1. Introduction
With the incoming of the fourth industrial revolution, the technological development of the Internet of Things (IoT) and smart infrastructure makes us pay more attention to the technology in order to collect and analyze a huge amount of information [
1,
2]. Particularly in medical and healthcare fields, there has been a paradigm shift from cure-oriented to prevention-oriented medical practices, partly due to the emergence of wearable devices that can measure and acquire vital signs wherever and whenever the users are [
3,
4,
5,
6]. Wearables are now part of every individual since these devices provide more concrete analytics decisions about the individuals using the individual data, which could help in better decision making connection with the bio-signals [
7]. Naturally, it enables better and high-quality medical and healthcare services utilizing the vital signs acquired.
Recently, such data have been accumulated exponentially with the help of the devices [
8]. It is not that difficult to imagine the potential knowledge and information inferred by the analysis of the big data for disease prevention, health management, diagnosis, therapies, etc. [
9,
10,
11,
12]. Artificial intelligence has created a lot of positive impacts in clinical decision making, diagnosis, predictive medicine, etc., which is a good sign for developing personalized systems [
13].
Personalized and customized healthcare services are expected to be common sooner or later. Since smartphones and wearable healthcare devices are already employed, the technology for collection and analysis of health information gathering is easier and advanced enough [
14,
15]. This situation promotes more research on various healthcare services utilizing and analyzing vital signs [
16,
17]. Global IT giants including Apple, Google, and Samsung are carrying out huge projects where healthcare platforms and services as well as wearable devices with biosensors are designed and developed [
18,
19].
The development of a bio-signal analysis algorithm is of prime importance to provide a seamless healthcare service. All bio-signal data have no meaning on their own. For example, electrocardiogram (ECG) signals and pulse wave data are time-series data, and health status cannot be analyzed using data alone. In this case, to analyze the health status, it is necessary to extract feature values by applying an analysis algorithm suitable for the data, since these services can be provided to the healthcare system using these characteristic values. Moreover, due to the fact that the development of bio-signal analysis algorithms is performed in multiple languages such as MATLAB and R, the source code conversion technology is a requirement to make the system development independent of the programming language. However, source code conversion techniques are primarily a very complex and redundant process and also depend heavily on the development tool which is used for deployment. Furthermore, due to the complexity, the management of the source codes of algorithms and the reusability of the source codes becomes very difficult. Therefore, to overcome the complex manual conversion process, this work implemented an algorithm specification for developing bio-signal analysis algorithms in different languages and a common execution engine that will be able to execute the algorithms written in different languages. The proposed architecture provides software architecture, by which one can reuse the bio-signal analysis algorithms developed by other developers in different languages such as MATLAB and R, without building a transformation process between multiple development environments.
The primary objective of the study is to develop a smart interface to run bio-signal analysis algorithms developed in different languages. An execution engine is developed to apply the smart interface. The execution engine can easily apply the bio-signal analysis technology developed in various algorithm development languages to the system using the source code conversion technology. This technology is expected to increase the reusability of analysis algorithms and the efficiency of system development.
When such a smart interface is provided, healthcare system developers can have more room to go further to higher service-oriented development using bio-signals. In addition, it is judged that the execution engine proposed in this paper can be used in various fields that require signal processing other than the healthcare field.
The remainder of this paper is organized as follows. First, we present the related works and backgrounds. Second, we describe the design of bio-signal storage where bio-signals with big sizes are stored and managed. Third, we discuss an architecture to support a smart interface among heterogeneous mining algorithms implemented in different languages. Fourth, the results and discussion of this paper are presented. Finally, we conclude with a description of the results.
2. Related Works
The conversion technique of the analysis of the vital sign algorithm source code is the task of changing the algorithm source code to match the system that provides healthcare services. Typically, the algorithms developed by MATLAB and Python are converted to C/C++ and applied to the system [
20,
21]. However, applying the source code converted to C/C++ to the system requires additional work by the developer to accommodate the system environment. We developed a system that can execute the source code of algorithms from multiple programming languages in the Java environment. The interface developed in the work is a Java-based interface, that can execute various bio-signal analysis algorithms from a single service definition. The work proposed in the paper allows the execution of bio-signal analysis source codes developed in the MATLAB and R programming using Java-based libraries running on Java Runtime Environment.
R programming was conducted to secure the interoperability between Java and R programming using rJava [
22]. An interoperability study using rJava uses Java’s graphical user interface (GUI) to overcome the delicate graphic task, which is a disadvantage of R programming. This is a graphical representation of the data analyzed using JavaFX by R programming [
23]. The study also analyzes the disease data of patients using R programming and shows the analyzed data using the GUI in Java [
24].
The MATLAB control library can connect to the MATLAB engine in Java and execute the MATLAB source code [
25]. A typical remote connection to a server installed with MATLAB was made to execute the MATLAB command using Java and MATLAB control [
26].
The technology of executing the algorithm source code itself has been studied to perform more sophisticated graphical tasks or to use development tools remotely. As such, most studies have been conducted by choosing the development tool for the system environment being developed. So far, research into applying development tools developed in different languages is insufficient. Therefore, research needs to be done by applying the source code developed with various development tools to the system and executing the desired algorithms. This study will be the basic research to apply various algorithm managements to the system.
This paper proposes an architecture for executing the source code itself, which is developed by MATLAB and R programming in the system, as shown in
Figure 1. The proposed architecture is divided into an execution engine that executes the vital signs algorithm and a repository that stores the bio-signals.
3. Materials and Methods
The bio-signal analysis system proposed in this paper has two services, as shown in
Figure 1. First, the bio-signal storage service collects bio-signals and stores the collected bio-signals in big bata-based NoSQL. Second, the algorithm execution service develops an execution engine for executing the bio-signal analysis algorithms developed in various development languages.
3.1. Bio-Signal Storage Design
The data accumulated by wearable health devices typically form big data. For instance, when the ECG sampling rate is 500 Hz, the system collects 500 pieces of data per second from an individual. Suppose it can gather them for a day. Then, the amount is 43,200,000 pieces of data. If it gathers them from more than 1000 people for a year or so, the amount of ECG data increases exponentially. The database storing such big data must secure scalability. As we know it, however, the relational database management system (RDBMS) has difficult aspects of processing such explosive vital sign data. Since RDBMS stores structured data, it uses data consistency and normalization and provides high performance. However, we face a huge problem to process unstructured data and big data beyond zettabytes [
27]. There is a need for a new way of storing and processing big unstructured or semi-structured data, which we call NoSQL. NoSQL is a non-relational database where its table schema is not fixed, join operation is not supported, and its horizontal expansion is easy. Therefore, NoSQL is more suitable for processing a vast number of data [
28].
NoSQL can be divided into three ways of storing: Key-value store, document store, and column store. The key-value store database stores, retrieves, and manages data as a key/value pair. A document store NoSQL database retrieves data by more complex conditions than key/value types, and its typical examples are MongoDB and CouchDB. Column store databases have a more powerful scalability in, for example, Cassandra and HBase.
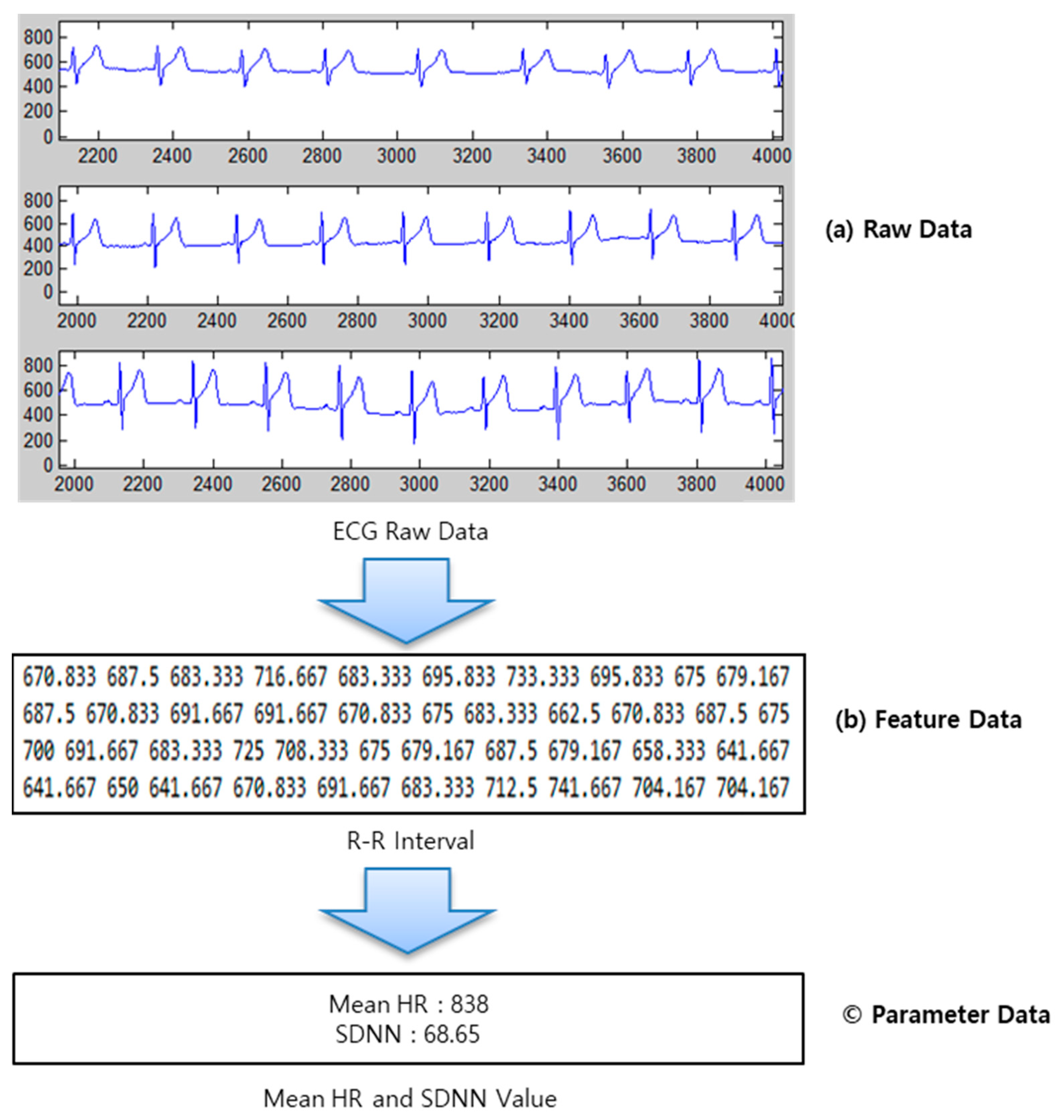
In this paper, according to the bio-signal characteristics of
Figure 2, the bio-signal raw data and feature data are stored in a storage. Bio-signal raw data is stored in NoSQL based on big data, and feature data is stored in Datawarehouse for big data analysis. Since recent bio-signals reflect various bio-signals such as electrocardiogram, respiration, respiration, SpO2, etc. to analyze disease or health conditions. To facilitate the search and analysis of bio-signals, raw data and feature data should be stored separately. In addition, this bio-signal classification method is easy to further expand feature data according to various bio-signal analysis techniques.
3.1.1. Design of Bio-Signal Raw Data Storage
In this paper, we designed a wide column database based on big data to store raw bio-signal data. This is due to the fact that the wide column database has excellent compression, distributed processing, aggregation processing (sum, count, avg, etc.), and query operation speed and scalability of large amounts of data. In addition, it is important to analyze bio-signals in units of year/month/week/day. Therefore, the column-oriented wide column database is easy to retrieve only the information of raw bio-signal data. In addition, this paper designed a bio-signal raw data storage using HBase, which is mainly used in the wide column database.
Raw data on their own have no meaning. They must have more meaningful attributes together such as the time when raw data are measured, whose data are, sampling rates, types of bio-signals, etc., as well as the raw bio-signals such as ECG, respiration, and acceleration data.
Table 1 shows an example of the data table that we have designed, using HBase. HBase stores data in a key-value format. Therefore, ‘Row-Key’ specifies the measurement date and ID. The ‘Data’ column is the bio-signal information. The ‘User’ column is the user information that measured the bio-signals. We need information about the types of bio-signals such as electrocardiogram, acceleration, respiration, etc., and the hertz (Hz) which is the sampling frequency of the signal to analyze bio-signals. Moreover, ‘User’ information includes age and gender, since the analysis techniques of bio-signal analysis algorithms vary according to age and gender.
3.1.2. Design of Data Warehouse for Feature Data
Our approach uses HBase to store the vast amount of bio-signal data, depending on the column family. The extracted data (e.g., heart rate variability (HRV)) from raw data (e.g., ECG) are sometimes large as well, and they are stored in the data warehouse. Moreover, we use SQL-On-Hadoop [
29] to search and analyze the mined data, which processes the data in a familiar way of interfacing SQL, working with data warehouse-based Hive. Hive uses a similar interface to SQL called HiveQL, and it can be used for statistical analysis.
Since Hive is Hadoop-based, its processing speed is much slower if it searches and accesses all the data. Therefore, we use the partitioning method to improve the speed. There is also a need to connect three heterogeneous information types to store the mined and analyzed data in
Figure 3. First, the information about the given algorithm to analyze bio-signals in the algorithm information table of MySQL. Second, the information about bio-signals used to analyze in HBase. Third, the extracted feature data in Hive.
Table 2 shows the table structure of Hive. The data are expressed by algorithm ID, algorithm name, the mined data value, and date. In addition, since it is partitioned by bio-signal ID, the acquired year, and month, the search time can be shorter.
3.2. Architecture of Bio-Signal Data Mining
Many researchers employ MATLAB to analyze bio-signals, and there is also a recent tendency to use an open-source programming R for big data analysis. Some develop signal processing and mining techniques with MATLAB, others with R programming or with other languages or tools. Data mining techniques are developed in various environments. However, when developers try to use components developed in another language environment than the current development environment, the process of transforming sources in one language to the ones in another is needed, which demands a substantial amount of time for implementing its processor for coding the components working in the development language.
For this reason, it is of great meaning to provide an execution engine enabling to skip the source transforming process, which supports interoperability between different sources. It is particularly important and desirable when one wants to develop systems using vital sign data mining techniques developed in various languages and environments previously. We describe a flow to support interoperability between different (bio-signal) data mining techniques. The execution engine that we designed requires data mining technique specifications where input/output parameters and tool (or language) types are specified to interact with the engine. With such specifications, the execution engine makes the data mining algorithms implemented in different languages work as if they operated in one common environment, resulting in features and other values after executing the sources.
Among the many development languages, we concentrated on two popular languages, MATLAB and R, which are most frequently used to implement data mining algorithms, as well as Java which is our development language. Both MATLAB and R programming have the advantage in that they support many libraries, GUI, and various ways of expressing the analyzed data and enable the bio-signal analysis with the usage of function-based source files, simultaneously. In our approach, the execution engine helps execute *.m files of MATLAB and *.R of R programming and get feature values from the given bio-signals.
The proposed architecture is based on a web service model based on a service oriented architecture (SOA) in
Figure 4. SOA can be integrated and used without a redundant development of applications that provide various bio-signal services. Therefore, SOA can minimize development costs, and users can easily receive biometric information monitoring services in an integrated environment. In this paper, an SOA-based bio-signal analysis system was developed. The architecture for interoperating among the components consists of the following four processes:
Service request for executing the bio-signal analysis algorithm through the simple object access protocol (SOAP) message.
Input value, output value, and algorithm explanation for supporting the mining specification of the bio-signal analysis algorithm.
Execution engine to run the bio-signal analysis algorithm.
Design a data warehouse that stores and classifies the results from the execution engine.
The web-based simple object access protocol (SOAP) message offers the service for executing the bio-signal analysis algorithm. It includes a request to search for raw bio-signals data, a request that uploads the bio-signal algorithm source file developed by using MATLAB or R programming, and a request that extracts the bio-signal feature value by executing the bio-signal analysis algorithm.
To run the bio-signal analysis algorithm in the system, the parameters and variables of the bio-signal analysis algorithm should be defined. Hence, the algorithm specification describes the information on types of bio-signals to be analyzed (such as ECG, respiration, and acceleration signals), an input value of the bio-signals, result value after the execution of the algorithm, clear explanation of the algorithm, and the developer.
The data warehouse stores the results from the execution engine. The data extracted by applying the bio-signal analysis algorithm may be a great amount in a single column. Therefore, the data is needed to save into the data warehouse for big data analysis.
3.2.1. Data Modeling Specification
To execute data mining modules, an accurate specification of the mining techniques is necessary, since the execution engine works according to the specification in which a type of language (or tool), input/output values, and explanation of the mining algorithms are described. Our study focuses on two well-known languages, MATLAB and R. To understand the execution of source files in these languages, we need to be aware of ‘function’ in MATLAB and R. They help analyze the bio-signal data by providing the functions where various input values are represented, stored, and visualized.
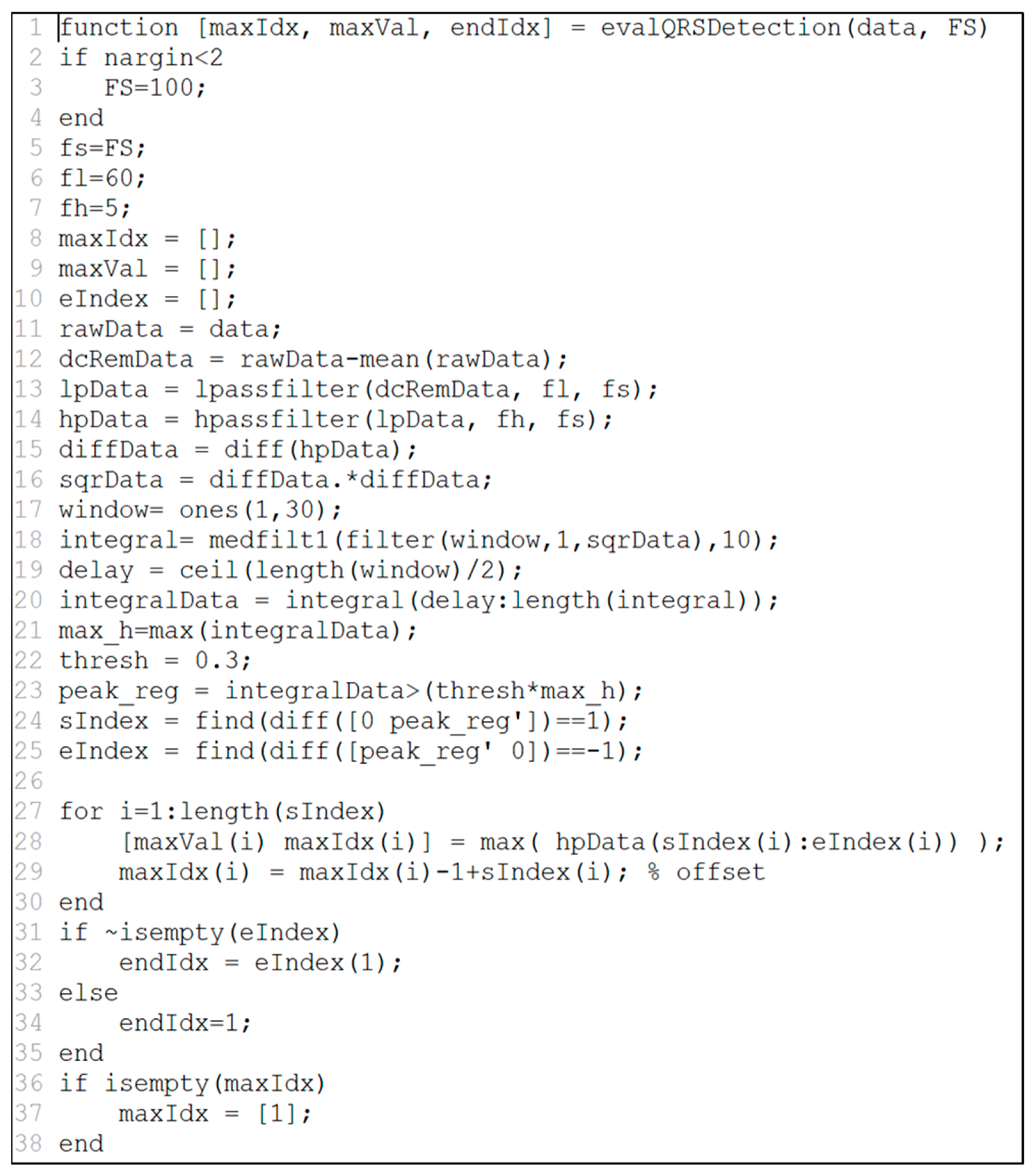
Figure 5 shows an example of MATLAB source code to extract HRV from ECG raw data. In the source, two input values appear such as data (ECG data) and FS (sampling rate). The output values are maxIdx (R-R interval index), maxVal (value of R-R interval), and endIdx (last R-R interval index). MATLAB has a vector data structure so that it can process different types of both input and output variables. For example, it supports several variables to handle ECG such as int, int array, double, and double array.
In general, software specification is a summary of the requirements and functions demanded in the design phase. The mining technique specifications proposed in our work are needed to define and execute the mining techniques in the system. In addition, the mining technique specifications are used to insert, delete, and update input/output parameters, as well as describe the techniques themselves.
Our approach uses the relational database management system (RDBMS) for specification concerning functions in MATLAB and R programming, so that various input/output values can be defined, inserted, and updated systematically.
Figure 6 presents the related database modeling. Table ‘algorithm_details’ represents basic information about a data mining algorithm including ‘id’ (who uploads it), file name, explanation, type of bio-signal, type of analysis tool, and registration date. Here, ‘vitalsign_type’ is a column needed to process various bio-signals, whose values are ECG, respiration, acceleration data, etc. In addition, the tool_type’s values are MATLAB or R to express which bio-signal analysis tool is employed. The table ‘algorithm_inp_out’ is the table where definitions of input/output values are, and one registers what algorithm is applied, the order of parameters (if it is an input value or output value), parameter type, and parameter explanation.
3.2.2. Source File Strategy for the Mining Technique
Hadoop’s Hadoop distributed file system (HDFS) plays a role in storing mining algorithm source files developed in MATLAB and R, which is suitable for the safe storage of sources.
Figure 7 illustrates how source files are stored in Hadoop. It shows that mining algorithm source files are stored under the Hadoop’s folder ‘/AlgorithmDB/’ in Linux to execute algorithm source files (‘
[email protected]/AlgorithmFile’). Here, it is necessary to copy the source files in HDFS to Linux or Windows OS by downloading the files in a browser used in HDFS or writing a command.
3.2.3. Bio-Signal Analysis Algorithm Execution Engine
The bio-signal analysis algorithm source execution technology is a technology that executes a bio-signal analysis algorithm developed by a user, utilizing a bio-signal analysis tool developed in different languages in the system. By omitting the source conversion technology according to the system environment, the environment and interface to execute the source file itself in the system are provided.
In this paper, we design an architecture that performs the functions developed in MATLAB and R programming using Java, as shown in
Figure 8.
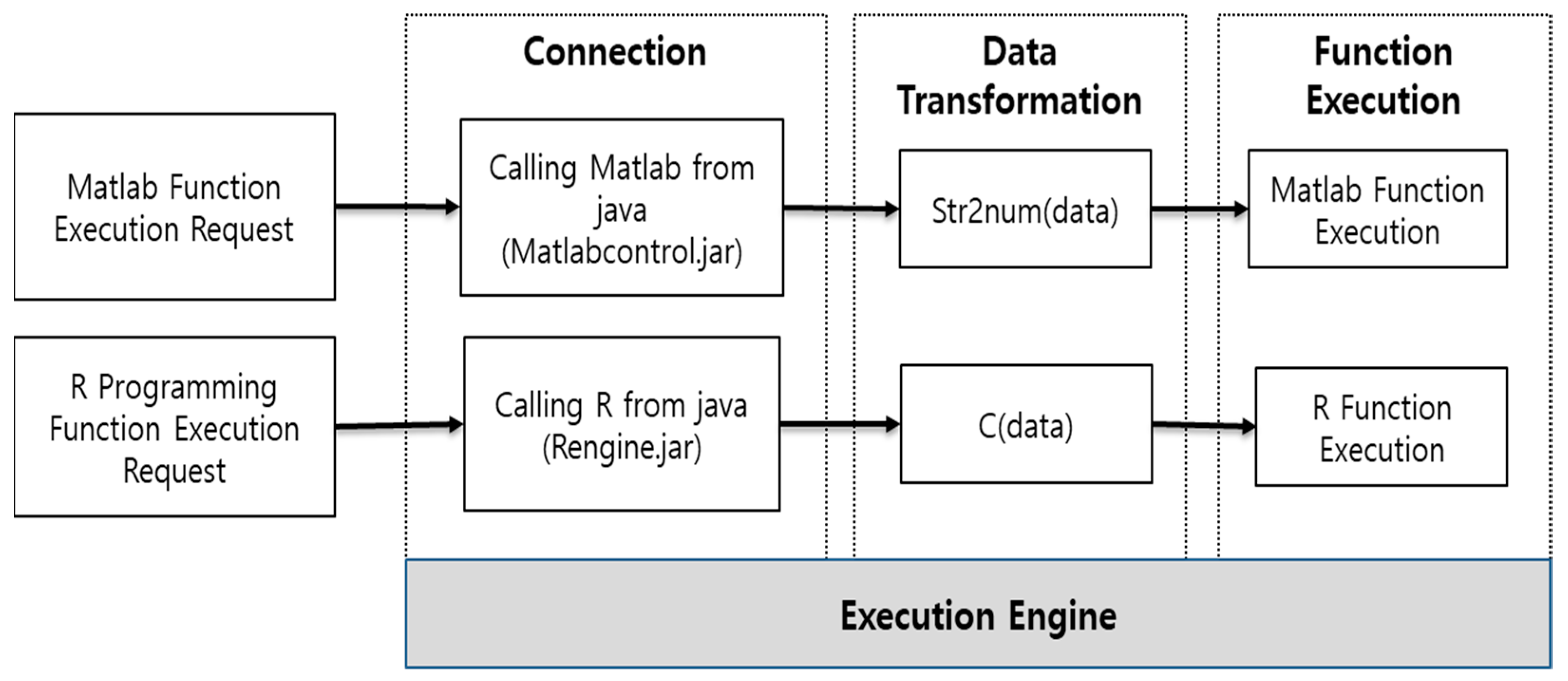
The execution technology of the bio-signal analysis algorithm runs the source code developed by MATLAB and R programming in Java. The bio-signal analysis algorithm developed by MATLAB is executed using the MATLAB control library. In addition, the bio-signal analysis algorithm developed by R programming is executed using the Rengine library. Each library is the application programming interface between Java and the development tools.
To run MATLAB in Java, use the MATLAB control library. The MATLAB control can use MATLAB commands in Java using the eval and f eval methods. The MATLAB control eval and f eval methods can be passed to the MATLAB workspace to execute MATLAB commands. In addition, the result value executed in MATLAB can be returned to Java. The result value returned from MATLAB is returned using the returning eval method of MATLAB controls. This paper accesses MATLAB using Java to execute MATLAB functions. Since the input value to execute the function is inputted through Java, it is inputted in a text format. Therefore, as shown in
Figure 9, the input value needs to be converted to a number format through str2 num, a MATLAB method. If the entered value is a text, it can be used as it is. After inputting the input value, execute the MATLAB function, and return the result value to Java for processing.
To execute R programming, we use a method similar to MATLAB. Java uses the Rengine library to access R programming. Rengine can use R programming commands in Java using eval. The R programming eval method can be passed to the R programming workspace to execute R programming instructions. In addition, the result value executed in R programming can be returned to Java. The result value returned from R programming is returned using the eval method. In this paper, we access R programming using Java to execute the R programming function. The input value for executing the function is converted into an R programming input instruction through Java and inputted immediately. Therefore, as shown in
Figure 10, since the input value is converted to the c format, there is no need to use a separate conversion function. After entering the input value, execute the R programming function, and return the result value to Java for processing.
Since R programming is an open-source type of development tool, various R packages exist. This is important since developers can freely install and use the R packages they need. Therefore, this paper developed a service that can install the R package. However, the R package installation cannot use the Java JRI, since JRI is a Java and R programming interface that allows you to run R in Java applications with a single thread. Here, JRI operates as a single thread, thus installing the R package is physically impossible. Therefore, in this paper, we created the R function in
Figure 11 and installed the R package using the Rscirpt of R programming.
4. Results
Table 3 measures the execution time of the algorithm source code. It was measured using an electrocardiogram signal among the biological signals. Using data from 60,000 to 150,000 ECG data, one source code was executed a hundred times to obtain an average. The algorithm source code used a lowpass filter developed by MATLAB and R programming to secure universality. As shown in
Table 3, the source code is executed directly in R programming and MATLAB runs faster than the source code executed in conjunction with the development tool in Java. The difference in execution speed is to create an input value and pass it to the development tool to execute it in Java. This is due to the fact that it takes time to generate the input value. In addition, it is judged that there is no time difference felt when the bio-signal analysis system is executed.
5. Discussion
We can check the results of the feature values through analysis and visualization using the ECG signal. Currently, bio-signals can be measured using various sensors. For example, there are data such as electrocardiogram, brain wave, pulse wave, and acceleration signal. These data have a process of making feature values from raw data and servicing them using feature values. Therefore, the system proposed in this paper can apply various bio-signal data. However, since the algorithm is analyzed using only electrocardiogram data, it is necessary to analyze various bio-signal data such as brain waves and pulse waves. Bio-signal analysis processing can be used in all the versions using a basic analysis module. However, while doing an analysis the version compatibility such as licenses have to be checked, which is a necessary condition. Our framework can be used for all kinds of bio-signals with little customization and also different kinds of analyses can be performed with little or no modification.
In addition, this paper was developed with an emphasis on analyzing feature values through signal processing. However, recently, artificial intelligence technology using train sets and test sets have been widely used. It is necessary to develop a technology that automatically converts the train set and test set to match the bio-signal development language through further research.
6. Implementation
We have implemented a bio-signal analysis system that can execute SOA-based MATLAB and R programming source codes. The bio-signal analysis system consists of a service that transmits the algorithm developed by MATLAB and R programming to a server and a service that executes the algorithm. In this paper, we have implemented the evalQRSDetection function in
Figure 5.
Figure 12a is a request SOAP message to execute a function, which includes the function name, input data, and development language. The input values are electrocardiogram data and sampling frequency. The input value can be inputted as the input value of the bio-signal data stored in the bio-signal storage. Moreover, you can input the direct input value. Furthermore,
Figure 12b is the response SOAP message. This SOAP message contains the result of executing the function.
Figure 13 shows the UI for executing the evalQRSDetection function developed in MATLAB and the result UI.
Figure 13a is the request UI for executing the evalQRSDetection function.
Figure 13b is the response UI showing the result of executing the evalQRSDetection function. The evalQRSDetection function displays three result values. Therefore, we show three UIs for the result values, which show the result data and chart in data format.
7. Conclusions
This paper presented an architecture that manages and executes bio-signal analysis algorithms more effectively, with a special focus on interoperability between data mining algorithms developed in heterogeneous environments. While bio-signal analysis components are implemented in different languages such as MATLAB, R, and Java, the proposed platform helps the design teams develop such components and systems as if they were developed in one common language.
Until now, bio-signal analysts have paid little attention to bio-signals as big data. However, as IoT and wearable technology are rapidly developing, the issue of bio-signals has high potentiality as a research theme for big data processing. Therefore, we need a repository for bio-signals as big data. Secondly, we designed mining algorithm specifications to share algorithms implemented in heterogeneous environments among developers. When design teams implement systems according to such specifications, they are expected to have many benefits, e.g., acquisition of many open algorithms, the overcoming of development restrictions caused by different environments, effective management of bio-signals, and application of the mining algorithms to various and wider environments and languages. In particular, it is expected that healthcare and medical system developers will be able to shorten the system development time using the algorithm execution engine technology. In addition, the real-time execution of various algorithms on the system will be very helpful for system maintenance and management. Thirdly, we developed the execution engine, naturally leading to an advantage that one can execute so many heterogeneous mining techniques with one common system. It also brings about a reduction of the development time and would make people and bio-signal analysts developing in different languages work together. We also hope that communication and competition between algorithms developers are enhanced, and thus higher quality mining technology will be eventually promoted. However, the system presented in this paper has limitations in applying artificial intelligence based on supervised learning. Supervised learning-based artificial intelligence needs to collect and transform a large amount of train set data. The difficulty of transferring large amounts of image files and the study on the application of the conversion technology to train set data are still insufficient. It is judged that such data transmission and conversion technology will be able to find a solution through future research.
Finally, we hope that this research will be fundamental, in which we can go one more step to high-quality, service-oriented research beyond simple signal processing for biodata, by utilizing and developing mining algorithms easily regardless of whatever environments are available.
Author Contributions
Conceptualization, M.-I.J. and H.-C.K.; methodology, M.-I.J.; software, M.-I.J.; validation, M.-I.J., S.A., and H.-C.K.; formal analysis, S.A.; investigation, M.-I.J.; resources, S.A.; data curation, S.A.; writing—original draft preparation, M.-I.J.; writing—review and editing, S.A. and H.-C.K.; visualization, M.-I.J.; supervision, H.-C.K.; project administration, H.-C.K.; funding acquisition, M.-I.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF2021R1I1A1A01050306) and by the Ministry of Science, ICT, and Future Planning (NRF2017R1D1A3B04032905).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are available on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, J.; Kao, H.A.; Yang, S. Service innovation and smart analytics for industry 4.0 and big data environment. Procedia Cirp. 2014, 16, 3–8. [Google Scholar] [CrossRef] [Green Version]
- Morrar, R.; Arman, H.; Mousa, S. The fourth industrial revolution (Industry 4.0): A social innovation perspective. Technol. Innov. Manag. Rev. 2017, 7, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Trossen, D.; Pavel, D.; Platt, G.; Wall, J.; Valencia, P.; Graves, C.A.; Zamarripa, M.S.; Gonzalez, V.M.; Favela, J.; Lovquist, E.; et al. Sensor networks, wearable computing, and healthcare applications. IEEE Pervasive Comput. 2007, 6, 58–61. [Google Scholar] [CrossRef]
- Bonato, P. Wearable sensors and systems. IEEE Eng. Med. Biol. Mag. 2010, 29, 25–36. [Google Scholar] [CrossRef] [PubMed]
- Buenaflor, C.; Kim, H.C. Wearable computers in human perspective: The decision process of innovation acceptance with user issues and concerns. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 573–580. [Google Scholar]
- Gimhae, G.N. Six human factors to acceptability of wearable computers. Int. J. Multimed. Ubiquitous Eng. 2013, 8, 103–114. [Google Scholar]
- Yetisen, A.K.; Martinez-Hurtado, J.L.; Ünal, B.; Khademhosseini, A.; Butt, H. Wearables in medicine. Adv. Mater. 2018, 30, 1706910. [Google Scholar] [CrossRef] [PubMed]
- Khan, Y.; Ostfeld, A.E.; Lochner, C.M.; Pierre, A.; Arias, A.C. Monitoring of vital signs with flexible and wearable medical devices. Adv. Mater. 2016, 28, 4373–4395. [Google Scholar] [CrossRef] [PubMed]
- Pantelopoulos, A.; Bourbakis, N.G. A survey on wearable sensor-based systems for health monitoring and prognosis. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 40, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.W.; Park, K.H.; Yi, S.H.; Kim, H.C. A big data framework for u-healthcare systems utilizing vital signs. In Proceedings of the 2014 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 10–12 June 2014. [Google Scholar]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Joo, M.I.; Ko, D.H.; Kim, H.C. Development of smart healthcare wear system for acquiring vital signs and monitoring personal health. J. Korea Multimed. Soc. 2016, 19, 808–817. [Google Scholar] [CrossRef] [Green Version]
- Secinaro, S.; Calandra, D.; Secinaro, A.; Muthurangu, V.; Biancone, P. The role of artificial intelligence in healthcare: A structured literature review. BMC Med. Inform. Decis. Mak. 2021, 21, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Boulos, M.N.K.; Wheeler, S.; Tavares, C.; Jones, R. How smartphones are changing the face of mobile and participatory healthcare: An overview, with example from eCAALYX. Biomed. Eng. Online 2011, 10, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, H.; Kim, T.; Joo, M.; Yi, S.; Yoo, C.; Lee, K.; Kim, J.; Chung, G. Design of a calorie tracker utilizing heart rate variability obtained by a nanofiber technique-based wellness wear system. Appl. Math. Inf. Sci. 2011, 5, 171S–177S. [Google Scholar]
- Luxton, D.D.; McCann, R.A.; Bush, N.E.; Mishkind, M.C.; Reger, G.M. mHealth for mental health: Integrating smartphone technology in behavioral healthcare. Prof. Psychol. Res. Pract. 2011, 42, 505. [Google Scholar] [CrossRef] [Green Version]
- Ozdalga, E.; Ozdalga, A.; Ahuja, N. The smartphone in medicine: A review of current and potential use among physicians and students. J. Med. Internet Res. 2012, 14, e128. [Google Scholar] [CrossRef] [PubMed]
- Farshchian, B.A.; Vilarinho, T. Which mobile health toolkit should a service provider choose? A comparative evaluation of Apple HealthKit, Google Fit, and Samsung Digital Health Platform. In Proceedings of the 13th European Conference on Ambient Intelligence, Malaga, Spain, 26–28 April 2017. [Google Scholar] [CrossRef]
- Park, S.J.; Park, B.S.; Kang, S.A.; Kang, S.Y. The Application of Digital Health Content Using Mobile Device. In Proceedings of the Information Science and Applications (ICISA) 2016, Ho Chi Minh, Vietnam, 16 February 2016. [Google Scholar] [CrossRef]
- Vikström, A. A Study of Automatic Translation of MATLAB Code to C Code Using Software from MathWorks. Master’s Thesis, Lulea University, Luleå, Sweden, 2009. [Google Scholar]
- Aycock, J. Converting Python virtual machine code to C. In Proceedings of the 7th International Python, Houston, TX, USA, 10–13 November 1998. [Google Scholar]
- Satman, M.H. RCaller: A software library for calling R from Java. J. Adv. Math. Comput. Sci. 2014, 2188–2196. [Google Scholar] [CrossRef]
- Ignatchenko, V.; Ignatchenko, A.; Sinha, A.; Boutros, P.C.; Kislinger, T. VennDIS: A JavaFX-based Venn and Euler diagram software to generate publication quality figures. Proteomics 2015, 15, 1239–1244. [Google Scholar] [CrossRef] [PubMed]
- Furtună, T.F.; Vinte, C. Integrating R and Java for Enhancing Interactivity of Algorithmic Data Analysis Software Solutions. Rom. Stat. Rev. 2016, 64, 29–41. [Google Scholar]
- Wu, C.H. A patient-centered self-care support system for diabetics. In Proceedings of the 2014 IEEE 11th International Conference on e-Business Engineering, Guangzhou, China, 5–7 November 2014. [Google Scholar] [CrossRef]
- Bisták, P. Remote laboratory server based on Java Matlab interface. In Proceedings of the 2011 14th International Conference on Interactive Collaborative Learning, Piestany, Slovakia, 21–23 September 2011. [Google Scholar] [CrossRef]
- Cattell, R. Scalable SQL and NoSQL data stores. Acm Sigmod Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa, 26–28 October 2011. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Bian, H.; Chen, J.; Dong, Z.; Du, X.; Gao, X.; Liu, D.; Lu, J.; Zhang, H. A study of SQL-on-Hadoop systems. In Proceedings of the Workshop on Big Data Benchmarks, Performance Optimization, and Emerging Hardware, Salt Lake City, UT, USA, 1 March 2014. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}