

A Multi-View Vision System for Astronaut Postural Reconstruction with Self-Calibration


Abstract
:1. Introduction
- First, an alternating iterative optimization of the camera pose parameter estimation and human pose parameters is proposed to provide a convenient and accurate estimation of the camera’s extrinsic parameters.
- Second, a shape optimization is implemented based on the pre-scanned astronaut body model to refine the shape parameters for long-term space exploration missions and the astronaut’s postural performance is reconstructed with non-linear optimization.
2. Related Works
2.1. Astronaut Performance Capture
2.2. Calibration-Free Multi-View System
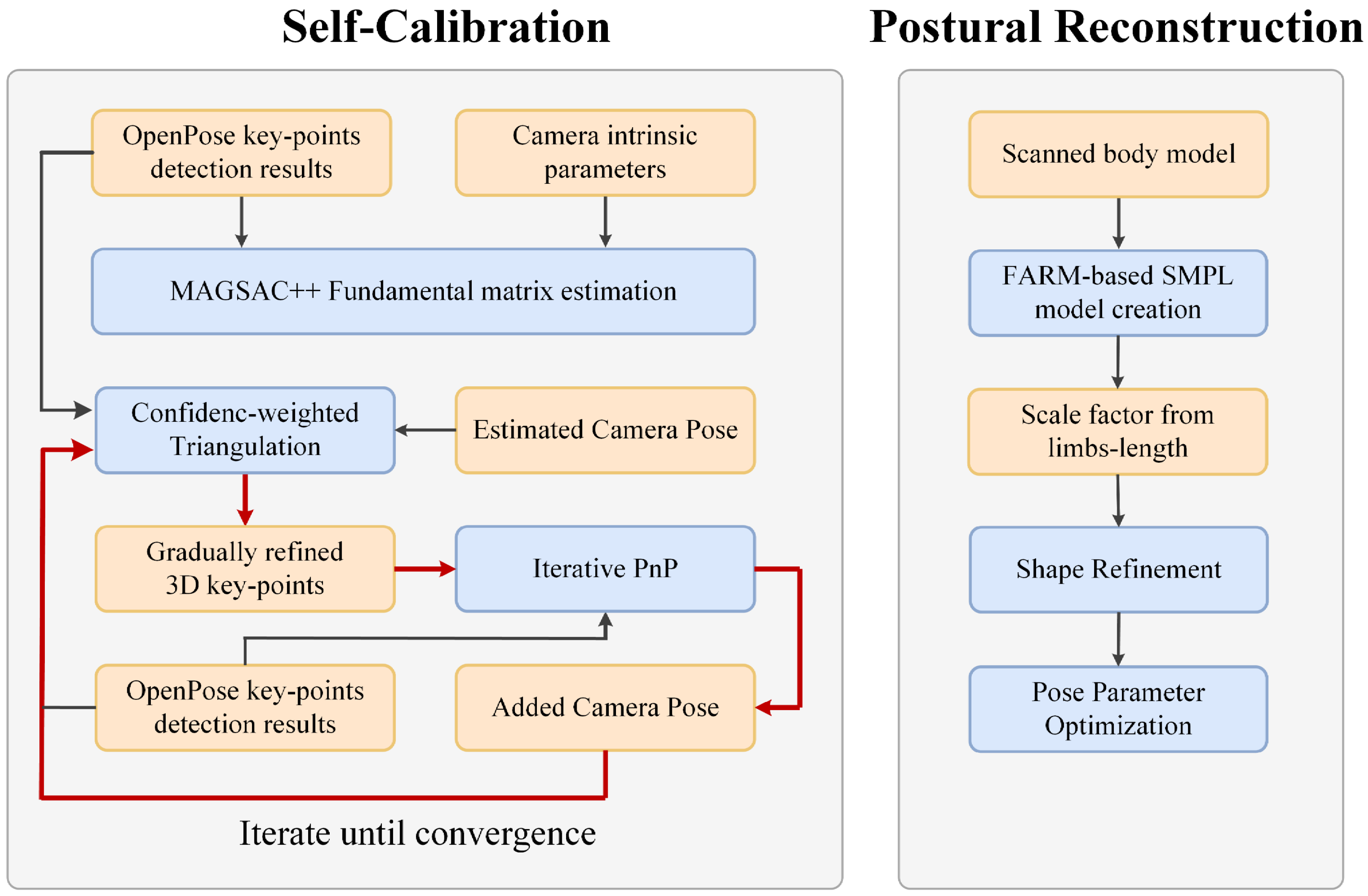
3. Proposed Method
3.1. MAGSAC-Based Fundamental Matrix Estimation
3.2. Confidence-Weighted Camera Pose Refinement
3.3. SMPL-Based Postural Reconstruction
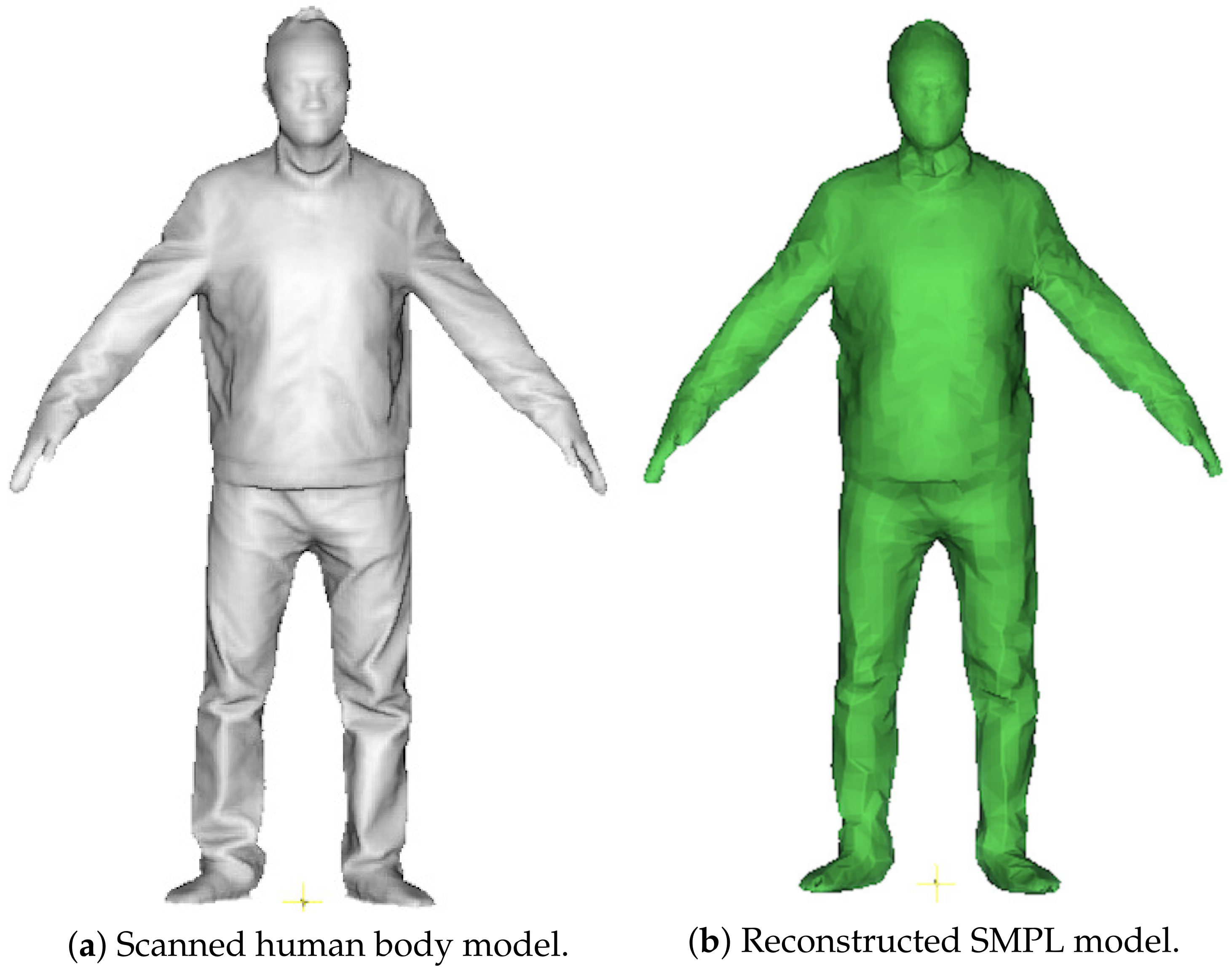
3.3.1. Personalized SMPL Model
3.3.2. Shape Parameters Refinement
3.3.3. Postural Reconstruction
4. Experimental Evaluation
- 1.
- Camera pose differences with available ground truth.
- 2.
- 2D reprojection error of the reconstructed joints.
- 3.
- 3D reconstruction error of the reconstructed joints.
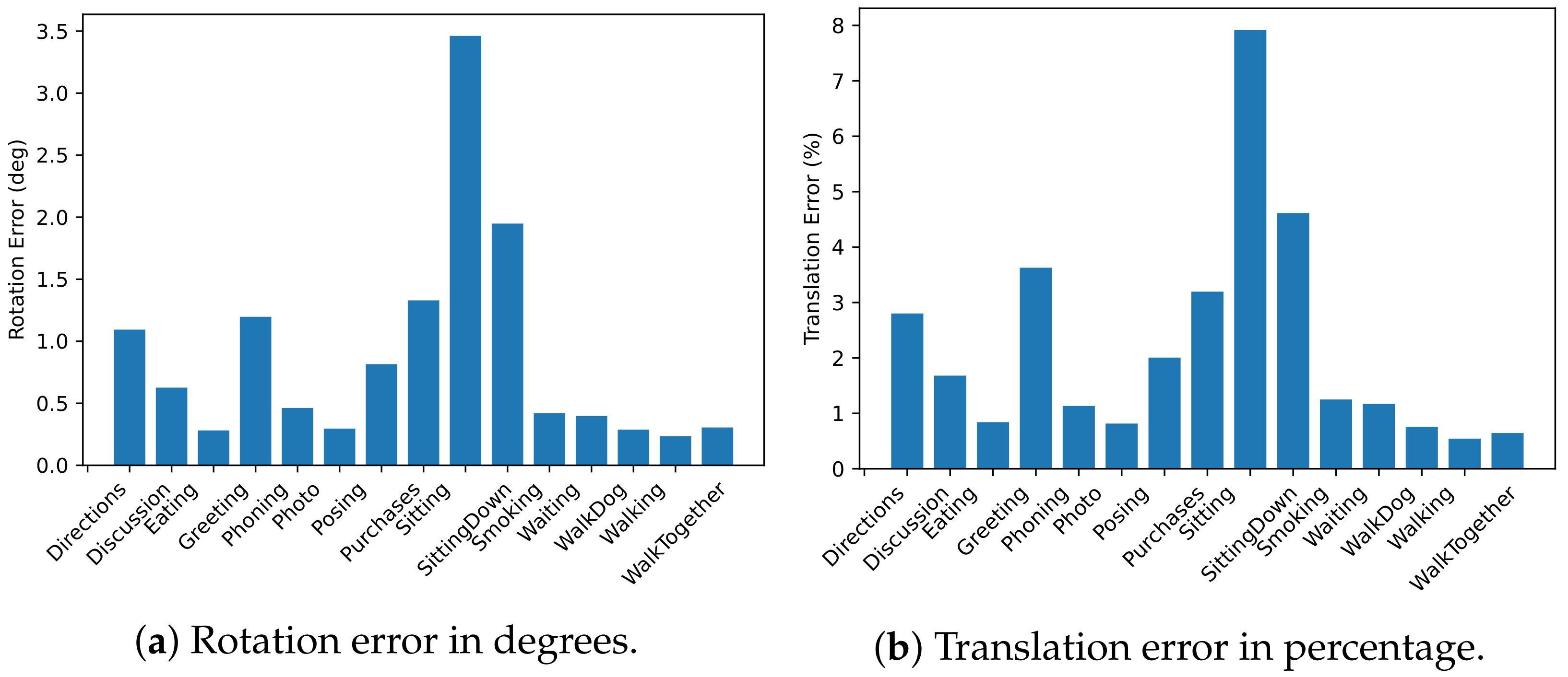
4.1. Extrinsic Parameter Calibration
4.1.1. Human 3.6M Evaluation
4.1.2. Ground Verification Test Data
4.2. Postural Reconstruction
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amir, A.; Baroni, G.; Pedrocchi, A.; Newman, D.; Ferrigno, G.; Pedotti, A. Measuring astronaut performance on the ISS: Advanced kinematic and kinetic instrumentation. In Proceedings of the IMTC/99, 16th IEEE Instrumentation and Measurement Technology Conference (Cat. No. 99CH36309), Venice, Italy, 24–26 May 1999; Volume 1, pp. 397–402. [Google Scholar]
- Wu, E.Q.; Tang, Z.R.; Xiong, P.; Wei, C.F.; Song, A.; Zhu, L.M. ROpenPose: A rapider OpenPose model for astronaut operation attitude detection. IEEE Trans. Ind. Electron. 2021, 69, 1043–1052. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, W.; Feng, W. The astronaut ergonomics assessment methodology in microgravity environment. In Proceedings of the 2017 Second International Conference on Reliability Systems Engineering (ICRSE), Beijing, China, 10–12 July 2017; pp. 1–7. [Google Scholar]
- Xia, S.; Gao, L.; Lai, Y.K.; Yuan, M.Z.; Chai, J. A survey on human performance capture and animation. J. Comput. Sci. Technol. 2017, 32, 536–554. [Google Scholar] [CrossRef] [Green Version]
- Mihcin, S. Simultaneous validation of wearable motion capture system for lower body applications: Over single plane range of motion (ROM) and gait activities. Biomed. Eng. Tech. 2022, 67, 185–199. [Google Scholar] [CrossRef] [PubMed]
- McGrath, T.M. IMU-Based Estimation of Human Lower Body Kinematics and Applications to Extravehicular Operations. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2021. [Google Scholar]
- Desmarais, Y.; Mottet, D.; Slangen, P.; Montesinos, P. A review of 3D human pose estimation algorithms for markerless motion capture. Comput. Vis. Image Underst. 2021, 212, 103275. [Google Scholar] [CrossRef]
- Gall, J.; Rosenhahn, B.; Brox, T.; Seidel, H.P. Optimization and filtering for human motion capture. Int. J. Comput. Vis. 2010, 87, 75–92. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Stoll, C.; Gall, J.; Seidel, H.P.; Theobalt, C. Markerless motion capture of interacting characters using multi-view image segmentation. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; pp. 1249–1256. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Dong, J.; Jiang, W.; Huang, Q.; Bao, H.; Zhou, X. Fast and robust multi-person 3d pose estimation from multiple views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7792–7801. [Google Scholar]
- Qiu, H.; Wang, C.; Wang, J.; Wang, N.; Zeng, W. Cross view fusion for 3d human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 4342–4351. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Liu, W.; Zeng, W. Voxeltrack: Multi-person 3d human pose estimation and tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2613–2626. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, K.; Mikami, D.; Isogawa, M.; Kimata, H. Human pose as calibration pattern; 3D human pose estimation with multiple unsynchronized and uncalibrated cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1775–1782. [Google Scholar]
- Xu, Y.; Li, Y.J.; Weng, X.; Kitani, K. Wide-baseline multi-camera calibration using person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13134–13143. [Google Scholar]
- Lee, S.E.; Shibata, K.; Nonaka, S.; Nobuhara, S.; Nishino, K. Extrinsic Camera Calibration from a Moving Person. IEEE Robot. Autom. Lett. 2022, 7, 10344–10351. [Google Scholar] [CrossRef]
- Winnard, A.; Nasser, M.; Debuse, D.; Stokes, M.; Evetts, S.; Wilkinson, M.; Hides, J.; Caplan, N. Systematic review of countermeasures to minimise physiological changes and risk of injury to the lumbopelvic area following long-term microgravity. Musculoskelet. Sci. Pract. 2017, 27, S5–S14. [Google Scholar] [CrossRef] [PubMed]
- Ferrigno, G.; Pedrocchi, A.; Baroni, G.; Bracciaferri, F.; Neri, G.; Pedotti, A. ELITE-S2: The multifactorial movement analysis facility for the International Space Station. Acta Astronaut. 2004, 54, 723–735. [Google Scholar] [CrossRef] [PubMed]
- Neri, G.; Mascetti, G.; Zolesi, V. ELITE S2–A Facility for Quantitative Human Movement Analysis on Board the ISS. Microgravity Sci. Technol. 2014, 26, 271–278. [Google Scholar] [CrossRef]
- Lee, M.W. Exercise Sensing and Pose Recovery Inference Tool (ESPRIT)-A Compact Stereo-based Motion Capture Solution For Exercise Monitoring. In An Overview of SBIR Phase 2 Physical Sciences and Biomedical Technologies in Space; NASA: Washington, DC, USA, 2015. [Google Scholar]
- Available online: https://humanresearchroadmap.nasa.gov/Tasks/task.aspx?i=1557 (accessed on 29 July 2022).
- Wang, J.; Tan, S.; Zhen, X.; Xu, S.; Zheng, F.; He, Z.; Shao, L. Deep 3D human pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225. [Google Scholar] [CrossRef]
- Wang, L.; Duan, F.; Lu, K. An adaptively weighted algorithm for camera calibration with 1D objects. Neurocomputing 2015, 149, 1552–1559. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Guan, J.; Deboeverie, F.; Slembrouck, M.; Van Haerenborgh, D.; Van Cauwelaert, D.; Veelaert, P.; Philips, W. Extrinsic calibration of camera networks using a sphere. Sensors 2015, 15, 18985–19005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Zheng, Y.; Sugimoto, S.; Okutomi, M. A practical rank-constrained eight-point algorithm for fundamental matrix estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2013; pp. 1546–1553. [Google Scholar]
- Barath, D. Five-point fundamental matrix estimation for uncalibrated cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 235–243. [Google Scholar]
- Cheng, Y.; Lopez, J.A.; Camps, O.; Sznaier, M. A convex optimization approach to robust fundamental matrix estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2170–2178. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In Proceedings of the International Workshop on Vision Algorithms, Corfu, Greece, 21–22 September 1999; pp. 298–372. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7753–7762. [Google Scholar]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]
- Zheng, Y.; Kuang, Y.; Sugimoto, S.; Astrom, K.; Okutomi, M. Revisiting the pnp problem: A fast, general and optimal solution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2344–2351. [Google Scholar]
- Yang, K.; Fang, W.; Zhao, Y.; Deng, N. Iteratively reweighted midpoint method for fast multiple view triangulation. IEEE Robot. Autom. Lett. 2019, 4, 708–715. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. (TOG) 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Moakher, M. Means and averaging in the group of rotations. SIAM J. Matrix Anal. Appl. 2002, 24, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Trumble, M.; Gilbert, A.; Hilton, A.; Collomosse, J. Deep autoencoder for combined human pose estimation and body model upscaling. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Harvesting multiple views for marker-less 3d human pose annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6988–6997. [Google Scholar]
- Huang, Y.; Bogo, F.; Lassner, C.; Kanazawa, A.; Gehler, P.V.; Romero, J.; Akhter, I.; Black, M.J. Towards accurate marker-less human shape and pose estimation over time. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 421–430. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actions | Rotation Error (deg) | Translation Error (%) | Re-Projection Error (px) |
|---|---|---|---|
| No. 1 | 0.8234 | 1.2453 | 1.34 |
| No. 2 | 0.7422 | 0.8264 | 0.98 |
| No. 3 | 0.9231 | 1.534 | 1.65 |
| Methods | Shape | PA | Calibration | MPJPE |
|---|---|---|---|---|
| Trumble et al. [41] | No | No | Yes | 62.50 |
| Pavlakos et al. [42] | No | Yes | Yes | 56.89 |
| Huang et al. [43] | Yes | Yes | Yes | 47.09 |
| Yes | Yes | Yes | 41.52 | |
| Yes | Yes | No | 42.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, S.; Zhang, X.; Zhuge, S.; Ning, C.; Zhong, L.; Li, Y. A Multi-View Vision System for Astronaut Postural Reconstruction with Self-Calibration. Aerospace 2023, 10, 298. https://doi.org/10.3390/aerospace10030298
Gan S, Zhang X, Zhuge S, Ning C, Zhong L, Li Y. A Multi-View Vision System for Astronaut Postural Reconstruction with Self-Calibration. Aerospace. 2023; 10(3):298. https://doi.org/10.3390/aerospace10030298
Chicago/Turabian StyleGan, Shuwei, Xiaohu Zhang, Sheng Zhuge, Chenghao Ning, Lijun Zhong, and You Li. 2023. "A Multi-View Vision System for Astronaut Postural Reconstruction with Self-Calibration" Aerospace 10, no. 3: 298. https://doi.org/10.3390/aerospace10030298
APA StyleGan, S., Zhang, X., Zhuge, S., Ning, C., Zhong, L., & Li, Y. (2023). A Multi-View Vision System for Astronaut Postural Reconstruction with Self-Calibration. Aerospace, 10(3), 298. https://doi.org/10.3390/aerospace10030298