
An Efficient Real-Time FPGA-Based ORB Feature Extraction for an UHD Video Stream for Embedded Visual SLAM



Abstract
:1. Introduction
2. Oriented FAST and Rotated BRIEF
- Performing the fast accelerated segment test to determine the corners (FAST).
- Filtration using non-maximum suppression (NMS).
- Elimination of feature points for which it is not possible to determine the full context pixels (px).
- Filtering of feature points and leaving only the best N points.
- Computation of the Harris score and re-filtering of feature points.
- Calculation of the orientation of the feature point (intensity centroid).
- Determination of the context px and blurring with a Gaussian filter.
- Determination of the binary feature descriptor (rBRIEF).
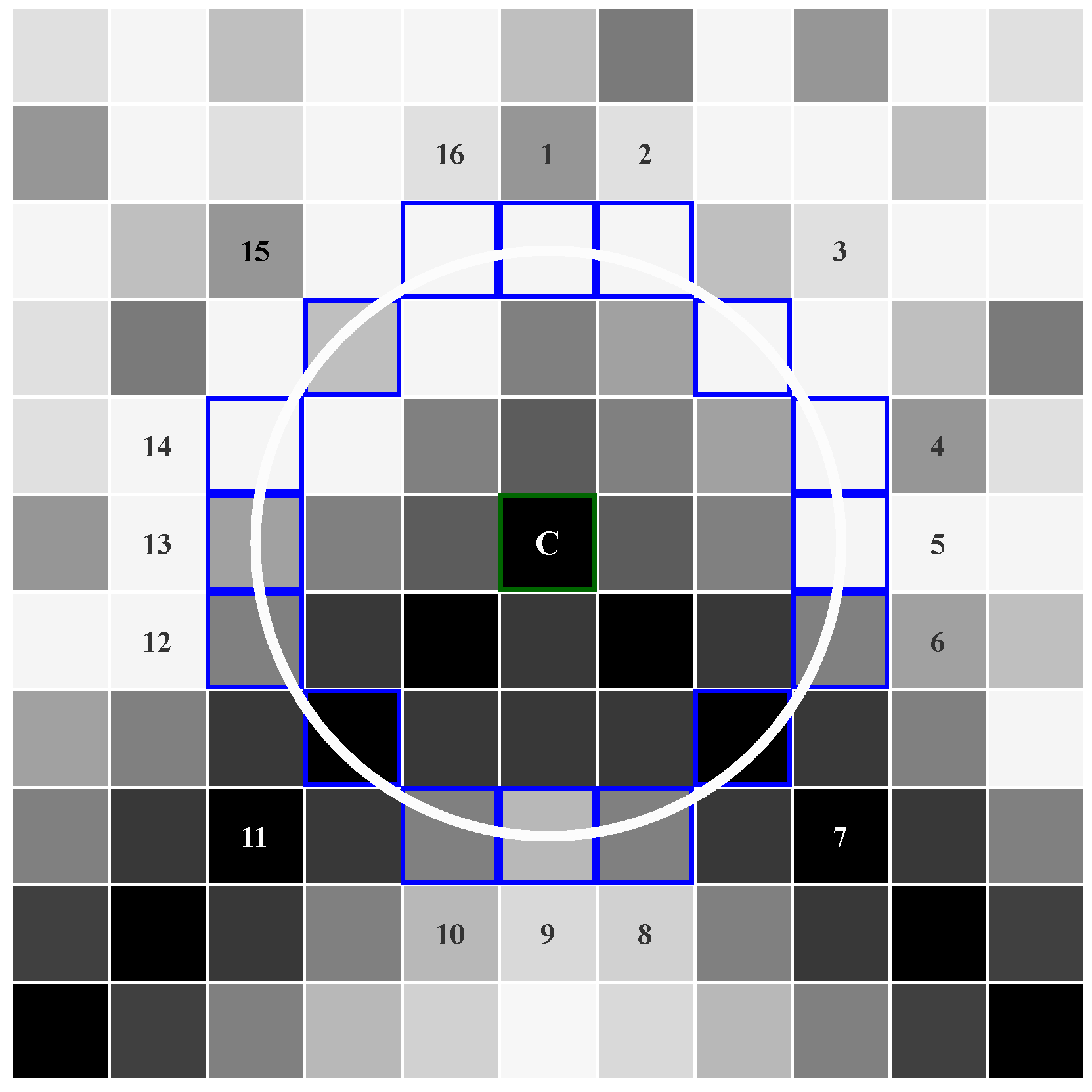
2.1. Oriented FAST Feature Detector
2.2. Rotated BRIEF Descriptor
3. Related Work
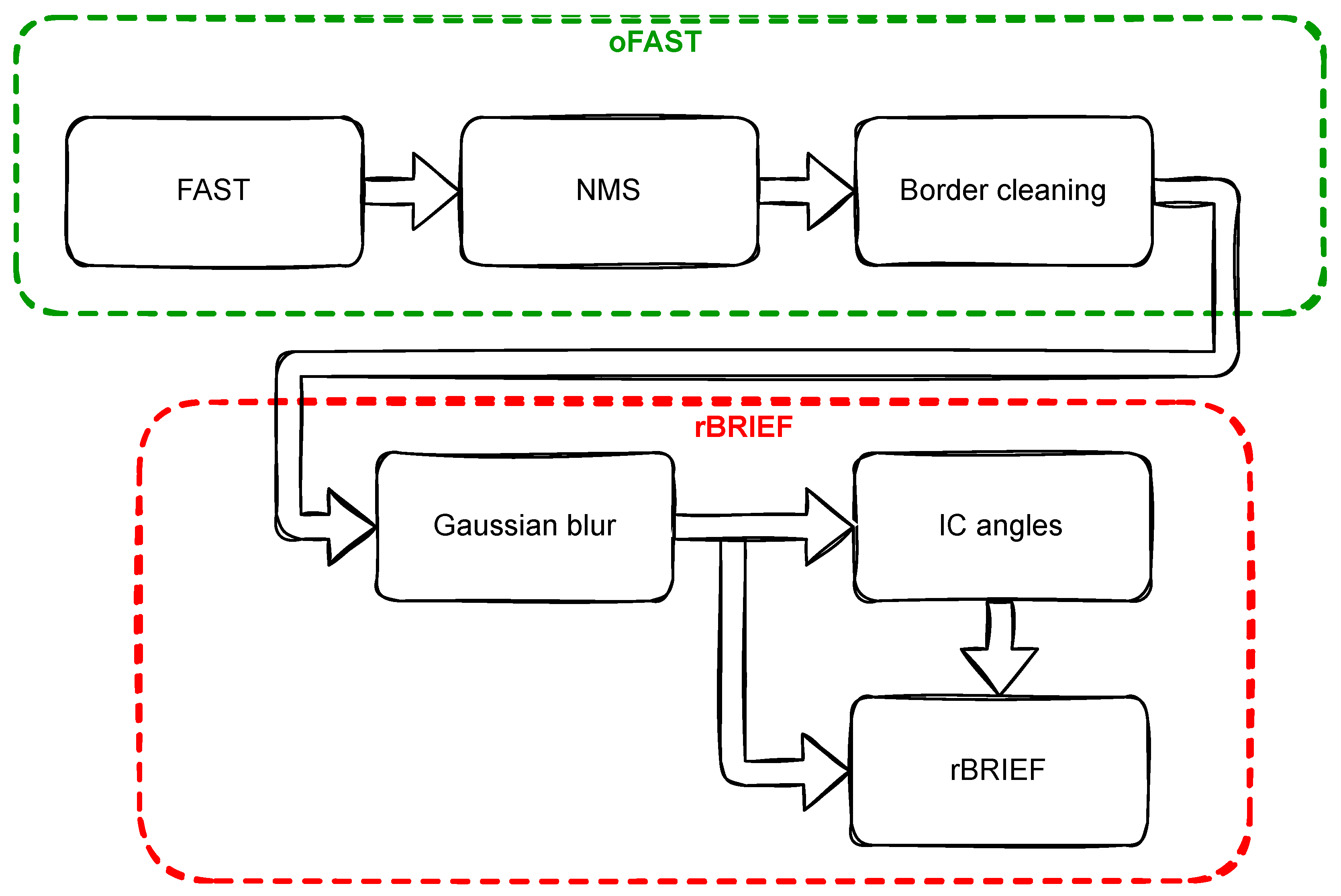
4. The Proposed ORB (FAST+BRIEF) Implementation
- Performing the fast accelerated segment test to determine the corners (FAST).
- Filtration using non-maximum suppression (NMS).
- Elimination of feature points for which it is not possible to determine the context px (border cleaning).
- Determination of the context px and blurring with a Gaussian filter.
- Calculation of the orientation of the feature point (IC angles).
- Determination of the binary feature descriptor (rBRIEF).
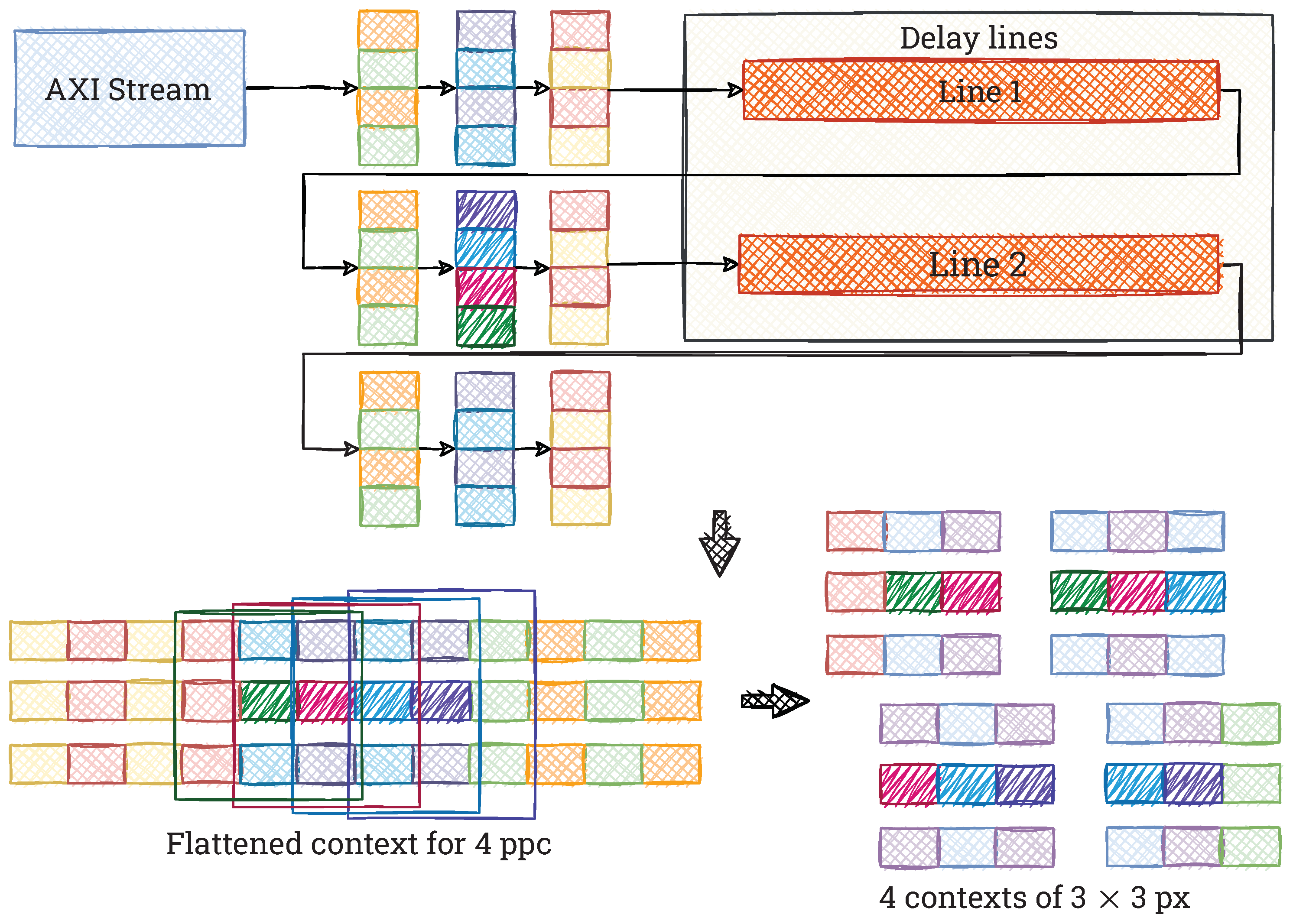
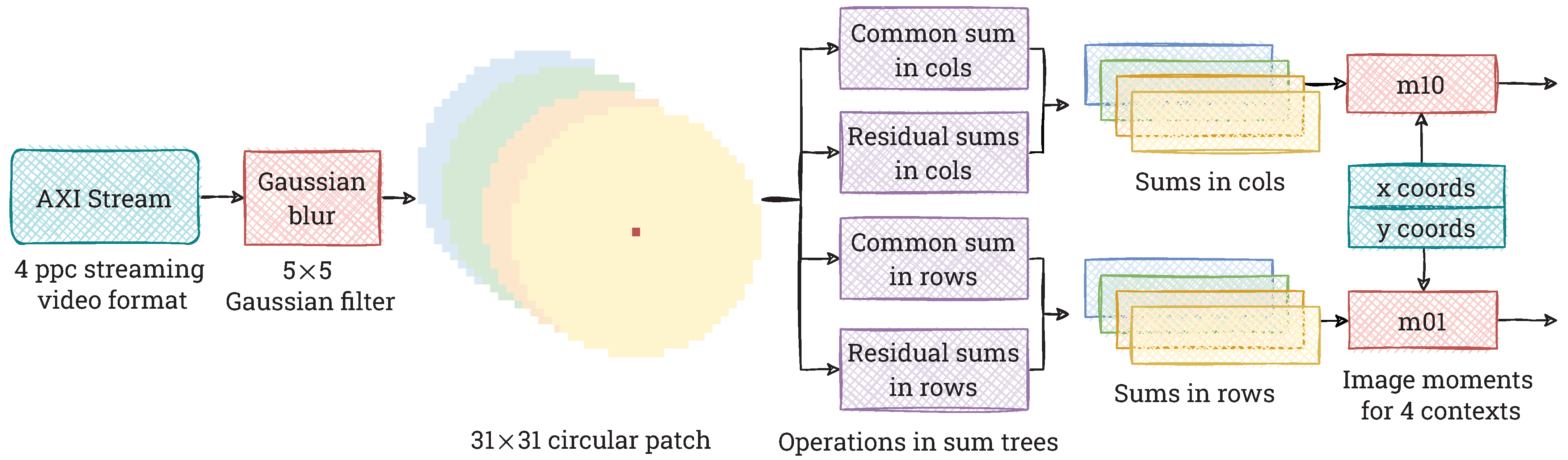
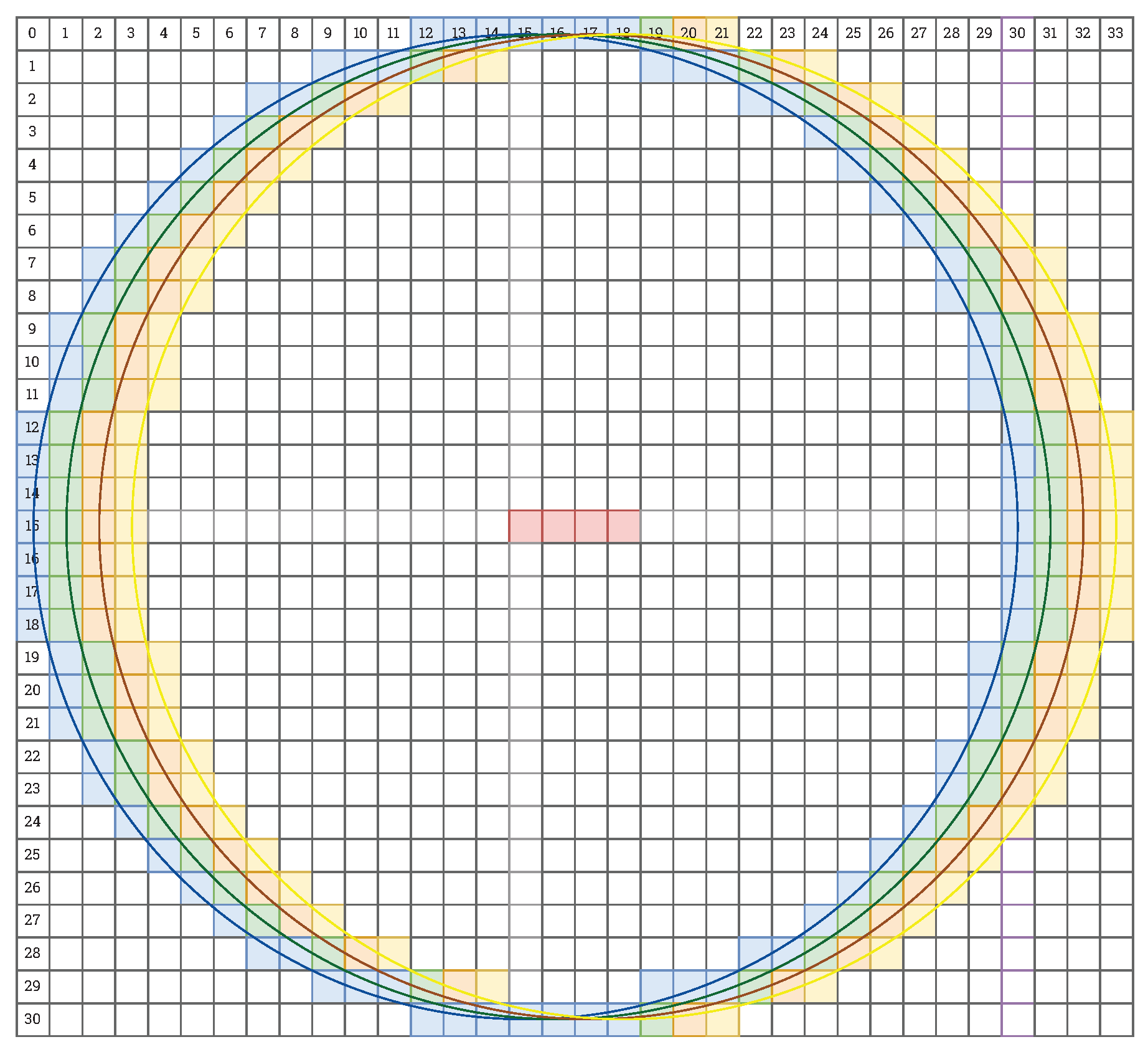
4.1. Context Generation in 4K
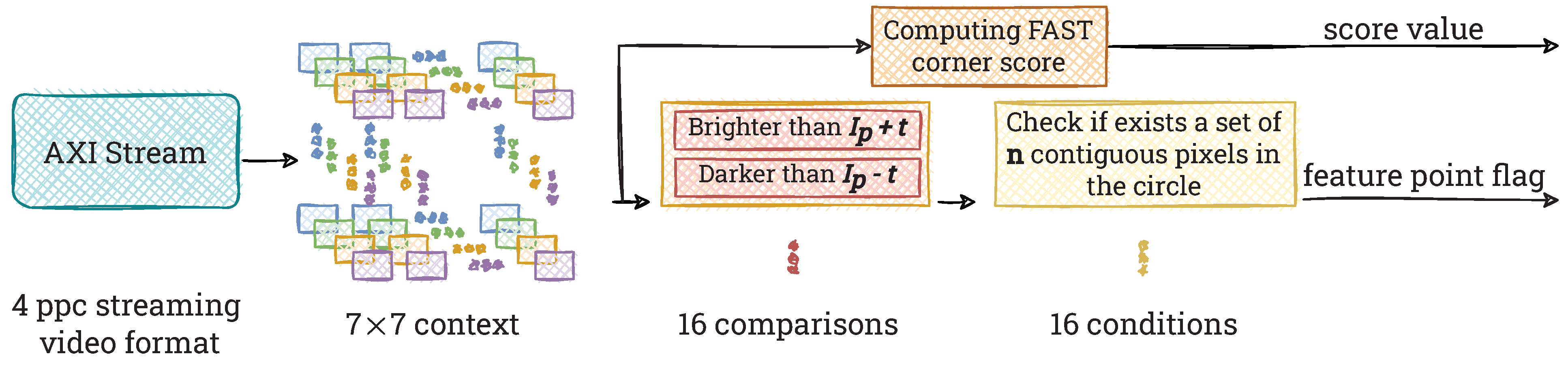
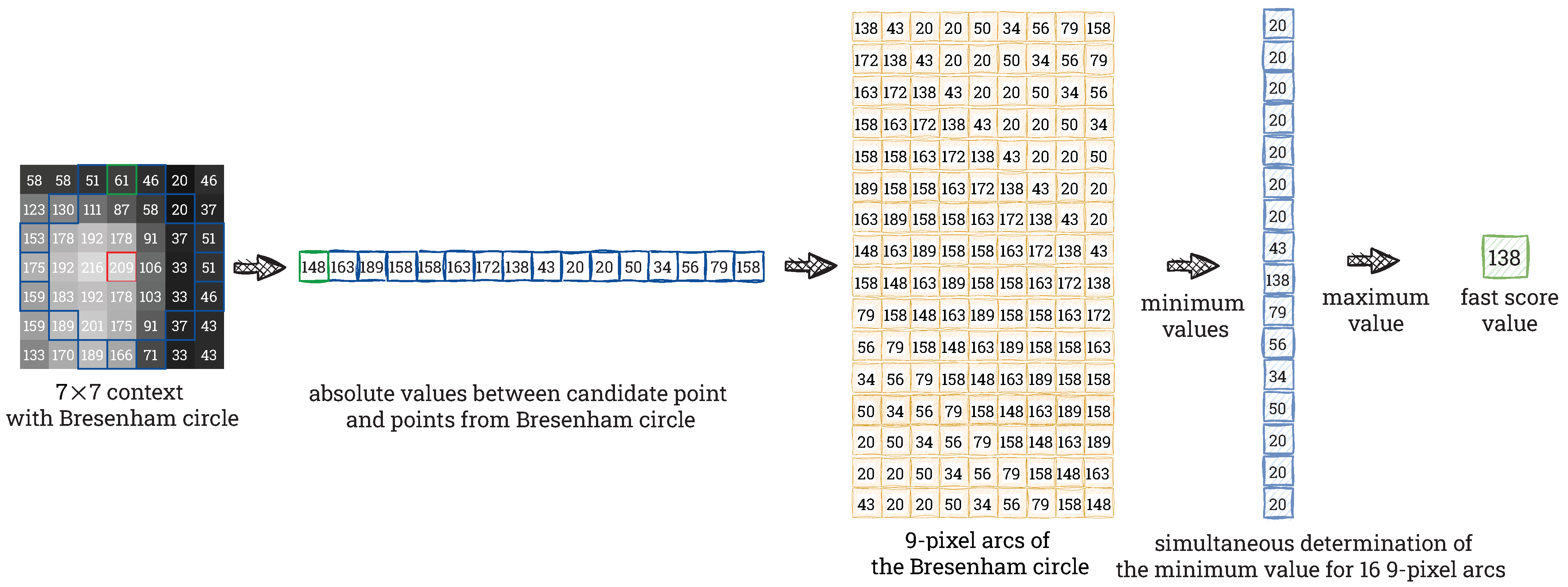
4.2. FAST Feature Detector
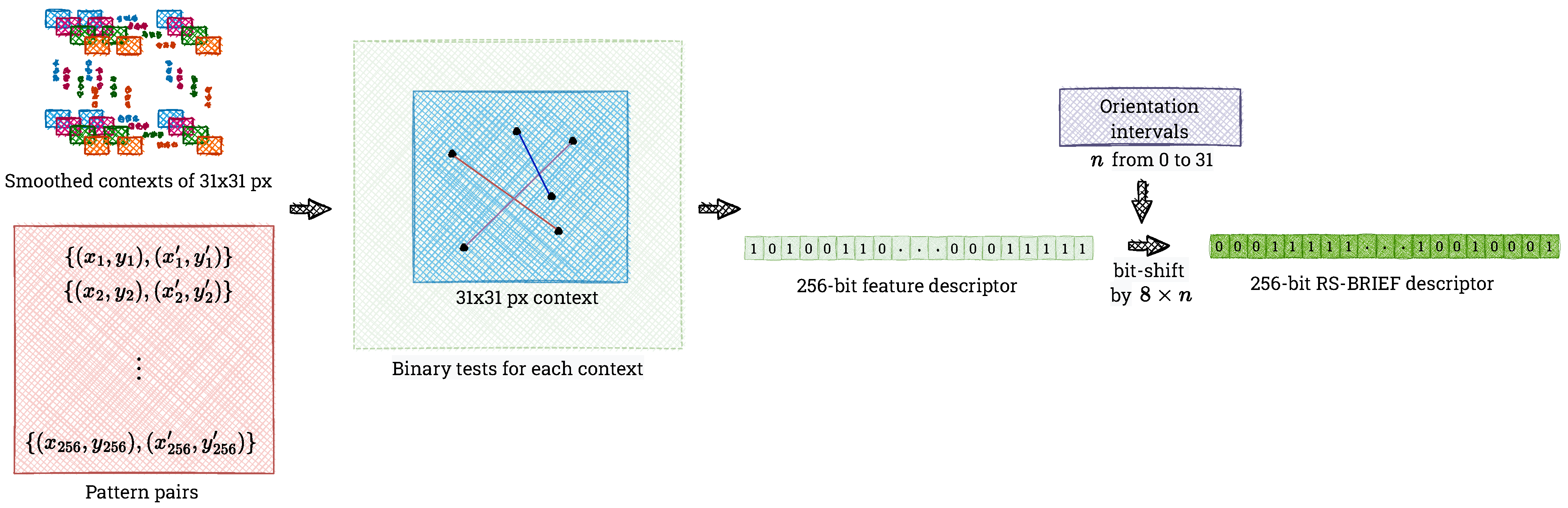
4.3. BRIEF Descriptor
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Lecture Notes in Computer Science, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Rosin, P.L. Measuring corner properties. Comput. Vis. Image Underst. 1999, 73, 291–307. [Google Scholar] [CrossRef] [Green Version]
- Calonder, M.; Lepetit, V.; Strecha, C.; Brief, F. Binary robust independent elementary features. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Liu, R.; Yang, J.; Chen, Y.; Zhao, W. eslam: An energy-efficient accelerator for real-time orb-slam on fpga platform. In Proceedings of the Proceedings of the 56th Annual Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Cui, T.; Guo, C.; Liu, Y.; Tian, Z. Precise landing control of UAV based on binocular visual SLAM. In Proceedings of the 2021 4th International Conference on Intelligent Autonomous Systems (ICoIAS), Wuhan, China, 14–16 May 2021; pp. 312–317. [Google Scholar]
- Sun, R.; Qian, J.; Jose, R.H.; Gong, Z.; Miao, R.; Xue, W.; Liu, P. A flexible and efficient real-time orb-based full-hd image feature extraction accelerator. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 565–575. [Google Scholar] [CrossRef]
- Fularz, M.; Kraft, M.; Schmidt, A.; Kasiński, A. A high-performance FPGA-based image feature detector and matcher based on the FAST and BRIEF algorithms. Int. J. Adv. Robot. Syst. 2015, 12, 141. [Google Scholar] [CrossRef] [Green Version]
- Fang, W.; Zhang, Y.; Yu, B.; Liu, S. FPGA-based ORB feature extraction for real-time visual SLAM. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 11–13 December 2017; pp. 275–278. [Google Scholar]
- Ding, R.; Sun, H.; Ye, P. Multi-scale FAST feature extraction heterogeneous design based on FPGA. In Proceedings of the 2018 5th International Conference on Systems and Informatics, Nanjing, China, 10–12 November 2018; pp. 100–108. [Google Scholar] [CrossRef]
- Kalms, L.; Ibrahim, H.; Gohringer, D. Full-HD accelerated and embedded feature detection video system with 63fps using ORB for FREAK. In Proceedings of the 2018 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 3–5 December 2018. [Google Scholar] [CrossRef]
- Sun, R.; Liu, P.; Wang, J.; Accetti, C.; Naqvi, A.A. A 42 fps full-HD ORB feature extraction accelerator with reduced memory overhead. In Proceedings of the 2017 International Conference on Field-Programmable Technology, ICFPT 2017, Melbourne, VIC, Australia, 11–13 December 2017; pp. 183–190. [Google Scholar] [CrossRef]
- Wang, C.; Liu, Y.; Zuo, K.; Tong, J.; Ding, Y.; Ren, P. ac2SLAM: FPGA Accelerated High-Accuracy SLAM with Heapsort and Parallel Keypoint Extractor. In Proceedings of the 2021 International Conference on Field-Programmable Technology (ICFPT), Auckland, New Zealand, 6–10 December 2021; pp. 1–9. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Imsaengsuk, T.; Pumrin, S. Feature Detection and Description based on ORB Algorithm for FPGA-based Image Processing. In Proceedings of the 2021 9th International Electrical Engineering Congress (iEECON), Pattaya, Thailand, 10–12 March 2021; pp. 420–423. [Google Scholar]
- Kowalczyk, M.; Przewlocka, D.; Kryjak, T. Real-time implementation of contextual image processing operations for 4K video stream in Zynq ultrascale+ MPSoC. In Proceedings of the 2018 Conference on Design and Architectures for Signal and Image Processing (DASIP), Porto, Portugal, 10–12 October 2018; pp. 37–42. [Google Scholar]
- Pham, T.H.; Tran, P.; Lam, S.K. High-throughput and area-optimized architecture for rbrief feature extraction. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 27, 747–756. [Google Scholar] [CrossRef]
- Xie, Z.; Wang, Y.; Yan, Z.; Wang, J.; Zhong, S. A real-time FPGA-based architecture of improved ORB. In Proceedings of the MIPPR 2019: Parallel Processing of Images and Optimization Techniques; and Medical Imaging, Wuhan, China, 2–3 November 2019; Volume 11431, p. 1143102. [Google Scholar]
- Zhang, Z.; Chen, H.; Zhou, L.; Wang, Z. Bucket-FEM: A Bucket-based Architecture of Real-time ORB Feature Extraction and Matching for Embedded SLAM Applications. In Proceedings of the 2021 6th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 19–21 November 2021; pp. 183–187. [Google Scholar]
- Heo, H.; Lee, J.Y.; Lee, K.y.; Lee, C.h. FPGA based implementation of FAST and BRIEF algorithm for object recognition. In Proceedings of the 2013 IEEE International Conference of IEEE Region 10 (TENCON 2013), Xi’an, China, 22–25 October 2013; pp. 1–4. [Google Scholar]
- Weberruss, J.; Kleeman, L.; Boland, D.; Drummond, T. FPGA acceleration of multilevel ORB feature extraction for computer vision. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; pp. 1–8. [Google Scholar]
- Huang, J.; Zhou, G.; Zhou, X.; Zhang, R. A new FPGA architecture of FAST and BRIEF algorithm for on-board corner detection and matching. Sensors 2018, 18, 1014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sturmanis, T.; Novickis, R. An efficient FPGA-based co-processor for sparse optical flow calculation in drone agents. In Proceedings of the 2021 24th Euromicro Conference on Digital System Design (DSD), Palermo, Italy, 1–3 September 2021. [Google Scholar] [CrossRef]
- Oxford Visual Geometry Group. Affine Covariant Features Datasets. [Online]. 2004. Available online: http://www.robots.ox.ac.uk/vgg/data/affine/ (accessed on 28 June 2022).
- OpenCV: Camera Calibration and 3D Reconstruction. [Online]. Available online: https://docs.opencv.org/4.6.0/d9/d0c/group__calib3d.html#ga61585db663d9da06b68e70cfbf6a1eac (accessed on 28 June 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Width | Precision |
|---|---|---|
| Fast Score values | 8 | 0 |
| Gaussian coefficient | 24 | 16 |
| Pixel values after Gaussian filter | 8 | 0 |
| Moments | 21 | 0 |
| Tangent values | 10 | 7 |
| Orientation interval number | 5 | 0 |
| Pattern pairs | 5 | 0 |
| BRIEF descriptor | 256 | 0 |
| Resource | Pass-Through | FAST | BRIEF | ORB | Entire System | Available |
|---|---|---|---|---|---|---|
| LUT | 38,383 | 11,041 | 51,182 | 62,223 (27%) | 100,606 (44%) | 230,400 |
| LUTRAM | 4564 | 386 | 11,951 | 12,337 (12%) | 16,901 (17%) | 101,760 |
| FF | 45,278 | 12,071 | 82,942 | 95,013 (21%) | 140,291 (31%) | 460,800 |
| CARRY8 | 925 | 1056 | 9043 | 10,099 (35%) | 11,024 (38%) | 28,800 |
| BRAM | 7 | 9 | 36 | 45 (14.4%) | 52 (17%) | 312 |
| DSP | 15 | 0 | 668 | 668 (38.7%) | 683 (40%) | 1728 |
| FPGA | Algorithm | # of LUTs | # of Registers, FFs | BRAM | DSP Blocks | FPS | Freq. [MHz] | Resolution | |
|---|---|---|---|---|---|---|---|---|---|
| [25] | AMD Xilinx Zynq-7000 | ORB +,1 | 4257 | 3187 | 576 Kb | - | 55 | 100 | |
| [13] | AMD Xilinx ZedBoard | ORB # | 9866 | 17,412 | 1.33 Mb | - | 325 | 100 | |
| [14] | Altera Stratix V | ORB #,4 | 25,648 | 21,791 | 9.44 Mb | 8 | 67 | 203 | |
| [26] | Altera Aria V | ORB +,8 | 206,000 | 231,973 | 8.58 Mb | 449 | 72 | 150 | |
| [27] | AMD Xilinx Kintex-7 | ORB + | 80,472 | 112,166 | 35 Kb | 0 | 310 | 100 | |
| [16] | AMD Xilinx ZedBoard | FAST #,2,6 | 5700 | 6272 | 1.984 Mb | - | 63 | 148.5 | |
| [22] | Altera Aria V | BRIEF #,3 | 12,523 | 10,019 | 110 Kb | 0 | 60 | 175 | |
| [12] | AMD Xilinx Ultrascale+ | ORB +,5 | 28,168 | 9528 | 1.47 Mb | 33 | 108 | 200 | |
| [9] | AMD Xilinx XCZ7045 | ORB +,6 | 56,954 | 67,809 | 2.73 Mb | 111 | 76 | 100 | |
| [23] | AMD Xilinx Kintex-7 | ORB # | 54,435 | 30,281 | 1.836 Mb | 44 | 161 | 150 | |
| [28] | Altera Cyclone V | ORB +,9 | 5711 | 5453 | 0.3–2.3 Mb | - | 325 | 100 | |
| [24] | AMD Xilinx Virtex-7 | ORB #,6,9 | 71,423 | 49,649 | 3.132 Mb | 285 | 68.8 | 142.8 | |
| [18] | AMD Xilinx ZCU 104 | ORB +,6,7 | 146,572 | 74,166 | 7.43 Mb | 173 | - | 100 | - |
| Ours | AMD Xilinx ZCU 104 | ORB # | 100,606 | 140,291 | 6.7 Mb | 683 | 60 | 150 | 3840 × 2160 |
| Sequence | # of Image | Implementation | # of Keypoints | # of Matches | # of Inliers | Matching Rate | Rotation Error | Translation Error [] |
|---|---|---|---|---|---|---|---|---|
| Boat | 1 | OpenCV | 507 | 45 | 38 | 84% | 0.01679 | 2.06 |
| 2 | 507 | |||||||
| 1 | Hardware | 872 | 118 | 74 | 63% | 0.00116 | 1.50 | |
| 2 | 892 | |||||||
| Bikes | 1 | OpenCV | 537 | 201 | 199 | 99% | 0.00237 | 6.49 |
| 2 | 514 | |||||||
| 1 | Hardware | 486 | 235 | 221 | 94% | 0.00062 | 4.95 | |
| 2 | 462 | |||||||
| Graffiti | 1 | OpenCV | 509 | 48 | 41 | 85% | 0.01002 | 1.24 |
| 2 | 508 | |||||||
| 1 | Hardware | 604 | 94 | 65 | 69% | 0.01136 | 1.15 | |
| 2 | 607 |
| Resolution | FPS | Freq. [MHz] | Energy [mW] | |
|---|---|---|---|---|
| [14] | 67 | 203 | 4559 | |
| [26] | 72 | 150 | 5340 | |
| [22] | 60 | 175 | 456 | |
| [12] | 108 | 200 | 873 | |
| [24] | 68.8 | 142.8 | 507 (dynamic) | |
| Ours | 3840 × 2160 | 60 | 150 | 4278 (dynamic power) |
| 764 (static power) | ||||
| 5042 (total power) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wasala, M.; Szolc, H.; Kryjak, T. An Efficient Real-Time FPGA-Based ORB Feature Extraction for an UHD Video Stream for Embedded Visual SLAM. Electronics 2022, 11, 2259. https://doi.org/10.3390/electronics11142259
Wasala M, Szolc H, Kryjak T. An Efficient Real-Time FPGA-Based ORB Feature Extraction for an UHD Video Stream for Embedded Visual SLAM. Electronics. 2022; 11(14):2259. https://doi.org/10.3390/electronics11142259
Chicago/Turabian StyleWasala, Mateusz, Hubert Szolc, and Tomasz Kryjak. 2022. "An Efficient Real-Time FPGA-Based ORB Feature Extraction for an UHD Video Stream for Embedded Visual SLAM" Electronics 11, no. 14: 2259. https://doi.org/10.3390/electronics11142259
APA StyleWasala, M., Szolc, H., & Kryjak, T. (2022). An Efficient Real-Time FPGA-Based ORB Feature Extraction for an UHD Video Stream for Embedded Visual SLAM. Electronics, 11(14), 2259. https://doi.org/10.3390/electronics11142259