
RUL Prediction for Piezoelectric Vibration Sensors Based on Digital-Twin and LSTM Network


Abstract
:1. Introduction
- The PVS DT framework for RUL prediction based on the LSTM network is optimized and validated by building a DT platform for RUL prediction that fully utilizes the features of PVSs and sample datasets for the multiple failure modes. The scheme paves the way for DT and LSTM-based modeling of similar devices.
- A novel method to predict the RUL of PVS based on DT data and the LSTM network is proposed and provides accurate RUL prediction results for the PVS. It can help deal with degradation sequences with complex feature distribution and utilize the historical degradation data from different failure modes and non-failed samples.
- The influence of sample set parameters on the prediction effect is discussed through the training and validation of different training sets, verifying the method’s advantages in utilizing degraded data and prediction effect.
2. Structure and Failure Modes of PVS
2.1. Structure and Signal Characters of PVS
2.2. Failure Analysis of PVS
2.2.1. Output Short Circuit Caused by Coating Metal Whiskers Growth
2.2.2. Output Open Circuit Caused by Solder Joint Fracture
2.2.3. Sensitivity Out-of-Tolerance
3. DT-Based PVS RUL Analysis
3.1. DT Architecture for PVS RUL Prediction Based on LSTM Network
3.2. Relative Factors Analysis of RUL for PVS
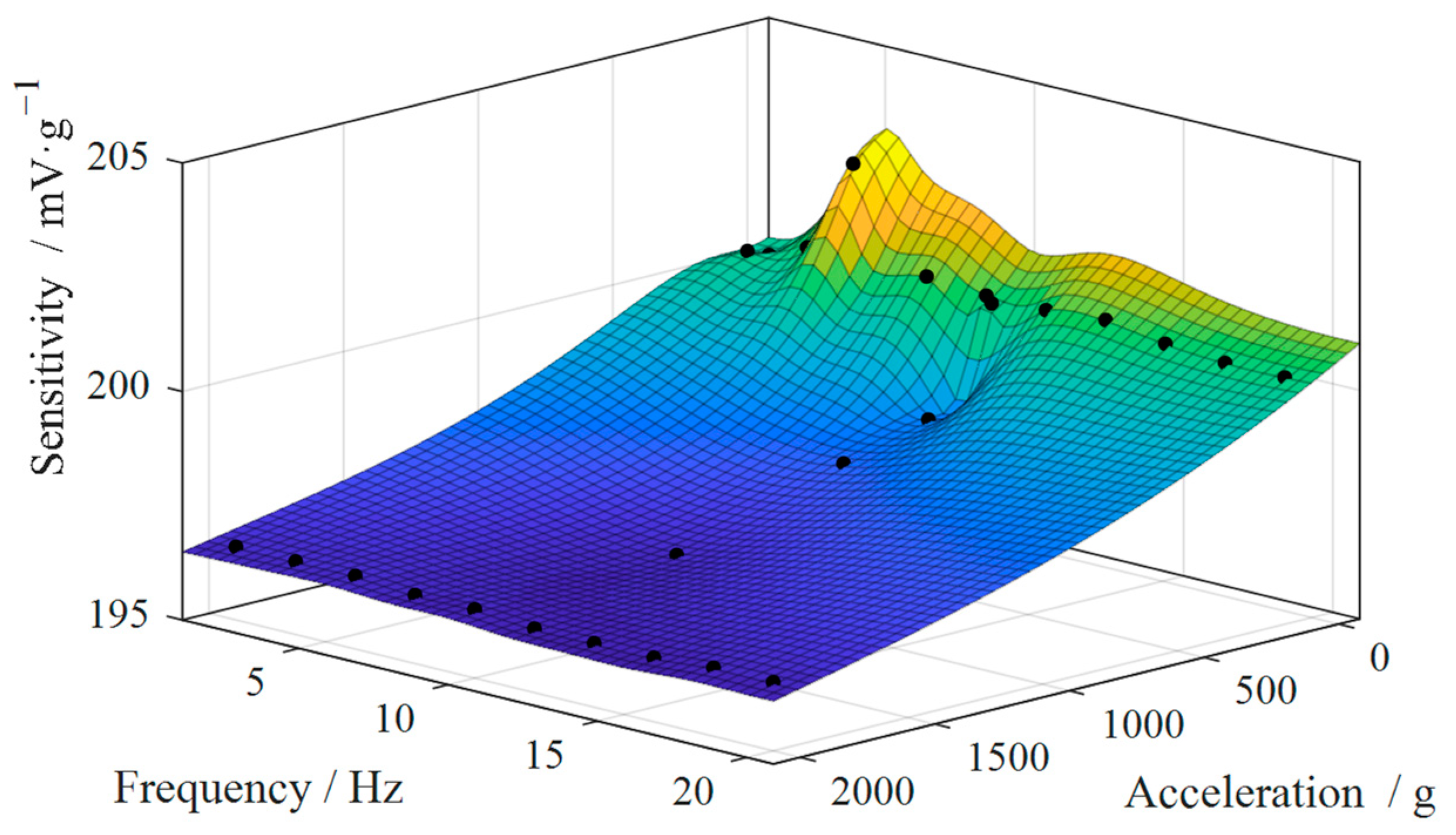
3.2.1. Calculation of Features in DT
3.2.2. Simulation of Features in DT
4. RUL Prediction Algorithm Based on DT Data and LSTM Network
4.1. LSTM Structure Details
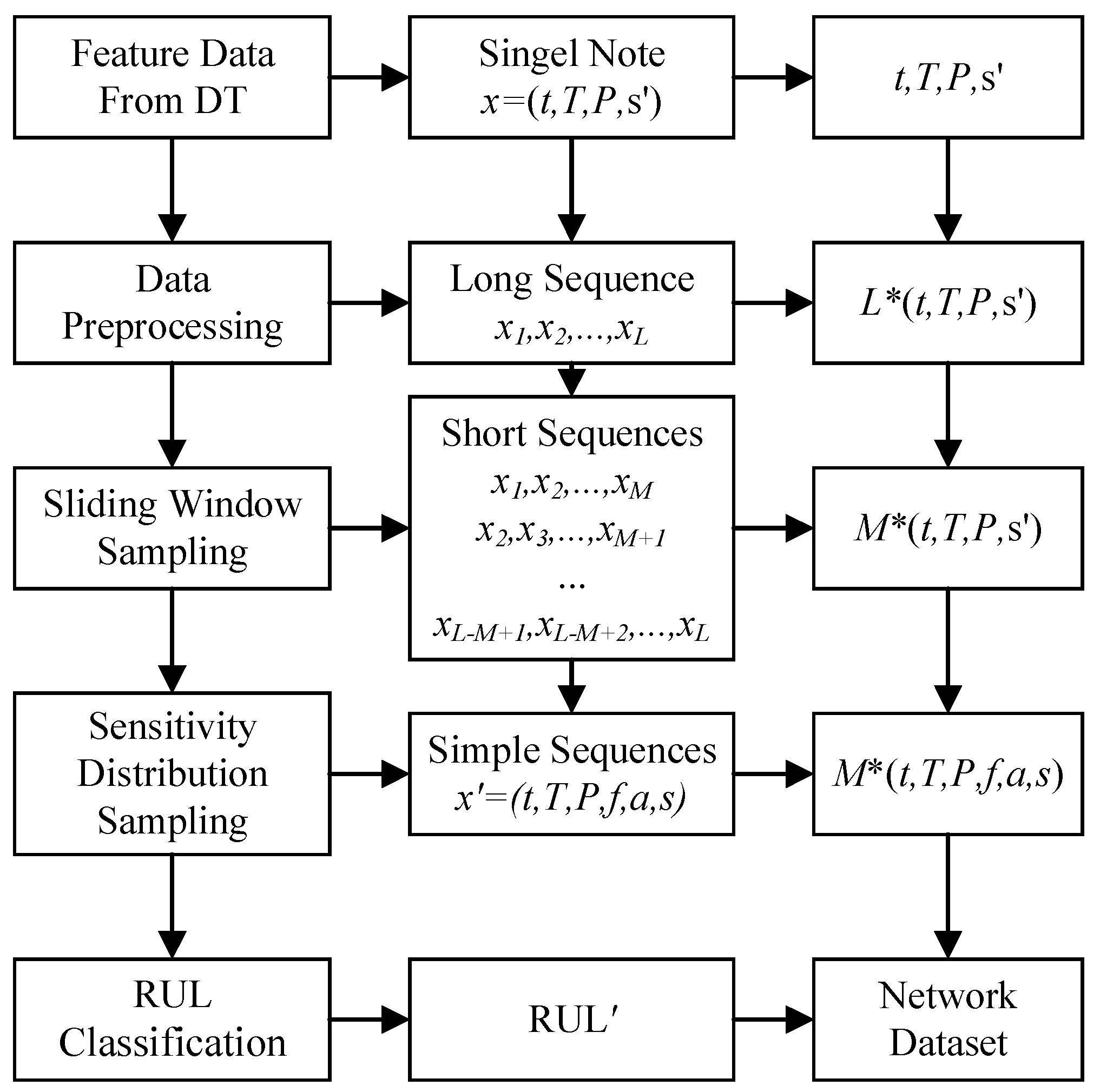
4.2. Data Organization
4.2.1. Degradation Features Data Collection
4.2.2. Sample Optimization Based on Sliding Window and Sensitivity Distribution Data Sampling
4.2.3. Classification of RUL
4.3. Network Training and Performance Evaluation
5. Results and Discussion
5.1. Degradation Data Acquisition
- All samples are placed in the high-temperature test chamber and subjected to heating at a constant rate;
- After the determined heating time, the samples are removed from the test chamber with a fixed cooling rate and installed on the vibration exciter;
- The vibration condition is set at 28 typical conditions as listed in Table 2, and the function and sensitivity of the PVSs are recorded;
- The test is terminated once a PVS sample fails.
5.2. LSTM Network Training and Validation
5.2.1. DT Data Pre-Processing and Organization
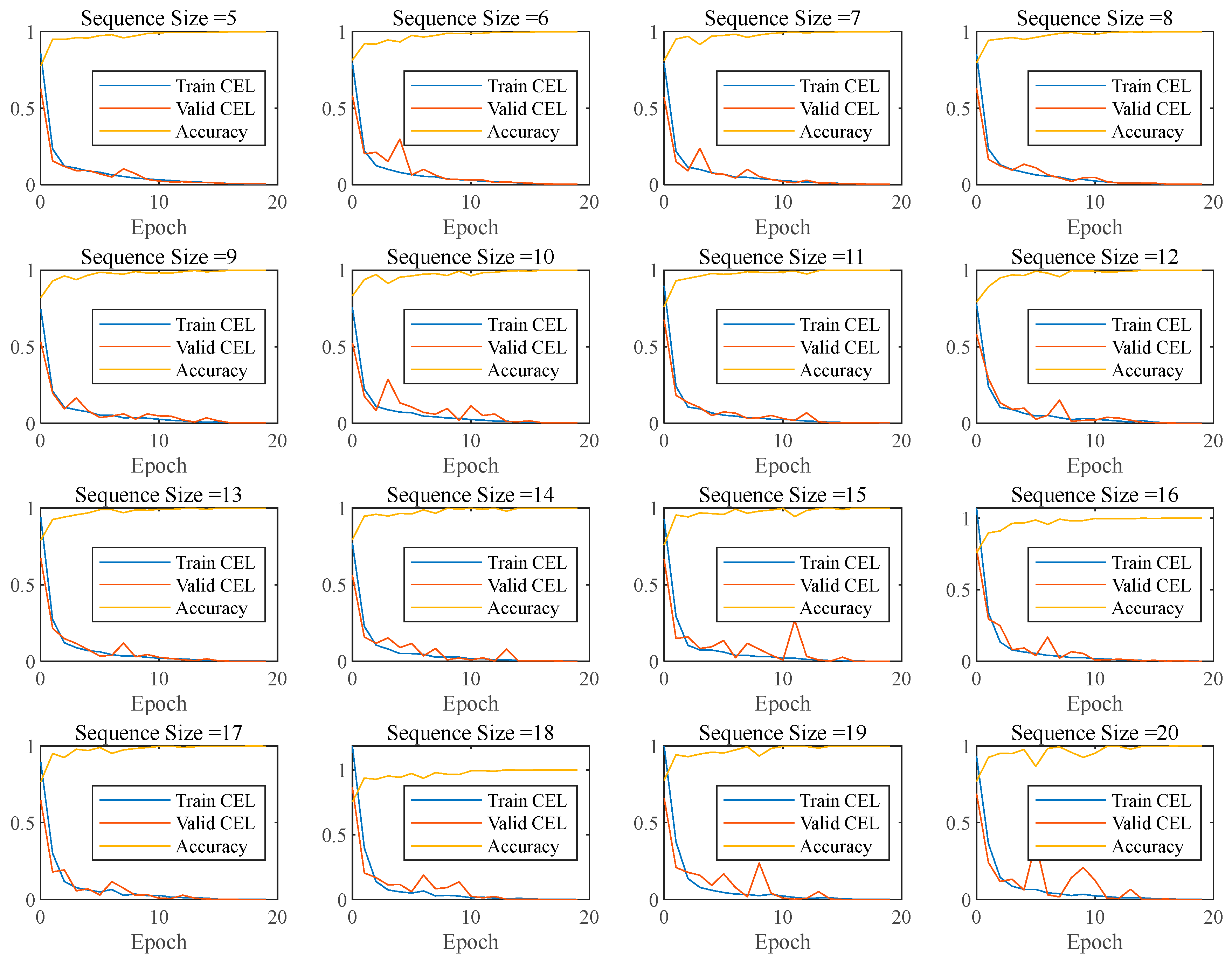
5.2.2. Comparison of Different Sequence Sizes
5.2.3. Comparison of Different Sensitivity Sampling Sizes
5.3. RUL Prediction Case Based on DT and LSTM
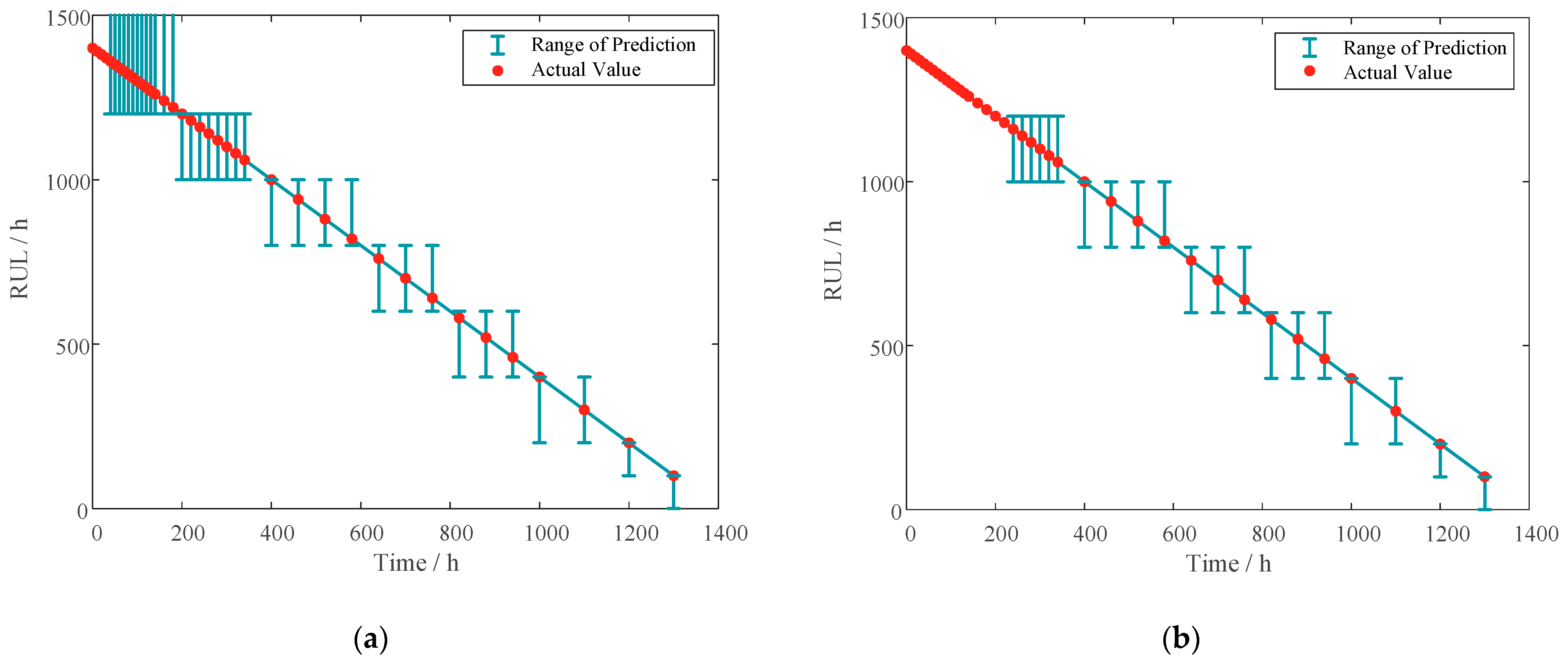
5.3.1. RUL Prediction Based on Single Sample
5.3.2. RUL Prediction Based on Multi-Samples from Sensitivity Sampling
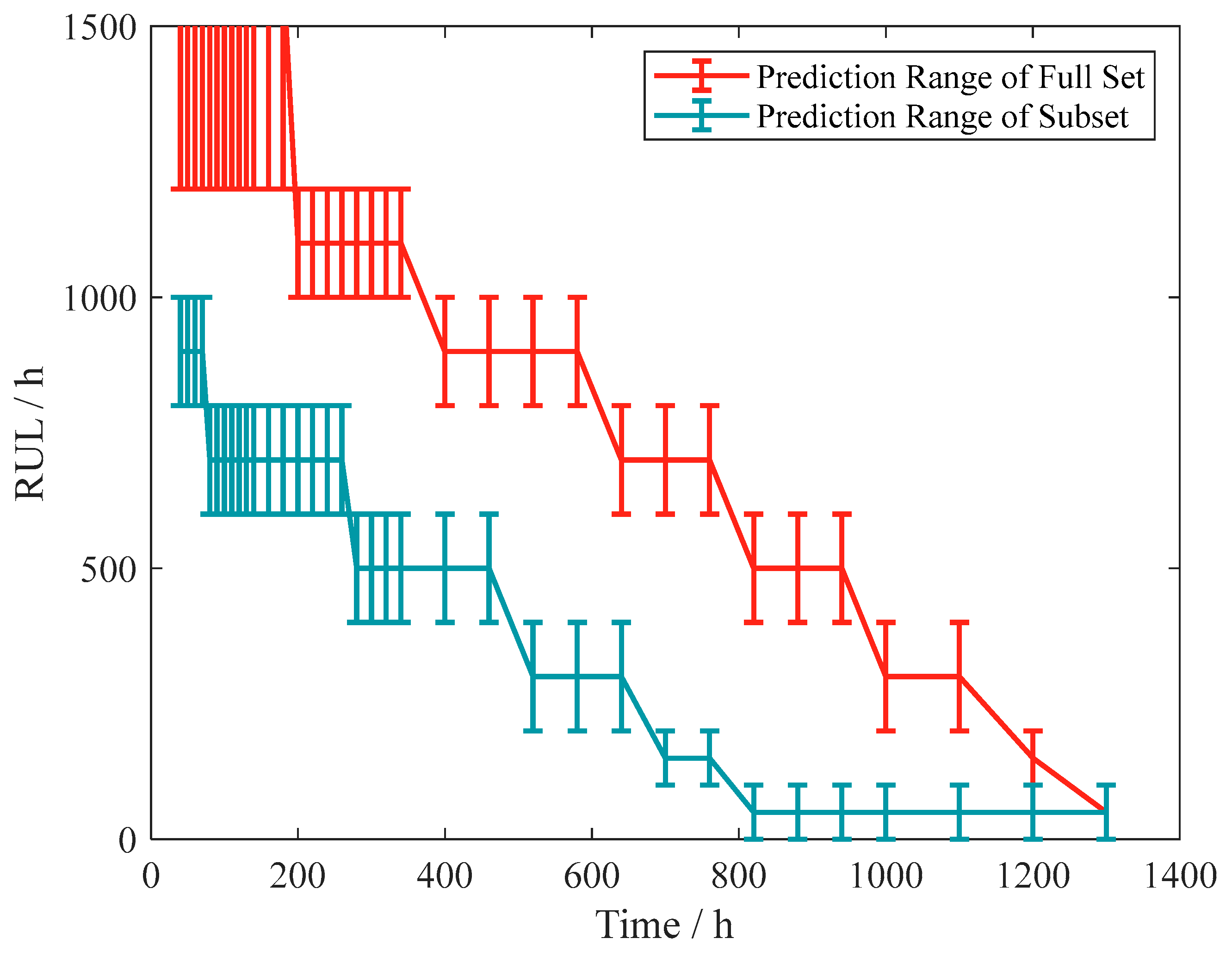
5.3.3. RUL Prediction Based on Samples from Single Failure Mode
6. Conclusions
- The DT framework for PVS is optimized to meet the needs of LSTM-based prediction of RUL, which fully uses PVS features and sample datasets for multiple failure modes. It is verified by PVS degradation tests and training, validation, and prediction of the LSTM network. A method for the RUL prediction of PVS based on DT data and the LSTM network is proposed. It includes the degradation feature data collection method, a sample optimization method based on sliding window and sensitivity distribution data sampling, and a RUL classification and prediction approach. The effectiveness of the method is verified by the degradation test of PVS. Under the experimental real sample set and hardware conditions, the validation set prediction accuracy is above 99.7%, and the total training time is within 94 s.
- The influence of sample set parameters on the prediction effect is discussed through the training and validation of different training sets, including the sequence size, sensitivity sampling size, and failure mode coverage. When the sequence size is increased from 5 to 20, the size of samples is almost halved, the training time is reduced from 94.0 to 48.4 s, the CEL in the training and validation sets decreases by several times, and the validation accuracy keeps improving from 99.79% to 99.99%. As the sensitivity sampling size increases, the CEL of the final epoch decreases significantly, and the accuracy keeps improving. In particular, a sensitivity sampling size of 1000 is big enough for a good prediction.
- The compatibility of the method with different forms of sample and prediction demands is verified by comparing the prediction process for single and multiple samples. The effect of the data source on the prediction effect of the LSTM model was analyzed by comparing the prediction effect of the training set from different failure mode samples. This also validates the compatibility of the present method with different failure modes and partially unfailed degradation data. The proposed RUL prediction method can help deal with degradation sequences with complex feature distribution and utilize the historical degradation data from different failure modes and non-failed samples.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koskoletos, A.O.; Aretakis, N.; Alexiou, A.; Romesis, C.; Mathioudakis, K. Evaluation of Aircraft Engine Gas Path Diagnostic Methods Through ProDiMES. J. Eng. Gas. Turbines Power-Trans. ASME 2018, 140, 12. [Google Scholar] [CrossRef]
- Hunter, G.W.; Wrbanek, J.D.; Okojie, R.S.; Neudeck, P.G.; Fralick, G.C.; Chen, L.Y.; Xu, J.; Beheim, G.M. Development and application of high temperature sensors and electronics for propulsion applications. In Proceedings of the Conference on Sensors for Propulsion Measurement Applications, Kissimmee, FL, USA, 20–21 April 2006. [Google Scholar]
- Kulagin, V.P.; Akimov, D.A.; Pavelyev, S.A.; Potapov, D.A. Automated Identification of Critical Malfunctions of Aircraft Engines Based on Modified Wavelet Transform and Deep Neural Network Clustering. In Proceedings of the Workshop on Materials and Engineering in Aeronautics (MEA), Moscow, Russia, 16–17 October 2019. [Google Scholar]
- Kim, K.; Zhang, S.J.; Salazar, G.; Jiang, X.N. Design, fabrication and characterization of high temperature piezoelectric vibration sensor using YCOB crystals. Sens. Actuator A-Phys. 2012, 178, 40–48. [Google Scholar] [CrossRef]
- Jiang, C.; Liu, X.L.; Yu, F.P.; Zhang, S.J.; Fang, H.R.; Cheng, X.F.; Zhao, X. High-temperature Vibration Sensor Based on Ba2TiSi2O8 Piezoelectric Crystal with Ultra-Stable Sensing Performance up to 650 °C. IEEE Trans. Ind. Electron. 2021, 68, 12850–12859. [Google Scholar] [CrossRef]
- Han, C.Y.; Zhao, C.Y.; Ding, H.; Chen, C. Temperature-insensitive polarimetric vibration sensor. Opt. Lett. 2022, 47, 2714–2717. [Google Scholar] [CrossRef] [PubMed]
- How Vibration Informs the Maintenance of Aircraft Engines. Available online: https://www.aerospacetestinginternational.com/features/how-vibration-data-informs-the-maintenance-of-aircraft-engines.html (accessed on 1 August 2023).
- Yuan, Y.; Liu, X.F.; Ding, S.T.; Pan, B.C. Fault Detection and Location System for Diagnosis of Multiple Faults in Aeroengines. IEEE Access 2017, 5, 17671–17677. [Google Scholar] [CrossRef]
- Trivedi, S.; Ganesh, R.H.; Shen, T.; Huang, P.W.; Li, S.S.; IEEE. Piezoelectric MEMS Vibration Sensor Module for Machining Quality Prediction. In Proceedings of the IEEE Sensors Conference, Rotterdam, The Netherlands, 25–28 October 2020. [Google Scholar]
- Wei, H.F.; Geng, W.P.; Bi, K.X.; Li, T.; Li, X.M.; Qiao, X.J.; Shi, Y.K.; Zhang, H.Y.; Zhao, C.Q.; Xue, G.; et al. High-Performance Piezoelectric-Type MEMS Vibration Sensor Based on LiNbO3 Single-Crystal Cantilever Beams. Micromachines 2022, 13, 329. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Sun, B.; IEEE. Remaining Useful Life Prediction of MEMS Sensors Used in Automotive Under Random Vibration Loading. In Proceedings of the 59th Annual Reliability and Maintainability Symposium (RAMS), Orlando, FL, USA, 28–31 January 2013. [Google Scholar]
- Wang, S.; Jin, S.; Bai, D.; Fan, Y.; Shi, H.; Fernandez, C. A critical review of improved deep learning methods for the remaining useful life prediction of lithium-ion batteries. Energy Rep. 2021, 7, 5562–5574. [Google Scholar] [CrossRef]
- Wang, X.; Ye, P.; Liu, S.; Zhu, Y.; Deng, Y.; Yuan, Y.; Ni, H. Research Progress of Battery Life Prediction Methods Based on Physical Model. Energies 2023, 16, 3858. [Google Scholar] [CrossRef]
- Lei, J.; Zhang, W.; Jiang, Z.; Gao, Z. A Review: Prediction Method for the Remaining Useful Life of the Mechanical System. J. Fail. Anal. Prev. 2022, 22, 2119–2137. [Google Scholar] [CrossRef]
- Salazar, R.; Serrano, M.; Abdelkefi, A. Fatigue in piezoelectric ceramic vibrational energy harvesting: A review. Appl. Energy 2020, 270, 115161. [Google Scholar] [CrossRef]
- Cheng, S.; Pecht, M.; IEEE. A Fusion Prognostics Method for Remaining Useful Life Prediction of Electronic Products. In Proceedings of the IEEE International Conference on Automation Science and Engineering, Bangalore, India, 22–25 August 2009; pp. 102–107. [Google Scholar]
- Fu, C.; Gao, C.; Zhang, W. A Digital-Twin Framework for Predicting the Remaining Useful Life of Piezoelectric Vibration Sensors with Sensitivity Degradation Modeling. Sensors 2023, 23, 8173. [Google Scholar] [CrossRef]
- Kullaa, J. Detection, identification, and quantification of sensor fault in a sensor network. Mech. Syst. Signal Proc. 2013, 40, 208–221. [Google Scholar] [CrossRef]
- Sawant, V.; Deshmukh, R.; Awati, C. Machine learning techniques for prediction of capacitance and remaining useful life of supercapacitors: A comprehensive review. J. Energy Chem. 2023, 77, 438–451. [Google Scholar] [CrossRef]
- Wang, X.-l.; Gu, H.; Xu, L.; Hu, C.; Guo, H. A SVR-Based Remaining Life Prediction for Rolling Element Bearings. J. Fail. Anal. Prev. 2015, 15, 548–554. [Google Scholar] [CrossRef]
- Tian, Z.G. An artificial neural network method for remaining useful life prediction of equipment subject to condition monitoring. J. Intell. Manuf. 2012, 23, 227–237. [Google Scholar] [CrossRef]
- Song, Y.; Gao, S.Y.; Li, Y.B.; Jia, L.; Li, Q.Q.; Pang, F.Z. Distributed Attention-Based Temporal Convolutional Network for Remaining Useful Life Prediction. IEEE Internet Things J. 2021, 8, 9594–9602. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C.; IEEE. Long Short-Term Memory Network for Remaining Useful Life Estimation. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 January 2017; pp. 88–95. [Google Scholar]
- Liao, Y.; Zhang, L.X.; Liu, C.D.; IEEE. Uncertainty Prediction of Remaining Useful Life Using Long Short-Term Memory Network Based on Bootstrap Method. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), Seattle, WA, USA, 11–13 June 2018. [Google Scholar]
- Berghout, T.; Benbouzid, M. A Systematic Guide for Predicting Remaining Useful Life with Machine Learning. Electronics 2022, 11, 1125. [Google Scholar] [CrossRef]
- Ma, J.; Ma, S.; Zhang, H.; Li, R.; Xiao, P. Research on Modeling Method of Crack Propagation Life Prediction for Digital Twin Frame. Mach. Des. Res. 2023, 39, 172–177. [Google Scholar]
- Peng, A.; Ma, Y.; Huang, K.; Wang, L. Digital twin-driven framework for fatigue life prediction of welded structures considering residual stress. Int. J. Fatigue 2024, 181, 108144. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, C.; Fan, B.; Wang, J.; Gu, F.; Peyrano, O.G.; Wang, S.; Lv, D. Research on rolling bearing virtual-real fusion life prediction with digital twin. Mech. Syst. Signal Proc. 2023, 198, 110434. [Google Scholar] [CrossRef]
- Meng, W.; Wang, Y.; Zhang, X.; Li, S.; Bai, X.; Hou, L. Prediction of fault evolution and remaining useful life for rolling bearings with spalling fatigue using digital twin technology. Appl. Intell. 2023, 53, 28611–28626. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Z.; Liu, B.; Sun, Z.; Xu, J. Digital Twin Driven Few-Shot Prediction of Remaining Useful Life for Rotating Machinery. J. Xi’an Jiaotong Univ. 2023, 57, 168–178. [Google Scholar]
- Zhao, W.; Zhang, C.; Wang, J.; Wang, S.; Lv, D.; Qin, F. Research on Digital Twin Driven Rolling Bearing Model-Data Fusion Life Prediction Method. IEEE Access 2023, 11, 48611–48627. [Google Scholar] [CrossRef]
- Cheng, X.; Lv, K.; Zhang, Y.; Wang, L.; Zhao, W.; Liu, G.; Qiu, J. RUL Prediction Method for Electrical Connectors with Intermittent Faults Based on an Attention-LSTM Model. IEEE Trans. Compon. Packag. Manuf. Technol. 2023, 13, 628–637. [Google Scholar] [CrossRef]
- Lyu, G.; Zhang, H.; Miao, Q. Parallel State Fusion LSTM-based Early-cycle Stage Lithium-ion Battery RUL Prediction Under Lebesgue Sampling Framework. Reliab. Eng. Syst. Saf. 2023, 236, 109315. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, N.; Chen, C.; Guo, Y. Adaptive self-attention LSTM for RUL prediction of lithium-ion batteries. Inf. Sci. 2023, 635, 398–413. [Google Scholar] [CrossRef]
- Wu, G.d.; Liu, X.l.; Yu, F.p.; Li, F.l.; Tian, S.w.; Cheng, X.f.; Zhao, X. The Accelerometer Utilizing the Transverse Vibration Mode of LGT Piezoelectric Crystal. In Proceedings of the 13th Symposium on Piezoelectrcity, Acoustic Waves and Device Applications (SPAWDA), Harbin, China, 11–14 January 2019; pp. 1–5. [Google Scholar]
- Chen, X. A novel gear RUL prediction method by diffusion model generation health index and attention guided multi-hierarchy LSTM. Sci. Rep. 2024, 14, 1795. [Google Scholar] [CrossRef] [PubMed]
- Guo, R.; Li, H.; Huang, C. Operation stage division and RUL prediction of bearings based on 1DCNN-ON-LSTM. Meas. Sci. Technol. 2024, 35, 025035. [Google Scholar] [CrossRef]
- Yao, X.; Zhu, J.; Jiang, Q.; Yao, Q.; Shen, Y.; Zhu, Q. RUL prediction method for rolling bearing using convolutional denoising autoencoder and bidirectional LSTM. Meas. Sci. Technol. 2024, 35, 035111. [Google Scholar] [CrossRef]
- Yu, Y.; Hu, C.; Si, X.; Zheng, J.; Zhang, J. Averaged Bi-LSTM networks for RUL prognostics with non-life-cycle labeled dataset. Neurocomputing 2020, 402, 134–147. [Google Scholar] [CrossRef]
- Xu, J.; Liu, B.; Zhou, Y.; Liu, M.; Yao, R.; Shao, Z. Diverse Image Captioning via Conditional Variational Autoencoder and Dual Contrastive Learning. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–16. [Google Scholar] [CrossRef]
- Yang, X.W.; Zhang, A.X.; Zhao, C.R.; Yang, H.X.; Dou, M.F. Categorization of ECG signals based on the dense recurrent network. Signal Image Video Process. 2024, 18, 3373–3381. [Google Scholar] [CrossRef]
- Ignacio, O. tsai—A State-of-the-Art Deep Learning Library for Time Series and Sequential Data. Available online: https://github.com/timeseriesAI/tsai (accessed on 9 October 2023).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RUL Prediction Method | Failure Mechanism | Data-Driven | Fusion Method | |
|---|---|---|---|---|
| Statistical Model-Based | ML-Based | |||
| Characteristic | insight | clear distribution range | massive calculation | complex |
| Failure mode | specific | specific | most | undetermined |
| Sample quantity | few | few | more | undetermined |
| For PVS | failure mechanism not clear | only for sensitivity degradation | insufficient training data set | undetermined |
| Conclusion | difficult | operable | operable | more difficult |
| RUL Prediction Based on | LSTM | DT and Degradation Modeling (Previous Paper) | DT and LSTM (This Paper) |
|---|---|---|---|
| Failure mode | no need | single | no need |
| other need | sequence data | degradation data characteristics | Sensitivity distribution acquisition |
| Computation amount | large | small | large |
| Sample size | large | small | sensitivity distribution sampling to increase |
| Suitable object | Li battery, ball bearing, complex equipment, but no studies for PVS | PVS, depends on the degradation data distribution characteristics | PVS, devices with complex feature distribution |
| Feature | Variable | Unit |
|---|---|---|
| Time | t | h |
| Temperature | T | K |
| Pressure | P | N |
| Frequency of vibration | f | Hz |
| Acceleration of vibration | a | m·s−2 |
| Sensitivity | s | pC m−1·s2 |
| NO. | f/Hz | a/g | NO. | f/Hz | a/g | NO. | f/Hz | a/g |
|---|---|---|---|---|---|---|---|---|
| 1 | 100 | 2 | 11 | 2000 | 2 | 21 | 20 | 10 |
| 2 | 100 | 4 | 12 | 2000 | 4 | 22 | 40 | 10 |
| 3 | 100 | 6 | 13 | 2000 | 6 | 23 | 80 | 10 |
| 4 | 100 | 8 | 14 | 2000 | 8 | 24 | 160 | 10 |
| 5 | 100 | 10 | 15 | 2000 | 10 | 25 | 315 | 10 |
| 6 | 100 | 12 | 16 | 2000 | 12 | 26 | 630 | 10 |
| 7 | 100 | 14 | 17 | 2000 | 14 | 27 | 1250 | 10 |
| 8 | 100 | 16 | 18 | 2000 | 16 | 28 | 2000 | 10 |
| 9 | 100 | 18 | 19 | 2000 | 18 | |||
| 10 | 100 | 20 | 20 | 2000 | 20 |
| Device | Parameters |
|---|---|
| High-temperature test chamber | LIGAO HF-100FN, 300 K~600 K |
| Vibration exciter | SINOCERA JZK-20, 200 N, 30 g |
| Power supply | SINOCERA YE5874, 810 W |
| Waveform generator | KEYSIGHT 33500B, 30 MHz, 5 V |
| Standard VPS | Endevco 6222S-20A, 200 mV/g |
| Charge amplifier | Endevco 2777A-10-10, 10 Hz~10 kHz |
| Host computer | ThinkStation P350, Intel i7 11700 |
| DAQ card | NI Compact DAQ 9232, 3 channel, 102.4 kS/s/ch |
| PVS Number | Temperature/K |
|---|---|
| A1 and A2 | 523.15 |
| B1 and B2 | 493.15 |
| C1 and C2 | 473.15 |
| D1 and D2 | 448.15 |
| E1 and E2 | 423.15 |
| PVS Number | Failure Time/h | Failure Modes |
|---|---|---|
| A1 | 240 | output short circuit |
| A2 | 600 | sensitivity out-of-tolerance |
| B1 | 1400 | output open circuit |
| B2 | 880 | sensitivity out-of-tolerance |
| C1 | >3000 | - |
| C2 | 1400 | sensitivity out-of-tolerance |
| D1 | >3000 | - |
| D2 | 200 | output open circuit |
| E1 | >3000 | - |
| E2 | >3000 | - |
| Sequence Size | Samples | Training Samples | Testing Samples |
|---|---|---|---|
| 5 | 289,000 | 202,300 | 86,700 |
| 6 | 279,000 | 195,300 | 83,700 |
| 7 | 269,000 | 188,300 | 80,700 |
| 8 | 260,000 | 182,000 | 78,000 |
| 9 | 251,000 | 175,700 | 75,300 |
| 10 | 242,000 | 169,400 | 72,600 |
| 11 | 233,000 | 163,100 | 69,900 |
| 12 | 224,000 | 156,800 | 67,200 |
| 13 | 215,000 | 150,500 | 64,500 |
| 14 | 206,000 | 144,200 | 61,800 |
| 15 | 197,000 | 137,900 | 59,100 |
| 16 | 188,000 | 131,600 | 56,400 |
| 17 | 179,000 | 125,300 | 53,700 |
| 18 | 170,000 | 119,000 | 51,000 |
| 19 | 162,000 | 113,400 | 48,600 |
| 20 | 154,000 | 107,800 | 46,200 |
| Classification | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| RUL Range/h | (0, 100] | (100, 200] | (200, 400] | (400, 600] | (600, 800] | (800, 1000] | (1000, 1200] | (1200, +∞) |
| Sequence Size | Training Time/s | Train CEL | Valid CEL | Accuracy/% |
|---|---|---|---|---|
| 5 | 93.95805931 | 0.004598 | 0.006693 | 99.786 |
| 6 | 87.52612972 | 0.003087 | 0.004678 | 99.857 |
| 7 | 85.31973052 | 0.002984 | 0.004185 | 99.887 |
| 8 | 84.82289147 | 0.002089 | 0.003432 | 99.905 |
| 9 | 78.97516322 | 0.00206 | 0.002597 | 99.938 |
| 10 | 73.74387383 | 0.002939 | 0.002127 | 99.964 |
| 11 | 73.66227794 | 0.00157 | 0.001924 | 99.961 |
| 12 | 70.45144176 | 0.00189 | 0.001249 | 99.978 |
| 13 | 67.65879798 | 0.001438 | 0.001075 | 99.980 |
| 14 | 66.34648776 | 0.001964 | 0.000739 | 99.985 |
| 15 | 58.13756585 | 0.000953 | 0.000787 | 99.983 |
| 16 | 60.89499235 | 0.001465 | 0.00081 | 99.991 |
| 17 | 59.87257957 | 0.001182 | 0.000621 | 99.989 |
| 18 | 57.55060816 | 0.001325 | 0.000511 | 99.996 |
| 19 | 55.03493381 | 0.001172 | 0.000498 | 99.996 |
| 20 | 48.43837452 | 0.00144 | 0.000709 | 99.994 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, C.; Gao, C.; Zhang, W. RUL Prediction for Piezoelectric Vibration Sensors Based on Digital-Twin and LSTM Network. Mathematics 2024, 12, 1229. https://doi.org/10.3390/math12081229
Fu C, Gao C, Zhang W. RUL Prediction for Piezoelectric Vibration Sensors Based on Digital-Twin and LSTM Network. Mathematics. 2024; 12(8):1229. https://doi.org/10.3390/math12081229
Chicago/Turabian StyleFu, Chengcheng, Cheng Gao, and Weifang Zhang. 2024. "RUL Prediction for Piezoelectric Vibration Sensors Based on Digital-Twin and LSTM Network" Mathematics 12, no. 8: 1229. https://doi.org/10.3390/math12081229
APA StyleFu, C., Gao, C., & Zhang, W. (2024). RUL Prediction for Piezoelectric Vibration Sensors Based on Digital-Twin and LSTM Network. Mathematics, 12(8), 1229. https://doi.org/10.3390/math12081229