
Data Analysis and Domain Knowledge for Strategic Competencies Using Business Intelligence and Analytics



Abstract
:1. Introduction
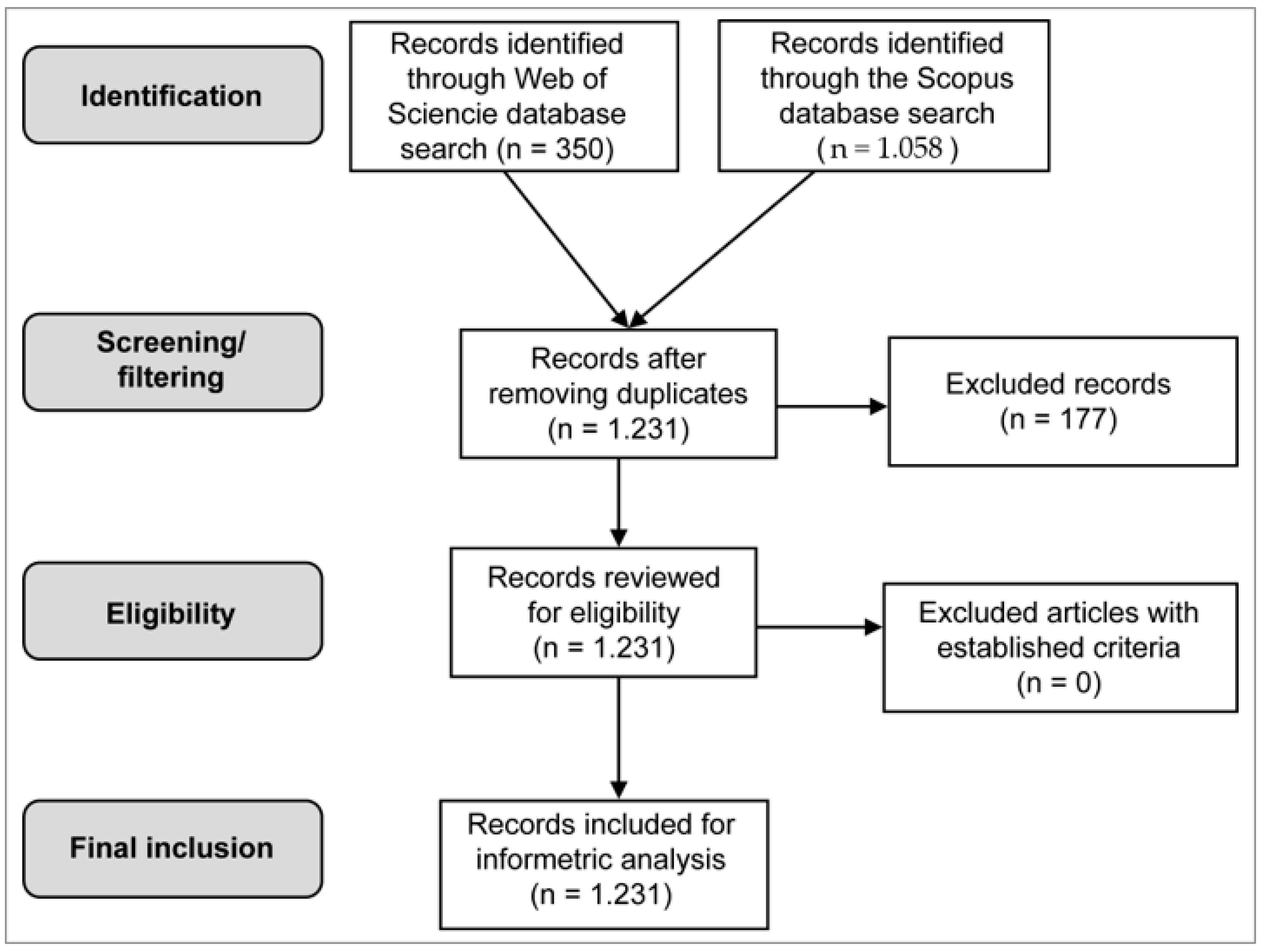
2. Literature Review and Previous Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Base | Informetric | IA | Validation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Years | WoS | GS | Scopus | N° Articles | Bibliometric | Scientometrics | PLN | Lematization | Clustering | AP | I +IA | ||
| Data intelligence and analytics: A bibliometric analysis of human–Artificial intelligence in public sector decision-making effectiveness | Di Vaio, A. (2022) [25] | 2007–2021 | x | x | 161 | x | |||||||
| Understanding the structure, characteristics, and future of collective intelligence using local and global bibliometric analyses | Calof, J. (2022) [41] | 1964–2004 | x | x | 3.138 | x | |||||||
| Business Intelligence in Balanced Scorecard:Bibliometric analysis | Żółtowski, D. (2022) [42] | * | x | x | >10.000 | x | |||||||
| Detection of emerging technologies and their evolution through deep learning and weak-signal analysis | Ebadi, A. (2022) [40] | 1985–2020 | x | 590 | x | x | |||||||
| Big data analytics and machine learning: A retrospective overview and bibliometric analysis | Zhang, JZ. (2021) [43] | 2006–2020 | x | 2.160 | x | ||||||||
| Influential and determinant models in big data analytics research: a bibliometric analysis | Aboelmaged, M. (2020) [44] | 2013–2019 | x | x | 229 | x | |||||||
| * Various periods of years | |||||||||||||
| Data Base | Informetric | IA | Validation | ||||||||||
| Years | WoS | GS | Scopus | N° Articles | Bibliometric | Scientometrics | PLN | Lematization | Clustering | AP | I +IA | ||
| Data Analysis and Domain Knowledge for Strategic Compe-tencies Using Business Intelligence and Analytics | 1999–2021 | x | x | x | x | x | x | x | x | x | |||
| Supervised Algorithms | Sources | NON-Supervised Algorithms | Sources |
|---|---|---|---|
| Decision Tree | Mahesh, B. (2020) [45] | Principal Component Analysis (PCA) | Mahesh, B. (2020) [45] |
| Navie Bayes | Ullah, I. (2022) [46] | Probabilistic latent semantic indexing (PLSI) | Suominen, A. (2016) [47] |
| Support Vector Machine | Chen, L. (2022) [48] | Latent Semantic Indexing (LSI) | Farkhod, A. (2021) [49] |
| Linear regression | Mayilvahanan, KS. (2022) [50] | Latent Dirichlet approach (LDA) | Tseng, SC. (2022) [51] |
| Logistic Regression | Tiwari, S. (2022) [52] | K-Means Clustering | Montavon, G. (2022) [53] |
| Main Evaluation Metrics (Supervised Learning) | Main Evaluation Metrics (NON-Supervised Learning) | ||
| Decision Tree | Predictive accuracy rate; Accuracy rate: Sensitivity and specificity; Number of leaves; Number of decision variables; The confusion matrix | Principal Component Analysis (PCA) | Scaling of variables; Proportion of variance explained; Optimal number of principal components |
| Navie Bayes | Retention method | Probabilistic latent semantic indexing (PLSI) | Conditional probability distribution |
| Support Vector Machine | F1-Score;Precision;Recall Breakeven Point (PRBEP) | Latent Semantic Indexing (LSI) | Correlation of semantic terms |
| Linear regression | The confusion matrix; Recall, F1-Score;Area under the curve (AUC) | Latent Dirichlet approach (LDA) | Perplexity; Coherence |
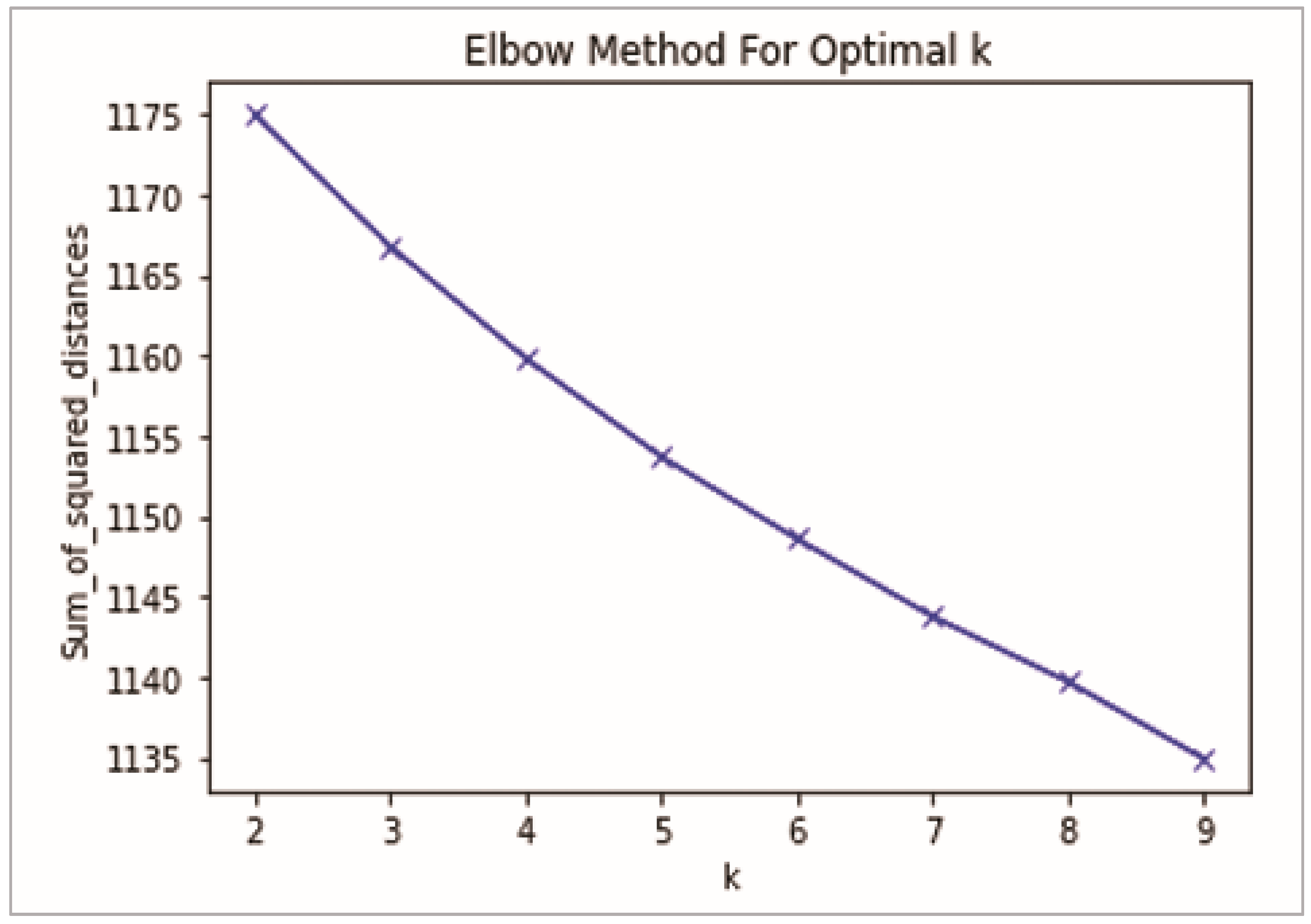
| Logistic Regression | ROC curve; AUCPR;R-squared; root mean squared error (RMSE);Mean average precision (MAP) | K-Means Clustering | Elbow method |
Comparison and Selection of Models
3. Description of the Problem
4. Methodology
4.1. Hypotheses
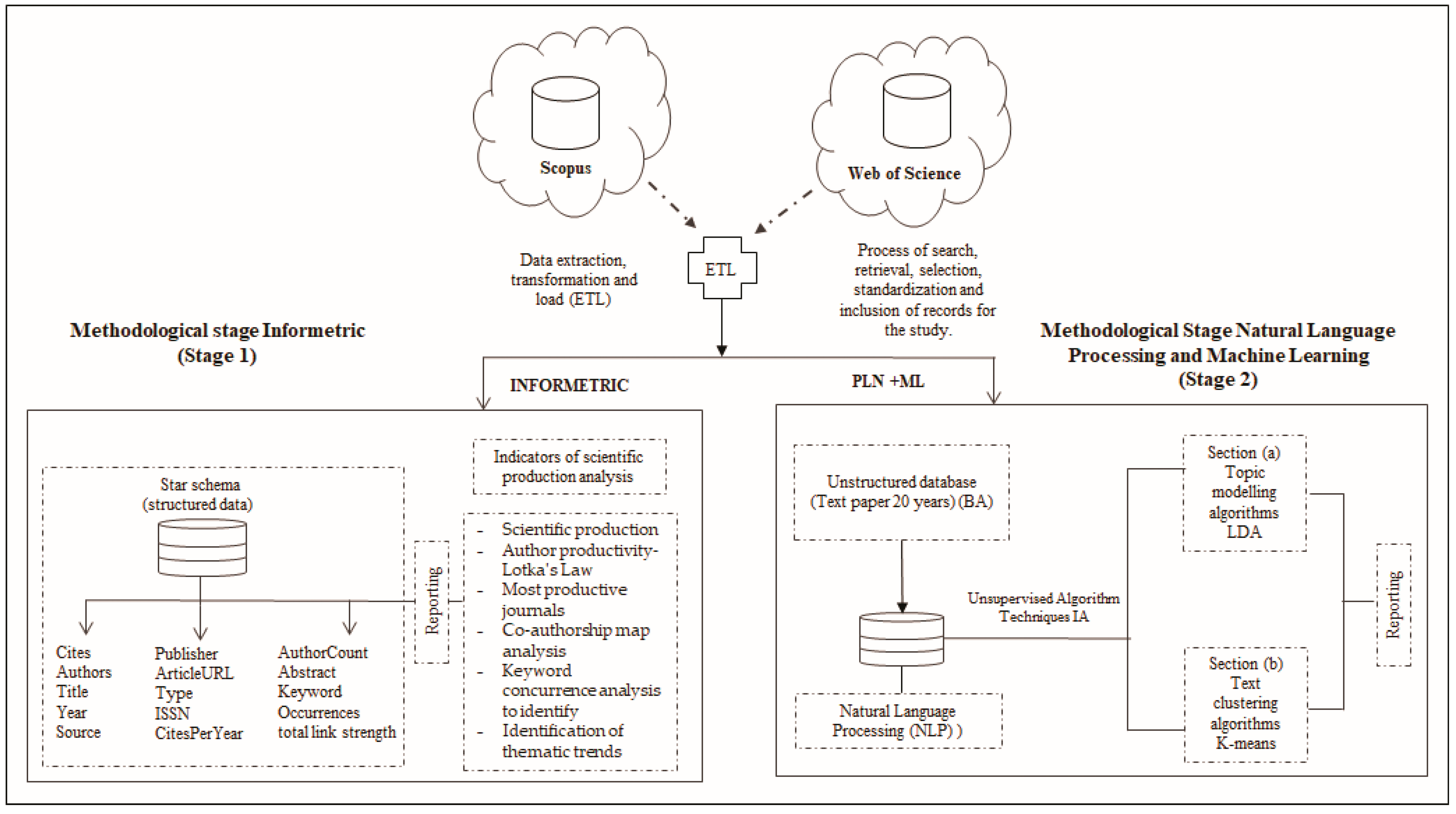
4.2. Methodological Steps
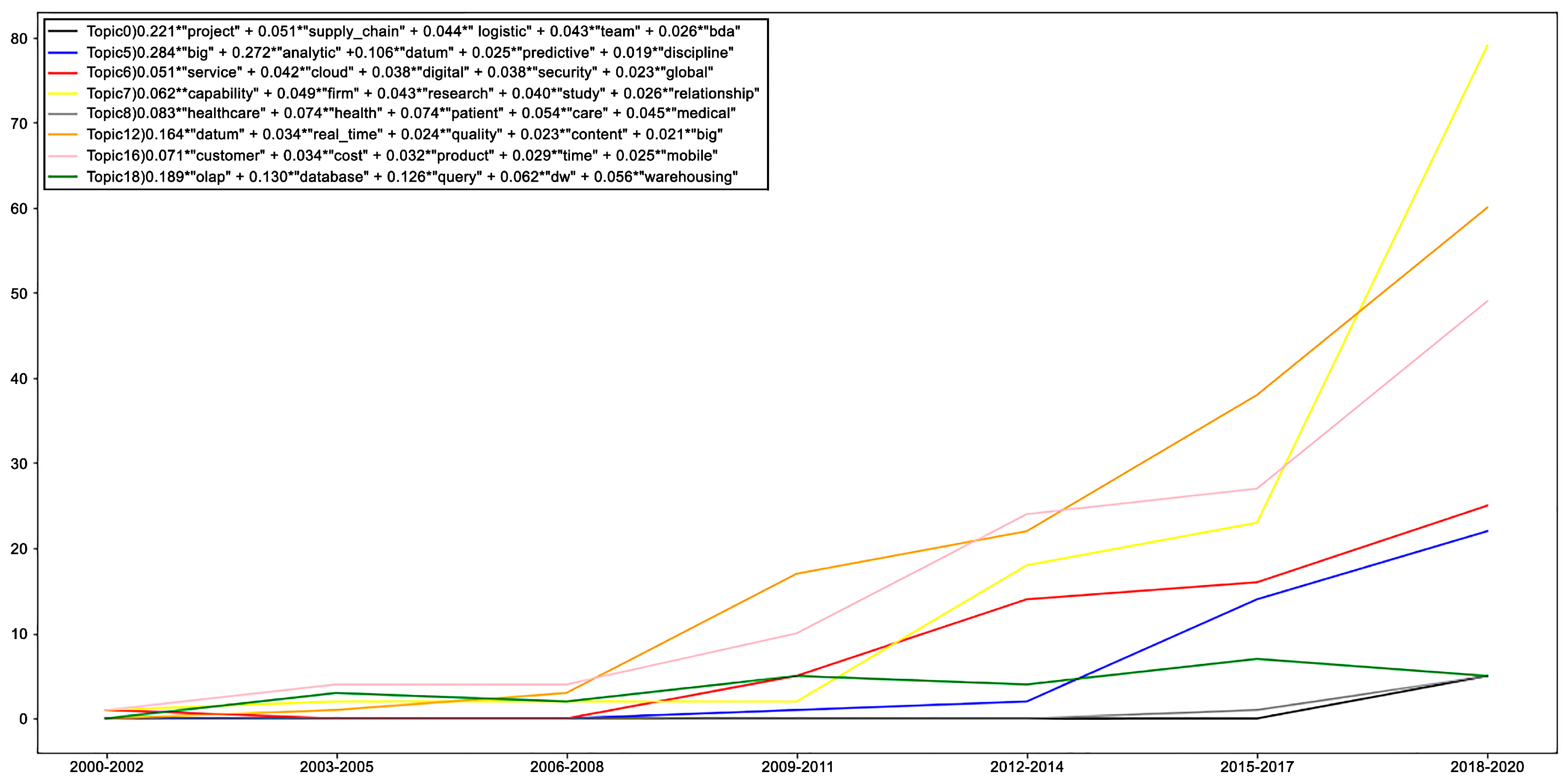
- Topic-modelling algorithms have proven to be successful in the area of aspect-based opinion mining to extract “latent” topics, which are aspects of interest. A technique called latent Dirichlet allocation (LDA) is used, which is based on a generative probabilistic model in which each document consists of a combination of several topics, where terms or words can be assigned to a specific topic. Latent LDA is a good-topic-modeling algorithm compared to latent semantic analysis and the hierarchical Dirichlet process for the aspect extraction process in aspect-based opinion mining [60]. The results of this technique were used to analyze the most relevant topics of the scientific production regarding strategic leadership competencies in BI&A and their relationships with the competence domains.
- The second unsupervised machine learning algorithm was applied to a grouping of texts in order to analyze the main clusters resulting from the 1231 articles considered. The aim was to analyze the results of the k-means model trained to predict the type of cluster belonging to each article related to each of these and to analyze the resulting pattern of the most relevant scientific production with respect to the emphasis on the dimension of strategic leadership competencies in BI&A and its relationship with the competence domains.
Application of the Informetrics Methodology (Stage 1)
4.3. Natural Language Processing and Machine Learning—Stage 2
4.3.1. Natural Language Processing (NLP) Techniques
- (1)
- Analysis
- (2)
- Tokenization
- (3)
- Construction of bigram and trigram models
- (4)
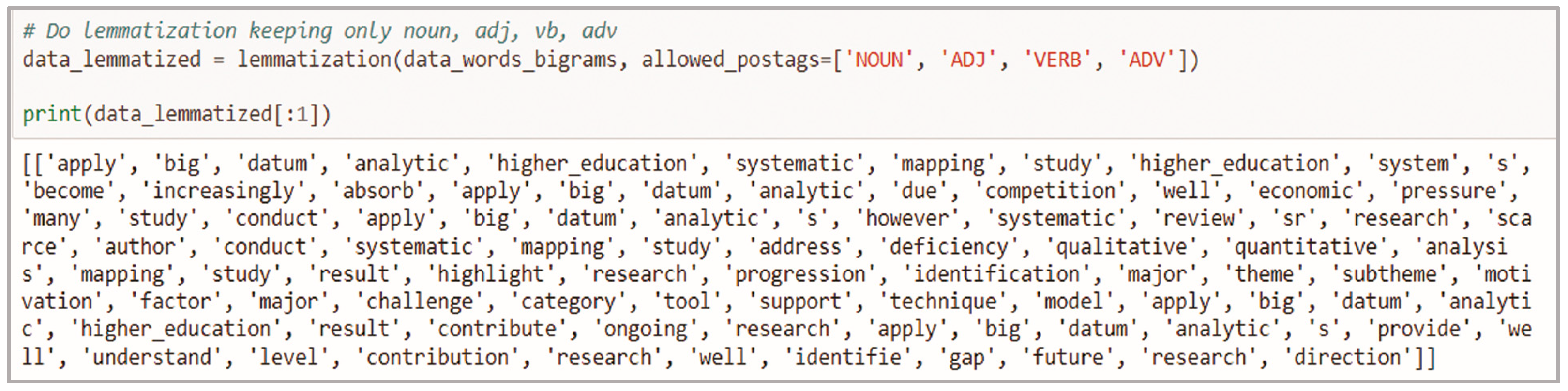
- Applying natural language processing
- (a)
- Elimination of empty words:
- (b)
- Lemmatization:
- (c)
- POS tagging:
4.3.2. Application of the Natural Language Processing and Machine Learning (Stage 2)
4.3.3. Section (a) Topic Modelling Algorithms: LDA Model
- (1)
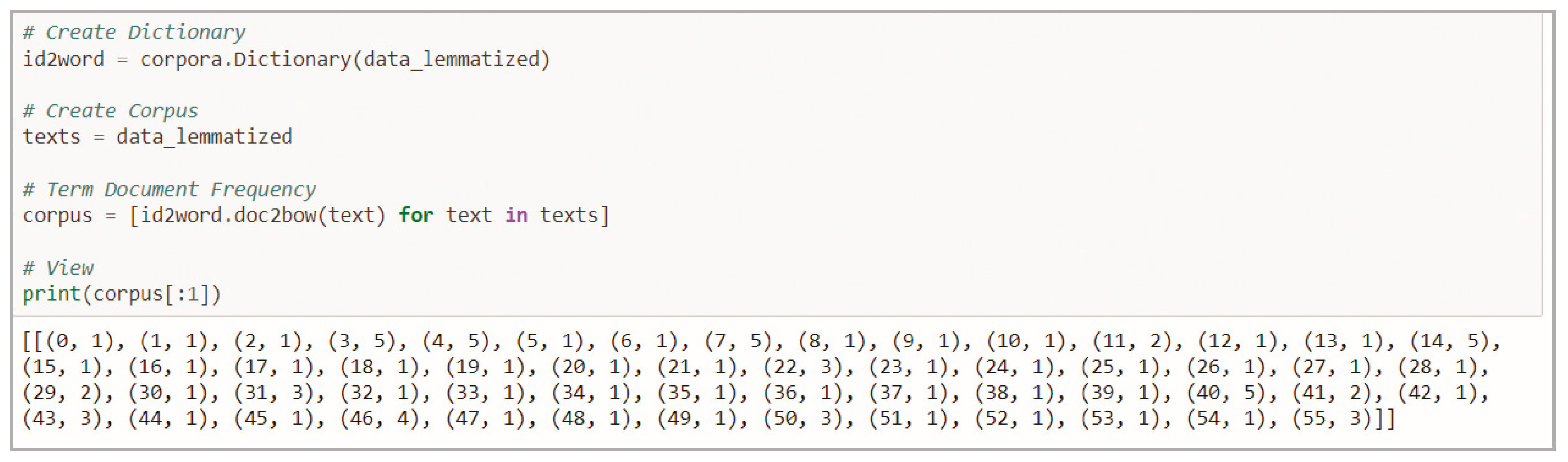
- Dictionary word assignment
- (2)
- Construction of BOW representations
4.3.4. Development of a Research Model, see code 3 in Figure 5


4.3.5. Section (b) Text Clustering Algorithms
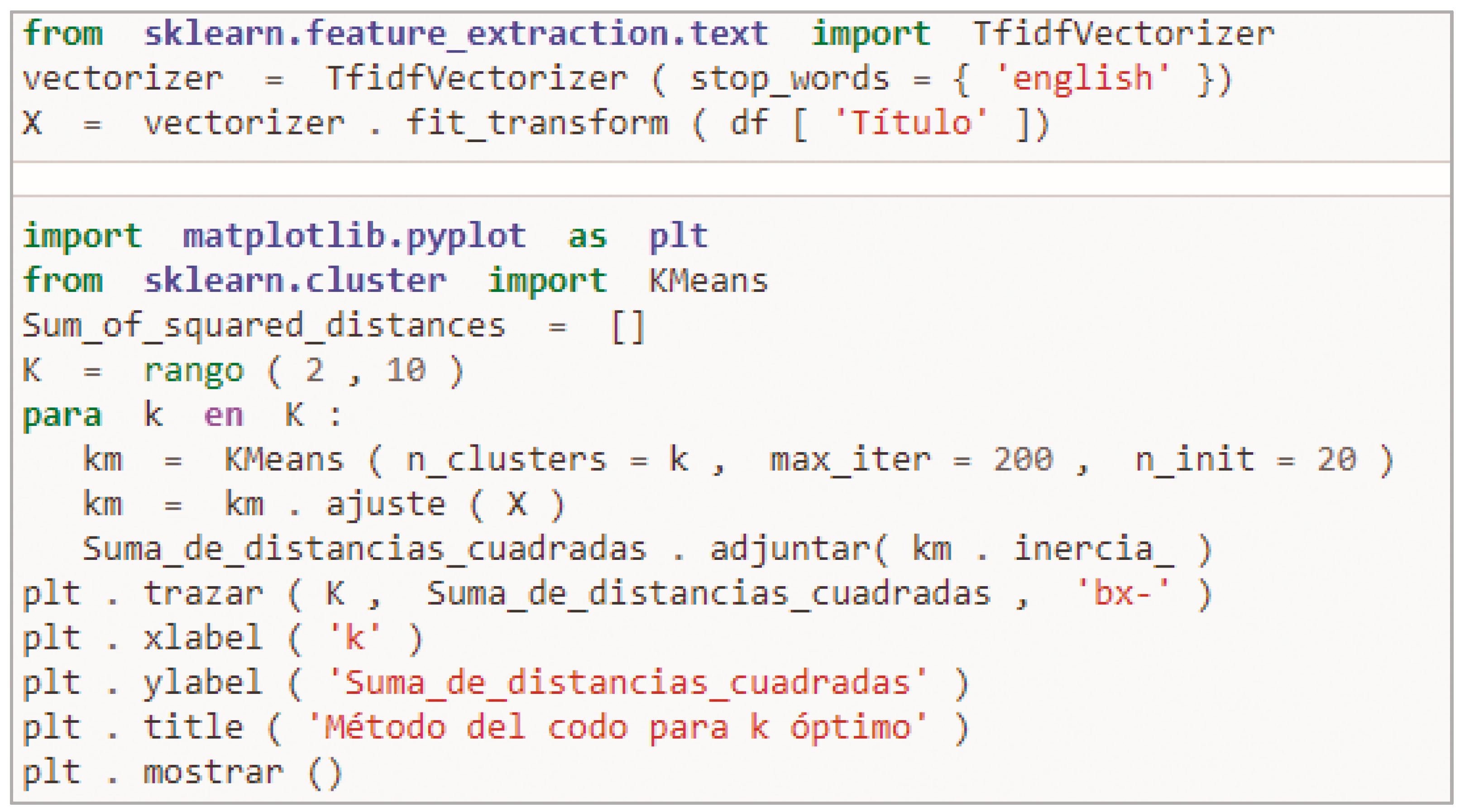
- TF-IDF Vectorization:
- 2.
- Applying K-Means:
- 3.
- Elbow method for optimal k
- Performing k-means clustering with all these different values of k.
- Plotting these points and finding the point where the mean distance to the centroid drops sharply (“elbow”), see Figure 10.
5. Results
5.1. Results of Stage 1
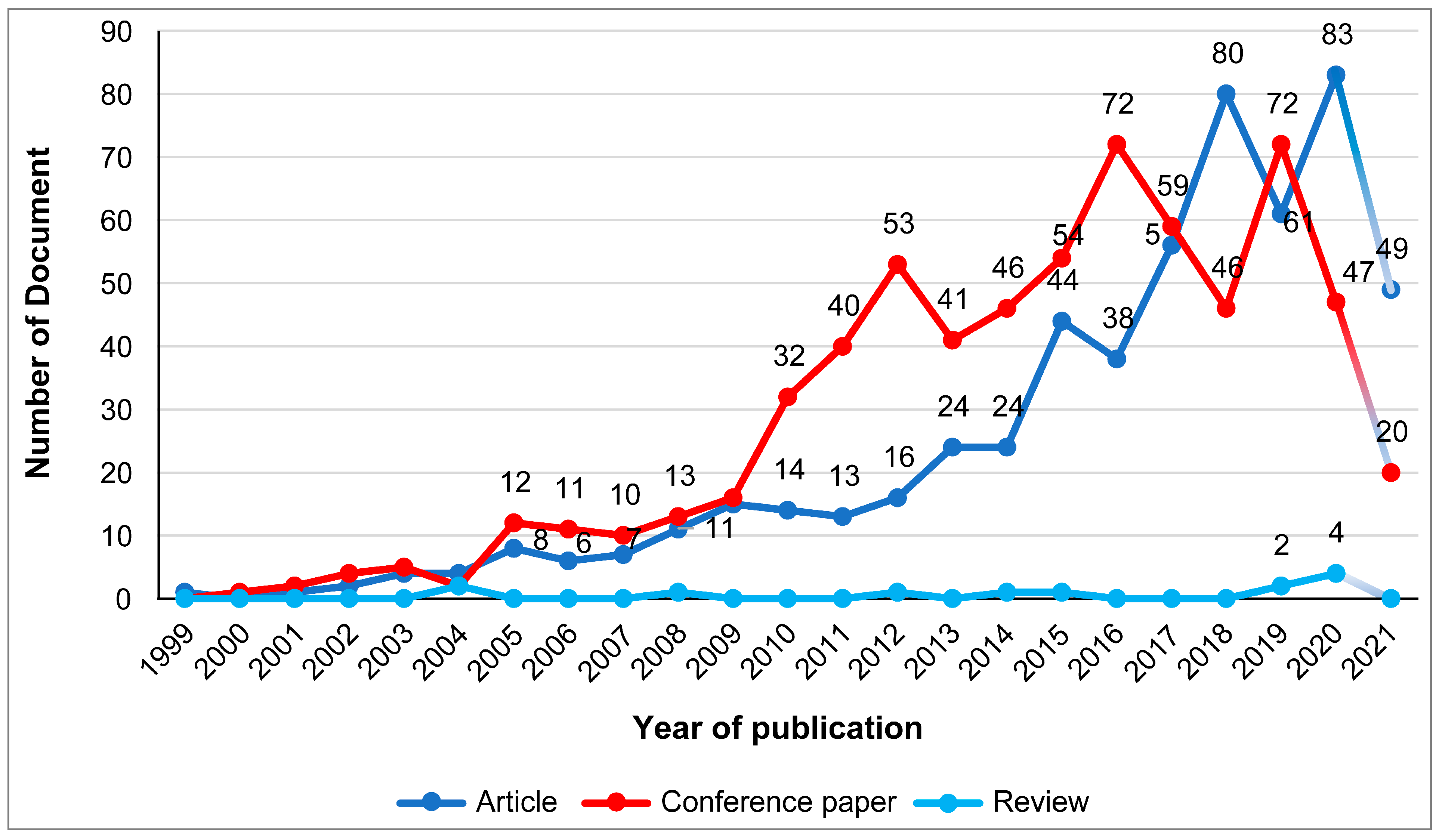
5.1.1. Scientific Production According to Documentary Typology
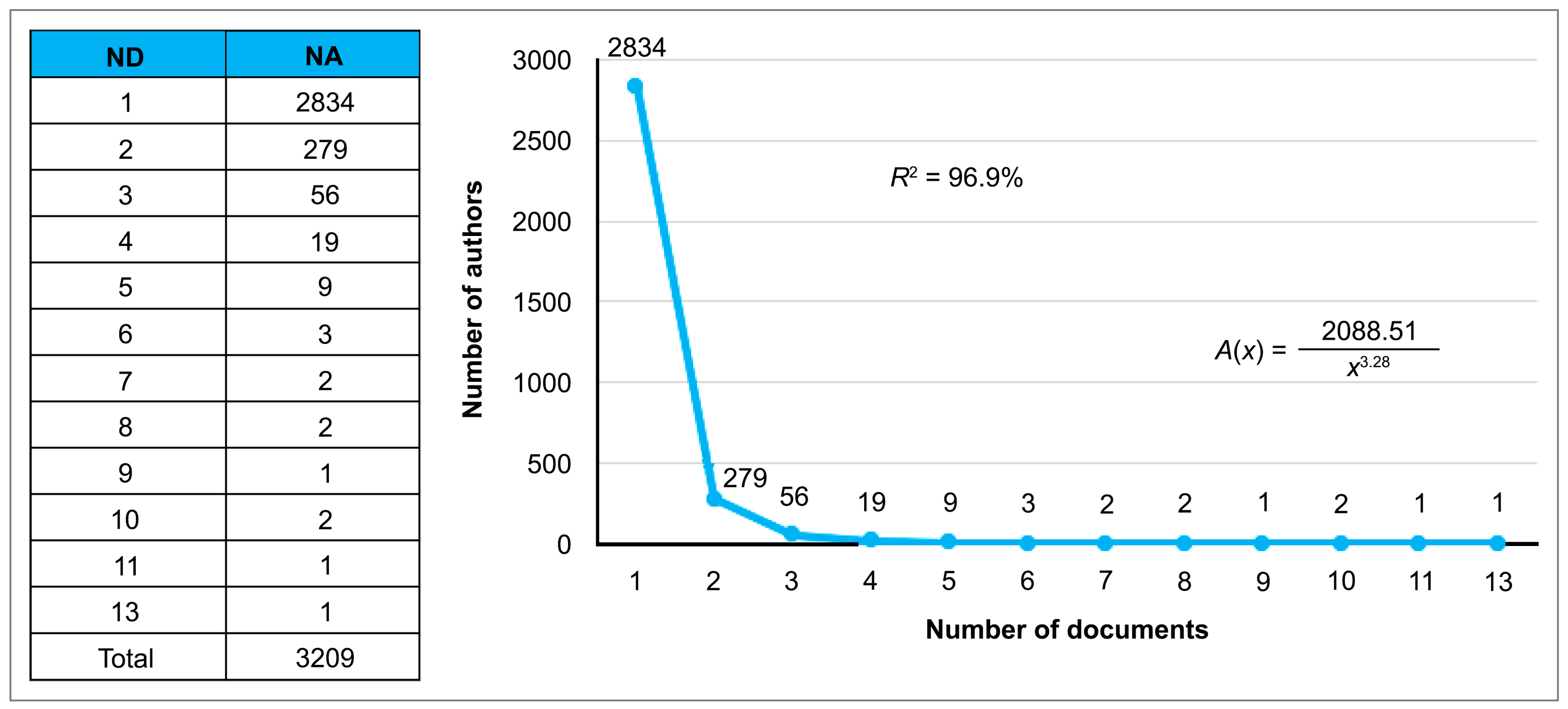
5.1.2. Most Productive Authors
5.1.3. Journals with the Highest Scientific Output
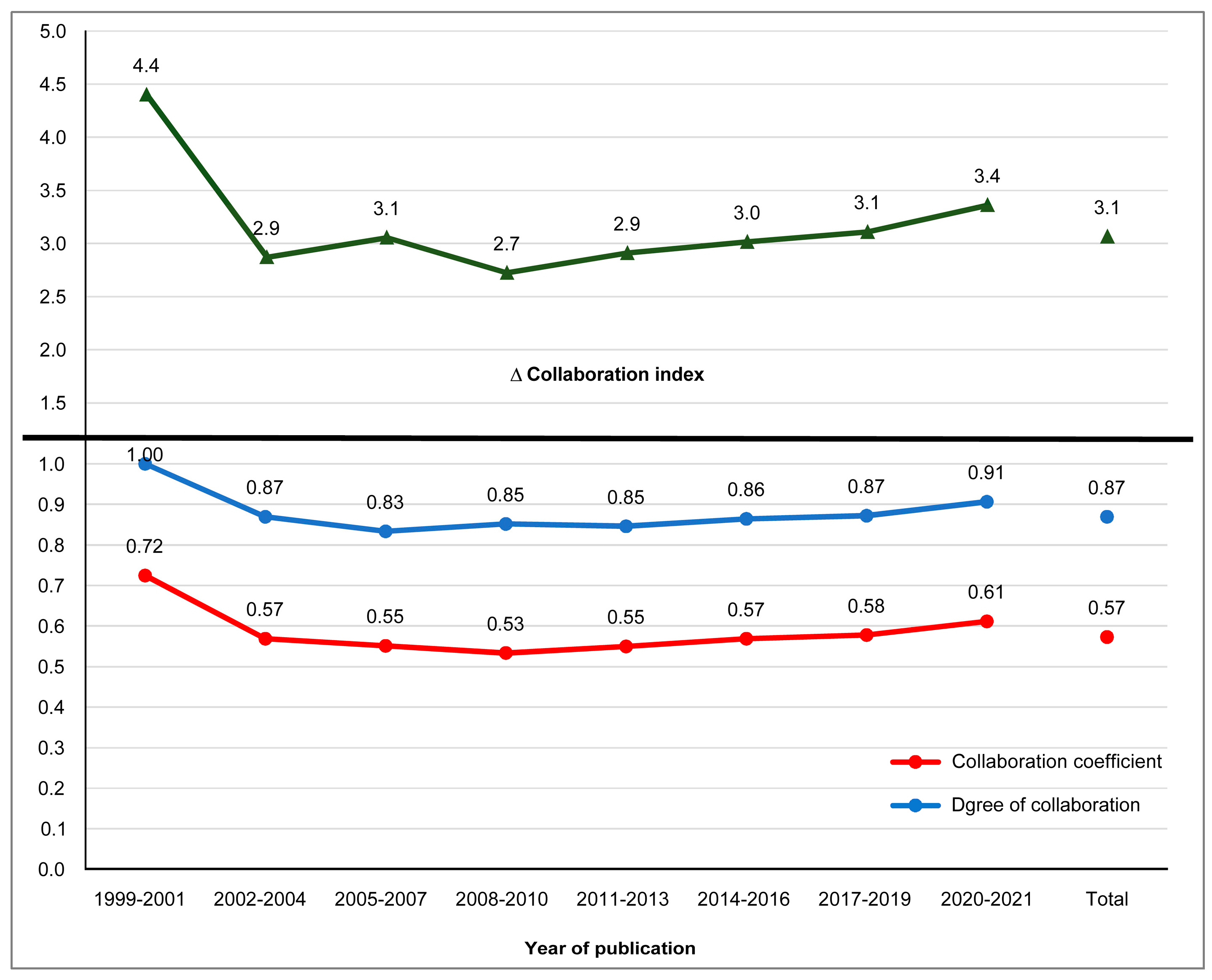
5.1.4. Indicators of Collaboration
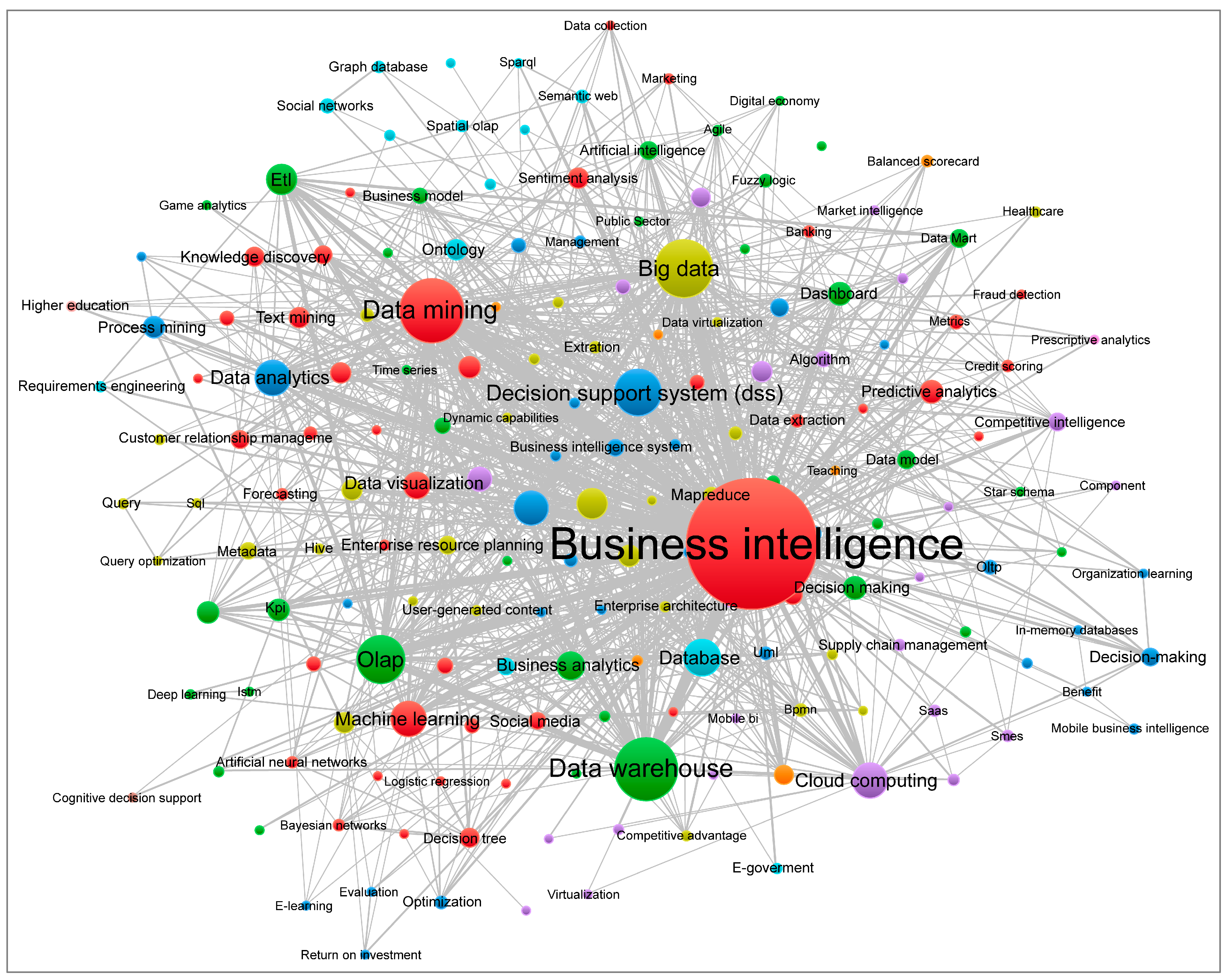
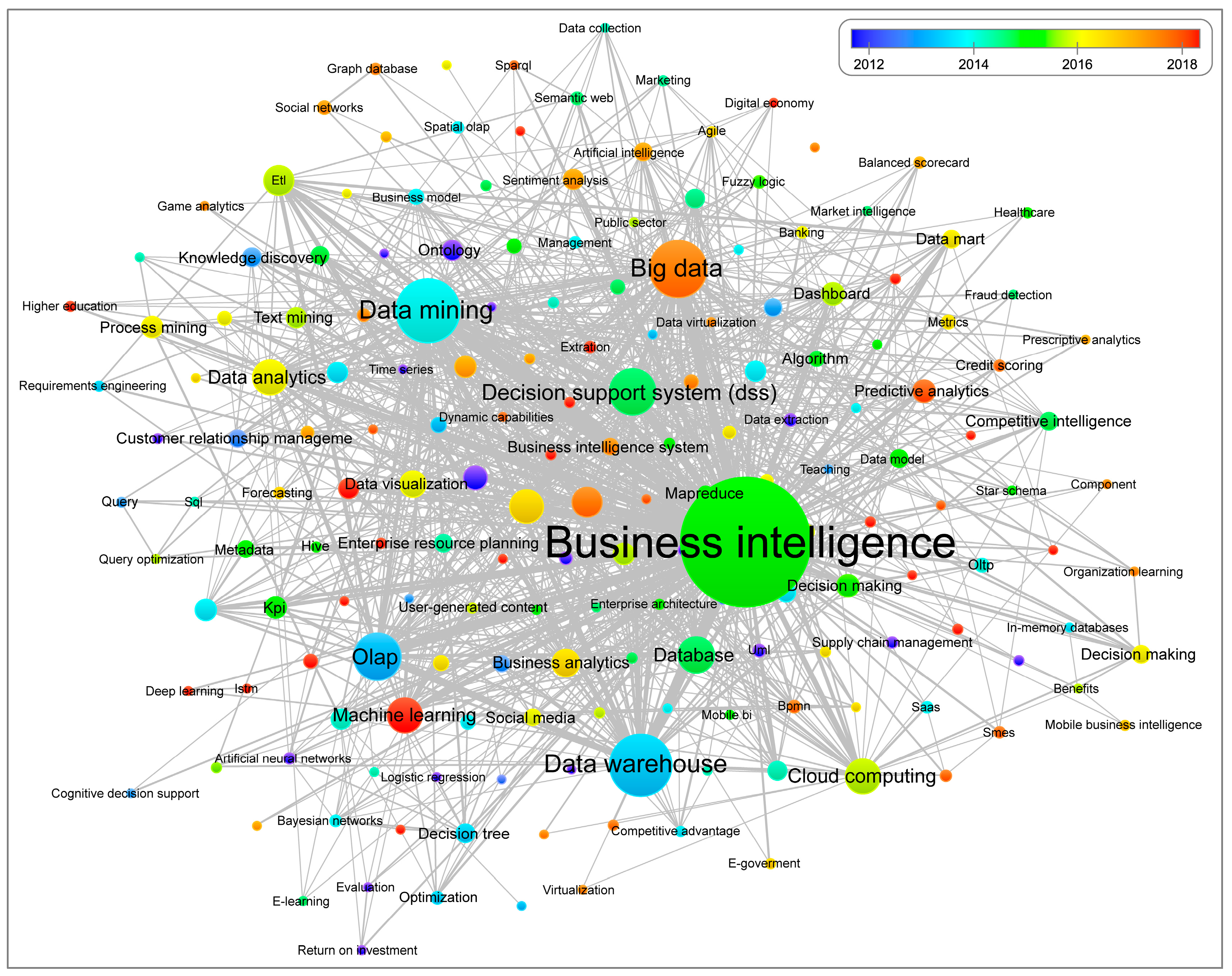
5.1.5. Visualization of the Network and Keyword Overlay
5.2. Results of Stage 2
5.2.1. Recognition of Main Study Topics in Scientific Production from 1999 to 2021: LDA Model
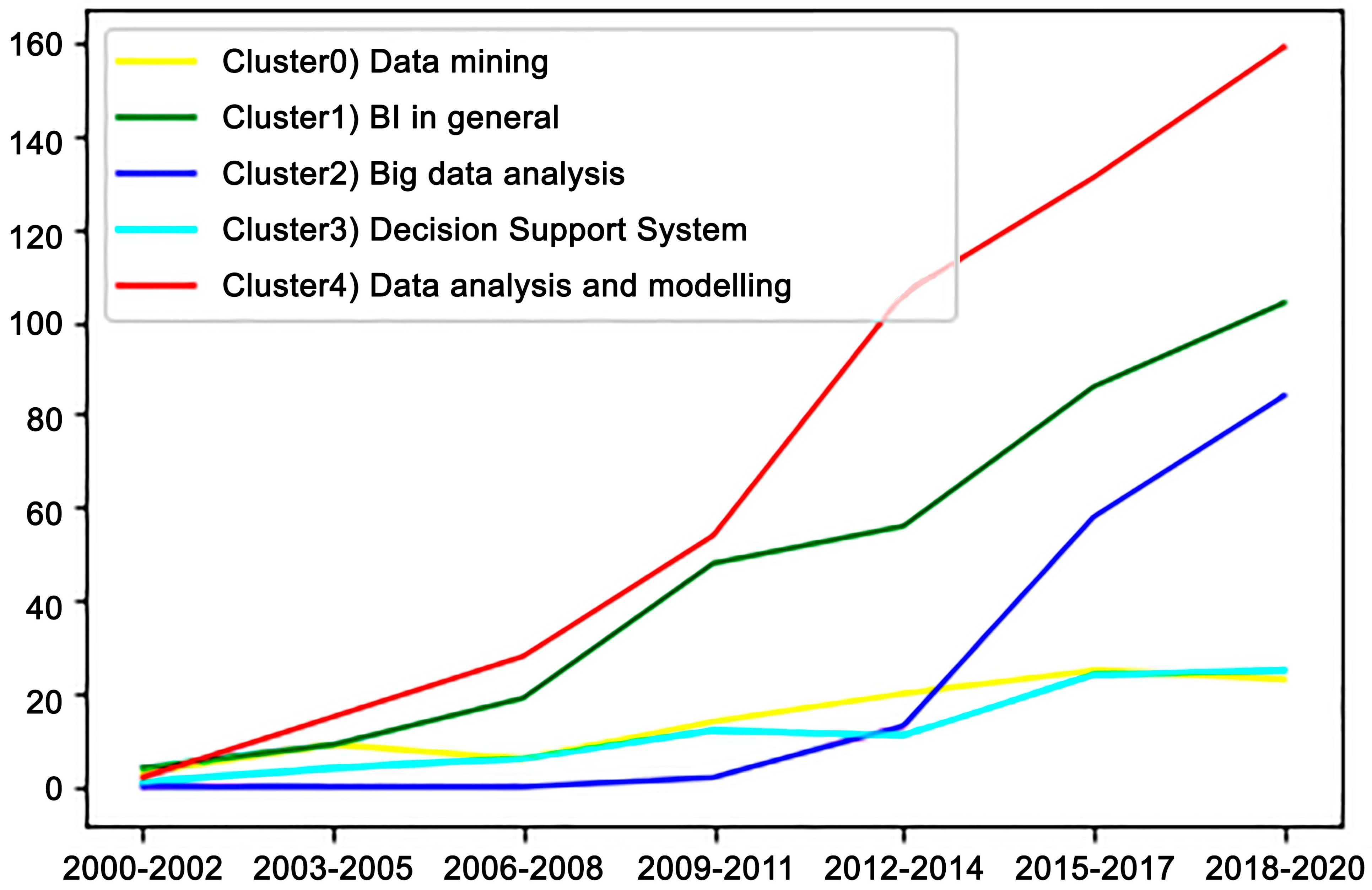
5.2.2. Main Clusters of Scientific Production, Articles from 1999 to 2021: Text Clustering
6. Discussion
7. Conclusions
8. Limitations and Suggestions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Côrte-Real, N.; Ruivo, P.; Oliveira, T. The diffusion stages of business intelligence & analytics (BI&A): A systematic mapping study. Procedia Technol. 2014, 16, 172–179. [Google Scholar] [CrossRef] [Green Version]
- Wixom, B.; Watson, H. The BI-based organization. Int. J. Bus. Intell. Res. 2010, 1, 13–28. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.L.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165. [Google Scholar] [CrossRef]
- Olszak, C.M. Toward better understanding and use of business intelligence in organizations. Inf. Syst. Manag. 2016, 33, 105–123. [Google Scholar] [CrossRef]
- Davenport, T.H. From analytics to artificial intelligence. J. Bus. Anal. 2018, 1, 73–80. [Google Scholar] [CrossRef] [Green Version]
- Burgess, A.J. The Executive Guide to Artificial Intelligence: How to Identify and Implement Applications for AI in Your Organization; Palgrave Macmillan: Cham, Switzerland, 2018. [Google Scholar]
- Grover, V.; Chiang, R.H.L.; Liang, T.-P.; Zhang, D. Creating strategic business value from big data analytics: A research framework. J. Manag. Inf. Syst. 2018, 35, 388–423. [Google Scholar] [CrossRef]
- Davenport, T.H. Competing on analytics. Harv. Bus. Rev. 2006, 84, 98. [Google Scholar]
- Olszak, C.M.; Ziemba, E. Critical success factors for implementing business intelligence systems in small and medium enterprises on the example of upper Silesia, Poland. Interdiscip. J. Inf. Knowl. Manag. 2012, 7, 129–150. [Google Scholar] [CrossRef] [Green Version]
- Dinh, J.E.; Lord, R.G.; Gardner, W.L.; Meuser, J.D.; Liden, R.C.; Hu, J. Leadership theory and research in the new millennium: Current theoretical trends and changing perspectives. Leadersh. Q. 2014, 25, 36–62. [Google Scholar] [CrossRef] [Green Version]
- Lussier, R.N.; Achua, C.F. Leadership: Theory, Application & Skill Development, 6th ed.; Cengage Learning: Boston, MA, USA, 2016. [Google Scholar]
- Yammarino, F. Leadership: Past, present, and future. J. Leadersh. Organ. Stud. 2013, 20, 149–155. [Google Scholar] [CrossRef]
- Bolden, R.; Gosling, J.; Marturano, A.; Dennison, P. A Review of Leadership Theory and Competency Framework; Centre for Leadership Studies, University of Exeter: Exeter, UK, 2003. [Google Scholar]
- Northouse, P.G. Leadership: Theory and Practice, 6th ed.; SAGE Publications: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Paulienė, R. Interaction between managerial competencies and leadership in business organisations. Reg. Form. Dev. Stud. 2021, 21, 97–107. [Google Scholar] [CrossRef]
- Boyatzis, R.E. Beyond Competence: The choice to be a leader. Hum. Resour. Manag. Rev. 1993, 3, 1–14. [Google Scholar] [CrossRef]
- McClell, S. Gaining competitive advantage through strategic management development (SMD). J. Manag. Dev. 1994, 13, 4–13. [Google Scholar] [CrossRef]
- Spencer, L.M.; Spencer, S.M. Competence at Work: Models for Superior Performance; John Wiley & Sons: Nashville, TN, USA, 1993. [Google Scholar]
- Black, S.A. Qualities of effective leadership in higher education. Open J. Leadersh. 2015, 04, 54–66. [Google Scholar] [CrossRef] [Green Version]
- Bennett, N.; Lemoine, G.J. What a difference a word makes: Understanding threats to performance in a VUCA world. Bus. Horiz. 2014, 57, 311–317. [Google Scholar] [CrossRef]
- Dondi, M.; Klier, J.; Panier, F.; Schubert, J. Defining the Skills Citizens Will Need in the Future World of Work. McKinsey Global Institute. Available online: https://www.mckinsey.com/industries/public-and-social-sector/our-insights/defining-the-skills-citizens-will-need-in-the-future-world-of-work (accessed on 30 June 2021).
- Faúndez, M.O.; de la Fuente-Mella, H. Skills Measurement Strategic Leadership Based on Knowledge Analytics Management through the Design of an Instrument for Business Managers of Chilean Companies. Sustainability 2022, 14, 9299. [Google Scholar] [CrossRef]
- Wang, Y. Business Intelligence and Analytics Education: Hermeneutic Literature Review and Future Directions in IS Education. 2015. Available online: https://papers.ssrn.com/abstract=2603365 (accessed on 19 November 2022).
- Ardito, L.; Scuotto, V.; Del Giudice, M.; Petruzzelli, A.M. A bibliometric analysis of research on Big Data analytics for business and management. Manag. Decis. 2019, 57, 1993–2009. [Google Scholar] [CrossRef]
- Di Vaio, A.; Hassan, R.; Alavoine, C. Data intelligence and analytics: A bibliometric analysis of human–Artificial intelligence in public sector decision-making effectiveness. Technol. Forecast. Soc. Chang. 2022, 174, 121201. [Google Scholar] [CrossRef]
- Peifer, Y.; Jeske, T.; Hille, S. Artificial Intelligence and its Impact on Leaders and Leadership. Procedia Comput. Sci. 2022, 200, 1024–1030. [Google Scholar] [CrossRef]
- Thomas, B.; Senith, S.; Alfred Kirubaraj, A.; Jino Ramson, S.R. Does management graduates’ emotional intelligence competencies predict their work performance? Insights from Artificial Neural Network Study. Mater. Today 2022, 58, 466–472. [Google Scholar] [CrossRef]
- Olszak, C.M. Business intelligence systems for innovative development of organizations. Procedia Comput. Sci. 2022, 207, 1754–1762. [Google Scholar] [CrossRef]
- Nacke, O. Informatrie: Ein never name für eine disciplin. Nachr. Dokum. 1979, 30, 429–433. [Google Scholar]
- Lotka, A.J. La distribución de frecuencias de la productividad científica. Rev. Acad. Cienc. Wash. 1926, 16, 317–323. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. Aggarwal, C.C.; Zhai, C. A survey of text clustering algorithms. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 77–128. [Google Scholar]
- Muller, A.E.; Ames, H.M.R.; Jardim, P.S.J.; Rose, C.J. Machine learning in systematic reviews: Comparing automated text clustering with Lingo3G and human researcher categorization in a rapid review. Res. Synth. Methods 2022, 13, 229–241. [Google Scholar] [CrossRef]
- Carpineto, C.; Osiński, S.; Romano, G.; Weiss, D. A survey of Web clustering engines. ACM Comput. Surv. 2009, 41, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Stansfield, C.; Thomas, J.; Kavanagh, J. “Clustering” documents automatically to support scoping reviews of research: A case study: “Clustering” to support scoping reviews. Res. Synth. Methods 2013, 4, 230–241. [Google Scholar] [CrossRef]
- Sarkar, D. Semantic Analysis. In Text Analytics with Python; Apress: Berkeley, CA, USA, 2019; pp. 519–566. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. Article: EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Aich, L.; Das, A. Informetrics of Webinars through Video Conferencing Platforms for Teaching and Learning by Different LIS Professional during COVID-19 Period: An Evaluative Study. Libr. Philos. Pract. 2021, 6679. [Google Scholar]
- Ebadi, A.; Auger, A.; Gauthier, Y. Detecting emerging technologies and their evolution using deep learning and weak signal analysis. J. Informetr. 2022, 16, 101344. [Google Scholar] [CrossRef]
- Calof, J.; Søilen, K.S.; Klavans, R.; Abdulkader, B.; Moudni, I.E. Understanding the structure, characteristics, and future of collective intelligence using local and global bibliometric analyses. Technol. Forecast. Soc. Chang. 2022, 178, 121561. [Google Scholar] [CrossRef]
- Żółtowski, D. Business intelligence in the balanced scorecard: Bibliometric analysis. Procedia Inf. 2022, 207, 4075–4086. [Google Scholar]
- Zhang, J.Z.; Srivastava, P.R.; Sharma, D.; Eachempati, P. Big data analytics and machine learning: A retrospective overview and bibliometric analysis. Expert Syst. Appl. 2021, 184, 115561. [Google Scholar] [CrossRef]
- Aboelmaged, M.; Mouakket, S. Influential models and deterministic models in big data analytics research: A bibliometric analysis. Inf. Process. Manag. 2020, 57, 102234. [Google Scholar] [CrossRef]
- Mahesh, B. Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Ullah, I.; Liu, K.; Yamamoto, T.; Zahid, M.; Jamal, A. Machine learning modeling with SHAP approach for predicting electric vehicle charging station choice behavior. Travel Behav. Soc. 2023, 31, 78–92. [Google Scholar] [CrossRef]
- Suominen, A.; Toivanen, H. Map of science with topic modeling: Comparison of unsupervised learning and human-assigned subject classification. J. Assoc. Inf. Sci. Technol. 2016, 67, 2464–2476. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, K.; Jing, J.; Fan, H.; Li, J. Solution path algorithm for twin multiclass support vector machines. Expert Syst. Appl. 2022, 210, 118361. [Google Scholar] [CrossRef]
- Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-based topic modeling sentiment analysis using topic/document/sentence (TDS) model. Appl. Sci. 2021, 11, 11091. [Google Scholar] [CrossRef]
- Mayilvahanan, K.S.; Takeuchi, K.; Takeuchi, E.; Marschilok, A.; West, A. Supervised learning of synthetic big data for li-ion battery degradation diagnosis. Batter. Supercaps 2022, 5, e202100166. [Google Scholar] [CrossRef]
- Tseng, S.C.; Lu, Y.C.; Chakraborty, G.; Chen, L.S. Comparison of opinion analysis of review comments using unsupervised feature clustering via LSA and LDA. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology, Morioka, Japan, 23–25 October 2019. [Google Scholar]
- Tiwari, S.; Agarwal, S. Life log data analysis using optimal feature selection-based unsupervised logistic regression (OFS-ULR) for chronic disease classification. arXiv 2022, arXiv:2204.01281. [Google Scholar]
- Montavon, G.; Kauffmann, J.; Samek, W.; Müller, K.-R. Explaining the predictions of unsupervised learning models. In xxAI—Beyond Explainable AI; Springer International Publishing: Cham, Switzerland, 2022; pp. 117–138. [Google Scholar]
- Gupta, O.; Roos, G. Mergers and acquisitions through an intellectual capital perspective. J. Intellect. Cap. 2001, 2, 297–309. [Google Scholar] [CrossRef]
- Lang, Z.; Liu, H.; Meng, N.; Wang, H.; Wang, H.; Kong, F. Mapping the knowledge domains of research on fire safety—An informetrics analysis. Tunn. Undergr. Space Technol. 2021, 108, 103676. [Google Scholar] [CrossRef]
- Hood, W.W.; Wilson, C.S. The Literature of Bibliometrics, Scientometrics, and Informetrics. Scientometrics 2001, 52, 291–314. [Google Scholar] [CrossRef]
- Ghahramani, Z. Unsupervised Learning. In Advanced Lectures on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 72–112. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Anderson, B.D.O.; Moore, J.B. Optimal Filtering; Prentice-Hall: London, UK, 1979. [Google Scholar]
- Korenčić, D.; Ristov, S.; Repar, J.; Šnajder, J. A topic coverage approach to evaluation of topic models. IEEE Access 2021, 9, 123280–123312. [Google Scholar] [CrossRef]
- Eck, N.J.V.; Waltman, L. Visualizing bibliometric networks. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 285–320. [Google Scholar]
- Palacios Jimenez, P.H.; Mori-Diestra, K.E.; Limaymanta Alvarez, C.H.; Loyola Romaní, J.M.; Gregorio Chaviano, O. Análisis bibliométrico y de redes sociales de la Revista Peruana de Medicina Experimental y Salud Pública (2010–2019). e-Cienc. Inf. 2020, 11. [Google Scholar] [CrossRef]
- Fujita, K.; Kajikawa, Y.; Mori, J.; Sakata, I. Detecting research fronts using different types of weighted citation networks. J. Eng. Technol. Manag. 2014, 32, 129–146. [Google Scholar] [CrossRef]
- Hofmann, M.; Chisholm, A. (Eds.) Text Mining and Visualization: Case Studies Using Open-Source Tools; Apple Academic Press: Oakville, MO, USA, 2015. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining—WSDM ’15, Shanghai, China, 2–6 February 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar]
- Nicholls, P.T. Bibliometric modeling processes and the empirical validity of Lotka’s Law. J. Am. Soc. Inf. Sci. 1989, 40, 379–385. [Google Scholar] [CrossRef]
- Musarra, G.; Kadile, V.; Zaefarian, G.; Oghazi, P.; Najafi-Tavani, Z. Emotions, culture intelligence, and mutual trust in technology business relationships. Technol. Forecast. Soc. Chang. 2022, 181, 121770. Available online: https://www.sciencedirect.com/science/article/pii/S0040162522002943 (accessed on 19 November 2022). [CrossRef]
















| Web of Science | Scopus |
|---|---|
| TS = (“business intelligence” AND (analytical OR strategic OR analysis OR descriptive OR predictive OR prescriptive OR competitive OR “Analytics 1.0” OR “Analytics 2.0” OR “Analytics 3.0” OR “Analytics 4.0”) AND (Leadership OR Models OR Competenc * s OR “competency center” OR leadership OR capability * OR skill * OR ability *) AND (“big data” OR “data warehouse” OR “machine learning” OR “predictive modeling” OR mobile OR dashboard OR cloud OR “data mining” OR “Artificial Intelligence” OR OLAP) AND (exploratory OR benefits OR implementation OR solutions OR success OR satisfaction OR decision OR continuum OR management OR adoption OR benefits OR implementation)) Refined by: DOCUMENT TYPES: (Article OR review OR proceedings papers) Indexes: SCI-EXPANDED, SSCI, A&HCI, ESCI. | TITLE-ABS-KEY (“business intelligence” AND (analytical OR strategic OR analysis OR descriptive OR predictive OR prescriptive OR competitive OR “Analytics 1.0” OR “Analytics 2.0” OR “Analytics 3.0” OR “Analytics 4.0”) AND (leadership OR models OR competenc * s OR “competency center” OR leadership OR capability * OR skill * OR ability *) AND (“big data” OR “data warehouse” OR “machine learning” OR “predictive modeling” OR mobile OR dashboard OR cloud OR “data mining” OR “Artificial Intelligence” OR olap) AND (exploratory OR benefits OR implementation OR solutions OR success OR satisfaction OR decision OR continuum OR management OR adoption OR benefits OR implementation)) AND (LIMIT-TO (DOCTYPE, “cp”) OR LIMIT-TO (DOCTYPE, “ar”) OR LIMIT-TO (DOCTYPE, “re”)) |
| Analyzed Dimensions | Indicators/Variables: Description |
|---|---|
| Scientific activity | Scientific Production |
| |
| Scientific collaboration |
|
| Structural analysis | Statistical technique and variables |
| Thematic structure | Keyword co-occurrence network |
| N° | Author | NT | Main Institution & Country | Scopus ID | H-Index * |
|---|---|---|---|---|---|
| 1 | Trujillo, Juan Carlos | 13 | Universidad de Alicante Spain | 7103051196 | 29 |
| 2 | Mylopoulos, John | 11 | University of Toronto Canada | 7005652259 | 53 |
| 3 | Bimonte, Sandro | 10 | Université Clermont Auvergne France | 15074087900 | 14 |
| 4 | Maté, Alejandro | 10 | Universidad de Alicante Spain | 42961909600 | 14 |
| 5 | Schrefl, Michael | 9 | Johannes Kepler University Linz Austria | 6603818133 | 17 |
| 6 | Carta, Salvatore Mario | 8 | Università degli Studi di Cagliari Italy | 7004254388 | 24 |
| 7 | Saia, Roberto | 8 | Università degli Studi di Cagliari Italy | 56029094200 | 14 |
| 8 | Goul, Michael | 7 | W. P. Carey School of Business United States | 6701579478 | 16 |
| 9 | Shi, Yong | 7 | Chinese Academy of Sciences China | 7404963015 | 43 |
| No. | Journal | Country | NT | Quartile * | Publisher |
|---|---|---|---|---|---|
| 1 | Decision Support Systems | Netherlands | 12 | Q1 | Elsevier |
| 2 | International Journal of Information Management | United Kingdom | 12 | Q1 | Elsevier |
| 3 | Expert Systems with Applications | United Kingdom | 10 | Q1 | Elsevier |
| 4 | Communications of the Association for Information Systems | United States | 8 | Q2 | Association for Information Systems |
| 5 | IEEE Access | United States | 7 | Q1 | Institute of Electrical and Electronics Engineers |
| 6 | Journal of Intelligence Studies in Business | Sweden | 7 | Q2 | Halmstad University |
| 7 | Journal of Computer Information Systems | United Kingdom | 6 | Q1 | Taylor and Francis |
| 8 | Sustainability (Switzerland) | Switzerland | 6 | Q1 | MDPI AG |
| 9 | Journal of Database Management | United States | 5 | Q3 | IGI Publishing |
| 10 | Management Decision | United Kingdom | 5 | Q1 | Emerald Group Publishing |
| 11 | Information Professional | Spain | 5 | Q1 | The Information Professional |
| No. of Authors | Year of Publication | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1999–2001 | 2002–2004 | 2005–2007 | 2008–2010 | 2011–2013 | 2014–2016 | 2017–2019 | 2020–2021 | ||
| 1 | 0 | 3 | 9 | 15 | 29 | 38 | 48 | 19 | 161 (13.1%) |
| 2 | 1 | 5 | 12 | 38 | 54 | 70 | 95 | 50 | 325 (26.4%) |
| 3 | 1 | 9 | 19 | 24 | 51 | 88 | 115 | 51 | 358 (29.1%) |
| ≥4 | 3 | 6 | 14 | 24 | 54 | 84 | 118 | 83 | 386 (31.4%) |
| Total | 5 | 23 | 54 | 101 | 188 | 280 | 376 | 203 | 1230 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faúndez, M.O.; de la Fuente-Mella, H. Data Analysis and Domain Knowledge for Strategic Competencies Using Business Intelligence and Analytics. Mathematics 2023, 11, 34. https://doi.org/10.3390/math11010034
Faúndez MO, de la Fuente-Mella H. Data Analysis and Domain Knowledge for Strategic Competencies Using Business Intelligence and Analytics. Mathematics. 2023; 11(1):34. https://doi.org/10.3390/math11010034
Chicago/Turabian StyleFaúndez, Mauricio Olivares, and Hanns de la Fuente-Mella. 2023. "Data Analysis and Domain Knowledge for Strategic Competencies Using Business Intelligence and Analytics" Mathematics 11, no. 1: 34. https://doi.org/10.3390/math11010034
APA StyleFaúndez, M. O., & de la Fuente-Mella, H. (2023). Data Analysis and Domain Knowledge for Strategic Competencies Using Business Intelligence and Analytics. Mathematics, 11(1), 34. https://doi.org/10.3390/math11010034