
Pedestrian Gender Recognition by Style Transfer of Visible-Light Image to Infrared-Light Image Based on an Attention-Guided Generative Adversarial Network



Abstract
:1. Introduction
- -
- For improving gender recognition performance, we propose SI-AGAN, which transfers the style of the visible-light image to resemble that of an IR image. Existing multimodal camera-based methods required both a visible-light image and an IR image during training and testing. In this study, however, an IR image is not required during testing as the IR image generated by SI-AGAN is used.
- -
- We reduced the computational cost of the SI-AGAN by revising convolutional layers of the attention module, attention-guided generator, and attention-guided discriminator of the original attention-guided generative adversarial network (AGGAN) to a depthwise separable convolution layer.
- -
- Furthermore, the quality of generated images and the gender recognition performance were improved by applying a perceptual loss in SI-AGAN. Moreover, the matching score obtained through the residual network (ResNet)-101, trained with a visible-light image and the syn-IR image generated by SI-AGAN, was applied with score-level fusion based on a support vector machine (SVM) to improve gender recognition performance.
- -
- Our trained SI-AGAN models and the generated syn-IR dataset are disclosed through [12] for a fair performance evaluation by other researchers.
2. Related Work
2.1. Handcrafted Feature-Based Methods
2.2. Deep Feature-Based Methods
2.2.1. CNN-Based Methods
2.2.2. CNN and GAN-Based Methods
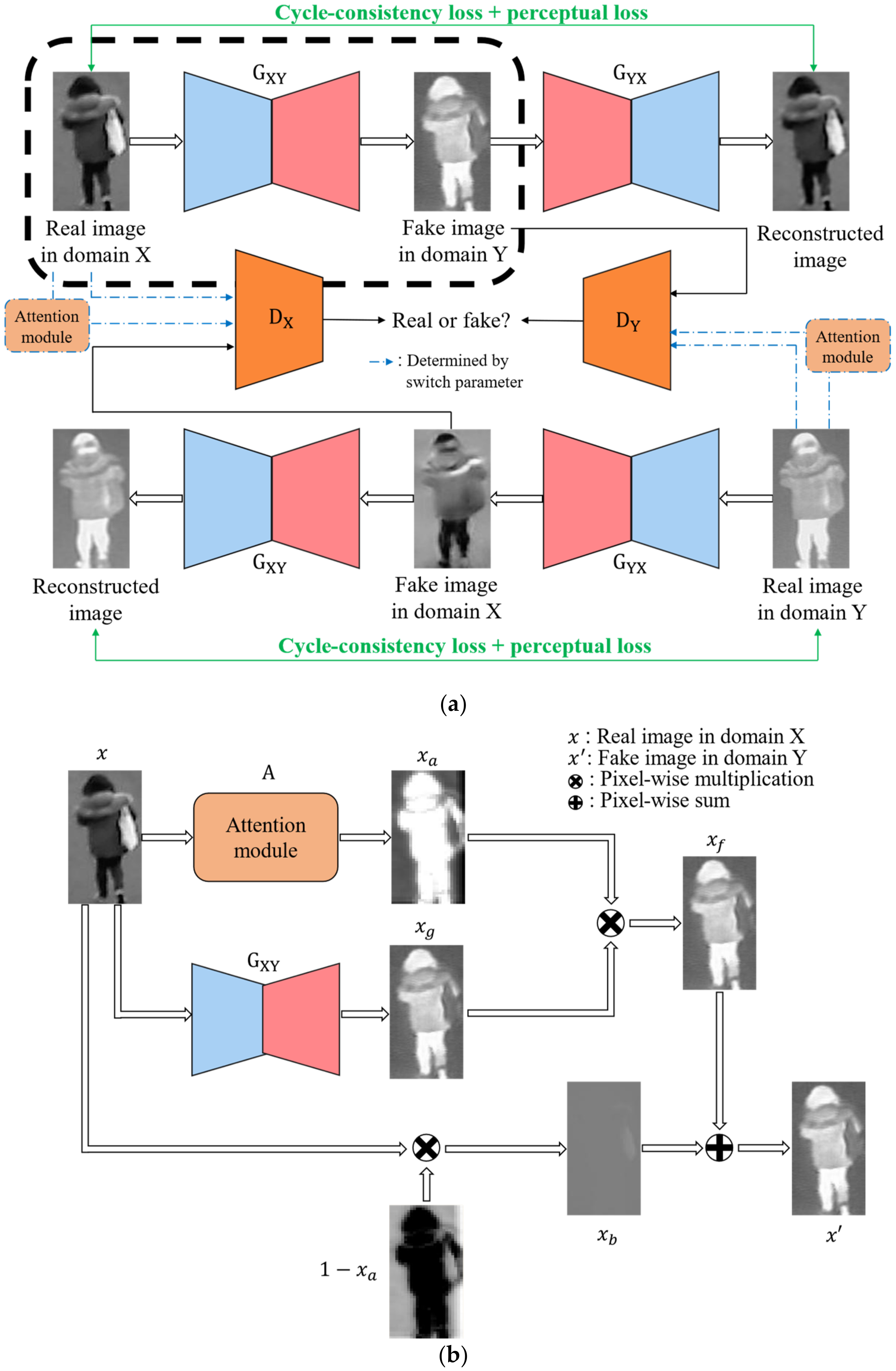
3. Proposed Method
3.1. Overview of the Proposed Method
| Algorithm 1 The proposed method detailed by using pseudo code |
| Input visible-light image: Input reconstructed image: R Input synthesized image: S Output score obtained from reconstructed image: Output score obtained from synthesized image: N Final output score: Z 2-step image reconstruction model = SI-AGAN model = s_ Gender recognition CNN model = g_ SVM classifier = |
| Algorithm procedure |
3.2. 2-Step Image Reconstruction
3.3. SI-AGAN
3.3.1. Attention-Guided Generator Architecture
3.3.2. Attention-Guided Discriminator Architecture
3.3.3. Loss Function of SI-AGAN
3.3.4. Differences between the Proposed SI-AGAN and Original AGGAN
- -
- In the original AGGAN, a square image is used as an input. However, body shapes and body proportions of males and females provide critical information regarding gender recognition. Therefore, the proposed SI-AGAN was trained using vertically long rectangular input images instead of square images.
- -
- To reduce the computational cost, certain convolutional layers of the original AGGAN were revised to depthwise separable convolutional layers in the SI-AGAN. The revised convolutional layers are the entire convolutional layers of the residual blocks in the attention module, second and third convolutional layers of the attention-guided generator, entire convolutional layers of the residual blocks in the attention-guided generator, and second and third convolutional layers of the attention-guided discriminator.
- -
- Finally, VGG Net-19-based perceptual loss was applied between the input image and the reconstructed image in SI-AGAN. While training the SI-AGAN, pixels of the images on the same domain and the quality of the image generated by considering the difference in feature maps were improved, thus enhancing the gender recognition performance.
3.4. CNN and Score-Level Fusion for Gender Recognition
4. Experimental Results
4.1. Experimental Database and Environment
4.2. Training of SI-AGAN and CNN Models
4.3. Testing of SI-AGAN and CNN Models with RegDB
4.3.1. Ablation Studies
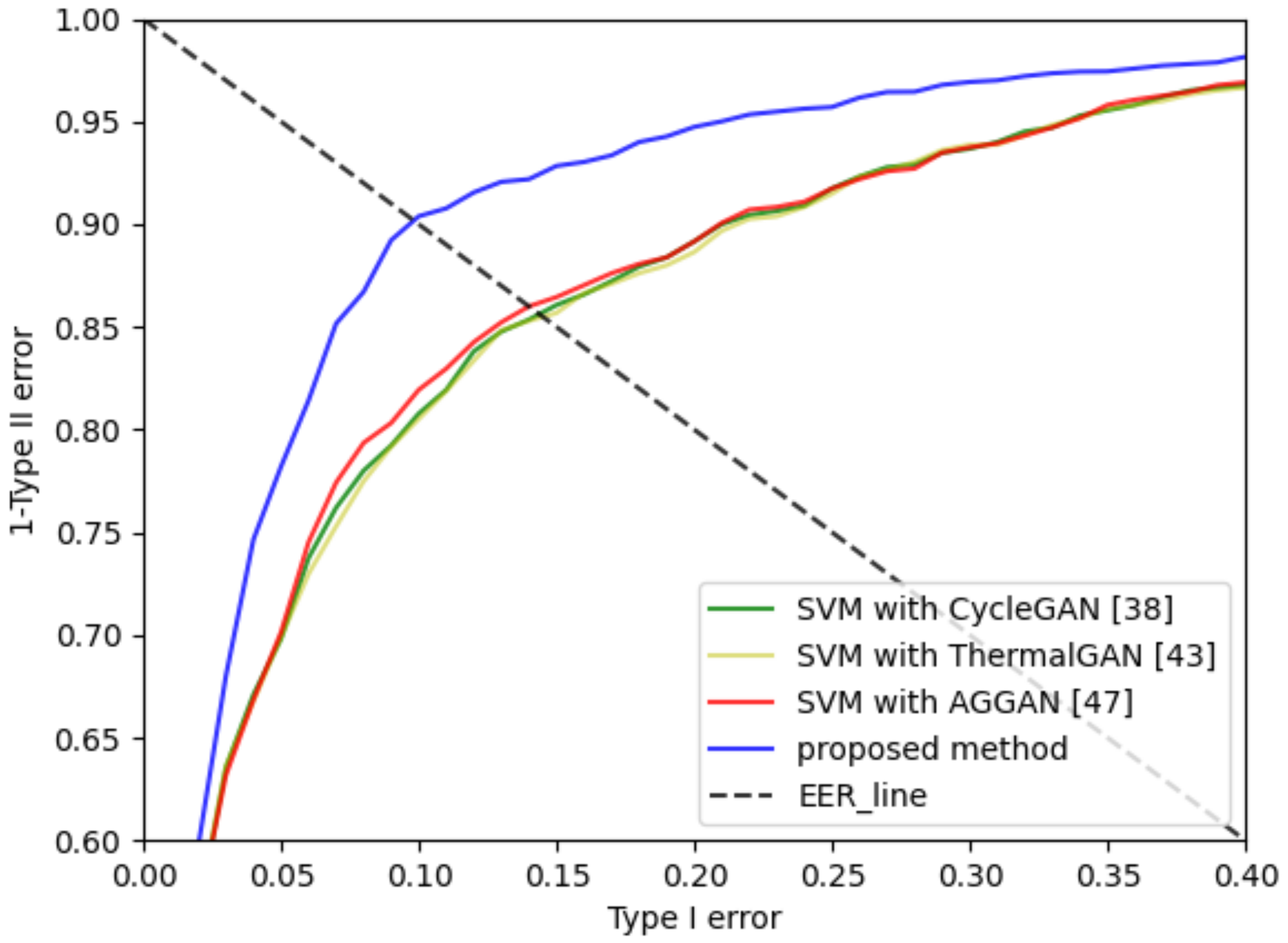
4.3.2. Comparative Experiments of SI-AGAN with the State-of-the-Art Methods for Style Transfer
4.3.3. Recognition Accuracies Based on Score-Level Fusion and Comparisons with State-of-the-Art Methods
4.4. Testing of SI-AGAN and CNN Models with SYSU-MM01
4.4.1. Ablation Studies
4.4.2. Recognition Accuracies Based on Score-Level Fusion and Comparisons with State-of-the-Art Methods
4.5. Computational Cost and Processing Time
4.5.1. Computational Cost
4.5.2. Processing Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. A review of facial gender recognition. Pattern Anal. Appl. 2015, 18, 739–755. [Google Scholar] [CrossRef]
- Yu, S.; Tan, T.; Huang, K.; Jia, K.; Wu, X. A study on gait-based gender classification. IEEE Trans. Image Process. 2009, 18, 1905–1910. [Google Scholar] [PubMed]
- Patua, R.; Muchhal, T.; Basu, S. Gait-based person identification, gender classification, and age estimation: A review. Prog. Adv. Comput. Intell. Eng. 2021, 1198, 62–74. [Google Scholar]
- Cao, L.; Dikmen, M.; Fu, Y.; Huang, T.S. Gender recognition from body. In Proceedings of the 16th ACM international Conference on Multimedia, Vancouver, BC, Canada, 26–31 October 2008; pp. 725–728. [Google Scholar]
- Collins, M.; Zhang, J.; Miller, P.; Wang, H. Full Body Image Feature Representations for Gender Profiling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1235–1242. [Google Scholar]
- Bourdev, L.; Maji, S.; Malik, J. Describing People: A Poselet-Based Approach to Attribute Classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1543–1550. [Google Scholar]
- Guo, G.; Mu, G.; Fu, Y. Gender from Body: A Biologically-Inspired Approach with Manifold Learning. In Proceedings of the Asian Conference on Computer Vision, Xi’an, China, 23–27 September 2009; pp. 236–245. [Google Scholar]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. A Convolutional Neural Network for Pedestrian Gender Recognition. In Proceedings of the International Symposium on Neural Networks, Dalian, China, 4–6 July 2013; pp. 558–564. [Google Scholar]
- Antipov, G.; Berrani, S.-A.; Ruchaud, N.; Dugelay, J.-L. Learned vs. Hand-Crafted Features for Pedestrian Gender Recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1263–1266. [Google Scholar]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. Pedestrian gender classification using combined global and local parts-based convolutional neural networks. Pattern Anal. Appl. 2019, 22, 1469–1480. [Google Scholar] [CrossRef]
- Baek, N.R.; Cho, S.W.; Koo, J.H.; Truong, N.Q.; Park, K.R. Multimodal camera-based gender recognition using human-body image with two-step reconstruction network. IEEE Access 2019, 7, 104025–104044. [Google Scholar] [CrossRef]
- Attention-Guided GAN for Synthesizing Infrared Image (SI-AGAN) and Syn-IR Datasets. Available online: http://dm.dgu.edu/link.html (accessed on 24 August 2021).
- Althnian, A.; Aloboud, N.; Alkharashi, N.; Alduwaish, F.; Alrshoud, M.; Kurdi, H. Face gender recognition in the wild: An extensive performance comparison of deep-learned, hand-crafted, and fused features with deep and traditional models. Appl. Sci. 2021, 11, 89. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Joachims, T. Making Large-Scale Support Vector Machine Learning Practical, Advances in Kernel Methods. Support Vector Learning. 1999. Available online: https://ci.nii.ac.jp/naid/10011961265/en/ (accessed on 1 October 2021).
- Webb, A.R. Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Zhang, H.-J. Orthogonal laplacianfaces for face recognition. IEEE Trans. Image Process. 2006, 15, 3608–3614. [Google Scholar]
- Cai, D.; He, X.; Zhou, K.; Han, J.; Bao, H. Locality Sensitive Discriminant Analysis. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 708–713. [Google Scholar]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.-J.; Yang, Q.; Lin, S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 29, 40–51. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.T.; Park, K.R. Body-based gender recognition using images from visible and thermal cameras. Sensors 2016, 16, 156. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.T.; Park, K.R. Enhanced gender recognition system using an improved histogram of oriented gradient (HOG) feature from quality assessment of visible light and thermal images of the human body. Sensors 2016, 16, 1134. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the 2012 Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Raza, M.; Sharif, M.; Yasmin, M.; Khan, M.A.; Saba, T.; Fernandes, S.L. Appearance based pedestrians’ gender recognition by employing stacked auto encoders in deep learning. Futur. Gener. Comp. Syst. 2018, 88, 28–39. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, J.; Zeng, H.; Chen, J.; Cai, C.; Ma, K.-K. HOG-assisted deep feature learning for pedestrian gender recognition. J. Frankl. Inst. 2018, 355, 1991–2008. [Google Scholar] [CrossRef]
- Fayyaz, M.; Yasmin, M.; Sharif, M.; Raza, M. J-LDFR: Joint low-level and deep neural network feature representations for pedestrian gender classification. Neural Comput. Appl. 2020, 33, 1–31. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person Re-Identification by Local Maximal Occurrence Representation and Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian attribute recognition: A survey. Pattern Recognit. 2021, 121, 108220. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Kim, K.W.; Hong, H.G.; Koo, J.H.; Kim, M.C.; Park, K.R. Gender recognition from human-body images using visible-light and thermal camera videos based on a convolutional neural network for image feature extraction. Sensors 2017, 17, 637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Cai, L.; Zeng, H.; Zhu, J.; Cao, J.; Wang, Y.; Ma, K.-K. Cascading Scene and Viewpoint Feature Learning for Pedestrian Gender Recognition. IEEE Internet Things J. 2020, 8, 3014–3026. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Hi-CMD. Available online: https://github.com/bismex/HiCMD (accessed on 24 August 2021).
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-infrared Cross-Modality Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Vedaldi, A.; Lenc, K. MatConvNet—Convolutional Neural Networks for MATLAB. In Proceedings of the ACM International Conference on Multimedia, Shanghai, China, 23–26 June 2015. [Google Scholar]
- Tensorflow: The Python Deep Learning Library. Available online: https://www.tensorflow.org/ (accessed on 24 August 2021).
- NVIDIA GeForce GTX 1070 Card. Available online: https://www.nvidia.com/en-in/geforce/products/10series/geforce-gtx-1070/ (accessed on 24 August 2021).
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal Color-to-Thermal Image Translation for Person Re-Identification in Multispectral Dataset. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mejjati, Y.A.; Richardt, C.; Tompkin, J.; Cosker, D.; Kim, K.I. Unsupervised attention-guided image to image translation. arXiv 2018, arXiv:1806.02311. [Google Scholar]
- Livingston, E.H. Who was student and why do we care so much about his t-test? J. Surg. Res. 2004, 118, 58–65. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155–159. [Google Scholar] [CrossRef] [PubMed]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 24 August 2021).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Advantage | Disadvantage | ||
|---|---|---|---|---|
| Handcrafted feature | HOG [4] | Effectively extracts HOG features by segmenting a pedestrian image into patches | Limited recognition performance from not using color information of a person | |
| PiHOG + LSHV [5] | The color feature is used to effectively extract gender features | Gender recognition cannot be performed using back or side view images | ||
| Poselets [6] | Robust to occlusion images by using a part-based method | Requires heavily annotated information | ||
| BIFs [7] | View classification is performed through BIFs with manifold learning and gender recognition is performed for each view | No performance available for side view | ||
| Multimodal Camera-based HOG [22,23] | Visible-light image and thermal image are combined after applying HOG or weighted HOG | Less accurate recognition because of low-resolution images captured from a far distance | ||
| Deep feature | CNN | CNN [8] | Similar or better performance than a handcrafted feature with simple architecture | Cannot exhibit high performance improvement due to a simple architecture |
| Mini-CNN [9] | Excellent performance in heterogeneous datasets compared to handcrafted features | Similar performance as a handcrafted feature in a homogeneous dataset | ||
| Global CNN + local CNN [10] | More discriminative features can be obtained by separately training the global region and local region | Complicated due to the use of four CNNs and can only be applied to a whole image | ||
| SSAE [27] | Performance is improved by using a pedestrian image in which the background is removed through preprocessing | Limited recognition performance as color information, which is an important factor | ||
| Handcrafted feature + CNN [28,29] | The discriminative features can be obtained by combining low-level and high-level features | Limited recognition performance due to various factor as only a visible-light image is used | ||
| Multimodal Camera-based CNN [11,33] | Less affected by background, lighting changes, clothing type, and accessories because visible-light image and thermal image are combined | Time-consuming since a CNN is applied to the visible-light image and IR image separately | ||
| CNN + GAN | KPT-GAN [35] | Robust to scene variation as KTP-GAN that performs scene transfer for the background is used | Numerous artifacts exist, and the scene transferred background region is noisier than the actual background | |
| SI-AGAN (Proposed method) | Recognition performance is improved by combining reconstructed visible-light images with the syn-IR image generated by the proposed SI-AGAN to be similar as an IR image | Two-step image reconstruction and GAN are time-consuming | ||
| Layer Type | Number of Filters | Size of Feature Map (Width × Height × Channel) | Size of Kernel (Width × Height) | Number of Stride | Number of Padding |
|---|---|---|---|---|---|
| Input layer [image] | W × H × 3 | ||||
| 1-D Conv 1 (ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| 2-D Conv 2 (Bnorm + ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 2 × 2 |
| 3-D Conv 3 (Bnorm + ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 3 × 3 |
| 4-D Conv 4 (Bnorm + ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 4 × 4 |
| 3-D Conv 5 (Bnorm + ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 3 × 3 |
| 2-D Conv 6 (Bnorm + ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 2 × 2 |
| 1-D Conv 7 | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Layer Type | Number of Filters | Size of Feature Map (Width × Height × Channel) | Size of Kernel (Width × Height) | Number of Stride | Number of Padding |
|---|---|---|---|---|---|
| Input layer [image] | W × H × 3 | ||||
| Conv N* (ReLU) | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Conv 20 | 64 | W × H × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Layer Type | Number of Filters | Size of Feature Map (Width × Height × Channel) | Size of Kernel (Width × Height) | Number of Stride | Number of Padding (Top, Left, Bottom, Right) | |
|---|---|---|---|---|---|---|
| Input layer | 224 × 100 × 3 | |||||
| Padding | 229 × 105 × 3 | (2, 2, 3, 3) | ||||
| Conv 1 (IN + ReLU) | 32 | 112 × 50 × 32 | 7 × 7 | 2 × 2 | ||
| Conv 2 (IN + ReLU) | 64 | 56 × 25 × 64 | 3 × 3 | 2 × 2 | (0, 0, 1, 1) | |
| Residual block | Padding | 58 × 27 × 64 | (1, 1, 1, 1) | |||
| DWConv (IN + ReLU) | 64 | 56 × 25 × 64 | 3 × 3 | 1 × 1 | ||
| Padding | 58 × 27 × 64 | (1, 1, 1, 1) | ||||
| DWConv (IN + ReLU) | 64 | 56 × 25 × 64 | 3 × 3 | 1 × 1 | ||
| Add | 56 × 25 × 64 | |||||
| Upsampling layer | 112 × 50 × 64 | |||||
| Conv 3 (IN + ReLU) | 64 | 112 × 50 × 64 | 3 × 3 | 1 × 1 | (1, 1, 1, 1) | |
| Upsampling layer | 224 × 100 × 64 | |||||
| Conv 4 (IN + ReLU) | 32 | 224 × 100 × 32 | 3 × 3 | 1 × 1 | (1, 1, 1, 1) | |
| Conv 5 (IN) | 1 | 224 × 100 × 1 | 7 × 7 | 1 × 1 | (3, 3, 3, 3) | |
| Sigmoid layer | 224 × 100 × 1 | |||||
| Layer Type | Number of Filters | Size of Feature Map (Width × Height × Channel) | Size of Kernel (Width × Height) | Number of Stride | Number of Padding (Top, Left, Bottom, Right) | |
|---|---|---|---|---|---|---|
| Input layer | 224 × 100 × 3 | |||||
| Padding | 230 × 106 × 3 | (3, 3, 3, 3) | ||||
| Conv 1 (IN + ReLU) | 32 | 224 × 100 × 32 | 7 × 7 | 1 × 1 | ||
| DWConv1 (IN + ReLU) | 64 | 112 × 50 × 64 | 3 × 3 | 2 × 2 | (0, 0, 1, 1) | |
| DWConv2 (IN + ReLU) | 128 | 56 × 25 × 128 | 3 × 3 | 2 × 2 | (0, 0, 1, 1) | |
| Residual block N* | Padding | 58 × 27 × 128 | (1, 1, 1, 1) | |||
| DWConv (IN + ReLU) | 128 | 56 × 25 × 128 | 3 × 3 | 1 × 1 | ||
| Padding | 58 × 27 × 128 | (1, 1, 1, 1) | ||||
| DWConv (IN + ReLU) | 128 | 56 × 25 × 128 | 3 × 3 | 1 × 1 | ||
| Add | 56 × 25 × 128 | |||||
| TransConv1 (IN + ReLU) | 64 | 112 × 50 × 64 | 3 × 3 | 2 × 2 | (1, 1, 1, 1) | |
| TransConv2 (IN + ReLU) | 32 | 224 × 100 × 32 | 3 × 3 | 2 × 2 | (1, 1, 1, 1) | |
| Conv 2 + Tanh | 3 | 224 × 100 × 3 | 7 × 7 | 1 × 1 | (3, 3, 3, 3) | |
| Layer Type | Number of Filters | Size of Feature Map (Width × Height × Channel) | Size of Kernel (Width × Height) | Number of Stride | Number of Padding (Top, Left, Bottom, Right) |
|---|---|---|---|---|---|
| Input layer | 224 × 100 × 3 | ||||
| Padding | 228 × 104 × 3 | (2, 2, 2, 2) | |||
| Conv 1 (IN* + LReLU) | 64 | 113 × 51 × 64 | 4 × 4 | 2 × 2 | |
| Padding | 116 × 54 × 64 | (1, 1, 2, 2) | |||
| DWConv 1 (IN* + LReLU) | 128 | 57 × 26 × 128 | 4 × 4 | 2 × 2 | |
| Padding | 60 × 30 × 128 | (1, 2, 2, 2) | |||
| DWConv 2 (IN* + LReLU) | 256 | 29 × 14 × 256 | 4 × 4 | 2 × 2 | |
| Padding | 33 × 18 × 256 | (2, 2, 2, 2) | |||
| Conv 2 (IN* + LReLU) | 512 | 30 × 15 × 512 | 4 × 4 | 1 × 1 | |
| Padding | 34 × 19 × 512 | (2, 2, 2, 2) | |||
| Output layer (Conv) | 1 | 31 × 16 × 1 | 4 × 4 | 1 × 1 |
| Database | RegDB | SYSU-MM01 | |||
|---|---|---|---|---|---|
| Subset | Training | Test | Training | Validation | Testing |
| Number of people (male/female) | 331 (204/127) | 81 (50/31) | 295 (154/141) | 96 (58/38) | 99 (63/36) |
| Number of images (male/female) | 3310 (2040/1270) | 810 (500/310) | 9819 (5190/4629) | 1949 (1259/690) | 3727 (2283/1444) |
| Methods | 5-Fold Cross Validation | EER (%) | |
|---|---|---|---|
| 1~5 Fold | Average | ||
| Original image | 1 fold | 16.78 | 19.54 |
| 2 fold | 22.32 | ||
| 3 fold | 23.21 | ||
| 4 fold | 19.01 | ||
| 5 fold | 16.42 | ||
| Original image + IRCNN [36] | 1 fold | 24.81 | 24.25 |
| 2 fold | 23.73 | ||
| 3 fold | 25.96 | ||
| 4 fold | 22.59 | ||
| 5 fold | 24.19 | ||
| Original image + VDSR [37] | 1 fold | 13.73 | 18.75 |
| 2 fold | 19.57 | ||
| 3 fold | 20.46 | ||
| 4 fold | 20.98 | ||
| 5 fold | 19.01 | ||
| Original image + IRCNN + VDSR (proposed method) | 1 fold | 14.09 | 15.07 |
| 2 fold | 18.65 | ||
| 3 fold | 14.09 | ||
| 4 fold | 14.45 | ||
| 5 fold | 14.09 | ||
| Methods | 5-Fold Cross Validation | EER (%) | |
|---|---|---|---|
| 1~5 Fold | Average | ||
| SI-AGAN without perceptual loss and depthwise separable convolution | 1 fold | 14.55 | 19.01 |
| 2 fold | 16.62 | ||
| 3 fold | 24.61 | ||
| 4 fold | 19.21 | ||
| 5 fold | 20.10 | ||
| SI-AGAN with perceptual loss | 1 fold | 24.45 | 20.99 |
| 2 fold | 18.39 | ||
| 3 fold | 25.08 | ||
| 4 fold | 21.86 | ||
| 5 fold | 15.18 | ||
| SI-AGAN with depthwise separable convolution | 1 fold | 18.65 | 20.74 |
| 2 fold | 17.67 | ||
| 3 fold | 23.83 | ||
| 4 fold | 18.49 | ||
| 5 fold | 25.08 | ||
| SI-AGAN with perceptual loss and depthwise separable convolution (proposed method) | 1 fold | 18.03 | 17.65 |
| 2 fold | 14.45 | ||
| 3 fold | 19.37 | ||
| 4 fold | 19.27 | ||
| 5 fold | 17.14 | ||
| Methods | 5-Fold Cross Validation | EER (%) | |
|---|---|---|---|
| 1~5 Fold | Average | ||
| CycleGAN [38] | 1 fold | 21.18 | 19.37 |
| 2 fold | 17.67 | ||
| 3 fold | 20.62 | ||
| 4 fold | 20.52 | ||
| 5 fold | 16.88 | ||
| ThermalGAN [46] | 1 fold | 26.42 | 24.57 |
| 2 fold | 28.61 | ||
| 3 fold | 20.16 | ||
| 4 fold | 27.20 | ||
| 5 fold | 20.46 | ||
| AGGAN [47] | 1 fold | 14.55 | 19.01 |
| 2 fold | 16.62 | ||
| 3 fold | 24.61 | ||
| 4 fold | 19.21 | ||
| 5 fold | 20.10 | ||
| SI-AGAN | 1 fold | 18.03 | 17.65 |
| 2 fold | 14.45 | ||
| 3 fold | 19.37 | ||
| 4 fold | 19.27 | ||
| 5 fold | 17.14 | ||
| Methods | 5-Fold Cross Validation | EER (%) | |
|---|---|---|---|
| 1~5 Fold | Average | ||
| Visible-light image (+IRCNN+VDSR) + syn-IR image (CycleGAN) [38] | 1 fold | 14.31 | 13.63 |
| 2 fold | 19.74 | ||
| 3 fold | 18.35 | ||
| 4 fold | 14.77 | ||
| 5 fold | 1.00 | ||
| Visible-light image (+IRCNN+VDSR) + syn-IR image (ThermalGAN) [46] | 1 fold | 14.47 | 13.57 |
| 2 fold | 18.60 | ||
| 3 fold | 19.20 | ||
| 4 fold | 14.49 | ||
| 5 fold | 1.10 | ||
| Visible-light image (+IRCNN+VDSR) + syn-IR image (AGGAN) [47] | 1 fold | 13.61 | 12.92 |
| 2 fold | 18.03 | ||
| 3 fold | 17.39 | ||
| 4 fold | 14.43 | ||
| 5 fold | 1.16 | ||
| Visible-light image (+IRCNN+VDSR) + syn-IR image (SI-AGAN) (proposed method) | 1 fold | 9.94 | 9.05 |
| 2 fold | 9.16 | ||
| 3 fold | 13.51 | ||
| 4 fold | 10.92 | ||
| 5 fold | 1.75 | ||
| Methods | EER (%) |
|---|---|
| Visible-light image + IR image using HOG feature [4,22] | 16.28 |
| Visible-light image + IR image using weighted HOG feature [23] | 13.06 |
| Visible-light image + IR image using AlexNet [9,33] | 11.71 |
| Visible-light image (+IRCNN+VDSR) + IR image using ResNet-101 [11] | 10.98 |
| Visible-light image(+IRCNN+VDSR) + syn-IR image (SI-AGAN) using ResNet-101 (proposed method) | 9.05 |
| Methods | EER (%) |
|---|---|
| Original image | 16.24 |
| Original image + IRCNN + VDSR (proposed method) | 14.90 |
| Methods | EER (%) |
|---|---|
| SI-AGAN without perceptual loss and depthwise separable convolution | 39.13 |
| SI-AGAN with perceptual loss and depthwise separable convolution (proposed method) | 25.21 |
| Methods | EER (%) |
|---|---|
| Visible-light image (+IRCNN+VDSR) + syn-IR image (AGGAN) | 17.60 |
| Visible-light image (+IRCNN+VDSR) + syn-IR image (SI-AGAN) (proposed method) | 12.95 |
| Methods | EER (%) |
|---|---|
| Visible-light image + IR image using HOG feature [4,22] | 18.51 |
| Visible-light image + IR image using weighted HOG feature [23] | 23.90 |
| Visible-light image + IR image using AlexNet [9,33] | 24.53 |
| Visible-light image (+IRCNN+VDSR) + IR image using ResNet-101 [11] | 14.43 |
| Visible-light image (+IRCNN+VDSR) + syn-IR image (SI-AGAN) using ResNet-101 (proposed method) | 12.95 |
| #FLOPs | #Params | |
|---|---|---|
| AGGAN [47] | 9.19 × 109 | 2.95 × 106 |
| SI-AGAN | 2.28 × 109 | 5.40 × 105 |
| Environments | AGGAN | SI-AGAN |
|---|---|---|
| Desktop computer | 18.01 | 16.29 |
| Jetson TX2 embedded system | 66.17 | 45.61 |
| Environments | 2-Step Image Reconstruction | SI-AGAN | ResNet-101 and Score-Level Fusion | Total |
|---|---|---|---|---|
| Desktop computer | 6.31 | 16.29 | 24.69 | 47.29 |
| Jetson TX2 embedded system | 8.48 | 45.64 | 90.78 | 144.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baek, N.R.; Cho, S.W.; Koo, J.H.; Park, K.R. Pedestrian Gender Recognition by Style Transfer of Visible-Light Image to Infrared-Light Image Based on an Attention-Guided Generative Adversarial Network. Mathematics 2021, 9, 2535. https://doi.org/10.3390/math9202535
Baek NR, Cho SW, Koo JH, Park KR. Pedestrian Gender Recognition by Style Transfer of Visible-Light Image to Infrared-Light Image Based on an Attention-Guided Generative Adversarial Network. Mathematics. 2021; 9(20):2535. https://doi.org/10.3390/math9202535
Chicago/Turabian StyleBaek, Na Rae, Se Woon Cho, Ja Hyung Koo, and Kang Ryoung Park. 2021. "Pedestrian Gender Recognition by Style Transfer of Visible-Light Image to Infrared-Light Image Based on an Attention-Guided Generative Adversarial Network" Mathematics 9, no. 20: 2535. https://doi.org/10.3390/math9202535
APA StyleBaek, N. R., Cho, S. W., Koo, J. H., & Park, K. R. (2021). Pedestrian Gender Recognition by Style Transfer of Visible-Light Image to Infrared-Light Image Based on an Attention-Guided Generative Adversarial Network. Mathematics, 9(20), 2535. https://doi.org/10.3390/math9202535