
A Context-Aware Language Model to Improve the Speech Recognition in Air Traffic Control


Abstract
:1. Introduction
- A novel neural network language model, called CALM, is proposed to improve the callsign identification in ATC-related ASR systems.
- Compared to conventional LM, the proposed CALM has the ability to integrate the contextual information into the LM decoding by the designed context encoder and context-aware decoder, which improves the ASR performance from the perspective of scene awareness.
- To fuse the representations of the text and the contextual information, a context attention mechanism is proposed to generate a joint representation vector that further supports the context-aware decoder.
- We integrate the CALM into the decoding and rescoring procedure of the ASR systems and validate on the real-world speech corpus.
2. Related Work
2.1. Contextual ASR Systems
2.2. ATC Related Works
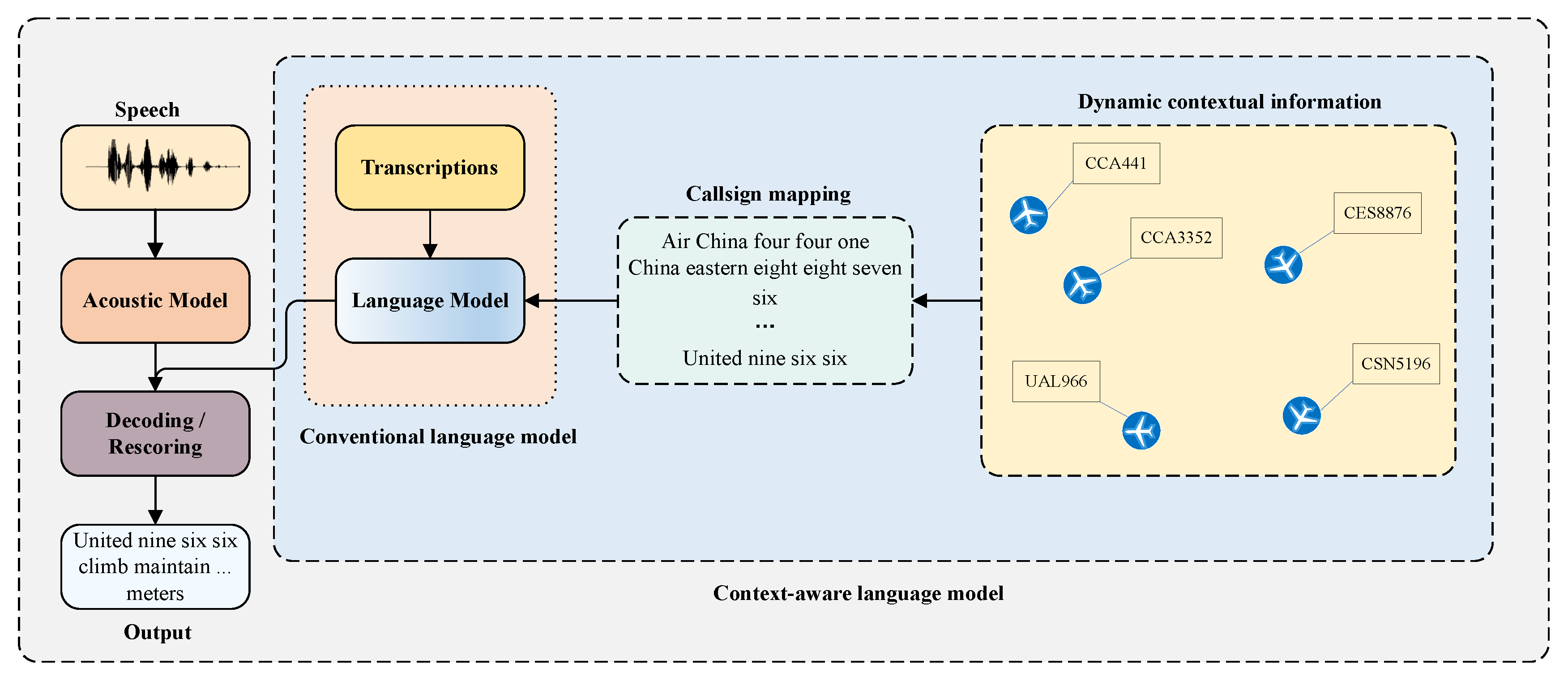
3. Methodology
3.1. The Acoustic Model
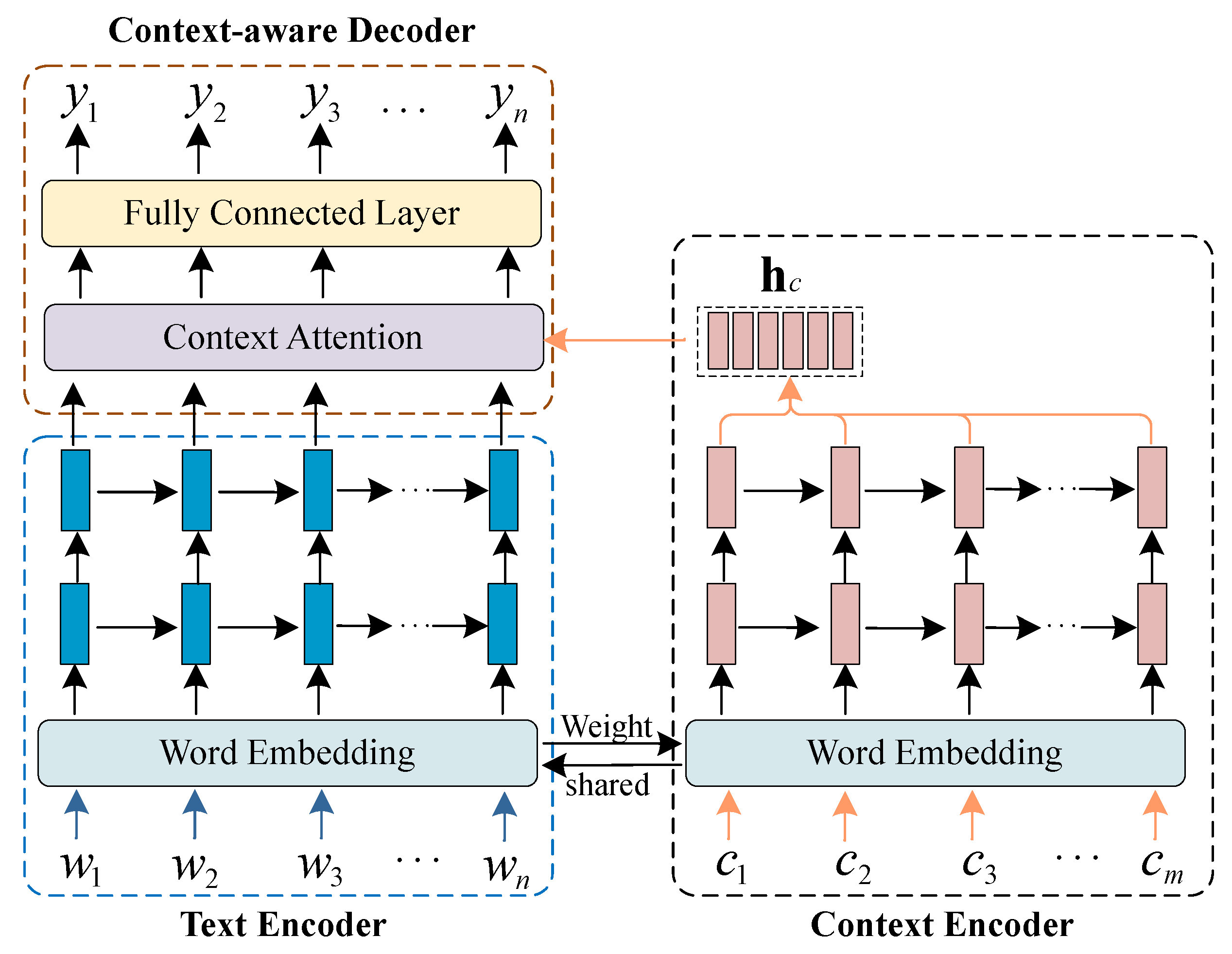
3.2. Context-Aware Language Model
- Text Encoder: The text encoder is composed of an input layer, embedding layer, and several LSTM layers. The purpose of the text encoder is to convert the input sequence into high-level feature representations. For a text sequence , the text encoder learns word representations through an embedding layer and intermediately outputs hidden features by LSTM layers, as shown below:
- Context Encoder: The context encoder shares the same network architecture with the text encoder, i.e., input layer, embedding layer, and several LSTM layers. Similarly, the context encoder learns the high-level representations from the context sequence which is generated by the contextual information mapping strategy. The context information mapping strategy is described in Section 3.3. With a context sequence being , the context encoder learns the context representations by:
- Context-aware Decoder: The context-aware decoder is constructed based on a context attention module and two FC layers. Specifically, the learned representations from the text encoder (AM output) and context encoder (contextual information) are fused with different weights optimized by the context attention module. Then, the first FC layer is applied to transform the fused features. The last FC layer with Softmax activation is applied to normalize the output probability on the vocabulary. The decoder process can be summarized as follows:The inference rule of the feature fusion method (context attention module) is motivation by the attention mechanism. Firstly, each hidden unit from the text sequence is assigned the score with the context vector by Equation (4), where are trainable parameters. Secondly, the scores are normalized by the Softmax operation as in Equation (5) to get the fusion weights . Then, in Equation (6), a weighted sum is calculated on the context feature to obtain the fused context feature representation for step i. Finally, as shown in Equation (7), the text representation vector and the fused context representation vector of step i are concatenated to form a context-aware vector for the FC layer to generate an output .
3.3. Contextual Information Organization
- multiple pronunciations for a single callsign: the airline company name DLH can be spoken as “delta lima hotel” or Lufthansa. Similarly, the airline number “8883” can be spoken as “eight eight eight three” or “triple eight three” in English or “ba ba ba san” in Chinese.
- multiple callsign entities from the real-time context: in most cases, there are several flights in a control sector, which are required to be fed into the context encoder to support the subsequent decoding procedure.
4. Experiments and Discussions
4.1. ATC Corpus
4.2. Experimental Configurations
- ASR-C: the model is optimized on the Chinese speech of the ATCSpeech corpus.
- ASR-E: the model is optimized on the English speech of the ATCSpeech corpus.
- ASR-A: the model is optimized on the whole ATCSpeech corpus.
4.3. Results
4.3.1. Decoding Results
4.3.2. Rescoring Results
- (1)
- By using the N-gram LM for the decoding procedure, the final ASR performance is slightly improved with both the CALM and RNNLM rescoring. This fact also validates the decoding procedure, which provides a more reliable N-best list and further benefits to the rescoring procedure.
- (2)
- For the test and test-real datasets, the CALM outperforms the common LM for both the ASR and callsign identification task. Thanks to the contextual information, the CALM achieves about 85% CSA, i.e., 20% absolute improvement.
- (3)
- The LMs trained with English words obtain superior performance over those trained with English letters. It can be attributed that taking English letters as the modeling unit leads to the input sequence being too long to capture the vocabulary dependencies, which further affects the final performance of the NN-based LMs.
- (4)
- It can also be seen that, since the rescoring is a separate procedure without considering the AM probability, the rescoring results are not always optimal (the lowest CER) compared to that of applying it to the decoding procedure. However, the rescoring is a one-pass procedure, and can be achieved with less computational resources in a real-time manner. It is a more preferable way to take advantage of the proposed CALM in the real environment.
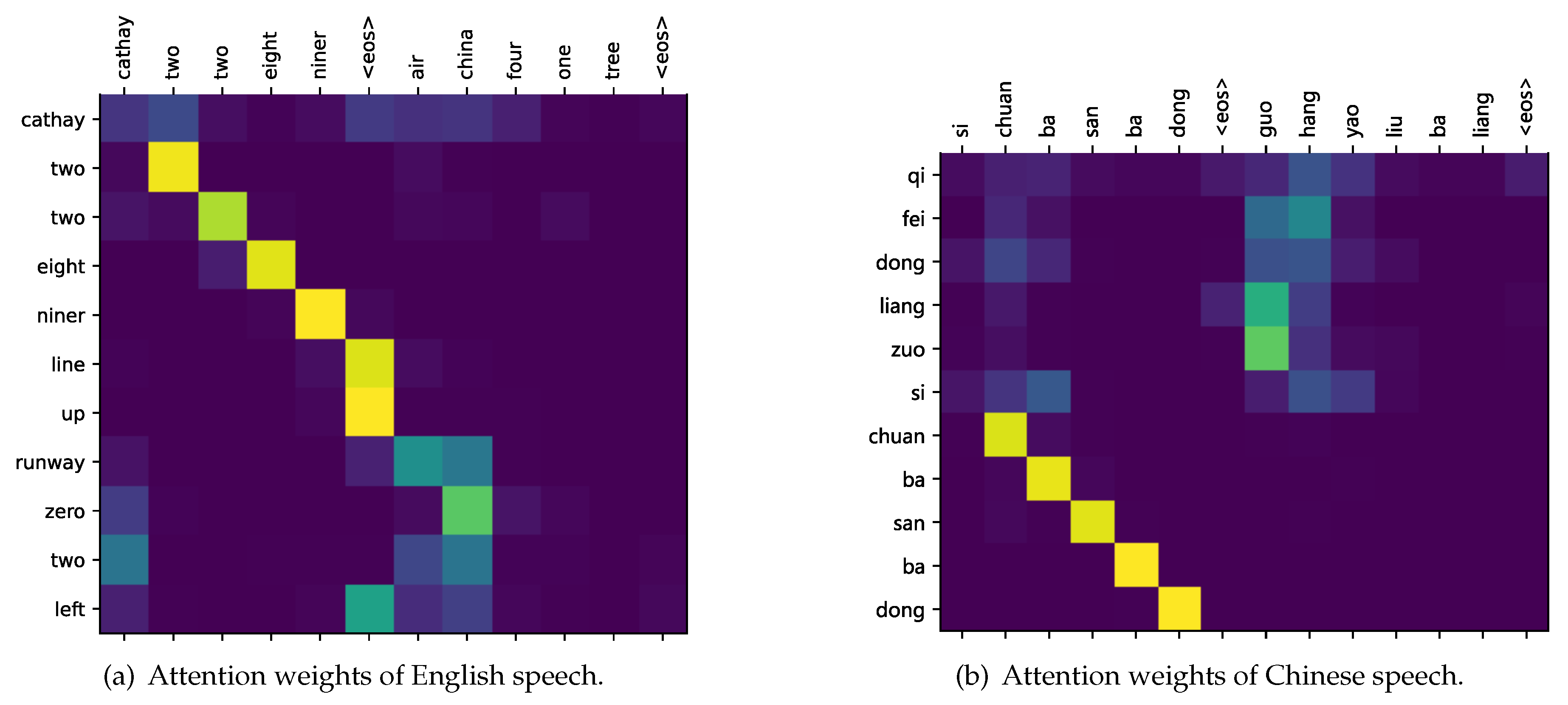
4.4. Visualization and Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ohneiser, O.; Helmke, H.; Ehr, H.; Gürlük, H.; Hössl, M.; Kleinert, M.; Mühlhausen, T.; Uebbing-Rumke, M.; Oualil, Y.; Schulder, M.; et al. Air Traffic Controller Support by Speech Recognition. In Proceedings of the International Conference on Applied Human Factors and Ergonomics (AHFE), Krakow, Poland, 19–23 July 2014; pp. 492–503. [Google Scholar]
- Lin, Y.; Tan, X.; Yang, B.; Yang, K.; Zhang, J.; Yu, J. Real-time Controlling Dynamics Sensing in Air Traffic System. Sensors 2019, 19, 679. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A Real-Time ATC Safety Monitoring Framework Using a Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4572–4581. [Google Scholar] [CrossRef]
- Ferreiros, J.; Pardo, J.; de Córdoba, R.; Macias-Guarasa, J.; Montero, J.; Fernández, F.; Sama, V.; d’Haro, L.; González, G. A speech interface for air traffic control terminals. Aerosp. Sci. Technol. 2012, 21, 7–15. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Wu, Y.; Guo, D.; Zhang, P.; Yin, C.; Yang, B.; Zhang, J. A Deep Learning Framework of Autonomous Pilot Agent for Air Traffic Controller Training. IEEE Trans. Hum. Mach. Syst. 2021, 51, 442–450. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Vesel, K.; Blatt, A.; Motlicek, P.; Landis, F. Automatic Call Sign Detection: Matching Air Surveillance Data with Air Traffic Spoken Communications. Proceedings 2020, 59, 14. [Google Scholar] [CrossRef]
- Nguyen, V.N.; Holone, H. Possibilities, Challenges and the State of the Art of Automatic Speech Recognition in Air Traffic Control. Int. J. Comput. Inf. Eng. 2015, 9, 1933–1942. [Google Scholar]
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A Unified Framework for Multilingual Speech Recognition in Air Traffic Control Systems. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 3608–3620. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Motlicek, P.; Zhan, Q.; Veselý, K.; Braun, R. Automatic Speech Recognition Benchmark for Air-Traffic Communications. Proc. Interspeech 2020, 2020, 2297–2301. [Google Scholar] [CrossRef]
- Srinivasamurthy, A.; Motlícek, P.; Himawan, I.; Szaszák, G.; Oualil, Y.; Helmke, H. Semi-Supervised Learning with Semantic Knowledge Extraction for Improved Speech Recognition in Air Traffic Control. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2406–2410. [Google Scholar]
- Lin, Y.; Yang, B.; Li, L.; Guo, D.; Zhang, J.; Chen, H.; Zhang, Y. ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems. Appl. Soft Comput. 2021, 112, 107847. [Google Scholar] [CrossRef]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Pellegrini, T.; Farinas, J.; Delpech, E.; Lancelot, F. The Airbus Air Traffic Control Speech Recognition 2018 Challenge: Towards ATC Automatic Transcription and Call Sign Detection. Proc. Interspeech 2019, 2019, 2993–2997. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Tan, X.; Chen, Z.; Wang, B.; Ruan, M.; Li, D.; Yang, Z.; Wu, X.; Lin, Y. ATCSpeech: A Multilingual Pilot-Controller Speech Corpus from Real Air Traffic Control Environment. Proc. Interspeech 2020, 2020, 399–403. [Google Scholar] [CrossRef]
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A Real-life, French-accented Corpus of Air Traffic Control Communications. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Mohri, M.; Pereira, F.; Riley, M. Speech Recognition with Weighted Finite-State Transducers. In Springer Handbook of Speech Processing; Benesty, J., Sondhi, M.M., Huang, Y.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 559–584. [Google Scholar] [CrossRef]
- Novak, J.R.; Minematsu, N.; Hirose, K. Dynamic Grammars with Lookahead Composition for WFST-based Speech Recognition. Proc. Interspeech 2012, 2012, 1079–1082. [Google Scholar]
- Hall, K.B.; Cho, E.; Allauzen, C.; Beaufays, F.; Coccaro, N.; Nakajima, K.; Riley, M.; Roark, B.; Rybach, D.; Zhang, L. Composition-based on-the-fly rescoring for salient n-gram biasing. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 1418–1422. [Google Scholar]
- Aleksic, P.S.; Ghodsi, M.; Michaely, A.H.; Allauzen, C.; Hall, K.B.; Roark, B.; Rybach, D.; Moreno, P.J. Bringing contextual information to google speech recognition. Proc. Interspeech 2015, 2015, 468–472. [Google Scholar] [CrossRef]
- Huang, R.; Abdel-hamid, O.; Li, X.; Evermann, G. Class LM and Word Mapping for Contextual Biasing in End-to-End ASR. Proc. Interspeech 2020, 2020, 4348–4351. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar] [CrossRef]
- Zhao, D.; Sainath, T.N.; Rybach, D.; Rondon, P.; Bhatia, D.; Li, B.; Pang, R. Shallow-Fusion End-to-End Contextual Biasing. Proc. Interspeech 2019, 2019, 1418–1422. [Google Scholar] [CrossRef] [Green Version]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Pundak, G.; Sainath, T.N.; Prabhavalkar, R.; Kannan, A.; Zhao, D. Deep Context: End-to-end Contextual Speech Recognition. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop, SLT 2018, Athens, Greece, 18–21 December 2018; pp. 418–425. [Google Scholar] [CrossRef] [Green Version]
- Jain, M.; Keren, G.; Mahadeokar, J.; Zweig, G.; Metze, F.; Saraf, Y. Contextual RNN-T for Open Domain ASR. Proc. Interspeech 2020, 2020, 11–15. [Google Scholar] [CrossRef]
- Oualil, Y.; Klakow, D.; Szaszák, G.; Srinivasamurthy, A.; Helmke, H.; Motlícek, P. A context-aware speech recognition and understanding system for air traffic control domain. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 16–20 December 2017; pp. 404–408. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlícek, P.; Veselý, K.; Kocour, M.; Szöke, I. Contextual Semi-Supervised Learning: An Approach To Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems. arXiv 2021, arXiv:2104.03643. [Google Scholar]
- Shore, T.; Faubel, F.; Helmke, H.; Klakow, D. Knowledge-Based Word Lattice Rescoring in a Dynamic Context. Proc. Interspeech 2012, 2012, 1083–1086. [Google Scholar]
- Schmidt, A.; Oualil, Y.; Ohneiser, O.; Kleinert, M.; Schulder, M.; Khan, A.; Helmke, H.; Klakow, D. Context-based recognition network adaptation for improving online ASR in Air Traffic Control. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop, SLT 2014, South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 13–18. [Google Scholar] [CrossRef]
- Oualil, Y.; Schulder, M.; Helmke, H.; Schmidt, A.; Klakow, D. Real-time integration of dynamic context information for improving automatic speech recognition. Proc. Interspeech 2015, 2015, 2107–2111. [Google Scholar]
- Gulcehre, C.; Firat, O.; Xu, K.; Cho, K.; Barrault, L.; Lin, H.C.; Bougares, F.; Schwenk, H.; Bengio, Y. On Using Monolingual Corpora in Neural Machine Translation. arXiv 2015, arXiv:1503.03535. [Google Scholar]
- Sriram, A.; Jun, H.; Satheesh, S.; Coates, A. Cold fusion: Training Seq2seq Models Together with Language Models. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lin, Y.; Yang, B.; Guo, D.; Fan, P. Towards multilingual end-to-end speech recognition for air traffic control. IET Intell. Transp. Syst. 2021, 15, 1203–1214. [Google Scholar] [CrossRef]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; et al. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. In Proceedings of the 33nd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 173–182. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning—ICML 2006, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar] [CrossRef]
- Heafield, K.; Lavie, A. Combining Machine Translation Output with Open Source: The Carnegie Mellon Multi-Engine Machine Translation Scheme. Prague Bull. Math. Linguist. 2010, 93, 27–36. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Items | ATCSpeech | Test-Real | |||
|---|---|---|---|---|---|
| Chinese | English | Chinese | English | ||
| Amount | #Hours | 39.83 | 18.69 | 3.56 | 1.46 |
| #Utterance | 45,586 | 16,939 | 3411 | 1485 | |
| Speaker role (Hours) | Pilot | 21.12 | 8.92 | 1.83 | 0.69 |
| Controller | 18.73 | 9.77 | 1.73 | 0.77 | |
| Speaker gender (Hours) | Male | 36.16 | 16.94 | 3.22 | 1.35 |
| Female | 3.69 | 1.75 | 0.34 | 0.11 | |
| Methods | Test Set | ||||
|---|---|---|---|---|---|
| AM | LM | Test | Test-Real | ||
| CER% | CSA% | CER% | CSA% | ||
| ASR-C | - | 8.10 | 65.58 | 7.94 | 64.07 |
| N-gram | 6.31 | 74.17 | 6.49 | 71.88 | |
| RNNLM | 6.13 | 76.58 | 6.24 | 75.81 | |
| CALM | 4.57 | 87.50 | 4.80 | 87.39 | |
| ASR-E | - | 10.40 | 46.54 | 10.81 | 45.68 |
| N-gram | 9.20 | 62.88 | 9.35 | 61.79 | |
| RNNLM | 8.10 | 64.86 | 8.24 | 63.19 | |
| CALM | 6.20 | 80.88 | 6.79 | 79.67 | |
| ASR-A | - | 6.96 | 65.34 | 7.35 | 66.17 |
| N-gram | 5.95 | 73.57 | 6.37 | 71.74 | |
| RNNLM | 5.91 | 74.17 | 6.03 | 77.60 | |
| CALM | 4.36 | 85.92 | 4.64 | 85.47 | |
| Methods | Test Set | ||||
|---|---|---|---|---|---|
| N-Best System | LM | Test | Test-Real | ||
| CER% | CSA% | CER% | CSA% | ||
| ASR-A | RNNLM | 6.79 | 67.52 | 7.12 | 63.53 |
| CALM | 6.49 | 74.69 | 6.70 | 75.97 | |
| ASR-A + N-gram | RNNLM | 6.17 | 69.83 | 6.29 | 68.75 |
| CALM | 5.79 | 84.62 | 5.68 | 85.15 | |
| Methods | Test Set | ||||
|---|---|---|---|---|---|
| N-Best System | LM | Test | Test-Real | ||
| CER% | CSA% | CER% | CSA% | ||
| ASR-A | RNNLM | 6.27 | 69.82 | 6.76 | 70.79 |
| CALM | 5.71 | 79.50 | 5.86 | 79.26 | |
| ASR-A + N-gram | RNNLM | 6.02 | 72.76 | 6.71 | 71.54 |
| CALM | 4.96 | 85.24 | 5.05 | 85.76 | |
| Ground Truth | Contextual Information | Outputs | |||
|---|---|---|---|---|---|
| AM | KenLM | RNNLM | CALM | ||
| Cathay two two eight niner line up runway zero two left | Cathay two two eight niner <eos> Air China four … United four five one <eos> | Cathay two eight niner line up runway zero two left | Cathay two eight niner line up runway zero two left | Cathay two eight niner line up runway zero two left | Cathay two two eight niner line up runway zero two left |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, D.; Zhang, Z.; Fan, P.; Zhang, J.; Yang, B. A Context-Aware Language Model to Improve the Speech Recognition in Air Traffic Control. Aerospace 2021, 8, 348. https://doi.org/10.3390/aerospace8110348
Guo D, Zhang Z, Fan P, Zhang J, Yang B. A Context-Aware Language Model to Improve the Speech Recognition in Air Traffic Control. Aerospace. 2021; 8(11):348. https://doi.org/10.3390/aerospace8110348
Chicago/Turabian StyleGuo, Dongyue, Zichen Zhang, Peng Fan, Jianwei Zhang, and Bo Yang. 2021. "A Context-Aware Language Model to Improve the Speech Recognition in Air Traffic Control" Aerospace 8, no. 11: 348. https://doi.org/10.3390/aerospace8110348
APA StyleGuo, D., Zhang, Z., Fan, P., Zhang, J., & Yang, B. (2021). A Context-Aware Language Model to Improve the Speech Recognition in Air Traffic Control. Aerospace, 8(11), 348. https://doi.org/10.3390/aerospace8110348