
Experimental Evaluation of Malware Family Classification Methods from Sequential Information of TLS-Encrypted Traffic


Abstract
:1. Introduction
- We propose an evaluation framework for TLS-encrypted malware family classification with the same configuration and the same input, which allows different sequential information representations and classification algorithms to be evaluated. We discuss the reasons that such experimental evaluation should be conducted in Section 2.4.
- In the evaluation of traffic classification methods especially for supervised learning-based methods, we need to obtain an appropriate labeled dataset. However, unfortunately, we find that the existing community efforts on labeled dataset with malware family traffic samples have some flaws. To this end, we describe a method to obtain better dataset in a public repository. More information can be found in Section 2.3.
- We provide experimental evaluation results with various criteria for the state-of-the-art methods which utilize sequential information (e.g., packet length sequence and directions) and can be applied in the malware family classification problem. Our results show that the state-of-the-art methods have several advantages and limitations to be resolved by future work.
2. Backgrounds and Related Work
2.1. Early Encrypted Traffic Classification Methods
2.2. Recent Advances in TLS-Encrypted Traffic Classification Methods
2.2.1. Exploiting Sequential Information of TLS Flow
2.2.2. Fine-Grained Classification for TLS-Encrypted Traffic in Mobile Apps
2.2.3. Malware Detection and Family Classification from TLS-Encrypted Traffic
2.3. Lack of Malware Family Dataset
2.4. Need for Evaluation Based on Packet Length Sequences
- Recent research efforts [7,8,19,20] showed that we can successfully classify TLS-encrypted malware traffic without decryption in a coarse-grained manner (i.e., malware detection) and a fine-grained manner (i.e., malware family classification), provided that more features are collected from unencrypted parts of network traffic but selected by security experts. Similarly, more recent works [28,33] insisted that more generic representation of the unencrypted parts can leverage the burden of domain expertise with the introduction of machine learning.
- Surprisingly, while there are various proposals to represent sequential information in TLS-encrypted traffic for machine learning-based classification, there is no clear discussion among the proposals, especially in the context of malware family classification due to diverse feature sets in the current methods. Considering a broad adoption of sequential information in recent research efforts, a fair experimental evaluation among the proposals (i.e., evaluation with the same configuration and the same input) should be given to understand which representations and classification algorithms are better than others.
- In particular, the packet length sequence and directions in TLS-encrypted traffic can be easily obtained with lower overhead, compared with TLS metadata. In addition, the time complexity to obtain the packet length sequence is comparable with that of unique packet length features (e.g., mean, max, and min), while more space complexity is required [34]. Fortunately, the space complexity problem can be alleviated with the recent advances of storage technology in speed and volume or with the use of a fixed-size packet length sequence.
- Currently, one minor but important advantage of flow sequential information is the measurability of the information in most scenarios of traffic classification. While the inclusion of TLS metadata as input improves accuracy, especially with the current dataset, a part of TLS metadata may be unavailable in some scenarios with TLS 1.2 session resumption, and a substantial part of TLS metadata is encrypted in TLS 1.3 [48] such that the information may be unavailable in near future.
3. Evaluation Framework
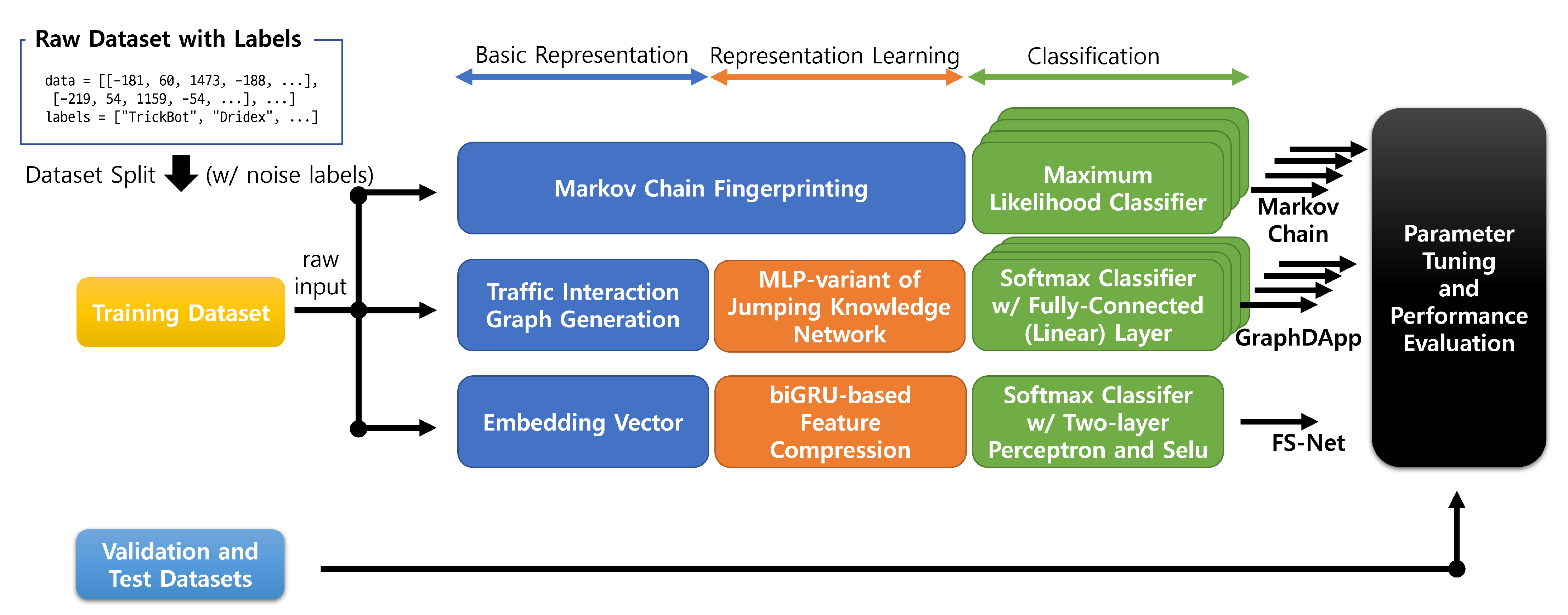
3.1. Framework Overview
3.2. Feature Representations
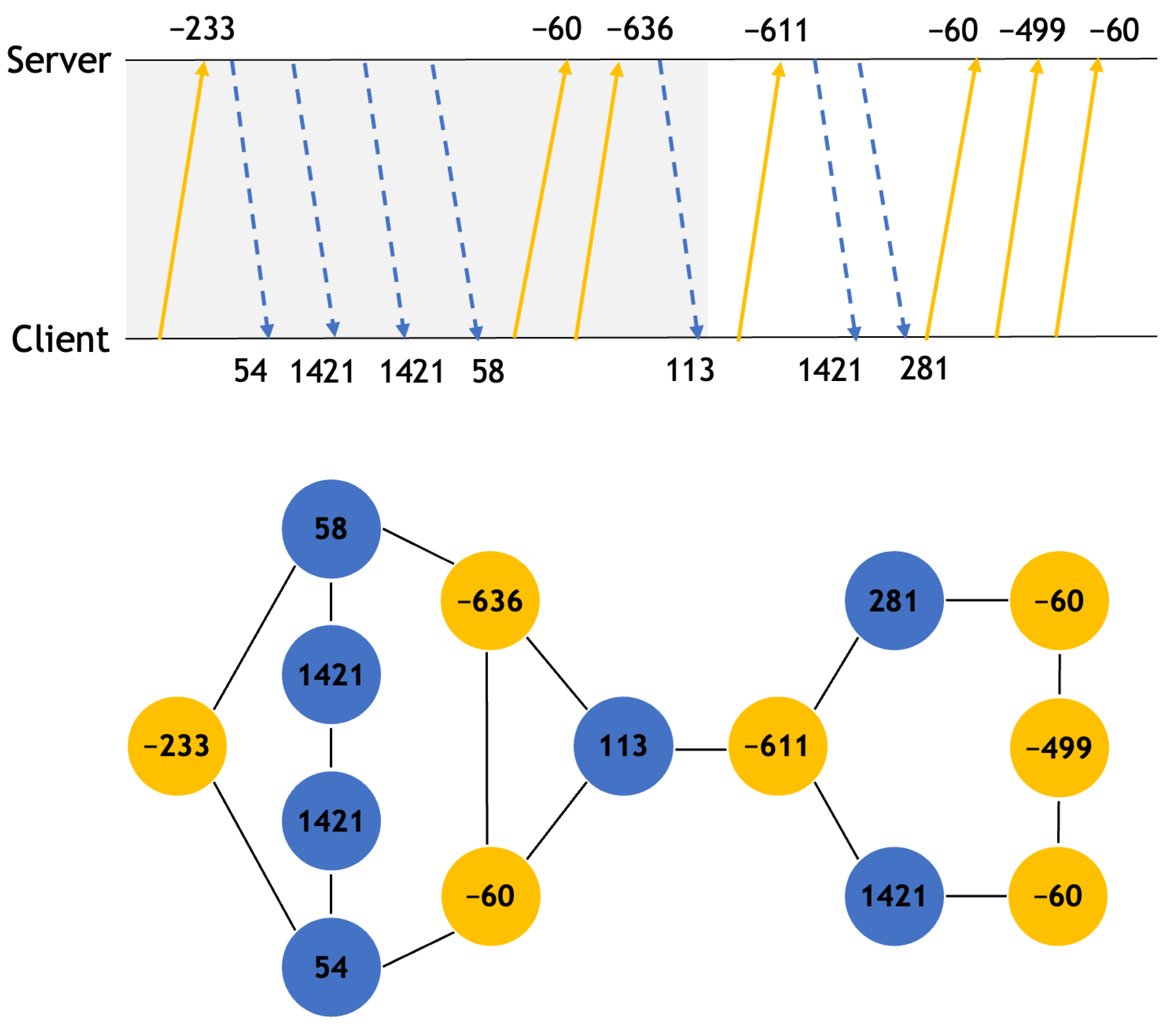
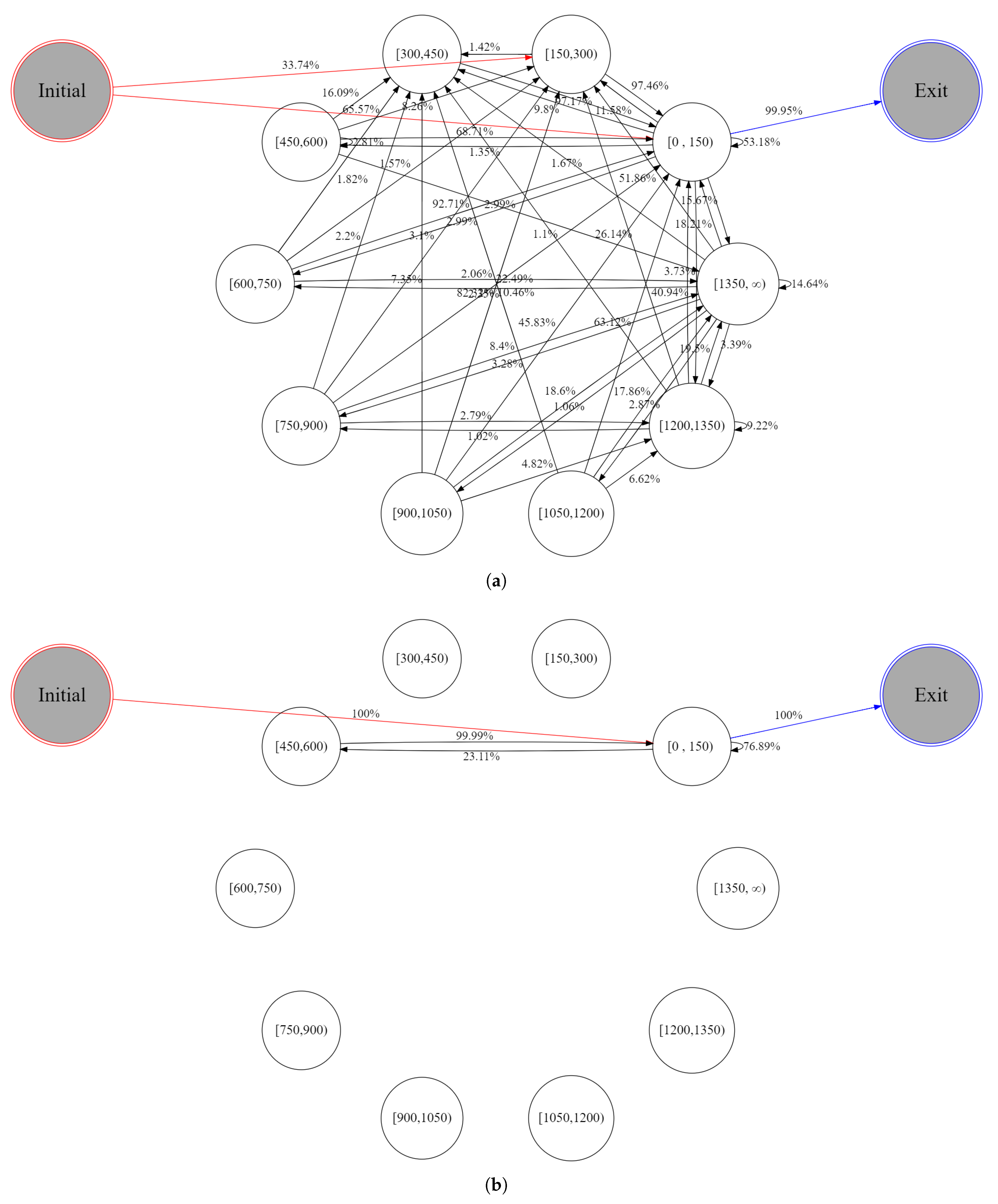
- Markov chain fingerprinting: While the original paper on Markov chain fingerprinting [6] utilizes TLS message type sequences for feature representation of a TLS session (i.e., bidirectional flow), our input is the packet length sequence with their directions for the TLS session. On the other hand, the method used in [7,20] only considers the packet length sequence since each unidirectional flow is used in the method. To this end, we propose a hybrid method to use 150 byte bins for the packet length but allow the minus sign in order to represent the direction of the packet. It implies that a total of 20 states are available in our Markov chain fingerprints. We also generate the enter probability distribution and the exist probability distribution described in [6] as features.
- GraphDApp: To construct the traffic interaction graph, we implement the same algorithm described in Algorithm 1 of [11]. For the representation learning, we also implement the graph neural network (GNN) architecture described in Sections IV.B and IV.C of [11]. In the architecture, the representation learning part consists of n layers of perceptrons, where each layer follows a recursive neighborhood aggregation scheme as a variant of the work of Xu et al. [50]; all layers are concatenated by the jumping knowledge network proposed by Xu et al. [51].
- FS-Net: In the embedding layer of FS-Net, the raw input is converted into a embedding vector sequence, which is widely used in natural language processing [52]. Since the representation learning part in FS-Net is highly related to the classification algorithm, we cover this part in Section 3.3.
3.3. Classification Algorithms
- Maximum likelihood classifier for Markov chain fingerprinting [6]: When a raw input is given, we can compute the conditional probability that the raw input is occurred, given that the input is generated by a specific malware family G aswhere is the state transition probability (from state i to state j) of the Markov chain fingerprint model for G. The maximum likelihood classifier outputs the most plausible family (i.e., the family which maximizes the likelihood function) when the likelihood function for a family G is defined as Equation (1).
- Linear SVM, decision tree, and random forest: We use a linear SVM-based classifier, a classification and regression tree (CART)-based decision tree classifier, and a random forest classifier implemented in scikit-learn v1.0.1 as in [8] both for Markov chain fingerprinting and the traffic interaction graph. Note that according to [9], there is no improvement in a statistically significant manner when we compare L1 logistic regression and linear SVM for the malware family classification problem.
- FS-Net: The flow-sequence network (FS-Net) architecture consists of several layers: embedding layer, encoder layer, decoder layer, reconstruction layer (only for representation learning), dense layer, classification layer (for classification). The embedding vector sequence is generated in the embedding layer as described in Section 3.2. Then, the embedding vector sequence is given to the encoder layer and the decoder layer (both are stacked multi-layer bi-GRUs [53]) to generate compressed expressive features (i.e., encoder and decoder sequences). In addition, the Softmax classifier is used in both the reconstruction layer and the classification layer. For the dense layer, a two-layer perceptron with the Selu activation function [54] is used. We use the default parameters described in [10]. To compute the loss, the cross entropy function is used.
4. Experimental Evaluation
4.1. Traffic Dataset
4.2. Evaluation Results
4.2.1. Accuracy and F1 Score of the State-of-the-Art Methods
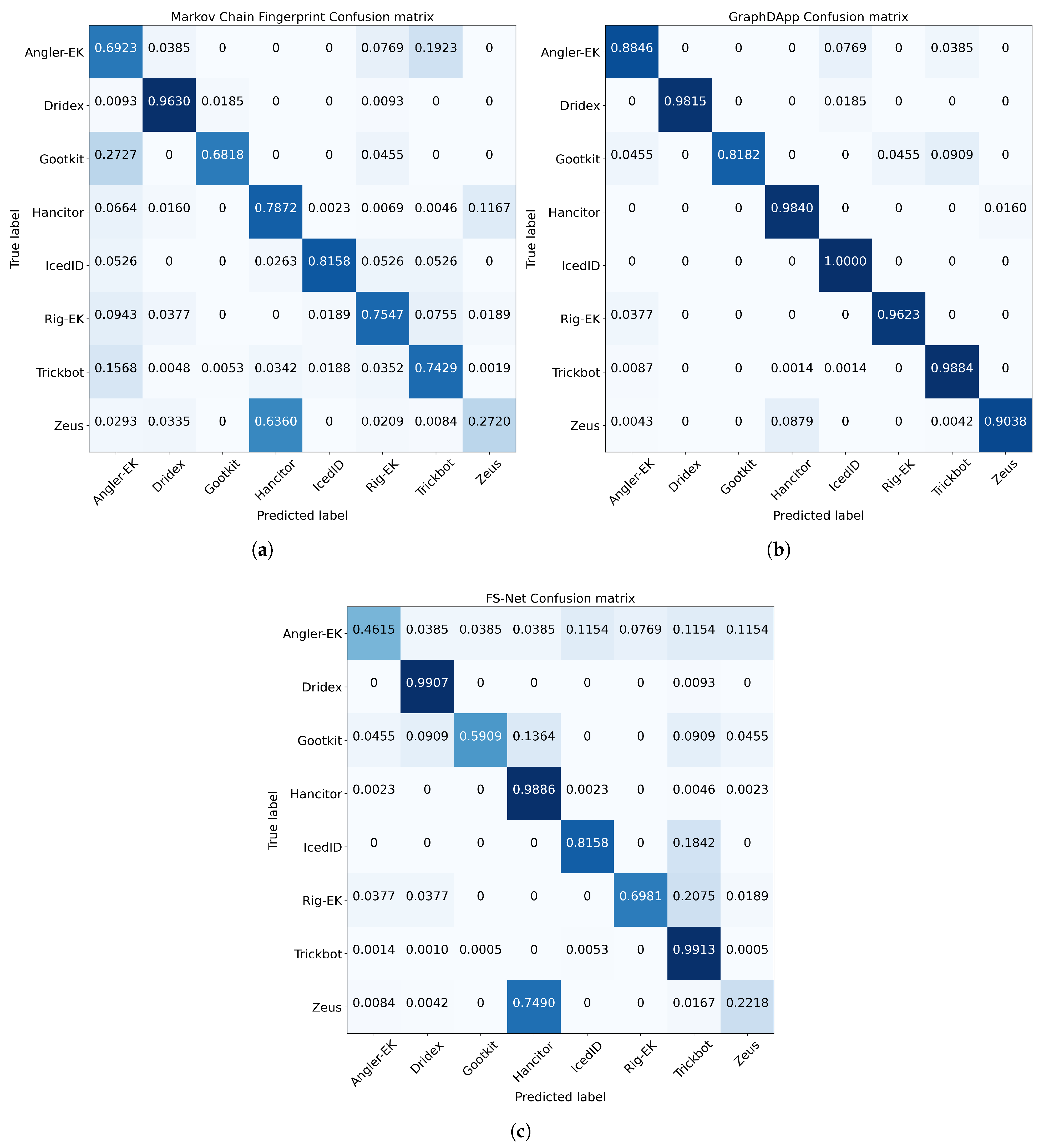
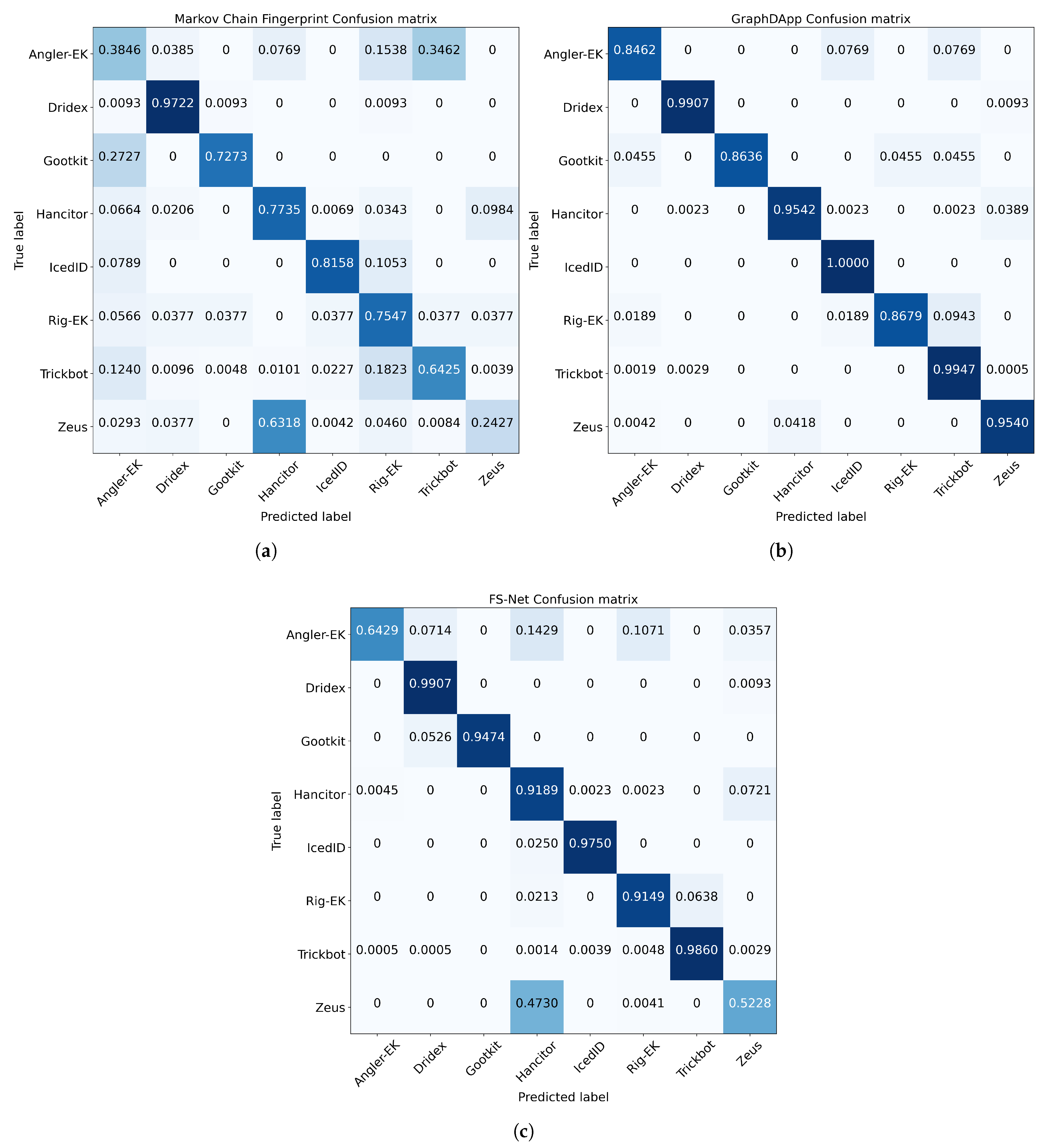
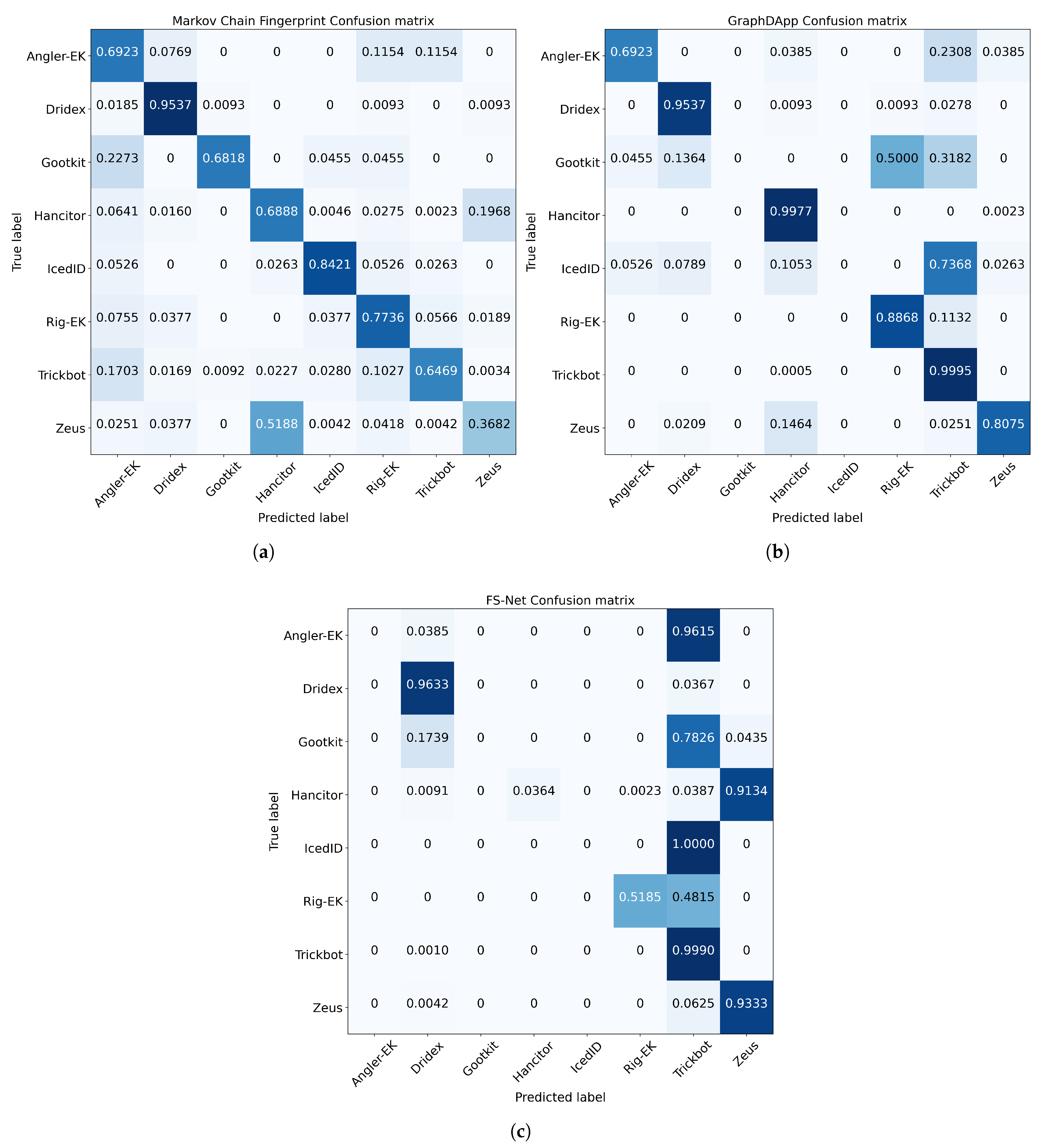
4.2.2. Confusion Matrices without Noisy Labels
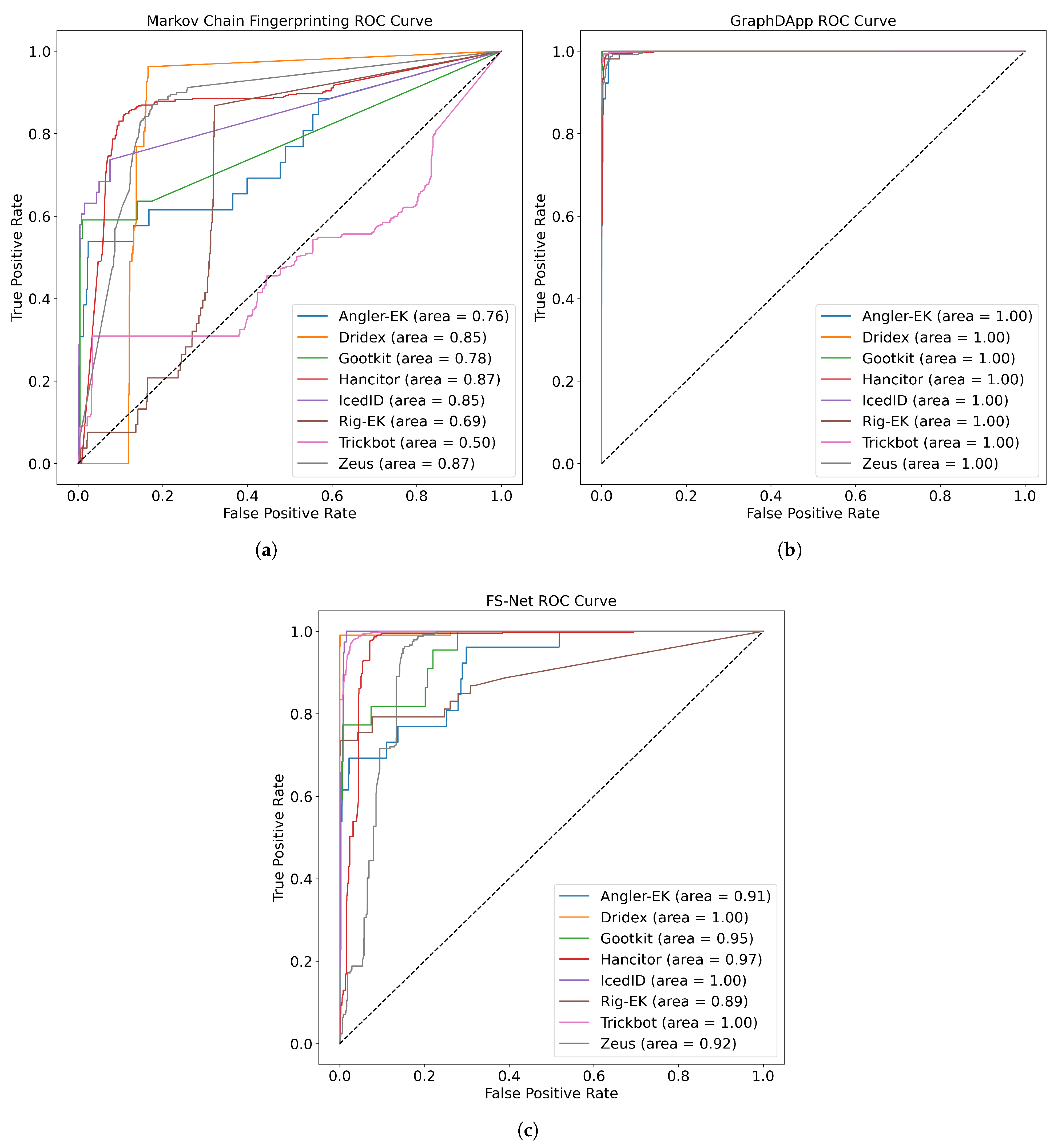
4.2.3. ROC Curves and AUC Values
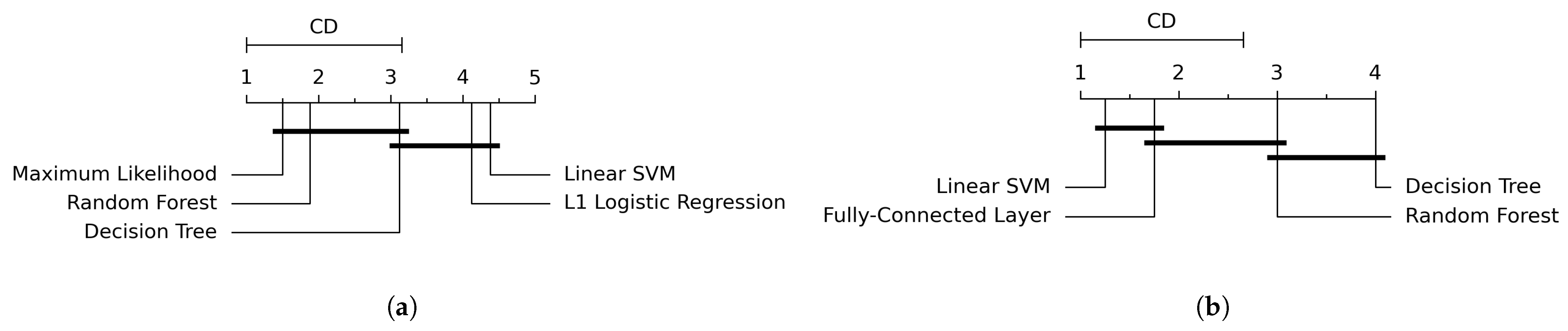
4.2.4. Non-Parametric Friedman Test and Post-Hoc Nemenyi Test
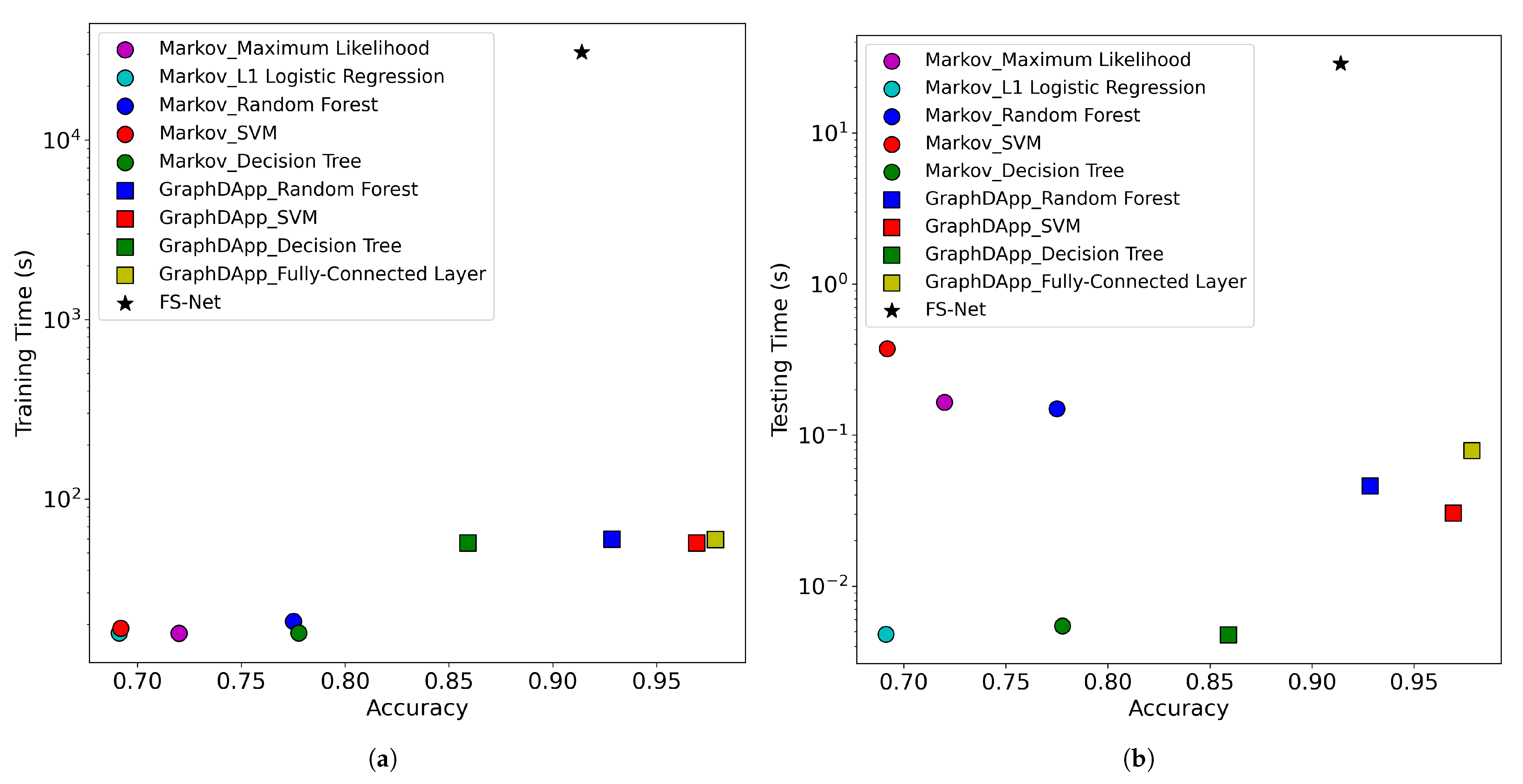
4.2.5. Training Time and Testing Time
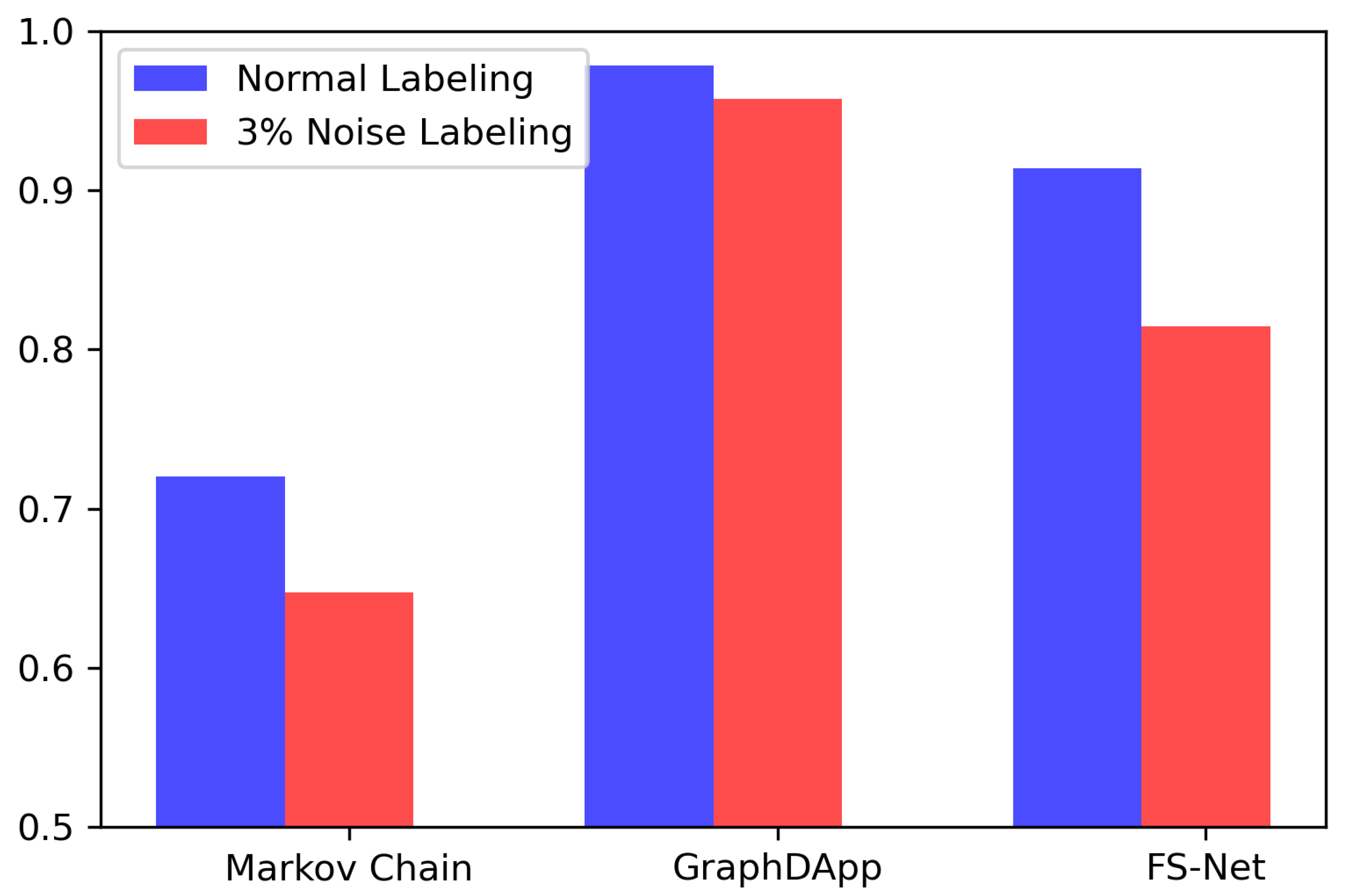
4.2.6. Performance Evaluation with Noisy Labels
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Naylor, D.; Finamore, A.; Leontiadis, I.; Grunenberger, Y.; Mellia, M.; Munafò, M.; Papagiannaki, K.; Steenkiste, P. The Cost of the “S” in HTTPS. In Proceedings of the 10th Conference on Emerging Networking Experiments and Technologies (CoNEXT’2014), Sydney, Australia, 2–5 December 2014; pp. 133–139. [Google Scholar] [CrossRef] [Green Version]
- Google. HTTPS Encryption on the Web. 2021. Available online: https://transparencyreport.google.com/https/overview (accessed on 27 November 2021).
- Lee, H.; Kim, D.; Kwon, Y. TLS 1.3 in Practice: How TLS 1.3 Contributes to the Internet. In Proceedings of the Web Conference 2021, WWW ’21, Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 70–79. [Google Scholar] [CrossRef]
- WatchGuard Threat Lab. Internet Security Report: Q2 2021; Technical Report. Available online: https://www.watchguard.com/wgrd-resource-center/security-report-q2-2021 (accessed on 27 November 2021).
- de Carnavalet, X.d.C.; van Oorschot, P.C. A survey and analysis of TLS interception mechanisms and motivations. arXiv 2020, arXiv:2010.16388. [Google Scholar]
- Korczyński, M.; Duda, A. Markov Chain Fingerprinting to Classify Encrypted Traffic. In Proceedings of the 33rd IEEE International Conference on Computer Communications (INFOCOM’2014), Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar] [CrossRef]
- Anderson, B.; McGrew, D. Identifying Encrypted Malware Traffic with Contextual Flow Data. In Proceedings of the 2016 ACM workshop on artificial intelligence and security, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 35–46. [Google Scholar] [CrossRef]
- Anderson, B.; McGrew, D. Machine Learning for Encrypted Malware Traffic Classification: Accounting for Noisy Labels and Non-stationarity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’2017), Halifax, NS, Canada, 13–17 August 2017; Volume Part F1296. [Google Scholar] [CrossRef]
- Anderson, B.; Paul, S.; McGrew, D. Deciphering malware’s use of TLS (without decryption). J. Comput. Virol. Hacking Tech. 2018, 14, 195–211. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. FS-Net: A Flow Sequence Network for Encrypted Traffic Classification. In Proceedings of the 38th IEEE International Conference on Computer Communications (INFOCOM’2019), Paris, France, 29 April–2 May 2019. [Google Scholar] [CrossRef]
- Shen, M.; Zhang, J.; Zhu, L.; Xu, K.; Du, X. Accurate Decentralized Application Identification via Encrypted Traffic Analysis Using Graph Neural Networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2367–2380. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Karagiannis, T.; Papagiannaki, K.; Faloutsos, M. BLINC: Multilevel Traffic Classification in the Dark. In Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’05, Philadelphia, PA, USA, 22–26 August 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 229–240. [Google Scholar] [CrossRef]
- Dainotti, A.; Pescapé, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Velan, P.; Čermák, M.; Čeleda, P.; Drašar, M. A survey of methods for encrypted traffic classification and analysis. Int. J. Netw. Manag. 2015, 25, 355–374. [Google Scholar] [CrossRef]
- Moore, A.W.; Papagiannaki, K. Toward the Accurate Identification of Network Applications. In Proceedings of the International Conference on Passive and Active Network Measurement, Boston, MA, USA, 31 March–1 April 2005; Dovrolis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–54. [Google Scholar]
- Bernaille, L.; Teixeira, R. Early recognition of encrypted applications. In Proceedings of the International Conference on Passive and Active Network Measurement, Louvain-la-neuve, Belgium, 5–6 April 2007; pp. 165–175. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.L.; Xue, Y.; Dong, Y.; Wang, D.; Li, C. An Novel Hybrid Method for Effectively Classifying Encrypted Traffic. In Proceedings of the Conference and Exhibition on Global Telecommunications (GLOBECOM’2010), Miami, FL, USA, 6–10 December 2010. [Google Scholar]
- Shen, M.; Wei, M.; Zhu, L.; Wang, M. Classification of Encrypted Traffic with Second-Order Markov Chains and Application Attribute Bigrams. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1830–1843. [Google Scholar] [CrossRef]
- McGrew, D.; Anderson, B. Enhanced telemetry for encrypted threat analytics. In Proceedings of the International Conference on Network Protocols, ICNP 2016, Singapore, 8–11 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Conti, M.; Mancini, L.V.; Spolaor, R.; Verde, N.V. Analyzing Android Encrypted Network Traffic to Identify User Actions. IEEE Trans. Inf. Forensics Secur. 2016, 11, 114–125. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. AppScanner: Automatic Fingerprinting of Smartphone Apps from Encrypted Network Traffic. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 439–454. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust Smartphone App Identification via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 63–78. [Google Scholar] [CrossRef] [Green Version]
- Lee, I.; Roh, H.; Lee, W. Poster Abstract: Encrypted Malware Traffic Detection Using Incremental Learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 1348–1349. [Google Scholar] [CrossRef]
- Liu, J.; Tian, Z.; Zheng, R.; Liu, L. A Distance-Based Method for Building an Encrypted Malware Traffic Identification Framework. IEEE Access 2019, 7, 100014–100028. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Barut, O.; Luo, Y.; Zhang, T.; Li, W.; Li, P. Multi-Task Hierarchical Learning Based Network Traffic Analytics. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, D.; Han, J.; Lee, J.; Roh, H.; Lee, W. Feasibility of Malware Traffic Analysis through TLS-Encrypted Flow Visualization. In Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP), Madrid, Spain, 13–16 October 2020; pp. 1–2. [Google Scholar] [CrossRef]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware Images: Visualization and Automatic Classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, VizSec ’11, Pittsburgh, PA, USA, 20 July 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Jian, Y.; Kuang, H.; Ren, C.; Ma, Z.; Wang, H. A novel framework for image-based malware detection with a deep neural network. Comput. Secur. 2021, 109, 102400. [Google Scholar] [CrossRef]
- Awan, M.J.; Masood, O.A.; Mohammed, M.A.; Yasin, A.; Zain, A.M.; Damaševičius, R.; Abdulkareem, K.H. Image-Based Malware Classification Using VGG19 Network and Spatial Convolutional Attention. Electronics 2021, 10, 2444. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Holland, J.; Schmitt, P.; Feamster, N.; Mittal, P. New Directions in Automated Traffic Analysis. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS ’21, Virtual Event, Korea, 15–19 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3366–3383. [Google Scholar] [CrossRef]
- Shen, M.; Liu, Y.; Zhu, L.; Xu, K.; Du, X.; Guizani, N. Optimizing feature selection for efficient encrypted traffic classification: A systematic approach. IEEE Netw. 2020, 34, 20–27. [Google Scholar] [CrossRef]
- AlAhmadi, B.A.; Martinovic, I. MalClassifier: Malware Family Classification Using Network Flow Sequence Behaviour. In Proceedings of the 13th APWG Symposium on Electronic Crime Research (eCrime’2018), San Diego, CA, USA, 15–17 May 2018; pp. 1–13. [Google Scholar] [CrossRef]
- Paxson, V. Bro: A system for detecting network intruders in real-time. Comput. Netw. 1999, 31, 2435–2463. [Google Scholar] [CrossRef]
- Verkerken, M.; D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. Unsupervised Machine Learning Techniques for Network Intrusion Detection on Modern Data. In Proceedings of the 2020 4th Cyber Security in Networking Conference (CSNet), UNIL, Lausanne, Switzerland, 21–23 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Gopalan, S.S.; Ravikumar, D.; Linekar, D.; Raza, A.; Hasib, M. Balancing Approaches towards ML for IDS: A Survey for the CSE-CIC IDS Dataset. In Proceedings of the 2020 International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 16–18 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Mauro, M.D.; Galatro, G.; Liotta, A. Experimental Review of Neural-Based Approaches for Network Intrusion Management. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2480–2495. [Google Scholar] [CrossRef]
- Chou, D.; Jiang, M. A Survey on Data-Driven Network Intrusion Detection. ACM Comput. Surv. 2021, 54. [Google Scholar] [CrossRef]
- Cisco. Cisco Encrypted Traffic Analytics. 2019. Available online: https://www.cisco.com/c/en/us/solutions/collateral/enterprise-networks/enterprise-network-security/nb-09-encrytd-traf-anlytcs-wp-cte-en.pdf (accessed on 27 November 2021).
- McGrew, D.; Anderson, B.; Perricone, P.; Hudson, B. Joy: A Package for Capturing and Analyzing Network Flow Data and Intraflow Data, for Network Research, Forensics, and Security Monitoring. 2016. Available online: https://github.com/cisco/joy (accessed on 27 November 2021).
- Anderson, B.; McGrew, D. TLS Beyond the Browser: Combining End Host and Network Data to Understand Application Behavior. In Proceedings of the 19th ACM SIGCOMM Internet Measurement Conference (IMC’2019), Amsterdam, The Netherlands, 21–23 October 2019. [Google Scholar] [CrossRef] [Green Version]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Thakkar, A.; Lohiya, R. A Review of the Advancement in Intrusion Detection Datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Stratosphere. Stratosphere Laboratory Datasets. 2015. Available online: https://www.stratosphereips.org (accessed on 27 November 2021).
- Barut, O.; Luo, Y.; Zhang, T.; Li, W.; Li, P. NetML: A Challenge for Network Traffic Analytics. arXiv 2020, arXiv:2004.13006. [Google Scholar]
- Andreasen, F.; Cam-Winget, N.; Wang, E. TLS 1.3 Impact on Network-Based Security. Internet-Draft draft-camwinget-tls-use-cases-05, Internet Engineering Task Force. 2019. Available online: https://tools.ietf.org/id/draft-camwinget-tls-use-cases-05.html (accessed on 27 November 2021).
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Don’ts of Machine Learning in Computer Security. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; USENIX Association: Boston, MA, USA, 2022. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.; Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5449–5458. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2, NIPS’13, Douglas, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 971–980. [Google Scholar]
- Bartos, K.; Sofka, M.; Systems, C.; Franc, V.; Bartos, K.; Sofka, M. Optimized Invariant Representation of Network Traffic for Detecting Unseen Malware Variants. In Proceedings of the USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016; pp. 807–822. [Google Scholar]
- Batista, G.E.A.P.A.; Bazzan, A.L.C.; Monard, M.C. Balancing Training Data for Automated Annotation of Keywords: A Case Study. In Proceedings of the II Brazilian Workshop on Bioinformatics, Macaé, Brazil, 3–5 December 2003; pp. 10–18. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Malware Family | Flow Samples | Train Set | Validation Set | Test Set |
|---|---|---|---|---|
| Angler-EK | 128 | 80 | 22 | 26 |
| Dridex | 539 | 351 | 80 | 108 |
| Gootkit | 112 | 70 | 20 | 22 |
| Hancitor | 2187 | 1392 | 358 | 437 |
| IcedID | 193 | 125 | 30 | 38 |
| Rig-EK | 264 | 168 | 43 | 53 |
| Trickbot | 10,363 | 6632 | 1658 | 2073 |
| Zeus | 1194 | 769 | 186 | 239 |
| Total | 14,980 | 9587 | 2397 | 2996 |
| Representation | Classification Algorithm | Accuracy | F1 Score | Recall | Precision |
|---|---|---|---|---|---|
| Markov Chain Fingerprint | Maximum Likelihood [6] | 71.99% | 76.74% | 71.99% | 86.02% |
| Markov Chain Fingerprint | L1 Logistic Regression [9] (cf. [20]) | 69.12% | 56.56% | 69.12% | 47.86% |
| Markov Chain Fingerprint | Linear SVM [9] (cf. [8] for detection) | 69.19% | 56.59% | 69.19% | 47.87% |
| Markov Chain Fingerprint | Decision Tree (cf. [8] for detection) | 77.77% | 71.60% | 77.77% | 73.55% |
| Markov Chain Fingerprint | Random Forest (cf. [8] for detection) | 77.50% | 71.30% | 77.50% | 75.87% |
| Traffic Interaction Graph | Fully-Connected Layer [11] | 97.83% | 97.93% | 97.83% | 98.18% |
| Traffic Interaction Graph | Linear SVM | 96.92% | 97.08% | 96.92% | 97.44% |
| Traffic Interaction Graph | Decision Tree | 85.91% | 87.72% | 85.91% | 91.56% |
| Traffic Interaction Graph | Random Forest | 92.85% | 91.93% | 92.85% | 92.50% |
| Embedding Vector | FS-Net [10] | 91.40% | 89.91% | 91.40% | 92.46% |
| Malware Family | Maximum Likelihood | L1 Logistic Regression | Random Forest | Linear SVM | Decision Tree |
|---|---|---|---|---|---|
| Angler-EK | 0.7611 (2) | 0.5979 (4) | 0.7635 (1) | 0.3281 (5) | 0.6960 (3) |
| Dridex | 0.8503 (1) | 0.5957 (3) | 0.6233 (2) | 0.3957 (5) | 0.5747 (4) |
| Gootkit | 0.7770 (1) | 0.5521 (4) | 0.6138 (2) | 0.5430 (5) | 0.5753 (3) |
| Hancitor | 0.8709 (1) | 0.2436 (5) | 0.7511 (2) | 0.2940 (4) | 0.7356 (3) |
| IcedID | 0.8498 (1) | 0.7120 (5) | 0.8169 (2) | 0.7139 (4) | 0.8069 (3) |
| Rig-EK | 0.6921 (1) | 0.6486 (2) | 0.5982 (3) | 0.4524 (5) | 0.5509 (4) |
| Trickbot | 0.4988 (4) | 0.3180 (5) | 0.7286 (1) | 0.6680 (3) | 0.7077 (2) |
| Zeus | 0.8710 (1) | 0.2520 (5) | 0.7347 (2) | 0.3130 (4) | 0.7229 (3) |
| Average Rank | 1.50 | 4.12 | 1.88 | 4.38 | 3.12 |
| Malware Family | Fully Connected Layer | Random Forest | Linear SVM | Decision Tree |
|---|---|---|---|---|
| Angler-EK | 0.9975 (2.0) | 0.9764 (3.0) | 0.9984 (1.0) | 0.5558 (4.0) |
| Dridex | 0.9999 (1.5) | 0.9934 (3.0) | 0.9999 (1.5) | 0.9786 (4.0) |
| Gootkit | 0.9999 (1.5) | 0.9710 (3.0) | 0.9999 (1.5) | 0.5681 (4.0) |
| Hancitor | 0.9986 (2.0) | 0.9971 (3.0) | 0.9990 (1.0) | 0.9721 (4.0) |
| IcedID | 0.9999 (1.0) | 0.9918 (3.0) | 0.9980 (2.0) | 0.8785 (4.0) |
| Rig-EK | 0.9992 (2.0) | 0.9761 (3.0) | 0.9996 (1.0) | 0.9201 (4.0) |
| Trickbot | 0.9992 (2.0) | 0.9799 (3.0) | 0.9994 (1.0) | 0.9019 (4.0) |
| Zeus | 0.9979 (2.0) | 0.9921 (3.0) | 0.9985 (1.0) | 0.8891 (4.0) |
| Average Rank | 1.75 | 3.00 | 1.25 | 4.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, J.; Roh, H. Experimental Evaluation of Malware Family Classification Methods from Sequential Information of TLS-Encrypted Traffic. Electronics 2021, 10, 3180. https://doi.org/10.3390/electronics10243180
Ha J, Roh H. Experimental Evaluation of Malware Family Classification Methods from Sequential Information of TLS-Encrypted Traffic. Electronics. 2021; 10(24):3180. https://doi.org/10.3390/electronics10243180
Chicago/Turabian StyleHa, Joonseo, and Heejun Roh. 2021. "Experimental Evaluation of Malware Family Classification Methods from Sequential Information of TLS-Encrypted Traffic" Electronics 10, no. 24: 3180. https://doi.org/10.3390/electronics10243180
APA StyleHa, J., & Roh, H. (2021). Experimental Evaluation of Malware Family Classification Methods from Sequential Information of TLS-Encrypted Traffic. Electronics, 10(24), 3180. https://doi.org/10.3390/electronics10243180