1. Introduction
Rice is a crucial food crop globally, serving as the staple food for approximately 50% of the world’s population [
1]. It holds significant importance in national agricultural production [
2]. The efficient and accurate identification of rice diseases is a pressing issue for rice growers, as rice disease is the primary factor affecting both yield and quality. The loss of yield and quality caused by rice disease has a direct impact on rice production, as well as human and animal safety [
3]. Given that the safe production of rice is a strategic concern related to social stability and national security, addressing this issue is of utmost importance. The traditional method of identifying rice diseases involves visual inspection by plant protection experts. However, this method is time consuming and relies heavily on subjective judgment, making it difficult to promptly prevent and control rice diseases [
4]. With the rapid improvement in computer hardware processing speed and software technology, the utilization of artificial intelligence, image recognition, big data, and deep learning technology has become increasingly prevalent in the field of agriculture, particularly in crop disease diagnosis and recognition. When rice plants are affected by diseases, their physiological structure and morphological characteristics change, resulting in symptoms such as leaf discoloration, decay, and deformation. To ensure higher yield and protect rice from pests and diseases, it is crucial to develop a new method for detecting rice diseases that can quickly and accurately identify and classify them in the early stages. This will help to maintain the overall quality and yield of rice.
The agricultural sector is witnessing a shift from traditional intensive farming to emerging technologies such as precision agriculture and intelligent agriculture. Precision agriculture utilizes information technology (IT), satellite technology, geographic information systems (GISs), and remote sensing to enhance all functions and services of the agricultural sector [
5]. This technology is crucial in improving crop disease and pest control and management, establishing intensive agricultural production management and operation mode, and enhancing the quality of agricultural products. Precision agriculture has begun to rely on various technologies such as mobile applications [
6], smart sensors [
7], drones [
8], cloud computing [
9], artificial intelligence (AI) [
10], the Internet of Things (IoT) [
11], and blockchain [
12]. These technologies enable real-time processing and access to data on soil, crop, and weather conditions. Additionally, they allow for the timely detection and reporting of plant health, and provide guidance to farmers on soil management, crop maturity rotation, optimal planting time, and harvest time. The utilization of emerging technologies, such as the Internet of Things, presents vast potential for the advancement of smart and precision agriculture. These technologies allow for the acquisition of real-time environmental data, facilitating more efficient and effective farming practices. The use of IoT devices such as unmanned aerial vehicles with high spatial and temporal resolution can be beneficial for crop management. However, the adoption of smart agriculture has not been as strong as expected due to various challenges such as data acquisition and image processing methods. Khattab et al. have developed an IoT-based monitoring system specifically designed for precision agriculture applications [
13]. This system provides environmental monitoring services to ensure that the crop growing environment is optimal and to predict early conditions that may lead to epidemic outbreaks. While the system is capable of obtaining real-time plant images and making predictions, the accuracy of its classification model for plant diseases remains a challenge. Yuki et al. proposed a straightforward image processing pipeline that adheres to the empirical principle of the simultaneous emergence of leaves and tillers in rice morphogenesis [
14]. The team utilized an unmanned aerial vehicle to capture field images at very low flight altitudes. They then calculated the number of long blades using the proposed image processing pipeline, which included binarization, skeletonization, and tip detection. This study highlights the potential of the proposed image-based tiller counting method to aid agronomists in efficient and non-destructive field phenotypic analysis. This paper focuses on addressing the challenges faced by image processing and prediction classification models in the context of mature real-time image acquisition technology. Specifically, the paper proposes a solution to process images and classify rice diseases using acquired image data.
Currently, rice disease classification faces several challenges: (1) The collected rice leaf images often contain noise and insignificant edge details. If these images are directly used for training without proper preprocessing, the network’s ability to extract rice disease features is greatly weakened, which ultimately leads to low recognition accuracy. (2) Rice exhibits large intraclass diversity and high interclass similarity [
15], evident in diseases such as blast and brown spot. Traditional convolutional neural networks struggle with accurate differentiation, thus requiring improvements in the network model to enhance its feature extraction capabilities [
16].
In order to improve the accuracy of rice disease recognition, image processing is performed on collected rice disease pictures to address the issue of unclear edge details and significant noise. This step is crucial in the overall process of rice disease recognition, as it allows for a more precise and accurate identification of the disease. Image processing techniques such as image enhancement, shadow removal (edge detection), noise elimination, and feature extraction are employed in capturing disease images of rice plant leaves. These processed images are then fed into a classifier for classification [
17]. In their study, Polesel et al. (2000) utilized an adaptive filter that regulates the sharpening path’s contribution. This approach allows for contrast enhancement in high-detail areas while minimizing or eliminating image sharpening in smooth regions. This is referred to as an unsharp masking technique for improving image contrast [
18]. Phadikar et al. (2013) proposed a segmentation method that utilizes Fermi energy to distinguish the infected area of a rice pest image from its background. This method employs new algorithms to extract features such as the color, shape, and location of the infected site to characterize disease symptoms. To minimize information loss and reduce the complexity of the classifier, the researchers utilized rough set theory (RST) to select important features [
19]. The Canny edge detection algorithm has become increasingly popular in image processing in recent years. Several studies have suggested using the Canny operator to enhance edge information in images and improve their clarity. The algorithm, proposed by John Canny in the 1980s, is a multi-level edge detection method [
20]. John Canny focused on identifying the optimal edge, which required detecting edges that closely resembled the actual edge while minimizing noise interference. However, traditional algorithms face difficulty when filtering low-contrast images, as they cannot adaptively determine the filtering threshold or differentiate the target from the background. To address the aforementioned issues, Xuan et al. (2017) proposed an enhanced Canny algorithm. This algorithm utilizes the amplitude gradient histogram to derive two adaptive thresholds and connect edge points to obtain generalized chains. The algorithm calculates the average value of the generalized chains and removes those that fall below it. The image edge detection results are then obtained using a linear fitting method. Experimental results demonstrate that the improved algorithm is more robust to noise and effectively distinguishes the target from the background [
21]. In their 2020 paper, Kalbasi et al. introduced an adaptive parameter selection method. This method uses the estimated noise intensity of the input image and the minimum output performance required for the application to select a value for the Canny parameter from a pre-existing configuration table, rather than calculating it at runtime [
22]. This implementation of the Canny algorithm is adaptive, ensuring high edge detection performance and noise robustness in various situations. Despite this, the execution time of our proposed Canny algorithm is still lower than that of the latest cutting-edge implementation. Wang et al. (2019) proposed an improved gravitational edge detection algorithm that utilizes gravitational field intensity instead of image gradient, along with the introduction of the gravitational field intensity operator. The algorithm also includes an adaptive threshold selection method based on the mean and standard deviation of image gradient amplitude for images with varying levels of edge information. The gravitational edge detection algorithm, which is relatively simple to implement, has been shown to retain more relevant edge information and exhibit stronger anti-noise ability through empirical data analysis [
23]. This paper proposes a Candy image enhancement algorithm (an improvement upon the Canny algorithm) to address the issues of noise and unclear edge details in rice leaf images. The method involves using an ideal high-pass filter and the gravitational edge detection algorithm to extract the edge mask of the rice disease image. Then, a simple detail-enhanced image is produced by combining smooth filtering and a Laplace operator. The proposed method multiplies the output by a mask and adds it to the input image to enhance edge detail. The experimental analysis demonstrates that this method significantly improves the visual effect of the image compared to the original image and homomorphic filtering. Additionally, the method effectively suppresses noise while maintaining image authenticity.
In order to solve the problem of high diversity and similarity among rice diseases, the accuracy of convolutional neural networks in rice disease image classification needs improvement. Lu et al. (2017) introduced a novel approach for identifying rice diseases using deep convolutional neural network (CNN) technology. The proposed model was evaluated using a 10-fold cross-validation strategy and achieved an impressive accuracy of 95.48%, surpassing that of traditional machine learning models. The feasibility and effectiveness of using deep convolutional neural networks to identify rice diseases and insect pests are demonstrated through simulation results of rice disease recognition. However, the success of this approach is contingent upon the availability of large-scale datasets and high-quality rice disease image samples. Additionally, selecting the optimal parameters still requires a significant number of experiments [
24]. Atole et al. (2018) explored the use of deep convolutional neural networks to classify rice plants according to the health of their leaves. They implemented a three-class classifier using transfer learning from the AlexNet deep network, which was able to distinguish between normal, unhealthy, and serpentine plants. The network achieved an accuracy of 91.23% using stochastic gradient descent. These results suggest that commonly used neural networks could still be optimized for rice diseases and insect pests. However, no improvements have been made to tailor the neural network specifically for rice diseases [
25]. Zhou et al. (2019) presented a rapid method for detecting rice diseases using a combination of FCM-KM and Faster-R-CNN fusion techniques. This approach not only enhances the recognition accuracy of the Faster R-CNN algorithm, but also reduces the time required for recognition. The method primarily concentrates on detecting diseases in collected images, which may not be suitable for monitoring large-scale rice cultivation. Furthermore, it also identifies diseases by monitoring the collected images [
26]. Rahman et al. (2020) utilized state-of-the-art large-scale architectures, such as VGG16 and InceptionV3, which were fine-tuned to detect and identify rice pests and diseases. While the experimental results demonstrated the efficacy of these models on real datasets, they were found to be inadequate in detecting and classifying rice pests and diseases in heterogeneous backgrounds [
27]. Wang et al. (2021) presented the ADSNN-BO, an attention-based deep separable Bayesian optimized neural network, as a means of detecting and classifying rice diseases from rice leaf images. The authors suggest that the use of artificial intelligence in the agricultural field can lead to rapid diagnosis and control of plant diseases. However, it is worth noting that their experiments did not utilize public datasets and as such, it may be difficult to promote their findings [
28]. Haque et al. (2022) proposed a method for rice leaf disease classification and detection using YOLOv5 deep learning. The YOLOv5 model was trained and evaluated on a dataset of approximately 1500 photos. The use of a large dataset during training resulted in high accuracy [
29].
While deep learning has demonstrated success in rice disease recognition, there remains room for improvement in recognition accuracy and the need to minimize model training time. To address these challenges, this paper presents the ICAI-V4 model, which offers the following main contributions:
This paper proposes an algorithm for enhancing Candy images. The proposed method involves extracting the edge mask through ideal high-pass filtering and gravitational field intensity operator. The simple detail enhancement image is obtained by combining smooth filtering and a Laplace operator. The resulting image is then multiplied by the mask and added to the input image to obtain a better edge detail enhanced image.
This paper proposes the ICAI-V4 model, which incorporates a coordinated attention mechanism into the backbone network. This enhancement is designed to improve the feature capture ability and overall performance of the network model. The INCV backbone structure incorporates both Inception-iv and Reduction-iv structures, while also integrating involution to enhance the network’s feature extraction capabilities from a channel perspective. This enables the network to better classify similar images of rice pests and diseases. Leaky ReLU is utilized as an alternative to the ReLU activation function to mitigate the issue of neuron death caused by the latter and enhance the model’s resilience.
2. Materials and Methods
2.1. Data Acquisition
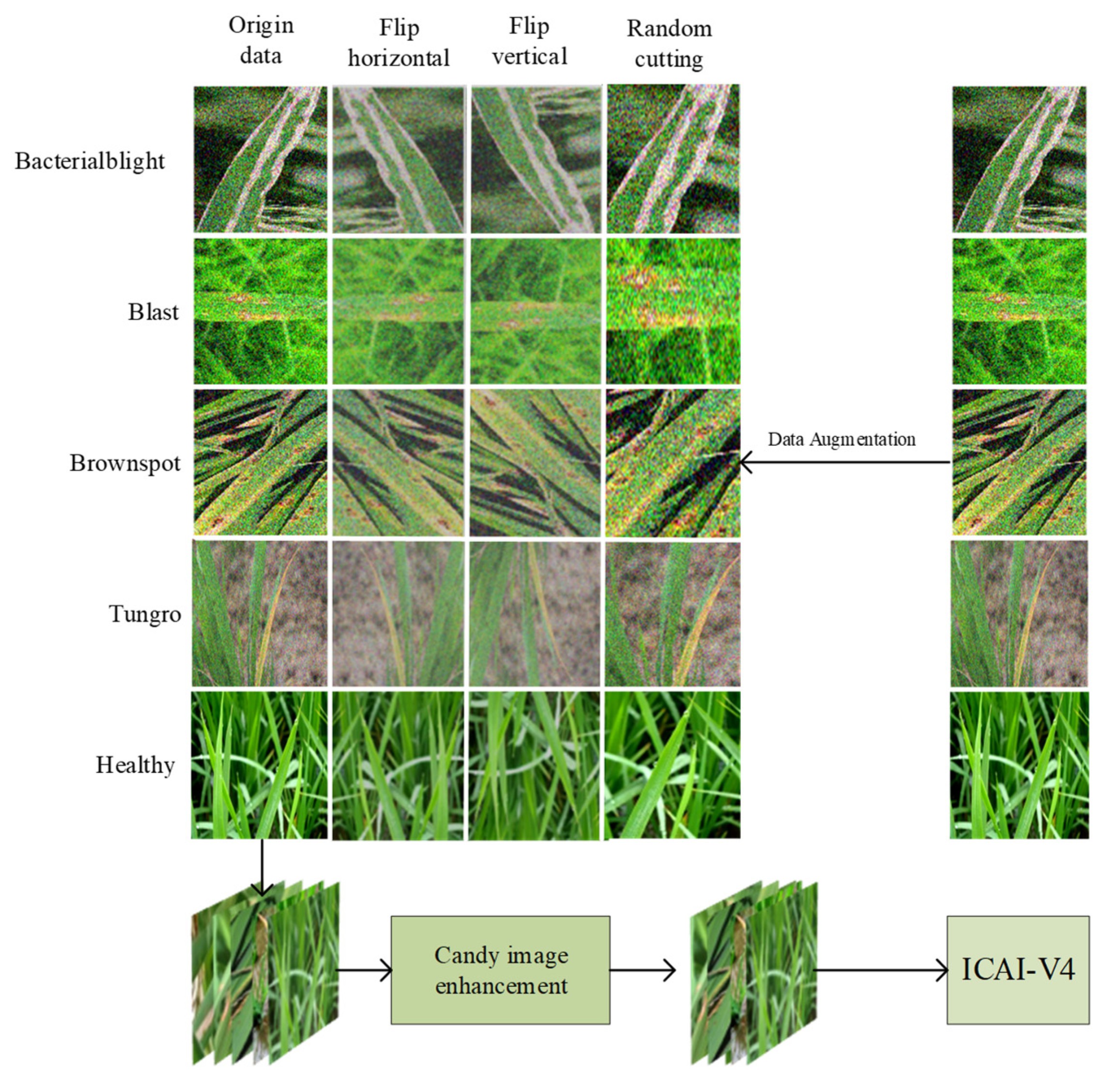
The identification and classification of rice diseases heavily rely on data collection. The datasets used in this study were primarily obtained from open-source platforms such as Kaggle (Rice Leaf Diseases Dataset | Kaggle) and Mendeley Data (Rice Leaf Disease Image Samples—Mendeley Data). The Kaggle platform contributed 3355 rice disease images, while the Mendeley Data platform provided 5932 images. To obtain a large number of datasets for network training and address the issue of duplicated images, various techniques such as deletion, horizontal flipping, vertical flipping, and random cropping were applied after enhancing the collected images. The final result was a dataset of 10,241 images, all saved in jpg format. The distribution and proportion of different types of rice disease images can be found in
Table 1. In
Figure 1, the process of collecting, transmitting, enhancing, and preprocessing rice images is demonstrated. In order to avoid any noise interference, it is important to enhance the image before inputting it into the recognition network. The dataset included various types of rice diseases such as bacterial blight, blast, brown spot, and tungro disease. The images were evenly distributed and randomly divided into training and test sets at a 9:1 ratio. The training set is utilized to train the model, while the test set is used to evaluate the model’s recognition ability. To maintain the objectivity of the results, the test set remains unprocessed. However, the images in the training set are subjected to random rotations, flips, and mirroring to expand the dataset without affecting the results’ objectivity. Additionally, all images in this study were normalized to a size of 299 × 299 to expedite the model training process [
30].
Our self-built dataset focuses on four primary types of rice diseases: bacterial blight, blast, brown spot, and tungro disease. Each disease is characterized by unique symptoms, which are as follows:
Rice bacterial blight is caused by the bacterium Xanthomonas, which produces water-stained lesions starting from the leaf margin a few centimeters from the tip of the leaf and spreading to the leaf base. The affected area increases in length and width, and changes color from yellow to light brown due to dryness [
19].
Rice blast disease is characterized by the appearance of green-gray spots on infected leaves, which are surrounded by dark green borders. As the disease progresses, the spots or lesions become oval or spindle-shaped with reddish-brown borders, and some may even become rhombus-shaped. The lesions can expand and merge, ultimately leading to the complete destruction of the leaves.
Rice brown spot is a fungal disease caused by Bipolaris oryzae that primarily damages the aboveground parts of rice plants, particularly the leaves. It is prevalent in all rice-growing regions, especially when there is a shortage of fertilizer and water, leading to poor growth of the rice. It often occurs in combination with rice blight. The disease causes leaf blight, resulting in reduced 1000-grain weight and an increase in empty grains, which adversely affects the yield and quality of rice. Although the harm of disease in rice production is decreasing with improved fertilization and water conservation, certain areas still experience increased incidence of ear blight in late rice due to prolonged seedling age, resulting in significant harvest losses.
Rice tungro disease causes infected leaves to turn from orange to yellow, with the staining spreading from the tip to the lower part of the leaf. Infected leaves may exhibit a striped appearance and rusty spots, and may contain planthoppers [
17].
This section provides a detailed explanation of image enhancement algorithms and rice disease classification models. To aid in comprehension,
Table 2 presents a list of variables utilized in the following formula.
Table 3 provides an explanation of the abbreviations used in this article.
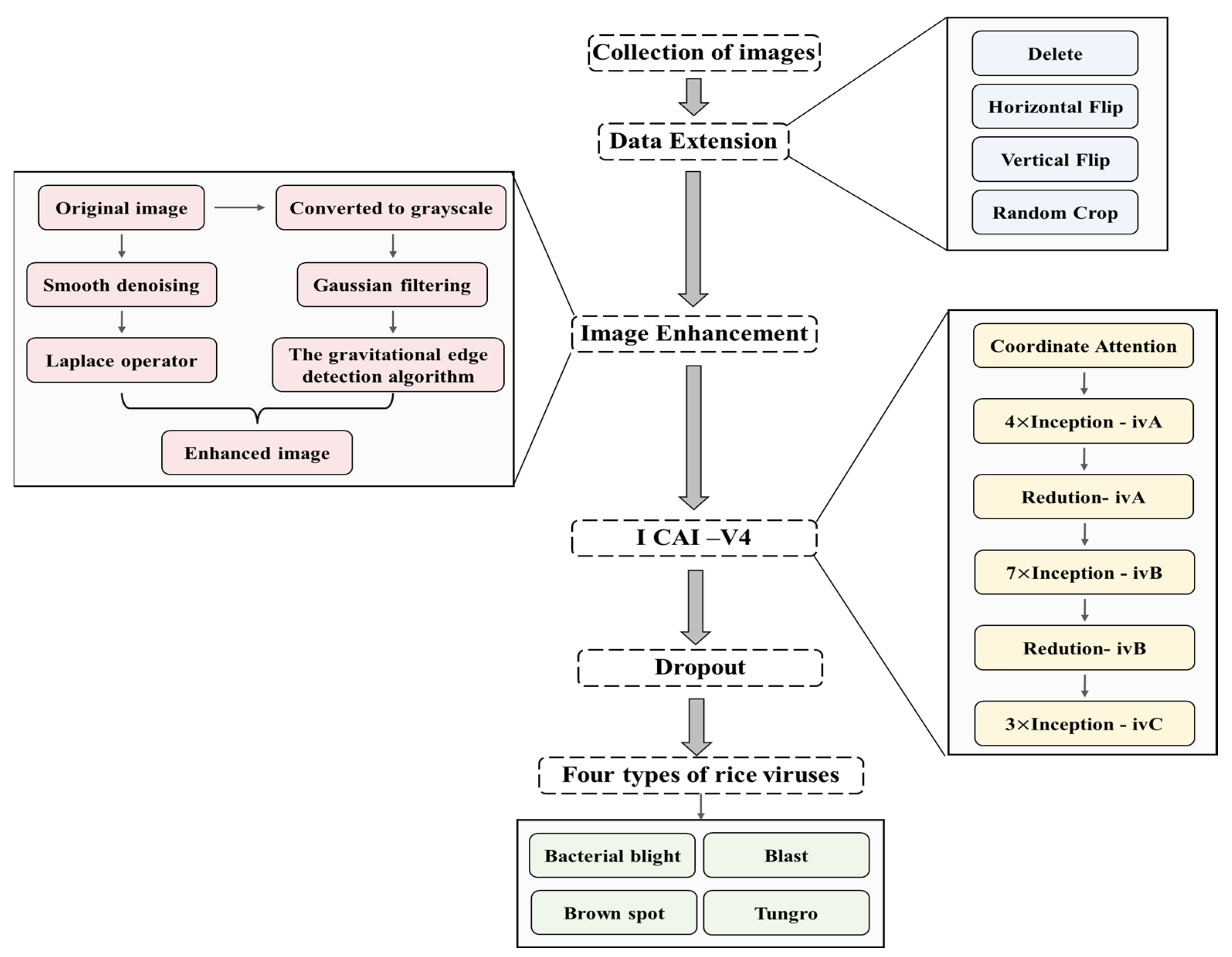
Figure 2 provides a flowchart of the program for this article.
2.2. Candy Image Enhancement Algorithm
The quality of rice disease images can be affected by various factors, such as illumination, resulting in issues such as noise and insignificant edge features. These problems can negatively impact the training and testing of the network, making identification and classification more difficult. To improve the accuracy and reliability of classification after recognition, it is necessary to enhance the image quality. This paper utilizes the Candy image enhancement algorithm to process the images. The algorithm replaces the image gradient used in the traditional Canny operator with gravitational field intensity and implements an adaptive threshold selection method based on standard deviation. The edge enhanced image is obtained by multiplying the initial enhanced image with the mask image, which is obtained through ideal high-pass filtering and gravitational field intensity operator processing. The resulting mask image is then combined with smooth filtering and the Laplacian operator to obtain a simple detail enhanced image. Finally, the edge enhanced image is obtained by adding the mask image multiplied initial enhanced image to the input image. The proposed method results in a visually improved image compared to the original and homomorphic filtering. It enhances edge details while effectively suppressing noise and preserving the authenticity of the image.
The Canny algorithm has long been used for image edge detection. However, it is known to be sensitive to noise, which often results in the loss of weak edge information while filtering out noise. Additionally, its adaptability to fixed parameters is poor. To address these issues, Weibin Rong proposed an improved algorithm based on the Canny algorithm [
31]. In this paper, the algorithm proposes a new concept, gravitational field strength, to replace the traditional image gradient method. The algorithm then introduces the gravitational field strength operator and an adaptive threshold selection method based on standard deviation for images with rich edge information. By implementing these improvements, the Canny algorithm becomes simpler, more efficient in saving useful edge information, and more robust to noise [
21].
The traditional Canny algorithm has the following steps:
The template of the image gradient calculation operator (Equations (4) and (5)) is:
The size and direction of the gradient can be calculated. The image gradient size (Equation (6)) is:
The azimuth of the image gradient (Equation (7)) is:
- 4.
Non-maximum suppression is a technique used to eliminate false edge detections. It involves suppressing pixels whose gradient is not large enough and retaining only the maximum gradient, resulting in thin edges. This classical thin-edge algorithm is applied after obtaining the gradient magnitude image to accurately locate the edge. The Canny algorithm utilizes 3 × 3 adjacent regions, consisting of eight directions to interpolate the gradient amplitude along the gradient direction. If the magnitude is greater than the two interpolation results in the gradient direction, it is identified as a candidate edge point; otherwise, it is marked as a non-edge point. This process generates a candidate edge image.
- 5.
To determine the possible boundary, the double threshold method is applied. Despite non-maximum suppression, there may still be noise points in the image. Therefore, the Canny algorithm employs a technique in which a threshold upper bound and a threshold lower bound are set. The process involves marking pixels with a gradient amplitude higher than the high threshold as edge points and those with a lower gradient amplitude as non-edge points. The remaining pixels are marked as candidate edge points. Candidate edge points connected to edge points are then marked as edge points, reducing the impact of noise on the final edge image.
- 6.
The boundary is tracked using the lag technique. The candidate edge points are re-evaluated and the 8-connected domain pixels of a weak edge point are examined. If there are any strong edge points present, the weak edge point is considered to be retained as part of the edge. However, if there are no strong edge points, the weak edge is suppressed.
The traditional Canny edge detection algorithm has been widely used in practical engineering, but there are still two aspects that require improvement. Firstly, the algorithm uses the first-order finite difference 2 × 2 adjacent region to calculate the image gradient. The lack of deviation in the 45° and 135° directions may cause the loss of genuine edge information. Additionally, setting a fixed value for the double threshold in the traditional Canny algorithm can result in the loss of local feature edge information, especially in images with abundant edge information such as rice pests and diseases. Therefore, the traditional Canny algorithm may not be the most adaptable option for such images. In this paper, the authors propose the use of gravitational field strength as a replacement for image gradient. Additionally, they suggest an adaptive threshold selection method based on standard deviation. These techniques aim to improve the clarity and accuracy of image processing.
The law of universal gravitation is utilized in gravitational edge detection algorithms for image processing. In this method, each pixel is treated as an object with a mass equivalent to its gray value. However, the performance of the gravitational edge detection algorithm varies significantly in bright and dark regions. When pixels are in darker areas with lower quality, their gradients generate less total gravity compared to brighter areas. This causes the gravity method to reduce the correlation of gradient changes in dark regions, leading to a loss of edge points. Therefore, the gravitational field strength is introduced to overcome the difference between the bright and dark regions. The total gravitational field strength generated at a point in the image is a combination of the gravitational field strength generated by the surrounding pixels. In this paper, the obtained gravitational field intensity is understood as an image gradient. If the intensity on a pixel exceeds the threshold, it is classified as an edge point. The formula to calculate the gravitational field strength assigned to the point (Equation (8)) is as follows:
The gradient component in the
X direction (Equation (9)) is:
The gradient component in the
Y direction (Equation (10)) is:
Therefore, the gradient size (Equation (11)) is:
The gradient azimuth (Equation (12)) is:
where
and
are the unit vectors in the horizontal and vertical directions, respectively. In order to retain more edge information, the adjacent region 2 × 2 is extended to 3 × 3.
The gradient component in the
X direction (Equation (13)) is:
The gradient component in the
Y direction (Equation (14)) is:
Therefore, the gradient size (Equation (15)) is:
The gradient azimuth (Equation (16)) is:
The value of the pixel located in the upper left corner of the central pixel is represented by . Moving clockwise around the central pixel, the values of the pixels in the adjacent positions are represented by , , ….
The image of rice diseases and insect pests contains rich edge information and a scattered gradient amplitude distribution. However, due to the inconsistent contrast of each part of the image and the relatively large standard deviation of the image gradient, selecting a double threshold for the entire image is not sufficient for completing edge detection. This is because some edge regions with a small gradient magnitude will have a selected threshold that is too high, resulting in the loss of detailed edges. This study proposes a method for selecting double thresholds for each pixel. The first step involves calculating the average value of the gradient size of the entire image
(Equation (17)).
If the gradient size of the pixel
is less than 15–20% of the average gradient amplitude (
), it will be classified as a non-edge point. This step is crucial in preventing the algorithm from introducing more noise in areas with fewer edges, such as those with small average gradient amplitude and standard deviation, in rice pest images. To determine the threshold of pixel
, the average and standard deviation of the gradient sizes of an N × N matrix are calculated. N is an odd number and is typically greater than 20. The center of the threshold is the pixel
. The pixel threshold (Equation (18)) can then be obtained by:
To obtain the threshold for each pixel in the boundary region of an image with a matrix less than N × N, the insufficient part is first set to empty. The mean and standard deviation of the matrix are then calculated. This process results in each pixel having its corresponding double threshold, which can be used to detect and connect the edges of the entire image [
32].
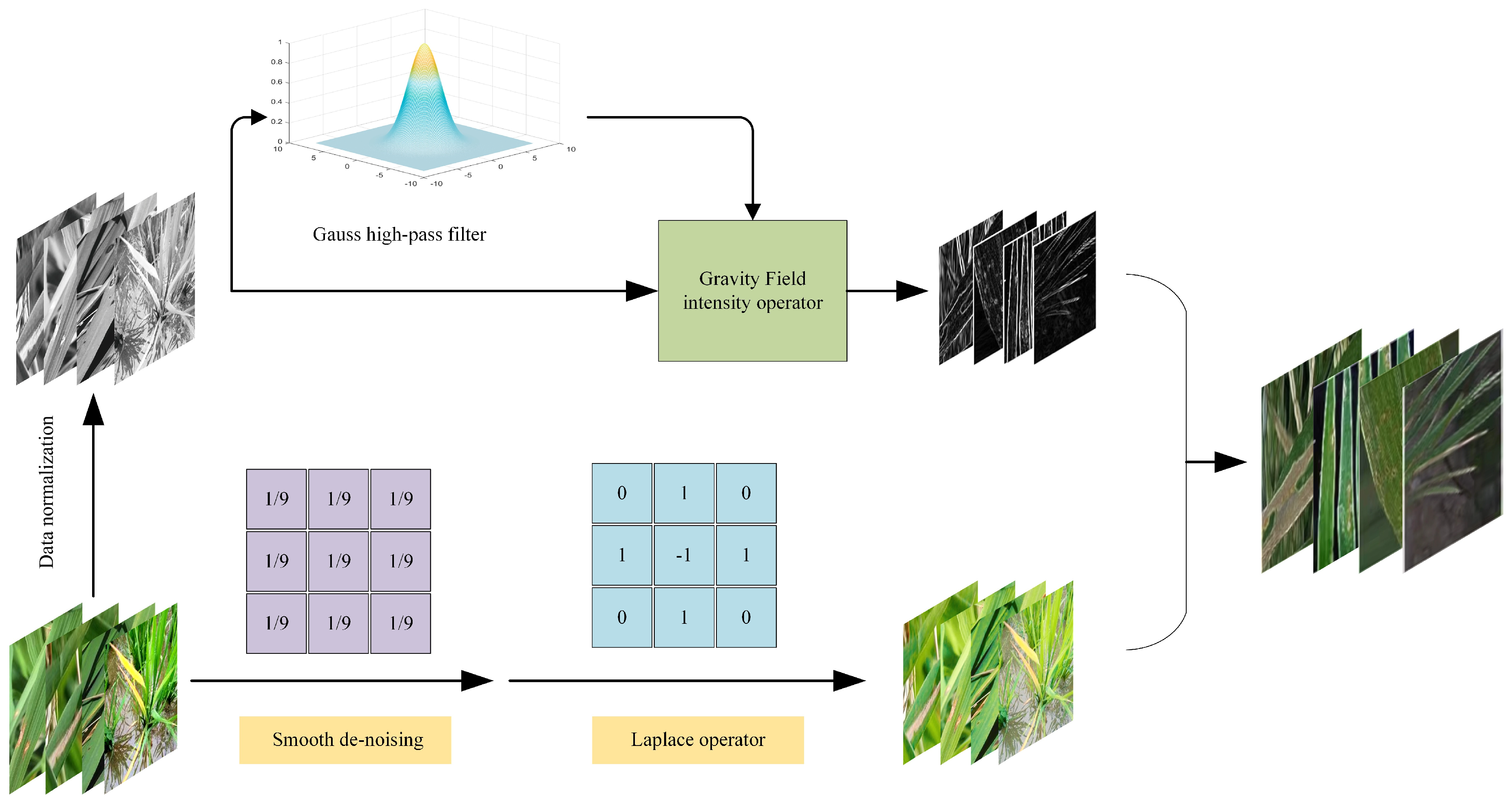
The Candy image enhancement algorithm follows a specific process, which is illustrated in
Figure 3:
The first step in the list number image processing pipeline involves preprocessing the original image. This includes normalization and conversion to grayscale if the original image is in color. The resulting normalized and grayscale image is then used as input for the subsequent steps.
The process of extracting the mask and detail enhancement images involves two steps. Firstly, the input image is processed using the improved canny algorithm to extract the edge details. The detected image edge information is then utilized as the mask. In the second step, the input image undergoes a process of smoothing and denoising. To deal with the noise, the Laplace operator is used, which can have a strong response to the noise and cause negative effects. Therefore, denoising processing should be carried out prior to using the Laplacian operator. This allows the denoised image to better highlight small details in the image.
A preliminary detail-enhanced image can be obtained by adding the result of the Laplacian operator to the input image. However, since the Laplacian operator is isotropic, it detects isolated points effectively, but may cause loss of the edges of the square. Therefore, further operations are required to preserve the information.
To extract the image well, the processed mask image is multiplied with the preliminary enhanced image. The image enhancement algorithm results from adding the edge and detail information to the input image [
33].
The rice leaf image was processed using the Candy image enhancement algorithm, as depicted in
Figure 4.
2.3. Identification of Rice Diseases Based on ICAI-V4 Model
In the field of rice pest and disease identification, leaf images exhibit significant intra-class diversity and inter-class similarity. To overcome this challenge, it is crucial to enhance the feature extraction capability of convolutional neural networks. This can be achieved by obtaining more detailed features and reducing the false positive rates. Deep convolutional networks have been instrumental in significantly improving image recognition performance in recent years and are therefore considered the core of this advancement. The Inception-V4 architecture has demonstrated impressive performance while requiring relatively low computational resources. This paper selects the Inception-V4 model as the primary component of the neural network framework. To ensure that the entire model can be stored in memory, the model was divided into six subnetworks and trained accordingly. The Inception architecture offers a high level of tunability, allowing for numerous adjustments in the number of filters per layer without compromising the quality of the fully trained network. Each subnetwork is inspired by traditional image filtering techniques and boasts two key features that contribute to its appeal and widespread use: spatial agnosticity and channel specificity. The convolution kernel’s ability to adapt to different visual modes in different spatial locations is limited, which raises questions about its flexibility for different channels.
To address the limitations mentioned above, this paper proposes a modification to the Inception blocks by incorporating involution to the subnetwork structure. This operation possesses symmetrical inverse inherent characteristics, which enhance flexibility across different channels and improve the network’s learning effect compared to convolution [
34]. To address the issue of neuron death caused by the ReLU function, the Leaky ReLU activation function is utilized. Furthermore, coordination concerns are integrated into the backbone network to enhance the overall performance. The proposed method has the ability to capture not only cross-channel information, but also direction-aware and location-sensitive information. This feature helps the model to identify and locate objects of interest more accurately and enhance features by emphasizing information representation.
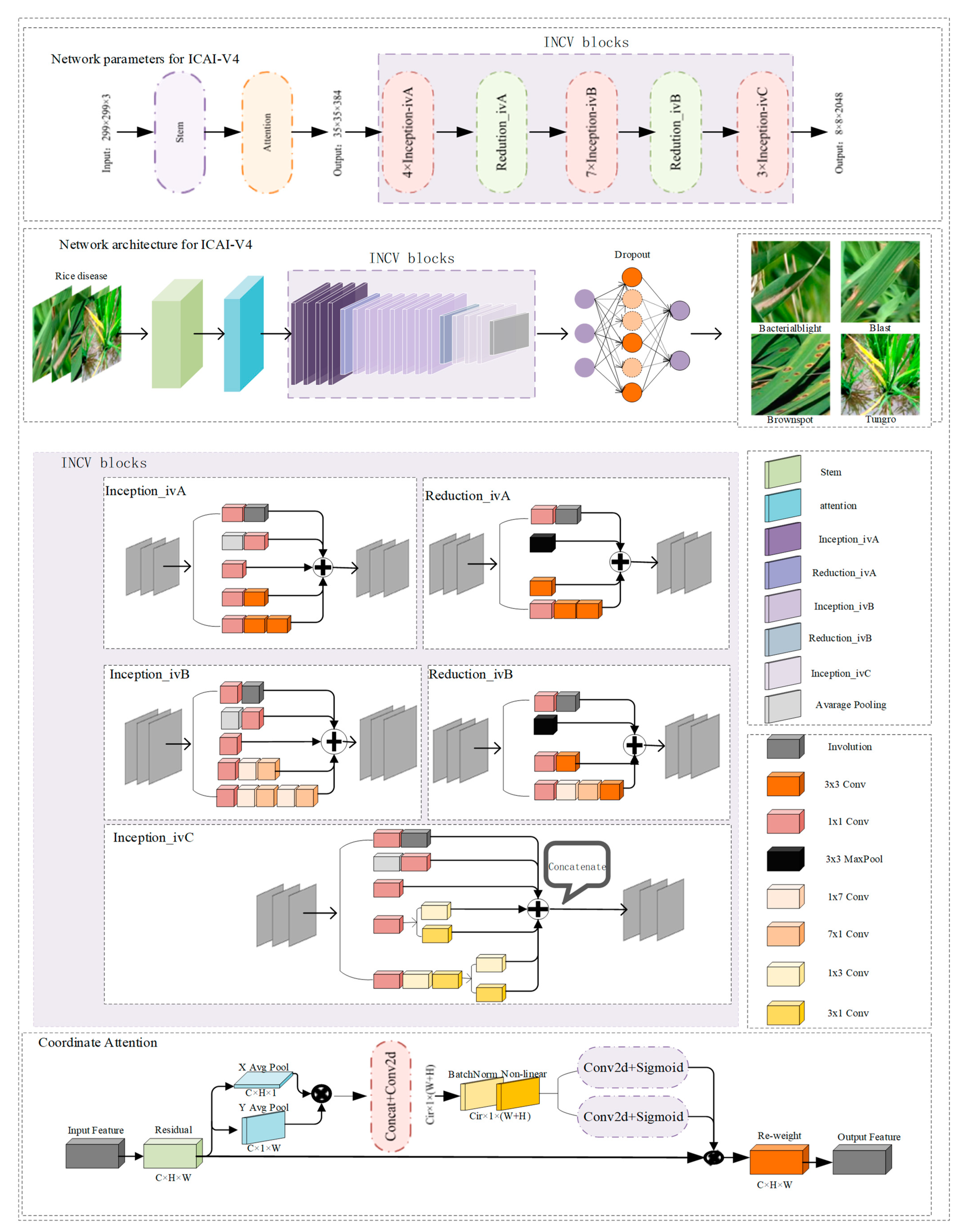
The ICAI-V4 network structure boasts excellent feature extraction capabilities and robustness. This results in improved accuracy in recognizing and classifying similar disease features, while also reducing the model’s running time. The structure comprises a backbone module, a coordination attention module, an INCV structure, an average pooling layer, a discard layer (with a keep probability of 0.8), and a classification block. The network structure of ICAI-V4 is illustrated in
Figure 5. The primary workflow can be summarized as follows:
The initial layer of ICAI-V4 is the Stem layer, which primarily serves to rapidly decrease the resolution of the feature map. This reduction in resolution allows for subsequent inceptions to decrease the amount of computation required. Additionally, the activation function of the standard convolution layer has been modified from ReLU to Leaky ReLU, which enhances the network’s robustness.
The second module in ICAI-V4 is the coordination attention module. This module is capable of capturing cross-channel information, as well as direction-aware and position-sensitive information. This enables the model to more accurately locate and identify objects of interest and enhance features by emphasizing information representation.
The third component of ICAI-V4 is the INCV structure, which consists of 1 × 1 convolution, 3 × 3 convolution, pooling layer, and asymmetric convolution decomposition. The involution layer is incorporated into various structures to enhance the flexibility of different channels and improve the overall network learning effect. The network comprises three Inception-iv structures and two Reduction-iv structures used multiple times. Refer to
Figure 5 for a detailed illustration of the specific structure.
ICAI-V4’s fourth component consists of an adaptive pooling layer, data dimensionality reduction, linear layer, and a discard layer. The classification results of input rice pest images are determined by a softmax activation function.
2.3.1. Coordinate Attention
In order to enhance the effectiveness of the model’s performance, this paper proposes the addition of a coordinated attention mechanism to the backbone network of Inception-V4. The attention mechanism is divided into two modules: channel attention and spatial attention. While channel attention has proven to be effective in improving model performance, it often disregards location information. In their recent study, Hou et al. (2021) introduced a novel approach to mobile network attention mechanisms, termed ‘coordinate attention’. This method involves incorporating location data into channel attention, resulting in improved network performance [
35].
In coordinating attention using two 1D global pooling operations, input features along the vertical and horizontal directions are aggregated into two separate directional software feature maps. These feature maps, which contain embedded direction-specific information, are then encoded into two attention graphs. Each attention graph captures the long-distance correlation of the input feature map along a spatial direction. The proposed attention method, named coordinate attention, can save location information in the generated attention map [
36]. This allows for the application of two attention maps to the input feature map through multiplication, resulting in an emphasized representation of interest. The operation of this method distinguishes spatial directions and generates a coordinate-aware attention map. Coordinated attention not only captures cross-channel information, but also direction-aware and position-sensitive information. This additional information aids the model in accurately identifying and locating objects of interest [
37].
A coordinate attention block serves as a computing unit that amplifies feature expression in mobile networks. It takes an intermediate characteristic tensor as input and outputs with the same size and enhanced representation, achieved through transformation.
The global pooling method is often utilized for encoding channel attention and spatial information. However, it can be challenging to retain location information since it compresses global spatial information into channel descriptors. To address this issue, the coordinate attention method decomposes global pooling into one-to-one feature encoding operations (Equation (19)). This allows the attention module to capture remote spatial interactions with accurate location information [
38].
In order to encode each channel in input
X, a pooled kernel of size (
H, 1) or (1,
W) is utilized along the horizontal and vertical coordinates. This results in the output of channel c with height h being expressed as (Equation (20)):
Similarly, the output of channel c with width w can be written as (Equation (21)):
The above two transformations generate feature maps along two spatial directions, enabling the attention module to capture long-term dependencies along one direction and preserve accurate location information along another. This aids the network in more precise target localization.
After the information embedding transformation, the resulting output is concatenated with another transformation, and then passed through the convolution transformation function (Equations (22)–(24)).
Finally, the output
Y of the coordinate attention block (Equation (25)) can be written as:
The specific structure of coordinate attention, which is added to the backbone network in this paper, aims to improve the model’s performance and feature grasping ability. This can be seen in
Figure 5.
2.3.2. INCV Blocks
The high intra-class diversity and inter-class similarity of rice leaf diseases require the network model to effectively extract feature information, thus improving the accuracy and efficiency of the model. Despite the rapid development of neural network architecture, convolution remains the backbone of deep neural network construction. The convolution kernel, inspired by classical image filtering methods, has two significant characteristics that contribute to its popularity and effectiveness: spatial agnosticity and channel specificity. While the concepts of spatial agnosticism and spatial compactness may seem beneficial in terms of increasing efficiency and explaining translation equivalence, they may limit the adaptability of convolution kernels to varying visual modes in different spatial locations. This raises concerns about the ability of convolution kernels to flexibly adjust to different channels.
In their recent paper, Li et al. (2021) introduced involution as a potential solution to address the limitations of convolution [
34]. Involution offers symmetrical inverse characteristics that are space specific and channel-unknown. This means that the involution cores are unique to each spatial location, but shared across channels. If the involution kernel is parameterized into a fixed-size matrix, such as a convolution kernel, and updated using a back-propagation algorithm, it may not be able to transmit between input images with varying resolutions due to its space-specific properties. To address variable feature resolution, the involution kernel for a specific spatial position can only be generated when the corresponding position’s incoming feature vector is present. This approach is intuitive and effective. Additionally, Involution reduces core redundancy by sharing involution cores along the channel dimension. The computational complexity of the involution operation increases in a linear fashion as the number of feature channels increase. This means that the dynamic parametric involution kernel is capable of covering a wide range of spatial dimensions. Reverse design allows for two advantages with involution: (i) it can summarize context in a wider spatial arrangement, overcoming the challenge of effectively modeling long-distance interaction; (ii) involution can assign adaptive weights to different locations to prioritize visual elements with the most information in the spatial domain [
39].
In contrast to convolution, involution involves sharing the kernel in the channel dimension while utilizing a space-specific kernel for more adaptable modeling in the spatial dimension. The size of the involution kernel (Equation (26)) is:
where
H and
W denote their height and width,
K is kernel size, and
denotes that all channels share G kernels. In the context of involvements, the fixed weight matrix is not utilized as a learnable parameter, unlike in convolution. Instead, the involvements kernel is generated based on the input feature mapping to ensure the automatic alignment of kernel size and input feature size in the spatial dimension [
40]. Unlike the convolution kernel, the shape of the involution kernel
depends on the shape of the input feature map. A natural idea is to generate an involution kernel based on the original input tensor, so that the output kernel and the input are easily aligned. We express the kernel generating function as ∅, and abstract the function mapping at each position
(Equation (27)) as [
34]:
where
is an index set of the neighborhood of coordinates
, and
represents a patch containing
on the feature map.
The output feature map of the involution is obtained by performing a multiplicative addition operation on the input with such an involution kernel (Equation (28)). The definition is as follows:
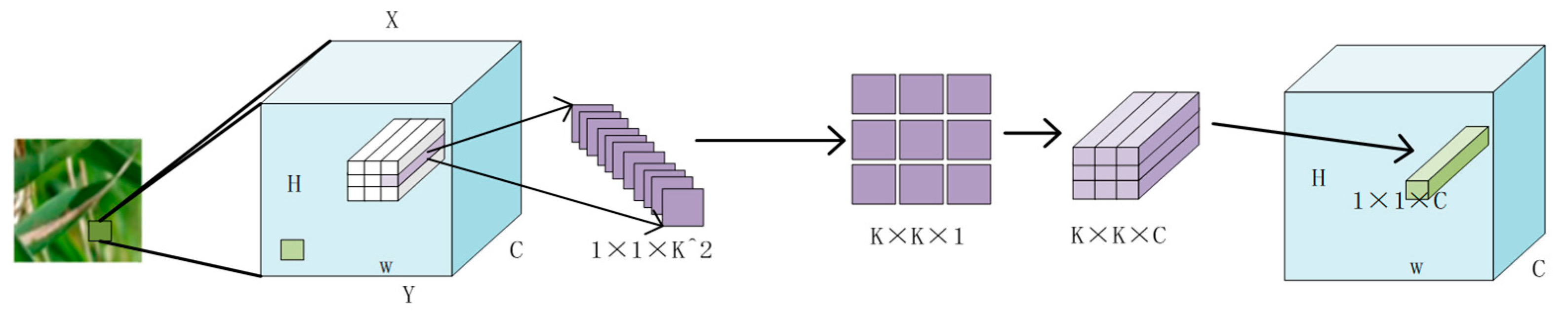
Figure 6 displays the complete involution diagram, depicting the process of generating the involution convolution kernel and subsequently producing a new feature diagram. In this method, the representation of a pixel of size 1 × 1 × C is reduced to C/r through linear change, where
r represents the reduction ratio. This is then changed to K × K × G, which is involution kernels. When
G is 1, the K×K×1 kernel is multiplied with the pixels in the K × K field of the current pixel in the original feature map, and repeated on
C channels to obtain the three-dimensional matrix of K × K × C. The width and height of the three-dimensional matrix are summed in two dimensions, while the channel dimension is retained. This generates a 1 × 1 × C vector in the sex feature diagram, where the value of
C channels in a pixel position is generated at once.
The involution kernel is created using a function φ that takes a single pixel at (i, j) as a condition and rearranges the channel to space. The multiplication and addition operations of the involution are divided into two steps. The product operation multiplies the tensors of C channels with the involution kernel H, respectively, while the addition operation adds the elements within the involution kernel to the involution kernel.
Involution has the following advantages over convolution:
Sharing kernels on the channel improves performance by allowing us to use large spatial spans while maintaining design efficiency through the channel dimension. This is true even if weights are not shared in different spatial locations, as it does not significantly increase the number of parameters and calculations.
While the kernel parameters of each pixel in the space are not directly shared, involution does share meta-weights at a higher level, specifically the parameters of the kernel generating function. This allows us to still share and migrate knowledge across different spatial locations. However, freeing the limitation of the convolution sharing kernel in space and allowing each pixel to learn its corresponding kernel parameters does not necessarily lead to better results, despite addressing the issue of large parameter increase.
The Inception-V4 model is trained in a partitioned manner, consisting of six subnetworks. The Inception architecture is highly flexible, with each subnetwork incorporating multiple branches inspired by classical image filtering methods. These branches exhibit spatial agnosticity and channel specificity, allowing for effective feature extraction. The convolution kernel’s ability to adapt to different visual modes in different spatial locations is limited, which questions its flexibility for different channels. Involution, on the other hand, is capable of modeling long-distance interactions and is sensitive to channel information. This paper proposes enhancements to the inception and reduction structures in the backbone network infrastructure of Inception-V4. The subnetworks now include a 1 × 1 convolution and an involution layer, which enhances the network’s ability to extract features from channel perspectives. As a result, it can better classify similar images of rice pests and diseases. To better fit the Inception architecture, a 1 × 1 convolution is added to adjust the input and output parameters. After adding this convolution and Involution layer to the structure, the model’s accuracy is shown, as in
Table 4. The results demonstrate that the proposed INCV structure has higher accuracy and is more suitable for rice pest classification [
40].
2.3.3. Leaky ReLU
The ReLU function is a commonly used activation function in deep learning. Its expression is (Equation (29)):
The ReLU function has the following characteristics:
When the input is positive, there is no gradient saturation problem.
The calculation speed is much faster. There is only a linear relationship in the ReLU function, so its calculation speed is faster than the Sigmoid function and the tanh function [
41].
The Dead ReLU problem arises when the input to the ReLU activation function is negative, rendering it completely invalid. This is not a concern during forward propagation as only certain areas are sensitive to negative input. However, during back propagation, if a negative number is encountered, the gradient will be zero, resulting in non-convergence of calculation results and neuronal death. This prevents weight updates, leading to the problem of non-updating neurons.
The output of the ReLU function is zero or positive, which means that the ReLU function is not a zero-centered function.
To address the Dead ReLU problem associated with the ReLU activation function, this paper proposes the use of Leaky ReLU. The proposed activation function is depicted in the accompanying figure. The expression for Leaky ReLU (Equation (30)) is:
The parameter ‘a’ is randomly generated during model training and eventually converges to a constant value. This process enables one-sided suppression while retaining some negative gradient information to prevent complete loss.
The Leaky ReLU function has the following advantages:
Some neurons will not die. The Dead ReLU problem of the ReLU function is solved;
The linear and unsaturated form of Leaky ReLU can converge quickly in SGD;
The Leaky ReLU function has a faster calculation speed compared to the sigmoid and tanh functions. This is because it has a linear relationship and does not require exponential calculations. Nonlinearity typically requires more computation and thus results in slower execution speeds.
2.4. Evaluating Indicator
This paper examines the classification of rice diseases and evaluates model performance using indicators such as accuracy, precision, recall rate, F1 score, and ROC/AUC.
Assuming that all images categorized under rice blast disease are positive samples, the remaining disease images are considered negative samples and do not belong to the rice blast disease category. The study focused on the category of rice blast and used it as an example. TP, which stands for true positive, refers to rice images that were accurately classified as having rice blast disease and were placed in the correct category. FP (false positive) refers to incorrectly predicting a rice image with other diseases as rice blast disease. TN (true negative) refers to predicting an image of rice with other diseases as belonging to their respective categories. FN (false negative) refers to mistakenly predicting an image of rice with rice blast disease as belonging to another disease category.
Table 5 displays the structure of the confusion matrix using a binary task as an example.
Accuracy (Equation (31)) is defined as the ratio of correctly classified samples to the total number of samples, expressed as a percentage. It is a commonly used metric to evaluate the performance of a classification model:
The accuracy rate (Equation (32)) is a metric that measures the proportion of correctly predicted positive samples out of all of the samples that are predicted to be positive by the model:
Recall rate (Equation (33)), also known as sensitivity or true positive rate, is a measure of the proportion of actual positive samples that are correctly identified as positive by a prediction model. In other words, it is the ratio of true positives to the sum of true positives and false negatives [
30]:
The
F1 score (Equation (34)), also known as the
F-score or
F-measure, is a measure of a test’s accuracy. It is calculated as a weighted average of the precision and recall, which are measures of the test’s ability to correctly identify positive results and correctly exclude negative results, respectively. The formula for calculating the
F1 score is:
4. Discussion
The effectiveness of ICAI-V4 in identifying rice leaf diseases was assessed and compared to other well-known networks including AlexNet [
46], ResNet-50 [
47], ResNeXt-50 [
48], Inception-V4 [
49], MobileNet-V2 [
50], and DenseNet-121 [
44]. The results presented in
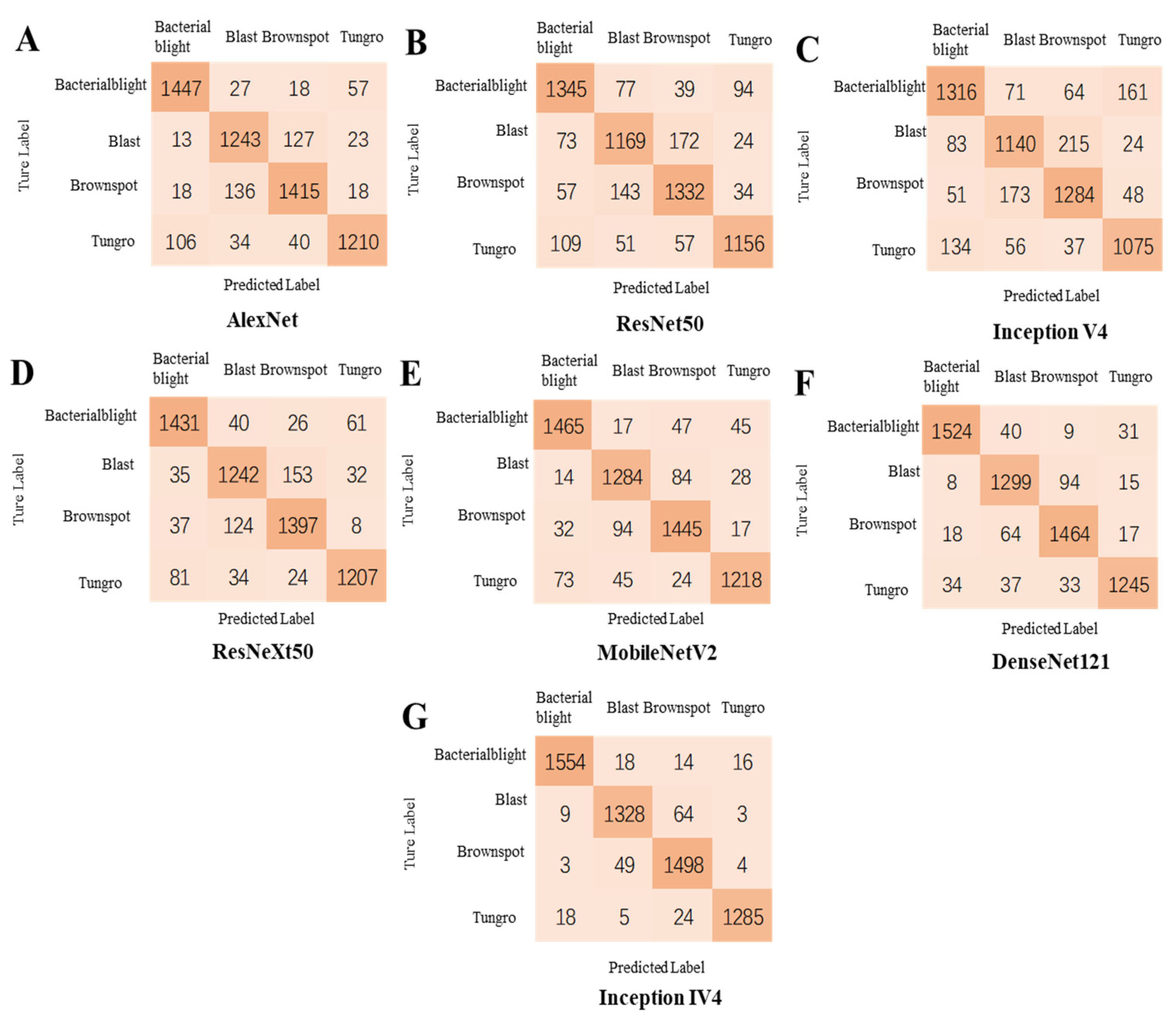
Table 10 demonstrate that ICAI-V4 outperformed the traditional mainstream networks in terms of recognition rate for the four rice diseases in the dataset. AlexNet employs dropout regularization to mitigate overfitting in its fully connected layers. To preserve the most salient features, maximum pooling is preferred over average pooling to avoid blurring effects. Furthermore, AlexNet suggests using a stride length smaller than the pooling kernel size to achieve overlap and coverage between the pooling layer outputs, thereby enhancing feature richness and minimizing information loss. The calculation process is straightforward and the convergence speed is rapid. However, the recognition accuracy is limited to 93.41%, 88.4%, 89.16%, and 87.05%. The ResNet-50 deep residual network addresses the issues of low learning efficiency and ineffective accuracy improvement caused by increasing network depth to some extent. While using a deep network layer can be beneficial, it can also result in the selective discarding of some layers, leading to information blocking and decreased recognition accuracy. In this particular case, the recognition accuracy was measured at 86.49%, 81.29%, 85.05%, and 84.19%. ResNeXt-50, a modification of ResNet-50, widened the network and improved its robustness and identification accuracy (91.84%, 84.95%, 89.20%, 89.67%). The network achieved better identification results for four rice leaf diseases compared to ResNet-50 (+5.35%, +3.66%, +4.15%, +5.48%). However, this improvement came at the cost of a significant increase in parameters and a decline in recognition efficiency. Inception-V4 is designed with a sparse network architecture, allowing it to perform well even with limited memory and computational resources. Its performance is impressive, achieving up to 81.63%, 77.97%, 82.51%, and 82.56%. On the other hand, MobileNet-V2 is a network that utilizes deeply separable convolution and shortcuts. The model utilizes Inverted Residuals and Linear Bottlenecks, resulting in a fast training process and a low number of parameters. While the network layer is not as deep, its recognition accuracy is lower (93.07%, 91.06%, 90.99%, 89.55%). On the other hand, DenseNet-121 employs a dense connection structure that imports the output of each layer into all subsequent layers, effectively reducing the number of parameters in the network. The use of a dense connection structure can effectively address the issues of gradient disappearance and parameter sparsity, resulting in improved generalization ability and model accuracy. In fact, the model achieved an accuracy of (95.01%, 91.73%, 91.50%, 95.18%). The study found that while MobileNet-v2 and Densenet121 had higher recognition accuracy for rice diseases, the ICAI-v4 proposed in the paper achieved even higher accuracy rates of (97.54%, 93.38%, 94.98%, 97.34%) in rice disease classification. The paper provides a summary of the reasons why ICAI-V4 is superior to other mainstream networks.
This study utilized the Candy algorithm to enhance images prior to input classification. The results, as shown in
Figure 3, demonstrate that this method significantly improves the visual quality of images compared to traditional filtering methods. The algorithm enhances edge details while suppressing noise, which maintains the authenticity of the image. The results of
Table 7 indicate that the classification accuracy of the model for rice diseases improved by 5.21% when using this method compared to no image enhancement.
This academic paper introduces a coordinated attention mechanism into the backbone network to enhance the feature capture capability and overall performance of the network model. The experiment in
Table 8 shows that the classification accuracy of Inception-V4, AlexNet, and ResNeXt for rice diseases improved after the addition of the coordinated attention mechanism (+7.79%, +1.57%, +2.14%).
The INCV trunk structure is a combination of Inception-iv and Reduction-iv structures, with the addition of involution to enable more flexible modeling in spatial dimensions. This approach also incorporates a channel dimension shared kernel with a space-specific kernel to enhance the feature extraction capability of the entire network. As a result, the classification of similar rice disease images is improved. This paper incorporates involution into Inception-V4 and conducts experiments by adding involution to each part. The results, presented in
Table 4, demonstrate that this matching enhances the network’s feature extraction ability and improves its classification accuracy (81.27%, 82.51%, 82.93%, 85.14%, 85.94%, 87.74%).
The use of Leaky ReLU as a replacement for the ReLU activation function has been shown to alleviate the problem of neuron death caused by the latter, while also enhancing the model’s elasticity. In fact,
Table 8 demonstrates that changing the activation function to Leaky ReLU resulted in a 2.87% improvement in the classification accuracy of rice diseases.
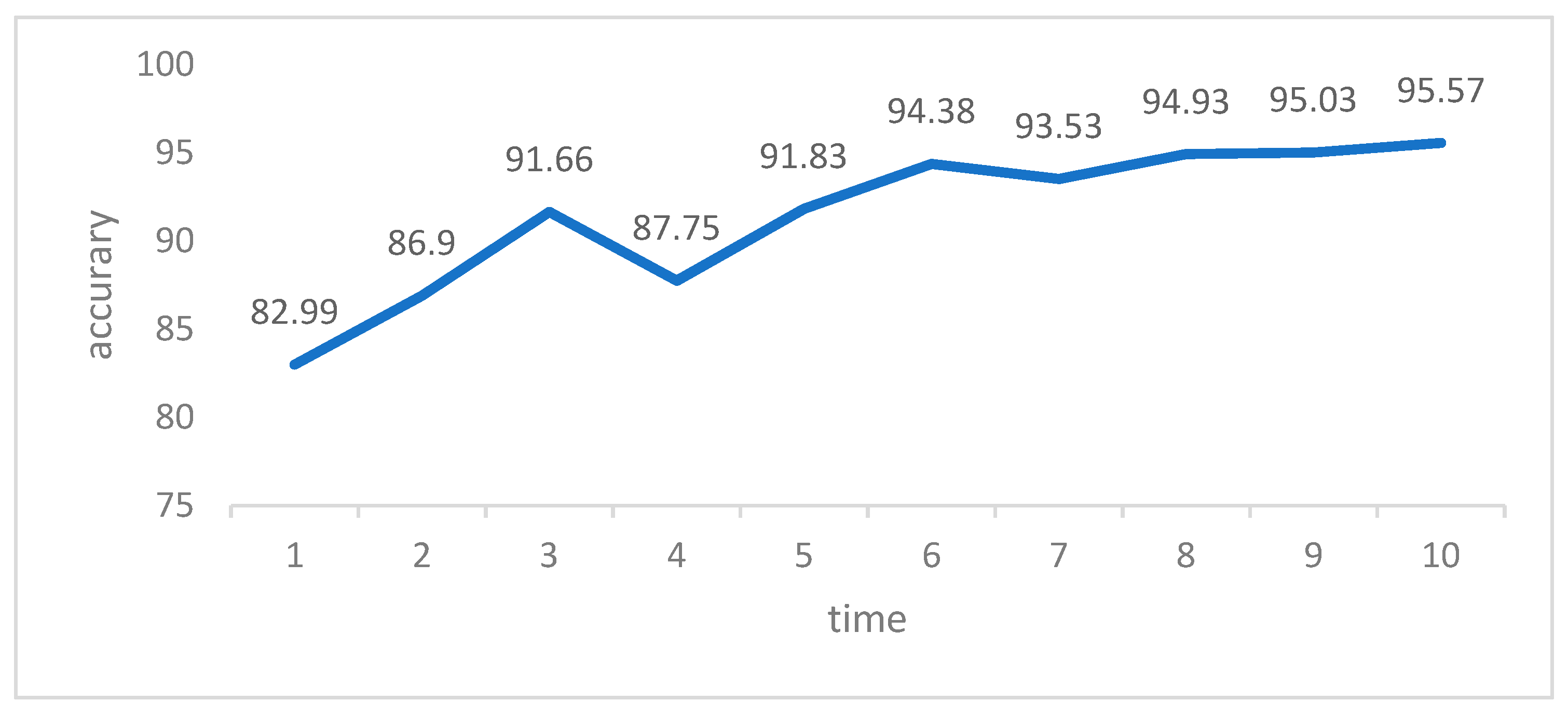
According to our research, this method has shown superior classification accuracy compared to other deep neural network models. The average accuracy is 95.57%, with a recall rate of 95.54% and an F1-score of 95.81%.
Although existing methods for detecting rice disease are effective, they may not be as accurate when the diseased leaves are in the early stages and their characteristics have not fully developed. Additionally, the automatic detection of rice disease has not been widely implemented and real-time dynamic detection has not been thoroughly researched. Current methods mainly focus on detecting disease in collected images. Further research is required to determine how this method can be applied to the large-scale detection of rice planting and disease dynamics. For the future, in the process of promoting this method, it is necessary to combine intelligent Internet facilities such as agricultural Internet of Things and mobile terminal processors to realize the real-time monitoring of grain storage and pest identification, which is conducive to promoting the modernization and intelligence of the agricultural industry.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}