1. Introduction and Background
With the rapid development of the civil aviation industry, there has been an increase in the number of routes and aircraft sorties, the complexity of the sector, and the air traffic controller workload, and thus on-job fatigue is becoming a major issue affecting the safety of civil aviation. In 2011, the FAA recommended double duty at night because of incidents of controllers sleeping on duty. In 2014, China Eastern Airlines Flight MU2528 was forced to turn around during its approach to Wuhan because the controller was asleep on duty.
In 2016, due to fatigue, the tower controller of Shanghai Hongqiao Airport gave conflicting control instructions, which led to the aircraft taking off and crossing the runway using the runway at the same time, resulting in an A-class runway invasion incident. Fatigue seriously affects the safety of the civil aviation industry. Increasingly, more researchers are committed to solving the problem of fatigue, currently from both subjective and objective perspectives.
The subjective aspect is the use of fatigue scales; the objective aspect includes the detection of physical and psychological parameters and their use, of which the most suitable parameter for controller fatigue detection is the detection method based on eye condition.
In 2019, Jin et al. [
1] proposed using the support vector machine model to fuse multiple physiological parameters and eye movement indicators to construct a controller fatigue detection model. The accuracy of identifying the normal group and the sleep-deprived group was 94.2%. Zhao et al. [
2] proposed an EM-convolution neural network to detect the state of the eyes and mouth from ROI images. The algorithm performance was better than that of algorithms based on VGG16, InceptionV3, AlexNet and others, with an accuracy and sensitivity of 93.623% and 93.643%, respectively.
Feng et al. [
3] proposed adding a central loss function to softmax loss to optimize the problem of large intraclass spacing in deep convolutional networks and improve the accuracy of facial fatigue state recognition. Zheng [
4] proposed a method that combines the MTCNN algorithm with an improved discriminative scale space tracking algorithm for face detection and key point positioning, and it uses the MobileNet V2 algorithm to determine the state of the eyes and mouth.
For comprehensively judging whether a driver is fatigued through fatigue indicators such as PERCLOS value, blink frequency, closed eye time, and yawn frequency. Mahmoud et al. [
5] used the YOLO algorithm to count the number of people in a specific area and built a face detection system based on deep learning. The YOLO algorithm directly implements an end-to-end training process and has a higher advantage in detection rate, and the recall and accuracy rates also showed great improvement.
Xiao et al. [
6] proposed a method to detect the fatigue state of a driver by using the spatiotemporal characteristics of the driver’s eyes. In the end, the built model was used to detect the driving state, and an accuracy of 96.12% was achieved. Hu et al. [
7] optimized the single shot multibox detector method to improve the robustness under light changes and similar background interference. However, in dealing with the task of data scarcity, the current network often produced data dependence problems. In order to solve the problem of fewer datasets, a transfer learning strategy was proposed.
The concept of deep transfer learning was also proposed, and network-based transfer learning can be widely used in different fields. Xie et al. [
8] used the network model trained on ImageNet to fine-tune and migrate on the DeepFashion dataset. Transfer learning effectively improves the classification accuracy and timeliness of the model. In the field of medical imaging, where data are scarce, transfer learning is an effective method. Atabansi et al. [
9] used the high-resolution image features of the large dataset to train a relatively small dataset model, which enhanced the generalization ability and verified the transfer learning strategy, and a higher accuracy rate was obtained.
Khan et al. [
10] used the public PCG dataset to pre-train a simple and lightweight CNN model for the detection of cardiovascular diseases and obtained a high detection accuracy rate. At present, the methods for eye feature extraction and state determination are mainly machine-learning and deep-learning methods.
Traditional machine learning methods all use shallow structures. These structures contain, at most, one or two layers of nonlinear transformations, including logistic regression, random forest, SVM, maximum entropy, Gaussian mixture models etc. The shallow structure can solve simple problems, or the effect is obvious for more restricted ideal problems; however, due to the manual extraction of feature information, selecting effective texture features often requires a lot of time and rich experience.
With the rapid development of deep learning, a large number of models based on supervised training [
11] and unsupervised training [
12] have been proposed, such as Deep Convolutional Neural Networks (DCNN) [
12], Deep Neural Networks (DNN) [
13,
14], Deep Belief Networks (DBN) [
15], Long Short-Term Memory (LSTM) [
16], non-linear unit activation function (Rectified linear unit, ReLU) [
14], and the Dropout strategy [
14], among others.
In the field of image detection and recognition, compared with traditional methods, deep learning methods have the advantage of omitting the steps for artificial feature extraction. At present, DNN and DCNN models are widely used in this field.
The following points summarize the main contributions of this work:
(1) A single network model needs to be optimized for detection accuracy. Therefore, combining the DNN model extraction vector features and DCNN model extraction texture features, a deep-fusion neural network (DFNN) model was built, which can extract image features more accurately.
(2) In order to solve the problem of insufficient controller fatigue data and the data dependence of the deep learning network model, the transfer learning strategy is used to pre-train the DNN and DCNN network, and the trained parameters are transferred to the DFNN model. The DFNN model has higher accuracy and reliability in detecting small-sized images of eyes compared with the trained VGG [
17], ResNet [
18] and Inception [
18,
19] models.
(3) Aiming at the special low-light working environment of the controller, the controller needs to constantly scan the radar screen, issue control instructions and deploy flight conflicts. Combined with the real-time requirements for the fatigue detection task of the controller, an eye selection mechanism (ES) is proposed, which can select a single eye for fatigue detection to increase the detection rate.
In this paper, by building an ES-DFNN controller fatigue detection model based on transfer learning, the memory of the model is reduced, and the detection accuracy and real-time performance are further improved. The structure of this paper is as follows:
Section 2 outlines the fatigue detection process and the key technologies of fatigue detection.
Section 3 focuses on the eye fatigue state detection model. The dataset and experimental results are described in detail in
Section 4. Finally, the main research results are analyzed and summarized in
Section 5.
2. Preliminary Background
The fatigue testing process is shown in
Figure 1.
First, the video image is used to detect the face of the controller through MTCNN and, at the same time, the coordinates of the left and right eyes are obtained. Secondly, the left-eye or right-eye image to be detected is obtained through the eye selection mechanism. Thirdly, DCNN and DNN models are pre-trained by transfer learning on the FER2013 [
20] and LFW [
21] datasets, respectively. The two trained models are fused to build a DFNN model. Fourthly, the eye state dataset is used to fine-tune the DFNN model. Finally, determination of whether the controller is fatigued occurs through PERCLOS.
2.1. Face Detection and Feature Point Positioning
Face detection and feature point positioning are the key parts of fatigue recognition. In the actual complex control environment, because the approach and area controllers need to pay attention to the aircraft dynamics on the radar screen in real time, the light is dimmed to ensure that the controller can see the radar screen in the control room clearly. At present, the traditional face detection method based on Adaboost classifier [
22] is susceptible to interference from a complex background and dim lighting conditions, resulting in unstable detection results, and it is easy to falsely detect similar face areas as human faces; thus, the false detection rate is high.
The method based on template matching cannot be adaptively changed due to the size and shape of the template, and it is easily affected by changes in the controller’s posture and the occlusion of objects in practical applications. Thus, the requirements for face detection and face key point positioning can no longer be met. MTCNN can combine face detection and face key point positioning at the same time, and the positioned face key points can be used to realize face correction [
23].
The MTCNN algorithm consists of three stages, as shown in
Figure 2.
The first stage is the P-Net convolutional neural network, where the candidate windows and boundary regression vector are obtained. The candidate forms are calibrated according to the bounding box, and the nonmaximum value suppression algorithm is used to remove overlapping windows.
The second stage is the R-Net convolutional neural network, which trains the pictures containing candidate forms determined by P-Net in the R-Net network and uses the fully connected neural network for classification. Bounding box vectors are used to fine-tune candidate windows and nonmaximum suppression algorithms to remove overlapping windows.
The third stage is the O-Net convolutional neural network, whose network and function are similar to R-Net, and, while removing the overlapping candidate windows, the positions of five key points of the face are calibrated.
Face detection and key point positioning are shown in Formula (
1).
Among them, is the coordinates of the bounding box of the detected face; and represent the point coordinates of the left eye and right eye respectively; is the video image to be detected.
2.2. Transfer Learning
Transfer learning defines the concepts of domain and task [
24]. The domain
includes two parts: the feature space
and the edge probability distribution
; the task
includes two parts: the label space
y and the target prediction function
. The source domain is defined as
, the source task is
, the target domain is
, and the target domain task is
. Transfer learning is to transfer the relevant information based on
and
to
based on
in the case of
or
, aiming to extract and transfer the potentially transferable knowledge in
and
to improve the efficiency of the prediction function. The schematic diagram of transfer learning is shown in
Figure 3.
At present, there are two problems in constructing a controller fatigue detection model with high accuracy and reliability. On the one hand, there are less data on eye fatigue of controllers, and data collection is more complex, expensive, and affects normal control tasks. It is difficult to construct a large-scale, high-quality labeled controller fatigue dataset; on the other hand, the existing deep learning methods are severely data dependent, and large-scale data are needed to understand the potential information under the data.
The feature extraction layer in the deep network model can extract the advanced characteristics of the training data, and the decision-making layer can identify the information needed to help make the final decision.
Transfer learning allows flexibility with regard to the two basic assumptions in traditional classification tasks: (1) the training samples and the new test samples meet the condition of independent and identical distribution; (2) there must be large-scale and high-quality training samples [
25]. The theory of transfer learning provides a method to solve this problem.
First, this paper pre-trains the DNN and DCNN network models by using the FER2013 and LFW datasets that are related to the target domain data or pixels similar to each other to obtain the initial parameters of the deep model. Second, the pre-trained DNN and DCNN model parameters are transferred to the fused DFNN model, and the feature extraction layer of the DFNN model is frozen, and part of the fully connected layer and output layer are opened. Finally, the DFNN model is fine-tuned using the controller’s eye image to obtain an eye state classification network model.
2.3. Eye Selection Mechanism
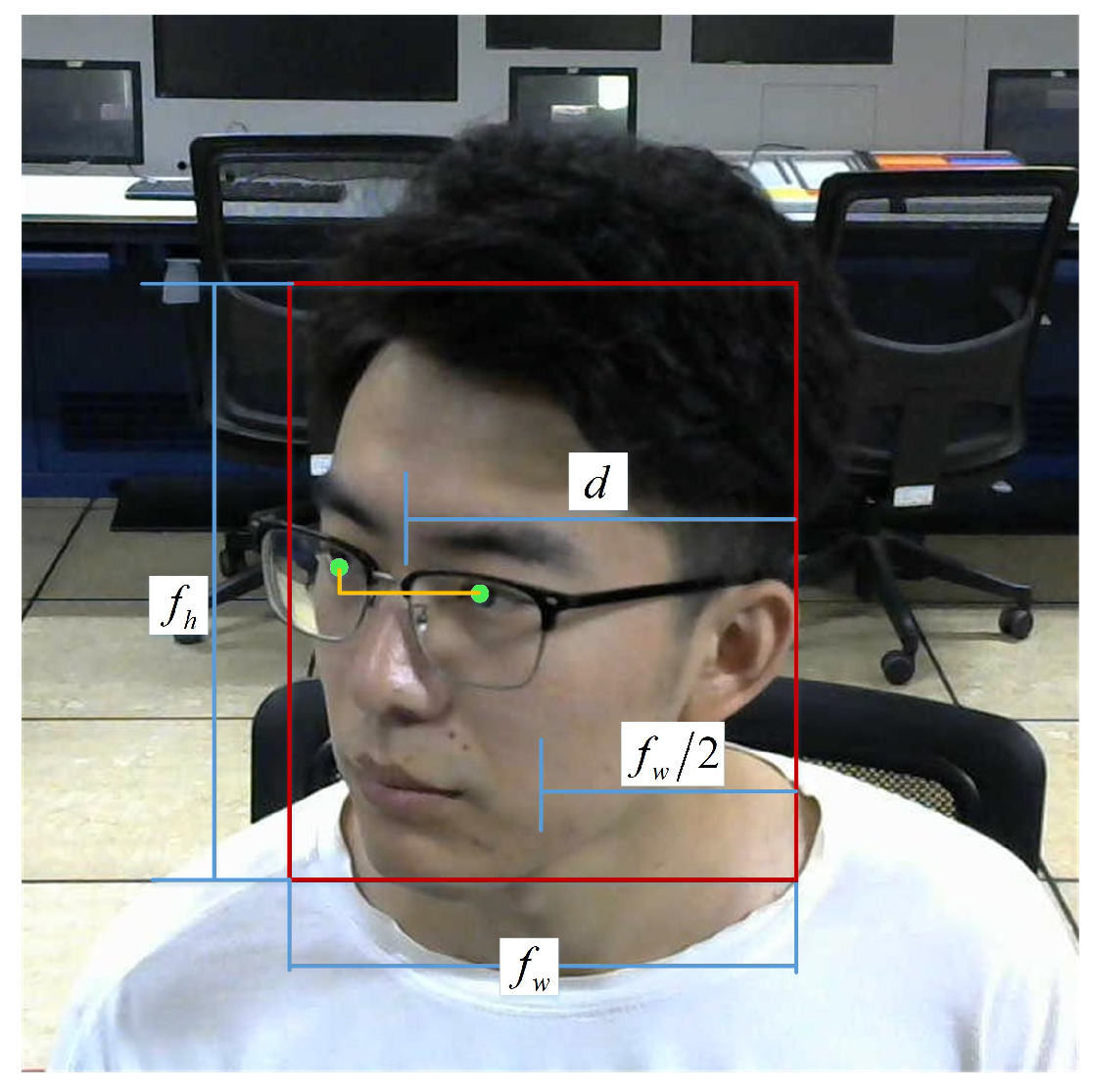
In the actual control environment, the controller needs to scan the radar screen back and forth uninterruptedly. Therefore, the head posture of the controller is diversified. When one eye is blocked due to head deflection, it is difficult to correctly detect the state of both eyes at the same time. When this happens, one eye can remain undetected, which can greatly interfere with the detection result. When the head is greatly tilted or deflected, the left and right eye areas are selected to detect the unobstructed eyes. When the left and right eyes are not covered, monocular with high confidence is also detected.
The eye selection mechanism is shown in
Figure 4, where
and
represent the width and height, respectively, of the face regression box detected by MTCNN, and
d represents the vertical distance from the midpoint of the abscissa of the left and right eyes to the right boundary of the face regression box. The formula is as follows:
In the Formula (
2), when
d is less than
, the left eye is selected as the eye to be tested; otherwise, the right eye is tested.
3. Methodology
At present, the algorithms for recognizing the open and closed state of eyes are divided into two types: manual feature extraction and automatic feature extraction. Among them, manual feature extraction mainly includes the template matching detection method, texture feature detection method, and shape feature detection method [
26,
27]. These methods rely on the extraction of texture features, and the selection of texture features requires a great deal of experimentation and sufficient experience.
The automatic extraction of features is used in deep learning methods, such as deep neural networks [
28,
29], deep convolutional neural networks [
30] and recurrent neural networks [
31], omitting manual extraction of features and automatically extracting advanced features of the dataset. Accuracy and reliability are also better than in manual feature extraction methods.
In deep learning methods, DNN is mainly used for natural language processing and visual target detection and recognition, such as speech recognition [
32], wind speed prediction [
33] and image classification. However, as the depth of the network increases, the number of parameters exponentially increases. When processing target detection and segmentation tasks, the gradient becomes increasingly sparse and converges to a local minimum.
The deeper the network, the higher the calculation performance requirements. DCNN is mainly used in speech recognition, document analysis [
34], language detection, image recognition [
35] and other fields, through convolution operations and pooling the dimensionality reduction and fully connected layer process images, which can effectively extract features. A single network model is easily affected by gradient dissipation and local optimization, resulting in poor accuracy and reliability.
The DFNN model can meet real-time requirements with its shallow depth and small memory. The DCNN model used for fusion mainly extracts pictures the texture feature, and the DNN model extracts vector features by converting the picture into a one-dimensional vector. The fused DFNN model can extract eye features more finely, which can meet the accuracy requirements. The advantages and disadvantages of the existing methods are shown in
Table 1.
3.1. DCNN Model
A deep convolutional neural network is a network model composed of several layers of “neurons” [
12]. Each neuron in the current layer applies a linear filter to the output of the previous layer of neurons and superimposes a bias on the output of the filter. A nonlinear activation function is applied to the result, which allows us to obtain a feature map.
(1) The convolutional layer is the core of the entire neural network, which uses two methods of “local perception” and “weight sharing” to perform dimensionality reduction and feature extraction. Compared with the neural network with different filters applied to all neurons, the number of parameters for the convolution shared filter structure is drastically reduced, reducing its ability to overfit. The formula is as follows:
In Formula (
3),
and
are the input and output of the
layer,
is the pixel of the
layer feature map,
W is the convolution kernel, and
b is the bias term. In Formula (
4),
,
p and
f are the convolution step size, the number of filling layers and the size of the convolution kernel, respectively.
L is the number of network layers, and the convolution step size refers to the step size of the convolution kernel at each time.
(2) The pooling layer is also called the downsampling layer, which performs feature selection and filtering on the feature map. The pooling layer uses max-pooling with a size of .
(3) The fully connected layer performs a nonlinear combination of the features extracted by the convolutional layer and the pooling layer to achieve classification.
In Formula (
5),
and
are the input and output of the
l layer,
f is the activation function, and
W and
b are the weight and bias, respectively.
The DCNN model consists of six convolutional layers, three pooling layers and one fully connected layer, as shown in
Figure 5. The size of the convolution kernel of the first convolutional layer is
, and the size of the convolution kernel of the other convolutional layers is
. In all convolutional layers, the boundary mode of the convolution operation is the same, that is, the dimensions of the input and output feature maps in the convolution operation are the same. The pooling layer uses the max-pooling strategy to reduce the dimensionality of the feature map, and the dimensionality reduction ratio of all pooling layers is
.
In order to prevent the model from overfitting due to the small dataset, set BatchNormalization after the convolutional layer, add Dropout regularization after the pooling layer, and set the Dropout regularization parameter to 0.25. The number of units in the fully connected layer is 512. Finally, a softmax classifier is added to the top layer as the output of the model. The activation functions of all layers in the model are ReLU functions.
The DCNN model mainly performs convolution calculation, pooling dimensionality reduction and fully connected flattening into a one-dimensional vector on the controller’s eye image obtained by the eye screening mechanism. The texture feature extraction is performed on the image of the controller’s eyes to determine the state of the controller’s eyes as open or closed.
3.2. DNN Model
The full name of DNN is deep neural network [
28]. Its model structure is shown in
Figure 6. It consists of one input layer, three hidden layers and one output layer. The number of input layer units is
; the numbers of neurons in the hidden layer are 256, 512 and 256; the output layer is a softmax classifier, and the number is 2. First, the DNN model preprocesses the eye image and converts the extracted eye image size into pixels. Second, it converts the two-dimensional image into a one-dimensional vector by fully connecting the input image of the controller’s eye.
The input vector is normalized, and the vector features of the eye image are extracted through the hidden layer through the weight parameter and the nonlinear unit activation function. Finally, the softmax judges the state of the eyes as open or closed. All activation functions in the model are ReLU functions, and the Dropout value of each layer is set to 0.5.
3.3. DFNN Model
The built DNN model and DCNN model are fused in the proposed DFNN model. The DCNN model mainly extracts the texture features of the eye image through convolution operation, pooling dimensionality reduction and the fully connected layer, while DNN mainly extracts the eye through the fully connected layer and the vector features of the picture. The DFNN model can more finely extract the features useful for eye state classification. The DFNN structure diagram is shown in
Figure 7.
First, the eye image is input to the DCNN model, and the eye image is converted into a one-dimensional vector and input to the DNN model. Then the result weighted average method is used to fuse the output results of the fully connected layers of the two models, where the weight of the DCNN model is 0.6 and the weight of the DNN model is 0.4, the fusion flow chart is shown in
Figure 8. Finally, the softmax classifier is used to classify the fused features.
3.4. Control Fatigue Judgment Index
When the controller has scanned the radar screen for a long time, adjusting the flight interval and issuing control instructions, fatigue characteristics will begin to appear, such as slow blinking, long-term continuous closed eyes etc. Therefore, the controller’s fatigue level can be judged by obtaining the controller’s eye status information.
represents the ratio of the number of closed eye frames to the total number of frames in that period of time [
36],
In Formula (
6),
m represents the number of closed-eye frames, and
M represents the total number of eye-detected frames during this period. When
is greater than the threshold, the controller is determined to be in a fatigue state. In the specific test, there are three measurement methods: EM, P70 and P80, as shown in
Table 2.
5. Conclusions
Eye condition detection is the primary method for fatigue detection in air traffic controllers. In order to improve the accuracy and detection rate of fatigue detection, a ES-DFNN model based on the classification task of small pixel images of the eyes was proposed to realize the method for fatigue detection in a controller. The following conclusions are drawn:
(1) In order to improve the robustness of the fatigue detection model, the MTCNN detection algorithm can be used to detect nonfrontal face images in real time.
(2) An eye-screening mechanism was proposed. By detecting the deflection or tilt angle of the head and comparing the left and right eye detection confidence, the eye pictures to be tested were selected to replace traditional binocular detection. The detection rate was improved and meets the requirements for the real-time detection of fatigue status.
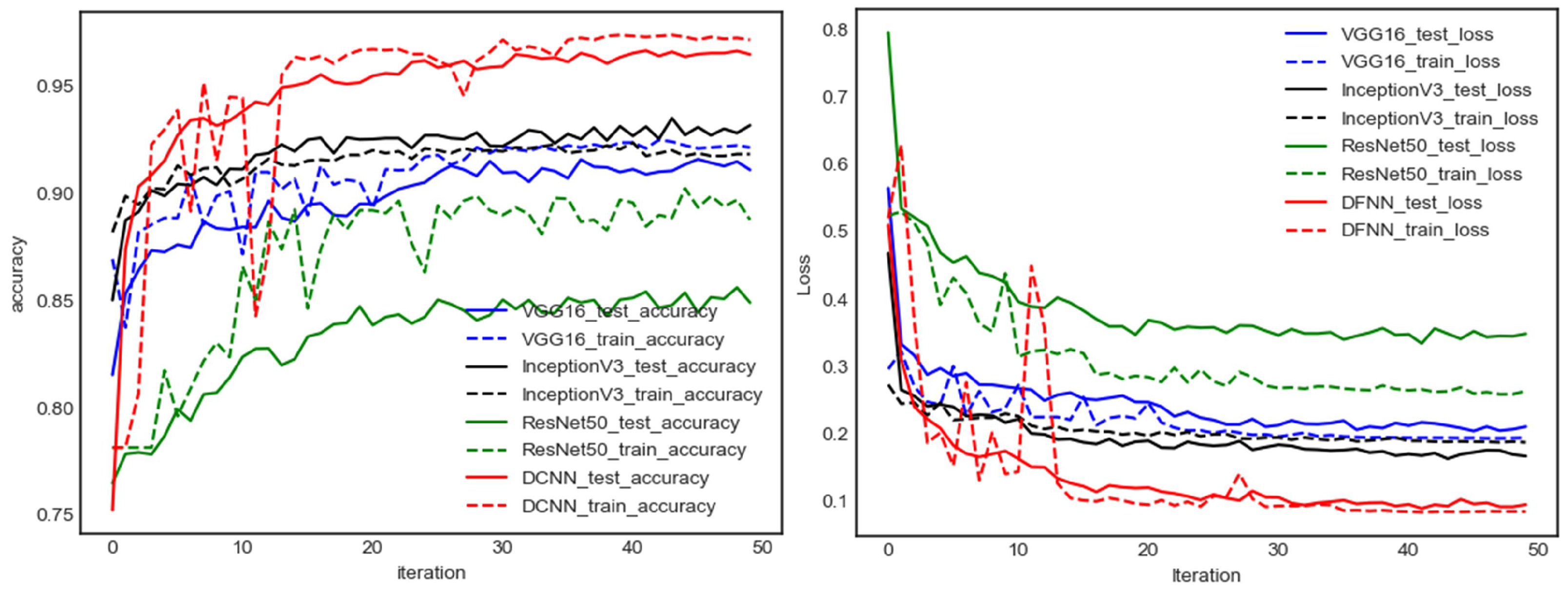
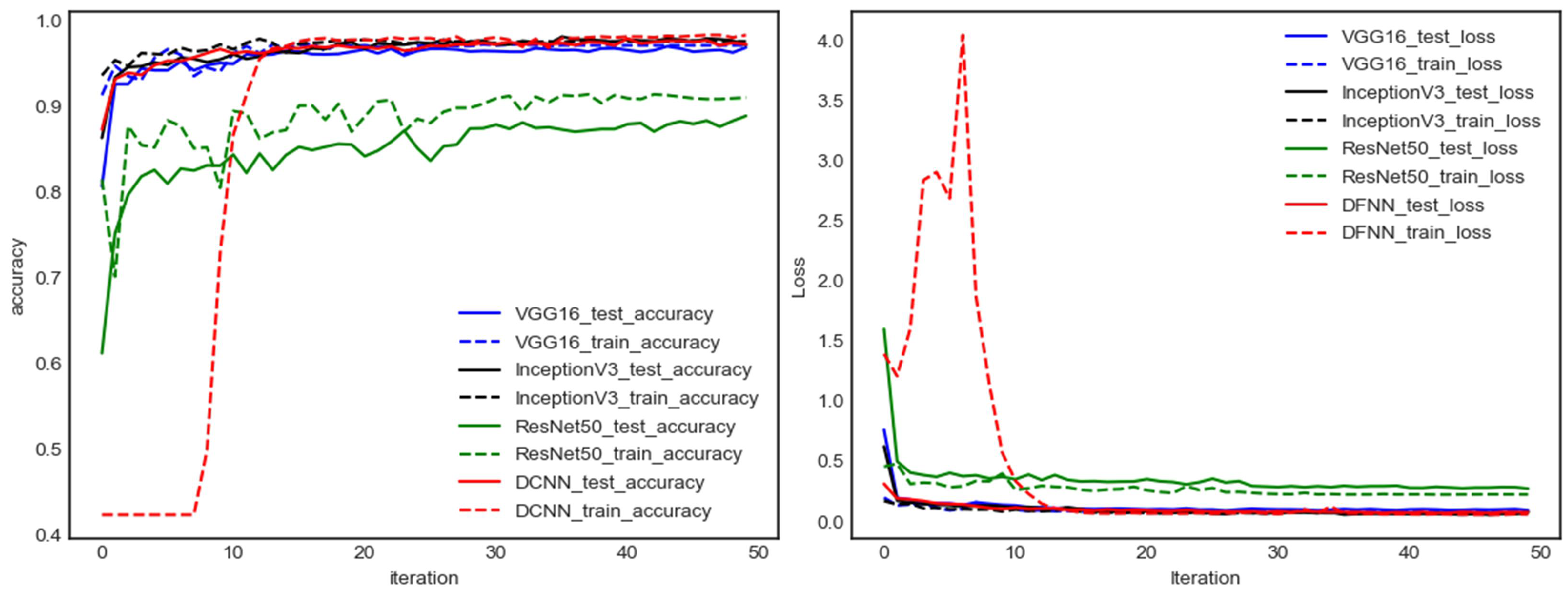
(3) In order to improve the detection efficiency and accuracy, the DFNN model fused with DCNN and DNN was used to learn and extract eye fatigue features. Applying the DFNN model on the ZJU dataset resulted in the accuracy being increased by 7%. The increase for the CEW dataset ranged from 3% to 7%. On the ATCE dataset, the test accuracy of the DFNN model was improved by 2% compared with the ZJU dataset and the CEW dataset.
When this model recognizes extreme head postures, nondetection may occur. In future work, we will enrich the eye dataset under extreme head postures, optimize face detection methods and increase the diversity of detection to make it more consistent with the actual control situation.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}