
Low-Light Image Enhancement by Combining Transformer and Convolutional Neural Network

 ,
,
Abstract
:1. Introduction
- We propose an end-to-end low-light image enhancement network by combining the transformer and CNN. Both the local and the global features are accurately learned for light enhancement within this network, where the CNN effectively extracts local features and the transformer precisely learns the long-range dependencies.
- We creatively applied the transformer model to the low-light image enhancement task, and built a U-shaped low-light network with fusion blocks including transformer and CNN.
- Our proposed method is evaluated on the LOL dataset, and the experimental results demonstrate that the proposed network outperforms the other state-of-the-art (SOTA) models in qualitative and quantitative comparisons.
2. Related Work
2.1. Conventional Low-Light Image Enhancement Methods
2.2. Intelligent Low-Light Image Enhancement Methods
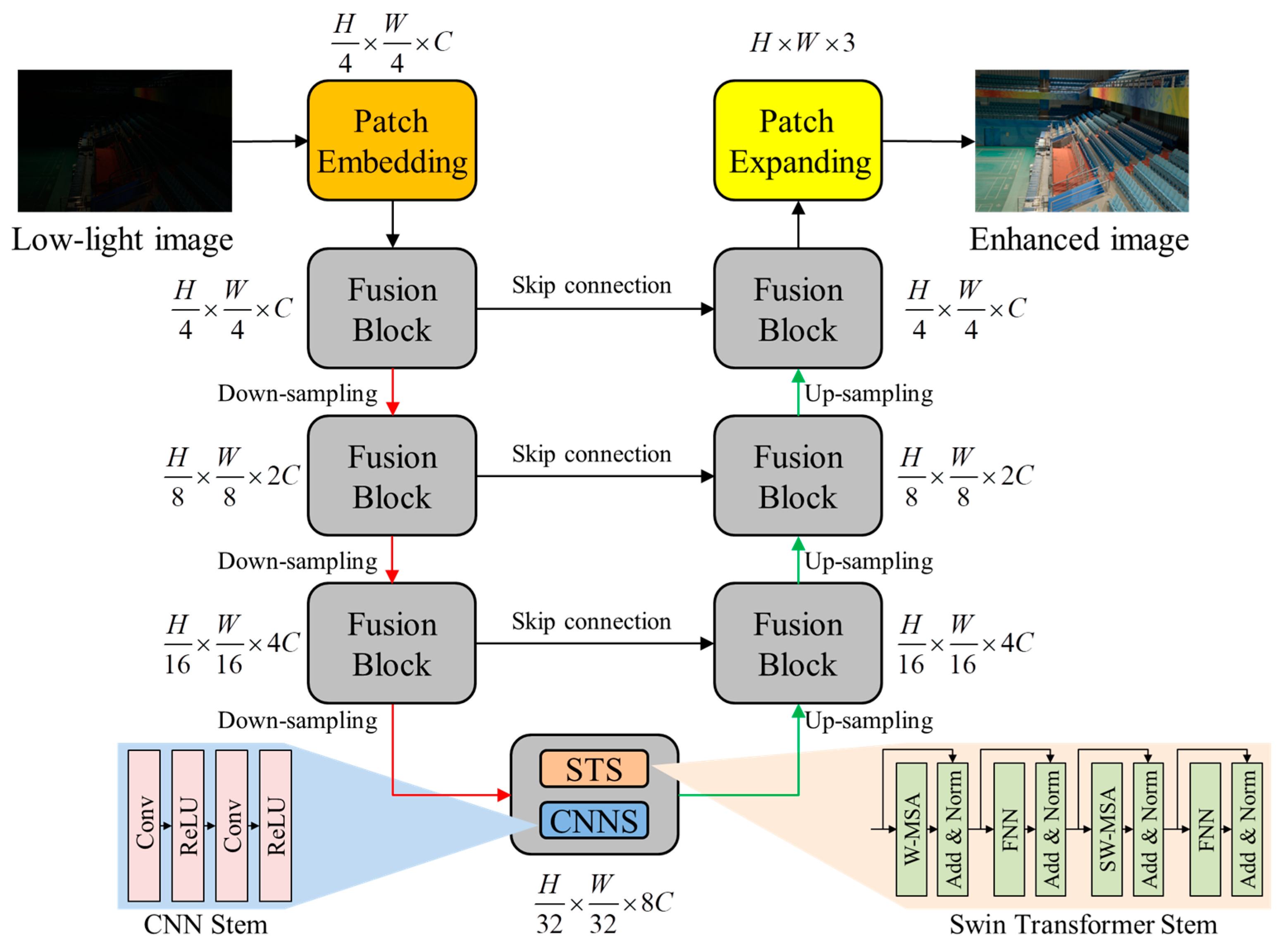
3. Proposed Method
3.1. Network Framework
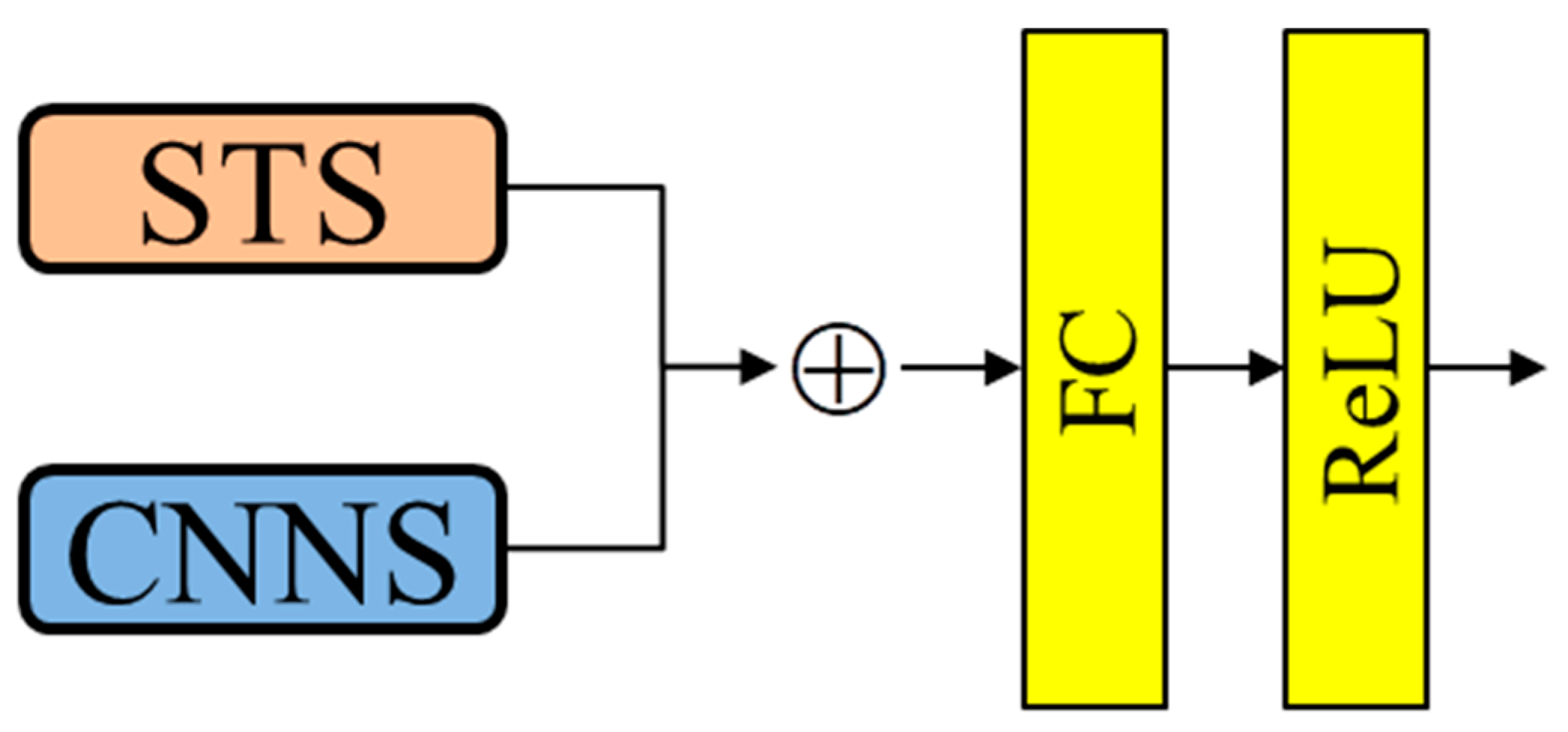
3.2. Fusion Block
3.2.1. Swin Transformer Stem
3.2.2. CNN Stem
3.3. Loss Function
3.3.1. Pixel-Level Parametric Loss
3.3.2. Structural Similarity Loss
3.3.3. Perceptual Loss
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Criteria
4.2. Comparison with Other Methods
4.2.1. Qualitative Comparison
4.2.2. Quantitative Comparison
4.3. Ablation Study
4.3.1. Effectiveness of Fusion Block
4.3.2. Effectiveness of Different Network Structures
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Xiong, P.; Fan, H. DFANet: Deep feature aggregation for realtime semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9514–9523. [Google Scholar]
- Maji, S.; Bourdev, L.D.; Malik, J. Action recognition from a distributed representation of pose and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3177–3184. [Google Scholar]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks. arXiv 2017, arXiv:1412.4729. [Google Scholar]
- Zhao, Z.; Sun, B.Y. Hyperspectral anomaly detection via memory-augmented autoencoders. CAAI Trans. Intell. Technol. 2022, 1–14. [Google Scholar] [CrossRef]
- Zhang, Q.; Xiao, J.Y.; Tian, C.W.; Lin, J.C.; Zhang, S.C. A robust deformed convolutional neural network (CNN) for image denoising. CAAI Trans. Intell. Technol. 2022, 1–12. [Google Scholar] [CrossRef]
- Guo, X.J.; Li, Y.; Ling, H.B. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.J.; Yang, W.H.; Liu, J.Y. Deep retinex decomposition for low-light enhancement. In Proceedings of the 29th British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Vyas, A.; Yu, S.; Paik, J. Fundamentals of digital image processing. In Signals and Communication Technology; Prentice-Hall: Upper Saddle River, NJ, USA, 2018; pp. 3–11. [Google Scholar]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for Image contrast enhancement. IEEE Trans. Consum. Electron. 2008, 53, 1752–1758. [Google Scholar] [CrossRef]
- Wang, C.; Ye, Z. Brightness preserving histogram equalization with maximum entropy: A variational perspective. IEEE Trans. Consum. Electron. 2005, 51, 1326–1334. [Google Scholar] [CrossRef]
- Chen, S.D.; Ramli, A.R. Minimum mean brightness error Bi-histogram equalization in contrast enhancement. IEEE Trans. Consum. Electron. 2003, 49, 1310–1319. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.H.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Li, M.D.; Liu, J.Y.; Yang, W.H.; Sun, X.Y.; Guo, Z.M. Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.H.; Zhang, J.W.; Guo, X.J. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia(ICM), Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Chen, C.; Chen, Q.F.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3291–3300. [Google Scholar]
- Wang, R.X.; Zhang, Q.; Fu, C.W.; Shen, X.Y.; Zheng, W.S.; Jia, J.Y. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6842–6850. [Google Scholar]
- Jiang, Y.F.; Gong, X.Y.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.H.; Yang, J.C.; Zhou, P.; Wang, Z.Y. EnlightenGAN: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.Y.; Liu, R.S.; Fan, X.; Luo, Z.Y. Toward Fast, Flexible, and Robust Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. arXiv 2016, arXiv:1603.08155. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Brauers, J.; Aach, T. A color filter array based multispectral camera. In Proceedings of the Workshop Farbbildverarbeitung, Ilmenau, Germany, 5–6 October 2006; Volume 12, pp. 1–11. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Webster, M.A.; Kay, P. Color categories and color appearance. Cognition 2012, 122, 375–392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, M.R.; Gui, G.; Rigg, B. The development of the cie 2000 colour difference formula: Ciede2000. Color Res. Appl. 2001, 26, 340–350. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Lv, F.F.; Lu, F.; Wu, J.H.; Lim, C.S. MBLLEN: Low-light image/video enhancement using CNNs. In Proceedings of the 29th British Machine Vision Conference(BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–13. [Google Scholar]
- Wang, W.J.; Wei, C.; Yang, W.H.; Liu, G.Y. GLADNet: Low-light enhancement network with global awareness. In Proceedings of the 13th IEEE International Conference on Automatic Face and Gesture Recognition(FG), Xi’an, China, 15–19 May 2018; pp. 751–755. [Google Scholar]
- Zhang, Y.; Di, X.G.; Zhang, B.; Wang, C. Self-supervised image enhancement network: Training with low light images only. arXiv 2020, arXiv:2002.11300. [Google Scholar]
- Guo, C.; Li, C.Y.; Guo, J.C. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1777–1786. [Google Scholar]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process 2015, 24, 3345–3356. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Lee, C.; Kim, C. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef] [PubMed]
- Vonikakis, V.; Andreadis, I.; Gasteratos, A. Fast centre-surround contrast modification. IET Image Process. 2008, 2, 19–34. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.H.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Cao, H.; Wang, Y.Y.; Chen, J.; Jiang, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MBLLEN | RetinexNet | KinD | GLADNet | LIME | SIE | Zero-DCE | Ours |
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | 17.73 | 16.46 | 19.95 | 19.50 | 17.25 | 17.13 | 18.53 | 21.68 |
| SSIM | 0.706 | 0.494 | 0.813 | 0.756 | 0.562 | 0.731 | 0.659 | 0.863 |
| LPIPS | 0.250 | 0.441 | 0.138 | 0.240 | 0.283 | 0.259 | 0.234 | 0.095 |
| DeltaE | 18.0333 | 16.0340 | 10.8781 | 11.7905 | 10.1873 | 13.4434 | 15.3983 | 10.0842 |
| DeltaE2000 | 23.0806 | 19.7853 | 15.8863 | 16.1066 | 12.4602 | 18.4470 | 21.6841 | 14.6195 |
| NIQE | 5.3745 | 7.0342 | 4.8470 | 4.7715 | 5.2755 | 5.4065 | 4.9446 | 4.0809 |
| Backbone | Swin Transformer Stem | CNN Stem | ViT Transformer Stem | Fusion Blocks | PSNR (dB) | SSIM | LPIPS | NIQE |
|---|---|---|---|---|---|---|---|---|
| √ | √ | 20.30 | 0.854 | 0.107 | 4.0778 | |||
| √ | √ | √ | 7 | 18.51 | 0.713 | 0.240 | 4.7611 | |
| √ | √ | √ | 5 | 20.24 | 0.851 | 0.115 | 4.2105 | |
| √ | √ | √ | 7 | 21.68 | 0.863 | 0.095 | 4.0809 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, N.; Zhao, X.; Sun, B.; Han, W.; Tan, J.; Duan, T.; Gao, X. Low-Light Image Enhancement by Combining Transformer and Convolutional Neural Network. Mathematics 2023, 11, 1657. https://doi.org/10.3390/math11071657
Yuan N, Zhao X, Sun B, Han W, Tan J, Duan T, Gao X. Low-Light Image Enhancement by Combining Transformer and Convolutional Neural Network. Mathematics. 2023; 11(7):1657. https://doi.org/10.3390/math11071657
Chicago/Turabian StyleYuan, Nianzeng, Xingyun Zhao, Bangyong Sun, Wenjia Han, Jiahai Tan, Tao Duan, and Xiaomei Gao. 2023. "Low-Light Image Enhancement by Combining Transformer and Convolutional Neural Network" Mathematics 11, no. 7: 1657. https://doi.org/10.3390/math11071657
APA StyleYuan, N., Zhao, X., Sun, B., Han, W., Tan, J., Duan, T., & Gao, X. (2023). Low-Light Image Enhancement by Combining Transformer and Convolutional Neural Network. Mathematics, 11(7), 1657. https://doi.org/10.3390/math11071657