The merging stage transforms a layout from a large set of relatively simple shapes into a smaller set of polygons that are more complex and thus more distinct. Inclusion of polysilicon features, being mostly MOSFET gates, makes this method sensitive not only to the shapes of interconnects but also to the size and orientation of MOSFETs.
The proposed method of plagiarism detection has two main components: identification of corresponding nets in a given pair of layouts and quantification of the visual similarity between corresponding nets. These two stages are described below.
2.2. Comparison of Corresponding Net Shapes
The initial approach adopted in this work relied on comparing nets based on their fundamental geometric properties. Those included the centroid, surface area, perimeter, moment of inertia, and moment invariants. However, it soon turned out that a single parameter, or even a linear combination of all the parameters listed above, is insufficient to capture enough properties of a polygon to reliably express visual similarity between two nets.
A better approach relies on representing the border (perimeter) of a polygon as a sequence of fixed-length vectors. Since most shapes on IC layouts are aligned along one of the two principal axes, those vectors point in one of four directions. Thus, each of them can be encoded as one of the four cardinal directions, i.e., N, S, W, or E. This way, the entire border of a polygon can be encoded as a string composed of those four symbols. The application of this idea to the nets from
Figure 2 is shown in
Figure 3. The black dots mark the initial point of the sequences.
Once two nets are encoded as strings, the dissimilarity between them may be expressed in a quantitative manner. In the simplest case, it is defined as the edit distance or the minimum number of basic operations necessary to align those strings, i.e., transform one into the other. Two such transformations are possible:
In the case of a mismatch between corresponding symbols in the two strings, a symbol copied from one of them replaces its counterpart in the other.
A symbol copied from one string is inserted into a gap made between symbols in the other string. This is equivalent to deleting the symbol from the original string. Either way, the length of one of the strings is modified.
Figure 4 shows one possible alignment of the strings describing nets
A and
B from
Figure 3.
Aligning these strings requires inserting two “missing” symbols into the top string and two other into the bottom string. The gaps made for the inserted symbols are denoted as dashes and marked in blue. In spite of the four insertions, though, a mismatch between letters S and N (marked in yellow) was unavoidable in the presented example. Other solutions, i.e., different locations of insertions and mismatches, are possible for this example. It can be easily shown, however, that the total number of those basic operations cannot be less than five, which is the actual edit distance between those two strings.
If a negative (or zero) weight is assigned to each matching pair of letters while insertions and mismatches carry positive weights, the best alignment between two strings can be defined as one that minimizes the sum of those weights. Finding such an alignment becomes an optimization problem known as
edit distance minimization (see, e.g., [
11], Chapter 6.3). This is the task performed, e.g., by spell checkers searching a dictionary for the best match for a misspelled word. In the simplest formulation of this problem, a mismatch and an insertion incur the same penalty. However, differentiating the cost of these two transformations may be useful in the context of comparing polygons with respect to their shape. An insertion is usually performed to match two identically oriented edges of different lengths. The last two insertions in
Figure 4, for instance, are necessary because nets
A and
B differ in the length of the branches pointing left and down. Still, such a size difference between two nets does not make them much different visually. A mismatch, on the other hand, corresponds to a pair of similarly sized but differently oriented edges—see the mismatch in
Figure 4, corresponding to differently oriented “jogs” in the horizontal parts of nets
A and
B. Differences in direction are easier to spot visually than differences in length. More importantly, the presence of differently oriented edges may suggest that the two interconnects are routed into different parts of their respective cells, thus making the entire cells look different. For these reasons, it seems reasonable to penalize mismatches more heavily than insertions.
The best alignment between two sequences of symbols is usually found using dynamic programming. In the case where the costs of insertions and mismatches are allowed to differ from each other, the procedure of choice is the Needleman–Wunsch algorithm (NWA) [
12]. This method was used for decades to align sequences of amino acids or nucleotides. However, it has also found numerous applications outside biology and chemistry.
One of several possible formulations of the NWA uses a positive cost d of an insertion as well as a function , whose value depends on whether the i-th symbol in the first string and the j-th symbol in the second string match or not. Comparing an m-letter string with another, n-letter string, starts with building an m-by-n matrix F. Its entry (i, j) corresponds to the cost of optimal alignment of the first i characters of the first string with the first j characters of the second string. The strings are analyzed from left to right; therefore, the matrix is filled out starting from the top-left corner (alignment of two empty strings) until the bottom-right entry is inserted (cost of aligning the complete strings). The matrix is initially empty with the exception of the first column and first row. The i-th entry in the first column corresponds to the cost of aligning the first i characters in the first string to an empty string. This task requires copying all the first i letters from the first string into an empty sequence, with each such insertion entailing the cost d. Thus, subsequent entries in the first column are d, , …, . Similarly, the j-th entry in the first row corresponds to the cost of aligning the second string to an empty sequence, so this row is filled out in the same way. The rest of matrix F is then filled out from left to right and from top to bottom, which corresponds to aligning increasingly long subsequences of both strings starting from the beginning. Every step must minimize the aggregate cost of such an alignment, i.e., the cost including all the previous steps. Matching the i-th symbol in the first string with the j-th symbol in the second one may be performed in one of three ways:
The i-th symbol is copied from the first string into the second one;
The j-th symbol is copied from the second string into the first one;
No modifications are made, and the cost of this step depends on whether or not the symbols match.
Out of those three possibilities, the operation minimizing the aggregate cost is chosen. Using the matrix notation, this choice can be written as:
After filling out a row (or column), the procedure is performed for the next row (or column) until the entire matrix is filled. The bottom-right entry is the last to be evaluated. It contains the full cost of matching the entire strings.
The following example illustrates the determination of optimal alignment cost of strings
and
. The costs of single-symbol mismatch and match are assumed here to be:
while the insertion cost is
. These values reflect the idea that, as previously stated, a mismatch should be penalized more heavily than an insertion, while a match should entail no cost.
Figure 5 shows the matrix used to achieve the optimal alignment.
Arrows leaving a cell point to all the optimal alignments of strings that can be transformed into the given string by making one of the basic operations. An upward-pointing arrow leaving cell
means that the optimal choice is to copy the
i-th symbol from NESW into NEENW—case ➀ in Formula (
2). An insertion from NEENW into NESW (case ➁) is indicated by a left-pointing arrow. A diagonal arrow means that matching the
i-th character of NESW with the
j-th character of NEENW is the best choice (case ➂). Pursuing the path from the bottom-right cell to the top-left one while performing the appropriate operation at each step allows one to reconstruct the optimally aligned strings. In some cases, two or three choices result in the same cost, which is reflected by two or three arrows leaving the cell. The example at hand has several optimal solutions, two of which have been plotted as colored paths. The solid orange line corresponds to string
b being transformed into NE–SW, while the dashed blue line corresponds to this string being transformed into NES–W. All the optimal alignments have a cost of 3, which is the bottom-right entry in the matrix. The actual transformations are of no interest in the context of IC layout comparison. What is important to note, however, is that if both strings are encoded as sequences of a similar length, say
l characters, the entire procedure of filling the matrix takes
time.
The proportion between the number of errors, i.e. insertions and mismatches, and the string length after the alignment (aligned strings have by definition identical lengths) is used as a measure of
distance between the nets represented by those strings. In the case of strings in
Figure 4, the distance is thus
. On the level of entire layouts, the
distance Δ
between a pair of designs is defined as the average distance between all the pairs of corresponding nets.
2.3. Algorithm Tuning
The procedure outlined above has several parameters, whose values affect both its execution time and accuracy. Some suggestions are provided below as to the choice of those values. This choice was validated using three benchmarks composed of operational transconductance amplifiers (OTAs), NAND gates, and OR gates. Within each benchmark, some layouts were considered “visually similar”.
Table 1 sums up the composition of each benchmark.
The layouts of those circuits were designed for a legacy technology used at the authors’ university to teach microelectronic design basics. The minimum MOSFET gate length in this technology is . The logic cells had a height between 30 and , while the OTA layouts measured between 150 and on a side.
One of the essential parameters to consider while encoding the nets as strings is the symbol length , defined here as the length of a net edge to be encoded as a single symbol (“character”) in a string. Intuitively, a smaller should provide better resolution, and hence superior accuracy, at the expense of a longer running time. The minimum value worth considering is the feature size of the target technology. Such a choice, however, would lead to nets being encoded as very long strings, which in turn would negatively impact the execution time. Therefore, the symbol length was tentatively chosen as , i.e., five times the process feature size and approximately one-tenth the logic gate height. This choice is justified later in this section.
Another important decision had to be taken regarding the encoding of edges shorter than
as well as the “remainders” of those edges whose lengths are not a multiple of
. Such edges and edge parts may be either encoded as symbols or ignored, as shown in
Figure 6a,b, respectively.
Solution (a) was used in this work, since it has been shown to consistently lead to smaller errors at the expense of producing slightly longer strings. However, it was decided to ignore any edges shorter than . This serves to smooth out small “jogs” in net borders.
As explained before, the insertion cost
d used in the NWA is allowed to differ from the mismatch cost. What matters is actually the ratio between those two quantities; therefore, the mismatch cost was assumed to be unity. As for the insertion cost
d, several values were tested while running the proposed procedure on the benchmarks. The NAND and OR gates were pooled together in this experiment in order to increase the sample size. OTAs were analyzed separately because of their significantly larger dimensions. Within each of those groups, all possible pairwise comparisons were performed. Statistical distributions of distance
obtained for several values of
d were approximated using kernel density estimations. The distributions were plotted in
Figure 7 separately for visually similar pairs (green) and for different ones (red). Since some differences in net shapes and sizes occur even in “similar” designs, increasing the insertion cost inevitably translates into greater values of
both for different pairs and for similar ones. What matters, however, is not the value of
but the separation between the two distributions. Ideally, the “most similar among the different” pairs should have a
greater than the “most different among the similar” ones. As regards OTAs, this is indeed the case irrespective of
d. As for logic gates (
Figure 7b), the separation is never perfect, but it improves as
d drops below unity. Interestingly, reducing the insertion cost
d further, below about
, does not change the distributions any more. This may be because insertions become so inexpensive that any shape difference between nets can be canceled by inserting an appropriate number of symbols into one or both nets, without the need to accept a relatively expensive mismatch. Based on the results of this experiment, the value
was chosen for the rest of this work.
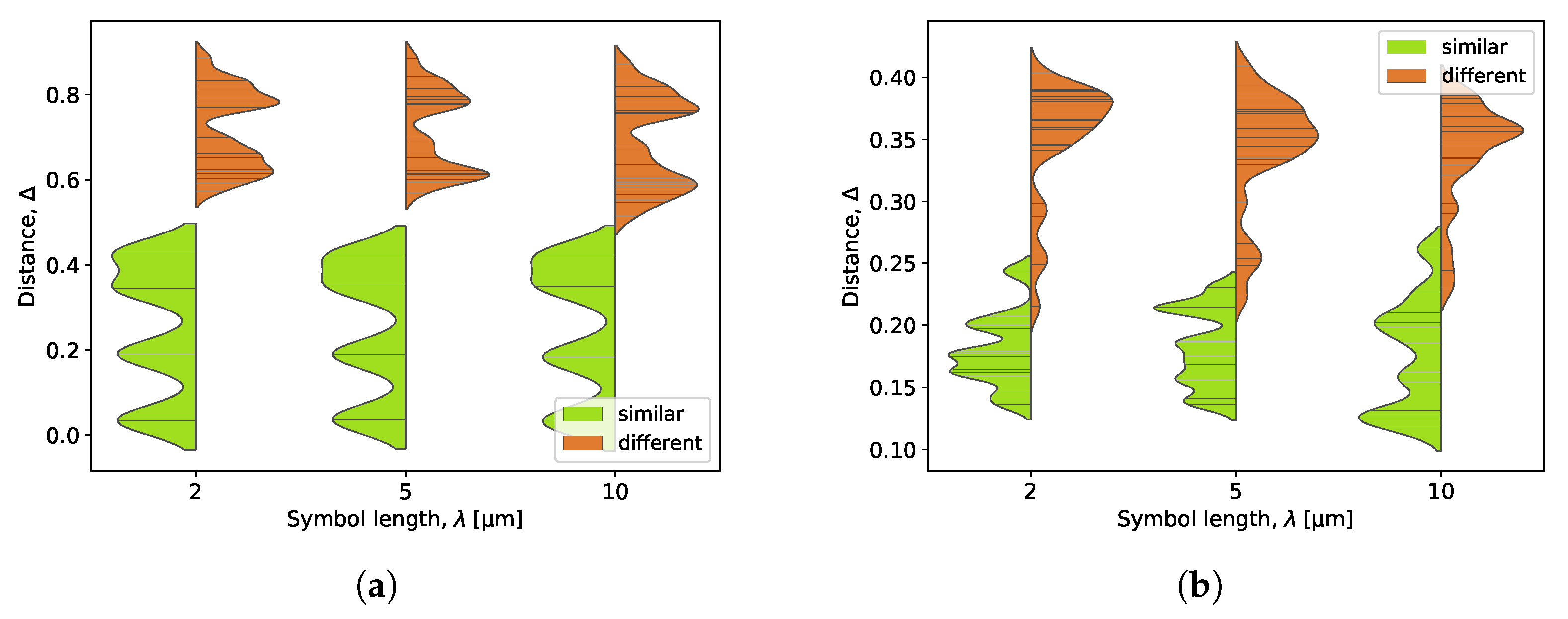
The same experimental setup was used to validate the choice of symbol length. As shown in
Figure 8, the value
used so far provides a better separation of “similar” and “dissimilar” cases than
. Further reduction of
to
does not visibly affect the distributions while producing longer symbol strings, which adversely affects the computation time.
To conclude, the most reasonable settings for the proposed procedure seem to be: symbol length about five times the minimum feature size and insertion cost .
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}