
Deep Learning Recommendations of E-Education Based on Clustering and Sequence

 ,
,  , and
, and
Abstract
:1. Introduction
- ➢
- Initialize learners as a homologous category via clustering;
- ➢
- Combine synchronous sequences and heterogeneous data;
- ➢
- Make time-aware course recommendations based on the sequence of learners’ history;
- ➢
- Overcome the learners’ cold-start problem by concatenating additional features;
- ➢
- Improve overall candidate generation performance when utilizing a large dataset.
2. Literature Review
2.1. Sequence-Oriented Recommendation Methods
2.2. Clustering-Based DL Recommendations
3. Proposed Approach
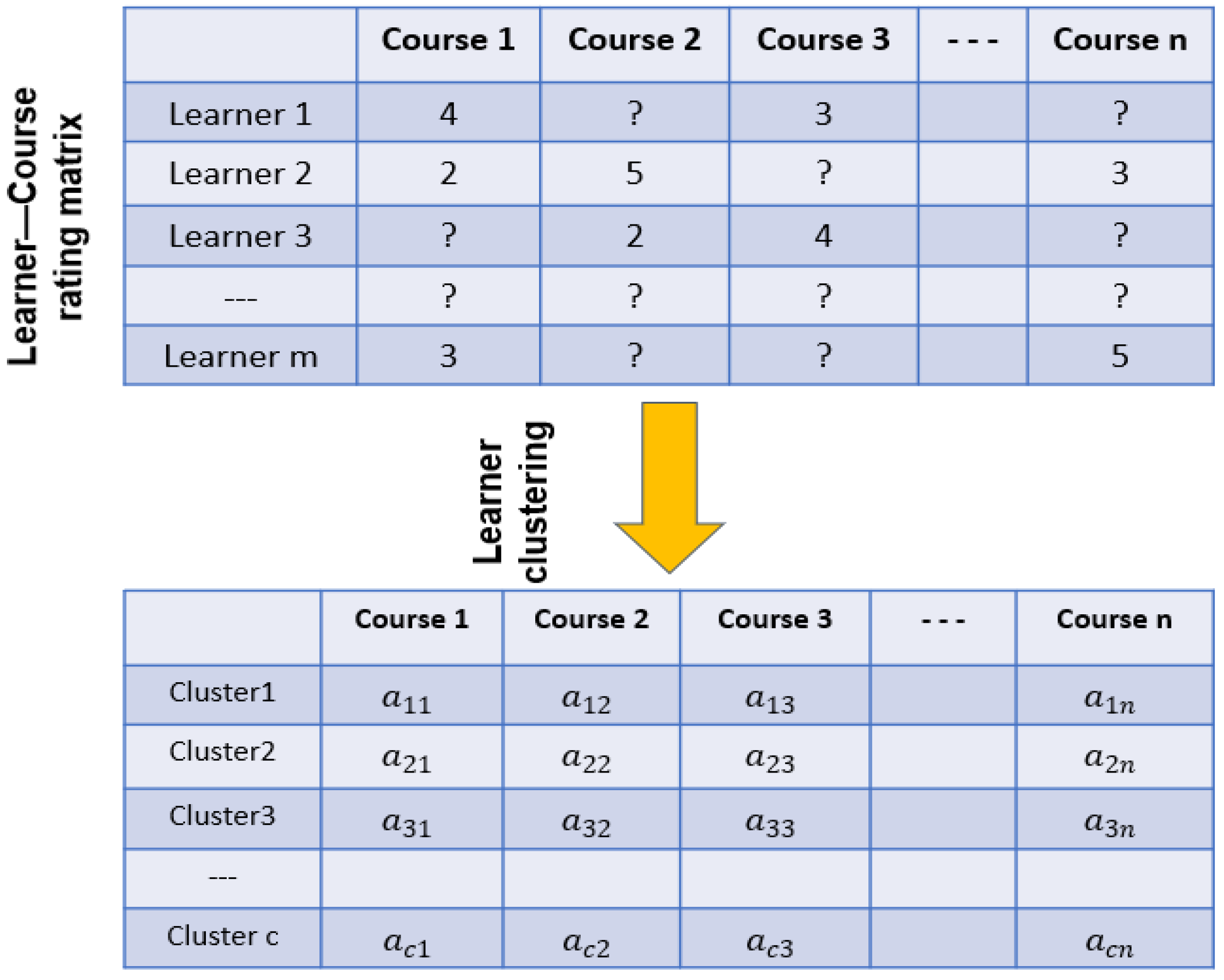
3.1. Initializing Learners via K-Means
| Algorithm 1: Learners’ clustering algorithm |
| Input:learner–course interactions data, k-number of clusters |
| Output:dense learner clusters |
| Begin: |
| Define learner set l; |
| Define course set c; |
| Choose primary r rating learners acting as the clustering ; |
| The clustering kernel is null as c ; |
| do |
| for each learner |
| for each cluster kernel c |
| calculate similarity sim(, c); |
| end for |
| sim(, c) = ; |
| end for |
| for each cluster |
| for each learner |
| c; |
| end for |
| end for |
| while (c is not change) |
| Finish |
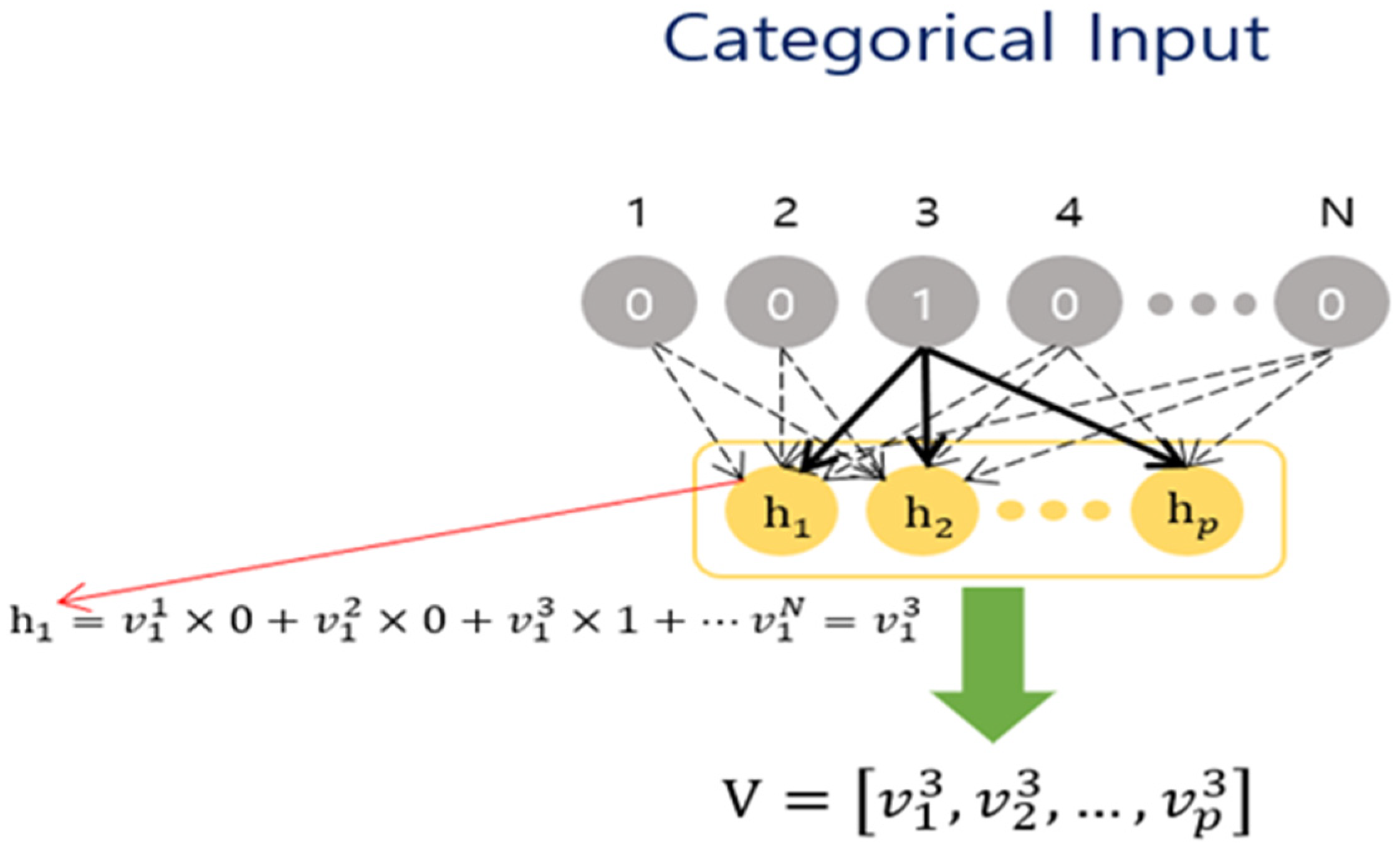
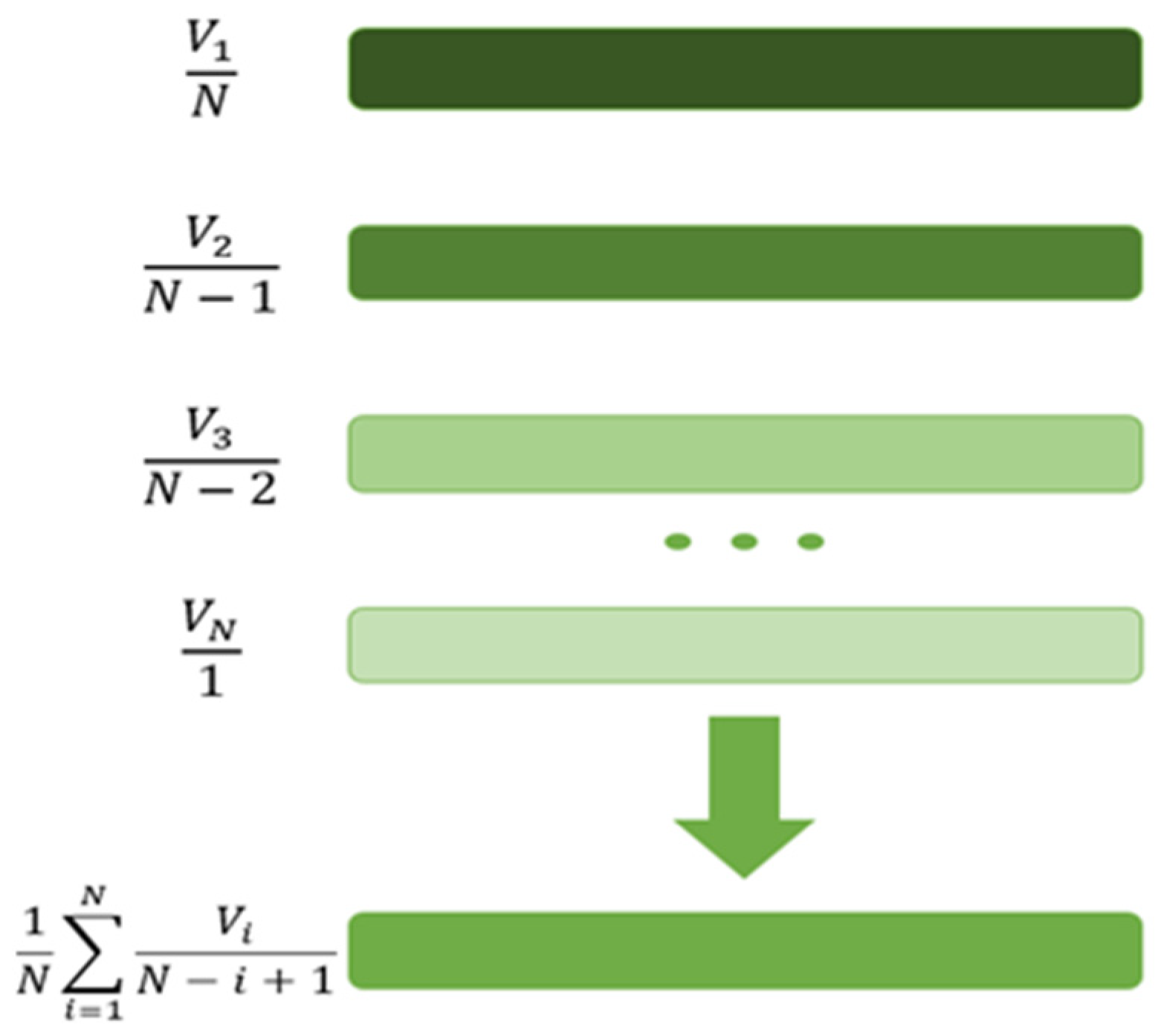
3.2. Sequence-Oriented Embedding
- ▪ uk: {management, economy}
- ▪ ul: {economy, management}
3.3. Content Data
- Female: [1, 0, 1]
- Male: [0, 1, 0]
- Missing data: [0, 0, 1]
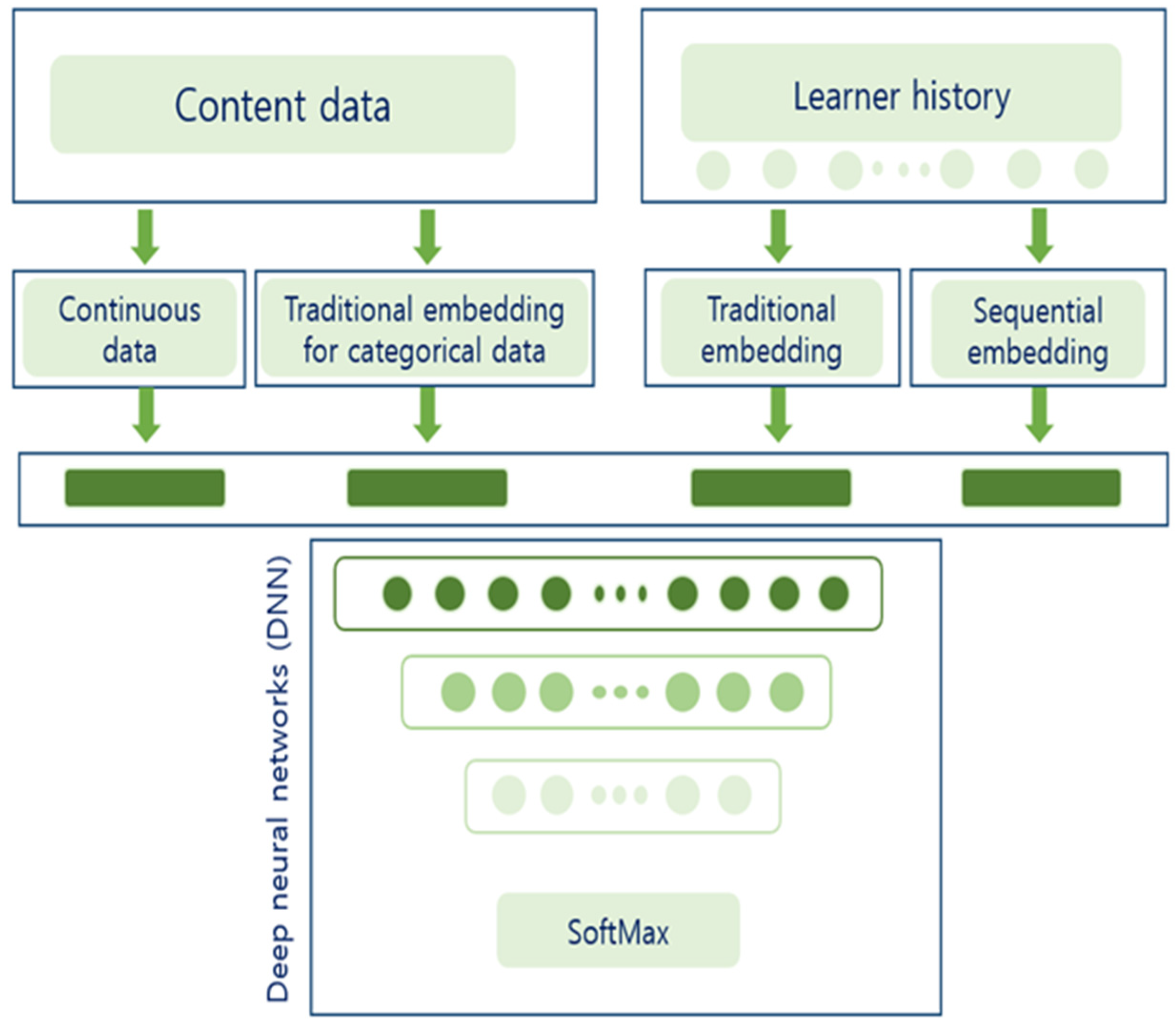
3.4. Deep Neural Network
4. Experimental Results
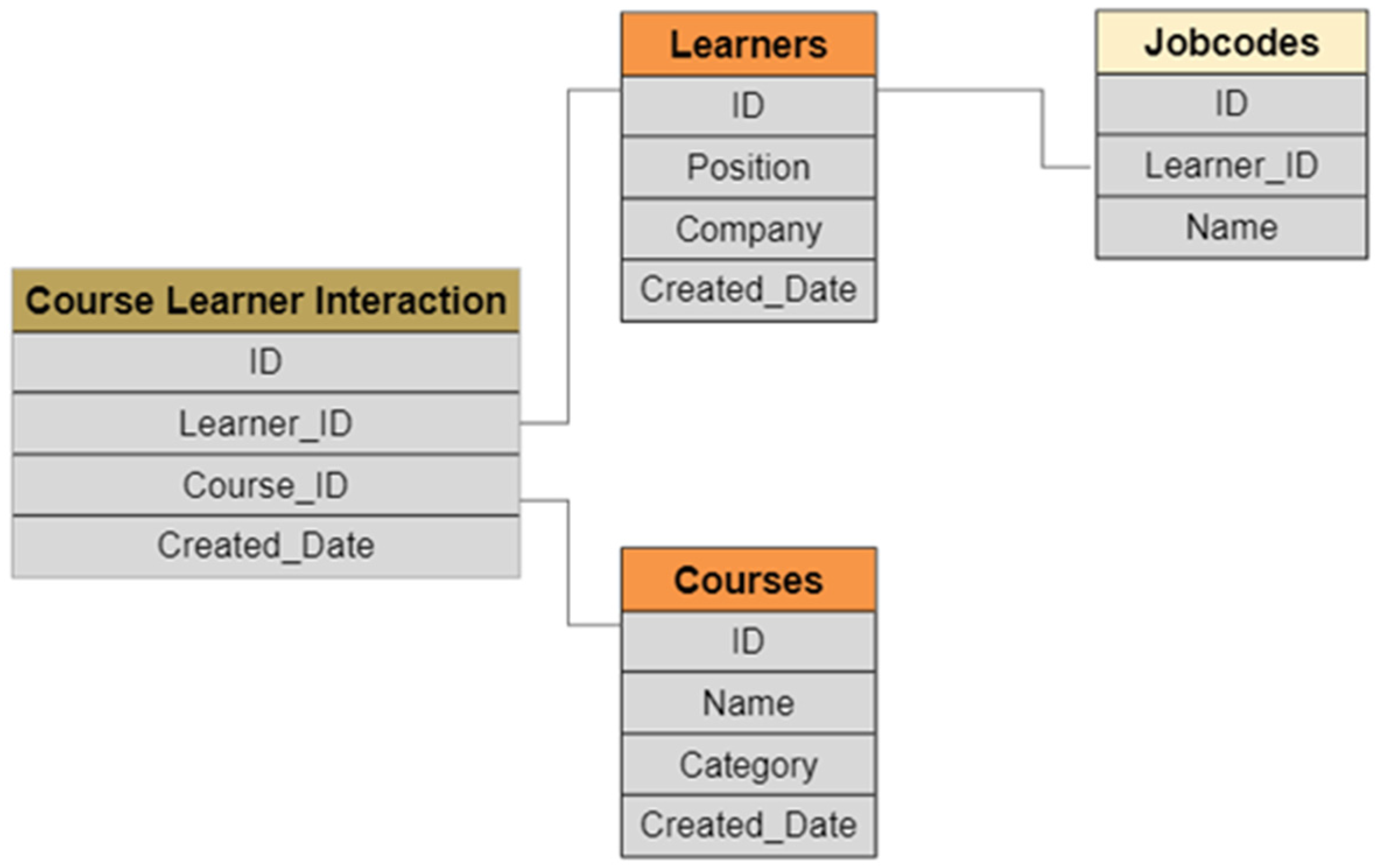
4.1. Dataset
4.2. Implementation Settings
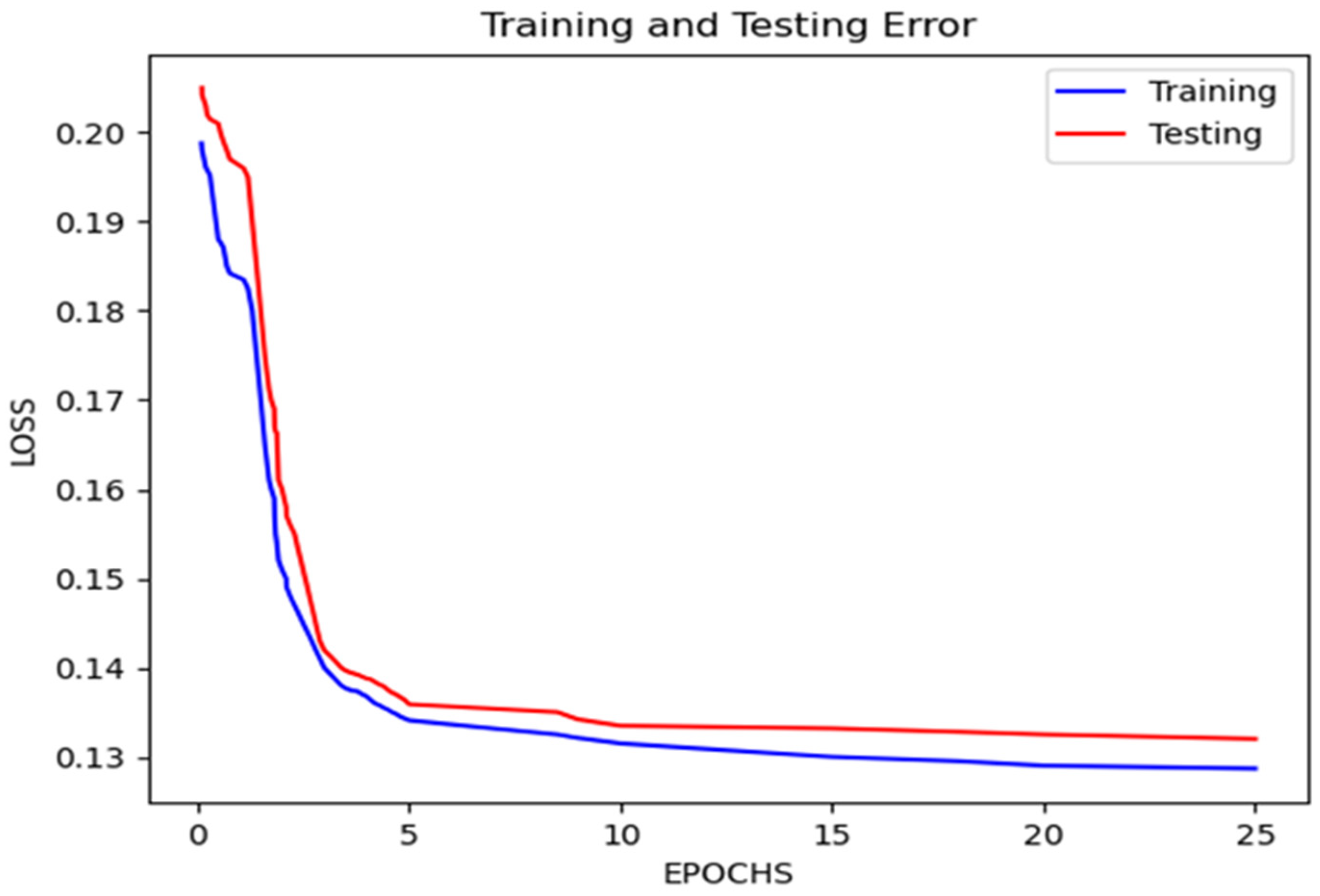
4.3. Model’s Results
4.3.1. Top-N Predication Performance
- AutoRec [26]: To deliver individualized suggestions, a method based on the autoencoder approach attempts to use customer preference data for various products.
- YouTube model [16]: The authors utilized categorical features and continuous data to make recommendations, whereas the sequence of customer history was disregarded.
- LightGCN [35]: This model learns customer and product embeddings by linearly distributing them on a customer-product interaction graph. The weighted sum of the embeddings was then utilized as the last embedding layer.
- FISM [36]: The authors offer a technique that creates two low-latent factorized matrices by learning the product–product matrices to represent and retain the relationships between products.
- E-LCRS [37]: This recommendation model was built based on the history and preferences using a collaborative filtering mechanism.
- Cluster-IHRS [38]: The recommender evaluates and learns the styles and features of the learners automatically. Split and conquer strategy-based clustering is used to process the various learning styles. The algorithm then makes intelligent suggestions based on the ratings of frequently occurring sequences.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision@1 | Precision@5 | Precision@10 |
|---|---|---|---|
| AutoRec [26] | 0.309 | 0.213 | 0.175 |
| YouTube model [16] | 0.599 | 0.461 | 0.294 |
| FISM [36] | 0.553 | 0.3238 | 0.2358 |
| LightGCN [35] | 0.589 | 0.4702 | 0.3768 |
| E-LCRS [37] | 0.611 | 0.453 | 0.209 |
| Cluster-IHRS | 0.46 | 0.352 | 0.216 |
| SODNN (proposed) | 0.626 | 0.498 | 0.385 |
4.3.2. Cold-Start Case
5. Conclusions and Future Work
- Address the need to offer the simplest possible dynamic candidate generation;
- Address the “gray sheep” problem, in which a learner cannot be associated with any homologous cluster and the online platform is incapable of suggesting relevant courses.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Koren, Y.; Bell, R.; Volinskiy, C. Matrix factorization techniques for recommender systems. IEEE Comput. 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Kutlimuratov, A.; Abdusalomov, A.; Whangbo, T.K. Evolving Hierarchical and Tag Information via the Deeply Enhanced Weighted Non-Negative Matrix Factorization of Rating Predictions. Symmetry 2020, 12, 1930. [Google Scholar] [CrossRef]
- Wang, J.; de Vries, A.P.; Reinders, M.J.T. Unifying Learner-based and Item-based Collaborative Filtering Approaches by Similarity Fusion. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 501–508. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2020, 52, 5. [Google Scholar] [CrossRef]
- Okura, S.; Tagami, Y.; Ono, S.; Tajima, A. Embedding-Based News Recommendation for Millions of Learners. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Ilyosov, A.; Kutlimuratov, A.; Whangbo, T.-K. Deep-Sequence–Aware Candidate Generation for e-Learning System. Processes 2021, 9, 1454. [Google Scholar] [CrossRef]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized denoising autoencoders for domain adaptation. arXiv 2012, arXiv:1206.468. [Google Scholar] [CrossRef]
- Zheng, L.; Lu, C.-T.; He, L.; Xie, S.; He, H.; Li, C.; Noroozi, V.; Dong, B.; Yu, P.S. MARS: Memory Attention-Aware Recommender System. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 11–20. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.-Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Lee, H.; Ahn, Y.; Lee, H.; Ha, S.; Lee, S.G. Quote Recommendation in Dialogue using Deep Neural Network. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 957–960. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar] [CrossRef]
- Ruining, H.; Julian, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI-16 Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Deshpande, M.; Karypis, G. Item-based top-N recommendation algorithms. ACM Trans. Inf. Syst. 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for Youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Agrawal, R.; Srikant, R. Mining sequential patterns. In Proceedings of the 11th International Conference on Data Engineering (ICDE), Taipei, Taiwan, 6–10 March 1995; pp. 3–14. [Google Scholar]
- Lam, X.N.; Vu, T.; Le, T.D.; Duong, A.D. Addressing cold-start problem in recommendation systems. In Proceedings of the 2nd International Conference on Ubiquitous Information Management and Communication, Suwon, Republic of Korea, 31 January–1 February 2008; ACM: New York, NY, USA, 2008; pp. 208–211. [Google Scholar]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Yu, H.; Riedl, M.O. A sequential recommendation approach for interactive personalized story generation. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012. [Google Scholar]
- Mobasher, B.; Dai, H.; Luo, T.; Nakagawa, M. Using sequential and non-sequential patterns in predictive Web usage mining tasks. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi, Japan, 9–12 December 2002; pp. 669–672. [Google Scholar]
- Zhao, G.; Lee, M.L.; Hsu, W.; Chen, W. Increasing temporal diversity with purchase intervals. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012. [Google Scholar]
- Bao, Y.; Fang, H.; Zhang, J. TopicMF: Simultaneously Exploiting Ratings and Reviews for Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Qiao, Z.; Zhang, P.; Cao, Y.; Zhou, C.; Guo, L.; Fang, B. Combining Heterogenous Social and Geographical Information for Event Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 165–174. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. AutoRec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar] [CrossRef]
- Rostami, M.; Oussalah, M.; Farrahi, V. A Novel Time-Aware Food Recommender-System Based on Deep Learning and Graph Clustering. IEEE Access 2022, 10, 52508–52524. [Google Scholar] [CrossRef]
- Kutlimuratov, A.; Abdusalomov, A.B.; Oteniyazov, R.; Mirzakhalilov, S.; Whangbo, T.K. Modeling and Applying Implicit Dormant Features for Recommendation via Clustering and Deep Factorization. Sensors 2022, 22, 8224. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Guo, L.; Xu, L.; Gao, B.; Liu, F.; Li, W. Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library. Information 2021, 12, 198. [Google Scholar] [CrossRef]
- Boppana, V.; Prasad, S. Web crawling based context aware recommender system using optimized deep recurrent neural network. J. Big Data 2021, 8, 144. [Google Scholar] [CrossRef]
- Jiang, M.; Zhang, Z.; Jiang, J.; Wang, Q.; Pei, Z. A collaborative filtering recommendation algorithm based on information theory and bi-clustering. Neural Comput. Appl. 2019, 31, 8279–8287. [Google Scholar] [CrossRef]
- Binbusayyis, A. Deep embedded fuzzy clustering model for collaborative filtering recommender system. Intell. Autom. Soft Comput. 2022, 33, 501–513. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. arXiv 2020, arXiv:2002.02126. [Google Scholar]
- Kabbur, S.; Ning, X.; Karypis, G. Fism: Factored item similarity models for top-n recommender systems. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 659–667. [Google Scholar]
- Jena, K.K.; Bhoi, S.K.; Malik, T.K.; Sahoo, K.S.; Jhanjhi, N.Z.; Bhatia, S.; Amsaad, F. E-Learning Course Recommender System Using Collaborative Filtering Models. Electronics 2023, 12, 157. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and Analysis of a Cluster-Based Intelligent Hybrid Recommendation System for E-Learning Applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Peng, X.; Li, Y.; Tsang, I.W.; Zhu, H.; Lv, J.; Zhou, J.T. XAI Beyond Classification: Interpretable Neural Clustering. arXiv 2018, arXiv:1808.07292. [Google Scholar] [CrossRef]
- Ji, P.; Zhang, T.; Li, H.; Salzmann, M.; Reid, I. Deep subspace clustering networks. In Proceedings of the 29th Advances in Neural Information Processing Systems, Montreal, QC, Canada, 4–9 December 2017. [Google Scholar]
- Makhmudov, F.; Kutlimuratov, A.; Akhmedov, F.; Abdallah, M.S.; Cho, Y.-I. Modeling Speech Emotion Recognition via Attention-Oriented Parallel CNN Encoders. Electronics 2022, 11, 4047. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Mukhiddinov, M.; Kutlimuratov, A.; Whangbo, T.K. Improved Real-Time Fire Warning System Based on Advanced Technologies for Visually Impaired People. Sensors 2022, 22, 7305. [Google Scholar] [CrossRef] [PubMed]






| Learner History Sequence | Following Course |
|---|---|
| L1 = [C1, C2, C3] | C4 |
| L2 = [C1, C2] | C3 |
| L3 = [C1] | C2 |
| Software | Programming tools | Python, Pandas, Keras-TensorFlow, |
| OS | Windows 10 | |
| Hardware | CPU | AMD Ryzen Threadripper 1900X 8-Core Processor 3.80 GHz |
| GPU | Titan Xp 16 GB | |
| RAM | 128 GB | |
| Parameters | Epochs | 20 |
| Learning rate | 0.001 | |
| Optimal Clusters | 8 |
| Courses | Similarity |
|---|---|
| Real Estate Disclosure Act | 0.801 |
| Real Estate Finance | 0.775 |
| Real Estate Investing | 0.698 |
| Real Estate Course Introduction | 0.623 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safarov, F.; Kutlimuratov, A.; Abdusalomov, A.B.; Nasimov, R.; Cho, Y.-I. Deep Learning Recommendations of E-Education Based on Clustering and Sequence. Electronics 2023, 12, 809. https://doi.org/10.3390/electronics12040809
Safarov F, Kutlimuratov A, Abdusalomov AB, Nasimov R, Cho Y-I. Deep Learning Recommendations of E-Education Based on Clustering and Sequence. Electronics. 2023; 12(4):809. https://doi.org/10.3390/electronics12040809
Chicago/Turabian StyleSafarov, Furkat, Alpamis Kutlimuratov, Akmalbek Bobomirzaevich Abdusalomov, Rashid Nasimov, and Young-Im Cho. 2023. "Deep Learning Recommendations of E-Education Based on Clustering and Sequence" Electronics 12, no. 4: 809. https://doi.org/10.3390/electronics12040809
APA StyleSafarov, F., Kutlimuratov, A., Abdusalomov, A. B., Nasimov, R., & Cho, Y.-I. (2023). Deep Learning Recommendations of E-Education Based on Clustering and Sequence. Electronics, 12(4), 809. https://doi.org/10.3390/electronics12040809