3.1. One-Dimensional Experiment
Although we are interested mainly in two-dimensional problems, as a prelude, a one-dimensional problem is illustrated and tested so that the reader can grasp the central idea and obtain a simple understanding of our approach.
In this experiment, the solution function is
where
. It satisfies the equations
in the domain
. Then,
, and the MN curves of Case 2 for interpolation apply if we choose
. The reason we adopt the inverse multiquadrics is that their programming is easier because the polynomial
in (2) disappears. For
, where
exists, the way of dealing with interpolation for
functions can be seen in Luh [
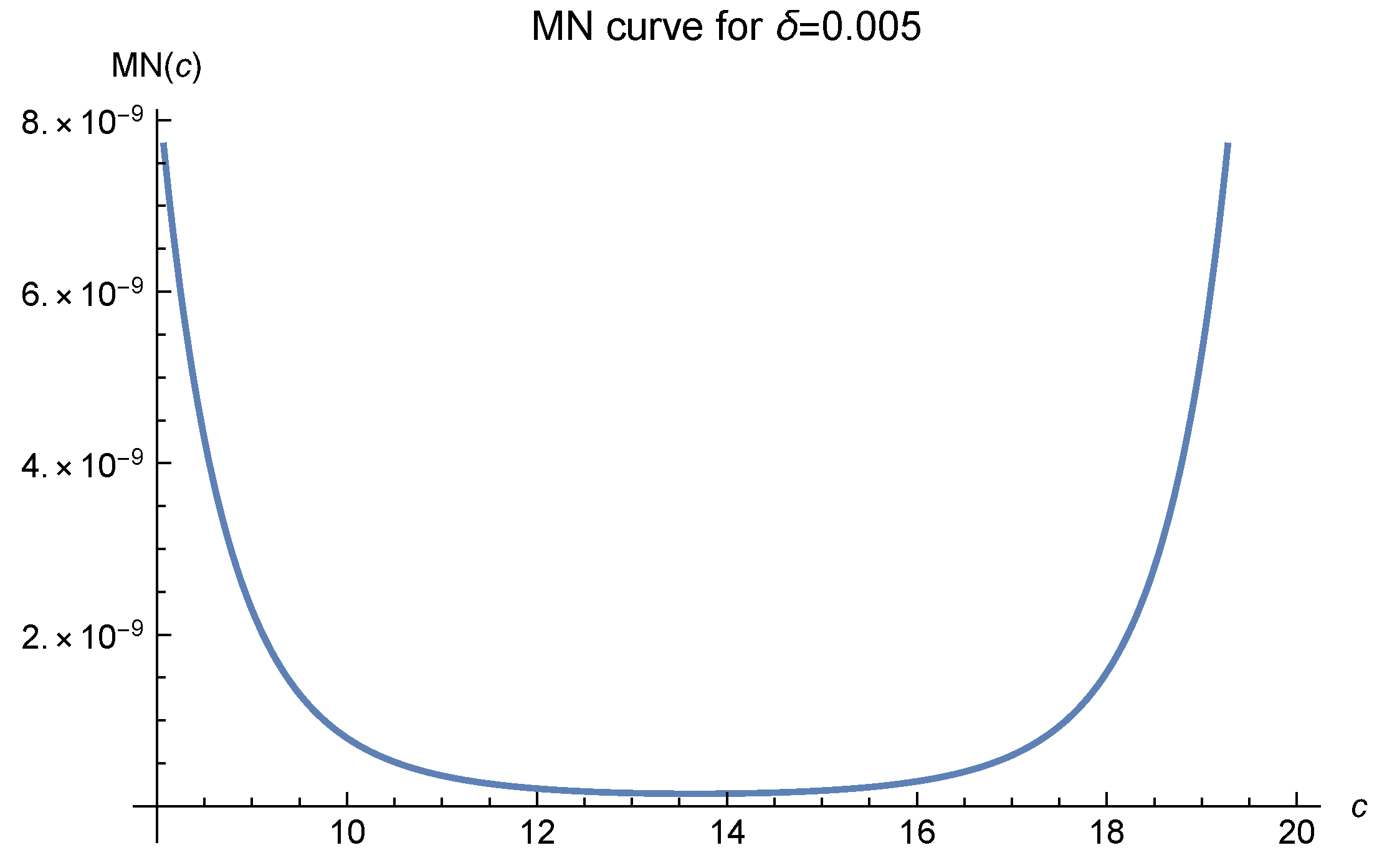
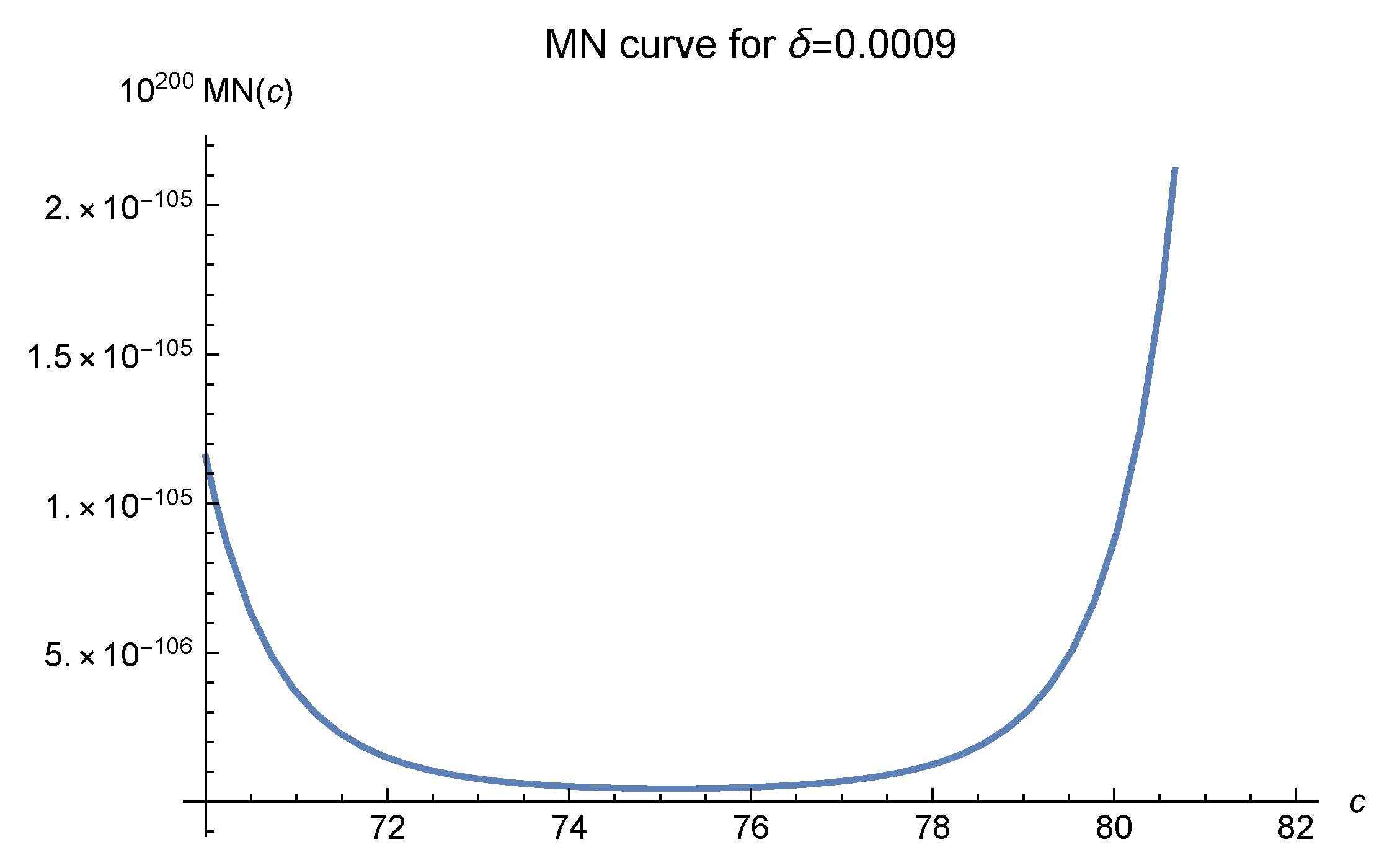
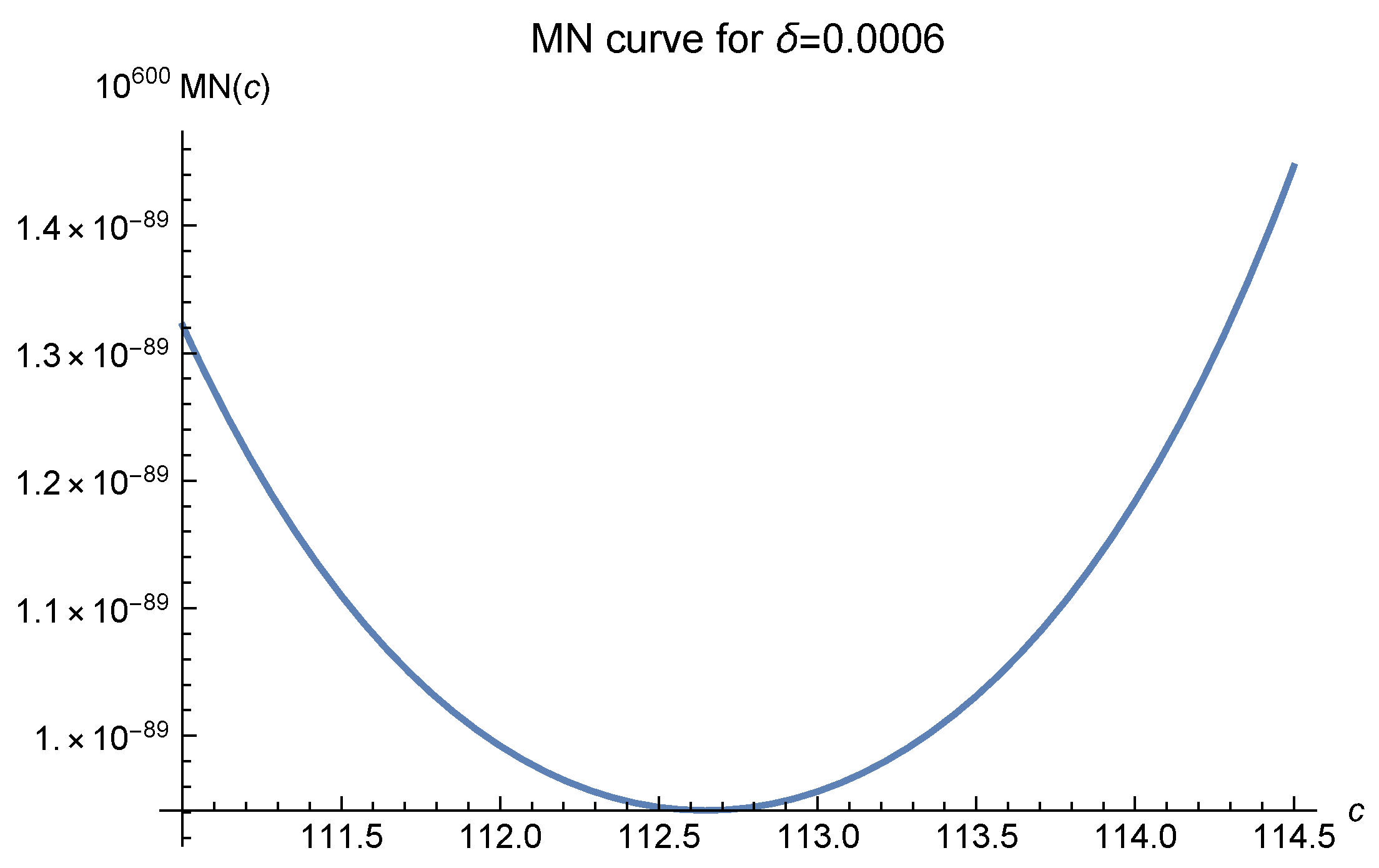
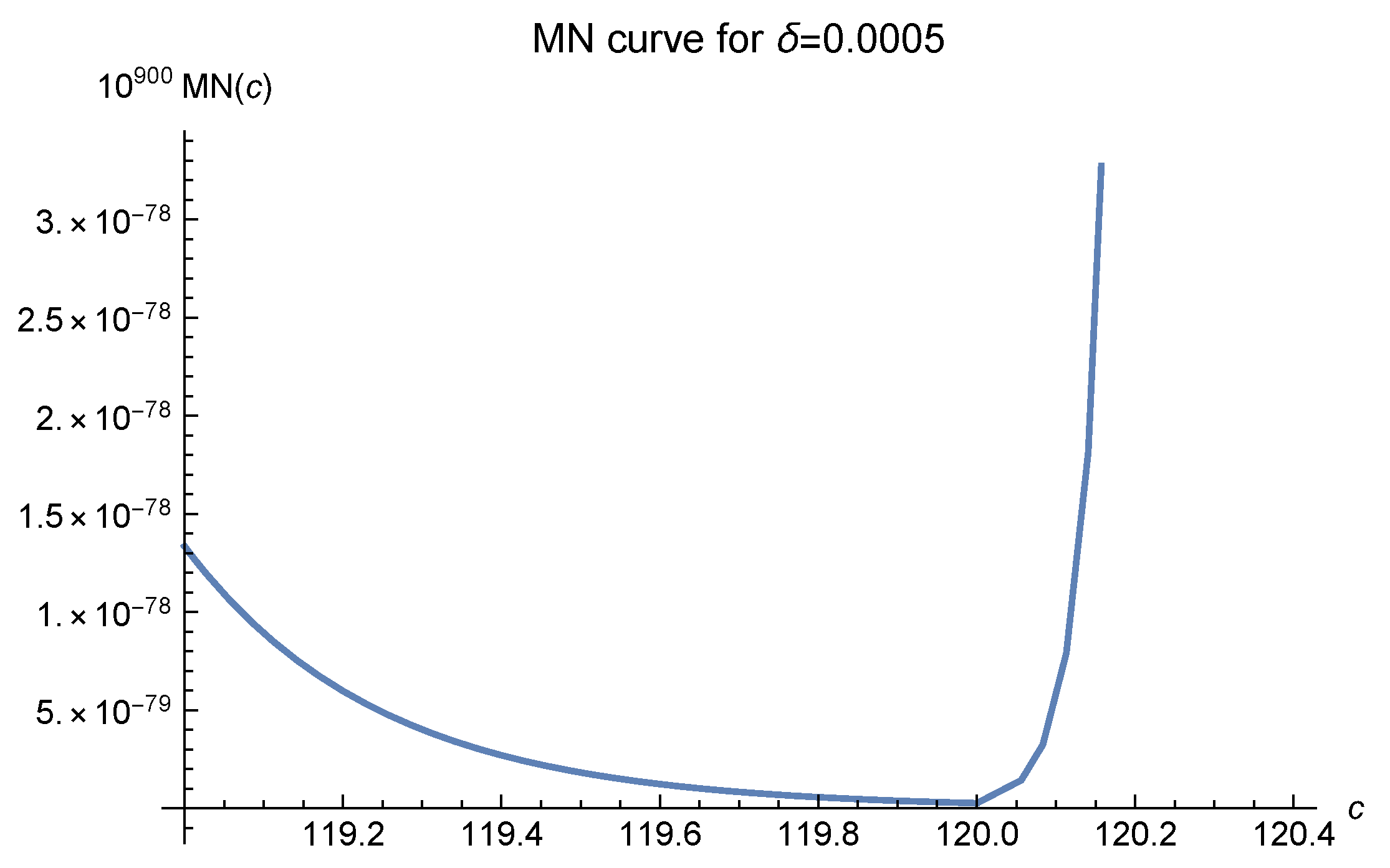
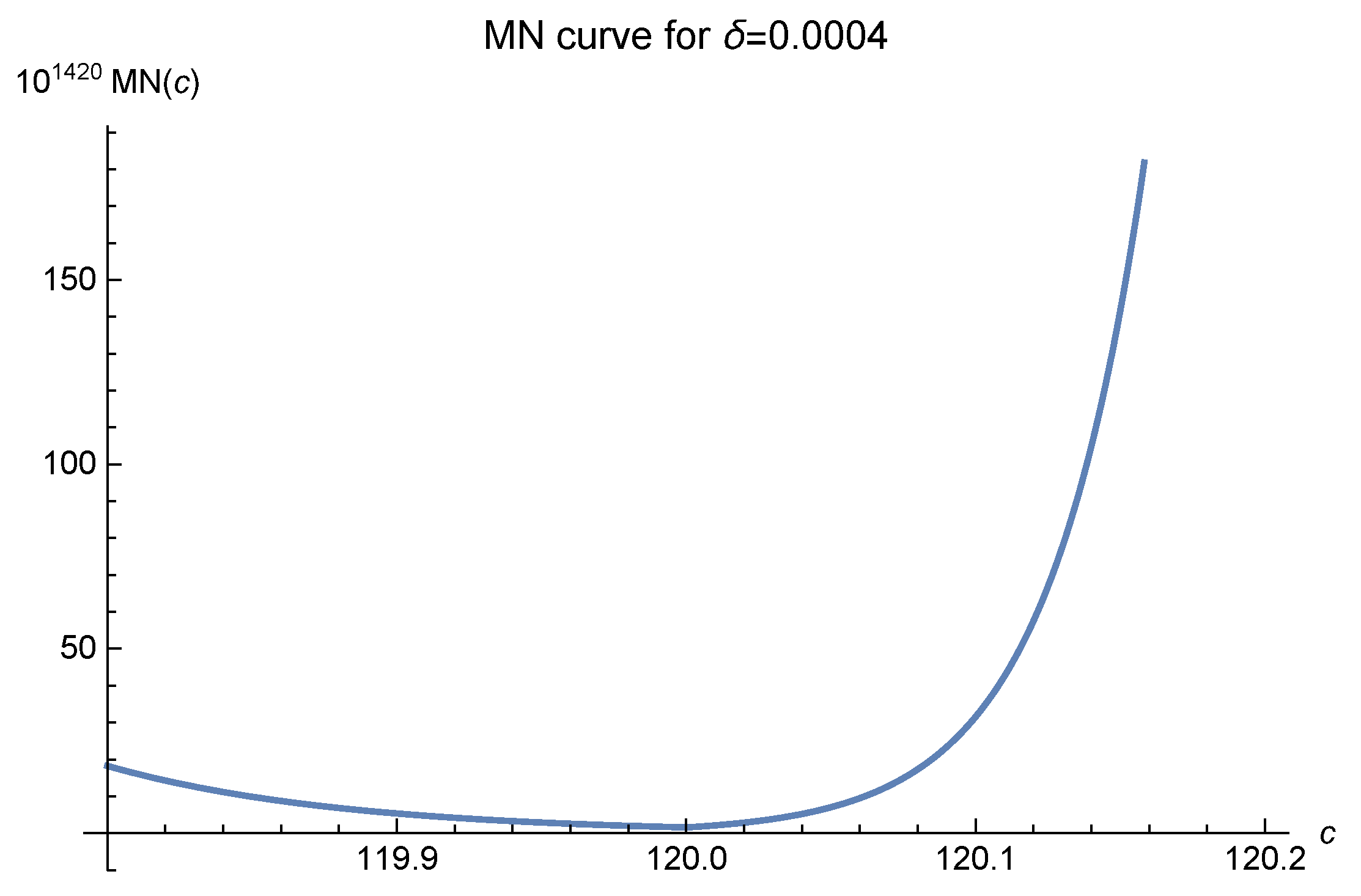
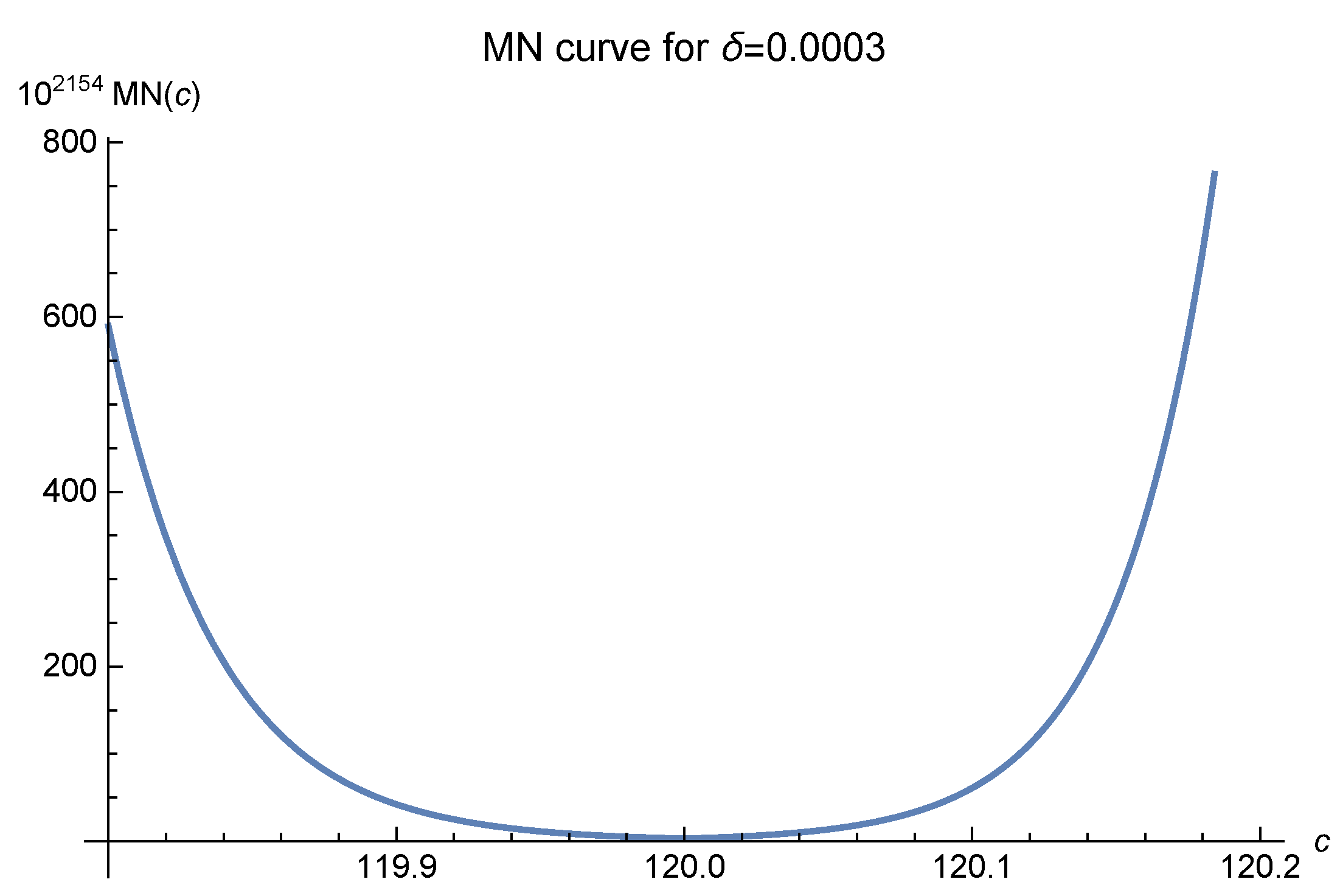
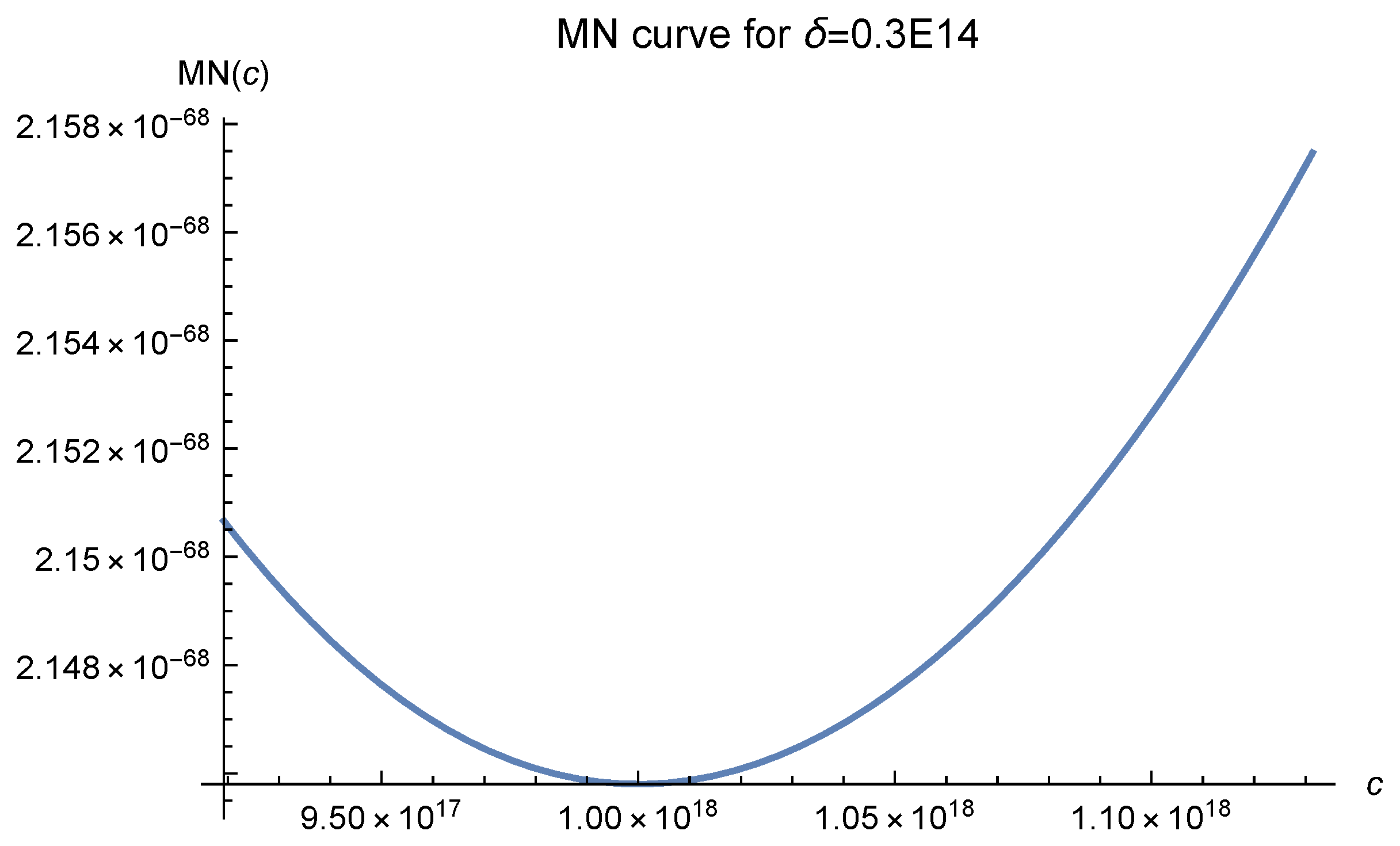
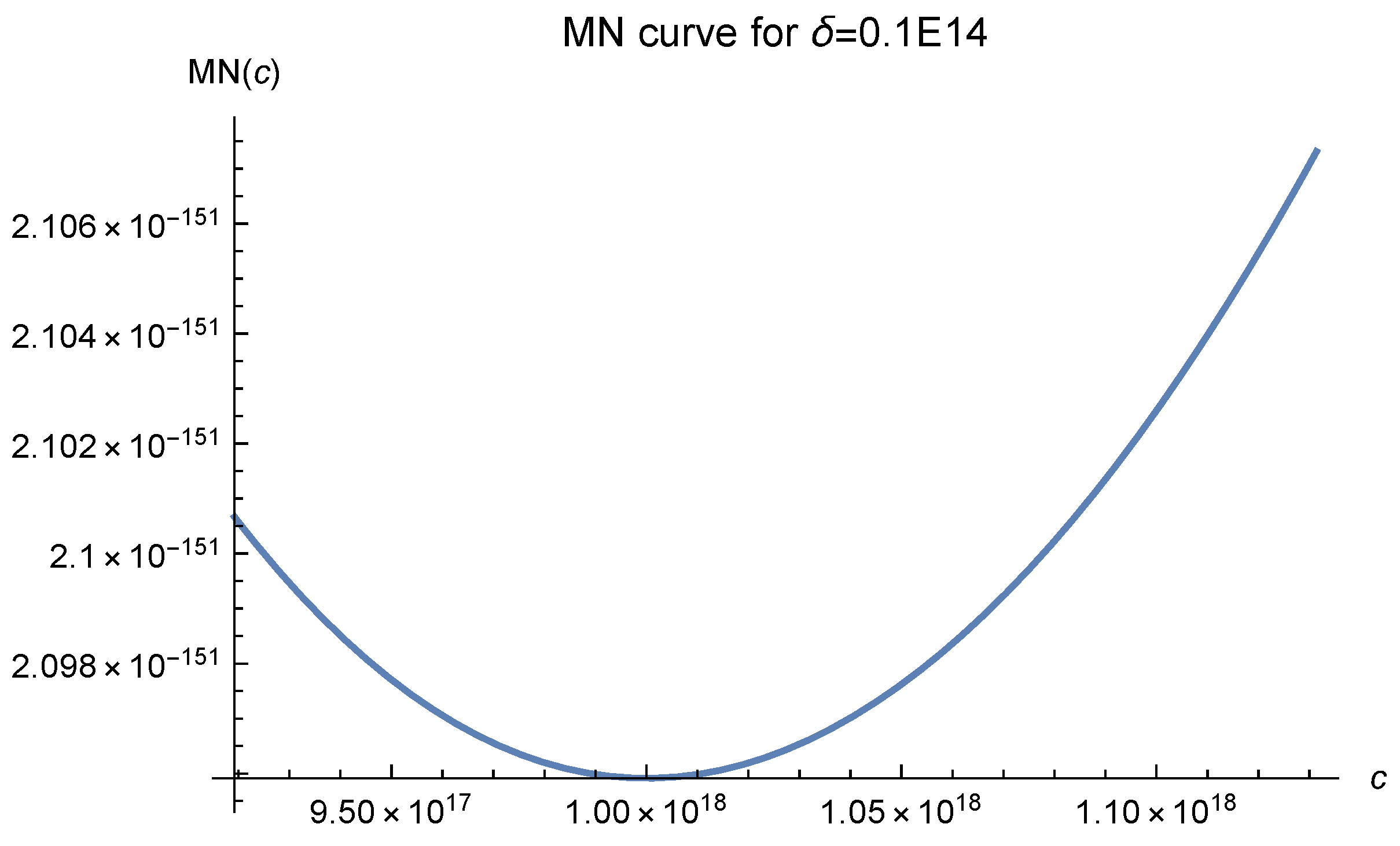
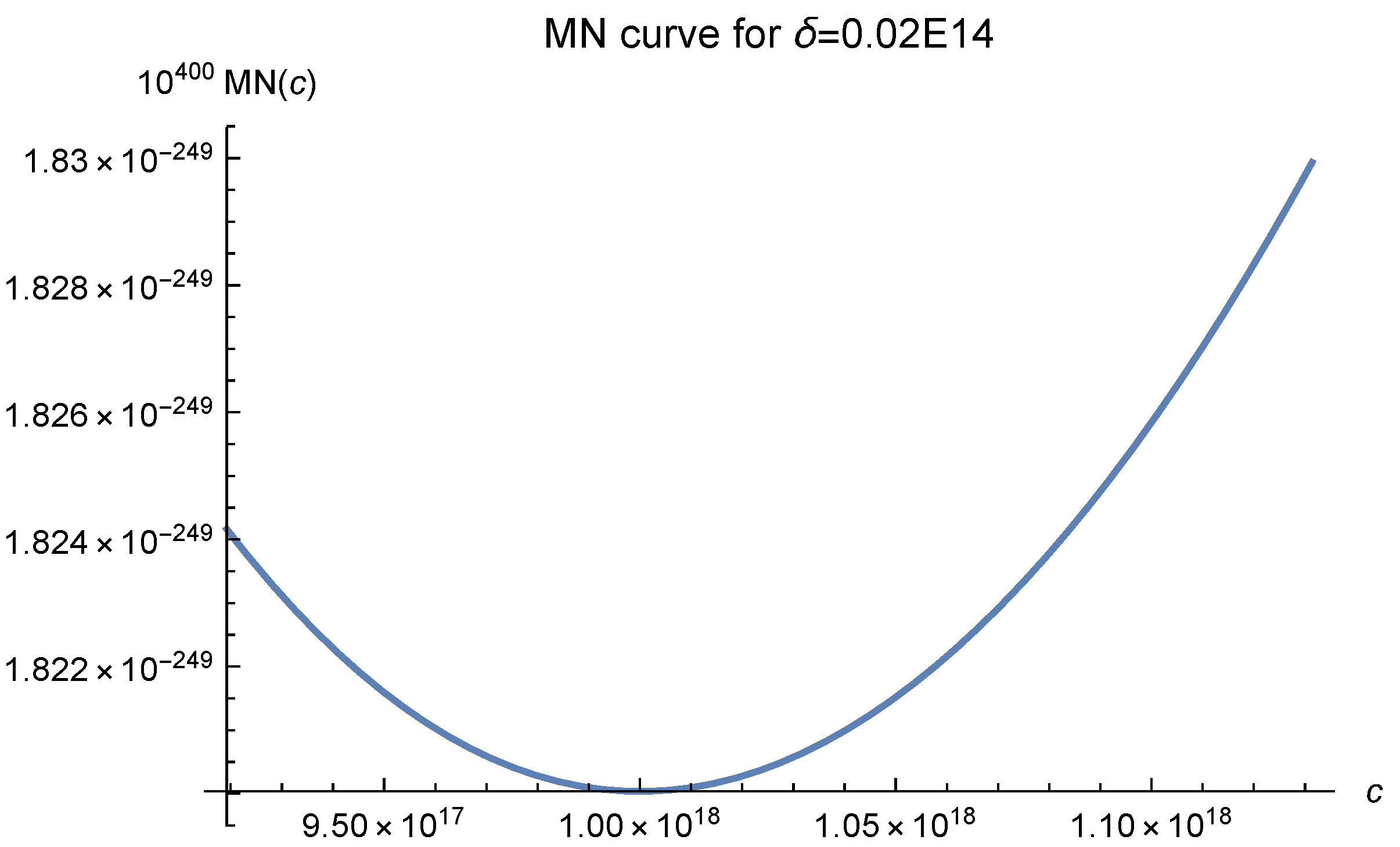
2]. We offer six MN curves in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6, which serve as the essential error bounds for the function interpolations. The number
, which greatly affects the MN curves, denotes the diameter of the interpolation domain. In these figures, it is easily seen that as the fill distance
decreases, i.e., the number of data points increases, the optimal values of
c move to 120 and are fixed there at last. The empirical results, as shown in Luh [
12], show that one should choose
to make the approximation.
Now, we let
where
, and require that
satisfies
and
where
and
for
.
This is a standard collocation setting. The function
is used to approximate the exact solution
of the differential equation. After solving the linear equations for
, we test
at 400 test points
evenly spaced in
and find its root-mean-square error (RMS)
The condition number of the linear system is . With the arbitrarily precise computer software Mathematica, we kept 800 effective digits to the right of the decimal point for each step of the calculation, successfully overcoming the problem of ill-conditioning. The computer time for solving the linear system is less than one second. We did not test smaller fill distances and different because the RMS is already satisfactory.
Note that, here, is in the same form as the interpolating function defined in (2) where because . Although the collocation points are not exactly the interpolation points, they are in spirit like the interpolation points. It is not surprising that is very small.
3.2. Two-Dimensional Experiment
Here, the solution function is
where
. The domain is a large square with vertices
, and
. The function
satisfies
for
in the interior of the domain
and
for
on the boundary
.
All these curves show that one should choose
as the shape parameter in
. We let
be the approximate solution of the Poisson equation satisfying (5) and (6), and require that it satisfy
for
where
belong to the interior of
, i.e.,
, and
denotes the number of data points used. Moreover,
for
where
belong to the boundary
.
A grid of
is adopted. Hence, there are 1681 data points
altogether. Among them, 160 are boundary points where the Dirichlet condition occurs. Thus, the fill distance is
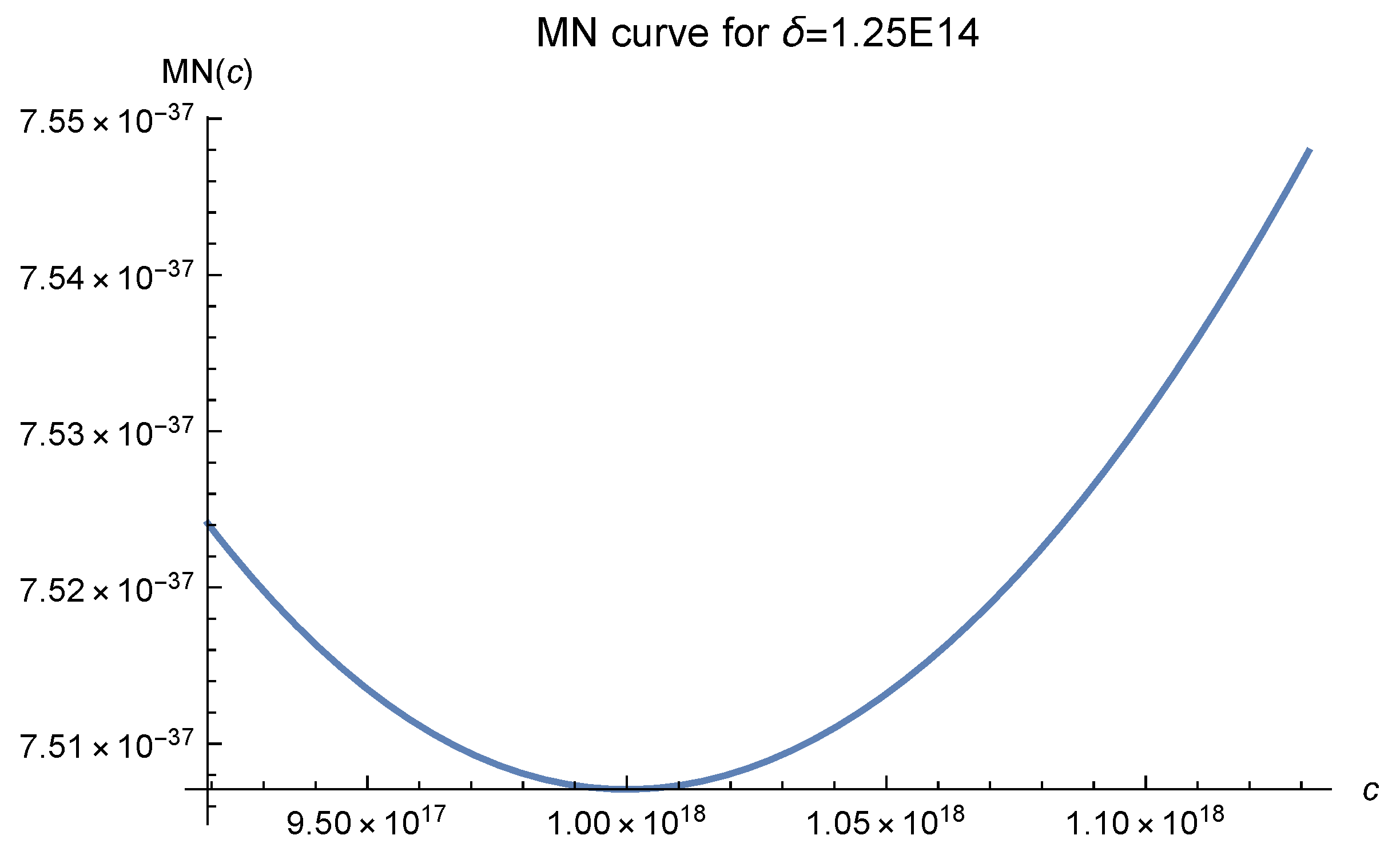
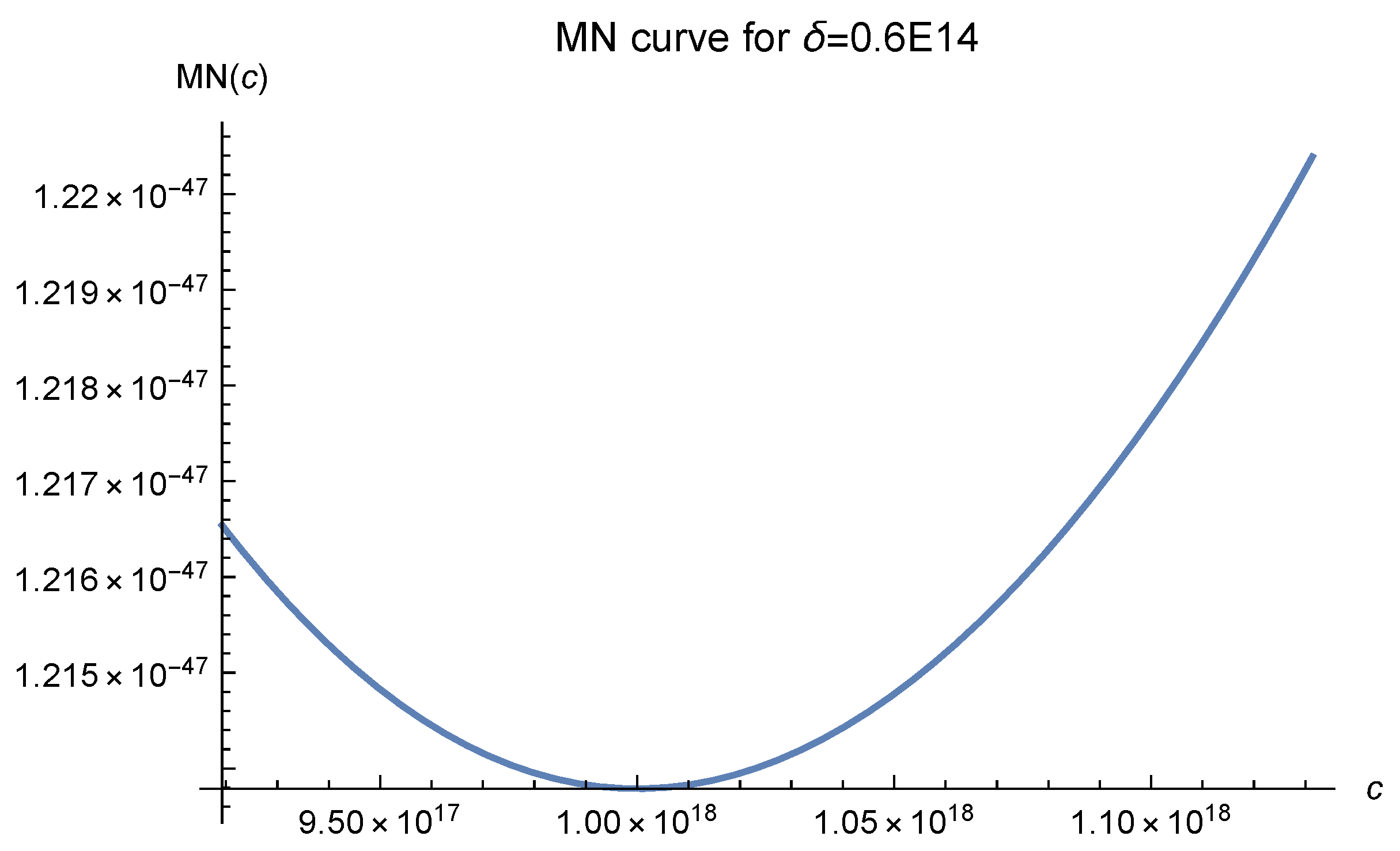
E14. The reason we choose such a delta is that it is close to the one in
Figure 7. When applying the MN curves, we consider all the 1681 data points to be the interpolation points, even though it is not theoretically rigorous. As explained in Luh [
12], it is supposed to work well. However, something important must be pointed out. Although MN curves can be used to predict almost exactly the optimal value of
c for function interpolation, a moderate search may be needed if this approach is used in a non-rigorous way. We begin with the theoretically predicted optimal value
and test two nearby values, one larger and the other smaller. Then, we check the RMS on the boundary for each
c and choose the direction which makes the RMS smaller. Continuing to choose
c in this direction, we stop when the RMS values begin to grow. Our experiment shows that not many steps are needed, and the finally obtained
c does produce the best result.
The experimental results are presented in
Table 1. Here,
and
denote the root-mean-square error, number of data points, number of test points, and condition number of the linear system, respectively. The optimal value of
c is marked with the symbol *. We use
to denote the root-mean-square error of the approximation on the boundary, generated by 800 test points located on the boundary. In the entire domain
, 6400 test points were used to generate the
s. The most time-consuming command of solving the system of linear equations took about 30 min for each
c. Although we adopted 1200 effective digits for each step of the calculation, it still worked with an acceptable time efficiency.
Note that the optimal value of
c is
which coincides with the value chosen by our stopping criterion based on
. This optimal value was obtained without much effort. The most time-consuming step is solving a linear system for each trial of the
c value whenever the condition number is very large. Fortunately, it took only 30 min in our experiment. Obviously, we could have obtained better RMS values by increasing the number of data points, whereas we did not do so because the approximation was already quite good. Moreover, it can be seen that the theoretical value
is not the same as the experimental value. The main reason is that we relaxed two strict requirements in Luh [
1,
2], as explained in the paragraph preceding Definition 2.2. Another important reason is that, according to the strict theory in [
1,
2], the MN functions are defined only for function interpolation, not for the collocation method of solving PDEs.
In this paper, all the calculations were not performed by double precision. Instead, they were made by the arbitrarily precise computer software Mathematica. In the MN-curve approach, the condition number of the linear system may be very large. If double precision is adopted, the final results may be meaningless. For example, in
Table 1, when
, the condition number is
. One has to adopt at least 750 effective digits to the right of the decimal point for each step of the calculation. In order to increase the reader’s confidence, we adopted 1200 digits at the cost of spending more time. Hence, our calculations should be reliable. This is about the stability. As for the convergence, in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11, it can be clearly seen that as the fill distance
decreases, the value of MN(c), which denotes the essential error bound of the approximation, decreases rapidly. It fully reflects a salient characteristic of the RBF approach. In our experiments, we did not test different fill distances because our primary concern is finding a good
c value, not the convergence rate.
Seemingly, it is a limitation of our approach that one has to adopt Mathematica rather than the widely used Matlab. In fact, it probably can be considered to be a limitation of the entire RBF approach. In Madych [
7], an incomplete experiment was presented. Meaningless results appear in that experiment whenever the condition number is greater than
. What Madych used was Matlab and a double-precision scheme. In the paper, Madych said that he did not know how to overcome this trouble. By virtue of Mathematica, we can now handle it successfully. The severe ill-conditioning of the RBF approach seems to be an inherent problem which we have to face.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}