
DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover



Abstract
:1. Introduction
2. Related Work
3. Proposed Method
3.1. Model Overview
3.2. Backbone
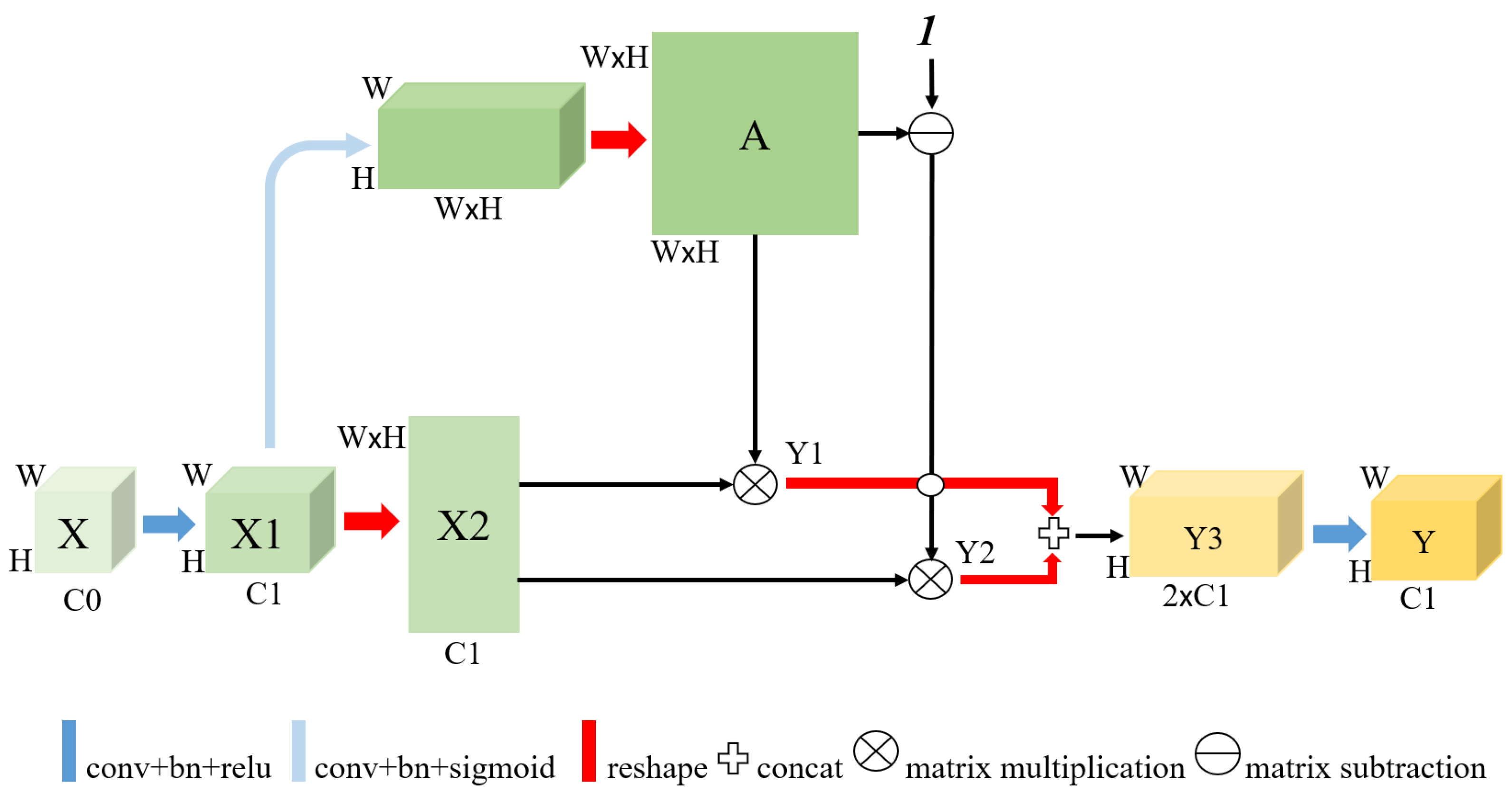
3.3. Affinity Matrix Module
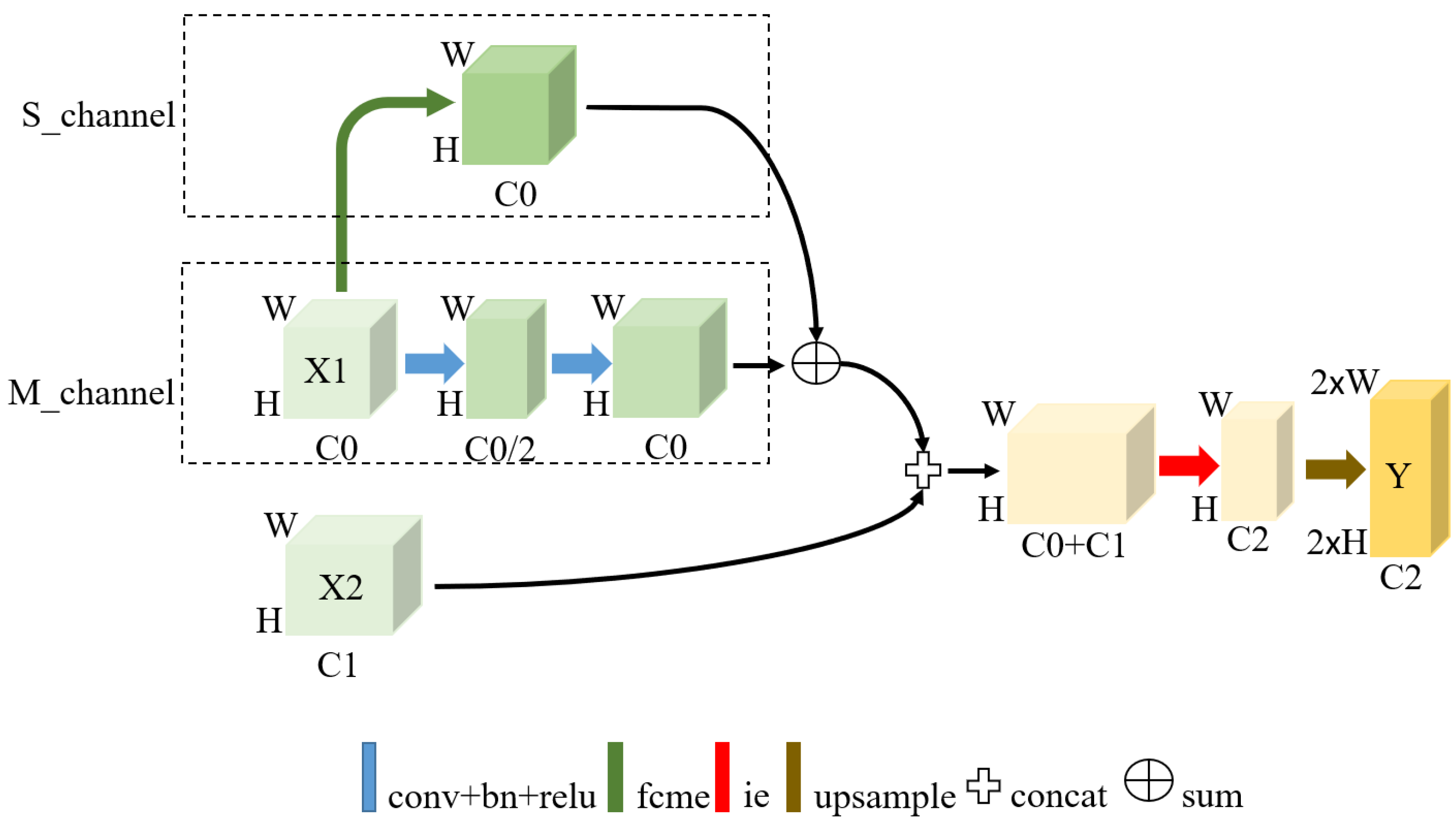
3.4. Boundary Feature Fusion Module
4. Experiment and Result Analysis
4.1. LandCover Dataset
4.2. Evaluation Metric
4.3. Experiment Setting and Training
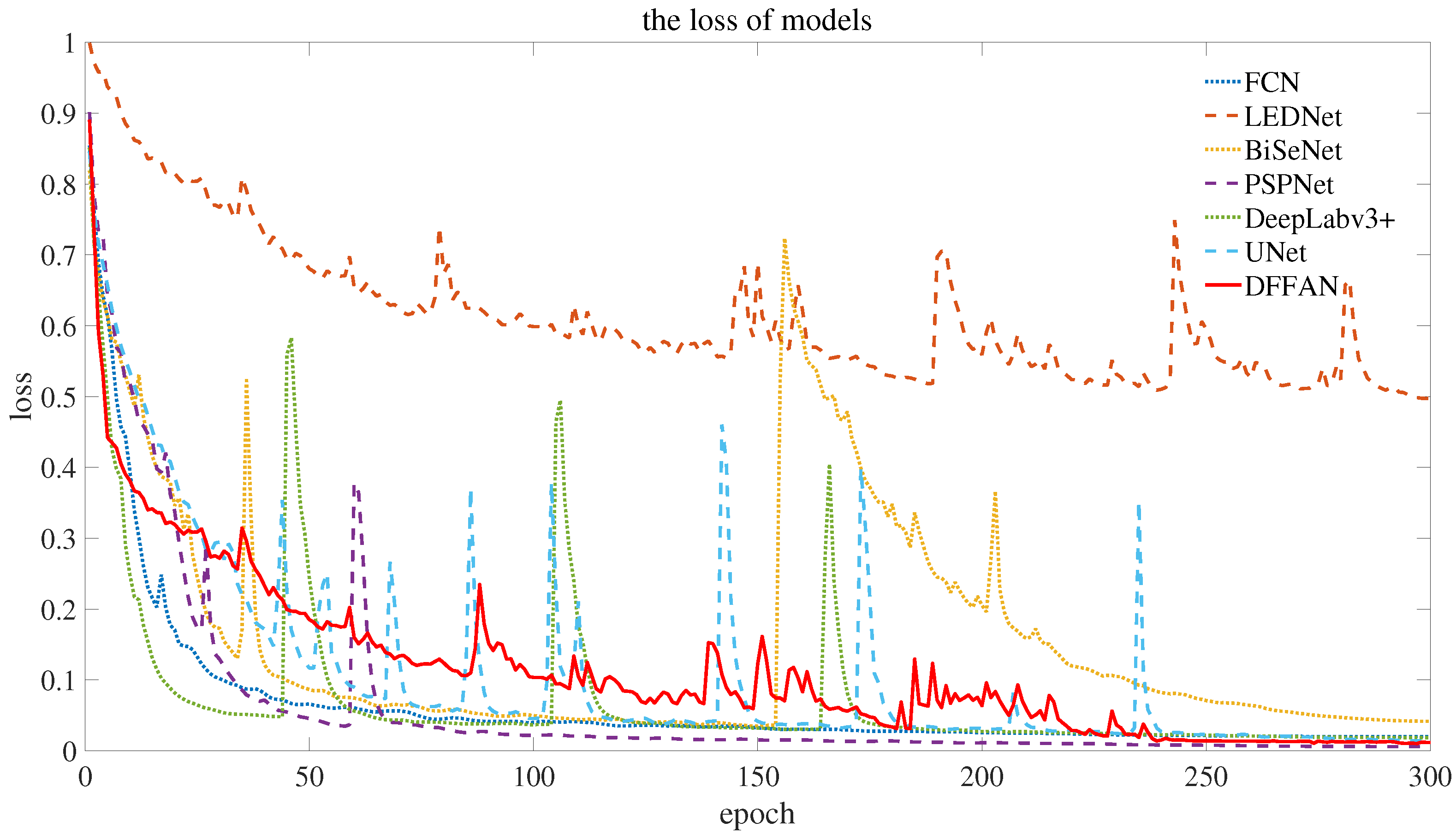
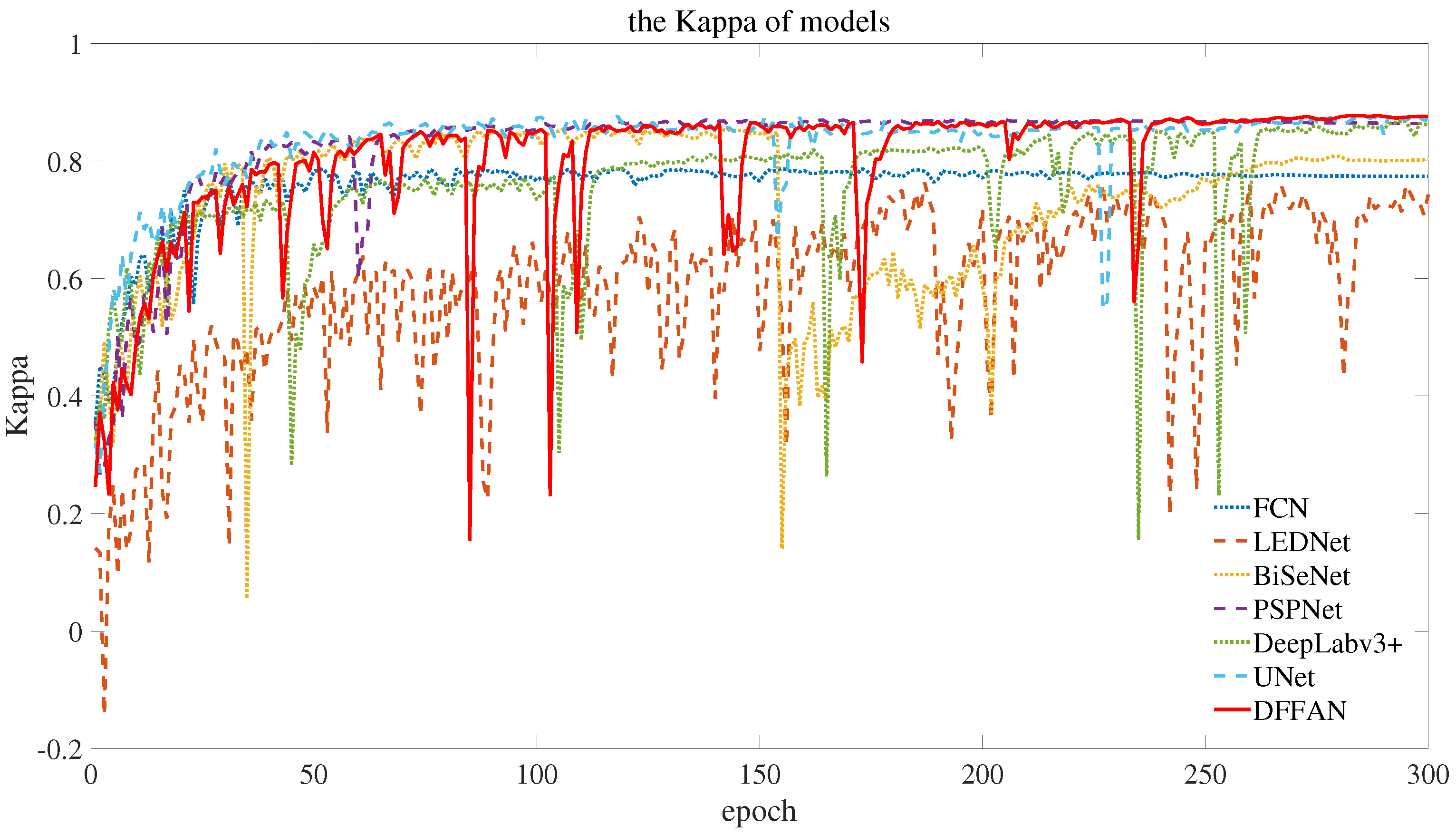
4.4. Result Analysis
4.5. Generalization Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| DFFAN | Dual Function Feature Aggregation Network |
| AMM | Affinity Matrix Module |
| BFF | Boundary Feature Fusion Module |
| RF | Random Forest |
| SVM | Support Vector Machine |
| FCN | Fully Convolutional Network |
| PSP | Pyramid Pooling |
| FCME | Feature Channels Maximum Element |
| IE | Information Extraction Function Module |
| CAM | Channel Attention Mechanism |
| MIoU | Mean Intersection over Union |
References
- Wulder, A.; Masek, G.; Cohen, B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Reza, K.; Giorgos, M.; Stephen, V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.; Arora, K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Samaniego, L.; Bardossy, A.; Schulz, K. Supervised Classification of Remotely Sensed Imagery Using a Modified k-NN Technique. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2112–2125. [Google Scholar] [CrossRef]
- Gislason, P.; Benediktsson, J.; Sveinsson, J. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Xia, M.; Zhang, X.; Liu, W.; Weng, L.; Xu, Y. Multi-stage Feature Constraints Learning for Age Estimation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Ahlawat, S.; Amit, C.; Anand, N.; Saurabh, S.; Byungun, Y. Improved handwritten digit recognition using convolutional neural networks (CNN). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Xiong, W.; Bai, Z. Human action recognition based on supervised class-specific dictionary learning with deep convolutional neural network features. Comput. Mater. Contin. 2020, 63, 243–262. [Google Scholar]
- Sezer, O.; Ozbayoglu, A. Financial trading model with stock bar chart image time series with deep convolutional neural networks. Intell. Autom. Soft Comput. 2020, 26, 323–334. [Google Scholar] [CrossRef]
- Qian, J.; Xia, M.; Zhang, Y.; Liu, J.; Xu, Y. TCDNet: Trilateral Change Detection Network for Google Earth Image. Remote Sens. 2020, 12, 2669. [Google Scholar] [CrossRef]
- Xia, M.; Tian, N.; Zhang, Y.; Xu, Y.; Zhang, X. Dilated Multi-scale Deep Forest for Satellite Cloud Image Detection. Int. J. Remote Sens. 2020, 41, 7779–7800. [Google Scholar] [CrossRef]
- Weng, L.; Xu, Y.; Xia, M.; Zhang, Y.; Liu, J.; Xu, Y. Wate-‘r Areas Segmentation from Remote Sensing Images Using a Separable Residual SegNet Network. Int. J. Geo-Inf. 2020, 9, 256. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Liu, J.; Xu, Y. DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attentionfeature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.; Wang, K.; Song, W.; Chen, C.; Li, Y. Non-intrusive load disaggregation based on composite deep long short-term memory network. Expert Syst. Appl. 2020, 160, 113669. [Google Scholar] [CrossRef]
- Lee, S.; Ahn, Y.; Kim, H. Predicting concrete compressive strength using deep convolutional neural network based on image characteristics. Comput. Mater. Contin. 2020, 65, 1–17. [Google Scholar] [CrossRef]
- Janarthanan, A.; Kumar, D. Localization based evolutionary routing (lober) for efficient aggregation in wireless multimedia sensor networks. Comput. Mater. Contin. 2019, 60, 895–912. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Li, J.; Peng, W.; Deng, A. A rub-impact recognition method based on improved convolutional neural network. Comput. Mater. Contin. 2020, 63, 283–299. [Google Scholar] [CrossRef]
- Fang, W.; Zhang, W.; Zhao, Q.; Ji, X.; Chen, W. Comprehensive analysis of secure data aggregation scheme for industrial wireless sensor network. Comput. Mater. Contin. 2019, 61, 583–599. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. Wiley Interdiplinary Rev. Data Min. Knowl. Discov. 2018, 12, e1264. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmenation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer Assisted lntervention(MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Gao, C.; Yu, G.; Shen, C.; Sang, N. Context Prior for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020. arXiv:2004.01547. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Huang, G.; Zhuang, L.; Laurens, M.; Weinberger, Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottleneck. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Diganta, M. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2020, arXiv:1908.0868110. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Zambrzycka, A.; Dziedzic, T. LandCover.ai: Dataset for Automatic Mapping of Buildings, Woodlands and Water from Aerial Imagery. arXiv 2020, arXiv:2005.02264. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R | G | B | |
|---|---|---|---|
| Void | 0 | 0 | 0 |
| Building | 128 | 0 | 0 |
| Woodland | 0 | 128 | 0 |
| Water | 0 | 0 | 128 |
| FCN | 0.8461 | 0.8032 | 0.7289 | 0.7865 |
| LEDNet | 0.843 | 0.7764 | 0.721 | 0.7613 |
| BiSeNet | 0.8757 | 0.8613 | 0.8028 | 0.8534 |
| PSPNet | 0.8907 | 0.8767 | 0.8284 | 0.8714 |
| DeepLabv3+ | 0.8938 | 0.8705 | 0.8337 | 0.8641 |
| UNet | 0.8788 | 0.8814 | 0.836 | 0.8755 |
| DFFAN | 0.9064 | 0.8921 | 0.8481 | 0.8872 |
| FCN | 0.8195 | 0.6955 | 0.6903 | 0.7171 |
| LEDNet | 0.8104 | 0.6823 | 0.6787 | 0.7039 |
| BiSeNet | 0.8584 | 0.7526 | 0.7493 | 0.7785 |
| PSPNet | 0.8595 | 0.7543 | 0.7524 | 0.78 |
| DeepLabv3+ | 0.8668 | 0.7654 | 0.7621 | 0.791 |
| UNet | 0.8519 | 0.7429 | 0.7371 | 0.7673 |
| DFFAN | 0.8672 | 0.7661 | 0.763 | 0.7915 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Weng, L.; Chen, B.; Xia, M. DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover. ISPRS Int. J. Geo-Inf. 2021, 10, 125. https://doi.org/10.3390/ijgi10030125
Huang J, Weng L, Chen B, Xia M. DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover. ISPRS International Journal of Geo-Information. 2021; 10(3):125. https://doi.org/10.3390/ijgi10030125
Chicago/Turabian StyleHuang, Junqing, Liguo Weng, Bingyu Chen, and Min Xia. 2021. "DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover" ISPRS International Journal of Geo-Information 10, no. 3: 125. https://doi.org/10.3390/ijgi10030125
APA StyleHuang, J., Weng, L., Chen, B., & Xia, M. (2021). DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover. ISPRS International Journal of Geo-Information, 10(3), 125. https://doi.org/10.3390/ijgi10030125