
Long-Term Person Re-Identification Based on Appearance and Gait Feature Fusion under Covariate Changes



Abstract
:1. Introduction

- We propose a new two-branch Re-ID model to combine appearance information with gait information. The complementary combination ensures the uniqueness of biometrics and maintains the robustness to appearance changes.
- We put forward a novel gait representation, namely Improved-Sobel-Masking active energy image (ISMAEI), instead of common GEI, which can retain the uniqueness of human motion information and overcome covariate changes.
- We design a feature-level fusion method with an adjustment factor to better integrate appearance features with gait features.
2. Related Work
2.1. Appearance-Based Person Re-ID
2.2. Gait-Based Person Re-ID
2.3. Appearance and Gait-Based Person Re-ID
3. Research Methodology
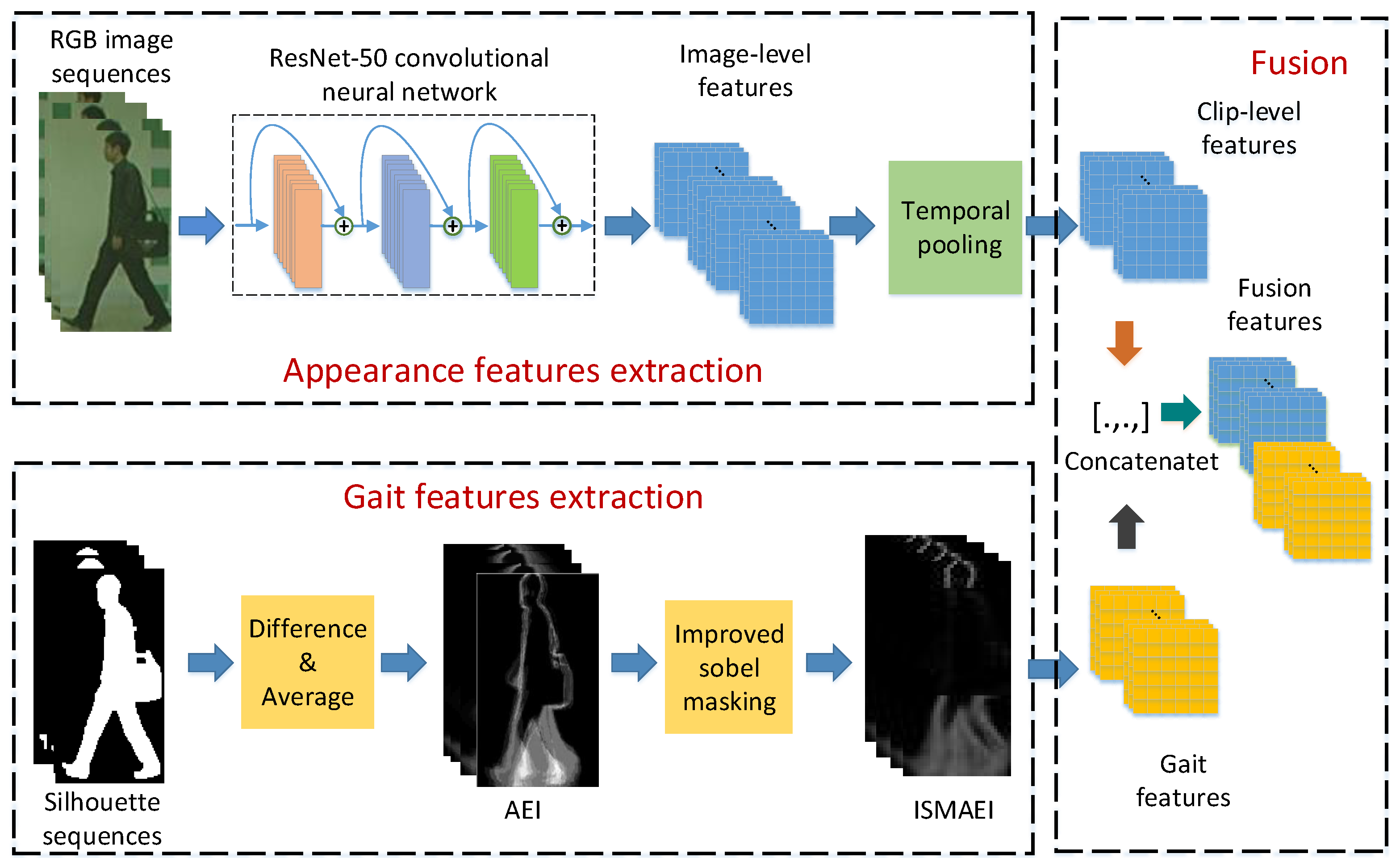
3.1. Proposed Framework
3.2. Appearance Feature Extraction
3.3. Improved-Sobel-Masking Active Energy Image
| Algorithm 1 Improved-Sobel-Masking Active Energy Image |
| Require: A gait silhouettes set , where denotes ith silhouette, ; W and denote the two-dimensional orthogonal discrete wavelet transform (DWT) matrix and its inverse, respectively; Ensure: denotes a gait representation of the sequence;
|
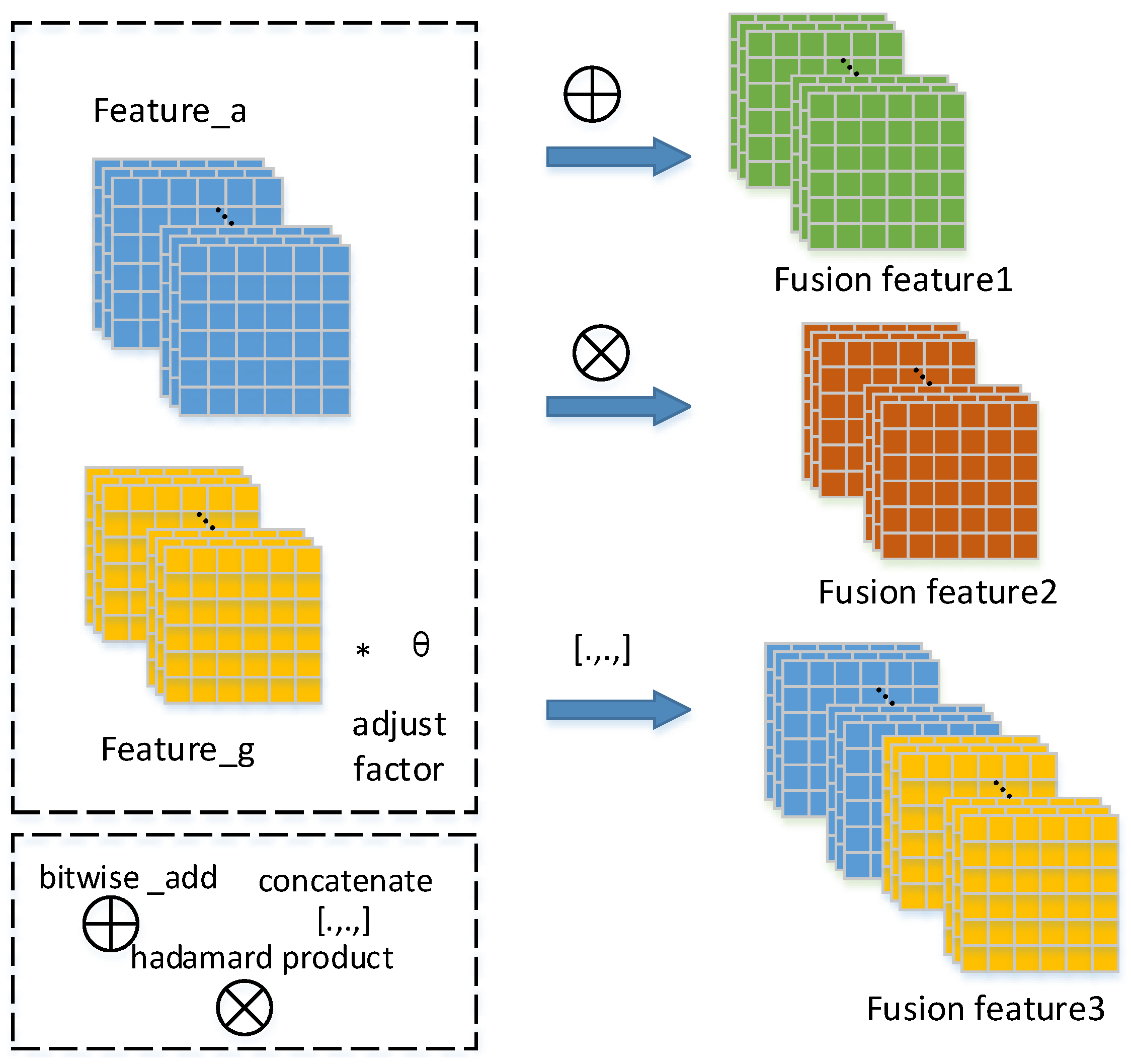
3.4. Feature-Level Fusion
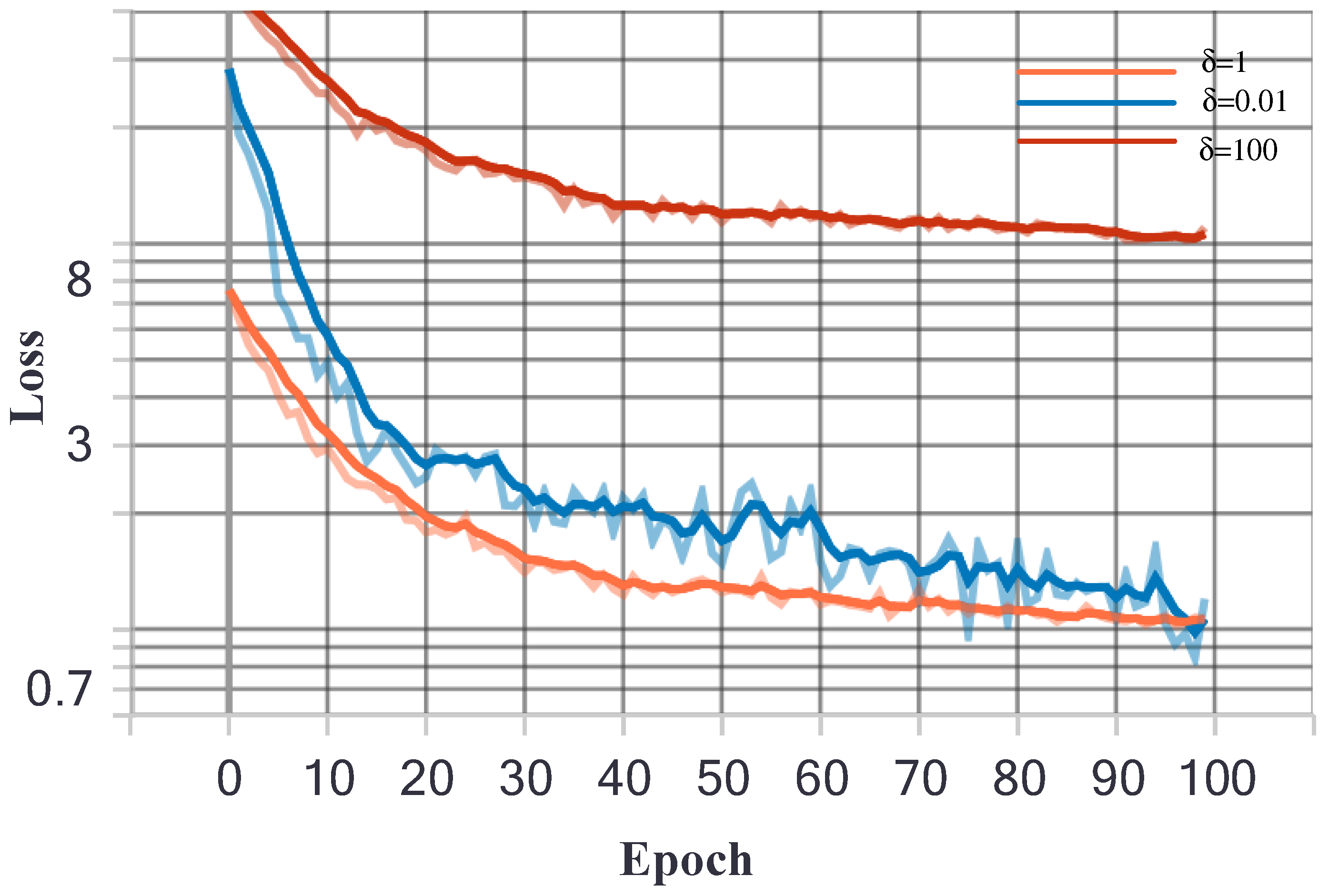
3.5. Loss Function
4. Results and Discussion
4.1. Datasets
4.2. Implementation Details
4.2.1. Model Parameters and Evaluate Metric
4.2.2. Performance on Balanced Coefficients of Total Loss Function
4.2.3. Feature Visualization
4.2.4. Performance on Adjustment Factor
4.2.5. Performance on Different Fusion Methods
4.3. Ablation Study
4.4. Comparison with the State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ISMAEI | Improved Sobel Masking Active Energy Image |
| Re-ID | Re-Identification |
| GEI | Gait Energy Image |
| AEI | Active Energy Image |
| CNN | convolutional Neural Network |
| LL | Low-Low |
| LH | Low-High |
| HL | High-Low |
References
- Cho, Y.J.; Kim, S.A.; Park, J.H.; Lee, K.; Yoon, K.J. Joint person re-identification and camera network topology inference in multiple cameras. Comput. Vis. Image Underst. 2019, 180, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Yaghoubi, E.; Kumar, A.; Proença, H. Sss-pr: A short survey of surveys in person re-identification. Pattern Recognit. Lett. 2021, 143, 50–57. [Google Scholar] [CrossRef]
- Ming, Z.; Zhu, M.; Wang, X.; Zhu, J.; Cheng, J.; Gao, C.; Yang, Y.; Wei, X. Deep learning-based person re-identification methods: A survey and outlook of recent works. Image Vis. Comput. 2022, 119, 104394. [Google Scholar] [CrossRef]
- Qian, X.; Wang, W.; Zhang, L.; Zhu, F.; Fu, Y.; Xiang, T.; Jiang, Y.G.; Xue, X. Long-term cloth-changing person re-identification. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Hong, P.; Wu, T.; Wu, A.; Han, X.; Zheng, W.S. Fine-grained shape-appearance mutual learning for cloth-changing person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 10513–10522. [Google Scholar]
- Shu, X.; Li, G.; Wang, X.; Ruan, W.; Tian, Q. Semantic-guided pixel sampling for cloth-changing person re-identification. IEEE Signal Process. Lett. 2021, 28, 1365–1369. [Google Scholar] [CrossRef]
- Jin, X.; He, T.; Zheng, K.; Yin, Z.; Shen, X.; Huang, Z.; Feng, R.; Huang, J.; Hua, X.S.; Chen, Z. Cloth-changing person re-identification from a single image with gait prediction and regularization. arXiv 2021, arXiv:2103.15537. [Google Scholar]
- Zhang, S.; Wang, Y.; Chai, T.; Li, A.; Jain, A.K. RealGait: Gait Recognition for Person Re-Identification. arXiv 2022, arXiv:2201.04806. [Google Scholar]
- Li, S.; Zhang, M.; Liu, W.; Ma, H.; Meng, Z. Appearance and Gait-Based Progressive Person Re-Identification for Surveillance Systems. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–7. [Google Scholar]
- Wu, J.; Huang, Y.; Wu, Q.; Gao, Z.; Zhao, J.; Huang, L. Dual-Stream Guided-Learning via a Priori Optimization for Person Re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 17, 1–22. [Google Scholar] [CrossRef]
- Bedagkar-Gala, A.; Shah, S.K. Gait-Assisted Person Re-identification in Wide Area Surveillance. In Computer Vision—ACCV 2014 Workshops; Springer International Publishing: Cham, Switzerland, 2015; pp. 633–649. [Google Scholar]
- Liu, Z.; Zhang, Z.; Wu, Q.; Wang, Y. Enhancing person re-identification by integrating gait biometric. Neurocomputing 2015, 168, 1144–1156. [Google Scholar] [CrossRef]
- Baltieri, D.; Vezzani, R.; Cucchiara, R. 3dpes: 3d people dataset for surveillance and forensics. In Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, Scottsdale, AZ, USA, 1 December 2011; pp. 59–64. [Google Scholar]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person re-identification by video ranking. In Computer Vision—ECCV 2014, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 688–703. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 152–159. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Hofmann, M.; Geiger, J.; Bachmann, S.; Schuller, B.; Rigoll, G. The TUM Gait from Audio, Image and Depth (GAID) database: Multimodalß recognition of subjects and traits. J. Vis. Commun. Image Represent. 2014, 25, 195–206. [Google Scholar] [CrossRef]
- Gheissari, N.; Sebastian, T.B.; Hartley, R. Person Reidentification Using Spatiotemporal Appearance. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1–6. [Google Scholar]
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In Computer Vision—ECCV 2008, Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2018; Springer: Berlin/Heidelberg, Germany, 2008; pp. 262–275. [Google Scholar]
- Prosser, B.J.; Zheng, W.S.; Gong, S.; Xiang, T.; Mary, Q. Person re-identification by support vector ranking. BMVC 2010, 2, 6. [Google Scholar]
- Zheng, W.S.; Gong, S.; Xiang, T. Reidentification by relative distance comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 653–668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, A.J.; Yuen, P.C.; Li, J. Domain transfer support vector ranking for person re-identification without target camera label information. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3567–3574. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S.; Mary, Q. Person re-identification by attributes. BMVC 2012, 2, 8. [Google Scholar]
- Su, C.; Yang, F.; Zhang, S.; Tian, Q.; Davis, L.S.; Gao, W. Multi-task learning with low rank attribute embedding for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3739–3747. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Ling, H.; Huang, K. A richly annotated dataset for pedestrian attribute recognition. arXiv 2016, arXiv:1603.07054. [Google Scholar]
- Geng, M.; Wang, Y.; Xiang, T.; Tian, Y. Deep transfer learning for person re-identification. arXiv 2016, arXiv:1611.05244. [Google Scholar]
- Wu, S.; Chen, Y.C.; Li, X.; Wu, A.C.; You, J.J.; Zheng, W.S. An enhanced deep feature representation for person re-identification. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1249–1258. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6036–6046. [Google Scholar]
- Kalayeh, M.M.; Basaran, E.; Gökmen, M.; Kamasak, M.E.; Shah, M. Human semantic parsing for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1062–1071. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Jing, S.; Tang, X. Spindle Net: Person Re-identification with Human Body Region Guided Feature Decomposition and Fusion. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–6. [Google Scholar]
- Varior, R.R.; Shuai, B.; Lu, J.; Xu, D.; Wang, G. A siamese long short-term memory architecture for human re-identification. In Computer Vision—ECCV 2016, Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 135–153. [Google Scholar]
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Jiang, W.; Zhang, C.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. Glad: Global-local-alignment descriptor for pedestrian retrieval. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 420–428. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2138–2147. [Google Scholar]
- Nambiar, A.; Bernardino, A.; Nascimento, J.C. Gait-based person re-identification: A survey. ACM Comput. Surv. 2019, 52, 1–34. [Google Scholar] [CrossRef]
- John, V.; Englebienne, G.; Krose, B. Person Re-identification Using Height-based Gait In Colour Depth Camera. In Proceedings of the 2013 20th IEEE Internationnal Conference On Image Processing (ICIP 2013), Melbourne, Australia, 15–18 September 2013; pp. 3345–3349. [Google Scholar]
- Castro, F.M.; Marín-Jimenez, M.J.; Medina-Carnicer, R. Pyramidal fisher motion for multiview gait recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1692–1697. [Google Scholar]
- Nambiar, A.; Nascimento, J.C.; Bernardino, A.; Santos-Victor, J. Person re-identification in frontal gait sequences via histogram of optic flow energy image. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 250–262. [Google Scholar]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person re-identification by discriminative selection in video ranking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2501–2514. [Google Scholar] [CrossRef]
- Wei, L.; Tian, Y.; Wang, Y.; Huang, T. Swiss-system based cascade ranking for gait-based person re-identification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 23. [Google Scholar]
- Fendri, E.; Chtourou, I.; Hammami, M. Gait-based person re-identification under covariate factors. Pattern Anal. Appl. 2019, 22, 1629–1642. [Google Scholar] [CrossRef]
- Chtourou, I.; Fendri, E.; Hammami, M. Person re-identification based on gait via Part View Transformation Model under variable covariate conditions. J. Vis. Commun. Image Represent. 2021, 77, 103093. [Google Scholar] [CrossRef]
- Bouchrika, I.; Carter, J.N.; Nixon, M.S. Towards automated visual surveillance using gait for identity recognition and tracking across multiple non-intersecting cameras. Multimed. Tools Appl. 2016, 75, 1201–1221. [Google Scholar] [CrossRef]
- Josinski, H.; Michalczuk, A.; Kostrzewa, D.; Świtonski, A.; Wojciechowski, K. Heuristic Method of Feature Selection for Person Re-identification Based on Gait Motion Capture Data. In Computer Vision—ACCV 2014 Workshops; Springer: Singapore, 2014; pp. 585–594. [Google Scholar]
- Balazia, M.; Sojka, P. You are how you walk: Uncooperative MOCAP gait identification for video surveillance with incomplete and noisy data. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 208–215. [Google Scholar]
- Xu, S.; Liu, C.; Zhang, B.; Lü, J.; Guo, G.; Doermann, D. BiRe-ID: Binary Neural Network for Efficient Person Re-ID. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, L.; Wei, Z.; Nie, J. Appearance feature enhancement for person re-identification. Expert Syst. Appl. 2021, 163, 113771. [Google Scholar] [CrossRef]
- Li, X.; Zhang, T.; Zhao, X.; Sun, X.; Yi, Z. Learning fused features with parallel training for person re-identification. Knowl.-Based Syst. 2021, 220, 106941. [Google Scholar] [CrossRef]
- Gao, J.; Nevatia, R. Revisiting temporal modeling for video-based person reid. arXiv 2018, arXiv:1805.02104. [Google Scholar]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 316–322. [Google Scholar] [CrossRef]
- Zhang, E.; Zhao, Y.; Xiong, W. Active energy image plus 2DLPP for gait recognition. Signal Process. 2010, 90, 2295–2302. [Google Scholar] [CrossRef]
- Leon, G.; Takeo, K. Fusion, Confidence Level. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 583–593. [Google Scholar]
- Ross, A. Fusion, Feature-Level. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 597–602. [Google Scholar]
- Noore, A.; Singh, R.; Vasta, M. Fusion, Sensor-Level. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 616–621. [Google Scholar]
- Kawai, R.; Makihara, Y.; Hua, C.; Iwama, H.; Yagi, Y. Person re-identification using view-dependent score-level fusion of gait and color features. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2694–2697. [Google Scholar]
- Jiang, J.; Jin, K.; Qi, M.; Wang, Q.; Wu, J.; Chen, C. A Cross-Modal Multi-granularity Attention Network for RGB-IR Person Re-identification. Neurocomputing 2020, 406, 59–67. [Google Scholar] [CrossRef]
- Wang, X.; Doretto, G.; Sebastian, T.; Rittscher, J.; Tu, P. Shape and appearance context modeling. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sets | Conditions | Covariates | IDs | Sequences (Probe Set|Gallery Set) | View Angles (Probe Set|Gallery Set) | ||
|---|---|---|---|---|---|---|---|
| Training set | Complex condition | NM, CL, BG | 1-84 | NM01-NM06, BG01-BG02, CL01-CL02 | 0– | ||
| N, B, S, TN, TB, TS | 1-20 | N1-N6, B1-B2, S1-S2, TN1-TN6, TB1-TB2, TS1-TS2 | |||||
| Testing set | Single condition | NM-NM | 85-124 | NM01, NM02 | NM05, NM06 | 0– | |
| Cross conditions | CL-NM | 85-124 | CL01, CL02 | NM05, NM06 | 0– | ||
| BG-NM | 85-124 | BG01, BG02 | NM05, NM06 | 0– | |||
| CL-BG | 85-124 | CL01, CL02 | BG01, BG02 | 0– | |||
| Long-term condition | (TB, TN, TS)-(N) | 21-32 | TN5, TN6, TB1, TB2, TS1,TS2 | N1-N6 | |||
| Conditions | NM-NM | CL-NM | BG-NM | CL-BG | ||
|---|---|---|---|---|---|---|
| Rank-1 (%) | ||||||
| Ratios δ | ||||||
| 1 | 98.2 | 68.5 | 67.5 | 66.9 | ||
| 0.01 | 87.2 | 66.7 | 60.3 | 60.1 | ||
| 100 | 74.1 | 60.1 | 57.9 | 56.4 | ||
| Conditions | CL-NM | BG-NM | CL-BG | (TB, TN, TS)-N | ||
|---|---|---|---|---|---|---|
| mAP (%) | ||||||
| Methods | ||||||
| Bitwise add | 70.1 | 68.6 | 65.4 | 64.7 | ||
| Hardmard product | 69.2 | 65.3 | 64.1 | 60.1 | ||
| Concatenate | 77.7 | 73.3 | 72.5 | 70.9 | ||
| Conditions | NM-NM | CL-NM | BG-NM | CL-BG | (TB, TN, TS)-N | ||
|---|---|---|---|---|---|---|---|
| mAP (%) | |||||||
| Methods | |||||||
| ResNet50TP + L2 | 96.0 | 51.1 | 40.8 | 49.7 | 48.1 | ||
| ISMAEI + L2 | 54.5 | 53.7 | 55.1 | 58.55 | 71.1 | ||
| GEI+ResNet50TP + L2 | 97.1 | 57.6 | 63.1 | 60.1 | 74.9 | ||
| proposed method | 98.2 | 63.5 | 67.4 | 66.5 | 82.1 | ||
| Methods | Rank-n Matching Accuracy (%) | mAP (%) | |||
|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | Rank-20 | ||
| EIGB (feature-level) [13] | 25.5 | 45.1 | 62.7 | 78.4 | 23.1 |
| SSCR [45] | 67.3 | 87.1 | 91.2 | 93.2 | 60.7 |
| HFEI [43] | 59.1 | 79.1 | 85.7 | 95.1 | 56.3 |
| DSHP [46] | 52.4 | 78.2 | 85.5 | 93.5 | 51.5 |
| DG-Net [39] | 66.9 | 88.1 | 89.9 | 92.7 | 62.9 |
| PVTM [47] | 60.1 | 71.2 | 87.5 | 94.5 | 59.2 |
| Proposed Method | 74.2 | 87.5 | 91.7 | 94.2 | 72.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Li, X.; Sheng, W.; Ge, S.S. Long-Term Person Re-Identification Based on Appearance and Gait Feature Fusion under Covariate Changes. Processes 2022, 10, 770. https://doi.org/10.3390/pr10040770
Lu X, Li X, Sheng W, Ge SS. Long-Term Person Re-Identification Based on Appearance and Gait Feature Fusion under Covariate Changes. Processes. 2022; 10(4):770. https://doi.org/10.3390/pr10040770
Chicago/Turabian StyleLu, Xiaoyan, Xinde Li, Weijie Sheng, and Shuzhi Sam Ge. 2022. "Long-Term Person Re-Identification Based on Appearance and Gait Feature Fusion under Covariate Changes" Processes 10, no. 4: 770. https://doi.org/10.3390/pr10040770
APA StyleLu, X., Li, X., Sheng, W., & Ge, S. S. (2022). Long-Term Person Re-Identification Based on Appearance and Gait Feature Fusion under Covariate Changes. Processes, 10(4), 770. https://doi.org/10.3390/pr10040770