
Multiscale Spatial Polygonal Object Granularity Factor Matching Method Based on BPNN



Abstract
:1. Introduction
2. Methodology
2.1. MSPOM Similarity Evaluation Indices Combined with Minimum Bounding Rectangle (MBR)
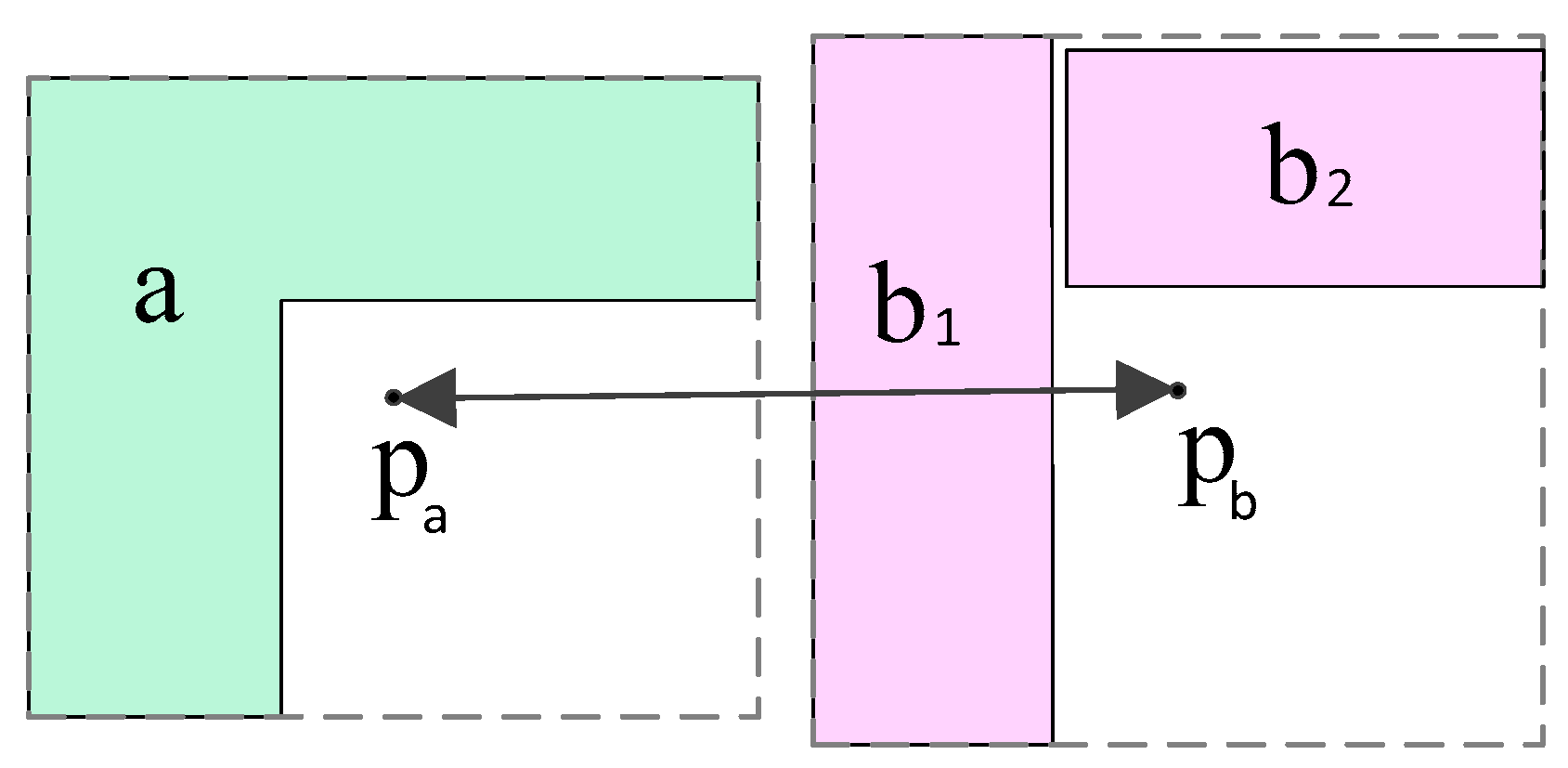
2.1.1. Distance Similarity
2.1.2. Overlap Rate of Area
2.1.3. Direction Similarity
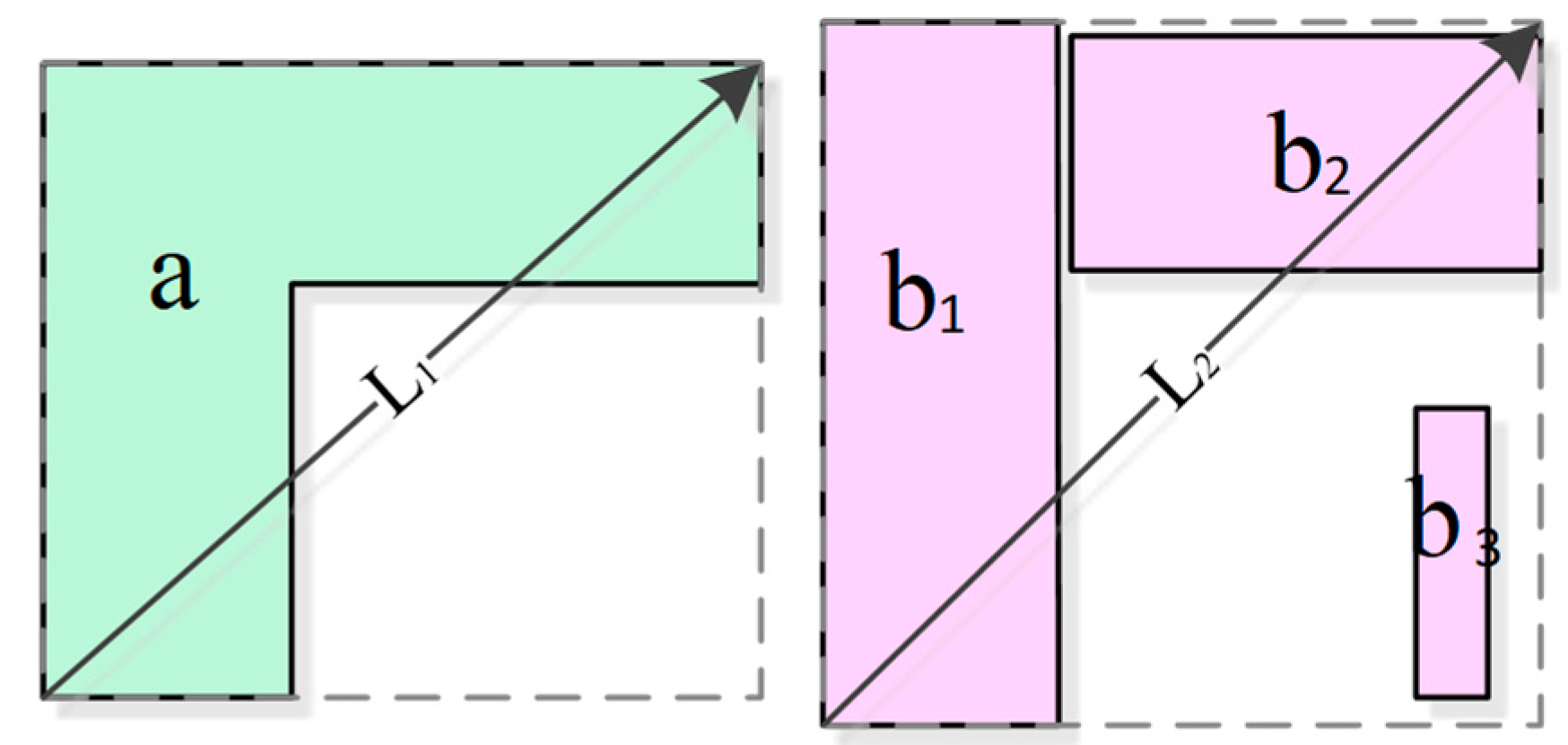
2.1.4. Shape Similarity
2.2. Granularity Factor Evaluation Index (GFEI)
2.3. Matching Model Based on BPNN (BPM)
- When , the matching result is “match”; furthermore, the closer the value of is to 1 or the value of is to 0, the more similar the matching pair.
- When , the matching result is “does not match”; furthermore, the closer the value of is to 0 or the value of is to 1, the more dissimilar the matching pair.
2.4. Matching Workflow
- Step 1: In the preparation stage, the data are preprocessed, which includes format conversion, topology checking, and geometric coordinate transformation. The purpose of preprocessing is to resolve systematic errors between data from different sources [47].
- Step 2: The matching stage is the focus of this study, which includes BPM training, first-matching, and last-matching. Model training is performed to acquire the geometric features and matching results of the training data. In first-matching, 1:1 and 1:N candidate matching pairs are detected using the MBR combinatorial optimization [48] (MBRCO) algorithm. MBRCO uses the objects’ MBR to replace them so as to find their candidate matching objects, and adopts the combination threshold to avoid the excessive calculation of the exhaustive method, which can quickly and effectively screen the candidate matching pairs. Then, 1:1 and 1:N correspondences are obtained using the trained BPM. In final matching, spatial districts (SDs) are divided based on Delaunay triangulation, in which the remaining unmatched objects (M:N and 1:0) are distributed. The M:N candidate matching pairs are detected using the MBRCO algorithm and the M:N correspondences are obtained using the trained BPM. The remaining unmatched objects are 1:0 correspondences.
- Step 3: In the evaluation stage, we evaluate the matching results by comparing them with the results of manual inspection.
3. Experiments and Discussion
3.1. GFEI Index Analysis
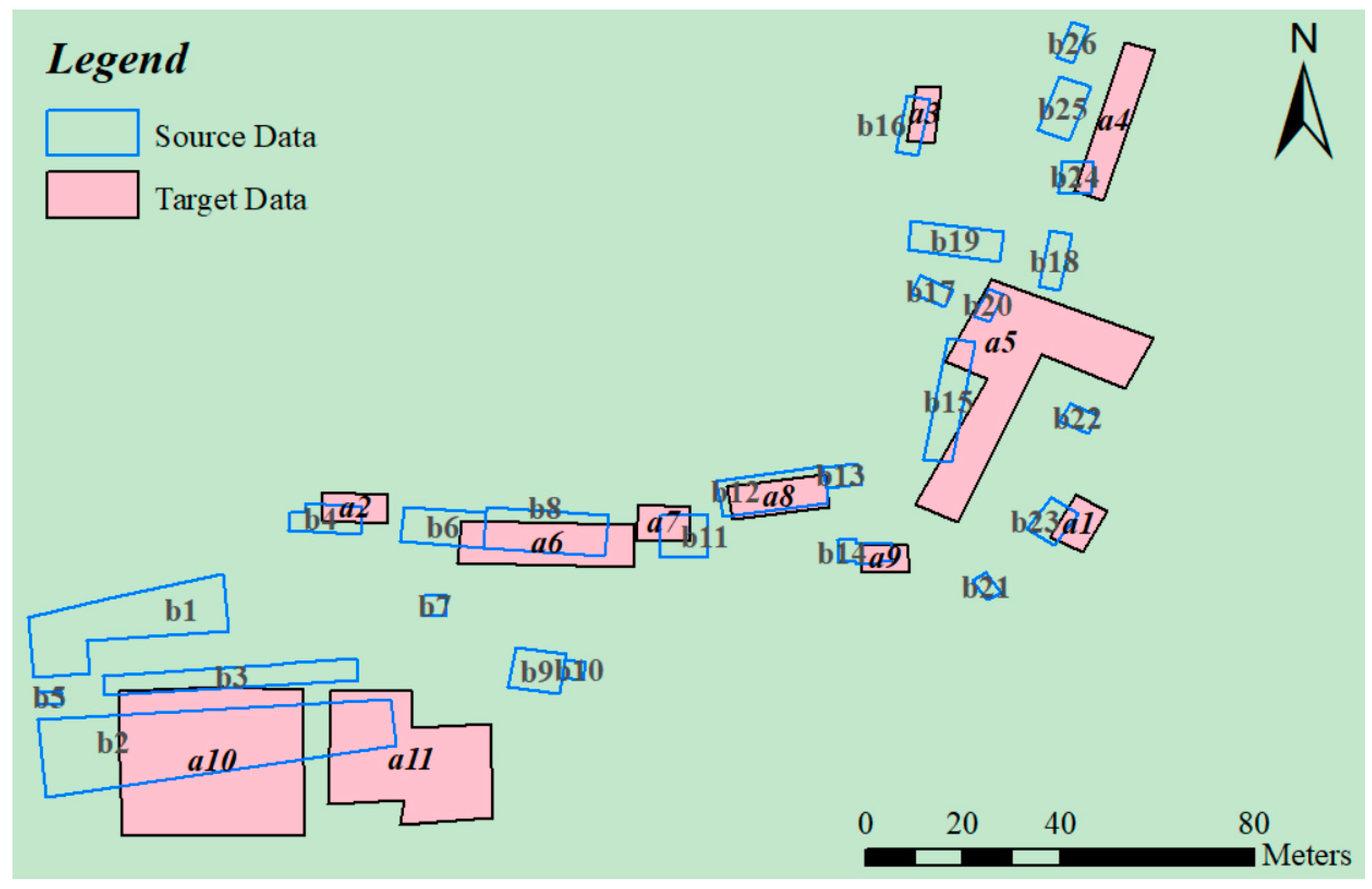
3.2. Experimental Data
3.3. Model Training
3.3.1. Sample Selection
3.3.2. Models and Parameters
- BPM: We established a three-layer BPNN structure. The activation function was a logistic function, number of nodes in the hidden layer was 9, momentum factor was 0.9, learning efficiency was 0.01, and maximum number of iterations was 1000.
- MLRM: The confidence interval of parameter estimation was 95%, maximum number of iterations was 1000, convergence value of parameters was , and singularity tolerance was .
- SRM: The random number state was 1, kernel function was the radial basis function, and gamma value was 20.
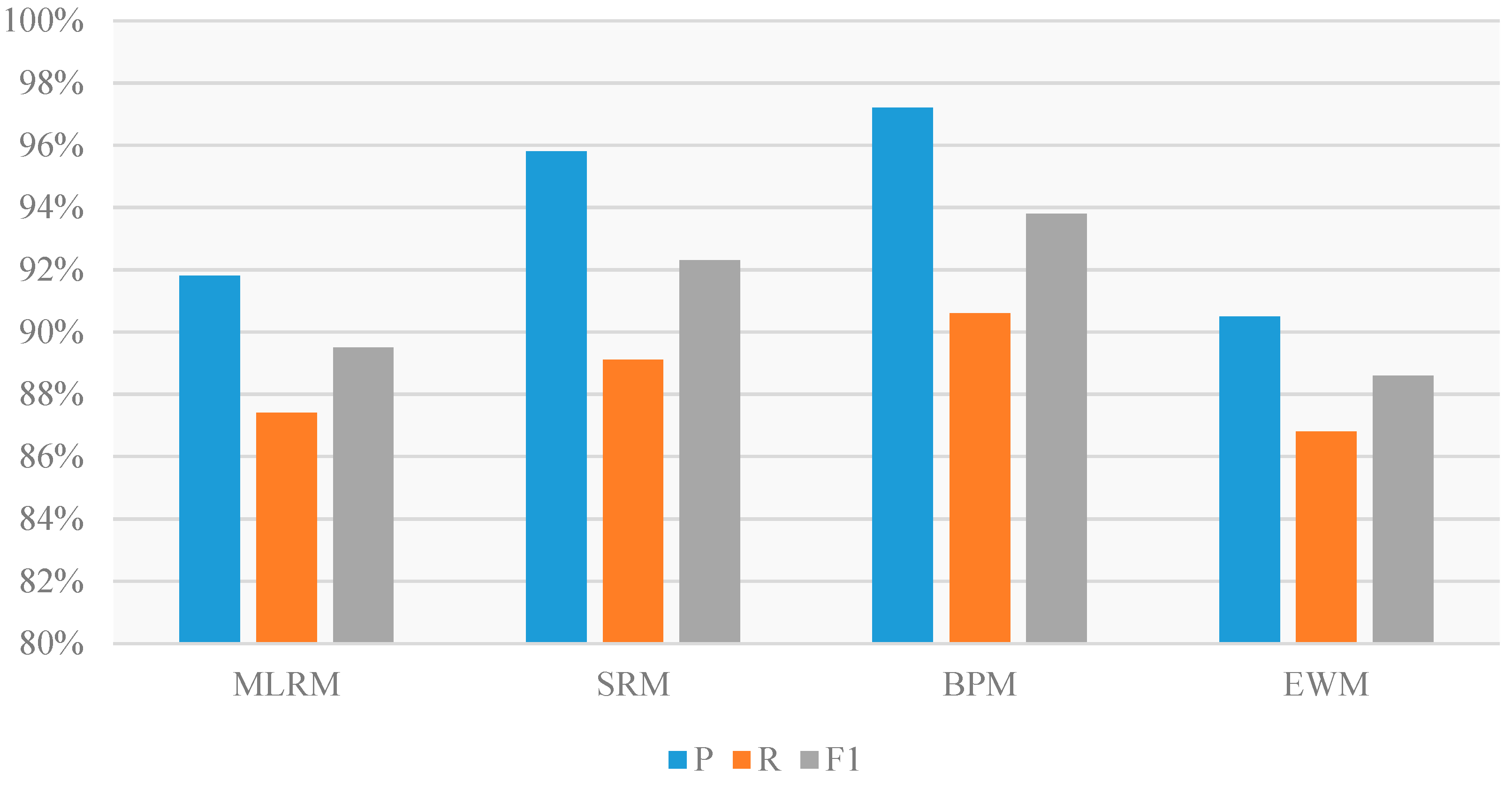
3.4. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, L.; Goodchild, M.F. Automatically and accurately matching objects in geospatial datasets. Adv. Geo Spat. Inf. Sci. 2012, 10, 71–79. [Google Scholar]
- Saalfeld, A. Automated Map Conflation; University of Maryland: College Park, MD, USA, 1993. [Google Scholar]
- Xavier, E.M.; Ariza-López, F.J.; Ureña-Cámara, M.A. A survey of measures and methods for matching geospatial vector datasets. ACM Comput. Surv. 2016, 49. [Google Scholar] [CrossRef]
- Kim, J.O.; Yu, K.; Heo, J.; Lee, W.H. A new method for matching objects in two different geospatial datasets based on the geographic context. Comput. Geosci. 2010, 36, 1115–1122. [Google Scholar] [CrossRef]
- Ruiz, J.J.; Ariza, F.J.; Ureña, M.A.; Blázquez, E.B. Digital map conflation: A review of the process and a proposal for classification. Int. J. Geogr. Inf. Sci. 2011, 25, 1439–1466. [Google Scholar] [CrossRef]
- Girres, J.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Bisheng, Y.; Yunfei, Z.; Xuechen, L. A probabilistic relaxation approach for matching road networks. Int. J. Geogr. Inf. Sci. 2013, 27, 319–338. [Google Scholar]
- Devogele, T. On spatial database integration. Int. J. Geogr. Inf. Syst. 1998, 12, 335–352. [Google Scholar] [CrossRef]
- Walter, V.; Fritsch, D. Matching spatial data sets: A statistical approach. Int. J. Geogr. Inf. Sci. 1999, 13, 445–473. [Google Scholar] [CrossRef]
- Hampe, M.; Sester, M.; Harrie, L. Multiple representation databases to support visualisation on mobile devices. ISPRS J. Photogramm. Remote Sens. 2004, 35, 135–140. [Google Scholar]
- Rauschenbach, U.; Jeschke, S.; Schumann, H. General rectangular fisheye views for 2D graphics. Comput. Graph. 2001, 25, 609–617. [Google Scholar] [CrossRef]
- Ying, S.; Li, L.; Gao, Y.R.; Min, Y. Probabilistic matching of map objects in multi-scale space. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011. [Google Scholar]
- Zhang, X.; Ai, T.; Stoter, J.; Zhao, X. Data matching of building polygons at multiple map scales improved by contextual information and relaxation. ISPRS J. Photogramm. Remote. Sens. 2014, 92, 147–163. [Google Scholar] [CrossRef]
- Taylor, E.G.; Hummel, J.E. Finding similarity in a model of relational reasoning. Cog. Sys. Res. 2009, 10, 229–239. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Chen, Z.; Wu, L. Shape similarity measurement model for holed polygons based on position graphs and Fourier descriptors. Int. J. Geogr. Inf. Sci. 2016, 31, 253–279. [Google Scholar] [CrossRef]
- Tong, X.; Shi, W. A probability-based multi-measure feature matching method in map conflation. Int. J. Remote Sens. 2009, 30, 5453–5472. [Google Scholar] [CrossRef]
- Fan, H.; Yang, B.; Zipf, A.; Rousell, A. A polygon-based approach for matching OpenStreetMap road networks with regional transit authority data. Int. J. Geogr. Inf. Sci. 2015, 30, 748–764. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, X.; Molenaar, M.; Stoter, J.; Kraak, M.; Ai, T. Pattern classification approaches to matching building polygons at multiple scales. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2012, 19–24. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-lendinez, J.J.; Ariza-lopez, F.J.; Ureña-cámara, M.A. Automatic positional accuracy assessment of geospatial databases using line-based methods. Surv. Rev. 2013, 45, 332–342. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, D.; Zhao, Z.; Ren, F.; Du, Q. A back-propagation neural network-based approach for multi-represented feature matching in update propagation. Trans. GIS 2015, 19, 964–993. [Google Scholar] [CrossRef]
- Deng, M.; Li, Z.L.; Chen, X.Y. Extended Hausdorff distance for spatial objects in GIS. Int. J. Geogr. Inf. Sci. 2007, 21, 459–475. [Google Scholar]
- Tong, X.; Liang, D.; Jin, Y. A linear road object matching method for conflation based on optimization and logistic regression. Int. J. Geogr. Inf. Sci. 2014, 28, 824–846. [Google Scholar] [CrossRef]
- Revell, P.; Antoine, B. Automated matching of building feature of differing levels of detail: A case study. In Proceedings of the 24th International Cartographic Conference, Santiago, Chile, 15–21 November 2009. [Google Scholar]
- Qi, H.B.; Li, Z.L.; Chen, J. Automated change detection for updating settlements at smaller-scale maps from updated larger-scale maps. J. Spatial Sci. 2010, 55, 133–146. [Google Scholar] [CrossRef]
- Winter, S. Location similarity of regions. ISPRS J. Photogramm. Remote Sens. 2000, 55, 189–200. [Google Scholar] [CrossRef]
- Gösseln, G.; Sester, M. Change detection and integration of topographic updates from ATKIS and geoscientific data sets. In Proceedings of the International Conference Next Generation Geospatial Infrastructure, Boston, MA, USA, 19–21 October 2003 . [Google Scholar]
- Wang, H.; Tang, X.; Qiu, B.; Wang, W. Geometric matching method of area feature based on multi-weighted operators. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 1671–8860. [Google Scholar]
- Ai, T.; Cheng, X.; Liu, P.; Yang, M. A shape analysis and template matching of building features by the Fourier transform method. Comput. Environ. Urban Syst. 2013, 41, 219–233. [Google Scholar] [CrossRef]
- Deng, M.; Li, Z. A statistical model for directional relations between spatial objects. Geoinformatica 2008, 12, 193–217. [Google Scholar] [CrossRef]
- Luo, G.; Zhang, X.; Qi, L.; Guo, T. The fast positioning and optimal combination matching method of change vector object. Acta Geod. Cartogr. Sin. 2014, 43, 1285–1292. [Google Scholar]
- Huh, Y.; Kim, J.; Lee, J.; Yu, K.; Shi, W. Identification of multi-scale corresponding object-set pairs between two polygon datasets with hierarchical co-clustering. ISPRS J. Photogramm. Remote Sens. 2014, 88, 60–68. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1993. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; Chapman and Hall: New York, NY, USA, 1984. [Google Scholar]
- Rish, I. Empirical study of the naive Bayes classifier. In The IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence; IBM: New York, NY, USA, 2001; pp. 41–46. [Google Scholar]
- Hsu, C.-W.; Lin, C.-J. Comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McKenzie, G.; Janowicz, K.; Adams, B. A weighted multi-attribute method for matching user-generated points of interest. Cartogr. Geogr. Inf. Sci. 2014, 41, 125–137. [Google Scholar] [CrossRef]
- Juan, R.-L.; Manuel, U.-C.; Francisco, A.-L. Polygon and point-based approach to matching geospatial features. ISPRS Int. J. Geoinf. 2017, 6, 399. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B.; Lee, S.; Buchroithner, M.F. A GIS-based back-propagation neural network model and its cross-application and validation for landslide susceptibility analyses. Comput. Environ. Urban Syst. 2010, 34, 216–235. [Google Scholar] [CrossRef]
- Cobb, M.A.; Petry, F.E.; Shaw, K.B. Fuzzy spatial relationship refinements based on minimum bounding rectangle variations. Fuzzy Sets Syst. 2000, 113, 111–120. [Google Scholar] [CrossRef]
- Hobbs, J.R. Granularity. In Readings in Qualitative Reasoning about Physical Systems; Weld, D.S., Kleer, J.D., Eds.; Morgan Kaufmann: San Mateo, CA, USA, 1990; pp. 542–545. [Google Scholar]
- Stell, J.; Worboys, M. Stratified map spaces: A formal basis for multi-resolution spatial databases. Int. Symp. Spat. Data Handl. 1998, 180–189. [Google Scholar]
- Deng, M.; Li, Z.; Cheng, T. Rough-set representation of GIS data uncertainties with multiple granularities. Acta Geod. Cartogr. Sin. 2006, 35, 64–70. [Google Scholar]
- Bin, J. Head/tail breaks: A new classification scheme for data with a heavy-tailed distribution. Prof. Geogr. 2012, 65, 482–494. [Google Scholar]
- Cracknell, M.J.; Reading, A.M. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhao, P.; Qin, D.; Li, G.; Chen, Z.; Zhang, Y. Driving intention identification based on long short-term memory and a case study in shifting strategy optimization. IEEE Access 2019, 7, 128593–128605. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, Z.; Zhang, C.; Dong, F.; Wei, P. Numerical investigation of the dynamic responses of long-span bridges with consideration of the random traffic flow based on the intelligent ACO-BPNN model. IEEE Access 2018, 6, 28520–28529. [Google Scholar] [CrossRef]
- Doytsher, Y. A rubber sheeting algorithm for non-rectangular maps. Comput. Geosci. 2000, 26, 1001–1010. [Google Scholar] [CrossRef]
- Liu, L.; Zhu, D.; Zhu, X.; Ding, X.; Guo, W. A multi-scale polygonal object matching method based on MBR combinatorial optimization algorithm. Acta Geod. Cartogr. Sin. 2018, 47, 652–662. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Matching Type | Matching Pair | ||||||
|---|---|---|---|---|---|---|---|
| 1:1 | 0.745 | 0.859 | 0.973 | 0.742 | 0.830 | Match | |
| 0.709 | 0.909 | 0.971 | 0.882 | 0.868 | Match | ||
| 0.805 | 0.922 | 0.998 | 0.943 | 0.917 | Match | ||
| 0.721 | 0.865 | 0.922 | 0.778 | 0.822 | Match | ||
| 0.940 | 0.903 | 0.992 | 0.813 | 0.912 | Match | ||
| 0.739 | 0.848 | 0.943 | 0.803 | 0.833 | Match | ||
| 1:N | 0.779 | 0.496 | 0.902 | 0.643 | 0.705 | Not recognized | |
| 0.811 | 0.359 | 0.885 | 0.684 | 0.685 | Not recognized | ||
| 0.822 | 0.874 | 0.988 | 0.784 | 0.867 | Match | ||
| M:N | 0.776 | 0.598 | 0.890 | 0.646 | 0.726 | Not recognized |
| Matching Type | Matching Pair | ||||||
|---|---|---|---|---|---|---|---|
| 1:1 | 1 | 1.8 | 1.249 | 0.113 | 0.75 | 0.790 | |
| 1 | 0.113 | 0.75 | 0.809 | ||||
| 1 | 0.113 | 0.75 | 0.833 | ||||
| 1 | 0.113 | 0.75 | 0.786 | ||||
| 1 | 0.113 | 0.75 | 0.831 | ||||
| 1 | 0.113 | 0.75 | 0.792 | ||||
| 1:N | 3 | 0.091 | 0.86 | 0.783 | |||
| 5 | 0.063 | 1 | 0.842 | ||||
| 2 | 0.108 | 0.775 | 0.821 | ||||
| M:N | 2 | 0.108 | 0.775 | 0.751 |
| Place | Zhoushan, China | |
| Area | ||
| Scale | 1:2000 | 1:10,000 |
| Production time | 2012 | 2009 |
| No. of polygons | 6774 | 778 |
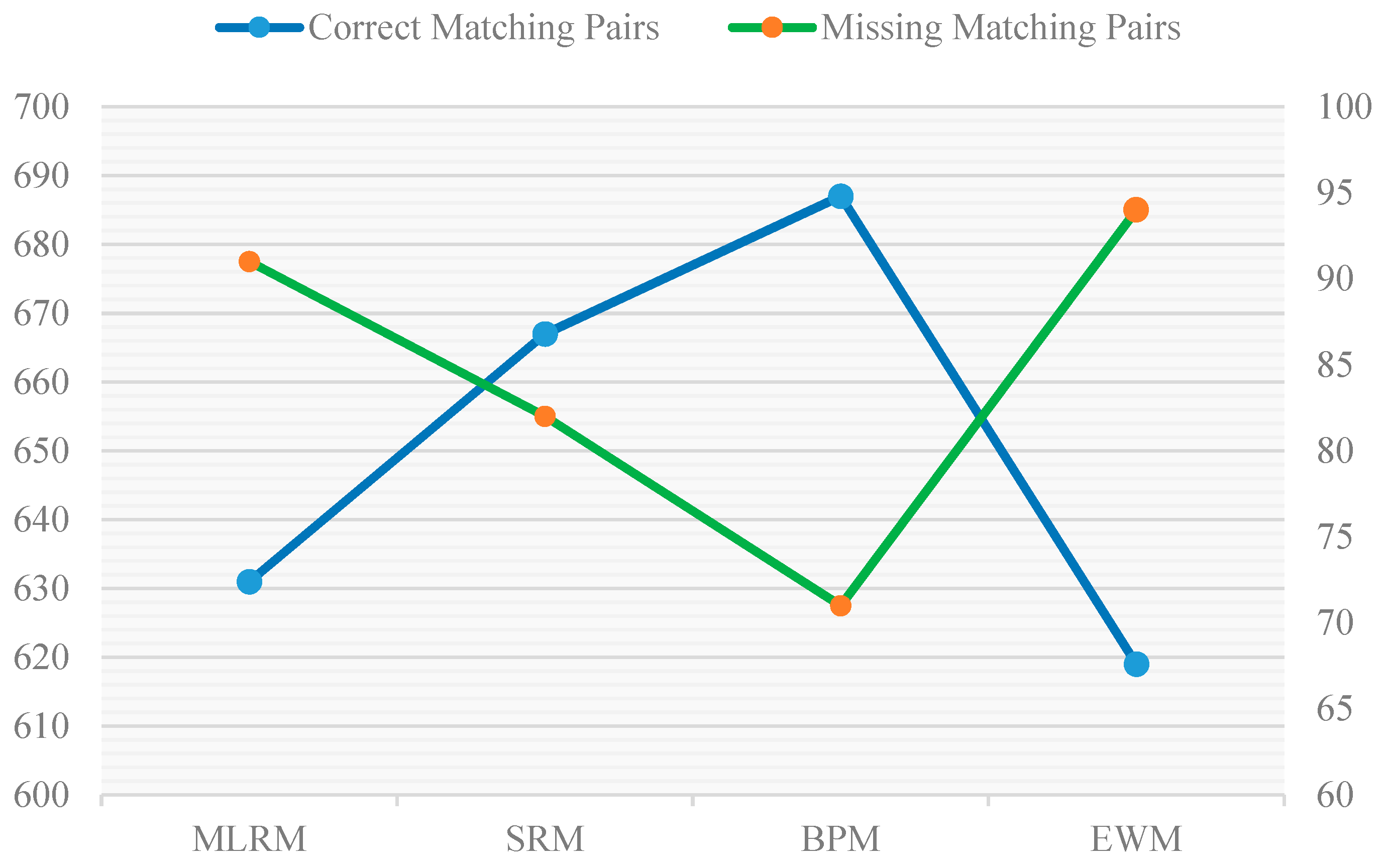
| Models | TP | FP | AM | FN | P | R | |
|---|---|---|---|---|---|---|---|
| MLRM | 631 | 42 | 14 | 91 | 91.8% | 87.4% | 89.5% |
| 81.1% | 5.4% | 1.8% | 11.7% | ||||
| SRM | 667 | 15 | 14 | 82 | 95.8% | 89.1% | 92.3% |
| 85.7% | 1.9% | 1.8% | 10.5% | ||||
| BPM | 687 | 6 | 14 | 71 | 97.2% | 90.6% | 93.8% |
| 88.3% | 0.8% | 1.8% | 9.1% | ||||
| EWM | 619 | 51 | 14 | 94 | 90.5% | 86.8% | 88.6% |
| 79.6% | 6.6% | 1.8% | 12.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Cheng, C.; Zhai, W.; Li, Y.; Li, S.; Chen, B. Multiscale Spatial Polygonal Object Granularity Factor Matching Method Based on BPNN. ISPRS Int. J. Geo-Inf. 2021, 10, 75. https://doi.org/10.3390/ijgi10020075
Zhu D, Cheng C, Zhai W, Li Y, Li S, Chen B. Multiscale Spatial Polygonal Object Granularity Factor Matching Method Based on BPNN. ISPRS International Journal of Geo-Information. 2021; 10(2):75. https://doi.org/10.3390/ijgi10020075
Chicago/Turabian StyleZhu, Daoye, Chengqi Cheng, Weixin Zhai, Yihang Li, Shizhong Li, and Bo Chen. 2021. "Multiscale Spatial Polygonal Object Granularity Factor Matching Method Based on BPNN" ISPRS International Journal of Geo-Information 10, no. 2: 75. https://doi.org/10.3390/ijgi10020075
APA StyleZhu, D., Cheng, C., Zhai, W., Li, Y., Li, S., & Chen, B. (2021). Multiscale Spatial Polygonal Object Granularity Factor Matching Method Based on BPNN. ISPRS International Journal of Geo-Information, 10(2), 75. https://doi.org/10.3390/ijgi10020075