
MSEDTNet: Multi-Scale Encoder and Decoder with Transformer for Bladder Tumor Segmentation



Abstract
:1. Introduction
2. Related Work
2.1. Bladder Tumor Segmentation
2.2. Transformer
3. Methods
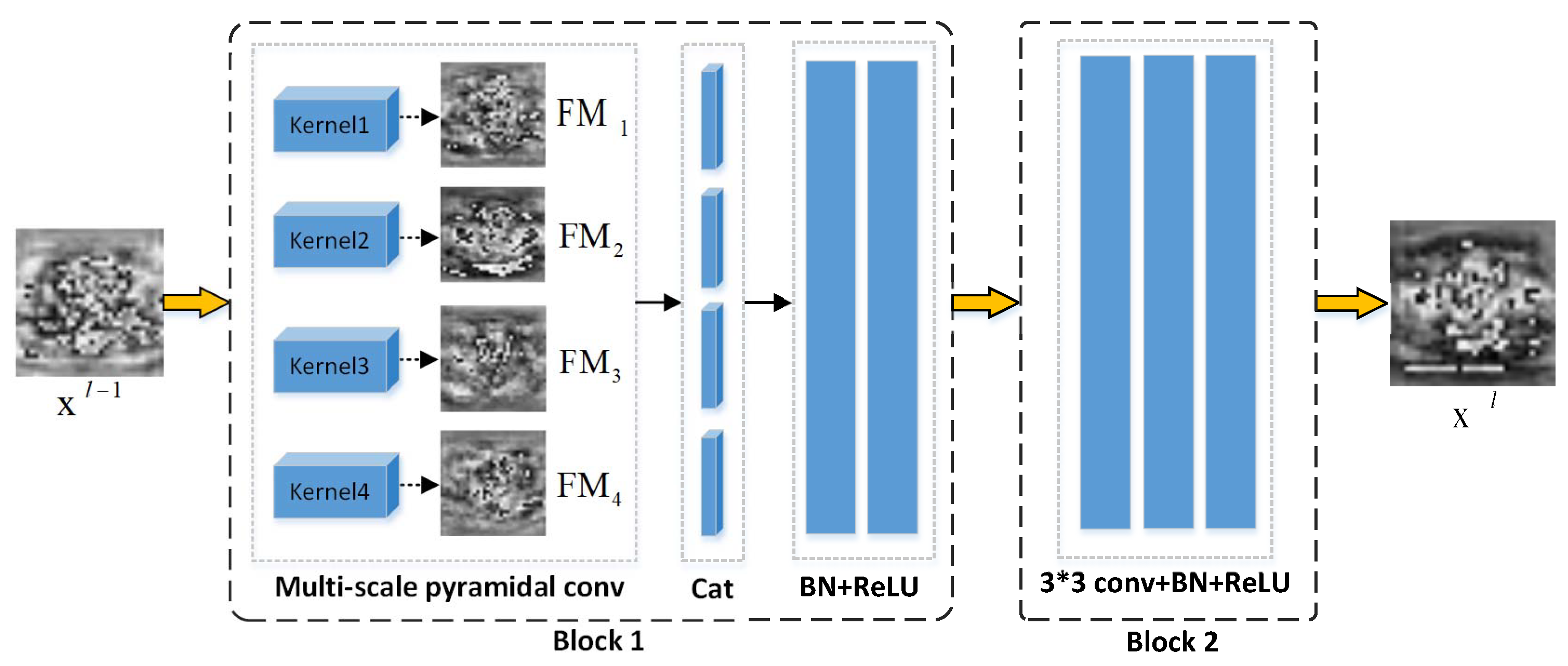
3.1. Multi-Scale Encoder
3.2. Transformer Bottleneck
3.3. Decoder with Spatial Context Fusion
4. Experiments
4.1. Dataset
4.2. Experiments and Implementation Details
4.3. Evaluate Metrics
5. Results and Analysis
5.1. Ablation Study
5.2. Segmentation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MSPC | Multi-Scale Pyramidal Convolution |
| SCFM | Spatial Context Fusion Module |
| SA | Self-Attention |
| MHSA | Multi-Head Self-Attention |
| MLP | Multilayer Perceptron |
| JI | Jaccard Index |
| DSC | Dice Similarity Coefficient |
| 95HD | 95th Percentage of Asymmetric Hausdorff Distance |
References
- Barani, M.; Hosseinikhah, S.M.; Rahdar, A.; Farhoudi, L.; Arshad, R.; Cucchiarini, M.; Pandey, S. Nanotechnology in bladder cancer: Diagnosis and treatment. Cancers 2021, 13, 2214. [Google Scholar] [CrossRef]
- Antoni, S.; Ferlay, J.; Soerjomataram, I.; Znaor, A.; Jemal, A.; Bray, F. Bladder cancer incidence and mortality: A global overview and recent trends. Eur. Urol. 2017, 71, 96–108. [Google Scholar] [CrossRef] [PubMed]
- Baressi Šegota, S.; Lorencin, I.; Smolić, K.; Anḍelić, N.; Markić, D.; Mrzljak, V.; Štifanić, D.; Musulin, J.; Španjol, J.; Car, Z. Semantic Segmentation of Urinary Bladder Cancer Masses from CT Images: A Transfer Learning Approach. Biology 2021, 10, 1134. [Google Scholar] [CrossRef] [PubMed]
- Bandyk, M.G.; Gopireddy, D.R.; Lall, C.; Balaji, K.; Dolz, J. MRI and CT bladder segmentation from classical to deep learning based approaches: Current limitations and lessons. Comput. Biol. Med. 2021, 134, 104472. [Google Scholar] [CrossRef] [PubMed]
- Borhani, S.; Borhani, R.; Kajdacsy-Balla, A. Artificial intelligence: A promising frontier in bladder cancer diagnosis and outcome prediction. Crit. Rev. Oncol. 2022, 171, 103601. [Google Scholar] [CrossRef]
- Gandi, C.; Vaccarella, L.; Bientinesi, R.; Racioppi, M.; Pierconti, F.; Sacco, E. Bladder cancer in the time of machine learning: Intelligent tools for diagnosis and management. Urol. J. 2021, 88, 94–102. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, Q.; Liu, Y. Image Segmentation of Bladder Cancer Based on DeepLabv3+. In Proceedings of the 2021 Chinese Intelligent Systems Conference; Springer: Berlin/Heidelberg, Germany, 2022; pp. 614–621. [Google Scholar]
- Li, L.; Liang, Z.; Wang, S.; Lu, H.; Wei, X.; Wagshul, M.; Zawin, M.; Posniak, E.J.; Lee, C.S. Segmentation of multispectral bladder MR images with inhomogeneity correction for virtual cystoscopy. In Proceedings of the Medical Imaging 2008: Physiology, Function, and Structure from Medical Images. International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2008; Volume 6916, p. 69160U. [Google Scholar]
- Costa, M.J.; Delingette, H.; Ayache, N. Automatic segmentation of the bladder using deformable models. In Proceedings of the 2007 4th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Arlington, VA, USA, 12–15 April 2007; pp. 904–907. [Google Scholar]
- Duan, C.; Liang, Z.; Bao, S.; Zhu, H.; Wang, S.; Zhang, G.; Chen, J.J.; Lu, H. A coupled level set framework for bladder wall segmentation with application to MR cystography. IEEE Trans. Med. Imaging 2010, 29, 903–915. [Google Scholar] [CrossRef] [Green Version]
- Gsaxner, C.; Pfarrkirchner, B.; Lindner, L.; Pepe, A.; Roth, P.M.; Egger, J.; Wallner, J. PET-train: Automatic ground truth generation from PET acquisitions for urinary bladder segmentation in CT images using deep learning. In Proceedings of the 2018 11th Biomedical Engineering International Conference (BMEiCON), Chiang Mai, Thailand, 21–24 November 2018; pp. 1–5. [Google Scholar]
- Hammouda, K.; Khalifa, F.; Soliman, A.; Ghazal, M.; Abou El-Ghar, M.; Badawy, M.; Darwish, H.; Khelifi, A.; El-Baz, A. A multiparametric MRI-based CAD system for accurate diagnosis of bladder cancer staging. Comput. Med. Imaging Graph. 2021, 90, 101911. [Google Scholar] [CrossRef]
- Hu, H.; Zheng, Y.; Zhou, Q.; Xiao, J.; Chen, S.; Guan, Q. MC-Unet: Multi-scale convolution unet for bladder cancer cell segmentation in phase-contrast microscopy images. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 1197–1199. [Google Scholar]
- Liang, Y.; Zhang, Q.; Liu, Y. Automated Bladder Lesion Segmentation Based on Res-Unet. In Proceedings of the 2021 Chinese Intelligent Systems Conference; Springer: Singapore, 2022; pp. 606–613. [Google Scholar]
- Li, Z.; Feng, N.; Pu, H.; Dong, Q.; Liu, Y.; Liu, Y.; Xu, X. PIxel-Level Segmentation of Bladder Tumors on MR Images Using a Random Forest Classifier. Technol. Cancer Res. Treat. 2022, 21, 15330338221086395. [Google Scholar] [CrossRef]
- Dolz, J.; Xu, X.; Rony, J.; Yuan, J.; Liu, Y.; Granger, E.; Desrosiers, C.; Zhang, X.; Ben Ayed, I.; Lu, H. Multiregion segmentation of bladder cancer structures in MRI with progressive dilated convolutional networks. Med. Phys. 2018, 45, 5482–5493. [Google Scholar] [CrossRef]
- Ge, R.; Cai, H.; Yuan, X.; Qin, F.; Huang, Y.; Wang, P.; Lyu, L. MD-UNET: Multi-input dilated U-shape neural network for segmentation of bladder cancer. Comput. Biol. Chem. 2021, 93, 107510. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Liu, L.; Xu, B.; Hou, X.; Liu, B.; Chen, X.; Shen, L.; Qiu, G. Bladder cancer multi-class segmentation in mri with pyramid-in-pyramid network. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 28–31. [Google Scholar]
- Duta, I.C.; Liu, L.; Zhu, F.; Shao, L. Pyramidal convolution: Rethinking convolutional neural networks for visual recognition. arXiv 2020, arXiv:2006.11538. [Google Scholar]
- Li, C.; Fan, Y.; Cai, X. PyConvU-Net: A lightweight and multiscale network for biomedical image segmentation. BMC Bioinform. 2021, 22, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Wu, H.; Zhong, Z.; Zheng, L.; Deng, Q.; Hu, H. TWC-Net: A SAR ship detection using two-way convolution and multiscale feature mapping. Remote Sens. 2021, 13, 2558. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, Y.; Li, X.; Cong, J.; Li, X.; Wei, B. Segmentation algorithm of lightweight bladder cancer MRI images based on multi-scale feature fusion. J. Shanxi Norm. Univ. (Nat. Sci. Ed.) 2022, 50, 89–95. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. Transbts: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 109–119. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Liu, Y.; Li, X.; Li, T.; Li, B.; Wang, Z.; Gan, J.; Wei, B. A deep semantic segmentation correction network for multi-model tiny lesion areas detection. BMC Med. Informatics Decis. Mak. 2021, 21, 1–9. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Li, J. Tree-structured kronecker convolutional network for semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 940–945. [Google Scholar]
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-net transformer: Self and cross attention for medical image segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2021; pp. 267–276. [Google Scholar]
- Peng, C.; Ma, J. Semantic segmentation using stride spatial pyramid pooling and dual attention decoder. Pattern Recognit. 2020, 107, 107498. [Google Scholar] [CrossRef]
- Xu, R.; Wang, C.; Xu, S.; Meng, W.; Zhang, X. DC-net: Dual context network for 2D medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 503–513. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Description |
|---|---|
| BaseNet | vanilla UNet baseline |
| BaseMNet | baseline + MSPC |
| BaseMTNet | baseline + MSPC + transformer |
| MSEDTNet | baseline + MSPC + transformer + SCFM |
| Model | JI (%) ↑ | DSC (%) ↑ | 95HD (mm) ↓ |
|---|---|---|---|
| BaseNet | 79.04 ± 1.35 | 87.94 ± 0.89 | 3.96 ± 0.11 |
| BaseMNet | 80.51 ± 1.32 | 90.45 ± 1.17 | 3.97 ± 0.12 |
| BaseMTNet | 82.63 ± 1.33 | 91.16 ± 1.12 | 3.87 ± 0.10 |
| MSEDTNet | 83.46 ± 1.26 | 92.35 ± 1.19 | 3.64 ± 0.18 |
| Kernel Size | JI (%) ↑ | DSC (%) ↑ | 95HD (mm) ↓ |
|---|---|---|---|
| 1,3,5,7 | 81.27 ± 0.98 | 90.45 ± 1.02 | 3.78 ± 0.14 |
| 1,3,9,11 | 81.32 ± 1.18 | 90.15 ± 0.86 | 3.48 ± 0.29 |
| 1,5,9,11 | 82.39 ± 1.13 | 91.32 ± 1.21 | 3.82 ± 0.22 |
| 1,7,9,11 | 83.09 ± 0.89 | 91.62 ± 1.39 | 3.61 ± 0.63 |
| 3,5,7,9 | 83.46 ± 1.26 | 92.35 ± 1.19 | 3.64 ± 0.18 |
| 3,5,7,11 | 83.44 ± 1.16 | 92.32 ± 1.26 | 3.64 ± 0.16 |
| 3,5,9,11 | 83.45 ± 0.84 | 92.12 ± 1.12 | 3.69 ± 0.19 |
| 3,7,9,11 | 83.42 ± 1.05 | 91.96 ± 1.43 | 3.78 ± 0.25 |
| 5,7,9,11 | 82.32 ± 1.42 | 90.98 ± 0.93 | 3.75 ± 0.19 |
| Model | JI (%) ↑ | DSC (%) ↑ | 95HD (mm) ↓ |
|---|---|---|---|
| DeepLabv3+ | 78.11 ± 1.16 | 87.38 ± 0.74 | 4.06 ± 0.12 |
| UNet | 79.04 ± 1.35 | 87.94 ± 0.89 | 3.96 ± 0.11 |
| Dolz et al. [16] | 79.51 ± 1.16 | 88.38 ± 0.74 | 3.98 ± 0.14 |
| Ge et al. [17] | 80.08 ± 1.38 | 89.43 ± 0.93 | 3.81 ± 0.23 |
| Liu et al. [18] | 79.91 ± 1.09 | 89.74 ± 1.02 | 3.84 ± 0.18 |
| TransUNet | 81.02 ± 1.36 | 90.87 ± 1.01 | 3.79 ± 0.19 |
| MSEDTNet | 83.46 ± 1.26 | 92.35 ± 1.19 | 3.64 ± 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Ye, X. MSEDTNet: Multi-Scale Encoder and Decoder with Transformer for Bladder Tumor Segmentation. Electronics 2022, 11, 3347. https://doi.org/10.3390/electronics11203347
Wang Y, Ye X. MSEDTNet: Multi-Scale Encoder and Decoder with Transformer for Bladder Tumor Segmentation. Electronics. 2022; 11(20):3347. https://doi.org/10.3390/electronics11203347
Chicago/Turabian StyleWang, Yixing, and Xiufen Ye. 2022. "MSEDTNet: Multi-Scale Encoder and Decoder with Transformer for Bladder Tumor Segmentation" Electronics 11, no. 20: 3347. https://doi.org/10.3390/electronics11203347
APA StyleWang, Y., & Ye, X. (2022). MSEDTNet: Multi-Scale Encoder and Decoder with Transformer for Bladder Tumor Segmentation. Electronics, 11(20), 3347. https://doi.org/10.3390/electronics11203347