8551 | 0.9847 | ||
| enhanced | 0.9436 | 0.8397 | 0.9778 | 0.9035 | 0.9919 | |||
| original | 0.9256 | 0.7989 | 0.9684 | 0.8755 | 0.9843 | |||
| enhanced | 0.9256 | 0.7913 | 0.9842 | 0.8773 | 0.9904 | |||
| original | 0.9299 | 0.8095 | 0.9684 | 0.8818 | 0.9900 | |||
| enhanced | 0.9333 | 0.8099 | 0.9842 | 0.8886 | 0.9921 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Ren, F.; Li, Y.; Na, L.; Ma, Y. Pneumonia Detection from Chest X-ray Images Based on Convolutional Neural Network. Electronics 2021, 10, 1512. https://doi.org/10.3390/electronics10131512
Zhang D, Ren F, Li Y, Na L, Ma Y. Pneumonia Detection from Chest X-ray Images Based on Convolutional Neural Network. Electronics. 2021; 10(13):1512. https://doi.org/10.3390/electronics10131512
Chicago/Turabian StyleZhang, Dejun, Fuquan Ren, Yushuang Li, Lei Na, and Yue Ma. 2021. "Pneumonia Detection from Chest X-ray Images Based on Convolutional Neural Network" Electronics 10, no. 13: 1512. https://doi.org/10.3390/electronics10131512
APA StyleZhang, D., Ren, F., Li, Y., Na, L., & Ma, Y. (2021). Pneumonia Detection from Chest X-ray Images Based on Convolutional Neural Network. Electronics, 10(13), 1512. https://doi.org/10.3390/electronics10131512