1. Introduction
The visible light spectrum spans from 400 to 700 nm, while the near-infrared (NIR) spectrum between 700 and 1100 nm. The human visual system can perceive only visible light. The visibility of a photograph is greatly influenced by the weather conditions, such as haze, smoke, and fog, etc. These bad weather conditions attenuate the contrast and detail of the captured image by scattering light. Nevertheless, the NIR light can be transmitted through haze [
1]. The NIR light response offers a higher contrast and richer textural details than that of visible light. Most commercial image sensors can detect both visible and NIR light, rendering them useful for night vision and surveillance applications [
2].
Surveillance cameras are used to capture objects under various lighting conditions, such as in dark rooms, in tunnels, in daylight, and in the presence of vehicle headlights. A surveillance camera system consists of an image sensor, a hot mirror filter, and an infrared (IR) light-emitting diode (LED) lamp. The hot mirror is an IR cutoff filter to prevent distortion or undesired artifacts caused by NIR light. The IR lamp serves as an auxiliary component to detect objects that cannot be perceived by human vision. The image sensor uses the hot mirror filter to take a visible image as it blocks NIR light during the day, while also uses IR flashes to illuminate dark regions. Visible images tend to include numerous colors, but a high level of noise is generated by high ISO settings under low-light conditions [
3]. In contrast, NIR images demonstrate sharper detail than visible images under low-light conditions. This is due to the use of the IR LED lamp, which tends to make them monotonically reddish.
Surveillance cameras at nighttime often use IR LED lights that do not have a visual effect for security or crime prevention as auxiliary light. In general, since the amount of infrared light emitted by the lamp is fixed, the IR image becomes too bright when capturing close objects, making it very hard to recognize an object. In particular, at night, the hot mirror filter for blocking infrared rays in the daytime is removed, and a complex visible-near-infrared image is captured. The overlap of visible and strong IR lighting affects the image’s color and saturation distortion [
4].
Figure 1 demonstrates images taken under various IR LED luminosity conditions. When photographing a distant object, the LED output increases to extend the reach of the light, whereas IR light saturation of a close object becomes relatively higher. When the brightness is reduced to facilitate identification of a nearby object, low-level saturation occurs as in the red arrow area of
Figure 1. The quality of an image taken at night faces a number of problems due to low-light environments, excessive or insufficient IR light, and inappropriate exposure times.
Lately, a wealth of research has investigated how to clearly identify objects in dark spaces under low-light conditions using new LED lighting and camera controls. In order to capture a clear night image, a technology that provides adjustable illumination to different zones of a field of view of an image sensor with a plurality of vertical cavity surface emitting lasers, or to prevent IR oversaturation, it has been proposed to adjust an auto-exposure target in an auto-exposure operation on a sequence of images by obtaining a histogram of at least one of the images [
5,
6]. However, it is difficult to adjust the camera parameters and the IR LED light adaptively according to the distance of the subject and amount of light in various environments, including severe environmental changes such as moving photography. The hardware configuration of a camera system corresponding to various functions becomes complicated. In addition, increasing just the camera sensitivity makes it difficult to capture an image at a level in which the human vision adapts and perceives a wide range of luminance conditions and sudden lighting changes experienced in everyday life. The proposed method can improve the camera performance for object identification, while preserving color information in various environments by using photography using IR LED pulses of a constant pattern regardless of the lighting environment and the distance of the object.
Visible and IR image fusion methods have been recently found using surveillance cameras. The literature has proposed a large number of fusion methods, including multi-scale transform [
7,
8], sparse representation [
9], neural network [
10,
11,
12], subspace [
13], and saliency methods [
14], as well as hybrid models [
15,
16,
17]. These approaches improve image quality and provide useful information by overcoming the disadvantages of visible and IR images. The multi-scale transform-based methods divide the input image into layers of multiple levels using wavelet, pyramid, and curvelet transforms, as well as an edge-preserving filter. Each layer is processed to analyze the image information and extract the image features and is recombined using a specific rule of each method. Spare representation-based methods convert the source images into a dictionary composed of a few atoms. This method extracts image features using a spare coefficient from the dictionary, fuses the features according to the fusion rule, and reconstructs the fused image. Neural network-based methods are developed based on pulse couple neuron network (PCNN) [
18]. PCNN depicts the perception behavior of the human brain to deal with neural information. PCNN-based methods are similar to multi-scale transform methods. Source infrared and visible images are decomposed into low and high frequency subbands and each subband is fused using various methods, such as wavelet, contourlet, and curvelet transforms. The final fused image is reconstructed by an inverse transform. Recently, deep learning-based neural network methods have been introduced in various fields [
19,
20,
21,
22]. The deep learning-based methods are applied not only to object detection and classification, but also to image processing such as multi-focus image fusion, remote sensing imagery, panchromatic image fusion as well as infrared and visible image fusion. Subspace-based methods reduce high-dimensional input data to low-dimensional space using principal component analysis, non-negative matrix factorization, and independent component analysis. The low-dimensional space has intrinsic information of input data without redundant information. This method is used for image fusion because it requires less memory and computational time and can improve generalization. Saliency-based methods extract salient object regions from an input image and generate salient layers and fuse the image based on these layers. The salient object region is more significant than the background of the image. These methods maintain the integrity of salient object regions and improve the visual quality of the fused images. Hybrid models combine the advantages of the multiple fusion methods to improve image quality [
23].
Sugimura et al. proposed an RGB and NIR image fusion method that relies on blending different exposure times to synthesize a noise- and blur-free image under extremely low-light conditions [
24]. The researchers used an adaptive smoothness map depending on the gradient and color correlations of each region. Vanmali et al. proposed a multi-resolution fusion process that is guided by weighting maps for visible and NIR images [
1]. These weighting maps are generated based on the local entropy, local contrast, and visibility of each image. Ma et al. proposed a multi-scale fusion method based on a visual saliency map (VSM) and weighted least squares (WLS) optimization models [
16]. The Ma et al. method decomposes the visible and NIR image into base and detailed layers. The base layer of each source is then recombined by the VSM. The VSM is used to extract salient structures, regions, and objects from an image. The detailed layer is fused using WLS optimization, which selects more useful details and reduces noise. Li et al. proposed deep-learning architecture, DenseFuse, for visible and IR image fusion [
12]. DenseFuse entails encoding and decoding processes. The encoding process combines convolution layers, fusion layers, and dense blocks to obtain useful features from input images. The decoding process is used to reconstruct the fused image.
In the image captured at night using a conventional surveillance camera, as the object gets closer to the camera, over-saturation occurs due to IR light reflections. It is difficult to accurately identify the object’s color and shape. To address this problem, it is important to design a complex hardware configuration to measure the amount of surrounding light and the distance between the camera and the object. Another way is to increase the camera sensitivity, but responding in real time to the instantaneous changes in the lighting environment is challenging. Therefore, a capturing that confirms the object shapes regardless of the distance between the object and the camera under various environmental conditions is highly essential.
In this paper, we propose an IR image fusion method combining high- and low-intensities using an IR image acquisition system to enhance image quality under low-illumination conditions. The input high- and low-intensity IR image pairs are taken sequentially for the same scene using an alternating IR lamp. The high-intensity IR image captures the objects with deeper distance depth, whereas the low-intensity IR image captures the overall color information and recognizes the near objects. The proposed method involves luminance blending, local tone mapping, and color scaling and correction (CsC) [
25,
26]. The luminance blending is used to extract and enhance the detail information of input sources. The luminance blending stage combines the low- and high-intensity IR luminance channels to create a single radiance map using four types of weighting maps: chroma, intensity, depth information based on intensity, and variance differences. Each weighting map is designed to extract the local details of the low- and high-intensity IR images. The local tone mapping is used to improve the visibility of the captured image. A local tone mapping technique, the multi-scale luminance adaptation transform (MLAT) [
27], is applied to the radiance map to enhance local contrast. CsC is then used with scaling factors to preserve the original color of the low-intensity IR image and to reduce the noise and color distortion caused by luminance blending and local tone mapping.
2. MLAT
In our previous work, the MLAT was proposed to enhance local contrast and preserve the color of tone-mapped images [
27]. The MLAT comprises the multiple luminance adaptation transform (LAT) with different surroundings. The LAT is processed in the LAB color space to decompose the luminance and chrominance channels. The LAT consists of local tone mapping in the luminance channel and color compensation in the chrominance channel. Local tone mapping uses a visual-brightness function [
28,
29] to enhance local contrast and image rendition depending on the scale of the surroundings. A narrower scope enhances detail, while a wider scope improves tonal rendition. To balance the detail and tonal rendition of an image, a multi-scale method consisting of the weighted sum of several single-scale methods with different surroundings is applied to the LAT. The equations for the MLAT are the following:
where
is the normalized adaptation luminance, the Gaussian-blurred image of the input luminance channel
. The maximum value of
is 100.
and
are the minimum and maximum luminance for
, respectively.
is the visual gamma function,
is the visual gamma image for pixel position
.
is the output luminance channel.
and
are applied to adjust the intensity range of
.
is the multi-scale LAT, and
is the weight.
The color compensation stage reduces the desaturation effect after local tone mapping. It does so by improving the chrominance gain based on the ratio of the input luminance to the LAT, as follows:
where
is the compensated chrominance channel using the input chrominance channel
and the ratio of the output luminance channel
to the input luminance
. The chrominance channel
represents the
and
channels of the LAB color space.
3. Visible and NIR Image Acquisition and Fusion
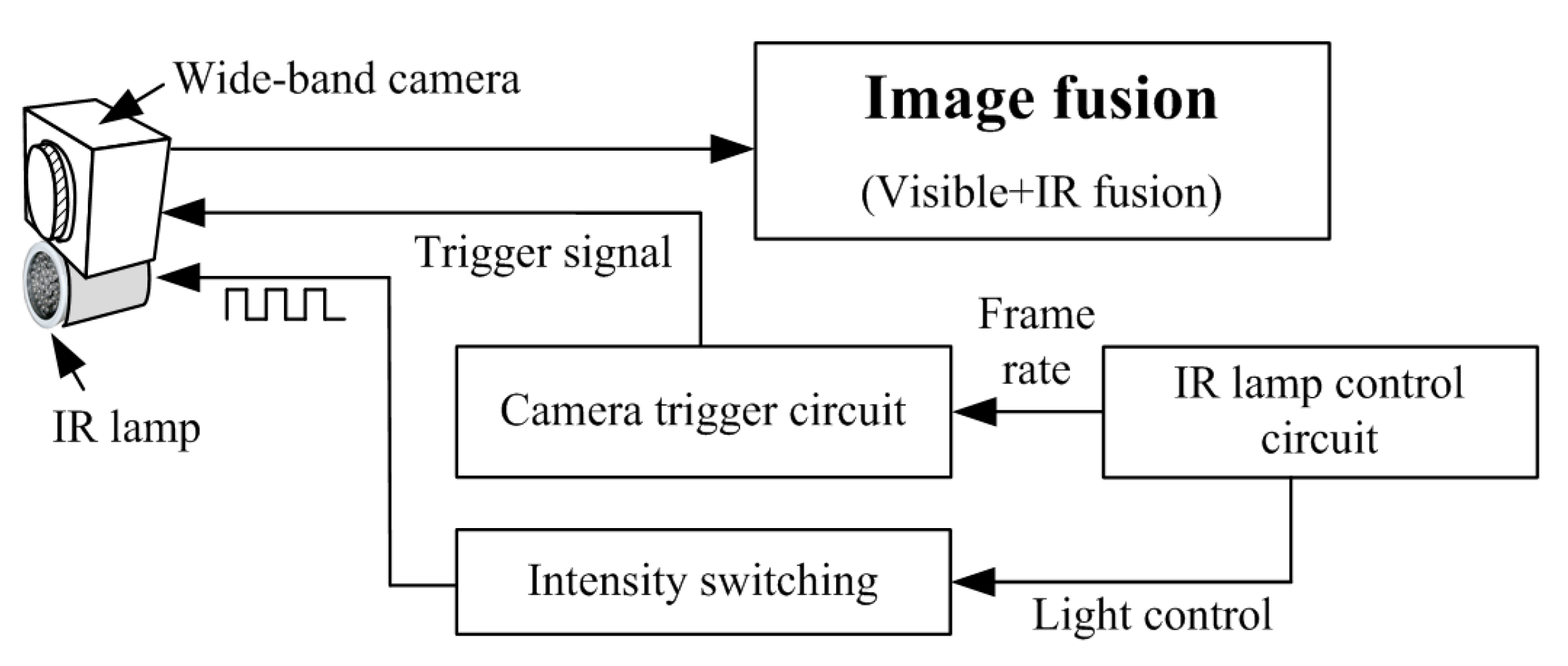
The proposed method assumes an indoor scene under ambient light, which contains less outdoor IR light and less ambient IR effect on the camera. This condition considers capturing that is only affected by the emitted IR light by the designed system. First, we designed an image acquisition system to capture IR image pairs using an alternating IR lamp with low and high intensities. The low level is for closer objects, and the high level is for relatively distant objects. The hot mirror filter was removed from the camera to capture IR images. The IR light can affect the visible image, but the low-intensity IR lamp under normal illumination has been adjusted for minimal impact. The proposed acquisition system is illustrated in
Figure 2 and
Figure 3. In
Figure 2, the proposed hardware consists of a wide-band camera that includes the visible and near-infrared band (OmniVision OV5640 CMOS, 1920 (W) × 1080 (H) pixels), two IR lamps (5 V–3 W), an IR lamp control circuit, and a camera trigger circuit. The IR lamps were synchronized with the capturing cycle and alternately light up in two levels, color information and near-field subject information were acquired at the low-level intensity of IR lamps for short distance, and detailed luminance information of distant subjects were acquired at the high-intensity of IR lamps for long distance, then images were synthesized. As shown in
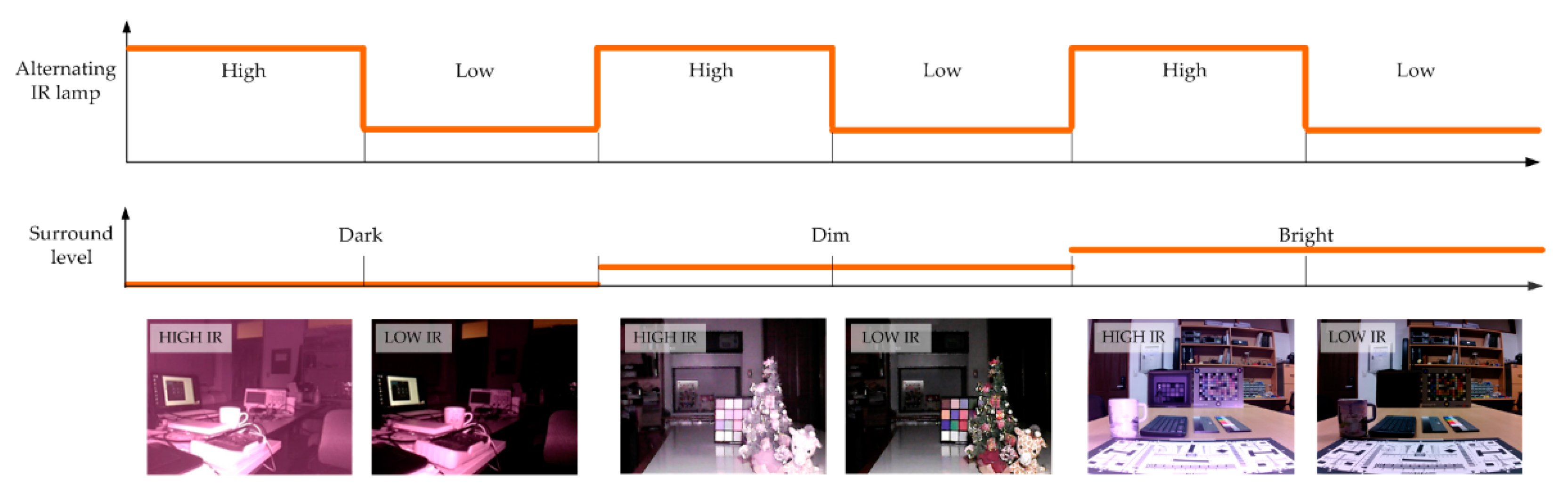
Figure 3, in dark surroundings, the high level of IR light can effectively capture a distant subject, and the low level of IR light can effectively capture a close subject. However, as the surround level increases, the lower level-IR does not significantly affect the image, and information in the visible light band without distortion, including color information, can be captured. Against this backdrop, the proposed system captures two types of IR images: high-intensity IR and low-intensity IR. High- and low-intensity IR images are captured when the alternating level of the IR lamp is high and low, respectively. These IR lamps are synchronized with the capturing period. The IR lamp pulse rate and the image frame rate are synchronized by the camera trigger circuit. As a result, the IR lamps alternately light up in two levels during high–low intensity IR image captures. The camera acquires color information and near-subject contour information at a low level and obtains distant subject contour information at a high level.
The images captured by the proposed acquisition system demonstrate the following features. In a dark scene, an image obtained with high-intensity IR is generally shot with a brighter image than that of low-intensity IR, but with a saturation of an adjacent object. Conversely, an image obtained with low-intensity IR has less light, containing details of the saturated region of high-intensity IR. In a bright scene, the low-intensity IR image contains less IR information, and most of the captured image has a visible light band. This enables the color of the scene to be preserved. In our experiments, we captured indoor images to reduce the impact of IR light found in natural light.
In
Figure 4, the left-hand image depicts the high-intensity IR image, which includes little color information, whereas the right-hand image depicts the low-intensity IR image. The low-intensity IR image has color information resulting from ambient light. The flower details and colors clearly appear in the low-intensity IR image, but some regions close to the camera in the high-intensity IR image are oversaturated due to the IR light reflections. For the flowerpot under the flowers and the lightbox in the background of the scene, compared to the low-intensity IR image, the high-intensity IR image demonstrates more details. The red boxes indicate areas with prominent details.
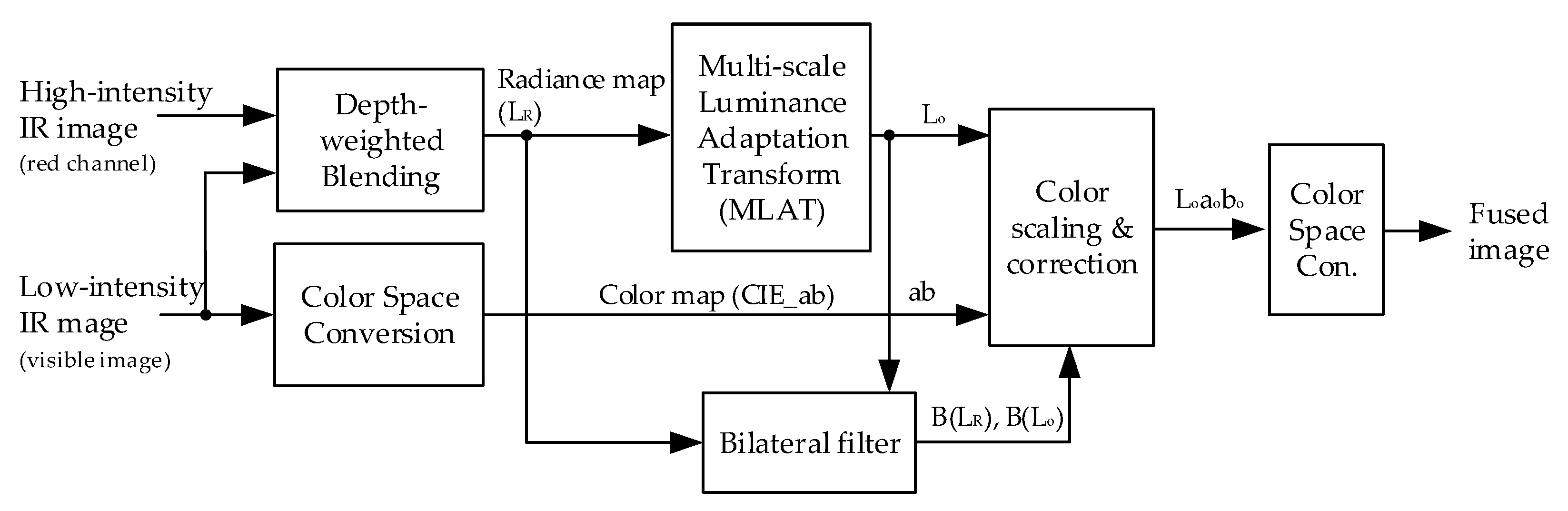
Figure 5 presents a block diagram of the proposed method for the captured images. It shows luminance blending and CsC. Each stage uses the LAB color space to decompose the luminance and chrominance components of the image.
3.1. Step 1: Depth-Weighted Luminance Blending
Luminance blending combines the input IR image pairs based on weighting maps to produce a radiance map with enhanced details. The weighting maps are calculated in the depth-weighted blending block of
Figure 5, incorporating chroma, intensity, intensity difference, and variance difference. Each weighting map shows weights ranging from zero to one. As a weight value moves closer to one, the radiance map becomes increasingly similar to the low-intensity IR image.
The chroma weighting map uses the chrominance channels of the input low-intensity IR image to produce higher weighting values for the objects in a scene. Compared to high-intensity IR images, low-intensity IR images are more colorful and accurate, without dim surroundings. Furthermore, the color components can be used as local details for the objects in a scene. The equation for this process is the following:
where
is a normalization function that converts the range of the weighting map from zero to one,
is the chroma weighting map, and
and
are the chrominance channels of the input low-intensity IR image in the LAB color space.
The intensity weighting map represents the local contrast, using the illumination component of the low-intensity IR image that can be obtained using bilateral filtering. In a simplified computer vision model, the pixel values of an image are the product of illumination and surface reflectance [
30,
31]. The illumination components can be represented by the weighted sum of adjacent pixels, such as through the use of a bilateral filter. A bilateral filter is an edge-preserving filter that smooths an image while retaining strong edges [
32]. Such a filter reduces halo artifacts caused by local tone mapping. The intensity weighting map is calculated as follows:
where
is the intensity weighting map,
is the bilateral filter function, and
is the luminance channel of the low-intensity IR image in the LAB color space.
The weighting map for the intensity difference represents the local edges between the high- and low-intensity IR images. In the captured images, a high-intensity IR image is brighter than a low-intensity IR image. The over-saturation occurs in the high-intensity IR image when an object is close to the camera. The intensity difference,
, between input IR image pairs has higher value when the object is close to the camera. Therefore, the more local edges can be obtained by increasing the weight of the low-intensity IR image when the value of
is close to 1:
where
is the intensity difference weighting map, and
is the red channel of the high-intensity IR image.
The variance difference weighting map was calculated using the difference in the local variance between the high- and low-intensity IR images. The local variance, obtained from pixel-wise processing, represents the local details of each input image. The difference in the local variance represents the local gain at a particular pixel position for each image. The intensity difference has a positive value because the luminance of a high-intensity IR image is always higher than that of a low-intensity IR image. However, the variance difference has both positive and negative values, because local variances have different values for scenes and pixel positions. To set the range for the variance difference weighting map between zero and one, we introduce an additional normalization function with a constraint, as follows:
where
is the variance difference weighting map,
is the variance difference, and
is the local variance based on pixel-wise processing. In Equation (12), the variance difference weighting map
is rearranged based on the variance difference
. The constraint is set at 0.5, where
, to assign the same weighting value for an input image pair.
Finally, the proposed weighting map was computed from the above four types of weighting maps as follows:
The radiance map can be obtained using the weighted blending of the input images:
where
is the radiance map,
is the relative exposure gain, and
calculates the global mean intensity of the image.
3.2. Step 2: Local Tone Mapping
After luminance blending, we applied local tone mapping using the MLAT to the radiance map, with the following steps:
(1) In Equations (1)–(6), the luminance channel
and the normalized adaptation luminance
are calculated as follows:
where the constant value of 100 is used in normalizing the output range.
is a Gaussian filter with standard deviation
that controls the local contrast of the LAT.
(2) The MLAT is performed using the weighted sum of three LAT versions. The weighting value of the MLAT is 1/3, and the standard deviation is 15, 50, and 250 for the respective versions of the LAT.
3.3. Step 3: Color Scaling and Correction
After MLAT processing, CsC was used to preserve the colors in the tone-mapped image. CsC reduces the noise and the color distortion caused by luminance blending and tone scaling using scaling factors, as follows:
where
and
are the chrominance channel of the low-intensity IR image in the LAB color space, and
and
are the results of using CsC.
is the tone scaling factor, which identifies the luminance change rates after tone mapping through bilateral filtering.
is the result of using the MLAT.
Finally, the tone-mapped luminance channel and the compensated chrominance channels and are converted back from the LAB color space to the RGB color space.
4. Simulation Results
We compared the results of the proposed method with those of two conventional methods introduced by Vanmali et al. [
1] and Li et al. [
12]. Vanmali et al. proposed a weighted-map-guided Laplacian–Gaussian pyramid to fuse visible and NIR images. Li et al. proposed deep-learning architecture based on a convolutional neural network and dense blocks for fusing infrared and visible images. In this study, the test images were taken using the proposed image acquisition system. For the two input images, only the red channel of the high-intensity IR image was used for the IR luminance image and the RGB channels of the low-intensity IR image was used for the visible image. We have the parameters of the conventional methods by referring to their original reports. The results of the respective methods are shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13.
The Vanmali approach does not consider low-light conditions. The algorithm uses the hue–saturation–value (HSV) color space to decouple the luminance and chrominance components. Weight maps are used to combine the luminance channels of the visible and NIR images. The combined luminance channel is converted back from the HSV color space to the RGB color space without color compensation for the luminance variation. As a result, color distortion and color noise appear in regions where there are brightness differences between the input images. In the results for Li, the bright regions of the NIR image display blurring and desaturation effects. This is because the reflected NIR light affects the feature maps in the encoder, and the fused image is reconstructed from the sum of each feature map.
In
Figure 6, Vanmali’s method shows strong noise and color blocking for the overall image, and also over-saturation is shown in the book and the color checker. Li’s method shows the desaturation and low local contrast in the results. In
Figure 7, Vanmali’s method shows color noise on the desk at right bottom and over-saturation in the color checker, and the Li’s method shows white balance shift and de-saturation. In
Figure 8, Vanmali’s method shows strong color noise in the sharpness test chart and the flower area, whereas Li’s method shows a desaturation effect in the flower and flowerpot regions. In
Figure 9, Vanmali’s method shows color noise and over-saturation in the color checker and the front of the desk and represents low-level noise in the dark region. The proposed method reduces noise and color blocking, providing a higher local contrast than that of other methods.
In
Figure 10,
Figure 11,
Figure 12 and
Figure 13, the red boxes represent the low contrast, color distortion, and color noise regions. In
Figure 10, Vanmali’s method shows color distortion in the cup, while Li’s method shows low contrast and desaturation effects in the same region. In
Figure 11, Li’s method shows reflected light from the bright IR light. In
Figure 12, Vanmali’s method shows low-level noise in the red box at left bottom and color shift in the red box at right top. In contrast, the proposed algorithm demonstrates little color distortion and high contrast.
Figure 13 is taken in a dark scene. The low-intensity IR image contains little color information because the dark scene uses only an IR lamp, which provides the camera with insufficient color information. However, it offers detailed information about areas that are not displayed owing to saturation in the high-intensity IR image. In the synthesized image, Vanmali’s method results in image distortion in the background, and the contrast is low in the monitor area around the red box. In contrast, the proposed algorithm shows a higher contrast than the conventional methods, and the image inside the monitor appears well. These facts confirm that the proposed method has less color distortion and noise and better local contrast than the images produced using the conventional methods.
Subsequently, we performed objective evaluations for the naturalness image quality evaluator (NIQE) [
33] and the chroma difference. The NIQE is a supervised method based on a natural scene statistics (NSS) model. The NSS model is trained on statistical features derived from a corpus of natural and undistorted images. The NIQE measures the distance between the NSS model and the extracted features from the fused image. Lower NIQE scores reflect better perceptual quality of an image. The result of NIQE is shown in
Figure 14. The results of
Figure 7,
Figure 10 and
Figure 13 are in
Figure 14; the proposed method is visually superior, but the proposed method does not have the lowest score compared with the conventional methods. NIQE is based on an “opinion unaware” model that does not require training on databases of human judgments of distorted images. It often does not match human perceived quality. In particular, NIQE is evaluated using a gray scale image. As a result, the results of NIQE are somewhat insensitive to the color noise and the desaturation. To evaluate the color distortion, we added chroma difference using color patches of a color checker.
For 24 color points of the color checker in
Figure 11, the relative chroma difference scores were calculated from the Euclidean distance between the result image and the reference image on the chrominance channel in the LAB color space. The reference image was captured with the proposed image acquisition system in a normal environment without the IR lamp. The image in the right top of
Figure 15 shows the color checker of the reference image. The chroma difference equation is as follows:
where
is the chroma difference.
and
represent mean values of chrominance channels of each color patch. The subscript 1 represents the reference image and 2 represents the result image of each method.
The scores show how well those methods preserve chroma information after image fusion. The accuracy of color reproduction for the reference image was found to be the best in the proposed method on average.
Figure 14 and
Figure 15 show the scores resulting from using NIQE and chroma difference, respectively.
Table 1 lists the computational time for each method. All methods run on the same environment (a single CPU i7-6700 3.4 GHz, Ram 8 G, GPU Nvidia RTX 2070 super, image resolution 640 (W) × 480 (H), WITHROBOT, Seoul, Korea). The proposed method and Li’s method were processed using a Python code and Vanmali’s method was run based on MATLAB. The results show the computational speed of the proposed method is faster than the conventional methods. From the overall assessment, we conclude that the proposed method performs better than the conventional methods.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}