DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes




Abstract
:
1. Introduction
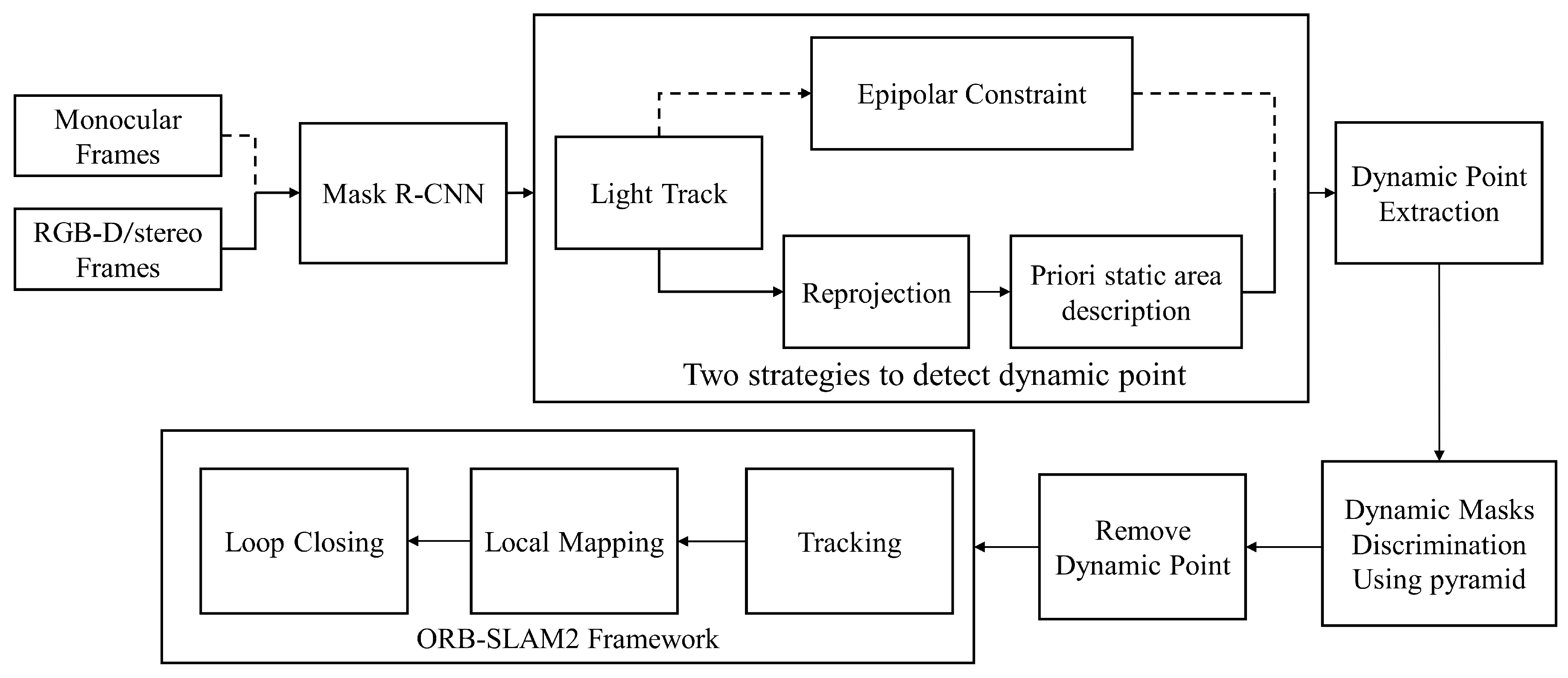
- We propose a complete visual SLAM system called DM-SLAM that combines an instance segmentation network and optical flow information. The system eliminates the influence of dynamic objects on pose estimation in highly dynamic environments and can handle data streams from monocular, stereo, and RGB-D sensors.
- We present two strategies to efficiently extract dynamic points between adjacent frames for RGB-D/stereo camera and monocular camera cases.
- We evaluate our proposed system on the public TUM and KITTI datasets and achieve good performance in highly dynamic scenarios. The absolute trajectory accuracy of DM-SLAM far outperforms those of the standard visual SLAM baselines.
2. Related Work
2.1. Dynamic SLAM
2.2. SLAM Combined with Deep Learning
3. System Introduction
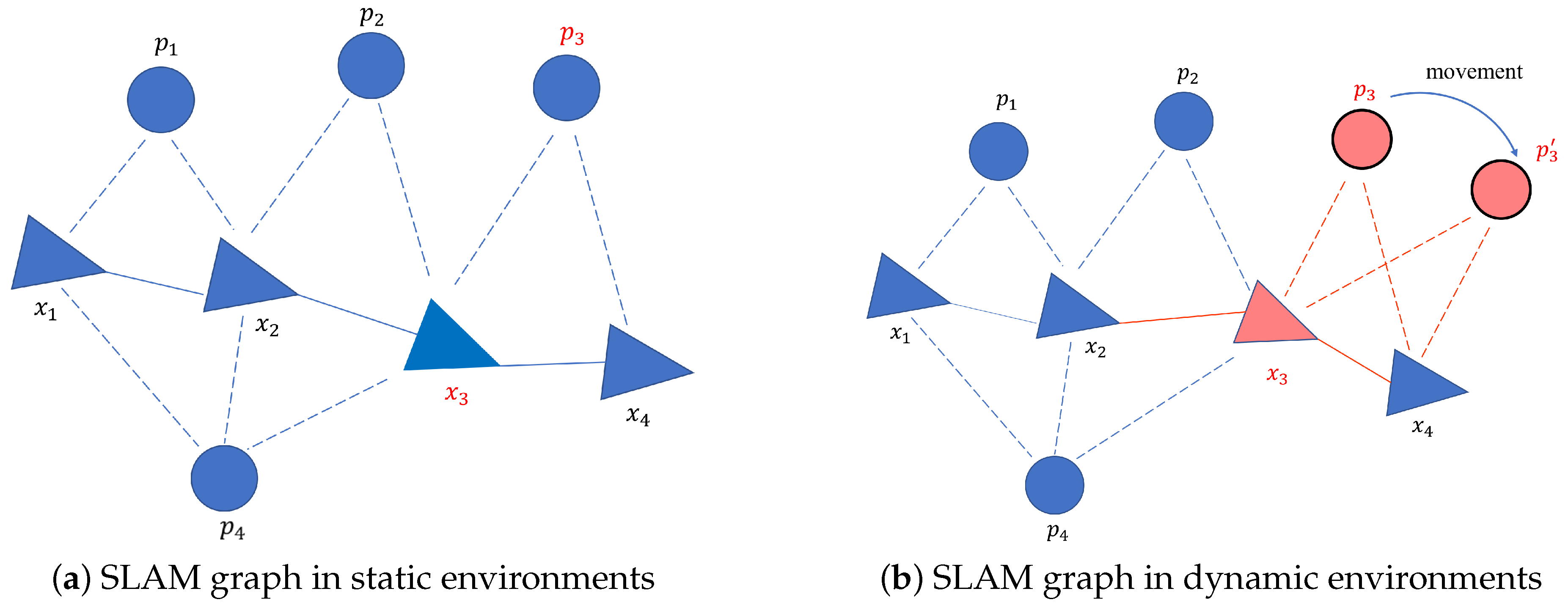
3.1. Problem Statement
3.2. Proposed Method
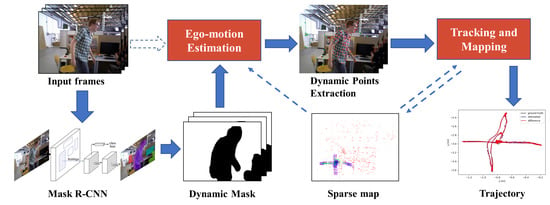
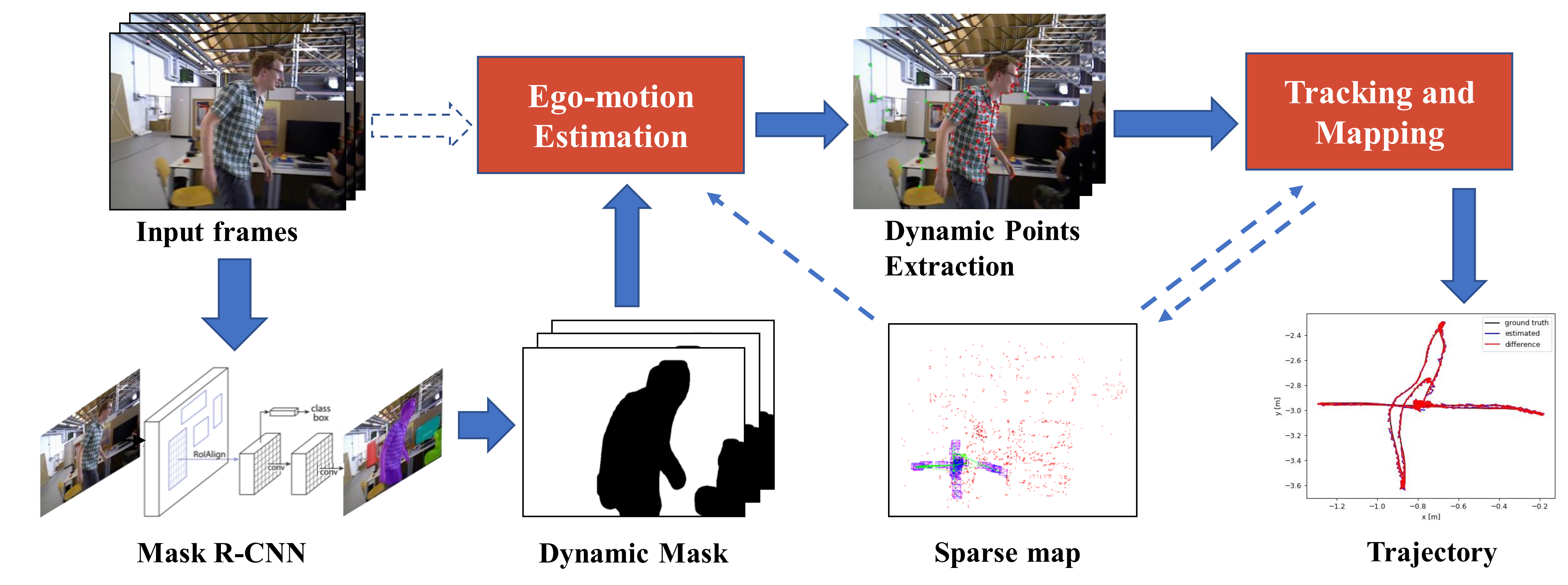
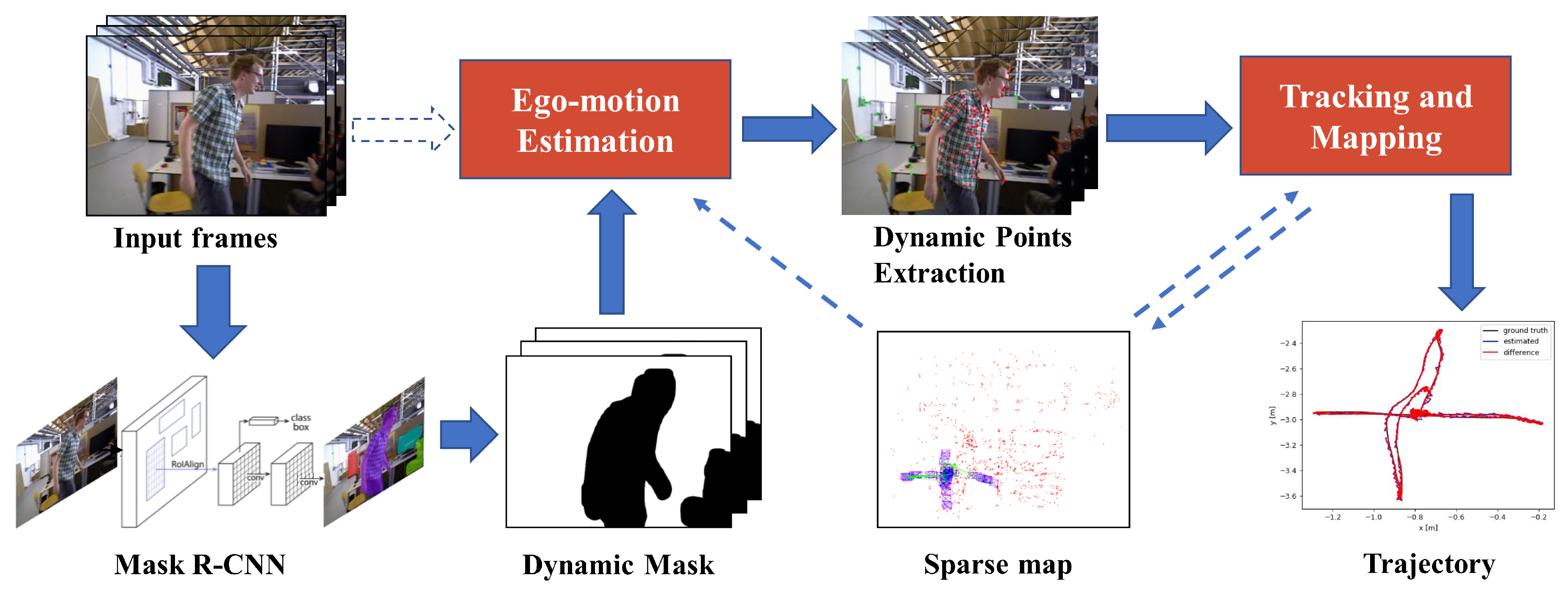
3.2.1. Overview of the Proposed Approach
3.2.2. Segmentation of Potentially Moving Objects
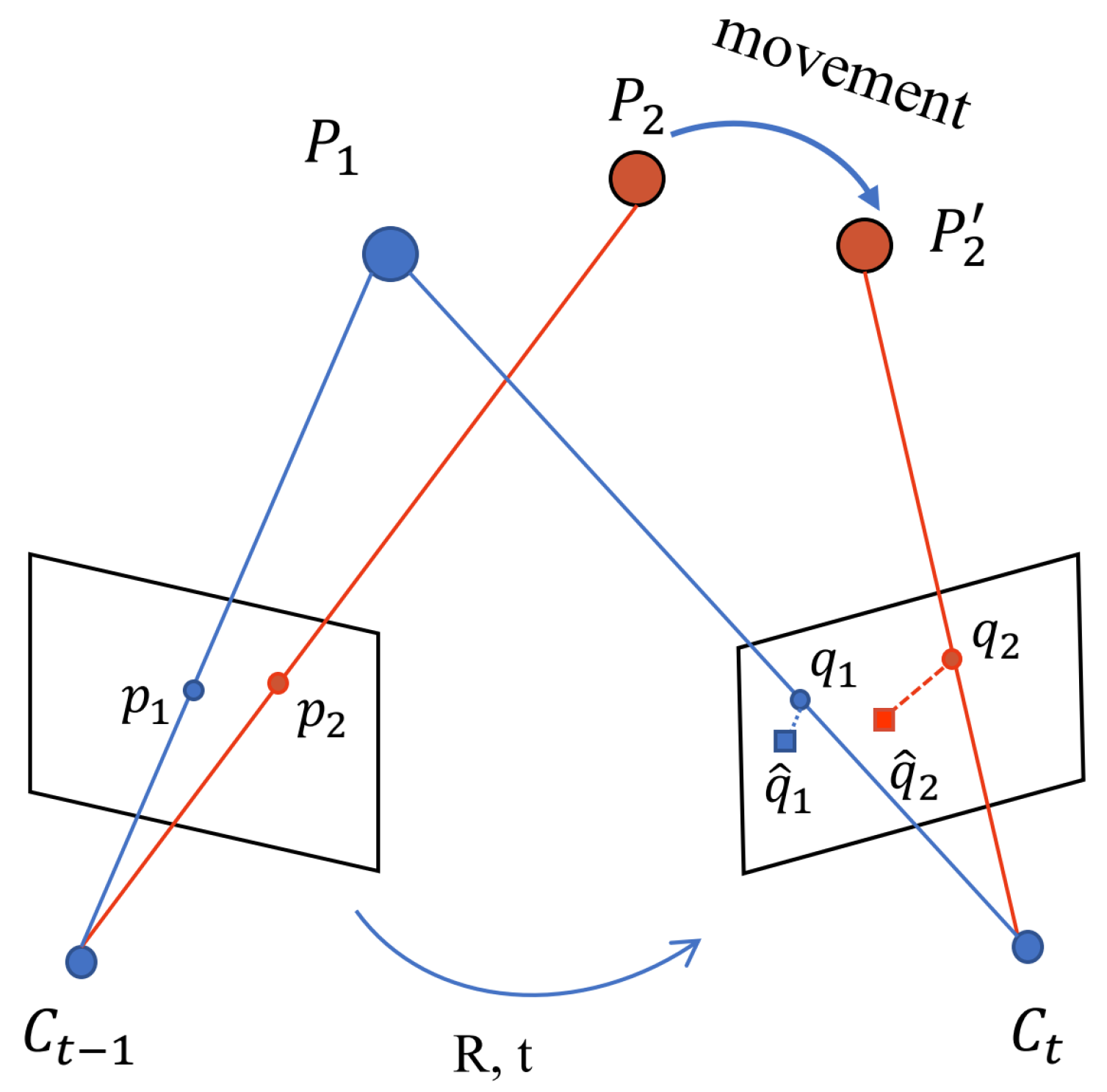
3.2.3. Ego-Motion Estimation
3.2.4. Dynamic Feature Points Extraction
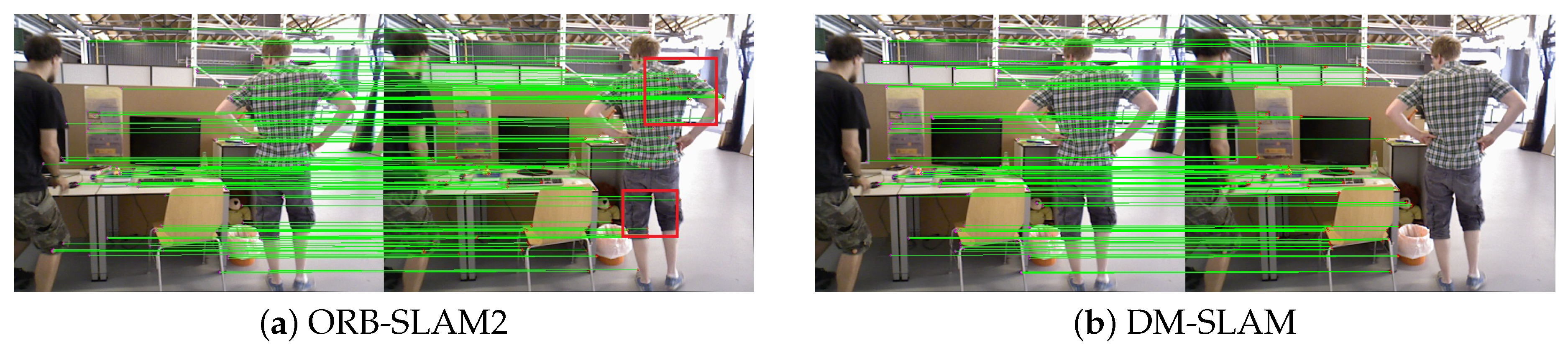
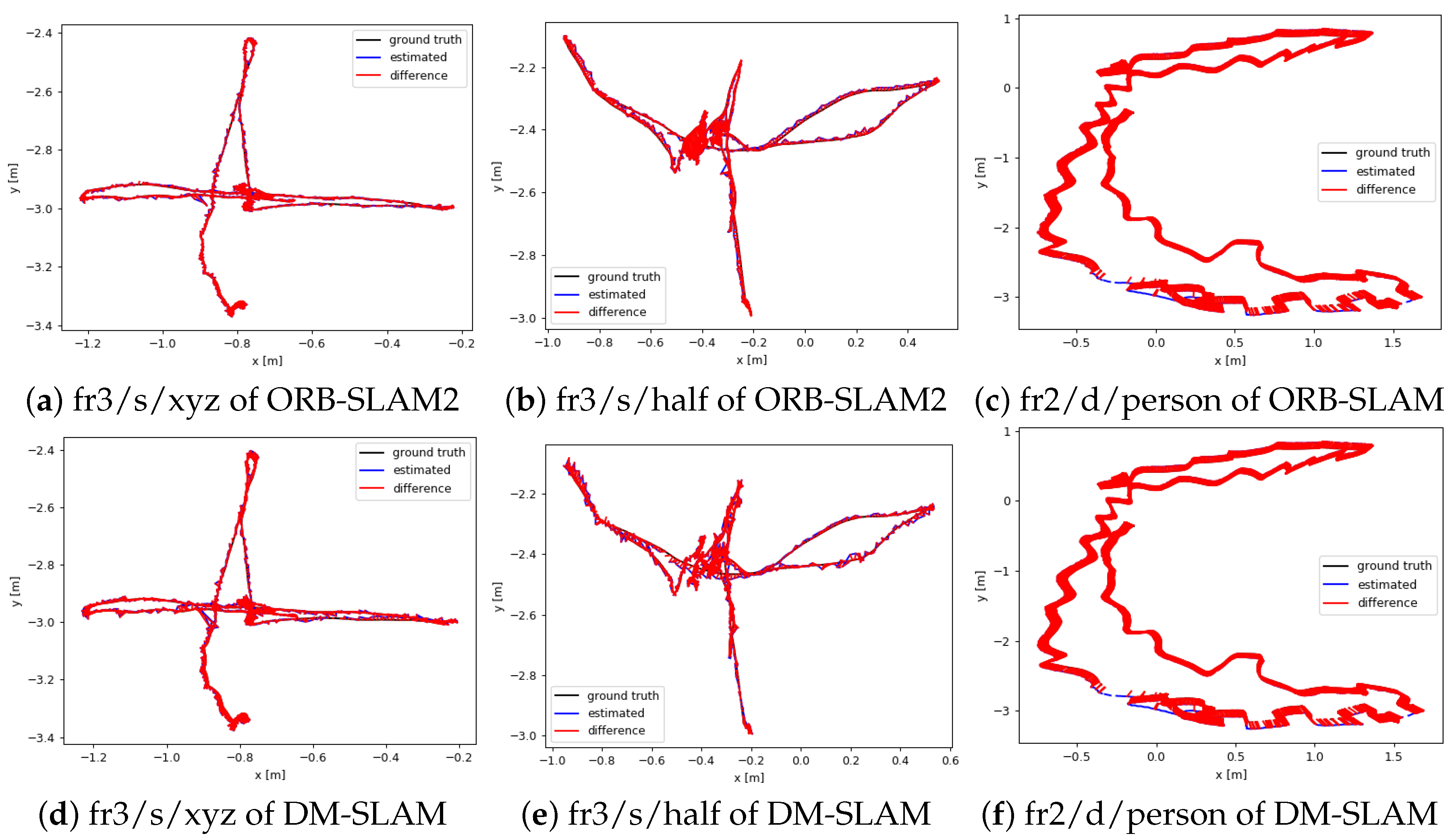
- DS-SLAM only takes the human as a typical representative of dynamic objects in experiments and cannot process stereo sensors data. We predefine 20 categories as potentially dynamic or movable in DM-SLAM and evaluate our system in the pubic monocular, stereo, and RGB-D datasets. DM-SLAM is applicable to a wider range of scenarios.
- DynaSLAM directly regards the segmented content as dynamic and does not extract feature points on them, which is not in line with the real situation (e.g., a parked car). Then, they only extract dynamic points in the RGB-D case using multi-view geometry. In our system, a mask motion discrimination module is added to avoid the problem of discarding too many points on a static mask, causing too few remaining static points. Thus, it has better robustness than the method of directly removing all feature points in the mask.
4. Experimental Results
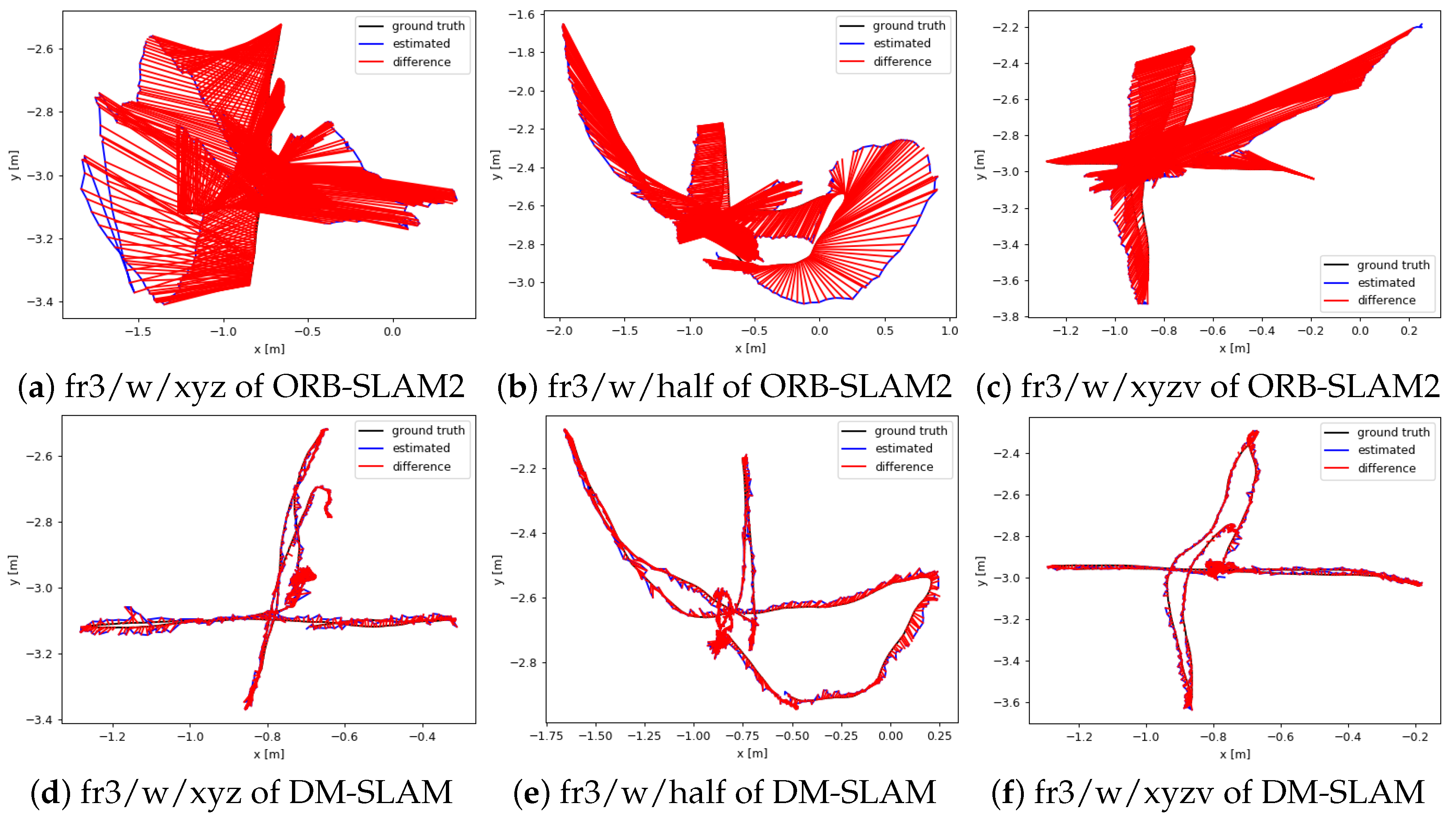
4.1. TUM Dataset
4.1.1. RGB-D
4.1.2. Monocular
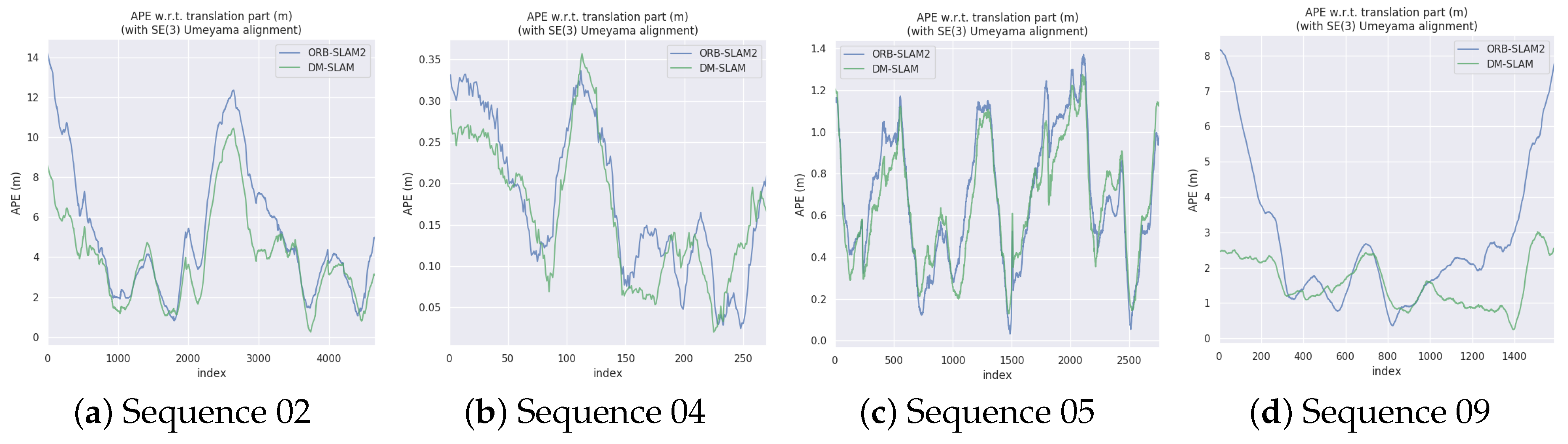
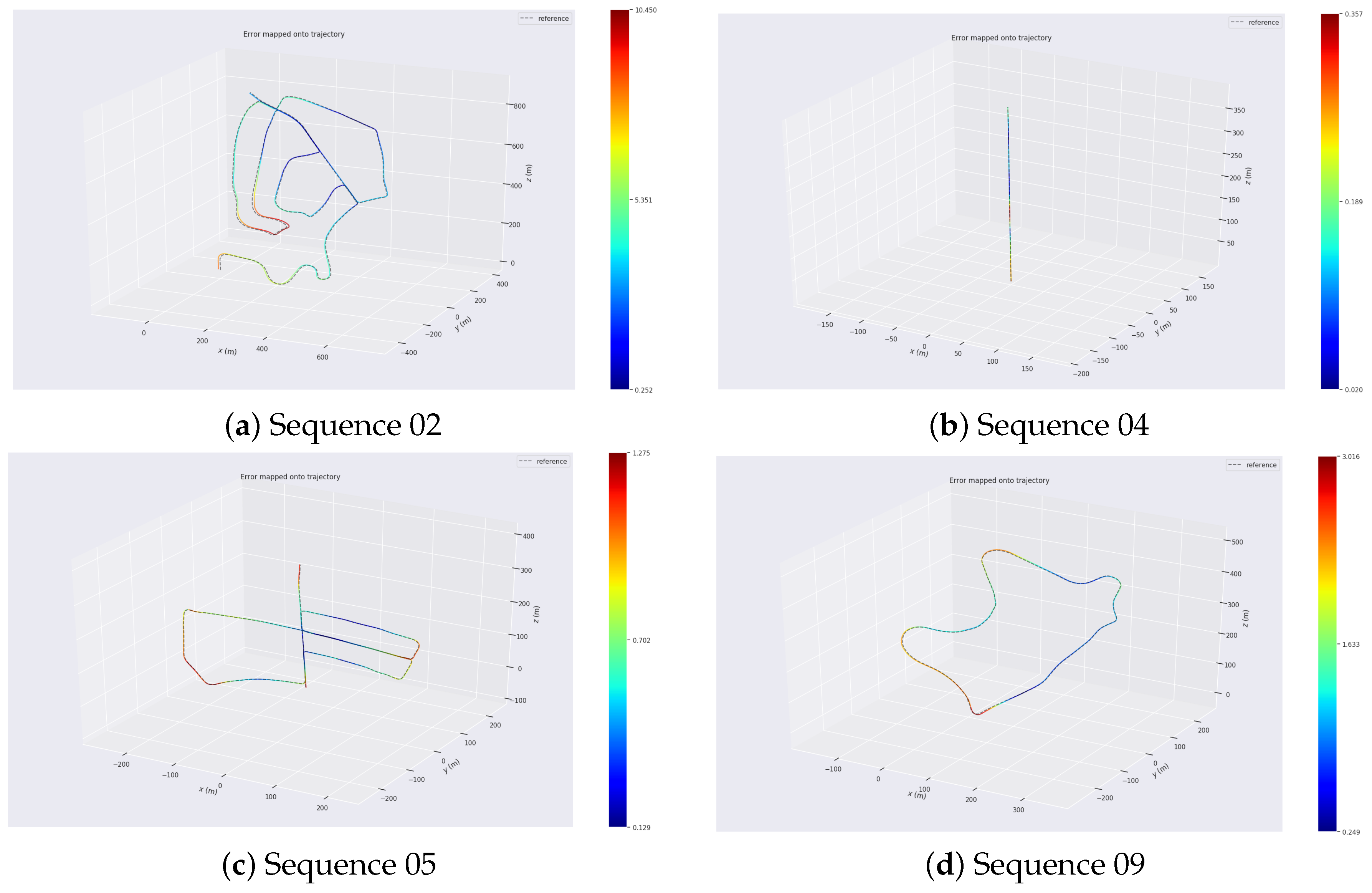
4.2. KITTI Dataset
4.3. Runtime Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Stühmer, J.; Gumhold, S.; Cremers, D. Real-time dense geometry from a handheld camera. In Proceedings of the Joint Pattern Recognition Symposium, Darmstadt, Germany, 22–24 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 11–20. [Google Scholar]
- Graber, G.; Pock, T.; Bischof, H. Online 3D reconstruction using convex optimization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 708–711. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 37. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Li, S.; Lee, D. RGB-D SLAM in dynamic environments using static point weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, S. Towards dense moving object segmentation based robust dense RGB-D SLAM in dynamic scenarios. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 1841–1846. [Google Scholar]
- Alcantarilla, P.F.; Yebes, J.J.; Almazán, J.; Bergasa, L.M. On combining visual SLAM and dense scene flow to increase the robustness of localization and mapping in dynamic environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1290–1297. [Google Scholar]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust monocular SLAM in dynamic environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Shimamura, J.; Morimoto, M.; Koike, H. Robust vSLAM for Dynamic Scenes. In Proceedings of the MVA2011 IAPR Conference on Machine Vision Applications, Nara, Japan, 13–15 June 2011; pp. 344–347. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F.; Siegwart, R. Real-time monocular visual odometry for on-road vehicles with 1-point ransac. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 4293–4299. [Google Scholar]
- Ferrera, M.; Moras, J.; Trouvé-Peloux, P.; Creuze, V. Real-Time Monocular Visual Odometry for Turbid and Dynamic Underwater Environments. Sensors 2019, 19, 687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, G.; Zeng, W.; Feng, B.; Xu, F. DMS-SLAM: A General Visual SLAM System for Dynamic Scenes with Multiple Sensors. Sensors 2019, 19, 3714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]
- Jones, E.S.; Soatto, S. Visual-inertial navigation, mapping and localization: A scalable real-time causal approach. Int. J. Robot. Res. 2011, 30, 407–430. [Google Scholar] [CrossRef]
- Leutenegger, S.; Furgale, P.; Rabaud, V.; Chli, M.; Konolige, K.; Siegwart, R. Keyframe-based visual-inertial slam using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.H.; Han, S.B.; Kim, J.H. Visual odometry algorithm using an RGB-D sensor and IMU in a highly dynamic environment. In Robot Intelligence Technology and Applications 3; Springer: Cham, Switzerland, 2015; pp. 11–26. [Google Scholar]
- Agudo, A.; Moreno-Noguer, F.; Calvo, B.; Montiel, J.M.M. Sequential non-rigid structure from motion using physical priors. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 979–994. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agudo, A.; Moreno-Noguer, F.; Calvo, B.; Montiel, J. Real-time 3D reconstruction of non-rigid shapes with a single moving camera. Comput. Vis. Image Underst. 2016, 153, 37–54. [Google Scholar] [CrossRef] [Green Version]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. Cnn-slam: Real-time dense monocular slam with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6243–6252. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Toward geometric deep SLAM. arXiv 2017, arXiv:1707.07410. [Google Scholar]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic slam. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar]
- Lianos, K.N.; Schonberger, J.L.; Pollefeys, M.; Sattler, T. Vso: Visual semantic odometry. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Riazuelo, L.; Montano, L.; Montiel, J. Semantic visual SLAM in populated environments. In Proceedings of the 2017 European Conference on Mobile Robots (ECMR), Paris, France, 6–8 September 2017; pp. 1–7. [Google Scholar]
- Vineet, V.; Miksik, O.; Lidegaard, M.; Nießner, M.; Golodetz, S.; Prisacariu, V.A.; Kähler, O.; Murray, D.W.; Izadi, S.; Pérez, P.; et al. Incremental dense semantic stereo fusion for large-scale semantic scene reconstruction. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 75–82. [Google Scholar]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 258–266. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. Ds-slam: A semantic visual slam towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bahraini, M.S.; Rad, A.B.; Bozorg, M. SLAM in Dynamic Environments: A Deep Learning Approach for Moving Object Tracking Using ML-RANSAC Algorithm. Sensors 2019, 19, 3699. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Baker, S.; Matthews, I. Lucas-kanade 20 years on: A unifying framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | ORB-SLAM2 | DS-SLAM | DynaSLAM | DM-SLAM | Improvement | |||
|---|---|---|---|---|---|---|---|---|
| RMSE [m] | STD [m] | RMSE [m] | RMSE [m] | RMSE [m] | STD [m] | RMSE [%] | STD [%] | |
| fr3/w/xyz | 0.7137 | 0.3584 | 0.0241 | 0.0158 | 0.0148 | 0.0072 | 97.93% | 97.99% |
| fr3/w/rpy | 0.8357 | 0.4169 | 0.3741 | 0.0402 | 0.0328 | 0.0194 | 96.08% | 95.35% |
| fr3/w/static | 0.3665 | 0.1448 | 0.0081 | 0.0080 | 0.0079 | 0.0040 | 97.84% | 97.24% |
| fr3/w/half | 0.4068 | 0.1698 | 0.0282 | 0.0276 | 0.0274 | 0.0137 | 93.26% | 91.93% |
| fr3/s/static | 0.0092 | 0.0039 | 0.0061 | 0.0064 | 0.0063 | 0.0032 | 31.52% | 17.95% |
| fr3/s/rpy | 0.0245 | 0.0172 | 0.0187 | 0.0302 | 0.0230 | 0.0134 | 6.12% | 22.09% |
| fr3/s/half | 0.0231 | 0.0112 | 0.0148 | 0.0191 | 0.0178 | 0.0103 | 22.94% | 30.41% |
| Sequences | ATE RMSE [m] | Traj (%) | ||||
|---|---|---|---|---|---|---|
| ORB-SLAM2 | DynaSLAM | DM-SLAM | ORB-SLAM2 | DynaSLAM | DM-SLAM | |
| fr3/w/xyz | 0.014 | 0.014 | 0.020 | 85.61 | 87.37 | 97.90 |
| fr3/w/half | 0.017 | 0.021 | 0.024 | 90.12 | 97.84 | 97.87 |
| fr3/w/rpy | 0.066 | 0.052 | 0.050 | 85.82 | 85.11 | 87.24 |
| fr3/w/static | 0.005 | 0.004 | 0.004 | 89.30 | 90.01 | 91.57 |
| fr3/s/xyz | 0.008 | 0.013 | 0.014 | 95.47 | 95.51 | 95.78 |
| fr3/s/rpy | 0.042 | 0.021 | 0.021 | 80.36 | 54.39 | 92.54 |
| Sequences | ORB-SLAM2 | DynaSLAM | DM-SLAM |
|---|---|---|---|
| ATE RMSE [m] | ATE RMSE [m] | ATE RMSE [m] | |
| KITTI 00 | 1.3 | 1.4 | 1.4 |
| KITTI 01 | 11.4 | 9.4 | 9.1 |
| KITTI 02 | 6.2 | 6.7 | 4.6 |
| KITTI 03 | 0.6 | 0.6 | 0.6 |
| KITTI 04 | 0.2 | 0.2 | 0.2 |
| KITTI 05 | 0.8 | 0.8 | 0.7 |
| KITTI 06 | 0.8 | 0.8 | 0.8 |
| KITTI 07 | 0.5 | 0.5 | 0.6 |
| KITTI 08 | 3.8 | 3.5 | 3.3 |
| KITTI 09 | 3.4 | 1.6 | 1.7 |
| KITTI 10 | 1.0 | 1.2 | 1.1 |
| Datasets | Semantic Segmentation [ms] | Ego-Motion Estimation [ms] | Dynamic Point Detection [ms] |
|---|---|---|---|
| TUM | 201.02 | 3.16 | 40.64 |
| KITTI | 210.11 | 7.03 | 94.59 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS Int. J. Geo-Inf. 2020, 9, 202. https://doi.org/10.3390/ijgi9040202
Cheng J, Wang Z, Zhou H, Li L, Yao J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS International Journal of Geo-Information. 2020; 9(4):202. https://doi.org/10.3390/ijgi9040202
Chicago/Turabian StyleCheng, Junhao, Zhi Wang, Hongyan Zhou, Li Li, and Jian Yao. 2020. "DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes" ISPRS International Journal of Geo-Information 9, no. 4: 202. https://doi.org/10.3390/ijgi9040202
APA StyleCheng, J., Wang, Z., Zhou, H., Li, L., & Yao, J. (2020). DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS International Journal of Geo-Information, 9(4), 202. https://doi.org/10.3390/ijgi9040202