1. Introduction
An artificial neural network (ANN) is a computational model based on the human nervous system and it is a useful modeling tool. For this reason, ANNs have been researched with interest in many disciplines such as engineering, finance, technology, etc. ANN structures inspired by biological neural networks have been developed and used in classification [
1,
2,
3], signal processing [
4,
5] and prediction tasks [
6,
7,
8], as well as in various other studies [
9,
10,
11,
12]. In the successful use of an ANN, it is important to choose the training algorithm, the activation function in the neurons, the neural network structure and the parameters (weights and biases) correctly. The training algorithms used in the training of networks aim to create a suitable network structure for the problem by finding the optimal weights and bias parameters. For example, studies have been conducted in an attempt to find the optimal weights and biases by keeping the network topology and activation function constant [
13,
14,
15].
There is a need for a training set that includes suitable features for network training. The parameters of the network are regulated by the training algorithms using the training data [
16]. In this context, the main purpose of network training is to ensure harmony between network output and real output by means of training algorithms.
There are many algorithms and methods in the literature that can be used in ANN training. The most commonly used mathematical methods are the back-propagation (BP) [
17], gradient descent (GD) [
18], conjugate gradient (CG) [
19] and Levenberg–Marquardt (LM) methods [
20]. Many heuristic algorithms can be used to construct the appropriate network in FNN training.
In [
14], the PSOGSA algorithm was proposed for FNN training. The obtained results were compared with the PSO-based FNN (FNNPSO). It has been observed that the PSOGSA-based FNN (FNNPSOGSA) algorithm produces better results compared to the PSO-based FNN (FNNPSO) and GSA-based FNN (FNNGSA) algorithms.
A study was conducted to investigate the effectiveness of the use of the VS algorithm in FNN training [
13]. In [
13], the performance of the VS-based FNN (FNNVS) was compared with the performance of an FNN trained with other optimization algorithms using different classification problems. The obtained results showed that the VS algorithm can be used in FNN training. Furthermore, the discrete-continuous version of the vortex search algorithm was used to determine the sizes and locations of PV sources [
21]. In [
22], the optimal selection of conductors in three-phase distribution networks was performed through the use of a discrete version of the vortex search algorithm.
It can be used in models obtained as a result of hybridizing classical training algorithms and heuristic optimization algorithms in ANN training. In [
23], a new method was presented, based on hybridizing the artificial bee colony (ABC) algorithm and the LM algorithm (ABC-LM). The authors carried out this study to prevent the LM algorithm from getting stuck on local minimums and the ABC algorithm converged slowly to global minimums.
Heidari et al. [
24] presented a stochastic training algorithm in their study. They suggested that the grasshopper optimization algorithm (GOA) performed well in the solution of optimization problems and could also be used in the training of multilayer perceptron (MLP) neural networks. The GOAMLP model was compared with other efficient algorithms using five different classification problems. The authors stated that the use of GOAMLP contributed to obtaining accurate classification performance.
In [
25], the dragonfly algorithm (DA) was used in FNN training. Experiments were conducted on classification problems and a civil engineering problems. The obtained results showed that the DA was quite successful in FNN training. Additionally, they tried to emphasize the avoidance of the local optima.
In [
26], weights and biases parameters of the FNN were optimized by means of the whale optimization algorithm (WOA). Within the scope of the study, comparisons were made with different algorithms through classification problems. The authors stated that it performed better in terms of its avoidance of the local optimum and its convergence rate. In addition to the studies mentioned above, other studies have been conducted using optimization algorithms for ANN training. These include studies of the krill-herd algorithm (KHA) [
27], the cuckoo search (CS) algorithm [
28] and the the symbiotic organism search (SOS) algorithm [
29].
Table 1 presents some algorithms used in FNN training. The main purpose of these studies was to train the FNN structure in the best way. The main difference between these studies is that they used different algorithms from one another. The algorithm presented in this study is different from these, and it was also used for transmission line fault classification.
To the best of our knowledge, this is the first study conducted on HTVS-based FNN training. In this study, our main purpose was not to find the most suitable FNN structure for a test problem or to obtain the smallest error value that could be achieved. Rather, the primary purpose of this study was to present the use of the HTVS algorithm [
32] in FNN training and to compare its performance with that of the VS [
33], PSO [
34], PSOGSA [
14] and GSA [
35]. Therefore, 3-bit parity, iris classification, wine recognition and seed classification benchmark datasets were used for performance comparisons. In order to show that the HTVS algorithm had a competitive character compared to other algorithms used in FNN training, tests were conducted using different hidden neuron numbers in the FNN structure.
The second main purpose of the study was to show that the proposed algorithm can be used in fault classification on transmission lines. For this purpose, a transmission line of 735 kV, 60 Hz and 100 km longwas modeled as frequency-dependent with the help of Matlab/Simulink. Fault data were produced and recorded on the modeled transmission line. Using these data, the FNNHTVS algorithm and the optimization algorithm-based FNNVS, FNNPSO, FNNPSOGSA and FNNGSA algorithms were compared. Additionally, the performance of the proposed algorithm was compared with that of classifiers such as a support vector machine (SVM), the K-nearest neighbor (KNN) method and an FNN with LM and Naive Bayes (NB). The results showed that the FNNHTVS algorithm was quite successful.
The main contributions of this study are briefly listed as follows.
The HTVS algorithm is presented for the first time as an alternative algorithm to overcome slow convergence and local optimum problems in FNN training.
The effectiveness of the HTVS algorithm in FNN training is demonstrated.
It has been proven that the FNNHTVS structure can achieve results comparable to and better than those of other successful algorithms in classification studies.
It has been shown that the FNNHTVS algorithm can be used as an alternative algorithm for transmission line short-circuit fault classification tasks.
The remainder of this paper is organized as follows. In
Section 2 we explain the basics concept of the FNN, the HTVS algorithm and FNN training using HTVS. In
Section 3 we present the experimental results and a discussion of the performance of the algorithms. In
Section 4 we present an evaluation of the performance of FNNHTVS in fault classification. In
Section 5, we present our conclusions.
3. Validation of the FNNHTVS via Benchmark Datasets
In this section, the proposed FNNHTVS training algorithm is compared with the FNNVS, FNNPSO, FNNGSA and FNNPSOGSA algorithms. All algorithms are run on FNNs with the same structure. To analyze the performance of the FNNHTVS algorithm and to compare it with other algorithms, four frequently used classification problems were selected. These are iris classification, wine recognition, seed classification and the 3-bit parity problem. The first three of these were taken from the UCI machine learning repository of the University of California at Irvine [
37]. The fourth problem is the 3-bit parity problem. The input and output values related to this problem are given in
Table 2.
The problems chosen for comparison are classification problems that are frequently used in the literature [
13,
14,
15]. The features and class numbers related to the problems are expressed in
Table 3.
The parameters common to all algorithms were kept the same. For all algorithms, the population size and maximum iteration were set to 30 and 100, respectively. An initial range of candidate solutions of [−50, 50] was preferred so that all the training algorithms could search within a wider space. Additionally, these algorithms contain user-controlled parameters.
Table 4 presents these parameters.
In this study, a network structure with 1 input, 1 hidden and 1 output (i-h-o) layer was selected. The Sigmoid function was determined for each node as the activation function. The algorithms were compared using benchmark datasets for 11 different numbers of hidden nodes. The algorithms were run until they reached the maximum number of iterations. Each algorithm was run 30 different times for each case. MSE was chosen as the comparison parameter and the mean, standard deviation (std. dev.) and best and worst values of the obtained data were recorded. These recorded statistical values provided information for the comparison. However, the Wilcoxon signed rank (WSR) pairwise comparison test was also applied to make a stronger comparison. The WSR test was used to determine which of the two comparing methods was superior. In this study, the statistical significance value was 0.05 for the WSR test. For each problem, the FNNHTVS algorithm was compared with other algorithms separately and measures of superiority, equality and loss were noted. Detailed information about the WSR test can be found in [
38].
3.1. 3-Bit Parity Problem
The 3-bit parity problem is a frequently used nonlinear problem. It is an important problem used to measure the performance of training algorithms against nonlinear problems. In the three-input, single-output 3-bit parity problem, if the number of ones in the inputs is odd, the output is one; if even, the output is zero. The input and output sets of this problem are expressed in
Table 2.
is the number of hidden nodes with
= 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 20, 30. For the 3-bit parity problem, a 3-
-1 FNN structure is used. This structure has a total of (
) parameters,
weights and
biases, and the parameter range is taken as [−50, 50]. Algorithms were evaluated based on the mean, standard deviation and the best and worst value of MSE. The statistical results obtained after 30 independent runs are shown in
Table A1.
Looking at
Table A1 from a general perspective, it can be observed that the FNNHTVS algorithm performed better than the other compared algorithms. The proposed algorithm for all hidden nodes obtained the best mean MSE values. This indicates that it effectively escaped the local minimum. We determined that the FNNGSA algorithm had the lowest standard deviations, except for hidden nodes 7, 15, 20 and 30. When the best and worst MSE values were examined, we found that the best values belonged to the FNNHTVS algorithm. The closest follower of the FNNHTVS algorithm was the FNNVS algorithm.
Additionally, the WSR test results are presented in
Table 5. The Winner column in
Table 5 shows in how many cases (11 different hidden nodes) the two compared algorithms outperformed each other. The column specified as Equal shows the number of cases where the algorithms could not outperform each other. As a result of the paired comparisons, the superiority of the FNNHTVS algorithm can be observed. Within the framework of the results, the effectiveness of the proposed training algorithm for this nonlinear problem has been shown.
3.2. Iris Classification Problem
The iris dataset is the best-known and most commonly used dataset in the pattern recognition literature [
37]. The dataset consists of four inputs and three classes. The dataset contains a total of 150 samples, fifty for each class. The first class is classified as
Iris setosa, the second class is
Iris Versicolor and the third class is
Iris Virginica. For the iris classification problem, a 4-
-3 FNN structure is used. This structure has a total of
parameters, 7
weights and
biases, and the initial parameter range is taken as [−50, 50]. The statistical results obtained after 30 independent runs are presented in
Table A2.
Based on the MSE results shown in
Table A2, the FNNHTVS training algorithm displayed the best mean values for all cases except
. For
, the proposed training algorithm was ranked third.FNNHTVS had the smallest values for
. For other cases, it was most often ranked third. Its performance was competitive with that of the other compared algorithms in terms of its robust operation. In this problem, it was observed that the FNNVS algorithm exhibited the worst standard deviation value. In terms of the MSE values, FNNHTVS was ranked first in 7 of 11 FNN structures with
.
The pairwise comparisons are presented in
Table 6. As a result of comparing FNNHTVS and FNNVS, FNNHTVS won in nine cases and lost in one case. The lost
value was determined to be 30.The two compared algorithms were not able to outperform each other for
. In addition, the FNNHTVS algorithm lost to the FNNPSO algorithm for
.
3.3. Wine Recognition Problem
These data are the result of a chemical analysis of wines grown in the same region in Italy and produced from three different types of grapes [
37]. Within the scope of the analysis, the amounts of 13 components found in wine types were recorded. Therefore, the dataset consists of 13 features. Wine types are divided into three classes according to these inputs. The dataset contains 178 samples. In the wine recognition dataset, there are 59 data samples for the first class, 71 for the second class and 48 for the third class. For the wine recognition problem, a 13-
-3 FNN structure is used. This structure has a total of
parameters,
weights and
biases, and the initial parameter range is taken as [−50, 50]. The statistical results obtained after 30 independent runs are presented in
Table A3.
For all
values, the FNNHTVS training algorithm achieved the best statistical values and showed superior performance. The FNNVS training algorithm was also a follower of the proposed algorithm in terms of performance. The WSR test results presented in
Table 7 support the claim that the proposed algorithm outperformed the other compared algorithms.
3.4. Seed Classification Problem
This dataset, which can be used in performance evaluations of classification and cluster analysis algorithms, includes the results of the classification of three different wheat seeds. The dataset consists of seven inputs and three classes [
39]. The dataset contains 210 samples, 70 for each class. The first class is classified as Kama, the second class is Rosa and the third class is Canadian. For this problem, a 7-
-3 FNNstructure is used. This structure has a total of
parameters,
weights and
biases, and the initial parameter range is taken as [−50, 50]. The statistical results obtained after 30 independent runs are demonstrated in
Table A4.
In terms of all statistical parameters shown in
Table A4, the FNNHTVS training algorithm outperformed the other algorithms. In the WSR test, it outperformed all the compared algorithms. The WSR test results are presented in
Table 8.
4. Performance Evaluation in Fault Classification
Short circuit fault classification is one of the important issues that are studied in order to more accurately intervene in response to faults occurring in transmission lines. Furthermore, some fault location algorithms need to know the fault class. This situation increases the importance of fault classification. For fault classification, various classification properties are obtained at first. Then, using these features and different artificial intelligence techniques, fault types are classified.
In this section of our study, short-circuit faults occurring on a 735 kV, 60 Hz, 100 km transmission line was modeled as frequency-dependent with the help of Matlab/Simulink. Classification data were produced by introducing short circuit faults into the model, which is shown in
Figure 4. Classification was carried out with the FNNHTVS algorithm, the validity of which has been shown in the previous section. The performance of the FNNHTVS algorithm in fault classification was compared not only with the FNNVS, FNNPSO, FNNPSOGSA and FNNGSA algorithms, but also with other classifiers (SVM, KNN, FNN with LM and NB).
The selected classification features need to be specific and consistent for each fault type. In this study, post-fault one-cycle line currents and the zero sequence component of the line currents were taken as the input data. In each fault condition, the three-phase currents and the zero component were reduced by means of a certain method. In this reduction method, the highest peak value of the three phase currents was found in any fault, then each line current and zero component were divided by this peak value and the signals were scaled. The transmission line model studied here was a frequency-dependent model. Three-phase current signals and the zero sequence component for one cycle post-fault were sampled with a sampling frequency of 20 kHz and recorded. Measurements were made from the sending side of the transmission line. The root mean square (RMS) values of these recorded signals were calculated. The dataset was created using different fault resistance values, fault locations, fault types and fault inception angles. Single line to ground (SLG), line to line (LL), line to line to ground (LLG) and three-phase symmetric ground (LLLG) faults were generated in each phase.A random fault resistance value was chosen between 0.1 and 150 ohms. The fault inception angles (FIA) were determined as 0, 30, 45, 90 150 or 270. The fault location was chosen as 10, 20, 30, 50, 60, 80 or 90 km. A total of 250 data were created, 175 of which were training data and 75 were test data. The proposed algorithm and all other algorithms for comparison were run 30 different times. In each independent run, training and test samples were randomly selected from the created dataset.
Based on the formula
presented in [
26,
31],
was used.
is the input number. For the fault classification problem, an 4-9-4 FNN structure is used. This structure has a total of 85 parameters, 72 weights and 13 biases, and the parameter range is taken as [−50, 50]. The maximum iteration number was equal to 100 for all algorithms, which were evaluated based on the mean, standard deviation and best and worst MSE and accuracy values. The statistical results obtained after 30 independent runs are shown in
Table 9. When
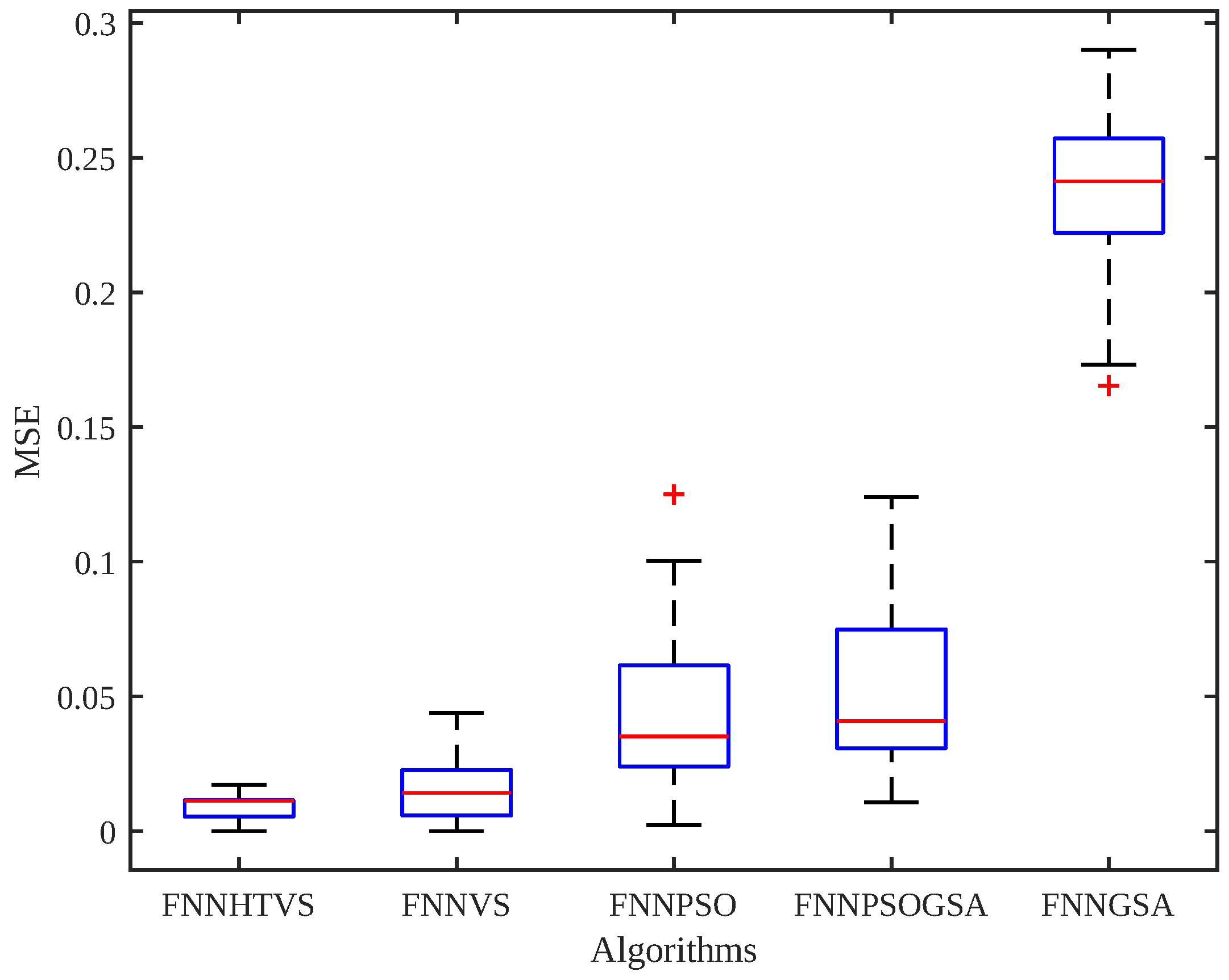
Table 9 is examined, it can be observed that the FNNHTVS algorithm had a lower mean MSE and higher mean classification accuracy, compared to the other methods. A box plot graph is shown in
Figure 5 and a convergence curve is depicted in
Figure 6. It can be observed that the FNNHTVS algorithm had a low standard deviation and reached a lower mean MSE value in fewer iterations. The convergence curve was obtained by taking the average of 30 different runs. The FNNHTVS algorithm was compared with the methods of SVM, KNN, FNN with LM and NB. When the results shown in
Table 10 are examined, it can be seen that the proposed algorithm exhibited a very competitive structure in relation to the other classifiers.
The accuracy values obtained in the fault classification studies may vary depending on the sample number, data type and the transmission line model studied. Therefore, it would be more accurate to compare the FNNHTVS algorithm with the classifiers and algorithms used in this study. The comparison of the FNNHTVS training algorithm with the studies related to fault classification in the literature could create a misleading impression due to the differences in the datasets studied. Considering this situation, some studies in the literature are presented in
Table 11, along with their important features. In [
40], the discrete wavelet (DW)-based SVM method was used. The average accuracy rate was approximately the same as for FNNHTVS. In [
41], fault classification and fault location tasks were undertaken using the multiclass SVM (MCSVM) method. In [
42], it was observed that the classification accuracy decreased as the fault resistance increased. In a study using the Poincare-based correlation (PbC) method, the authors stated that higher classification rates were obtained for fault resistances up to 100 and 120 ohms. Based on the results shown in
Table 11, we concluded that the FNNHTVS algorithm, with a mean accuracy rate of 99.1111%, obtained successful results that are compatible with those presented in the literature.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





