
Deep Learning for Depression Detection from Textual Data


 ,
,  and
and 
Abstract
:1. Introduction
- 1.
- We provide a detailed discussion of depression, depressive symptoms, and its types. This study concentrates on processing textual data and detecting depressive traits.
- 2.
- We extract features from a text dataset using One-Hot encoding method and Principal Component Analysis (PCA) to represent possible depression symptoms and sentiments in tweeter data.
- 3.
- We propose a deep learning model using LSTM, with 60 LSTM units with two hidden states and bias factors, and an RNN with two hidden layers for the early detection of depression by training the model with depressive and non-depressive sample data.
- 4.
- We evaluate the proposed prediction model using the Tweets-scraped depression dataset and evaluate the proposed model using the following evaluation matrices: precision, accuracy, f1-measure, and support.
- 5.
- The evaluation results show that the proposed framework improves accuracy by detecting depression from textual data.
2. Literature Review
Limitations of Existing Works
- 1.
- What are the difficulties in implementing a text-based depression detection?
- 2.
- What is the most effective text-based approach for early-stage depression detection?
- 3.
- How can we examine which factors are most efficient in detecting depression?
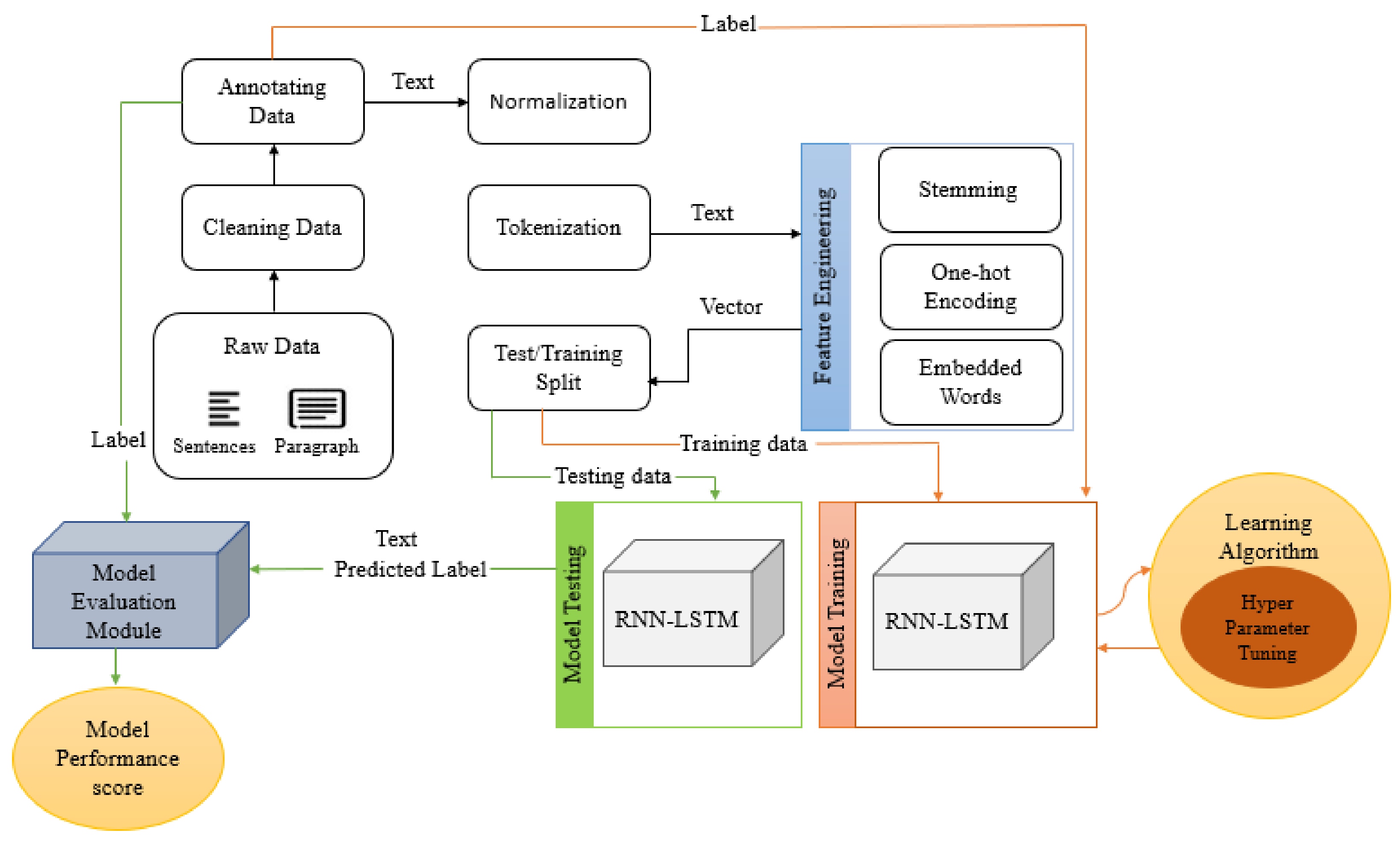
3. Proposed Methodology
3.1. Data Pre-Processing
| Algorithm 1 Feature-Extraction From Text |
|
3.2. Features Visualization Using Principal Component Analysis (PCA)
3.3. Modeling LSTM-RNN for Emotional State Analysis
| Algorithm 2 Model For Training Text |
|
| Algorithm 3 Prediction Model |
|
4. Experimental Analysis and Discussion
4.1. Dataset Description
4.2. Evaluation Metrics
5. Conclusions
Author Contributions
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, Y.; Yang, X. A hierarchical depression detection model based on vocal and emotional cues. Neurocomputing 2021, 441, 279–290. [Google Scholar] [CrossRef]
- Javed, A.R.; Fahad, L.G.; Farhan, A.A.; Abbas, S.; Srivastava, G.; Parizi, R.M.; Khan, M.S. Automated cognitive health assessment in smart homes using machine learning. Sustain. Cities Soc. 2021, 65, 102572. [Google Scholar] [CrossRef]
- Javed, A.R.; Sarwar, M.U.; ur Rehman, S.; Khan, H.U.; Al-Otaibi, Y.D.; Alnumay, W.S. PP-SPA: Privacy preserved smartphone-based personal assistant to improve routine life functioning of cognitive impaired individuals. Neural Process. Lett. 2021, 1–18. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Dysthe, K.K.; Følstad, A.; Brandtzaeg, P.B. Deep learning for prediction of depressive symptoms in a large textual dataset. Neural Comput. Appl. 2022, 34, 721–744. [Google Scholar] [CrossRef]
- Depression, W. Other Common Mental Disorders: Global Health Estimates; World Health Organization: Geneva, Switzerland, 2017; pp. 1–24. [Google Scholar]
- Aladağ, A.E.; Muderrisoglu, S.; Akbas, N.B.; Zahmacioglu, O.; Bingol, H.O. Detecting suicidal ideation on forums: Proof-of-concept study. J. Med. Internet Res. 2018, 20, e9840. [Google Scholar] [CrossRef]
- Wang, S.; Peng, G.; Zheng, Z.; Xu, Z. Capturing emotion distribution for multimedia emotion tagging. IEEE Trans. Affect. Comput. 2019, 12, 821–831. [Google Scholar] [CrossRef]
- Havigerová, J.M.; Haviger, J.; Kučera, D.; Hoffmannová, P. Text-based detection of the risk of depression. Front. Psychol. 2019, 10, 513. [Google Scholar] [CrossRef]
- Javed, A.R.; Sarwar, M.U.; Beg, M.O.; Asim, M.; Baker, T.; Tawfik, H. A collaborative healthcare framework for shared healthcare plan with ambient intelligence. Hum.-Centric Comput. Inf. Sci. 2020, 10, 1–21. [Google Scholar] [CrossRef]
- Zehra, W.; Javed, A.R.; Jalil, Z.; Khan, H.U.; Gadekallu, T.R. Cross corpus multi-lingual speech emotion recognition using ensemble learning. Complex Intell. Syst. 2021, 7, 1845–1854. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (XAI): Towards medical XAI. arXiv 2019, arXiv:1907.07374. [Google Scholar] [CrossRef]
- Javed, A.R.; Faheem, R.; Asim, M.; Baker, T.; Beg, M.O. A smartphone sensors-based personalized human activity recognition system for sustainable smart cities. Sustain. Cities Soc. 2021, 71, 102970. [Google Scholar] [CrossRef]
- Usman Sarwar, M.; Rehman Javed, A.; Kulsoom, F.; Khan, S.; Tariq, U.; Kashif Bashir, A. Parciv: Recognizing physical activities having complex interclass variations using semantic data of smartphone. Softw. Pract. Exp. 2021, 51, 532–549. [Google Scholar] [CrossRef]
- Javed, A.R.; Sarwar, M.U.; Khan, S.; Iwendi, C.; Mittal, M.; Kumar, N. Analyzing the effectiveness and contribution of each axis of tri-axial accelerometer sensor for accurate activity recognition. Sensors 2020, 20, 2216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, Y.; Chen, X.; Fu, Q.; Zhong, S. A depression recognition method for college students using deep integrated support vector algorithm. IEEE Access 2020, 8, 75616–75629. [Google Scholar] [CrossRef]
- Ghayvat, H.; Pandya, S.; Awais, M.; Dev, K. STRENUOUS: Edge-Line Computing, AI and IIoT enabled GPS Spatiotemporal data-based Meta-transmission Healthcare Ecosystem for Virus Outbreaks Discovery. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Pandya, S.; Sur, A.; Solke, N. COVIDSAVIOR: A Novel Sensor-Fusion and Deep Learning Based Framework for Virus Outbreaks. Front. Public Health 2021, 9, 797808. [Google Scholar] [CrossRef]
- Smys, S.; Raj, J.S. Analysis of Deep Learning Techniques for Early Detection of Depression on Social Media Network—A Comparative Study. J. Trends Comput. Sci. Smart Technol. (TCSST) 2021, 3, 24–39. [Google Scholar]
- Orabi, A.H.; Buddhitha, P.; Orabi, M.H.; Inkpen, D. Deep learning for depression detection of twitter users. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; pp. 88–97. [Google Scholar]
- Kim, J.; Lee, D.; Park, E. Machine Learning for Mental Health in Social Media: Bibliometric Study. J. Med. Internet Res. 2021, 23, e24870. [Google Scholar] [CrossRef]
- Wongkoblap, A.; Vadillo, M.; Curcin, V. Depression Detection of Twitter Posters using Deep Learning with Anaphora Resolution: Algorithm Development and Validation. JMIR Ment. Health. 2021. Available online: https://kclpure.kcl.ac.uk/portal/en/publications/depression-detection-of-twitter-posters-using-deep-learning-with-anaphora-resolution-algorithm-development-and-validation(1b1ef794-5c96-4890-a0a2-04bf74323540).html.
- Un Nisa, Q.; Muhammad, R. Towards transfer learning using BERT for early detection of self-harm of social media users. In Proceedings of the Working Notes of CLEF 2021—Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Chiong, R.; Budhi, G.S.; Dhakal, S. Combining sentiment lexicons and content-based features for depression detection. IEEE Intell. Syst 2021, 36, 99–105. [Google Scholar] [CrossRef]
- Fujita, H.; Selamat, A.; Lin, J.C.W.; Ali, M. Advances and Trends in Artificial Intelligence: From Theory to Practice: 34th International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2021, Kuala Lumpur, Malaysia, 26–29 July 2021: Proceedings; Springer Nature: Berlin/Heidelberg, Germany, 2021; Volume 12799. [Google Scholar]
- Ibitoye, A.O.; Famutimi, R.F.; Olanloye, D.O.; Akioyamen, E. User Centric Social Opinion and Clinical Behavioural Model for Depression Detection. Int. J. Intell. Inf. Syst. 2021, 10, 69. [Google Scholar]
- Trifan, A.; Antunes, R.; Matos, S.; Oliveira, J.L. Understanding depression from psycholinguistic patterns in social media texts. Adv. Inf. Retr. 2020, 12036, 402–409. [Google Scholar]
- Mathur, P.; Sawhney, R.; Chopra, S.; Leekha, M.; Shah, R.R. Utilizing temporal psycholinguistic cues for suicidal intent estimation. Adv. Inf. Retr. 2020, 12036, 265–271. [Google Scholar]
- Aldarwish, M.M.; Ahmad, H.F. Predicting depression levels using social media posts. In Proceedings of the 2017 IEEE 13th International Symposium on Autonomous Decentralized System (ISADS), Bangkok, Thailand, 22–24 March 2017; pp. 277–280. [Google Scholar]
- Shen, G.; Jia, J.; Nie, L.; Feng, F.; Zhang, C.; Hu, T.; Chua, T.S.; Zhu, W. Depression Detection via Harvesting Social Media: A Multimodal Dictionary Learning Solution. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3838–3844. [Google Scholar]
- Islam, M.R.; Kabir, M.A.; Ahmed, A.; Kamal, A.R.M.; Wang, H.; Ulhaq, A. Depression detection from social network data using machine learning techniques. Health Inf. Sci. Syst. 2018, 6, 8. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.L.; Kavuri, S.; Lee, M. A fuzzy convolutional neural network for text sentiment analysis. J. Intell. Fuzzy Syst. 2018, 35, 6025–6034. [Google Scholar] [CrossRef]
- Gaikar, M.; Chavan, J.; Indore, K.; Shedge, R. Depression Detection and Prevention System by Analysing Tweets. In Proceedings of the 2019: Conference on Technologies for Future Cities (CTFC), Panvel, India, 8–9 January 2019. [Google Scholar]
- Burdisso, S.G.; Errecalde, M.; Montes-y Gómez, M. A text classification framework for simple and effective early depression detection over social media streams. Expert Syst. Appl. 2019, 133, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Farima, I.; Ud Din Abbasi, B.; Khan, S.; Al-Saeed, M.; Farroq Ahmad, H.; Mumtaz, R. Prediction of postpartum depression using machine learning techniques from social media text. Expert Syst. 2019, 36, e12409. [Google Scholar]
- AlSagri, H.S.; Ykhlef, M. Machine learning-based approach for depression detection in twitter using content and activity features. IEICE Trans. Inf. Syst. 2020, 103, 1825–1832. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.; Park, E.; Han, J. A deep learning model for detecting mental illness from user content on social media. Sci. Rep. 2020, 10, 11846. [Google Scholar] [CrossRef]
- De Souza Filho, E.M.; Rey, H.C.V.; Frajtag, R.M.; Cook, D.M.A.; de Carvalho, L.N.D.; Ribeiro, A.L.P.; Amaral, J. Can machine learning be useful as a screening tool for depression in primary care? J. Psychiatr. Res. 2021, 132, 1–6. [Google Scholar] [CrossRef]
- Cho, H.K. Twitter Depression Data Set Tweets Scraped from Twitter, Depressed and Non-Depressed. 2021. Available online: https://www.kaggle.com/hyunkic/twitter-depression-dataset (accessed on 15 January 2022).
- Xiao, L.; Xue, Y.; Wang, H.; Hu, X.; Gu, D.; Zhu, Y. Exploring fine-grained syntactic information for aspect-based sentiment classification with dual graph neural networks. Neurocomputing 2022, 471, 48–59. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Method | Findings | Limitations |
|---|---|---|---|---|
| Aldarwish [28] | 2017 | SVM, NB | NB gives high accuracy | Data-set is in Arabic |
| Shen G. [29] | 2017 | MDL, MSNL, NB, WDL | MDL accuracy is high | Focused on user confession |
| Islam M.R. [30] | 2018 | DT, SVM, K-Nearest | DT gives best results | Data focus on comments |
| Nguyen T.L. [31] | 2018 | DT, SVM, Ensemble | DT gives high accuracy | Data focus on comments |
| Gaikar M. [32] | 2019 | NB, SVM Hybrid model | 85% Accuracy | Time Consuming |
| Burdisso S.G. [33] | 2019 | SS3, NB, SVM, KNN | SS3 is best | Time Consuming |
| Farima [34] | 2019 | MLP, SVM, NB | MLP is Best | Limited Data-set |
| Alsagri [35] | 2020 | SVM, DT, NB | SVM gives high accuracy | Cannot avoid over-fit data |
| Kim J. [36] | 2020 | CNN, XGBoost | CNN accuracy is high | Limited Scope |
| Filho De Souza [37] | 2021 | DT, SVM, RF, GB, LR | RF provides high accuracy | Focus on user confession |
| Depressed | Non-Depressed |
|---|---|
| End my life | I’m Happy |
| Suicidal thoughts | Having fun |
| Always tired | Enjoying movie |
| Feeling Sad | joyful |
| have no appetite | In happy mood |
| Crying | Enjoying life |
| Why I’m always negligible | Playing |
| Unmotivated | Inspired |
| Nothing interests me | Feeling motivated |
| Predicted Output | State | ||
|---|---|---|---|
| Depressed | Non-Depressed | Mean | |
| Precision | 0.99 | 0.97 | 0.98 |
| Recall | 0.98 | 1.00 | 0.99 |
| F1-measure | 0.99 | 0.97 | 0.98 |
| Support | 998 | 190 | 1181 |
| Approaches | Mean Accuracy (%) |
|---|---|
| SVM | 97.21 |
| Naive bayes | 97.31 |
| One-hot + SVM | 83 |
| TF-IDf + SVM | 85 |
| One-hot + Decision Trees | 82 |
| TF-IDF + CNN | 91 |
| one-hot + DBN | 89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amanat, A.; Rizwan, M.; Javed, A.R.; Abdelhaq, M.; Alsaqour, R.; Pandya, S.; Uddin, M. Deep Learning for Depression Detection from Textual Data. Electronics 2022, 11, 676. https://doi.org/10.3390/electronics11050676
Amanat A, Rizwan M, Javed AR, Abdelhaq M, Alsaqour R, Pandya S, Uddin M. Deep Learning for Depression Detection from Textual Data. Electronics. 2022; 11(5):676. https://doi.org/10.3390/electronics11050676
Chicago/Turabian StyleAmanat, Amna, Muhammad Rizwan, Abdul Rehman Javed, Maha Abdelhaq, Raed Alsaqour, Sharnil Pandya, and Mueen Uddin. 2022. "Deep Learning for Depression Detection from Textual Data" Electronics 11, no. 5: 676. https://doi.org/10.3390/electronics11050676
APA StyleAmanat, A., Rizwan, M., Javed, A. R., Abdelhaq, M., Alsaqour, R., Pandya, S., & Uddin, M. (2022). Deep Learning for Depression Detection from Textual Data. Electronics, 11(5), 676. https://doi.org/10.3390/electronics11050676