2.2. Detection of Tree-Like Structures via Pointwise Classification on Non-Ground Points
As a significant requirement of urban tree inventory, labeling input data with the category of tree is fundamental in exploiting the informative values for the instance segmentation of trees. The problem has been extensively researched. Some unified approaches combine handcrafted features in a heuristic manner but fails to capture high-level semantic structures. The segmented points generated by deep-learning methods are often corrupted with noise and outliers due to the unorganized distribution and uneven point density, which are inevitable in complex urban environments. It is a challenge to effectively and automatically recognize individual trees in environmentally complex urban regions from such data. To solve this problem, we revise an existing deep-learning architecture to directly process unstructured point clouds and implement a point-wise semantic learning network.
PointNet has revolutionized how we think about processing point clouds as it offers a learnable structured representation for 3D semantic segmentation tasks. However, the local features of point clouds cannot be effectively robustly learned, limiting its ability to recognize the object of interest in complex scenes. The proposed architecture is similar to PointNet with a few small modifications, i.e., features are computed from local regions instead of the entire point cloud, which makes the estimation of local information more accurate. We propose an improved 3D semantic segmentation network based on pointwise KNN (k-th nearest neighbor) search method, which has unique advantage that extract multi-level features. The proposed network takes local features of a query point from local region composed of neighbors set as its new features and establishes connections between multiple layers by adding skip connections to strengthen the learning ability of local features.
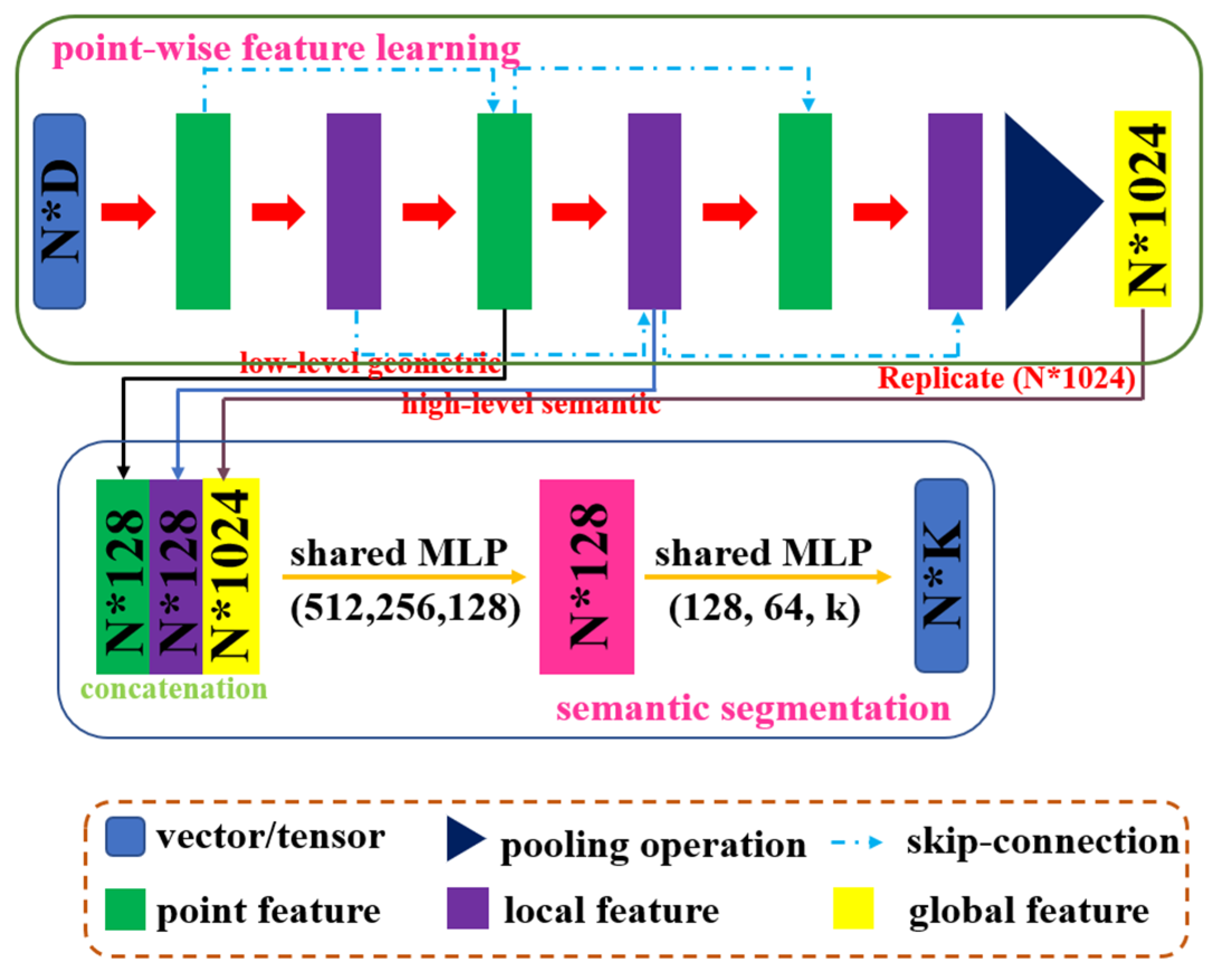
In this section, we further present the theoretical and logical principles of the proposed network for urban object segmentation from non-ground points of ALS data in details. Considering that the descriptiveness of differences between points from low-dimensional initial features is far from satisfactory and the richness of point features is good for local feature extraction, we first enhance the discriminability of point features and then obtain local information in the new feature space. The proposed network mainly contains two modules: (1) implementing optimized PointNet by KNN, which is used to extract more powerful local information in the high-dimensional feature space; (2) semantically segmenting large-scale point cloud using the global and local features. The architecture of the proposed method is summarized in
Figure 3.
Our detailed and complete feature learning network is illustrated in
Figure 3, the green part, which consists of two key modules: sub-module of point feature extraction based on PointNet and sub-module of local feature extraction in the high-dimensional feature space.
2.2.1. Sub-Module of Point Feature Extraction
The module is designed to obtain richer point cloud high-dimensional features by using feature extraction operations many times. For the whole pipeline, we directly use simplified PointNet as our backbone network. Our network takes a point cloud of size
as input, then encodes it into a
shaped matrix using the shared Multi-Layer Perceptron (MLP) [
29]. After max pooling, the dimension of the global feature of point cloud is 128. Finally, the global features are duplicated
N times and concatenates point feature into a feature vector. This vector is then input into the MLP to obtain a novel
shaped feature vector, which is fed into the following module to acquire the local attributes.
In general, the feature learning network mainly uses three sub-modules of point feature extraction with the same principle. In other words, we perform three repeated feature extractions. We pass and fuse the features of different layers through the connection, for extracting and fusing richer high-level features. The feature learning network illustrated in
Figure 4 is composes with two components including a simplified PointNet and connection channels.
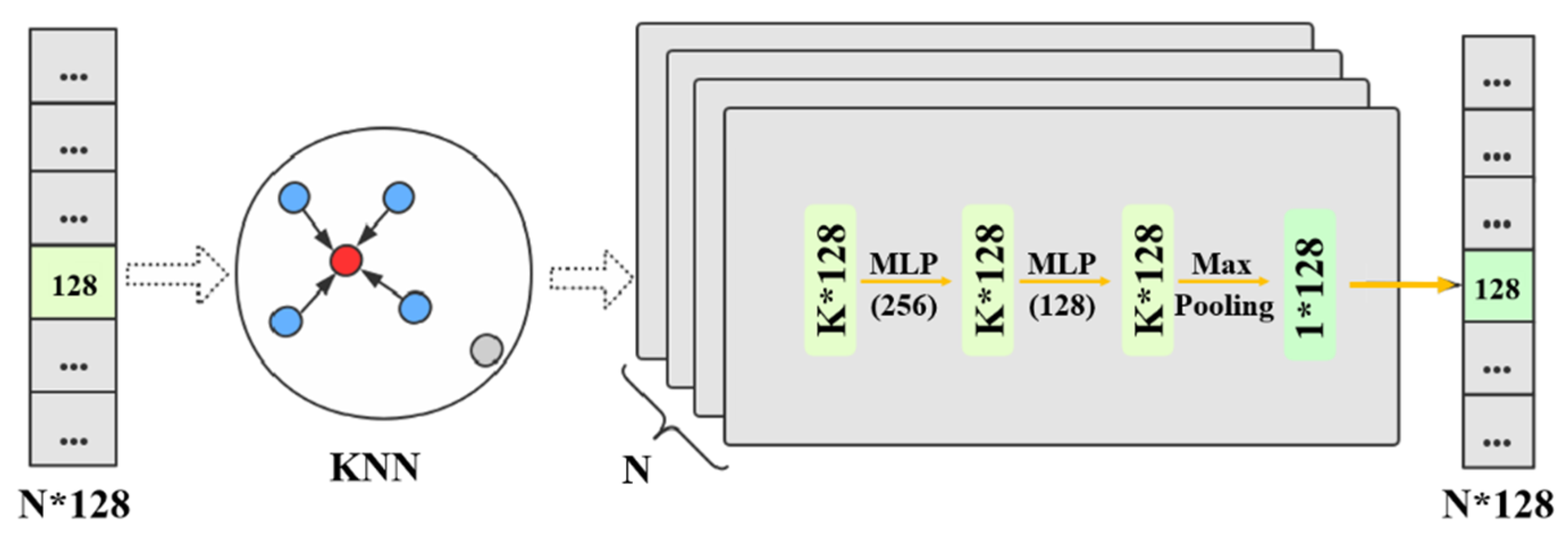
2.2.2. Sub-Module of Local Feature Extraction
The features of points belonging to the same semantic category are similar, this module aims to reduce the feature distance between similar points and increase the discriminability of different point clouds. The output from the above module forms a
tensor with low-level information. To get sufficient expressive power to transform each point feature into a higher-dimensional feature, a fully connected layer is added to the KNN module. We first transform the original points
to a canonical pose by a STN (spatial transformer network) [
51], and then search for the
K nearest neighbors on the spatially invariant points
for each query point
. The point-to-point set KNN search is defined as follows:
where
represents the
k-th nearest neighbor of the query point
.
In the feature space of the input data, we search for K neighboring points with the smallest feature distance from the query point. The pseudocode of the KNN module, which shows the details of the feature space search algorithm based on KNN, is presented in
Appendix A.
The feature learning network contains three local feature extraction sub-modules with identical structures. At a certain level, each module is a process of point cloud features learning within the local neighborhood. Therefore, this paper completes the task of learning within the multi-levels local neighborhoods by repeatedly applying sub-module of local feature extraction three times. The detailed processing of this module is shown in
Figure 5. The local feature extraction module based on feature space extracts local features at one level. By applying this module multiple times, the receptive field of operation can be expanded, it is equivalent to extracting multiple local features at different levels, which is beneficial to extract more and richer point cloud features.
2.2.3. Semantic Segmentation Module and Loss Function
The semantic segmentation component concatenates the three output vectors (low-level point feature vector, high-level local feature vector, and global feature vector) into a 1280-dimensional feature vector. This vector is gradually reduced in dimensionality by directly using MLP and then fed into the Softmax layers to acquire the final segmentation result, which consists of N × M scores for each of the N points and each of the M semantic categories.
To minimize model errors during training, the loss function
of our network consists of semantic segmentation loss
and contrastive loss
:
where
is defined with the classical and off-the-shelf softmax cross entropy loss function, which is formulated as follows:
where
denotes the one-hot label of
i-th training sample,
N denotes the batch size, and
is the softmax prediction score vector.
As for the contrastive loss, it is expressed by a discriminative function based on the assumption that the features of points belonging to the same semantic category are similar. Feature distance and point labels are metrics to measure the dissimilarity between two points. Therefore, in the training process, the proposed network minimizes the feature similarity difference between the points of the same label, and expands the feature difference between two points belonging to different object labels in the feature space. Specifically, the contrastive loss function is defined as follows:
where
d represents the Euclidean distance of two points feature,
N is the number of points, and margin is a preset threshold, which is a metric to measure the discrimination between two points.
y is a binary function that indicates whether two points belong to the same category.
y equals 1 if two points belong to the same object:
In this case, if the feature distance between the two points is small, the model is more suitable and the loss
is smaller. If two points do not belong to the same category, then
y = 0:
If the feature distance between two points is greater than the
, it means that the two points do not affect each other, and the loss
is 0. If the feature distance of the two points is less than the
, it means that the loss
increases with the decrease of the feature distance, then the current model is not suitable and needs to be retrained.
The point-wise semantic label is determined based on the prediction score vector after minimizing the loss function. Finally, the semantic segmentation maps the initial point cloud features to new high-level feature spaces. Namely, points of the same semantic category are clustered together, while the different classes are separated in the semantic feature space.
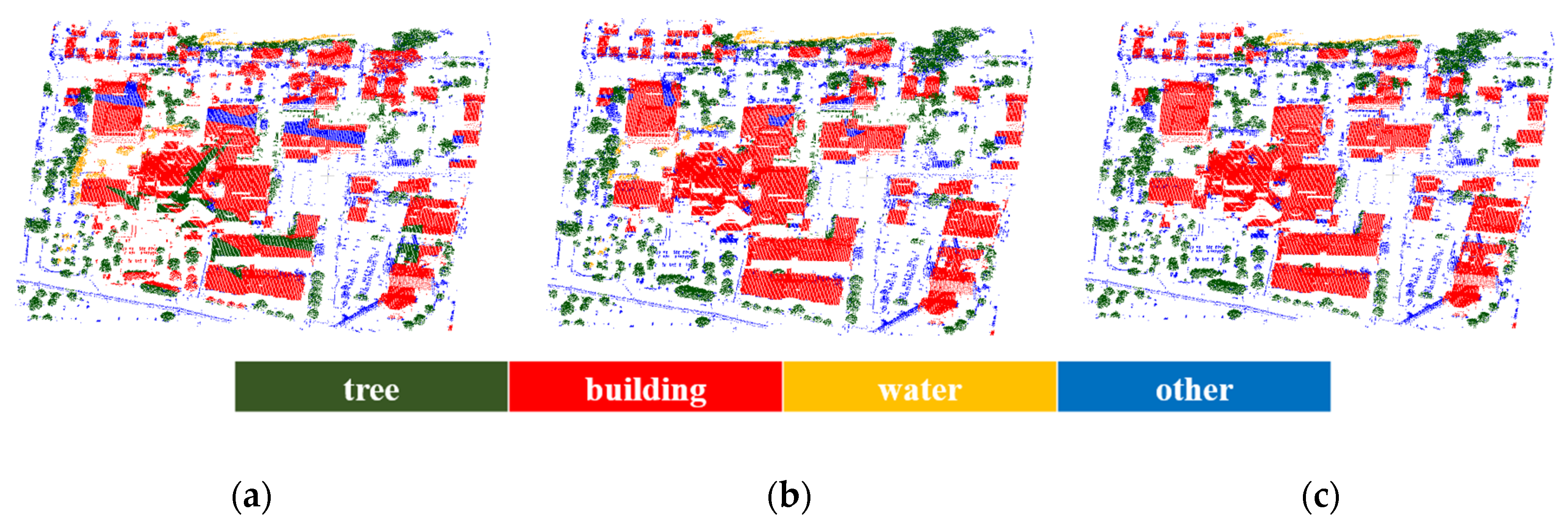
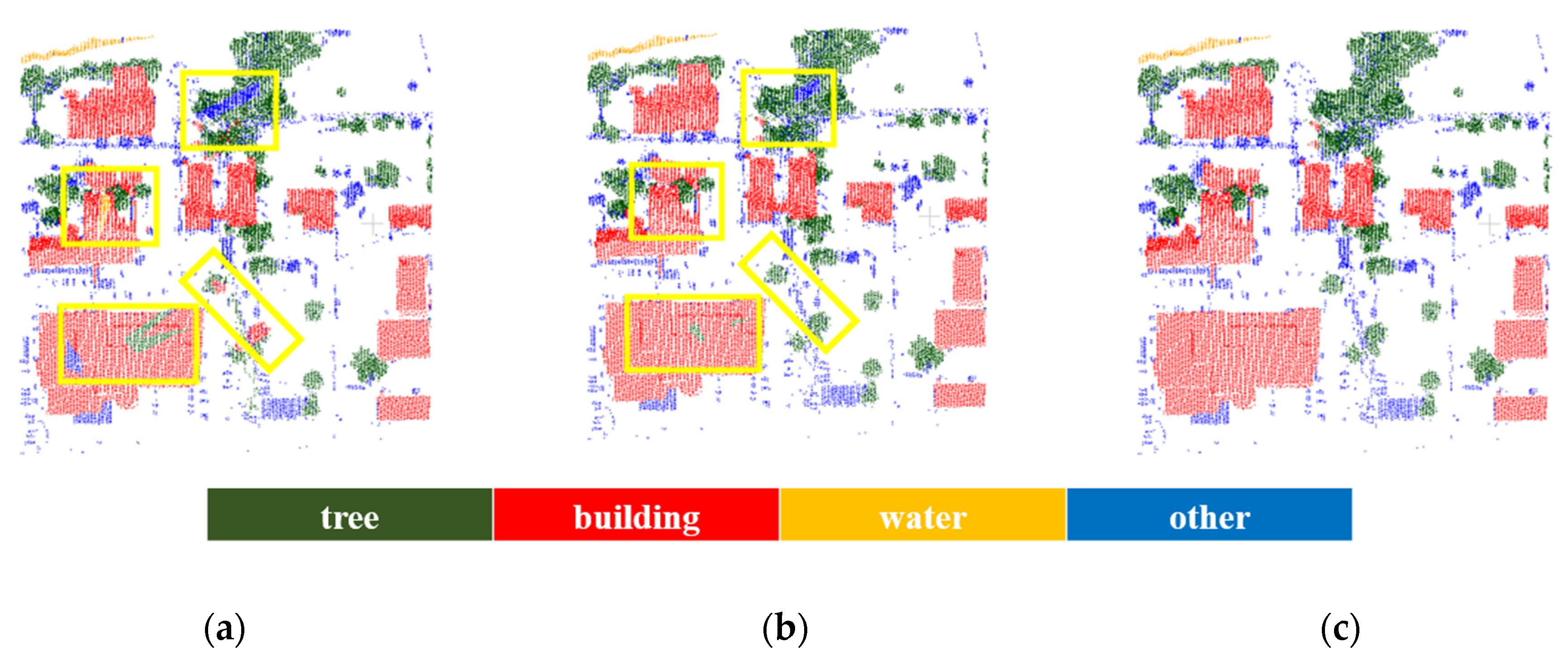
2.3. Graph-Structured Optimization for Classification Refinement
The proposed method exists a few local errors in the result of point-wise semantic learning network. For instance, a tree without canopy is misclassified as others or a pole mixed with tree is misclassified as a tree. Considering the object
tree in the classification result as input in last step, instance segmentation of trees, these inaccurate labels may have undesirable consequences. Therefore, we can optimize the initial results and further obtain locally smoothed results with a probabilistic model. It is obvious that the wrong labels can be revised by their local context, as advocated in [
52]. We model spatial correlations by applying a graph structure to ensure the consistency of point-wise label prediction, in other words, the labeling refinement can be converted into a graph-structured problem.
The first step is construction of the graph to structure the objective functional, the graphical model is constructed by the undirected adjacency graph
, where
represents the nodes and a set of edges
encode spatial relationship of adjacent points with weights
w. In graph
G, for a central vertex
v, we define its ten KNN neighbor according to the minimum number of edges from the other vertex
to
v. With respect to the edge weights
, the spatial distance, difference of normal vector angles and similarity are adopted for estimating weights. Furthermore, let
denote a set of the points, let
be a set of labels (in this paper, m is determined by the number of labels in the dataset), let
represent a set of feature variables of points, and let
denote all possible label configurations [
53]. To achieve global optimization using the constructed graph, we then formalize the optimal label configuration as an energy function minimization problem, and it is defined by following equation:
where unary potential term
quantitatively measures the disagreement between the possible label configuration
L and the observed data, while smooth potential term
keeps smoothness and consistency between predictions, and
is a weight coefficient used to balance the influence between the unary potential and the local smoothness.
With this configuration, the regularization process of the initial semantic segmentation will be performed to ensure labels locally continuous and globally optimal. In the proposed framework, the two terms have different definitions in the abovementioned energy functions. Consequently, the form of unary potential
is typically:
where
measures how well label
fits the feature variables
of given observed data and enforces the influence of the labels. As for the urban region, the same objects have similar features, while different objects have distinct features. The term
is derived from the predicted probability
output from the point-wise classification. The higher the category posterior probability, the smaller the unary potential.
The second term in Equation (7) suppresses the “salt and pepper” effect and demonstrates the penalty to assign labels to a couple of 3D points, and is thus judged by
[
54]. More specifically,
if
or 0 otherwise,
represents the Gaussian kernel relying on extracted features
f which is determined by the XYZ and intensity values of the points
i and
j, and
indicates constant coefficients. Two Gaussian kernels [
55,
56] are chosen as follows:
where,
is the weight of the bilateral kernel,
is the weight of the spatial kernel,
,
and
are three predefined hyperparameters.
While the regularization coefficient
is estimated as follows:
where
is the distance between points
i and
j, and
is the expectation of all neighboring distances.
Accordingly, the optimal label prediction
is the solution of minimization energy function with the following structure:
Although accurate minimization is intractable, the minimization problem is easily and appropriately solved by a graph-cut algorithm using the
-expansion [
57,
58]. With a few graph-cut iterations, we can effectively and quickly find an approximate solution for optimizing multi-label energies. The labeling cost is not considered since graph-based optimization can effectively leverage the prediction and confidence, as well as semantic label assignment between two similar points in each region. The optimized results could be automatically adaptive to the underlying urban scenes without the predefined features for some uncertain objects.
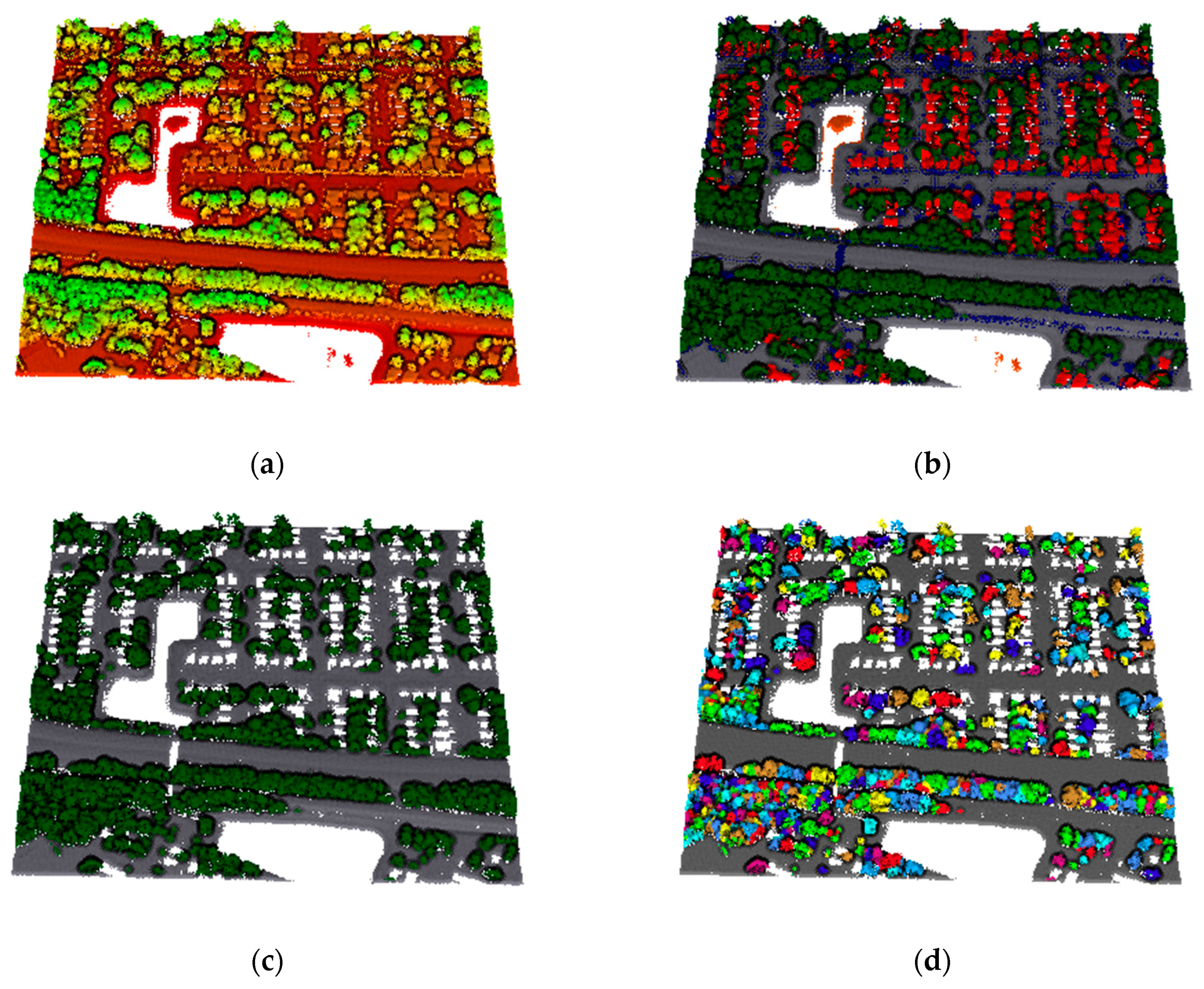
2.4. Segmentation of Individual Roadside Trees with Deep Metric Learning
After the class
tree is determined, the label-based segmentation method is used to extract the tree points. As tree crowns are often clumped and connected together, it is vital to determine the points of individual trees by correctly isolating tree crown points of each trunk. Instance recognition of trees in environmentally complex urban areas is a challenge due to the poor-quality data. To overcome this problem, the quality of the segmented tree data is first enhanced through recovering the missing regions and removing the noise, outliers. We extend the previously proposed method in [
59,
60], and seek self-similar points to denoise them simultaneously using graph Laplacian regularization. Inspired by the algorithm of [
61], we exploit an edge preserving smoothing algorithm using local neighborhood information to recover the regions with missing data. Delineation of individual trees from points after quality correction is then performed.
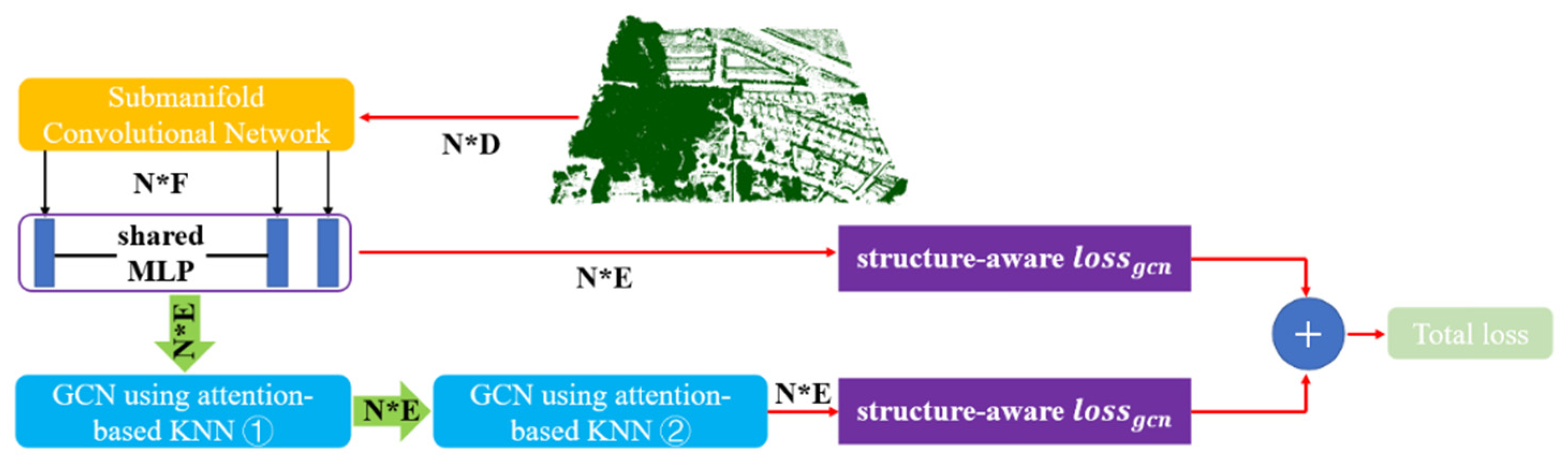
To automatically extract each tree crown points, a novel end-to-end architecture is applied to individual tree segmentation, which combines structure-aware loss function and attention-based k nearest neighbor (
KNN). The proposed framework is summarized in
Figure 6, we elaborate on the three main components of our proposed network, including the submanifold convolutional network, the structure-aware loss function and the graph convolutional network (GCN), respectively. We firstly generate initial embeddings for each point by the submanifold sparse convolutional network. Inspired by the work of [
62], we obtain discriminative embeddings for each tree from the LiDAR points based on the structure-aware loss function, which considers both the geometric and the embedding information. In order to achieve refined embeddings, we develop an attention-based graph convolutional neural network that aims to automatically choose and aggregate information from neighbors. Finally, to get segmentation of individual roadside trees, we employ a simple improved normalized cut segmentation algorithm to cluster refined embeddings.
Specifically, we directly use the architecture of the submanifold convolutional network (SCN) as our first component by borrowing from [
63]. In our experiment, we use two backbone networks, including an UNet-like architecture (with smaller capacity and faster speed) and a ResNet-like architecture (with larger capacity and slower speed). In this section, we mainly describe the last two components of our proposed method for instance segmentation of trees. In the metric learning, the points within the same tree have similar embeddings while points from different trees are apart in the embedding space. Considering points within each tree do not only have embedding features but also have geometric relations, we hope that the final results will more discriminative by combining structure information with embedding features. Some commonly used metrics (e.g., cosine distance) for measuring the similarity between embeddings may cause the learning process and the post-process more difficult as kinds of reason. To make embedding discriminative enough, the Euclidean distance chosen to measure the similarity between embeddings after many test experiments. After measuring the similarity between embeddings, we obtain discriminative embeddings for each tree by a structure-aware loss function. Our loss function is consisted of the following two items:
where
N is the total number of the tree in the entire scene. The first item
aims to minimize the distance between embeddings within the same tree. As shown in Equation (13), the overall feature of a tree can be described by a mean embedding.
where
denotes a threshold for penalizing large embedding distance,
is the point number of the
ith tree.
is the coordinate of the
jth point within the
ith tree, which measures the spatial distance between the
jth point and the geometric center
of the
ith tree;
is the embedding of the
jth point within the
ith tree, which measures the embedding distance between the
jth point and the mean embedding
. Further explanation,
and
are then represented as Equations (14) and (15), respectively.
On the other hand, the second item
is commonly used to make points from different trees discriminative. Specifically,
where
denotes a threshold for the distance between mean embeddings. After repeated experiments,
and
is set 0.7 and 1.5 respectively.
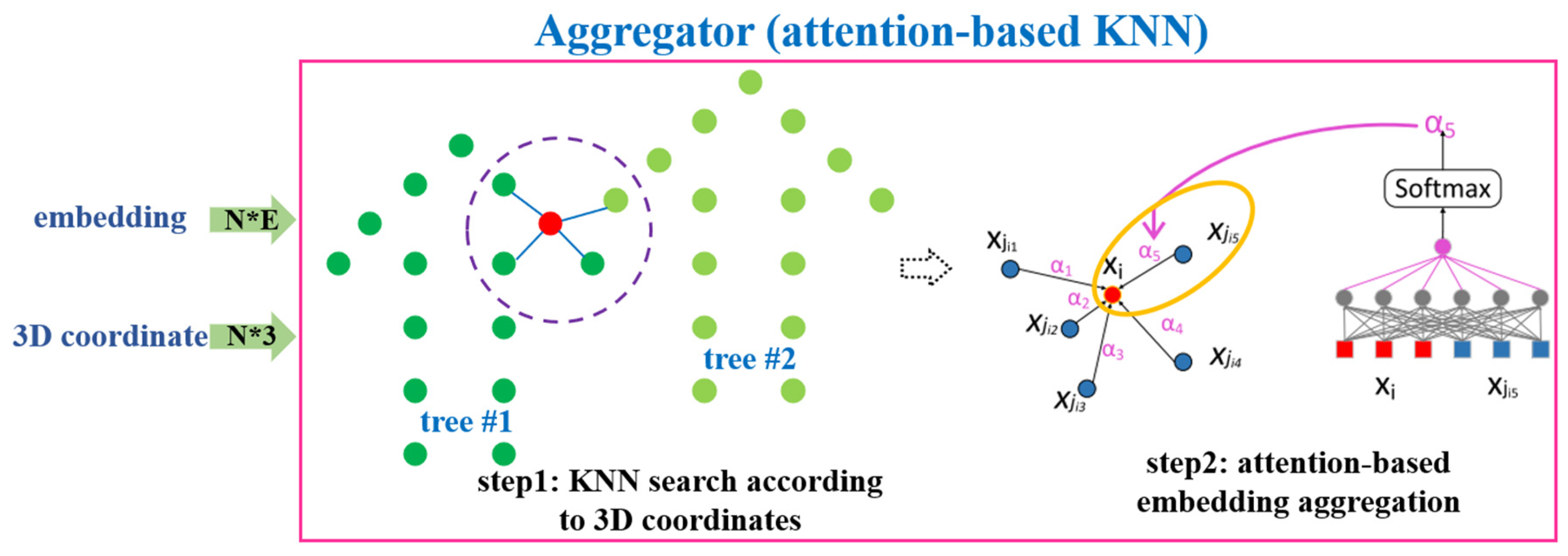
To achieve the goal that is to generate similar embeddings within the same tree and discriminative embeddings between different trees, KNN algorithm is applied to improve the local consistency of embeddings and aggregate information from surrounding points for a certain point. However, it is unfortunate that some wrong information brought by KNN will be harmful for embeddings. It is more obvious that a point near the edge of a certain tree may aggregates information from another trees. Instead of the standard KNN aggregation (
), an attention-based KNN is developed for embedding aggregation (
), which can assign different weights for different neighbors. The transform process can be formalized as follows:
where the input embeddings of point clouds are denoted by X =
,
are the
k nearest neighbors of
according to their spatial positions, and
is the attention weight for each neighbor and the normalization of the softmax function.
Figure 7 is the illustration of attention-based
KNN which is the aggregator of our proposed graph convolutional neural network containing two steps. In step 1, for each input point,
k nearest neighbors are searched according to the spatial coordinate. Different weights are assigned to different neighbors in step 2. The output of the aggregator is the weighted average of the embeddings of
k neighbors. In general, aggregator in the form of attention-based
KNN is a natural and meaningful operation for 3D points and allows the network to learn different importance for different neighbors.
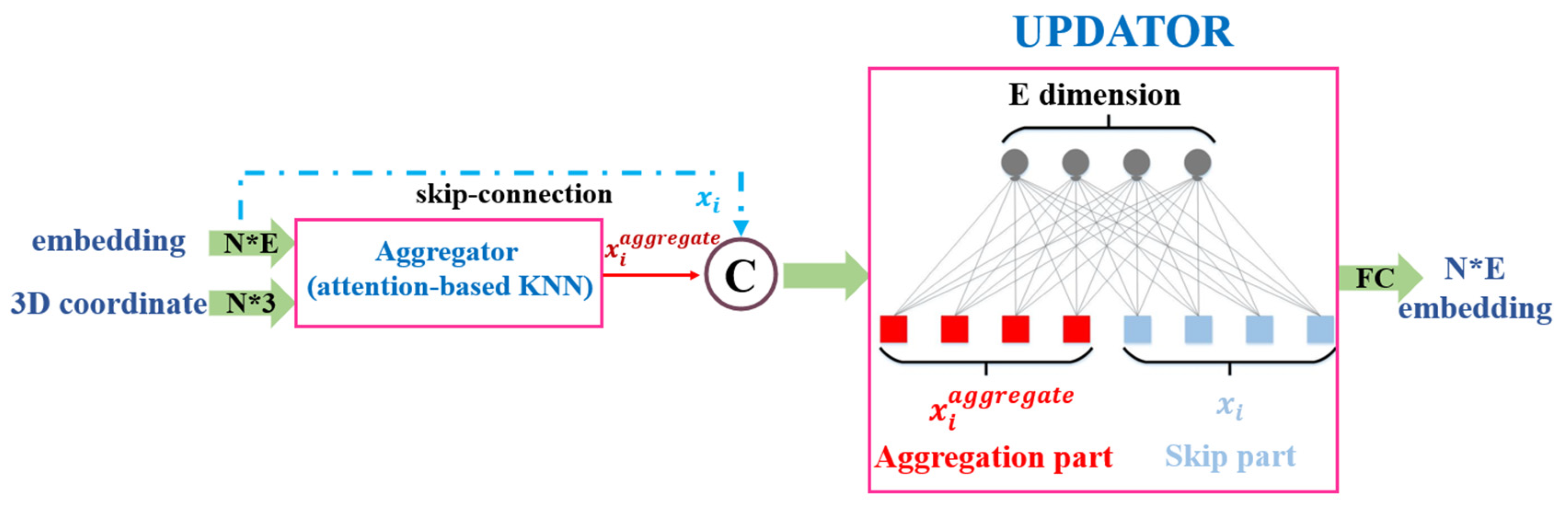
In the previous research, the GCN is normally composed of two parts: the aggregator and the updator (illustrated in
Figure 8). As explained above, the aggregator is to gather information from neighbors using the proposed attention-based
KNN. To update the aggregated information by mapping embeddings into a new feature space, a simple fully connected layer without bias is used as the updator. The operation is formalized as follows:
where
W ⊆
is a trainable parameter of the updator.
A portion of GCNs describe the relation using the laplacian matrix and the eigen-decomposition, which require huge computing cost (complexity ). In contrast to previous GCNs, the main spotlight of our spatial GCN is that the attention-based KNN is used as the aggregator. In other word, the KNN (complexity (n × k)) is used to describe the relation. It is quite vital for GCN to be applied to the original data. Last but not least, the proposed network will be easily trained end-to-end and uses the ADAM optimizer with constant learning rate 0.001. During implementation, we firstly pretrain the backbone network to obtain a pretrained segmentation model, then train the whole tree segmentation network based on the pretrained model, which can save time when conducting multiple experiments.
The spatially independent trees are quickly and effectively separated, but the overlapping or adjacent trees are difficult to isolate. Several previous researches reduced omission errors by a certain graph-cut algorithm, which enhanced accuracy but increased computational complexity. To further segment those objects containing more than one object, a supervoxel-based normalized cut segmentation method is developed. The mixed objects are firstly partitioned into homogeneous supervoxels with approximately equal resolution using the existing over-segmentation algorithm proposed in [
64], which can preserve the boundary of object much better than others. Then, consider a complete weighted graph
G(
V,
E) constructed from the given supervoxels according to their spatial neighbors, where the vertices
V are represented by the center of supervoxels, and edges
E are connected between each pair of adjacent supervoxels. The meaningful weight assigned to the edge is adopted for measuring the similarity between a pair of supervoxels connected by the edge and is calculated by the geometric information associated with the supervoxels as follows:
where
and
are the horizontal and vertical distance between supervoxels
i and
j, respectively.
,
and
indicate the standard deviations of
,
and
, respectively.
is a distance threshold for determining the maximal valid distance between two supervoxels in the horizontal plane.
is expressed as
where
and
denote the horizontal distance between supervoxels
i,
j and the top of nearest tree.
Specifically, the similarity between two supervoxels is measured by considering their distance in the horizontal plane and their relative horizontal and vertical distributions. By such a definition, we partition the complete weighted graph G into two disjoint groups A and B by normalized cut segmentation method, which maximizes the similarity within each group (
) and the dissimilarity between two groups (
). According to [
65], the corresponding cost function is defined as
where
denotes the sum of the weights on the edges connecting groups
A and
B;
and
denote the sum of the weights on the edges falling in group
A and
B, respectively.
The process of dividing the weighted graph
G into two separate groups A and B is regarded as the minimization of
. Since minimization problem is NP-hard, the proposed method relies on the approximation strategy, which achieves fairly good results in terms of solution quality and speed. Then the minimization of
is obtained by solving the corresponding generalized eigenvalue problem
where
W(
i,
j) =
, and
D is a diagonal matrix, whose
ith row records the sum of the weights on the edges associated with supervoxel
iWe introduce a parameter
z denoted as
, thus, the Equation (22) is represented as
. From the basic principle of the Rayleigh quotient, it can be known that solving the minimum value problem of
is converted into solving the second minimum eigenvector of the feature system, and the best division result of normalized segmentation is obtained.
where
is the small solution of the abovementioned feature system,
is the smallest feature vector.
Based on the normalized cut principle, the overlapping objects are divided into two segments by employing a threshold to the eigenvector associated with the second smallest eigenvalue. Since elements of the second smallest eigenvector generally appear as continuous real values, a separation point needs to be introduced to bisect, usually 0 or the median of the eigenvector elements is used as the separation point. In order to minimize
, heuristic method [
66] is used to find the optimal separation point. The elevation information plays a significant role in aerial LiDAR data processing, we finally adopt an elevation-attention module [
67] which directly applies the per-point elevation information to improve segmentation results.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}