The Stochastic Stationary Root Model


Abstract
:1. Introduction
- i
- introduce and study the SSR model, and
- ii
- propose a method for approximate frequentist estimation and inference.
2. The Model
3. Properties of the Process
3.1. The Unobserved Components
3.2. The Observed Process
4. Likelihood-Based Estimation and Inference
- 1.
- as , with ,
- 2.
- as , with , and
- 3.
- ,
5. The Incomplete Data Framework
5.1. The State Space Form and the Optimal Filtering Problem
5.2. The Sample Score and Observed Information as Smoothing Problems
6. Particle Filter-Based Approximations
6.1. Particle Filtering
| Algorithm 1: Locally Optimal Particle Filter. |
Given a parameter , initialize by setting and for . For :
|
6.2. The Approximate Sample Score and Observed Information Matrix
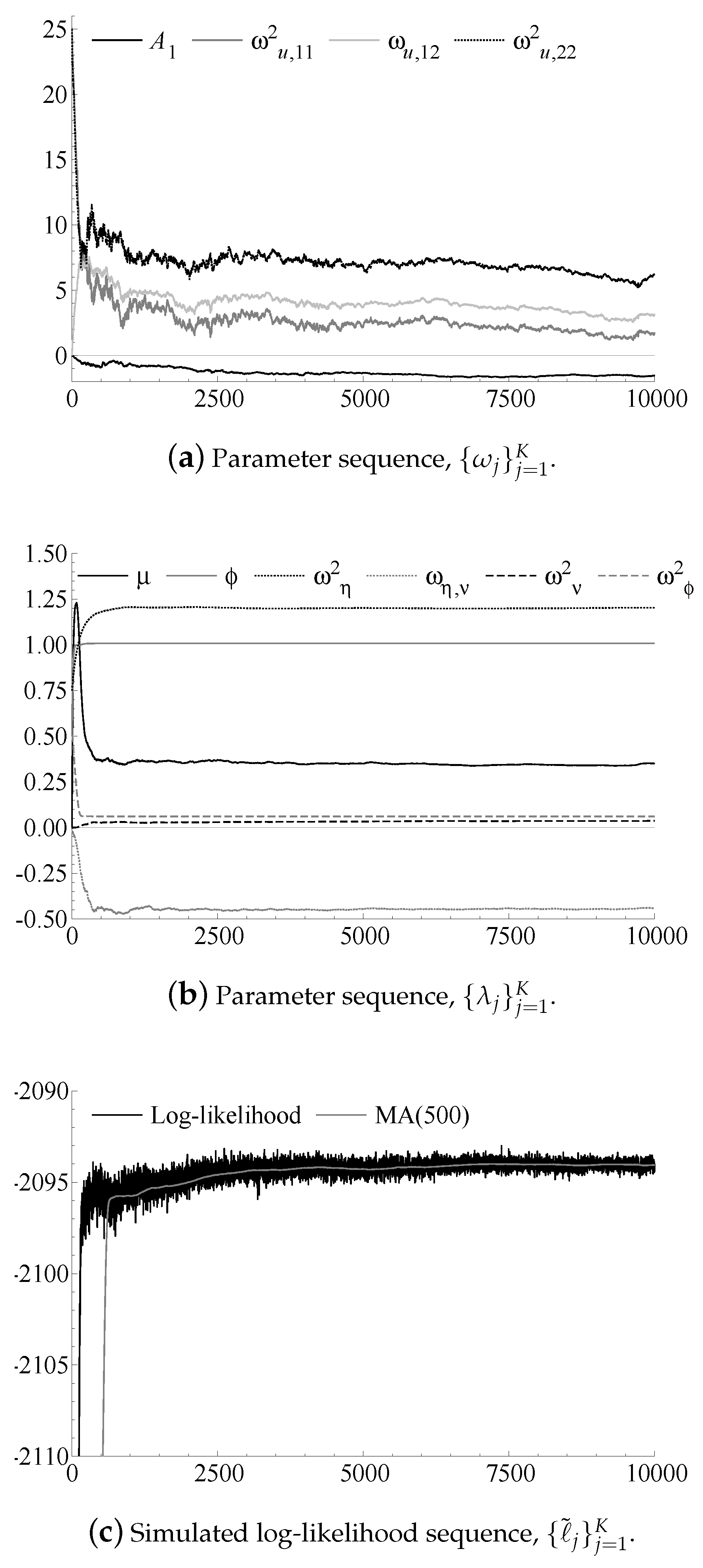
7. Particle Filter-Based Estimation and Inference
| Algorithm 2: Stochastic Approximation. |
Choose the initial parameter , the particle counts , the step sizes and weighting matrices . For :
|
8. Model Diagnostics
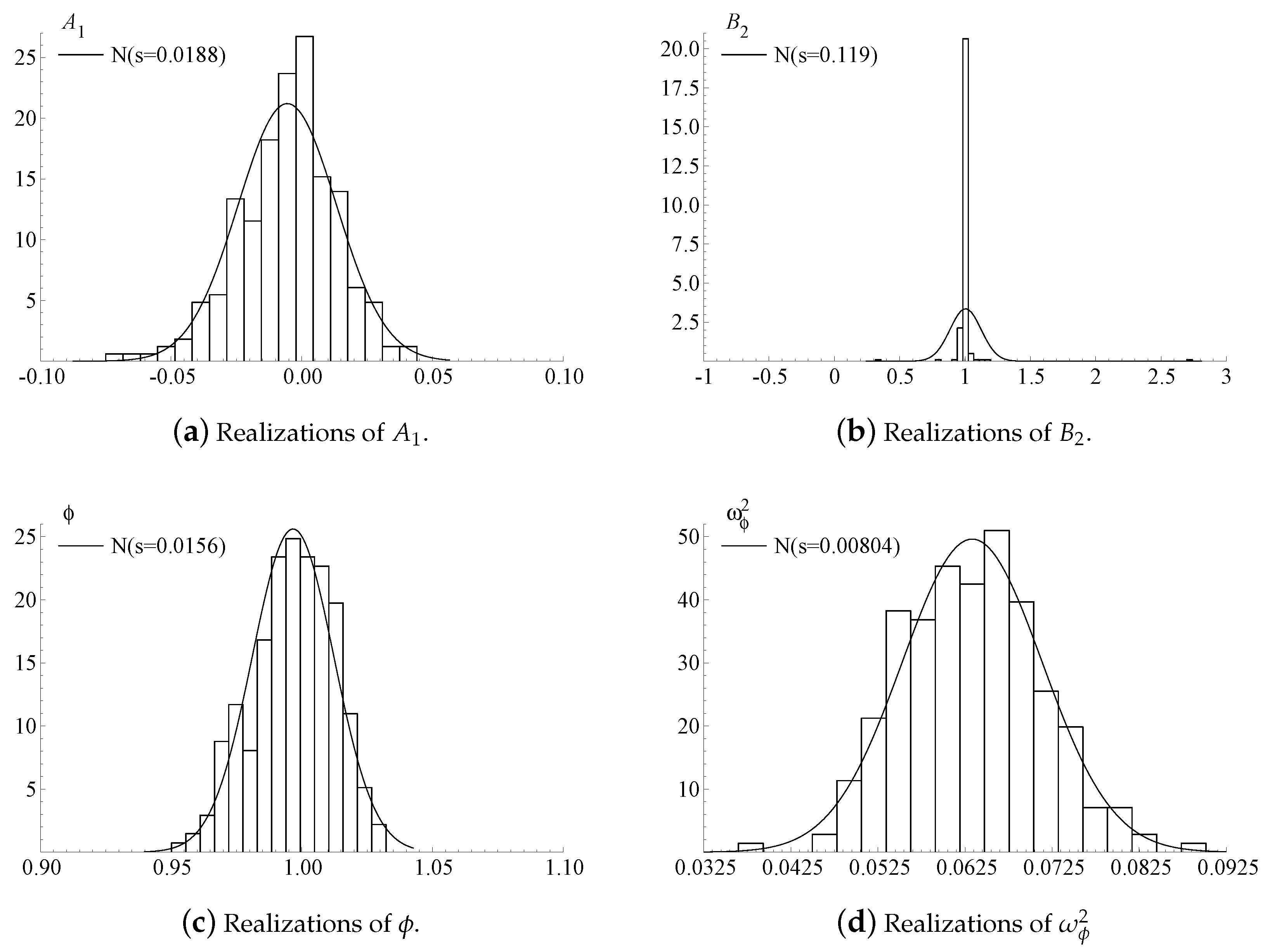
9. Simulation Study
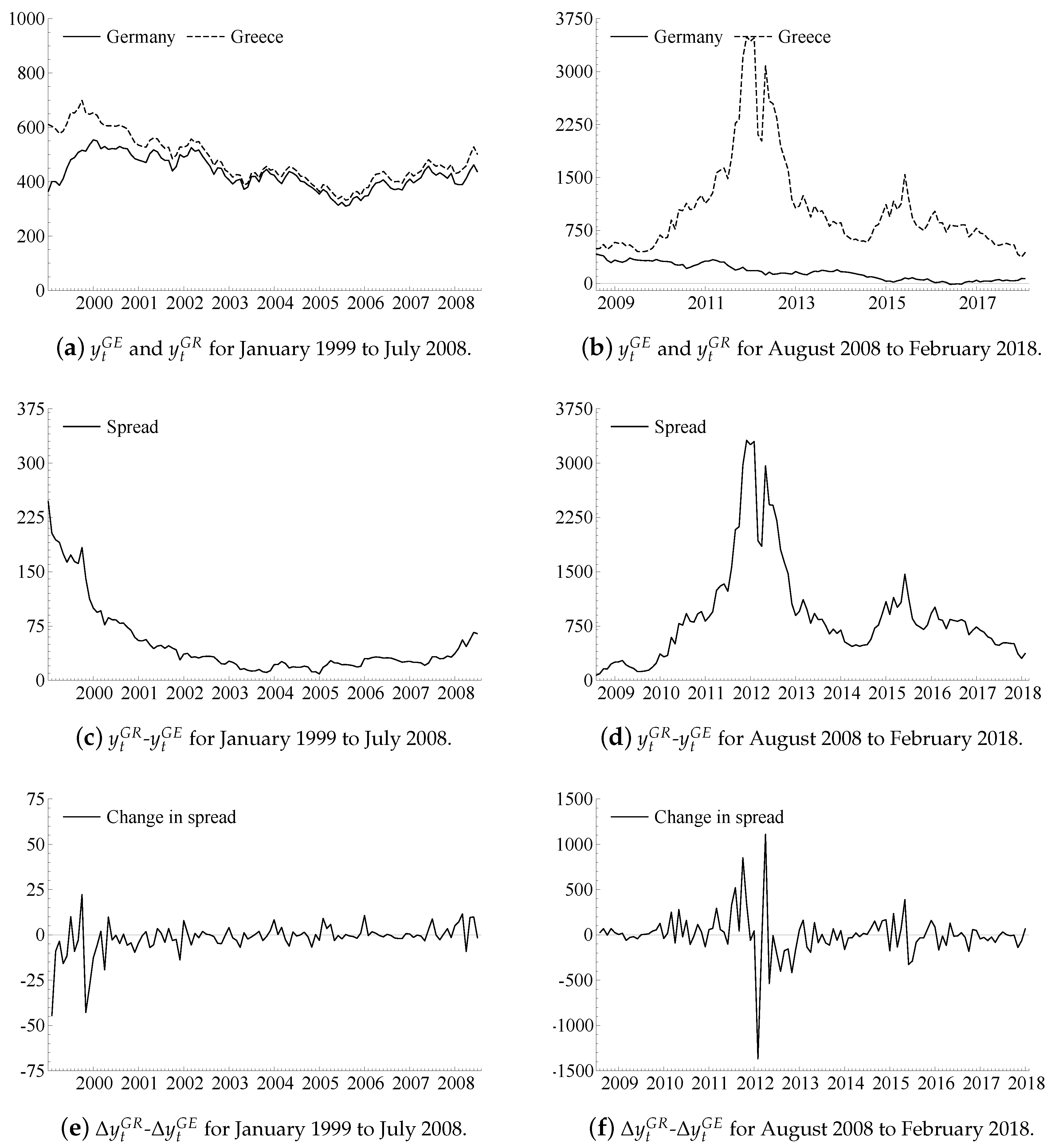
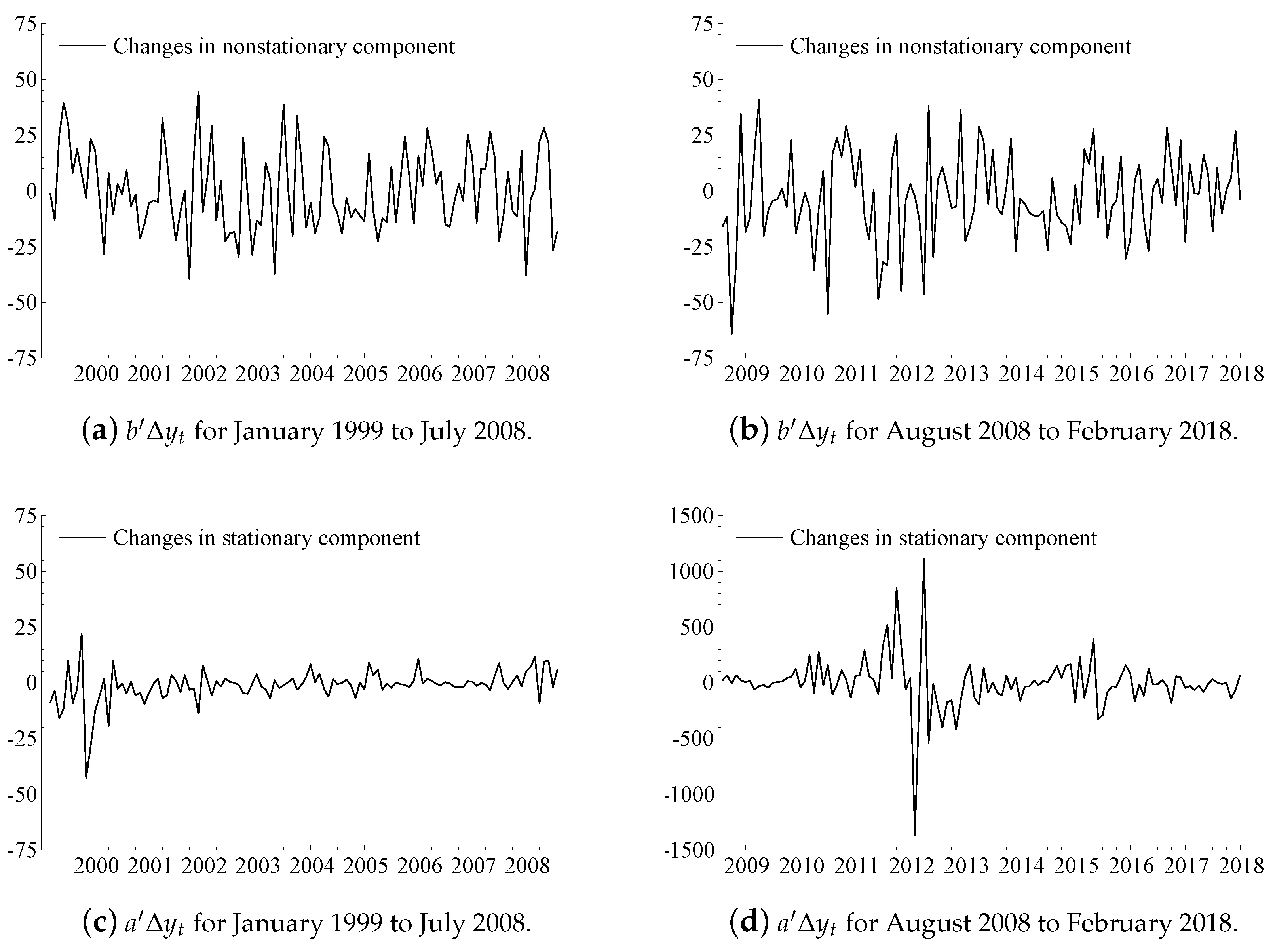
10. An Illustration
11. Conclusions
Acknowledgments
Conflicts of Interest
Appendix A. Auxiliary Results
Appendix B. Main Results
References
- Anderson, Brian D. O., and John B. Moore. 1979. Optimal Filtering. Upper Saddle River: Prentice-Hall, pp. 1–367. [Google Scholar]
- Andrieu, Christophe, and Arnaud Doucet. 2002. Particle filtering for partially observed Gaussian state space models. Journal of the Royal Statistical Society B 64: 827–36. [Google Scholar] [CrossRef]
- Bec, Frederique, and Anders Rahbek. 2004. Vector Equilibrium Correction Models with Non-Linear Discontinuous Adjustments. Econometrics Journal 7: 628–51. [Google Scholar] [CrossRef]
- Bec, Frédérique, Anders Rahbek, and Neil Shephard. 2008. The ACR Model: A Multivariate Dynamic Mixture Autoregression. Oxford Bulletin of Economics and Statistics 70: 583–618. [Google Scholar] [CrossRef]
- Cappé, Olivier, Eric Moulines, and Tobias Rydén. 2005. Inference in Hidden Markov Models. New York: Springer. [Google Scholar]
- Chang, Yoosoon, J. Isaac Miller, and Joon Y. Park. 2009. Extracting a Common Stochastic Trend: Theory with Some Applications. Journal of Econometrics 150: 231–47. [Google Scholar] [CrossRef]
- Chen, Rong, and Jun S. Liu. 2000. Mixture Kalman Filters. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 62: 493–508. [Google Scholar] [CrossRef]
- Chopin, Nicolas. 2004. Central Limit Theorem for Sequential Monte Carlo Methods and its Application to Bayesian Inference. The Annals of Statistics 32: 2385–411. [Google Scholar] [CrossRef]
- Creal, Drew. 2012. A Survey of Sequential Monte Carlo Methods for Economics and Finance. Econometric Reviews 31: 245–96. [Google Scholar] [CrossRef]
- Dempster, Arthur P., Nan M. Laird, and Donald B. Rubin. 1977. Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 37: 1–38. [Google Scholar]
- Dickey, David A., and Wayne A. Fuller. 1979. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. Journal of the American Statistical Association 74: 427–31. [Google Scholar]
- Dieci, Luca, and Erik S. Van Vleck. 1995. Computation of a Few Lyapunov Exponents for Continuous and Discrete Dynamical Systems. Applied Numerical Mathematics 17: 275–91. [Google Scholar] [CrossRef]
- Doornik, Jurgen A., and David F. Hendry. 2013. Modelling Dyamic Systems—PcGive 14: Volume II. London: Timberlake Consultants Ltd., pp. 1–284. [Google Scholar]
- Doornik, Jurgen A. 2012. Developer’s Manual for Ox 7. London: Timberlake Consultants Ltd., pp. 1–182. [Google Scholar]
- Douc, Randal, Olivier Cappé, and Eric Moulines. 2005. Comparison of Resampling Schemes for Particle Filtering. Paper presented at the 4th International Symposium on Image and Signal Processing and Analysis, Zagreb, Croatia, September 15–17; pp. 64–69. [Google Scholar]
- Douc, Randal, Eric Moulines, Jimmy Olsson, and Ramon Van Handel. 2011. Consistency of the Maximum Likelihood Estimator for General Hidden Markov Models. The Annals of Statistics 39: 474–513. [Google Scholar] [CrossRef]
- Douc, Randal, Eric Moulines, and David Stoffer. 2014. Nonlinear Time-Series: Theory, Methods, and Applications with R Examples. Boca Raton: CRC Press. [Google Scholar]
- Doucet, Arnaud, and Neil Shephard. 2012. Robust Inference on Parameters via Particle Filters and Sandwich Covariance Matrices. Economics Series Working Papers 606. Oxford, UK: University of Oxford. [Google Scholar]
- Doucet, Arnaud, Nando De Freitas, Kevin Murphy, and Stuart Russell. 2000. Rao-Blackwellised Particle Filtering for Dynamic Bayesian Networks. In Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc. [Google Scholar]
- Doucet, Arnaud, Nando de Freitas, and Neil Gordon. 2001. Sequential Monte Carlo Methods in Practice. New York: Springer. [Google Scholar]
- Durbin, James, and Siem Jan Koopman. 2012. Time Series Analysis by State Space Methods, 2nd ed. Oxford: Oxford University Press. [Google Scholar]
- Engle, Robert F., David F. Hendry, and Jean-Francois Richard. 1983. Exogeneity. Econometrica 51: 277–304. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Feigin, Paul D., and Richard L. Tweedie. 1985. Random Coefficient Autoregressive Processes: A Markov Chain Analysis of Stationarity and Finiteness of Moments. Journal of Time Series Analysis 6: 1–14. [Google Scholar] [CrossRef]
- Francq, Christian, and Jean-Michel Zakoian. 2010. GARCH Models: Structure, Statistical Inference and Financial Applications. Hoboken: Wiley, p. 489. [Google Scholar]
- Gordon, Neil J., David J. Salmond, and Adrian F. M. Smith. 1993. Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation. IEE Proceedings F, Radar and Signal Processing 140: 107–13. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Norman R. Swanson. 1997. An Introduction to Stochastic Unit-Root Processes. Journal of Econometrics 80: 35–62. [Google Scholar] [CrossRef]
- Hamilton, James Douglas. 1994. Time Series Analysis. Princeton: Princeton University Press. [Google Scholar]
- Jensen, Søren Tolver, and Anders Rahbek. 2004. Asymptotic Inference for Nonstationary GARCH. Econometric Theory 20: 1203–26. [Google Scholar] [CrossRef]
- Johansen, Søren. 1996. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models (Advanced Texts in Econometrics). Oxford: Oxford University Press. [Google Scholar]
- Juselius, Katarina. 2007. The Cointegrated VAR Model: Methodology and Applications (Advanced Texts in Econometrics). Oxford: Oxford University Press. [Google Scholar]
- Kalman, Rudolph Emil. 1960. A New Approach to Linear Filtering and Prediction Problems. Transactions of the ASME–Journal of Basic Engineering 82: 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kristensen, Dennis, and Anders Rahbek. 2010. Likelihood-based Inference for Cointegration with Nonlinear Error-Correction. Journal of Econometrics 158: 78–94. [Google Scholar] [CrossRef]
- Kristensen, Dennis, and Anders Rahbek. 2013. Testing and Inference in Nonlinear Cointegrating Vector Error Correction Models. Econometric Theory 29: 1238–88. [Google Scholar] [CrossRef]
- Kushner, Harold, and G. George Yin. 2003. Stochastic Approximation and Recursive Algorithms and Applications, 2nd ed. New York: Springer. [Google Scholar]
- Leybourne, Stephen J., Brendan P. M. McCabe, and Andrew R. Tremayne. 1996. Can Economic Time Series Be Differenced To Stationarity? Journal of Business & Economic Statistics 14: 435–46. [Google Scholar]
- Lieberman, Offer, and Peter C. B. Phillips. 2014. Norming rates and limit theory for some time-varying coefficient autoregressions. Journal of Time Series Analysis 35: 592–623. [Google Scholar] [CrossRef]
- Lieberman, Offer, and Peter C. B. Phillips. 2017. A multivariate stochastic unit root model with an application to derivative pricing. Journal of Econometrics 196: 99–110. [Google Scholar] [CrossRef]
- Ling, Shiqing. 2004. Estimation and Testing Stationarity for Double-Autoregressive Models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 66: 63–78. [Google Scholar] [CrossRef]
- Ling, Shiqing. 2007. A Double AR(p) Model: Structure and Estimation. Statistica Sinica 17: 161–75. [Google Scholar]
- Louis, Thomas A. 1982. Finding the Observed Information Matrix when Using the EM Algorithm. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 44: 226–33. [Google Scholar]
- McCabe, Brendan P. M., and Richard J. Smith. 1998. The power of some tests for difference stationarity under local heteroscedastic integration. Journal of the American Statistical Association 93: 751–61. [Google Scholar] [CrossRef]
- McCabe, Brendan P. M., and Andrew R. Tremayne. 1995. Testing a time series for difference stationarity. Annals of Statistics 23: 1015–28. [Google Scholar] [CrossRef]
- Meyn, Sean P., and Richard L. Tweedie. 2005. Markov Chains and Stochastic Stability. Cambridge: Cambridge University Press. [Google Scholar]
- Murray, Iain, Zoubin Ghahramani, and David MacKay. 2006. MCMC for Doubly-Intractable Distributions. Paper presented at the Twenty-Second Conference on Uncertainty in Artificial Intelligence (UAI2006), Cambridge, MA, USA, July 13–16. [Google Scholar]
- Nocedal, Jorge, and Stephen Wright. 2006. Numerical Optimization, 2nd ed. New York: Springer. [Google Scholar]
- Olsson, Jimmy, and Tobias Rydén. 2008. Asymptotic Properties of Particle Filter-Based Maximum Likelihood Estimators for State Space Models. Stochastic Processes and Their Applications 118: 649–80. [Google Scholar] [CrossRef]
- Pedersen, Rasmus Søndergaard, and Olivier Wintenberger. 2018. On the tail behavior of a class of multivariate conditionally heteroskedastic processes. Extremes 21: 261–84. [Google Scholar] [CrossRef]
- Pitt, Mark, and Neil Shephard. 1999a. Time Varying Covariances: A Factor Stochastic Volatility Approach. In Bayesian Statistics. Edited by José M. Bernardo, James O. Berger, A. P. Dawid and Adrian F. M. Smith. Oxford: Oxford University Press, vol. 6, pp. 547–70. [Google Scholar]
- Pitt, Michael K., and Neil Shephard. 1999b. Filtering via Simulation: Auxiliary Particle Filters. Journal of the American Statistical Association 94: 590–99. [Google Scholar] [CrossRef]
- Polyak, Boris T., and Anatoli B. Juditsky. 1992. Acceleration of Stochastic Approximation by Averaging. SIAM Journal on Control and Optimization 30: 838–55. [Google Scholar] [CrossRef]
- Polyak, Boris Teodorovich. 1990. A New Method of Stochastic Approximation Type. Automation and Remote Control 51: 98–107. [Google Scholar]
- Poyiadjis, George, Arnaud Doucet, and Sumeetpal S. Singh. 2011. Particle Approximations of the Score and Observed Information Matrix in State Space Models with Application to Parameter Estimation. Biometrika 98: 65–80. [Google Scholar] [CrossRef]
- Robbins, Herbert, and Sutton Monro. 1951. A Stochastic Approximation Method. The Annals of Mathematical Statistics 22: 400–7. [Google Scholar] [CrossRef]
- Robert, Christian P., and George Casella. 2010. Introducing Monte Carlo Methods with R, 1st ed. New York: Springer, p. 296. [Google Scholar]
- Nielsen, Heino Bohn, and Anders Rahbek. 2014. Unit Root Vector Autoregression with Volatility Induced Stationarity. Journal of Empirical Finance 29: 144–67. [Google Scholar] [CrossRef]
- Nielsen, Heino Bohn. 2016. The Co-integrated Vector Autoregression with Errors-in-Variables. Econometric Reviews 35: 169–200. [Google Scholar] [CrossRef]
| 1. | We use the Choleski factorization to ensure positive definiteness of the covariance matrices , and . Thus, we estimate the parameters B, A, , , , and using Algorithm 2 and transform the covariances to the original parametrization. We obtain standard errors via the -method. |
| 2. | Because we initialize at the true parameter value, the parameter sequences stabilize within the first 100 realizations. Using iterations is sufficient to reduce the impact of the approximation error. |
| 3. | The choice of weight matrix is based on hand-tuning the convergence speed of Algorithm 2 by running a small number of trial-and-error runs with particles and constant step size . |
| 4. | Obtained via a Bloomberg LP Terminal using the ticker codes ‘GDBR10 Index’ and ‘GGGB10YR Index’. |
| 5. | The difference between computing the classic standard errors with and particles is negligible. |
| 6. | Particle filter-based approximate robust standard errors have been suggested in Doucet and Shephard (2012), but we do not pursue this idea further in the present context. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Estimate | Std.err. | Parameter | Estimate | Std.err. |
|---|---|---|---|---|---|
| - | |||||
| - | |||||
| - | |||||
| Univariate tests for AR 1-2: | |||
| Multivariate test for AR 1-2: | |||
| Univariate tests for ARCH: | |||
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hetland, A. The Stochastic Stationary Root Model. Econometrics 2018, 6, 39. https://doi.org/10.3390/econometrics6030039
Hetland A. The Stochastic Stationary Root Model. Econometrics. 2018; 6(3):39. https://doi.org/10.3390/econometrics6030039
Chicago/Turabian StyleHetland, Andreas. 2018. "The Stochastic Stationary Root Model" Econometrics 6, no. 3: 39. https://doi.org/10.3390/econometrics6030039
APA StyleHetland, A. (2018). The Stochastic Stationary Root Model. Econometrics, 6(3), 39. https://doi.org/10.3390/econometrics6030039