
Design and Development of an Internet of Smart Cameras Solution for Complex Event Detection in COVID-19 Risk Behaviour Recognition




Abstract
:1. Introduction
- -
- To design and develop an integrated edge and cloud computing architecture for complex event detection using the interoperable Internet of smart cameras. This flexible architecture enables us to detect objects from single cameras and integrate them into a complex event in the cloud computing part.
- -
- To implement the integrated cloud and edge computing architecture of the IoSC to detect risk behaviours carried out by people that might lead to possible COVID-19 spread. Risk behaviours are considered complex events and are detected using the architecture model and reported to the cloud network in real-time.
- -
- To demonstrate how much the object detection model influences the number of missing events, we compared region- and regression-based object detection models for simple events.
2. Background
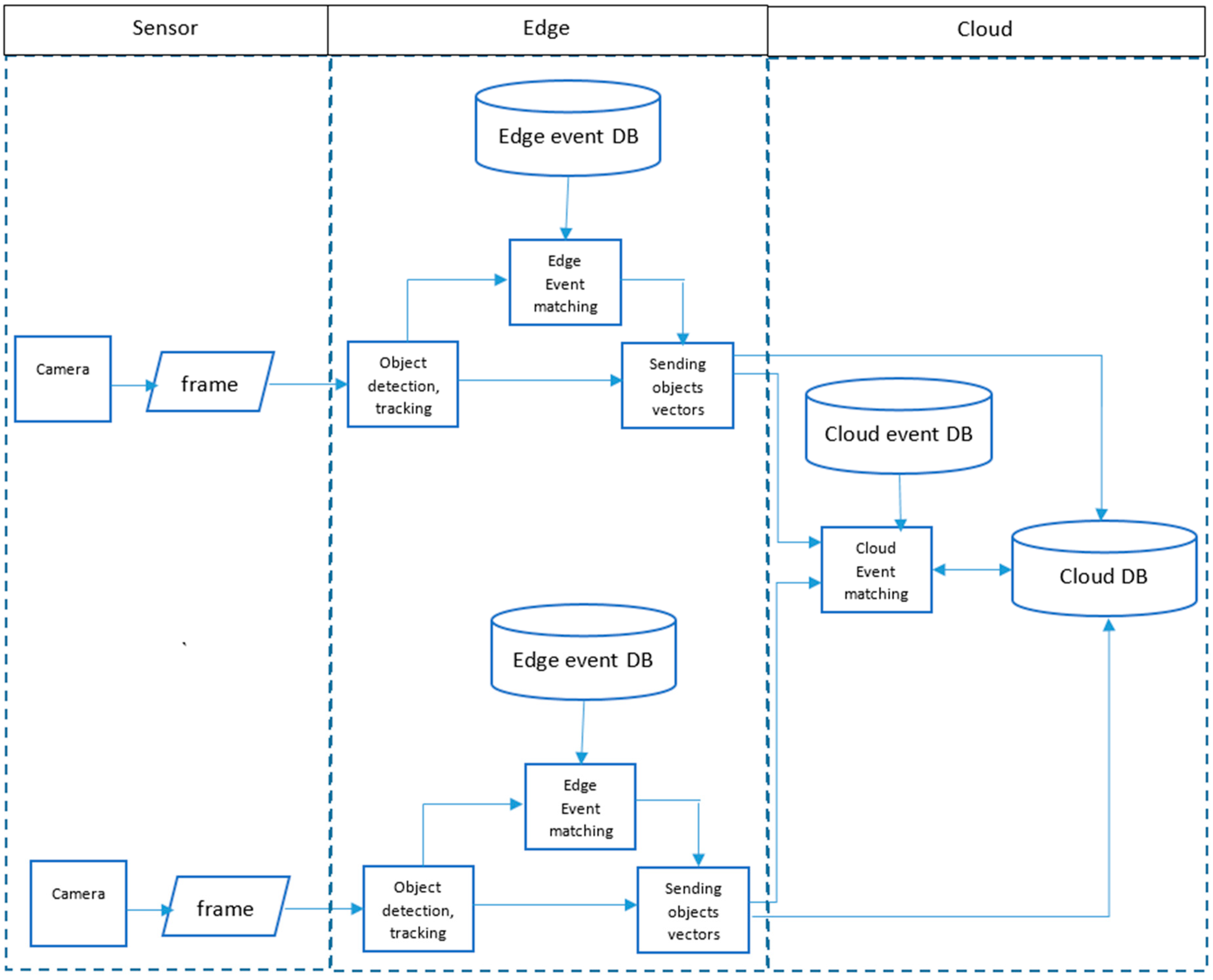
3. Complex Event Detection Methodology
3.1. Object Detection and Tracking
3.2. Event Matching with Edge
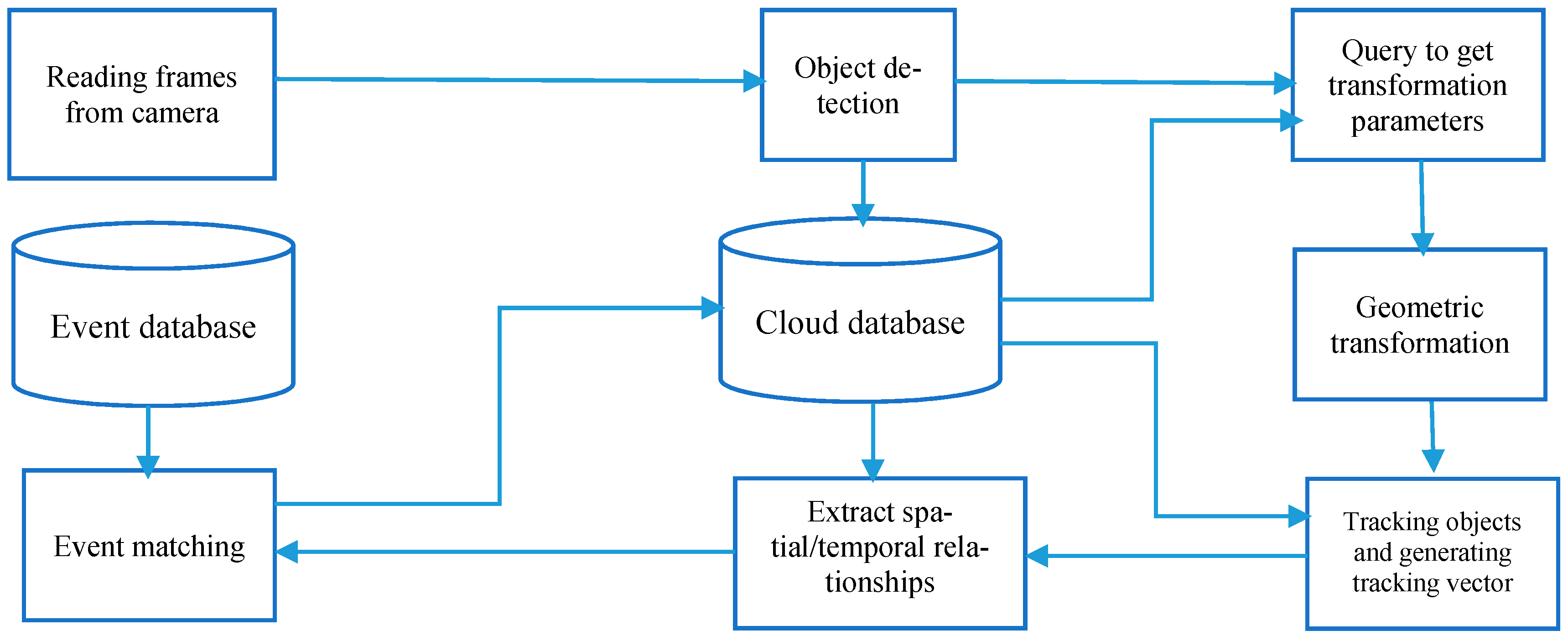
3.3. Event Matching Using Cloud Computing
4. Implementation
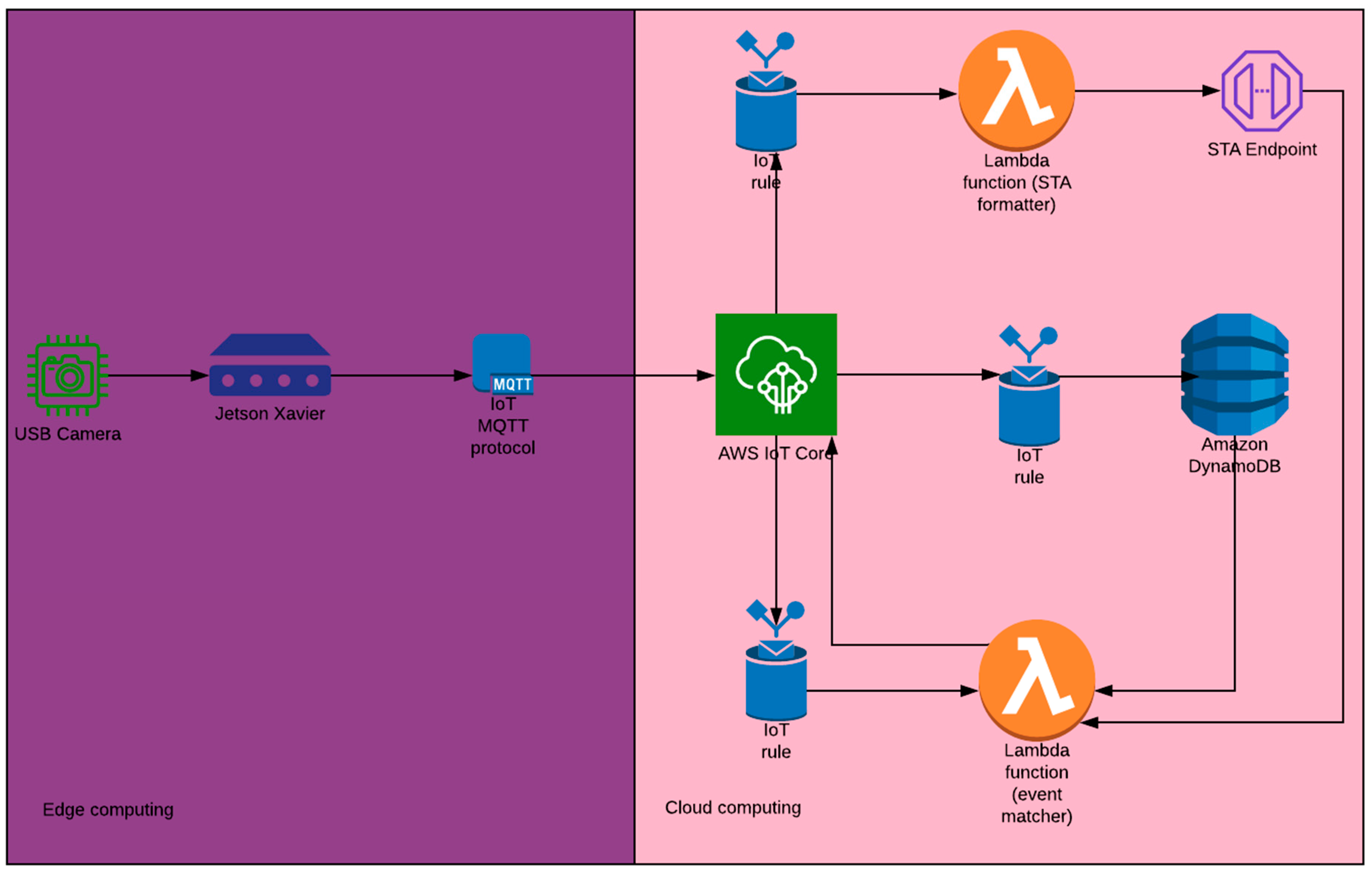
4.1. Implemented Architecture
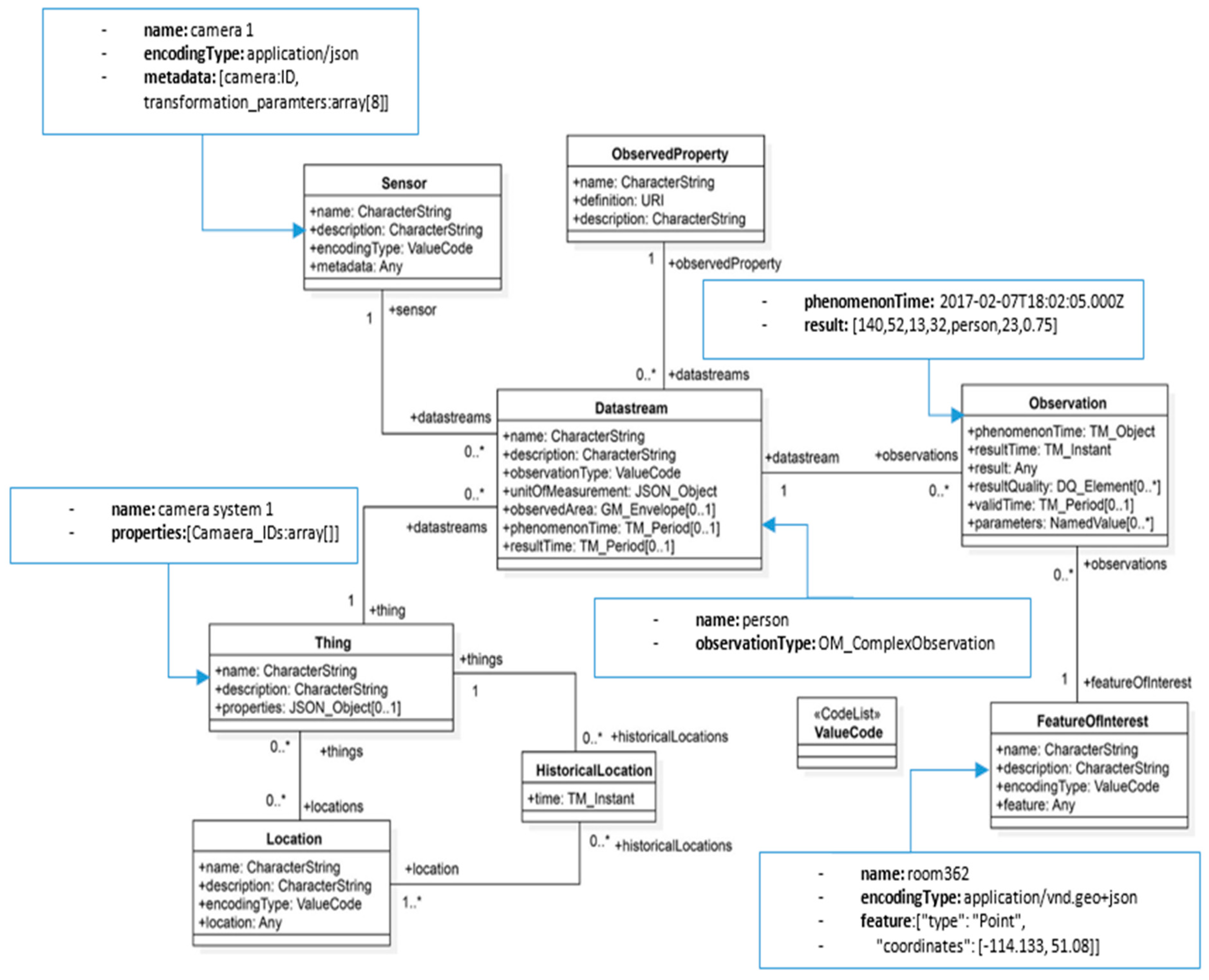
4.2. STA Model
4.3. Data and Object Detection Model
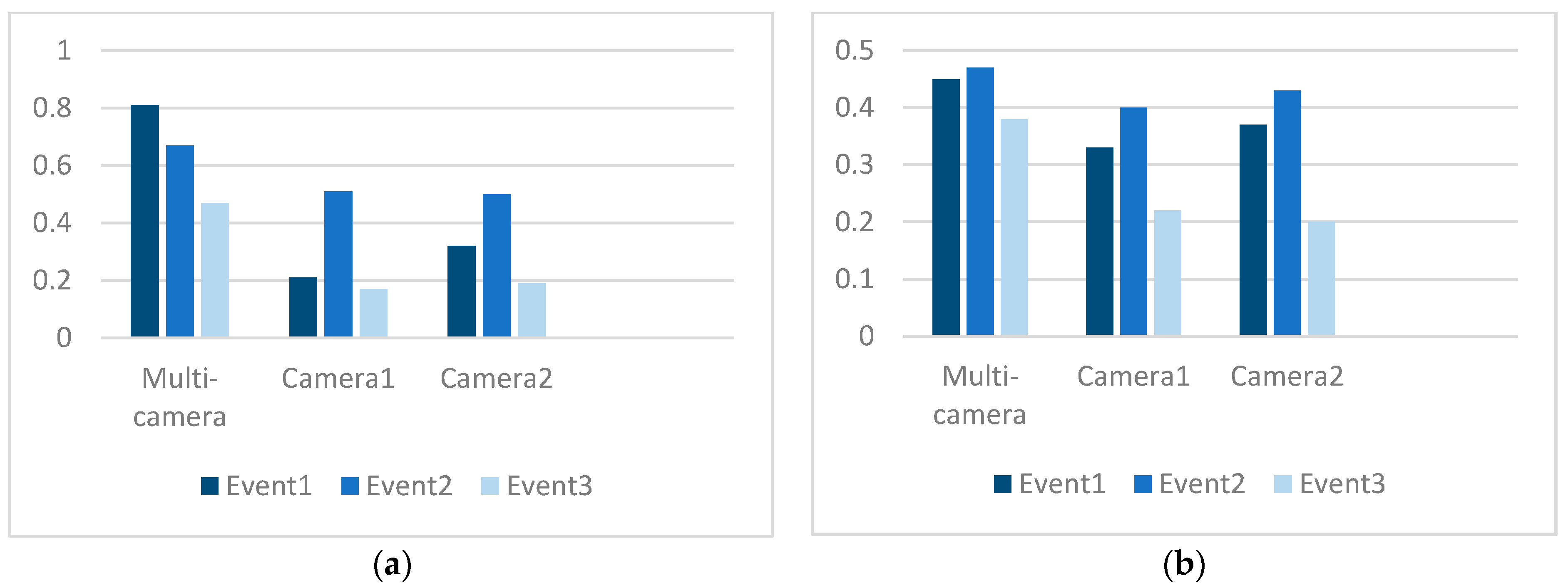
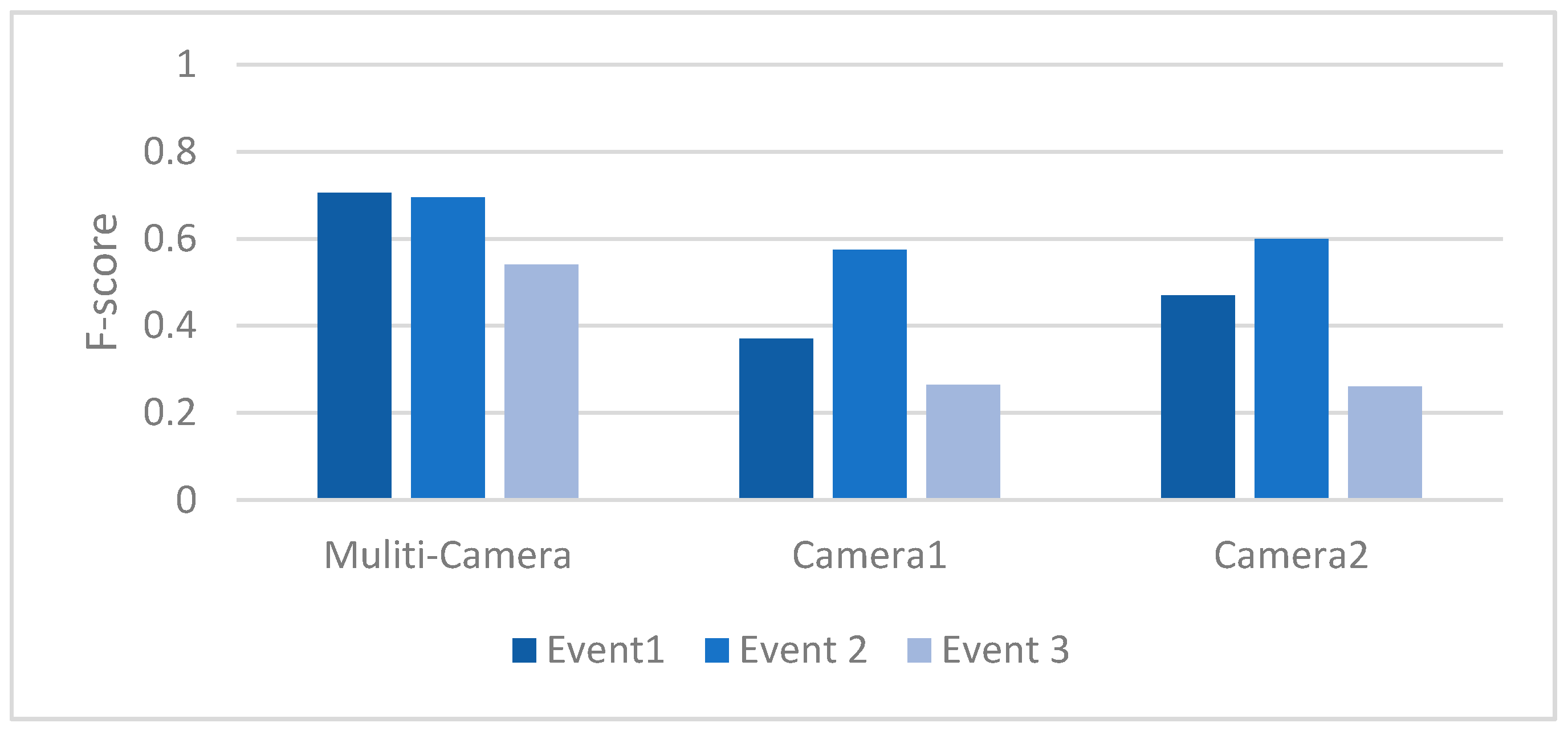
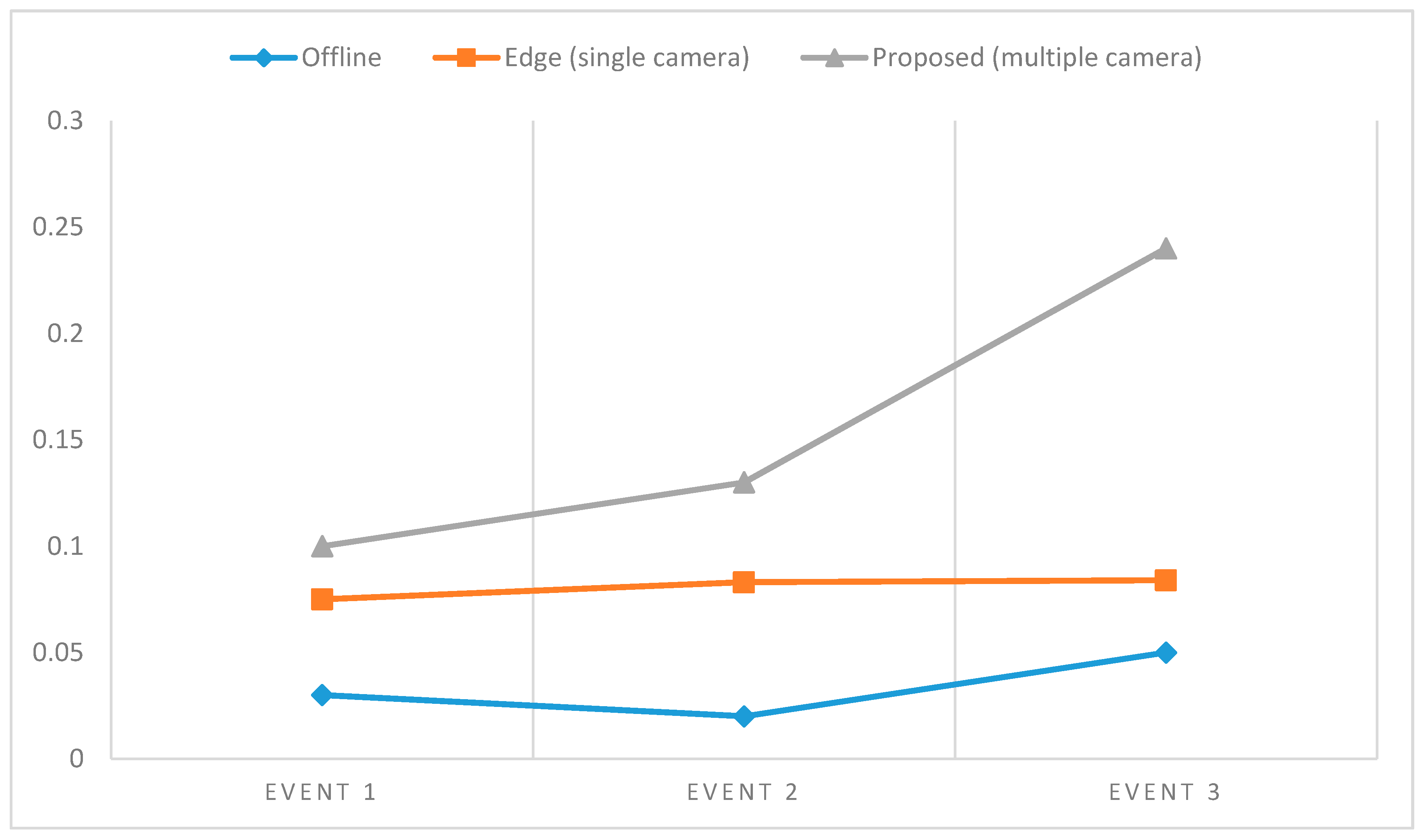
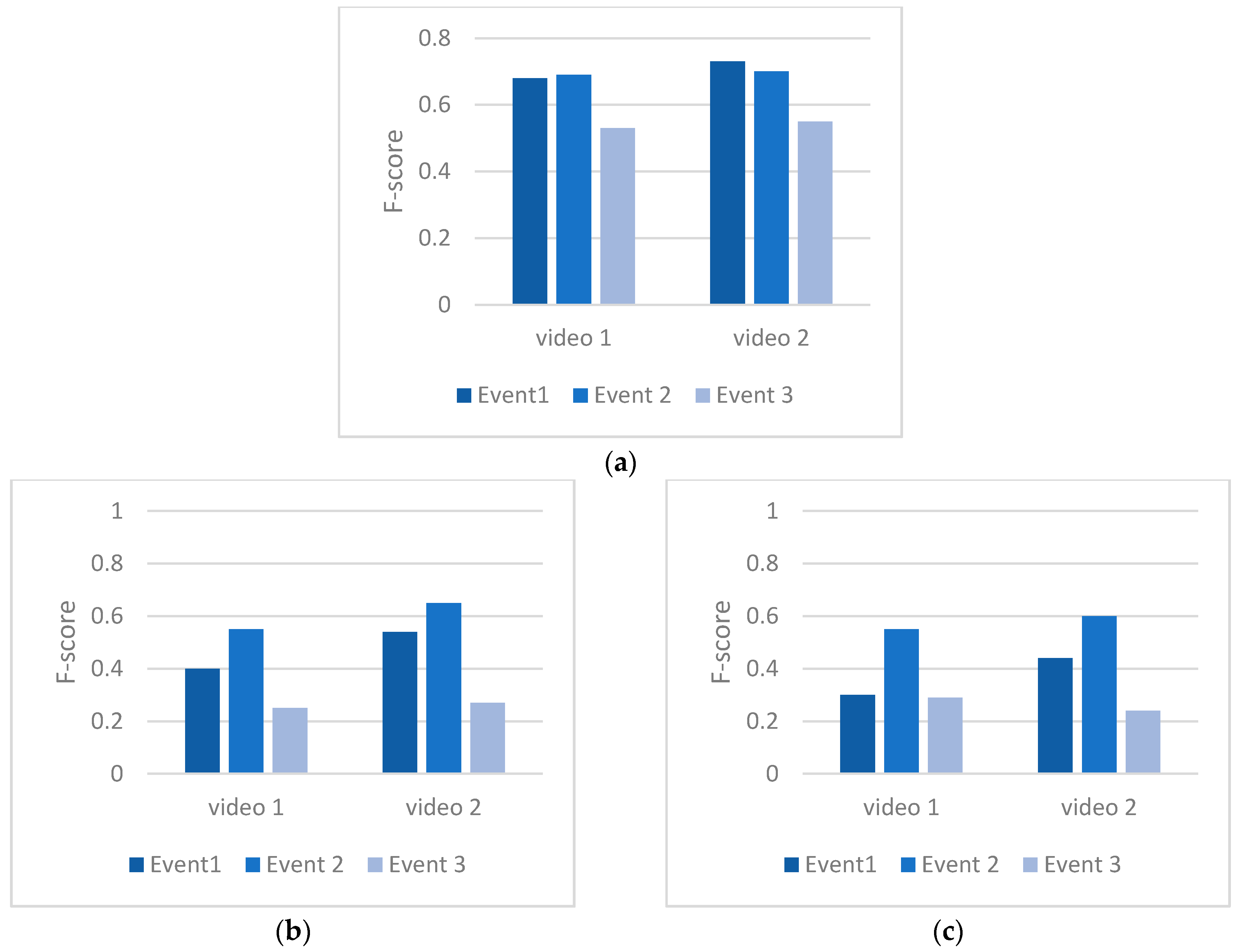
5. Experimental Results
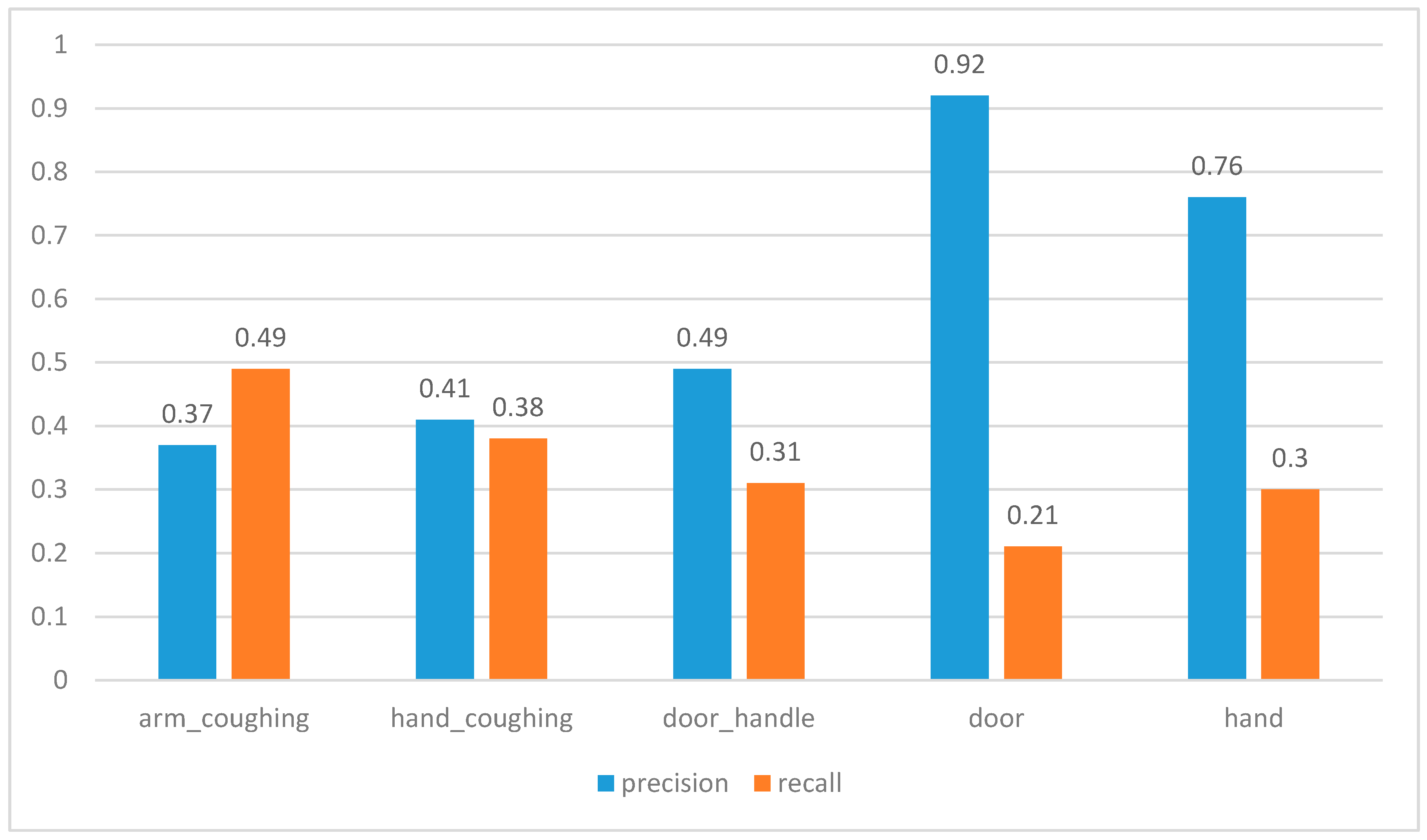
5.1. Object Detection Accuracy
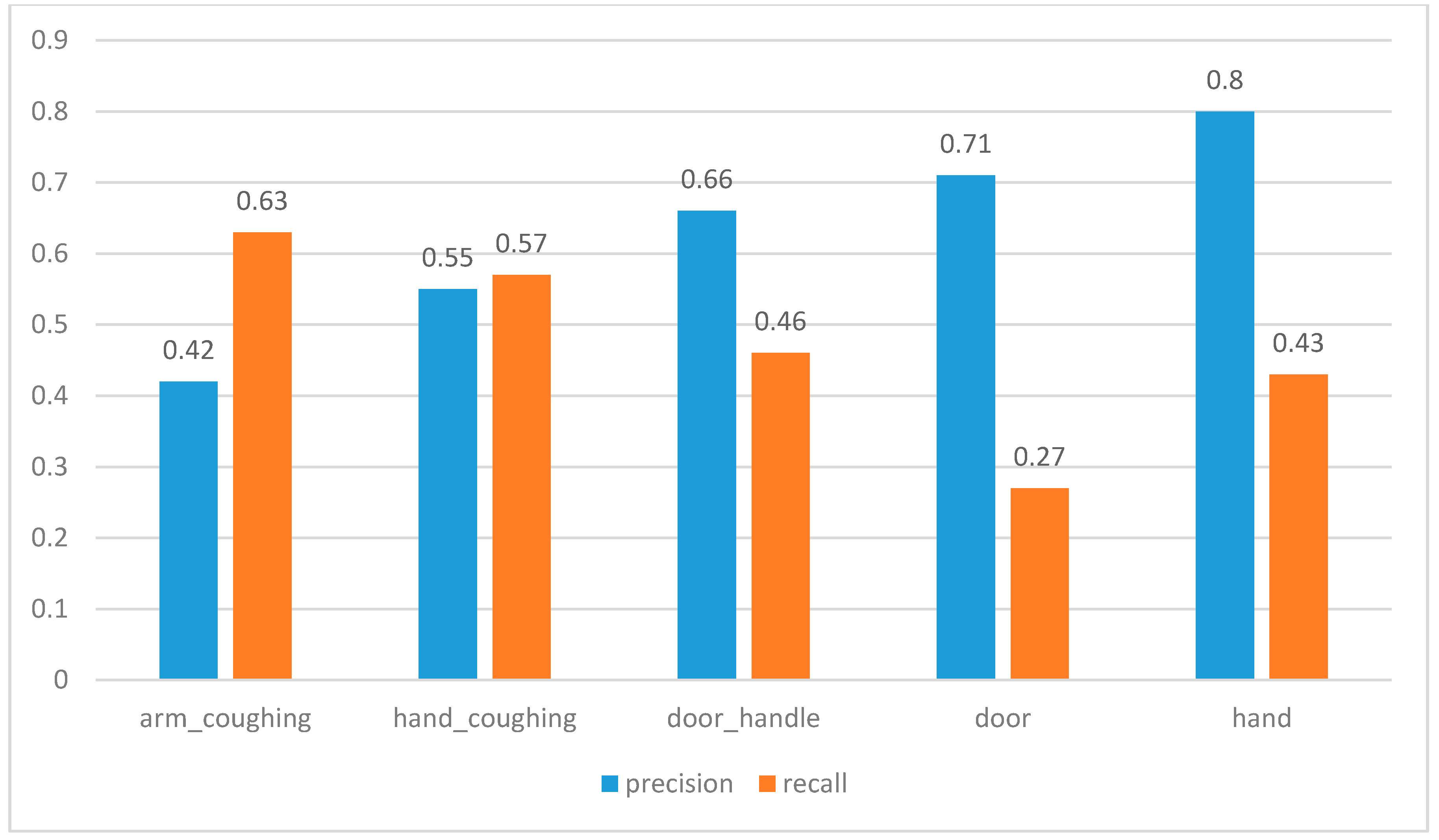
5.2. Online Event Matching Accuracy
5.3. Online Event Detection Speed
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
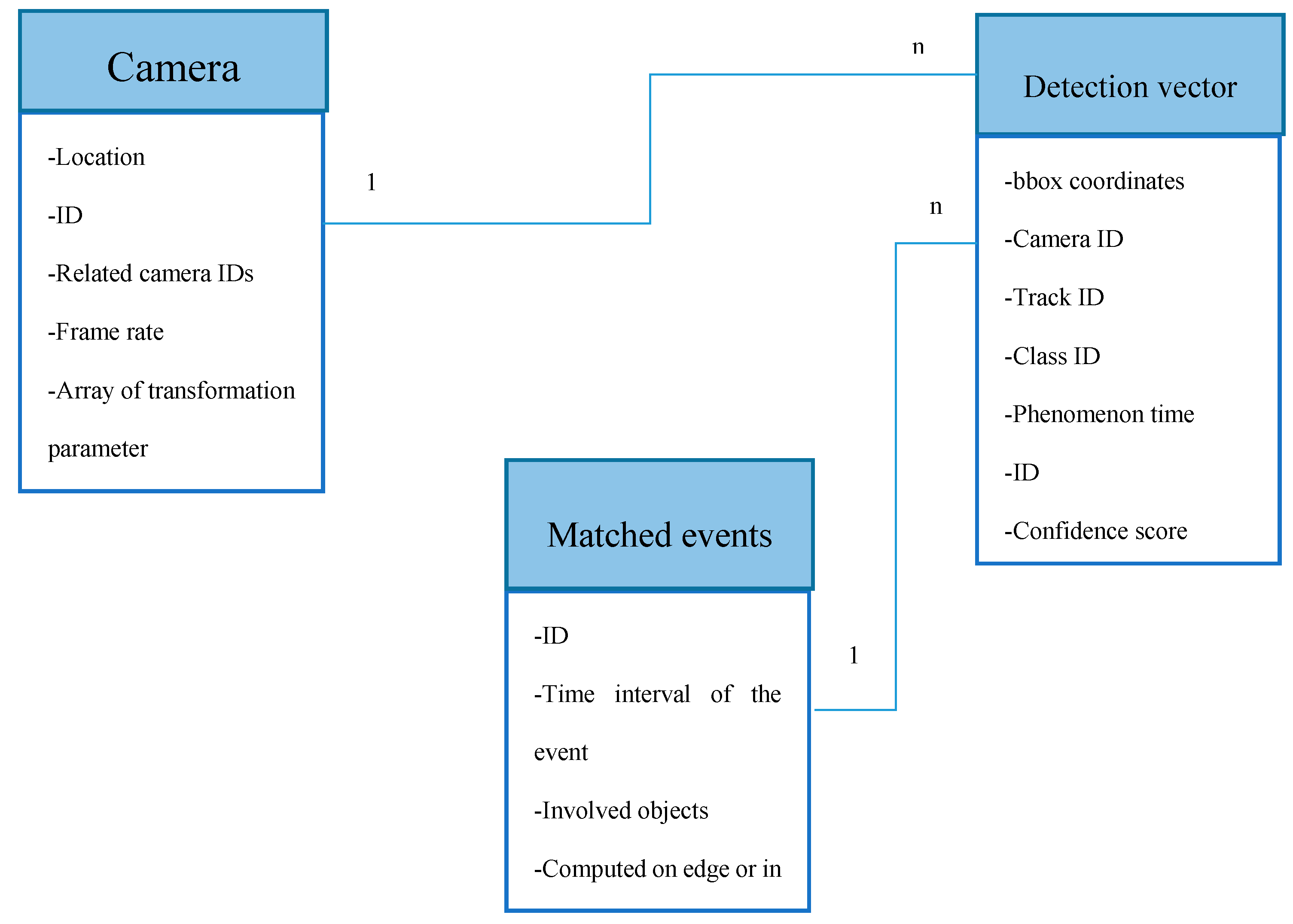
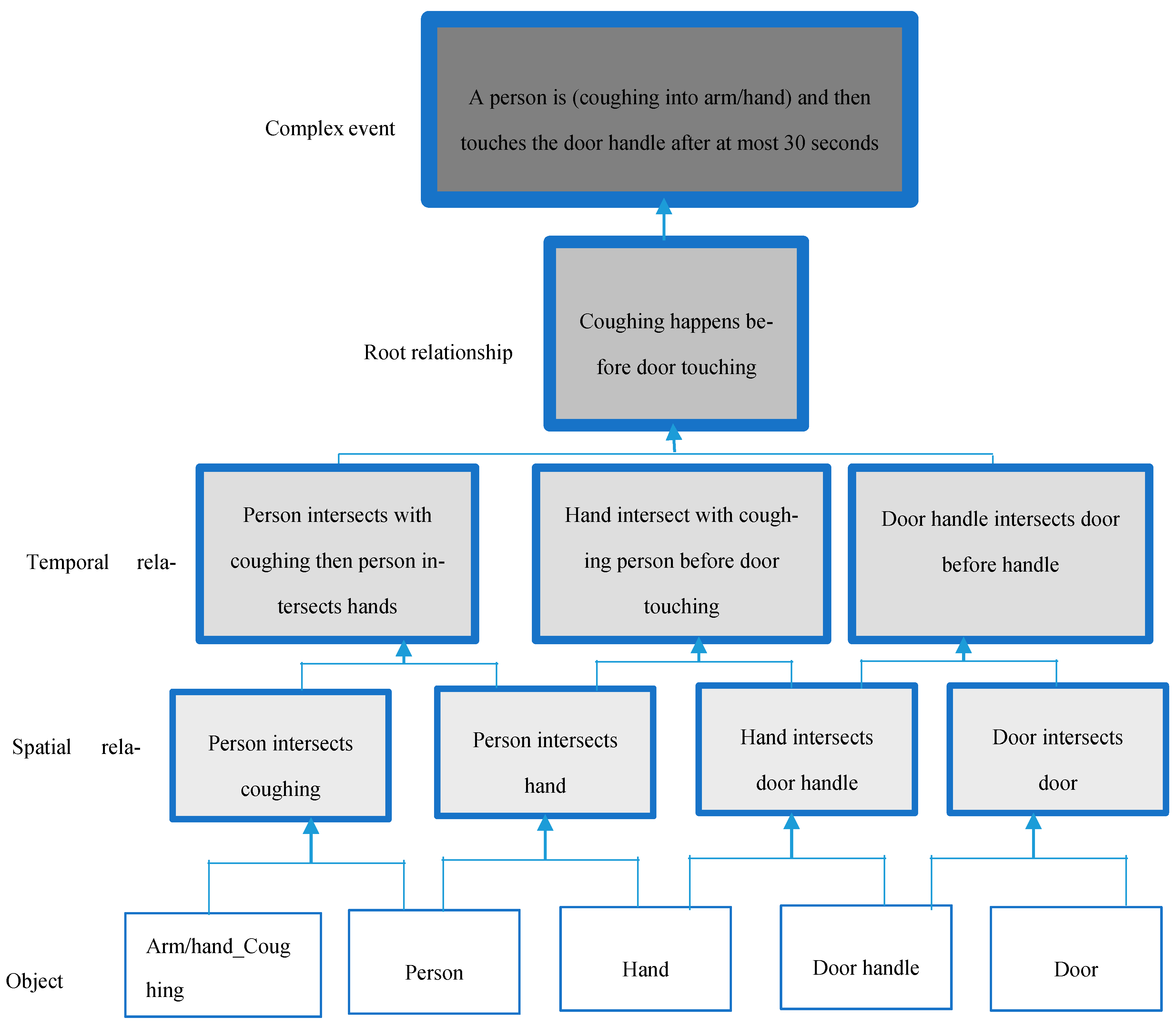
- Definition 1 (Event Vector).An event stored in the event database is considered a vector with the following elements:
- O = The array of detected object classes;
- Sr = Spatial relationship vector which includes the spatial relationship expression and involved object classes;
- Tr = Temporal relationship vector which includes the temporal relationship expression and involved spatial relationships;
- Rt = An array (the root vector) of vectors including relationships between Tr. For example, an Rt looks like this:
- Rt = [R1(Tr1,Tr2,relationship_expression1), …, Rn(Trn−1,Trn,relationship_expressionn)]
- Definition 2 (Detection Object Vector).The detected object in every frame which includes the following elements:
- Bbox = The rectangle of object bounding boxes is an array: [xmin, ymin, width, height];
- Class = The class name of the detected object;
- Confidence = The probability confidence value of the detected object.
- Trackid = The ID assigned to every object when the tracking module is run.
| Pseudocode 1—Event Matching Process begin c = captureFrame() spatial_rel=[] temporal_rel=[] while c t = captureTime() det_obj = objectDetector(c) if det_obj.siz>0 do for each event from eventPatterns do object_event = [] for each obj_pattern from event.object do if det_obj in obj_pattern do object_event.add(det_obj) end end if object_event.size() > 1 do for each sr from event.Sr do object1 = find(sr.object1.class,object_event) object2 = find(sr.object2.class,object_event) r = spatialRelation(object1,object2) if r is True do s = (sr,obj1,obj2,t) spatial_rel.add(s) end end for each temporal_rel from event.Tr do sr1 = find(temporal_rel.s1,spatial_rel) sr2 = find(temporal_rel.s2,spatial_rel) event_detected = temporalRelation(sr1.t,sr2.t) if event_detected is True do T = (sr,obj1,obj2,t) temporal_rel.add(T) end end for each root_vector from event.Rt do R1 = find(root_vector.T1,temporal_rel) R2 = find(root_vector.T2,temporal_rel) R = root_relationship(R1,R2) if R is False do skipFrame() end end return event end end end end end |
Appendix B

References
- Banerjee, S.; Wu, D.O. Final Report from the NSF Workshop on Future Directions in Wireless Networking; National Science Foundation: Washington, DC, USA, 2013. [Google Scholar]
- Frankowski, G.; Jerzak, M.; Miłostan, M.; Nowak, T.; Pawłowski, M. Application of the Complex Event Processing system for anomaly detection and network monitoring. Comput. Sci. 2015, 16, 351–371. [Google Scholar]
- Li, S.; Son, S.H.; Stankovic, J.A. Event detection services using data service middleware in distributed sensor networks. In Information Processing in Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2003; pp. 502–517. [Google Scholar]
- Fan, H.; Chang, X.; Cheng, D.; Yang, Y.; Xu, D.; Hauptmann, A.G. Complex event detection by identifying reliable shots from untrimmed videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 736–744. [Google Scholar]
- Wu, E.; Diao, Y.; Rizvi, S. High-performance complex event processing over streams. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 407–418. [Google Scholar]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. (CSUR) 2012, 44, 1–62. [Google Scholar] [CrossRef]
- Butakova, M.A.; Chernov, A.V.; Shevchuk, P.S.; Vereskun, V.D. Complex event processing for network anomaly detection in digital railway communication services. In Proceedings of the 2017 25th Telecommunication Forum (TELFOR), Belgrade, Serbia, 21–22 November 2017; pp. 1–4. [Google Scholar]
- Terroso-Saenz, F.; Valdes-Vela, M.; Sotomayor-Martinez, C.; Toledo-Moreo, R.; Gomez-Skarmeta, A.F. A cooperative approach to traffic congestion detection with complex event processing and VANET. IEEE Trans. Intell. Transp. Syst. 2012, 13, 914–929. [Google Scholar] [CrossRef]
- Mazon-Olivo, B.; Hernández-Rojas, D.; Maza-Salinas, J.; Pan, A. Rules engine and complex event processor in the context of internet of things for precision agriculture. Comput. Electron. Agric. 2018, 154, 347–360. [Google Scholar] [CrossRef]
- Liu, X.; Cao, J.; Tang, S.; Guo, P. Fault tolerant complex event detection in WSNs: A case study in structural health monitoring. IEEE Trans. Mob. Comput. 2015, 14, 2502–2515. [Google Scholar] [CrossRef]
- Terroso-Saenz, F.; Valdes-Vela, M.; Skarmeta-Gomez, A.F. A complex event processing approach to detect abnormal behaviours in the marine environment. Inf. Syst. Front. 2016, 18, 765–780. [Google Scholar] [CrossRef]
- Jin, X.; Yuan, P.; Li, X.; Song, C.; Ge, S.; Zhao, G.; Chen, Y. Efficient privacy preserving Viola-Jones type object detection via random base image representation. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 673–678. [Google Scholar]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Li, J.Z.; Ozsu, M.T.; Szafron, D.; Oria, V. MOQL: A multimedia object query language. In Proceedings of the 3rd International Workshop on Multimedia Information Systems, Seoul, Korea, 22–26 October 2018; pp. 19–28. [Google Scholar]
- Kuo, T.C.; Chen, A.L. Content-based query processing for video databases. IEEE Trans. Multimedia 2000, 2, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Aref, W.; Hammad, M.; Catlin, A.C.; Ilyas, I.; Ghanem, T.; Elmagarmid, A.; Marzouk, M. Video query processing in the VDBMS testbed for video database research. In Proceedings of the 1st ACM International Workshop on Multimedia Databases, New Orleans, LA, USA, 7 November 2003; pp. 25–32. [Google Scholar]
- Lu, C.; Liu, M.; Wu, Z. Svql: A sql extended query language for video databases. Int. J. Database Theor. Appl. 2015, 8, 235–248. [Google Scholar] [CrossRef]
- Kang, D.; Bailis, P.; Zaharia, M. BlazeIt: Optimizing declarative aggregation and limit queries for neural network-based video analytics. arXiv 2018, arXiv:1805.01046. [Google Scholar] [CrossRef]
- Jain, P.; Shukla, V.; Srinivasan, A.; de Castro Alves, A.; Hsiao, E. Support for a Parameterized Query/View in Complex Event Processing. U.S. Patent No. 8,713,049, 29 April 2014. [Google Scholar]
- Yadav, P.; Curry, E. VidCEP: Complex Event Processing Framework to Detect Spatiotemporal Patterns in Video Streams. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 10–12 December 2019; pp. 2513–2522. [Google Scholar]
- Medioni, G.; Cohen, I.; Brémond, F.; Hongeng, S.; Nevatia, R. Event detection and analysis from video streams. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 873–889. [Google Scholar] [CrossRef]
- Li, Z.; Ge, T. History is a mirror to the future: Best-effort approximate complex event matching with insufficient resources. Proc. VLDB Endow. 2016, 10, 397–408. [Google Scholar] [CrossRef] [Green Version]
- Ferreiros, J.; Pardo, J.M.; Hurtado, L.-F.; Segarra, E.; Ortega, A.; Lleida, E.; Torres, M.I.; Justo, R. ASLP-MULAN: Audio speech and language processing for multimedia analytics. Proces. Leng. Nat. 2016, 57, 147–150. [Google Scholar]
- Yang, A.; Zhang, C.; Chen, Y.; Zhuansun, Y.; Liu, H. Security and privacy of smart home systems based on the Internet of Things and stereo matching algorithms. IEEE Int. Things J. 2019, 7, 2521–2530. [Google Scholar] [CrossRef]
- Karthick, R.; Prabaharan, A.M.; Selvaprasanth, P. Internet of things based high security border surveillance strategy. Asian J. Appl. Sci. Technol. (AJAST) Vol. 2019, 3, 94–100. [Google Scholar]
- Al-Sakran, H.O. Intelligent traffic information system based on integration of Internet of Things and Agent technology. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 37–43. [Google Scholar]
- Zhang, S.; Yu, H. Person re-identification by multi-camera networks for Internet of Things in smart cities. IEEE Access 2018, 6, 76111–76117. [Google Scholar] [CrossRef]
- Sara Saeedi, J.L.; Liang, S.; Hawkins, B.; Chen, C.; Correas, I.; Starkov, I.; MacDonald, J.; Alzona, M.; Botts, M.; Mohammadi Jahromi, M.; et al. OGC SCIRA Pilot Engineering Report; Open Geospatial Consortium: Wayland, MA, USA, 2020. [Google Scholar]
- García, C.G.; Meana-Llorián, D.; G-Bustelo, B.C.P.; Lovelle, J.M.C.; Garcia-Fernandez, N. Midgar: Detection of people through computer vision in the Internet of Things scenarios to improve the security in Smart Cities, Smart Towns, and Smart Homes. Future Gener. Comput. Syst. 2017, 76, 301–313. [Google Scholar] [CrossRef] [Green Version]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1932–1939. [Google Scholar]
- Fan, H.; Luo, C.; Zeng, C.; Ferianc, M.; Que, Z.; Liu, S.; Niu, X.; Luk, W. F-E3D: FPGA-based acceleration of an efficient 3D convolutional neural network for human action recognition. In Proceedings of the 2019 IEEE 30th International Conference on Application-specific Systems, Architectures and Processors (ASAP), New York, NY, USA, 15–17 July 2019; pp. 1–8. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Han, Y.; Zhang, P.; Zhuo, T.; Huang, W.; Zhang, Y. Going deeper with two-stream ConvNets for action recognition in video surveillance. Pattern Recogn. Lett. 2018, 107, 83–90. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ko, K.-E.; Sim, K.-B. Deep convolutional framework for abnormal behavior detection in a smart surveillance system. Eng. Appl. Artif. Intell. 2018, 67, 226–234. [Google Scholar] [CrossRef]
- Gan, C.; Wang, N.; Yang, Y.; Yeung, D.-Y.; Hauptmann, A.G. Devnet: A deep event network for multimedia event detection and evidence recounting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 2568–2577. [Google Scholar]
- Xiong, Y.; Zhu, K.; Lin, D.; Tang, X. Recognize complex events from static images by fusing deep channels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 1600–1609. [Google Scholar]
- Jhuo, I.-H.; Lee, D. Video event detection via multi-modality deep learning. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 666–671. [Google Scholar]
- Wu, Z.; Jiang, Y.-G.; Wang, X.; Ye, H.; Xue, X. Multi-stream multi-class fusion of deep networks for video classification. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 5–19 October 2016; pp. 791–800. [Google Scholar]
- Habibian, A.; Mensink, T.; Snoek, C.G. Composite concept discovery for zero-shot video event detection. In Proceedings of the International Conference on Multimedia Retrieval, Glasgow, UK, 1–4 April 2014; pp. 17–24. [Google Scholar]
- Mazloom, M.; Gavves, E.; van de Sande, K.; Snoek, C. Searching informative concept banks for video event detection. In Proceedings of the 3rd ACM conference on International conference on multimedia retrieval, Dallas, TX, USA, 16–19 April 2013; pp. 255–262. [Google Scholar]
- Rastegari, M.; Diba, A.; Parikh, D.; Farhadi, A. Multi-attribute queries: To merge or not to merge? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 3310–3317. [Google Scholar]
- Dubba, K.S.; Cohn, A.G.; Hogg, D.C.; Bhatt, M.; Dylla, F. Learning relational event models from video. J. Artif. Intell. Res. 2015, 53, 41–90. [Google Scholar] [CrossRef]
- Kang, D.; Emmons, J.; Abuzaid, F.; Bailis, P.; Zaharia, M. Noscope: Optimizing neural network queries over video at scale. arXiv 2017, arXiv:1703.02529. [Google Scholar] [CrossRef]
- Hsieh, K.; Ananthanarayanan, G.; Bodik, P.; Venkataraman, S.; Bahl, P.; Philipose, M.; Gibbons, P.B.; Mutlu, O. Focus: Querying large video datasets with low latency and low cost. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 269–286. [Google Scholar]
- Choochotkaew, S.; Yamaguchi, H.; Higashino, T.; Shibuya, M.; Hasegawa, T. EdgeCEP: Fully-distributed complex event processing on IoT edges. In Proceedings of the 2017 13th International Conference on Distributed Computing in Sensor Systems (DCOSS), Ottawa, ON, Canada, 5 June 2017; pp. 121–129. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 779–788. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 580–587. [Google Scholar]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A low-shot transfer detector for object detection. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 5 February 2018. [Google Scholar]
- Hou, X.; Wang, Y.; Chau, L.-P. Vehicle Tracking Using Deep SORT with Low Confidence Track Filtering. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18 September 2019; pp. 1–6. [Google Scholar]
- Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Monitoring COVID-19 social distancing with person detection and tracking via fine-tuned YOLO v3 and Deepsort techniques. arXiv 2020, arXiv:2005.01385. [Google Scholar]
- Theagarajan, R.; Pala, F.; Zhang, X.; Bhanu, B. Soccer: Who has the ball? generating visual analytics and player statistics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1749–1757. [Google Scholar]
- Kurniawan, A.; Ramadlan, A.; Yuniarno, E. Speed Monitoring for Multiple Vehicle Using Closed Circuit Television (CCTV) Camera. In Proceedings of the 2018 International Conference on Computer Engineering, Network and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 26 November 2018; pp. 88–93. [Google Scholar]
- Chmielewska, A.; Marianna, P.; Marciniak, T.; Dabrowski, A.; Walkowiak, P. Application of the projective geometry in the density mapping based on CCTV monitoring. In Proceedings of the 2015 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 3 May 2015; pp. 179–184. [Google Scholar]
- Gonzalez-Sosa, E.; Vera-Rodriguez, R.; Fierrez, J.; Tome, P.; Ortega-Garcia, J. Pose variability compensation using projective transformation for forensic face recognition. In Proceedings of the 2015 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 9 September 2015; pp. 1–5. [Google Scholar]
- Miller, E.; Banerjee, N.; Zhu, T. Smart Homes that Detect Sneeze, Cough, and Face Touching. Smart Health 2020, 19, 100170. [Google Scholar] [CrossRef]
- Liang, S.H.; Saeedi, S.; Ojagh, S.; Honarparvar, S.; Kiaei, S.; Jahromi, M.M.; Squires, J. An Interoperable Architecture for the Internet of COVID-19 Things (IoCT) Using Open Geospatial Standards—Case Study: Workplace Reopening. Sensors 2021, 21, 50. [Google Scholar] [CrossRef]
- Maeda, K. Performance evaluation of object serialization libraries in XML, JSON and binary formats. In Proceedings of the 2012 Second International Conference on Digital Information and Communication Technology and It’s Applications (DICTAP), Bankok, Thailand, 16 May 2018; pp. 177–182. [Google Scholar]
- Yaghmazadeh, N.; Wang, X.; Dillig, I. Automated migration of hierarchical data to relational tables using programming-by-example. Proc. VLDB Endow. 2018, 11, 580–593. [Google Scholar] [CrossRef]
- Chasseur, C.; Li, Y.; Patel, J.M. Enabling JSON Document Stores in Relational Systems. In Proceedings of the WebDB, New York, NY, USA, 23 June 2013; pp. 14–15. [Google Scholar]
- Kotsev, A.; Schleidt, K.; Liang, S.; Van der Schaaf, H.; Khalafbeigi, T.; Grellet, S.; Lutz, M.; Jirka, S.; Beaufils, M. Extending INSPIRE to the Internet of Things through SensorThings API. Geosciences 2018, 8, 221. [Google Scholar] [CrossRef] [Green Version]
- Liang, S.; Huang, C.-Y.; Khalafbeigi, T. OGC SensorThings API Part 1: Sensing; Version 1.0; Open Geospatial Consortium: Wayland, MA, USA, 2016. [Google Scholar]
- Butler, H.; Daly, M.; Doyle, A.; Gillies, S.; Hagen, S.; Schaub, T. The Geojson Format; Internet Engineering Task Force (IETF): Wilmington, NC, USA, 2016. [Google Scholar]
- Horbiński, T.; Cybulski, P. Similarities of global web mapping services functionality in the context of responsive web design. Geod. Cartogr. 2018, 67, 159–177. [Google Scholar] [CrossRef] [Green Version]
- Horbiński, T.; Lorek, D. The use of Leaflet and GeoJSON files for creating the interactive web map of the preindustrial state of the natural environment. J. Spat. Sci. 2020. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 740–755. [Google Scholar]
- Mittal, A.; Zisserman, A.; Torr, P.H. Hand detection using multiple proposals. In Proceedings of the BMVC, Claverton, UK, 8 September 2020; p. 5. [Google Scholar]
- Bashiri, F.S.; LaRose, E.; Peissig, P.; Tafti, A.P. MCIndoor20000: A fully-labeled image dataset to advance indoor objects detection. Data Brief 2018, 17, 71–75. [Google Scholar] [CrossRef] [PubMed]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef] [Green Version]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and Tensorflow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 18 December 2020).
- Correia, I.; Fournier, F.; Skarbovsky, I. The uncertain case of credit card fraud detection. In Proceedings of the 9th ACM International Conference on Distributed Event-Based Systems, Barcelona, Spain, 3–7 July 1995; pp. 181–192. [Google Scholar]
- Adi, A.; Botzer, D.; Nechushtai, G.; Sharon, G. Complex event processing for financial services. In Proceedings of the 2006 IEEE Services Computing Workshops, Chicago, IL, USA, 18–22 September 2006; pp. 7–12. [Google Scholar]
- Cabanillas Macías, C.; Curik, A.; Di Ciccio, C.; Gutjahr, M.; Mendling, J.; Prescher, J.; Simecka, J. Combining Event Processing and Support Vector Machines for Automated Flight Diversion Predictions. In Proceedings of the 1st International Workshop on Modeling Inter-Organizational Processes and 1st International Workshop on Event Modeling and Processing in Business Process Management co-located with Modellierung, Vienna, Austria, 19 March 2014; pp. 45–47. [Google Scholar]
- Chen, C.Y.; Fu, J.H.; Sung, T.; Wang, P.-F.; Jou, E.; Feng, M.-W. Complex event processing for the internet of things and its applications. In Proceedings of the 2014 IEEE International Conference on Automation Science and Engineering (CASE), Taipei, Taiwan, 19 August 2014; pp. 1144–1149. [Google Scholar]
- Nielsen, S.; Chambers, C.; Farr, J. Systems and Methods for Complex Event Processing of Vehicle Information and Image Information Relating to a Vehicle. U.S. Patent No. 8,560,164, 15 October 2013. [Google Scholar]
- Bonino, D.; De Russis, L. Complex event processing for city officers: A filter and pipe visual approach. IEEE Int. Things J. 2017, 5, 775–783. [Google Scholar] [CrossRef]
- Peng, S.; He, J. Efficient Context-Aware Nested Complex Event Processing over RFID Streams. In Proceedings of the International Conference on Web-Age Information Management, Nanchang, China, 3 June 2016; pp. 125–136. [Google Scholar]
- Djedouboum, A.C.; Ari, A.; Adamou, A.; Gueroui, A.M.; Mohamadou, A.; Aliouat, Z. Big data collection in large-scale wireless sensor networks. Sensors 2018, 18, 4474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bruns, R.; Dunkel, J.; Masbruch, H.; Stipkovic, S. Intelligent M2M: Complex event processing for machine-to-machine communication. Expert Syst. Appl. 2015, 42, 1235–1246. [Google Scholar] [CrossRef]
- Ye, G.; Li, Y.; Xu, H.; Liu, D.; Chang, S.-F. Eventnet: A large scale structured concept library for complex event detection in video. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 471–480. [Google Scholar]
- Yadav, P.; Curry, E. VEKG: Video Event Knowledge Graph to Represent Video Streams for Complex Event Pattern Matching. In Proceedings of the 2019 First International Conference on Graph Computing (GC), Laguna Hills, CA, USA, 25–27 September 2019; pp. 13–20. [Google Scholar]
- Tawsif, K.; Hossen, J.; Raja, J.E.; Jesmeen, M.; Arif, E. A Review on Complex Event Processing Systems for Big Data. In Proceedings of the 2018 Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Kota Kinabalu, Indonesia, 26 March 2018; pp. 1–6. [Google Scholar]
- Saeedi, S.; Moussa, A.; El-Sheimy, N. Context-Aware Personal Navigation Using Embedded Sensor Fusion in Smartphones. Sensors 2014, 14, 5742–5767. [Google Scholar] [CrossRef] [PubMed]
- Ojagh, S.; Saeedi, S.; Liang, S.H.L. A Person-to-Person and Person-to-Place COVID-19 Contact Tracing System Based on OGC IndoorGML. ISPRS Int. J. Geo-Inf. 2021, 10, 2. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Spatial | Temporal |
|---|---|---|
| Relation | Direction-Based Spatial Relation (FORS) = (left,right,front,back) | SEQ → E1.t1 < E2.t2 where t1 < t2 |
| Relation | Topology-Based Spatial Relation = 9Intersection Matrix | EQ → E1.t1 = E2.t2 |
| Relation | Geometric Representation for Spatial Object (O) = e.g., Overlay Area of Bbox | CONJ → E1 and E2DISJ → E1 or E2 |
| VEQL Query Examples | SELECT intersection (Object1, Object2) FROM Camera1 WHERE Object1.label = ‘hand’ AND Object2.label = ‘door handle’ AND WITHIN TIMEFRAME_WINDOW(10) WITH_CONFIDENCE > 0.5 | SELECT SEQ (sr1, sr2) FROM Camera1 WHERE sr1.label = ‘coughing’ AND sr2.label = ‘door touching’ WITHIN TIMEFRAME_WINDOW(3600) WITH_CONFIDENCE > 0.5 |
| Model | Speed (Jetson Xavier) | Speed (Laptop) | Missing Objects | mAP | Average Recall |
|---|---|---|---|---|---|
| YOLOv3 | 4 (fps) | 25 (fps) | 23% | 59% | 34% |
| Mask-RCNN | 0.6 (fps) | 6 (fps) | 37% | 62% | 47% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Honarparvar, S.; Saeedi, S.; Liang, S.; Squires, J. Design and Development of an Internet of Smart Cameras Solution for Complex Event Detection in COVID-19 Risk Behaviour Recognition. ISPRS Int. J. Geo-Inf. 2021, 10, 81. https://doi.org/10.3390/ijgi10020081
Honarparvar S, Saeedi S, Liang S, Squires J. Design and Development of an Internet of Smart Cameras Solution for Complex Event Detection in COVID-19 Risk Behaviour Recognition. ISPRS International Journal of Geo-Information. 2021; 10(2):81. https://doi.org/10.3390/ijgi10020081
Chicago/Turabian StyleHonarparvar, Sepehr, Sara Saeedi, Steve Liang, and Jeremy Squires. 2021. "Design and Development of an Internet of Smart Cameras Solution for Complex Event Detection in COVID-19 Risk Behaviour Recognition" ISPRS International Journal of Geo-Information 10, no. 2: 81. https://doi.org/10.3390/ijgi10020081
APA StyleHonarparvar, S., Saeedi, S., Liang, S., & Squires, J. (2021). Design and Development of an Internet of Smart Cameras Solution for Complex Event Detection in COVID-19 Risk Behaviour Recognition. ISPRS International Journal of Geo-Information, 10(2), 81. https://doi.org/10.3390/ijgi10020081