


Meta-Learning for Zero-Shot Remote Sensing Image Super-Resolution

Abstract
:1. Introduction
- For the first time, a meta-learning framework was introduced into zero-shot remote sensing image super-resolution, and we propose a new solution;
- We learn to perform zero-shot super-resolution on remote sensing images from the task level, and learn meta-knowledge of the task through meta-learning, achieving good results with zero-shot remote sensing image super-resolution;
- We take full advantage of the advantages of MAML and ZSSR, so solving the mismatch between low-resolution remote sensing images and high-resolution remote sensing images.
2. Related Work
2.1. Zero-Shot Super-Resolution
2.2. Meta-Learning
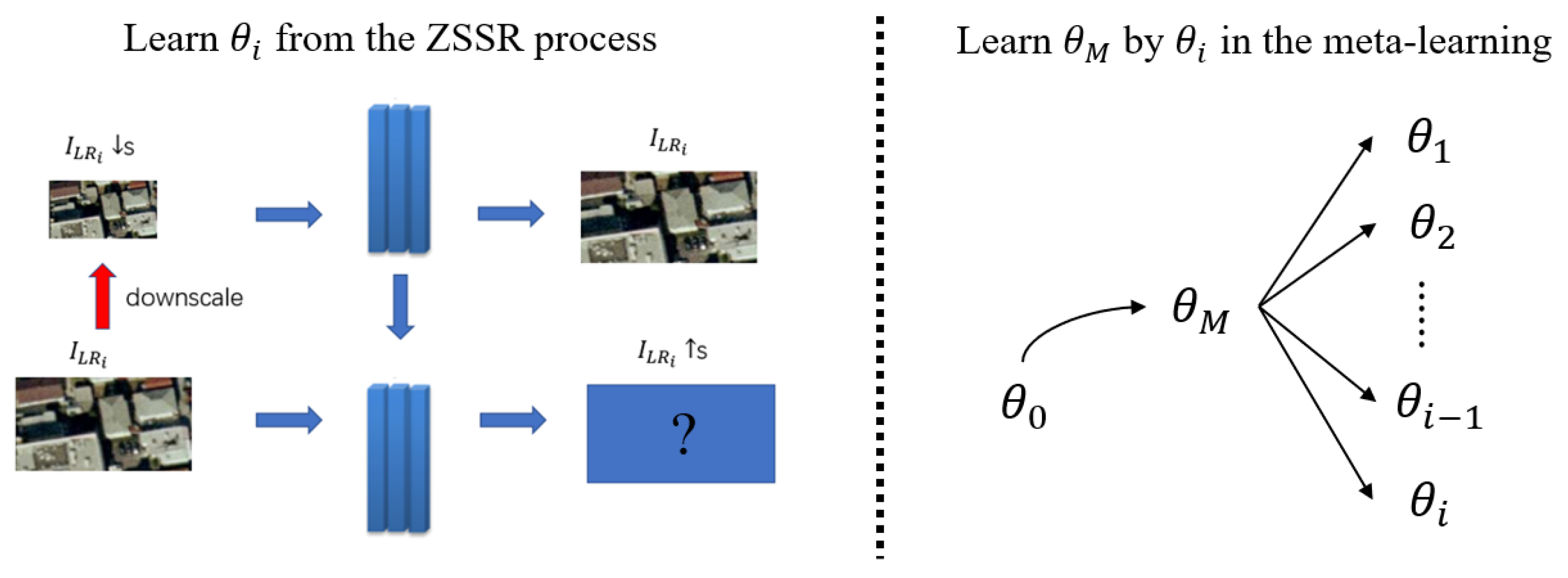
3. Proposed Method
4. Algorithm
| Algorithm 1: Meta-learning Zero-shot Image Super-resolution. |
 |
5. Experiments
5.1. Dataset, Evaluation Indicators, and Training Details
5.2. Visualize Images and Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Guo, X.; Woo, P.Y.M.; Yuan, Y. Super-Resolution Enhanced Medical Image Diagnosis with Sample Affinity Interaction. IEEE Trans. Med Imaging 2021, 40, 1377–1389. [Google Scholar] [CrossRef]
- Ran, Q.; Xu, X.; Zhao, S.; Li, W.; Du, Q. Remote sensing images super-resolution with deep convolution networks. Multimed. Tools Appl. 2020, 79, 8985–9001. [Google Scholar] [CrossRef]
- Zhang, M.; Xin, J.; Zhang, J.; Tao, D.; Gao, X. Curvature Consistent Network for Microscope Chip Image Super-Resolution. IEEE Trans. Neural Networks Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Feng, Y.; Dai, T.; Bai, J.; Jiang, Y.; Xia, S.T.; Wang, X. Adversarial Examples Generation for Deep Product Quantization Networks on Image Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1388–1404. [Google Scholar] [CrossRef]
- Wu, X.; Wu, Z.; Ju, L.; Wang, S. A One-Stage Domain Adaptation Network with Image Alignment for Unsupervised Nighttime Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 58–72. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolu tional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Haque, W.A.; Arefin, S.; Shihavuddin, A.S.M.; Hasan, M.A. DeepThin: A novel lightweight CNN architecture for traffic sign recognition without GPU requirements. Expert Syst. Appl. 2021, 168, 114481. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. RankSRGAN: Super Resolution Generative Adversarial Networks with Learning to Rank. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7149–7166. [Google Scholar] [PubMed]
- Zheng, X.; Chen, W.; Lu, X. Spectral super-resolution of multi spectral images using spatial–spectral residual attention network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, L.; Fu, H. Rrsgan: Reference-based super resolution for remote sensing image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Coupled adversarial training for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3633–3643. [Google Scholar] [CrossRef]
- Feng, X.; Zhang, W.; Su, X.; Xu, Z. Optical Remote Sensing Image Denoising Furthermore, Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain. Remote Sens. 2021, 13, 1858. [Google Scholar] [CrossRef]
- Wan, Y.; Ma, A.; He, W.; Zhong, Y. Accurate Multiobjective Low-Rank and Sparse Model for Hyperspectral Image Denoising Method. IEEE Trans. Evol. Comput. 2023, 27, 37–51. [Google Scholar] [CrossRef]
- Ning, Q.; Dong, W.; Li, X.; Wu, J.; Li, L.; Shi, G. Searching Efficient Model-Guided Deep Network for Image Denoising. IEEE Trans. Image Process. 2023, 32, 668–681. [Google Scholar] [CrossRef]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image Super-Resolution via Iterative Refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4713–4726. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Yao, Q.; Li, C.; Yokoya, N.; Zhao, Q.; Zhang, H.; Zhang, L. Non-Local Meets Global: An Iterative Paradigm for Hyperspectral Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2022, 44, 2089–2107. [Google Scholar] [CrossRef] [PubMed]
- Zha, Z.; Yuan, X.; Wen, B.; Zhou, J.; Zhu, C. Group Sparsity Residual Constraint with Non-Local Priors for Image Restoration. IEEE Trans. Image Process. 2020, 29, 8960–8975. [Google Scholar] [CrossRef] [PubMed]
- Fei, N.; Li, G.; Wang, X.; Li, J.; Hu, X.; Hu, Y. Deep Learning-Based Auto-Segmentation of Spinal Cord Internal Structure of Diffusion Tensor Imaging in Cervical Spondylotic Myelopathy. Diagnostics 2023, 13, 817. [Google Scholar] [CrossRef]
- Shocher, A.; Cohen, N.; Irani, M. “Zero-Shot” Super-Resolution Using Deep Internal Learning. Comput. Vis. Pattern Recognit. 2018, 3118–3126. [Google Scholar]
- Fu, Y.; Zhang, T.; Wang, L.; Huang, H. Coded Hyperspectral Image Reconstruction Using Deep External and Internal Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3404–3420. [Google Scholar] [CrossRef]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-transfer learning for zero shot super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3516–3525. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Ye, H.; Han, L.; Zhan, D. Revisiting Unsupervised Meta-Learning via the Characteristics of Few-Shot Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3721–3737. [Google Scholar] [CrossRef]
- Jiang, H.; Gao, M.; Li, H.; Jin, R.; Miao, H.; Liu, J. Multi-Learner Based Deep Meta-Learning for Few-Shot Medical Image Classification. IEEE J. Biomed. Health Inform. 2023, 27, 17–28. [Google Scholar] [CrossRef] [PubMed]
- Flennerhag, S.; Rusu, A.A.; Pascanu, R.; Visin, F.; Yin, H.; Hadsell, R. Meta-Learning with Warped Gradient Descent. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Xie, W.; He, L.; Gao, X. Deep Hybrid 2-D–3-D CNN Based on Dual Second-Order Attention with Camera Spectral Sensitivity Prior for Spectral Super-Resolution. IEEE Trans. Neural Networks Learn. Syst. 2023, 34, 623–634. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Jin, Z.; Zhao, Y. SRDRL: A Blind Super-Resolution Framework with Degradation Reconstruction Loss. IEEE Trans. Multimed. 2022, 24, 2877–2889. [Google Scholar] [CrossRef]
- Chen, H.; He, X.; Yang, H.; Wu, Y.; Qing, L.; Sheriff, R.E. Self-supervised cycle-consistent learning for scale-arbitrary real-world single image super-resolution. Expert Syst. Appl. 2023, 212, 118657. [Google Scholar] [CrossRef]
- Song, J.; Liu, K.; Sowmya, A.; Sun, C. Super-Resolution Phase Retrieval Network for Single-Pattern Structured Light 3D Imaging. IEEE Trans. Image Process. 2023, 32, 537–549. [Google Scholar] [CrossRef]
- Cheng, X.; Fu, Z.; Yang, J. Zero-shot image super-resolution with depth guided internal degradation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 265–280. [Google Scholar]
- Cheng, Z.; Xiong, Z.; Chen, C.; Liu, D.; Zha, Z.-J. Light field super resolution with zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10005–10014. [Google Scholar]
- Huisman, M.; Rijn, J.N.V.; Plaat, A. A survey of deep metalearning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Patacchiola, M.; Turner, J.; Crowley, E.J.; O’Boyle, M.; Storkey, A. Bayesian Meta-Learning for the Few-Shot Setting via Deep Kernels. In Proceedings of the Conference on Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 16108–16118. [Google Scholar]
- Dai, Z.; Chen, Y.; Yu, H.; Low, B.K.H.; Jaillet, P. On provably robust meta-Bayesian optimization. In Proceedings of the International Conference on Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022; pp. 475–485. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T.P. Meta-Learning with Memory-Augmented Neural Networks. J. Mach. Learn. Res. 2016, 48, 1842–1850. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4080–4090. [Google Scholar]
- Gupta, A.; Mendonca, R.; Liu, Y.; Abbeel, P.; Levine, S. Meta-Reinforcement Learning of Structured Exploration Strategies. In Proceedings of the Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 5307–5316. [Google Scholar]
- Nagabandi, A.; Clavera, I.; Liu, S.; Fearing, R.S.; Abbeel, P.; Levine, S.; Finn, C. Learning to Adapt in Dynamic, Real-World Environments through Meta-Reinforcement Learning. arXiv 2018, arXiv:1803.11347. [Google Scholar]
- Grant, E.; Finn, C.; Levine, S.; Darrell, T.; Griffiths, T. Recasting gradient-based meta-learning as hierarchical bayes. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, W.; Wang, T.; Wang, Z.; Cheng, L.; Wu, H. Meta transfer learning-based super-resolution infrared imaging. Digit. Signal Process. 2022, 131, 103730. [Google Scholar] [CrossRef]
- Park, S.; Yoo, J.; Cho, D.; Kim, J.; Kim, T.H. Fast adaptation to super-resolution networks via meta-learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 754–769. [Google Scholar]
- Yang, Z.; Shi, P.; Pan, D. A survey of super-resolution based on deep learning. In Proceedings of the 2020 International Conference on Culture-Oriented Science and Technology (ICCST), Beijing, China, 30–31 October 2020; pp. 514–518. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yue, H. The Temperature Vegetation Dryness Index (TVDI) Based on Bi-Parabolic NDVI-Ts Space and Gradient-Based Structural Similarity (GSSIM) for Long-Term Drought Assessment Across Shaanxi Province China (2000–2016). Remote Sens. 2018, 10, 959. [Google Scholar] [CrossRef] [Green Version]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local-Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CLASS | SCALE | PSNR | |||||
|---|---|---|---|---|---|---|---|
| Bicubic | SRCNN | VDSR | LGCNetR | ZSSR | Ours | ||
| Airplane | ×2 | 28.138 | 32.091 | 36.234 | 36.327 | 42.859 | 42.928 |
| ×4 | 23.582 | 26.034 | 29.122 | 29.019 | 35.963 | 35.987 | |
| Parking Lot | ×2 | 23.412 | 27.401 | 30.303 | 30.217 | 38.724 | 38.824 |
| ×4 | 19.073 | 20.845 | 22.609 | 22.719 | 31.560 | 31.836 | |
| Building | ×2 | 26.305 | 31.201 | 34.458 | 34.327 | 42.582 | 42.711 |
| ×4 | 21.561 | 24.019 | 26.578 | 26.703 | 35.747 | 35.826 | |
| DATASETS | SCALE | PSNR | |||||
|---|---|---|---|---|---|---|---|
| Bicubic | SRCNN | VDSR | LGCNet | ZSSR | Ours | ||
| UC Merced | ×2 | 30.152 | 31.749 | 33.580 | 33.660 | 40.310 | 40.530 |
| ×4 | 25.133 | 26.323 | 27.276 | 27.354 | 33.389 | 33.460 | |
| NWPU-RESISC45 | ×2 | 30.752 | 30.601 | 32.735 | 32.631 | 41.851 | 42.078 |
| ×4 | 26.380 | 27.393 | 27.551 | 27.696 | 34.742 | 35.164 | |
| SSIM | |||||||
| UC Merced | ×2 | 0.8286 | 0.8619 | 0.8932 | 0.8904 | 0.9857 | 0.9858 |
| ×4 | 0.6718 | 0.6895 | 0.7098 | 0.7220 | 0.9704 | 0.9710 | |
| NWPU-RESISC45 | ×2 | 0.8313 | 0.8151 | 0.8900 | 0.8860 | 0.9864 | 0.9867 |
| ×4 | 0.6427 | 0.6758 | 0.7003 | 0.7103 | 0.9750 | 0.9761 | |
| GSSIM | |||||||
| UC Merced | ×2 | 0.8249 | 0.8569 | 0.8876 | 0.8845 | 0.9816 | 0.9825 |
| ×4 | 0.6598 | 0.6815 | 0.7037 | 0.7139 | 0.9585 | 0.9636 | |
| NWPU-RESISC45 | ×2 | 0.8256 | 0.8102 | 0.8845 | 0.8802 | 0.9811 | 0.9808 |
| ×4 | 0.6326 | 0.6683 | 0.6916 | 0.6987 | 0.9664 | 0.9673 | |
| TASKS | STAGE | TIME (mins) | |
|---|---|---|---|
| ZSSR | OURS | ||
| 5 | Train | 15 | 16 |
| Test | 15 | 9 | |
| 10 | Train | 30 | 25 |
| Test | 30 | 16 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, Z.; Xu, D.; Tang, Y.; Jiang, Z. Meta-Learning for Zero-Shot Remote Sensing Image Super-Resolution. Mathematics 2023, 11, 1653. https://doi.org/10.3390/math11071653
Cha Z, Xu D, Tang Y, Jiang Z. Meta-Learning for Zero-Shot Remote Sensing Image Super-Resolution. Mathematics. 2023; 11(7):1653. https://doi.org/10.3390/math11071653
Chicago/Turabian StyleCha, Zhangzhao, Dongmei Xu, Yi Tang, and Zuo Jiang. 2023. "Meta-Learning for Zero-Shot Remote Sensing Image Super-Resolution" Mathematics 11, no. 7: 1653. https://doi.org/10.3390/math11071653
APA StyleCha, Z., Xu, D., Tang, Y., & Jiang, Z. (2023). Meta-Learning for Zero-Shot Remote Sensing Image Super-Resolution. Mathematics, 11(7), 1653. https://doi.org/10.3390/math11071653