
ML-Based Software Defect Prediction in Embedded Software for Telecommunication Systems (Focusing on the Case of SAMSUNG ELECTRONICS)


Abstract
:1. Introduction
2. Related Work
2.1. Software Defect Prediction Applied in Open-Source Projects
2.2. Software Defect Prediction Applied in Real Industrial Domains
3. Materials and Methods
3.1. Research Questions
3.2. Dataset
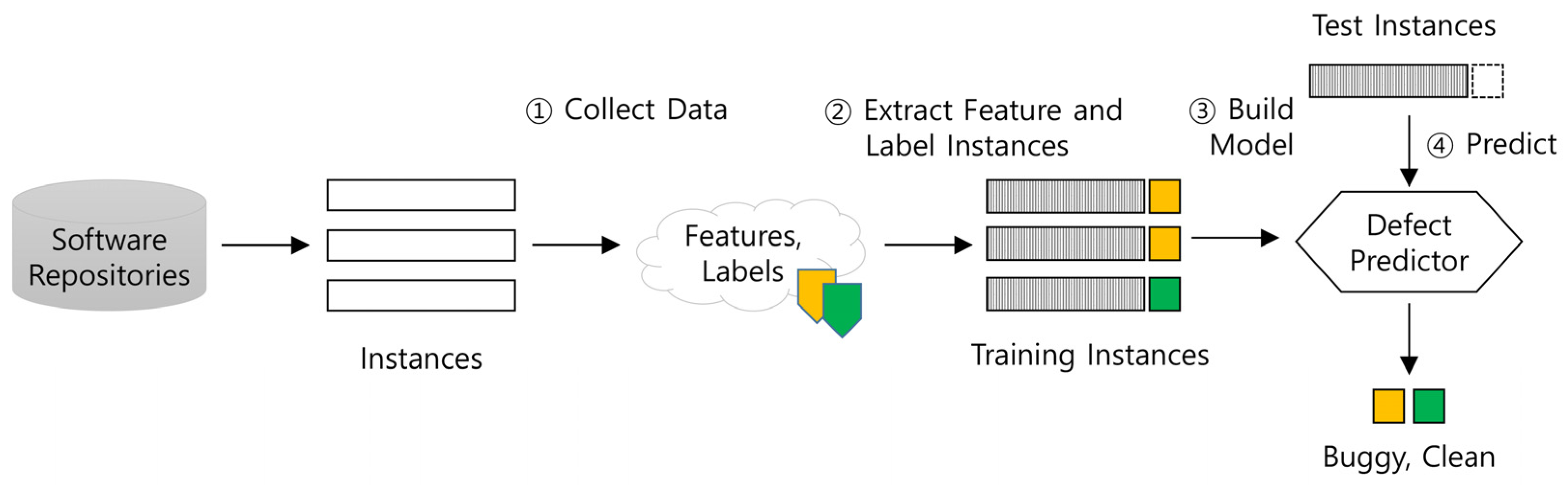
3.3. Research Design
3.4. Software Metrics
- The GV (global variable) represents a count of the global variables in each file that reference variables in other files. Global variables increase the dependencies between modules, deteriorating maintainability and making it difficult to predict when and by which module a value is changed, thereby complicating debugging. Therefore, it is generally recommended to use global variables at a moderate level to minimize the risk of such issues. However, in embedded software, there is a tendency toward the increased usage of global variables due to constraints in speed and memory.
- MCD (module circular dependency) indicates the number of loops formed when connecting files with dependencies. Having loops deteriorates the maintainability of the code, so it is recommended to avoid creating loops. In the case of large-scale software development, such as communication system software, where multiple developers work on the code for extended periods, such dependencies can unintentionally arise.
- DC (duplicate code) represents the size of the repetitive code. When there is a lot of duplicate code, there is a higher risk of missing modifications to some of the code during the maintenance process, which can be problematic. Therefore, removing duplicate code is recommended. Embedded software for communication systems tends to have a large overall codebase, where the code continuously expands to support new hardware developments. At the same time, development schedules may not allow sufficient time for the timely market release of new versions, and there is less likelihood of the same developer consistently handling the same code. In such environments, developers may not have enough time to analyze the existing code thoroughly, leading them to copy the existing code when developing code for new hardware models, resulting in duplicates.
- PPLOC (Preprocessor LOC) is the size of the code within preprocessor directives such as #ifdef… and #if… These codes are assessed for compilation inclusion based on the satisfaction of conditions written alongside preprocessor directives during the compilation time. In embedded software for communication systems, due to the memory constraints of hardware devices like DSPs (digital signal processors), the only codes running on each piece of hardware are included in the execution image to minimize code size. For this purpose, preprocessor directives are employed. However, similar to DC, this practice leads to the generation of repetitive, similar codes, increasing the risk of omitting modifications to some codes during code editing.
- cov_l and cov_b, respectively, represent line coverage and branch coverage, indicating the proportion of tested code out of the total code. A lower proportion of tested code in developer testing increases the likelihood of defects being discovered during system testing.
- Critical/Major denotes the number of defects detected by static analysis tools. If these defects are not addressed by the developer in the testing phase, the likelihood of defects being discovered during system testing increases.
- FileType serves as an identifier for distinguishing between C code and C++ code. It is a feature aimed at incorporating the differences between C and C++ code into machine learning training.
- Group_SSYS serves as information to identify subsystems. Subsystems are subunits that constitute the entire software structure. This feature enables the machine learning model to reflect the differences between subsystems in its training.
- Group_BLK serves as information to identify blocks. Blocks are subunits that constitute subsystems in the software structure. This feature enables the machine learning model to reflect the differences between blocks in its training.
3.5. Defect Labeling
3.6. Mitigating Class Imbalance
3.7. Machine Learning Models
3.8. Model Performance Assessment
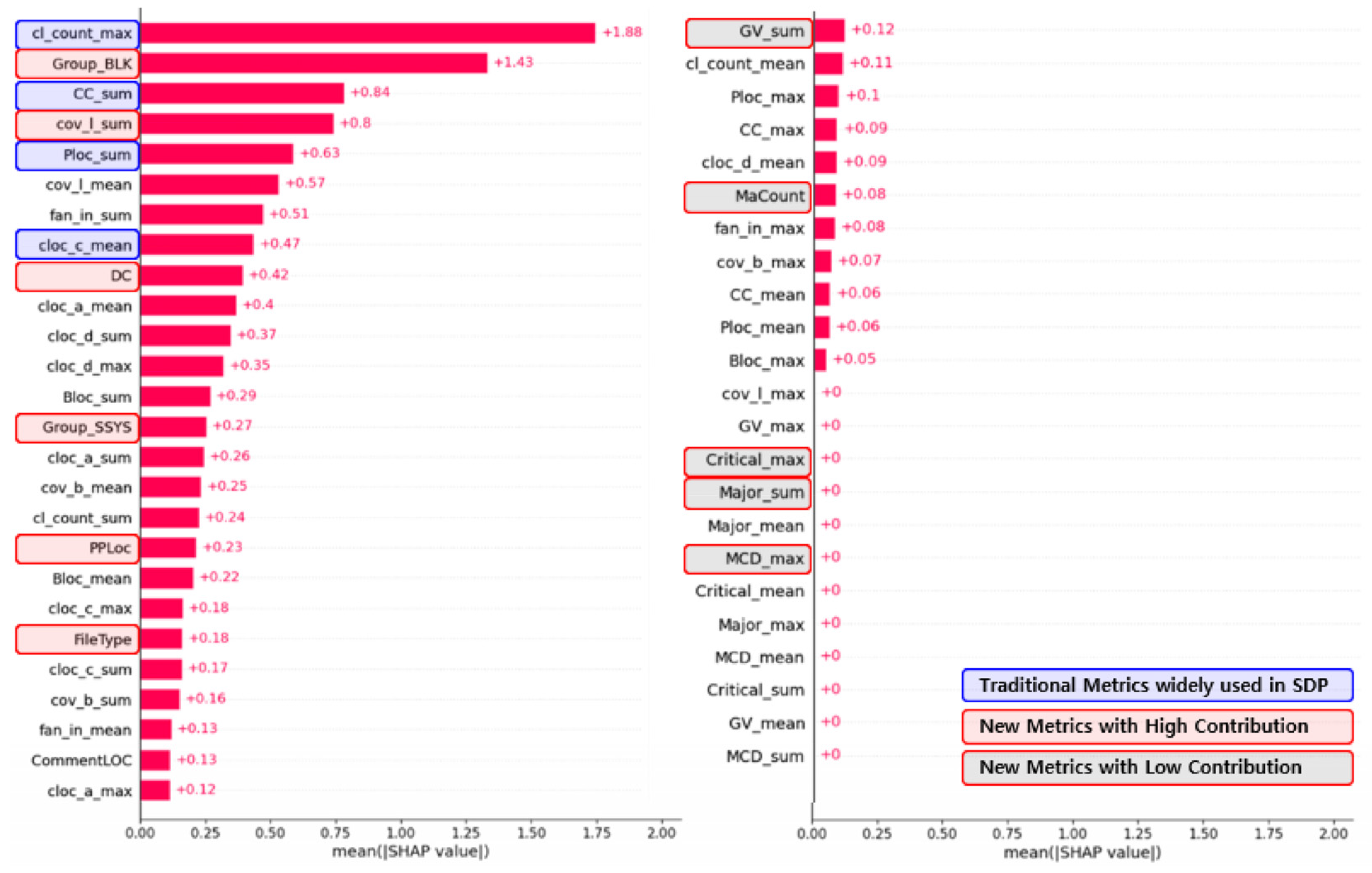
3.9. Feature Importance Analysis
3.10. Cross-Version Performance Measurement
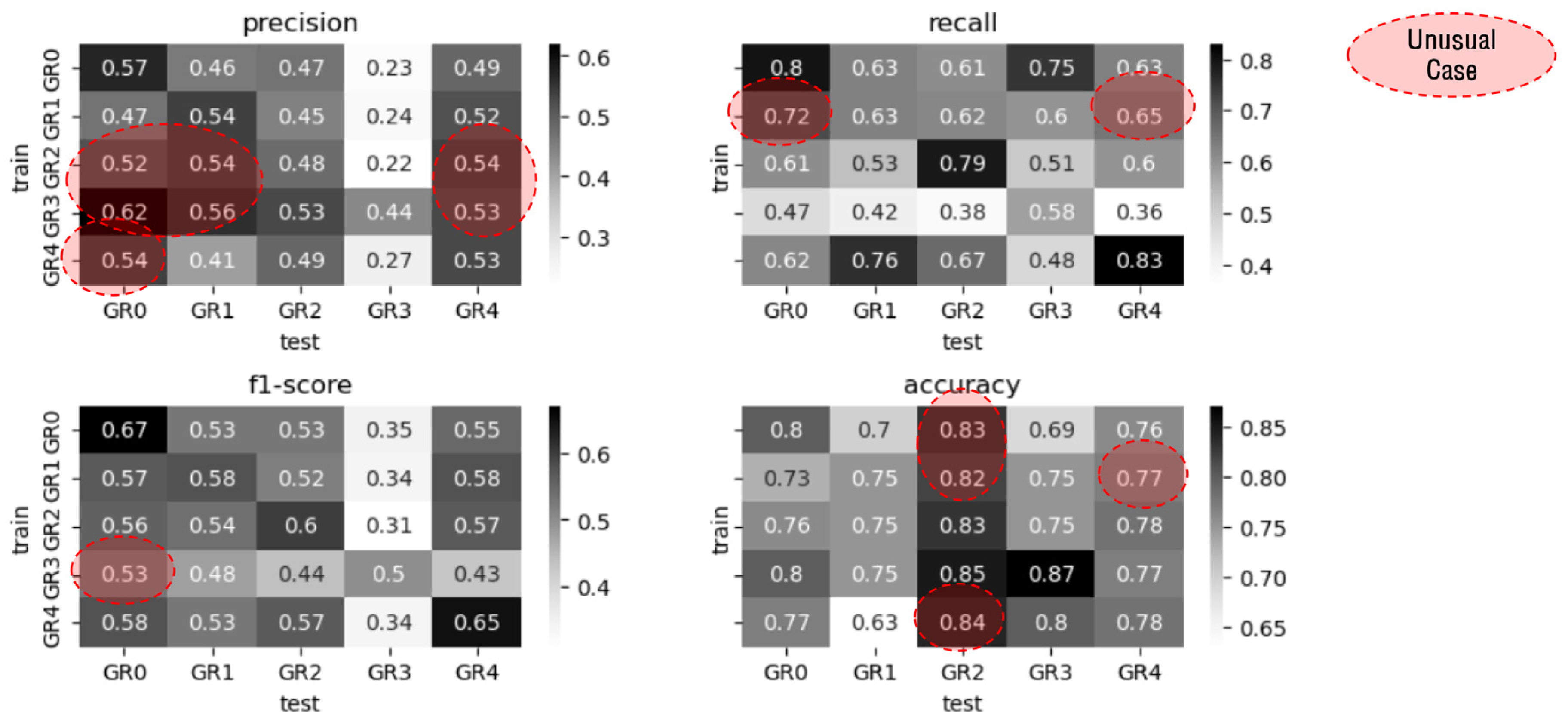
3.11. Cross-Group Performance Measurement
4. Results
5. Discussion and Conclusions
- This case study into embedded software for communication purposes provides empirical validation research results.
- Specialized features, such as PPLOC and DC, could serve as valuable indicators for software defect prediction and quality management in software that shares similar traits. These metrics hold a potential for application in analogous domains.
- If the proposed research methodology is concretized and tailored guidelines are established, this provides opportunities for the propagation of extension into domains with different characteristics.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Antinyan, V. Revealing the Complexity of Automotive Software. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event USA, 8 November 2020; pp. 1525–1528. [Google Scholar]
- Stradowski, S.; Madeyski, L. Exploring the Challenges in Software Testing of the 5G System at Nokia: A Survey. Inf. Softw. Technol. 2023, 153, 107067. [Google Scholar] [CrossRef]
- Wahono, R.S. A Systematic Literature Review of Software Defect Prediction: Research Trends, Datasets, Methods and Frameworks. J. Softw. Eng. 2015, 1, 1–16. [Google Scholar]
- IEEE Std 610.12-1990; IEEE Standard Glossary of Software Engineering Terminology. IEEE: Manhattan, NY, USA, 1990; pp. 1–84. [CrossRef]
- Shafiq, M.; Alghamedy, F.H.; Jamal, N.; Kamal, T.; Daradkeh, Y.I.; Shabaz, M. Scientific Programming Using Optimized Machine Learning Techniques for Software Fault Prediction to Improve Software Quality. IET Softw. 2023, 17, 694–704. [Google Scholar] [CrossRef]
- Iqbal, A.; Aftab, S.; Ali, U.; Nawaz, Z.; Sana, L.; Ahmad, M.; Husen, A. Performance Analysis of Machine Learning Techniques on Software Defect Prediction Using NASA Datasets. Int. J. Adv. Sci. Comput. Appl. 2019, 10, 300–308. [Google Scholar] [CrossRef]
- Paramshetti, P.; Phalke, D.A. Survey on Software Defect Prediction Using Machine Learning Techniques. Int. J. Sci. Res. 2012, 3, 1394–1397. [Google Scholar]
- Thota, M.K.; Shajin, F.H.; Rajesh, P. Survey on Software Defect Prediction Techniques. Int. J. Appl. Sci. Eng. 2020, 17, 331–344. [Google Scholar] [CrossRef] [PubMed]
- Durelli, V.H.S.; Durelli, R.S.; Borges, S.S.; Endo, A.T.; Eler, M.M.; Dias, D.R.C.; Guimarães, M.P. Machine Learning Applied to Software Testing: A Systematic Mapping Study. IEEE Trans. Reliab. 2019, 68, 1189–1212. [Google Scholar] [CrossRef]
- Stradowski, S.; Madeyski, L. Machine Learning in Software Defect Prediction: A Business-Driven Systematic Mapping Study. Inf. Softw. Technol. 2023, 155, 107128. [Google Scholar] [CrossRef]
- Stradowski, S.; Madeyski, L. Industrial Applications of Software Defect Prediction Using Machine Learning: A Business-Driven Systematic Literature Review. Inf. Softw. Technol. 2023, 159, 107192. [Google Scholar] [CrossRef]
- Kamei, Y.; Shihab, E.; Adams, B.; Hassan, A.E.; Mockus, A.; Sinha, A.; Ubayashi, N. A Large-Scale Empirical Study of Just-in-Time Quality Assurance. IEEE Trans. Softw. Eng. 2013, 39, 757–773. [Google Scholar] [CrossRef]
- Menzies, T.; Greenwald, J.; Frank, A. Data Mining Static Code Attributes to Learn Defect Predictors. IEEE Trans. Softw. Eng. 2007, 33, 2–13. [Google Scholar] [CrossRef]
- Catal, C.; Diri, B. A Systematic Review of Software Fault Prediction Studies. Expert Syst. Appl. 2009, 36, 7346–7354. [Google Scholar] [CrossRef]
- Amasaki, S.; Takagi, Y.; Mizuno, O.; Kikuno, T. A Bayesian Belief Network for Assessing the Likelihood of Fault Content. In Proceedings of the 14th International Symposium on Software Reliability Engineering, Denver, CO, USA, 17–20 November 2003; pp. 215–226. [Google Scholar]
- Akmel, F.; Birihanu, E.; Siraj, B. A Literature Review Study of Software Defect Prediction Using Machine Learning Techniques. Int. J. Emerg. Res. Manag. Technol. 2018, 6, 300. [Google Scholar] [CrossRef]
- Khan, M.J.; Shamail, S.; Awais, M.M.; Hussain, T. Comparative Study of Various Artificial Intelligence Techniques to Predict Software Quality. In Proceedings of the 2006 IEEE International Multitopic Conference, Islamabad, Pakistan, 23–24 December 2006; pp. 173–177. [Google Scholar]
- Kim, S.; Zimmermann, T.; Whitehead, E.J., Jr.; Zeller, A. Predicting Faults from Cached History. In Proceedings of the 29th International Conference on Software Engineering (ICSE’07), Minneapolis, MN, USA, 20–26 May 2007; pp. 489–498. [Google Scholar]
- Hassan, A.E. Predicting Faults Using the Complexity of Code Changes. In Proceedings of the 2009 IEEE 31st International Conference on Software Engineering, Vancouver, BC, Canada, 16 May 2009; pp. 78–88. [Google Scholar]
- Khoshgoftaar, T.M.; Seliya, N. Tree-Based Software Quality Estimation Models for Fault Prediction. In Proceedings of the Eighth IEEE Symposium on Software Metrics, Ottawa, ON, Canada, 4–7 June 2002; pp. 203–214. [Google Scholar]
- Li, J.; He, P.; Zhu, J.; Lyu, M.R. Software Defect Prediction via Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security (QRS), Prague, Czech Republic, 25–29 July 2017; IEEE: Prague, Czech Republic, 2017; pp. 318–328. [Google Scholar]
- Chen, J.; Hu, K.; Yu, Y.; Chen, Z.; Xuan, Q.; Liu, Y.; Filkov, V. Software Visualization and Deep Transfer Learning for Effective Software Defect Prediction. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June 2020; pp. 578–589. [Google Scholar]
- Malhotra, R.; Jain, A. Fault Prediction Using Statistical and Machine Learning Methods for Improving Software Quality. J. Inf. Process. Syst. 2012, 8, 241–262. [Google Scholar] [CrossRef]
- Chidamber, S.R.; Kemerer, C.F. A Metrics Suite for Object Oriented Design. IEEE Trans. Softw. Eng. 1994, 20, 476–493. [Google Scholar] [CrossRef]
- Lee, S.; Kim, T.-K.; Ryu, D.; Baik, J. Software Defect Prediction with new Image Conversion Technique of Source Code. J. Korean Inst. Inf. Sci. Eng. 2021, 239–241. Available online: https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE11112825 (accessed on 21 October 2023).
- Sojeong, K.; Eunjung, J.; Jiwon, C.; Ryu, D. Software Defect Prediction Based on Ft-Transformer. J. Korean Inst. Inf. Sci. Eng. 2022, 1770–1772. Available online: https://www-dbpia-co-kr.translate.goog/journal/articleDetail?nodeId=NODE11113815&_x_tr_sl=ko&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=sc (accessed on 21 October 2023).
- Choi, J.; Lee, J.; Ryu, D.; Kim, S. Identification of Generative Adversarial Network Models Suitable for Software Defect Prediction. J. KIISE 2022, 49, 52–59. [Google Scholar] [CrossRef]
- Lee, J.; Choi, J.; Ryu, D.; Kim, S. TabNet based Software Defect Prediction. J. Korean Inst. Inf. Sci. Eng. 2021, 1255–1257. Available online: https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE11036011&nodeId=NODE11036011&medaTypeCode=185005&isPDFSizeAllowed=true&locale=ko&foreignIpYn=Y&articleTitle=TabNet+%EA%B8%B0%EB%B0%98%EC%9D%98+%EC%86%8C%ED%94%84%ED%8A%B8%EC%9B%A8%EC%96%B4+%EA%B2%B0%ED%95%A8+%EC%98%88%EC%B8%A1&articleTitleEn=TabNet+based+Software+Defect+Prediction&language=ko_KR&hasTopBanner=true (accessed on 21 October 2023).
- Zhang, Q.; Wu, B. Software Defect Prediction via Transformer. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (IT-NEC), Chongqing, China, 12–14 June 2020; pp. 874–879. [Google Scholar]
- Qureshi, M.R.J.; Qureshi, W.A. Evaluation of the Design Metric to Reduce the Number of Defects in Software Development. Int. J. Inf. Technol. Converg. Serv. 2012, 4, 9–17. [Google Scholar] [CrossRef]
- Xing, F.; Guo, P.; Lyu, M.R. A Novel Method for Early Software Quality Prediction Based on Support Vector Machine. In Proceedings of the 16th IEEE International Symposium on Software Reliability Engineering (ISSRE’05), Chicago, IL, USA, 8–11 November 2005; pp. 10–222. [Google Scholar]
- Tosun, A.; Turhan, B.; Bener, A. Practical Considerations in Deploying AI for Defect Prediction: A Case Study within the Turkish Telecommunication Industry. In Proceedings of the 5th International Conference on Predictor Models in Software Engineering, Vancouver, BC, Canada, 18 May 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 1–9. [Google Scholar]
- Kim, M.; Nam, J.; Yeon, J.; Choi, S.; Kim, S. REMI: Defect Prediction for Efficient API Testing. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August 2015; pp. 990–993. [Google Scholar]
- Kim, D.; Lee, S.; Seong, G.; Kim, D.; Lee, J.; Bhae, H. An Experimental Study on Software Fault Prediction considering Engineering Metrics based on Machine Learning in Vehicle. In Proceedings of the Korea Society of Automotive Engineers Fall Conference and Exhibition, Jeju, Republic of Korea, 18–21 November 2020; pp. 552–559. [Google Scholar]
- Kang, J.; Ryu, D.; Baik, J. A Case Study of Industrial Software Defect Prediction in Maritime and Ocean Transportation Industries. J. KIISE 2020, 47, 769–778. [Google Scholar] [CrossRef]
- McCabe, T.J. A Complexity Measure. IEEE Trans. Softw. Eng. 1976, SE-2, 308–320. [Google Scholar] [CrossRef]
- Huang, F.; Liu, B. Software Defect Prevention Based on Human Error Theories. Chin. J. Aeronaut. 2017, 30, 1054–1070. [Google Scholar] [CrossRef]
- ETSI TS 138 401. Available online: https://www.etsi.org/deliver/etsi_ts/138400_138499/138401/17.01.01_60/ts_138401v170101p.pdf (accessed on 21 October 2023).
- Han, I. Communications of the Korean Institute of Information Scientists and Engineers. Young 2013, 31, 56–62. [Google Scholar]
- Shin, H.J.; Song, J.H. A Study on Embedded Software Development Method (TBESDM: Two-Block Embedded Software Development Method). Soc. Converg. Knowl. Trans. 2020, 8, 41–49. [Google Scholar]
- Friedman, M.A.; Tran, P.Y.; Goddard, P.L. Reliability Techniques for Combined Hardware and Software Systems; Defense Technical Information Center: Fort Belvoir, VA, USA, 1992. [Google Scholar]
- Lee, S.; No, H.; Lee, S.; Lee, W.J. Development of Code Suitability Analysis Tool for Embedded Software Module. J. Korean Inst. Inf. Sci. Eng. 2015, 1582–1584. Available online: https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE06602802 (accessed on 21 October 2023).
- Lee, E. Definition of Check Point for Reliability Improvement of the Embedded Software. J. Secur. Eng. Res. 2011, 8, 149–156. [Google Scholar]
- Moser, R.; Pedrycz, W.; Succi, G. A Comparative Analysis of the Efficiency of Change Metrics and Static Code Attributes for Defect Prediction. In Proceedings of the 13th International Conference on Software Engineering—ICSE ’08; ACM Press: Leipzig, Germany, 2008; p. 181. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- SMOTE—Version 0.11.0. Available online: https://imbalanced-learn.org/stable/references/generated/imblearn.over_sampling.SMOTE.html (accessed on 15 October 2023).
- Yoo, B.J. A Study on the Performance Comparison and Approach Strategy by Classification Methods of Imbalanced Data. Korean Data Anal. Soc. 2021, 23, 195–207. [Google Scholar] [CrossRef]
- Introduction to Boosted Trees—Xgboost 2.0.0 Documentation. Available online: https://xgboost.readthedocs.io/en/stable/tutorials/model.html (accessed on 21 October 2023).
- Molnar, C. 9.5 Shapley Values|Interpretable Machine Learning. Available online: https://christophm.github.io/interpretable-ml-book/shapley.html (accessed on 21 October 2023).
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates Inc.: Glasgow, Scotland, 2017; Volume 30. [Google Scholar]
- Zhao, Y.; Damevski, K.; Chen, H. A Systematic Survey of Just-in-Time Software Defect Prediction. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | Data | Buggy Rate (%) | Granularity | Feature | Model | Evaluation |
|---|---|---|---|---|---|---|
| [5] | PC1 | Unknown | Unknown | Complexity, LOC | ACO-SVM | Precision 0.99, Recall 0.98, F-Measure 0.99 |
| [23] | Apache POI | 63.57 | Class | OO-Metric [24], Complexity, LOC | Bagging, … | Recall 0.83, Precision 0.82, AUC 0.876 |
| [25] | jEdit Lucene log4j Xalan Poi | 19.2~49.7 | File | Image of Source Code | DTL-DP | F-Measure 0.58~0.82, Accuracy 0.70~0.86 |
| [26] | AEEEM Relink | 9.26~50.52 | Class | Complexity, LOC | Ft-Transformer | Recall 0.77 |
| [27] | AEEEM AUDI JIRA | 4~40 | Unknown | Complexity LOC | Unknown | F-Measure 0.50~0.86 |
| [28] | AEEEM AUDI | 2.11~39.81 | Class, File | - | TabNet | Recall 0.85 |
| [29] | Camel Lucene Synapse Xerces Jedit Xalan Poi | 15.7~64.2 | File | AST (Abstract Syntax Tree) | Transformer | F-Measure Average 0.626 |
| Studies | Data | Buggy Rate (%) | Granularity | Feature | Model | Evaluation |
|---|---|---|---|---|---|---|
| [31] | MIS | Unknown | Unknown | Complexity LOC | TSVM | Accuracy 0.90 |
| [32] | GSM+ NASA | Avg 0.3~1 | File | Complexity LOC | Naïve Bayes | Recall Average 0.90 |
| [33] | Tizen API | Unknown | API | OO-Metric Complexity LOC | Random Forest | Precision 0.8 Recall 0.7 F-measure 0.75 |
| [34] | Software in Vehicle | 17.6 | Class | Complexity LOC Engineering-Metric | Random Forest | Accuracy 0.96 F-measure 0.90 AUC 0.92 |
| [35] | Software in the maritime and ocean transportation industries | Unknown | Unknown | Diffusion LOC Purpose History Experience | Random Forest | Accuracy 0.91 Precision 0.86 Recall 0.80 F-Measure 0.83 |
| Version | Samples (Files) | Buggy Files | Buggy Rate | Sample Rate | Code Submitter | Feature Count | Dev. Period |
|---|---|---|---|---|---|---|---|
| V1 | 4282 | 1126 | 26.3% | 42% | 897 | 353 | 3M |
| V2 | 4637 | 1575 | 34.0% | 40% | 1159 | 642 | 6M |
| V3 | 8808 | 1292 | 14.7% | 74% | 1098 | 568 | 6M |
| Sum | 17,727 | 3993 | - | - | - | - | - |
| Average | 5909 | 1331 | 22.5% | - | - | - | - |
| Language | Samples (Files) | Buggy Files | Buggy Rate |
|---|---|---|---|
| C | 8585 | 2188 | 20.3% |
| C++ | 5149 | 1805 | 26.0% |
| Sum | 17,727 | 3993 | - |
| Average | 5909 | 1331 | 22.5% |
| No | Metric Type | Feature Name | Definition | Comments |
|---|---|---|---|---|
| 1 | Product Metric | Ploc | Physical LOC | min/max/sum |
| 2 | Bloc | Build LOC | min/max/sum | |
| 3 | CommentLOC | Comment LOC | ||
| 4 | fan_in | Fan In | min/max/sum | |
| 5 | CC | Cyclomatic Complexity | min/max/sum | |
| 6 | GV 1 | Global Variables accessing to | min/max/sum | |
| 7 | MCD 1 | Module Circular Dependency | min/max/sum | |
| 8 | DC 1 | Duplicate Code | ||
| 9 | PPLOC 1 | Preprocessor LOC | ||
| 10 | Process Metric | cl_count | Change List Count | min/max/sum |
| 11 | cloc_a | Added LOC | min/max/sum | |
| 12 | cloc_c | Changed LOC | min/max/sum | |
| 13 | cloc_d | Deleted LOC | min/max/sum | |
| 14 | cov_l, cov_b 1 | Line/Branch Coverage | min/max/sum | |
| 15 | Critical/Major 1 | Static Analysis Defect | ||
| 16 | FileType1 1 | Programming Language Type | ||
| 17 | Group_SSYS 1 | Subsystem ID | 0~4 | |
| 18 | Group_BLK 1 | Block ID | 0~99 |
| Confusion Matrix | Predicted Class | ||
|---|---|---|---|
| Buggy (Positive) | Clean (Negative) | ||
| Actual Class | Buggy | TP (True Positive) | FN (False Negative) |
| Clean | FP (False Positive) | TN (True Negative) | |
| Group | Samples (Files) | Buggy Files | Buggy Rate |
|---|---|---|---|
| G0 | 3999 | 1321 | 24.8% |
| G1 | 3477 | 1319 | 27.5% |
| G2 | 1743 | 328 | 15.8% |
| G3 | 2118 | 263 | 11.0% |
| G4 | 2397 | 762 | 24.1% |
| Sum | 17,727 | 3993 | 22.5% |
| Classifier | ① No Processing | ② Scaling | ||||||||
| Precision | Recall | F-measurement | Accuracy | ROC-AUC | Precision | Recall | F-measurement | Accuracy | ROC-AUC | |
| RF | 0.69 | 0.41 | 0.52 | 0.83 | 0.85 | 0.69 | 0.41 | 0.52 | 0.83 | 0.85 |
| LR | 0.63 | 0.39 | 0.49 | 0.81 | 0.76 | 0.71 | 0.34 | 0.46 | 0.82 | 0.83 |
| XGB | 0.63 | 0.45 | 0.53 | 0.82 | 0.85 | 0.63 | 0.45 | 0.53 | 0.82 | 0.85 |
| MLP | 0.44 | 0.25 | 0.32 | 0.76 | 0.54 | 0.49 | 0.47 | 0.48 | 0.77 | 0.75 |
| Classifier | ③ Outlier Processing | ④ Oversampling | ||||||||
| Precision | Recall | F-measurement | Accuracy | ROC-AUC | Precision | Recall | F-measurement | Accuracy | ROC-AUC | |
| RF | 0.67 | 0.4 | 0.5 | 0.82 | 0.85 | 0.49 | 0.74 | 0.59 | 0.77 | 0.85 |
| LR | 0.58 | 0.42 | 0.49 | 0.80 | 0.8 | 0.42 | 0.78 | 0.55 | 0.71 | 0.81 |
| XGB | 0.64 | 0.47 | 0.54 | 0.82 | 0.85 | 0.51 | 0.69 | 0.58 | 0.78 | 0.84 |
| MLP | 0.42 | 0.41 | 0.41 | 0.74 | 0.65 | 0.39 | 0.41 | 0.4 | 0.72 | 0.61 |
| Classifier | ⑤ Additional Metric | ⑥ Sample Grouping | ||||||||
| Precision | Recall | F-measurement | Accuracy | ROC-AUC | Precision | Recall | F-measurement | Accuracy | ROC-AUC | |
| RF | 0.5 | 0.76 | 0.6 | 0.78 | 0.86 | 0.52 | 0.75 | 0.61 | 0.79 | 0.86 |
| LR | 0.42 | 0.62 | 0.5 | 0.72 | 0.72 | 0.42 | 0.62 | 0.5 | 0.72 | 0.72 |
| XGB | 0.54 | 0.73 | 0.62 | 0.8 | 0.86 | 0.55 | 0.74 | 0.63 | 0.80 | 0.87 |
| MLP | 0.39 | 0.3 | 0.34 | 0.74 | 0.51 | 0.45 | 0.25 | 0.32 | 0.76 | 0.5 |
| Studies | Precision | Recall | F-Measurement | Accuracy | ROC-AUC | Data |
|---|---|---|---|---|---|---|
| [5] | 0.99 | 0.98 | 0.99 | - | - | PC1 |
| [23] | 0.82 | 0.83 | - | - | 0.88 | Apache |
| [25] | - | - | 0.58~0.82 | 0.70~0.86 | - | iEdit, … |
| [26] | - | 0.77 | - | - | - | AEEEM, … |
| [27] | - | - | 0.50~0.86 | - | - | AEEEM, … |
| [28] | - | 0.50 | - | - | - | AEEEM, … |
| [29] | - | - | 0.626 | - | - | Camel, … |
| [31] | - | - | - | 0.90 | - | MIS |
| [32] | - | 0.90 | - | - | - | GSM, NASA |
| [33] | 0.80 | 0.70 | 0.75 | - | - | Tizen API |
| [34] | - | - | 0.90 | 0.96 | 0.92 | Vehicle S/W |
| [35] | 0.86 | 0.80 | 0.83 | 0.91 | - | Ship S/W |
| This study | 0.55 | 0.74 | 0.63 | 0.80 | 0.87 | Samsung |
| Case | Precision | Recall | F-Measurement | Accuracy | ROC-AUC |
|---|---|---|---|---|---|
| Average for Within-Version | 0.55 | 0.72 | 0.62 | 0.79 | 0.86 |
| Average for Cross-Version | 0.52 | 0.62 | 0.54 | 0.76 | 0.81 |
| Case | Precision | Recall | F-Measurement | Accuracy | ROC-AUC |
|---|---|---|---|---|---|
| Average of Within-Group | 0.51 | 0.73 | 0.60 | 0.81 | 0.85 |
| Average of Cross-Group | 0.46 | 0.58 | 0.50 | 0.77 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.; Do, S. ML-Based Software Defect Prediction in Embedded Software for Telecommunication Systems (Focusing on the Case of SAMSUNG ELECTRONICS). Electronics 2024, 13, 1690. https://doi.org/10.3390/electronics13091690
Kang H, Do S. ML-Based Software Defect Prediction in Embedded Software for Telecommunication Systems (Focusing on the Case of SAMSUNG ELECTRONICS). Electronics. 2024; 13(9):1690. https://doi.org/10.3390/electronics13091690
Chicago/Turabian StyleKang, Hongkoo, and Sungryong Do. 2024. "ML-Based Software Defect Prediction in Embedded Software for Telecommunication Systems (Focusing on the Case of SAMSUNG ELECTRONICS)" Electronics 13, no. 9: 1690. https://doi.org/10.3390/electronics13091690
APA StyleKang, H., & Do, S. (2024). ML-Based Software Defect Prediction in Embedded Software for Telecommunication Systems (Focusing on the Case of SAMSUNG ELECTRONICS). Electronics, 13(9), 1690. https://doi.org/10.3390/electronics13091690