1. Introduction
Achieving a good level of profit requires a well-prepared production plan, settings, and optimized usage of available resources in production operations. In many services and industries (such as logistics, manufacturing [
1], and health services [
2]), one of the challenging problems with wide applications in the industrial and production field is the cutting problem. In particular, finding the best way to trim raw materials in order to manufacture finished goods while maintaining the maximum profit and minimizing the environmental effect is difficult in the manufacturing industry. The cutting problem has been tackled to solve various real-life manufacturing cases. These include, among others, applications in coronary stent manufacturing [
2], the glass manufacturing industry [
3], silicon steel coil manufacturing [
4], paper production processes [
5], green manufacturing [
6], plastic rolls manufacturing [
7], multiple manufacturing modes applied to construction industry [
8], and TFT-LCD manufacturing [
9].
In the cutting stock problem, a set of items with specified dimensions must be cut from an available raw material to meet the required demand. The problem and its variants are in strong connection to real field applications in cutting processes. One variant of the problem consists of the two-level strip-cutting problem (hereinafter 2D-SCP). The 2D-SCP is theoretically equivalent to the two-dimensional strip packing problem (2D-SPP). The difference between the two versions is explained by the data structure of the instances related to the two problems and from the different developed methods to solve them. In fact, cutting instances are known by the high demand for items (high multiplicity factor) while the packing instances have generally unitary or small demands (low multiplicity factor). Thus, in some cases, the developed algorithms to solve cutting instances may not solve the packing case efficiently and vice versa [
1].
Formally, the 2D-SCP can be described as follows: a set of rectangular items
with width
, height
and demand
are to be cut from a strip with fixed width W. In the context of two-dimensional cutting problems, Lodi et al. [
10] introduced the following classification of the 2D-SCP based on the items’ orientation and the cutting types (guillotine/non-guillotine).
RF: Rotation of items by 90° is allowed (R) and no guillotine restriction is imposed (F)
RG: Rotation of items by 90° is allowed (R) and guillotine restriction is imposed (G)
OF: All items have a fixed orientation (O) and no guillotine restriction is imposed (F)
OG: All items have a fixed orientation (O) and guillotine restriction is imposed (G)
Our addressed problem belongs to the OG class. The guillotine cut constraint obliges the tool to cut the plate from edge to edge. Moreover, the number of cutting stages is only two. In the case of a guillotine cutting process, on one hand, increasing the number of cutting stages can reduce the waste and increase the efficiency of the cutting process. On the other hand, it increases the hardness of the problem and may cause disorder in the workshop.
In this paper, we modified the so-called graph compression technique and proposed it to enhance the arc-flow formulation of the two-dimensional strip cutting problem. The proposed compression steps reduced the size of the mathematical model that is based on arc-flow formulation. The impact of such an improvement is assessed on a large set of benchmark instances. Our experimental study shows the good performance of the compressed model where new improved lower/upper bounds are provided for open instances.
The sequel of this paper is organized as follows.
Section 2 is devoted to the literature review of the problem and highlights the most familiar solution methods. In
Section 3, three recent mathematical models presented in [
11] are described. The graph compression technique is explained and applied on the 2D-SCP through a detailed example in
Section 4.
Section 5 includes the details of the experimental studies and the analysis of the obtained results. Finally, the conclusion of the paper is considered in
Section 6.
2. Literature Review
In a pioneering work, Ref. [
12] provided a set covering formulation for different versions of the two-dimensional cutting stock problem. This has been improved by Refs. [
13,
14] who introduced one-dimensional bounded knapsacks and branch-and-bound procedures, respectively. New models and bounds have been proposed by Ref. [
15] to solve the two-dimensional bin packing problem (2BP) and the two-dimensional strip packing problem (2SP). The tightness of the proposed bounds were tested on 10 classes of instances, class 1–4 in Ref. [
10] and class 5–10 in Ref. [
16]. An effective branch-and-price algorithm associated with the generation of Chvatal–Gomory cutting planes is introduced by Ref. [
17] for the two-dimensional cutting stock problem. Better bounds obtained by decomposition techniques and constraint programming were used by Ref. [
18]. Dichotomous-based lower bounds introduced by Ref. [
19] showed good computational results in terms of optimality. An extension of the one-cut model of Ref. [
20] for the one-dimensional cutting stock problem has been performed by Ref. [
21]. Macedo et al., in Ref. [
22], extended the arc-flow model of one-dimensional case in Ref. [
23] to solve the two-dimensional cutting stock problem and obtained better results than those in Ref. [
15]. An SOS-based branch-and-price algorithm has been derived from the arc-flow formulation by Ref. [
24].
Rinaldi and Franz [
25] developed two heuristics to solve the two-dimensional strip-cutting problem with sequencing constraints. An efficient Branch-and-Price algorithm for the two-dimensional cutting stock and the two-dimensional strip-packing problems has been developed by Ref. [
26]. Another column generation-based algorithm is presented by Ref. [
27] with a set covering formulation of the two dimensional level strip packing problem. Mrad [
28] developed a strong arc-flow model for the two-stage guillotine strip cutting problem. Bezerra et al. Ref. [
11] proposed three mathematical formulations to solve the 2D-SCP that turned out to be very sensitive to the structure of the considered instances. A hybrid heuristic based on new improved rules and reinforcement learning, proposed by Ref. [
29], outperformed many heuristics from the literature for the 2D-SCP. For a comprehensive review of the two-dimensional cutting and packing problems, the reader may refer to the recent paper of Ref. [
30].
3. State-of-the-Art Mathematical Models
In this section, the most recent mathematical models from literature for the 2D-SCP are presented. The literature stated the high flexibility of using a formulation of packing problem to solve the cutting version and vice versa. Three different formulations were rewritten by Ref. [
11]. The first one is based on the model of Lodi et al. [
15], while the second formulation is based on the work of Furini et al., Ref. [
31], about the two dimensional two-staged guillotine cutting stock problem with multiple stock size. The third formulation is developed based on the model of Silva et al. [
21]. An interesting model which is based on arc-flow formulation has been introduced by Ref. [
28]. The proposed model made it feasible to efficiently solve some classes of the benchmark instances of the 2D-SCP.
3.1. The Model Based on Lodi et al. [15]
To each individual item,
j is associated a shelf with height,
hj, that may include any item with height less than or equal to
hj (including item
j itself). Note that not all the defined shelves need to be used. The decision variables are therefore defined as follows:
where
denotes the total number of items. Let
with
. The proposed model can be described by the following:
The objective function (1) aims to minimize the total height used from the strip. Constraints (2) ensure that each item is placed once on its own level or on a higher level. Constraints (3) oblige the width of any level to be enough to include all the assigned items. Constraint (4) is related to the objective function and forces its value to be larger or equal to the total used height. Constraints (5) and (6) are two valid inequalities of the two-dimensional knapsack problem that were introduced by Ref. [
32]. The purpose of these two inequalities is to break symmetry that might occur in the solution. The model (1)–(7) is denoted by
M1
ineq.
3.2. The Model Based on Furini et al. [31]
The same method of cutting items into shelves, as explained in
M1
ineq, is adopted for this model. The latter is introduced by Ref. [
31] for the two-dimensional two-staged guillotine cutting stock problem with multiple stock size. In addition to the decision variables
xjk, a continuous decision variable
yk is included that represents the height of shelf
k (
. The model is formulated as follows:
The objective function (8) minimizes the total height
used to cut all items. Constraint (9) assures that the total height of the shelves is less than or equal to the used strip height
. Constraints (10) state that the total width of shelves should be less than or equal to the strip width
. Constraints (11) amount to the initialization of each shelf
, which means that a shelf
is initialized by cutting item
. Constraints (12) ensure that the height of each item which is cut from shelf
k should be smaller than or equal to the height
. Constraints (13) and (14) are valid inequalities that were introduced by Ref. [
31] to enhance their formulation. Inequality (13) ensures that the overall area of items placed in shelf
k is smaller than the area of the shelf
. Inequality (14) prevents the occurrence of symmetry, where the shelves are sorted in increasing order. The model (8)–(16) is denoted by
M2
ineq.
3.3. The Model Based on Silva et al. [21]
In fact, cutting one item produces two residual boards: the right residual board and the top residual board. For each item, the model checks iteratively the possibility of cutting some other items from the corresponding residual boards (see Example 1). Thus, all cuts and residual boards are known in advance.
Let
be the set of all residual boards. Note that for each
, the residual boards with height and width
are such that
. In addition,
N designates the subset of
B which dimensions are equal to one of the items. The model variables are:
The model can then be formulated as follows:
The objective function (17) minimizes the total consumed height H defined by (18). Constraints (19) ensure the demand satisfaction. In constraints (20) and (21), the number of residual boards obtained from cutting board i is greater than or equal to the number of cut items from board i. The difference between (20) and (21) is that in (20), the residual boards from item i still offer possible cutting smaller items. Finally, the domain of decision variables is given in (22). The model (17)–(22) is denoted by M3.
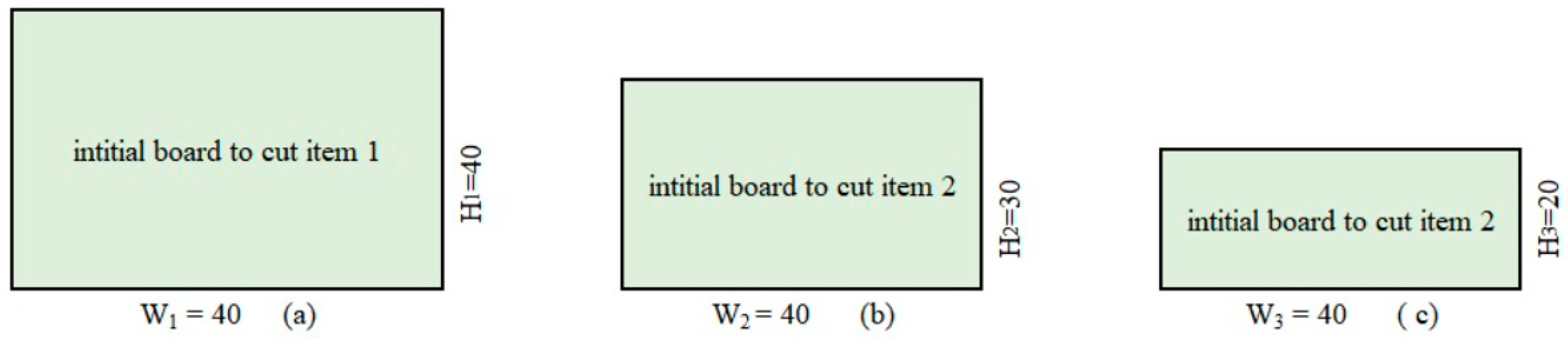
Example 1. Consider a strip with an infinite height and fixed width W = 20. Three items are to be cut from the strip. The height and width (,) of each item j are presented in Table 1.
The first phase is to establish all initial boards by applying a horizontal cut for each item
. In this cutting phase, three boards are initialized. As shown in
Figure 1, boards (a), (b) and (c) correspond to items 1, 2 and 3, respectively.
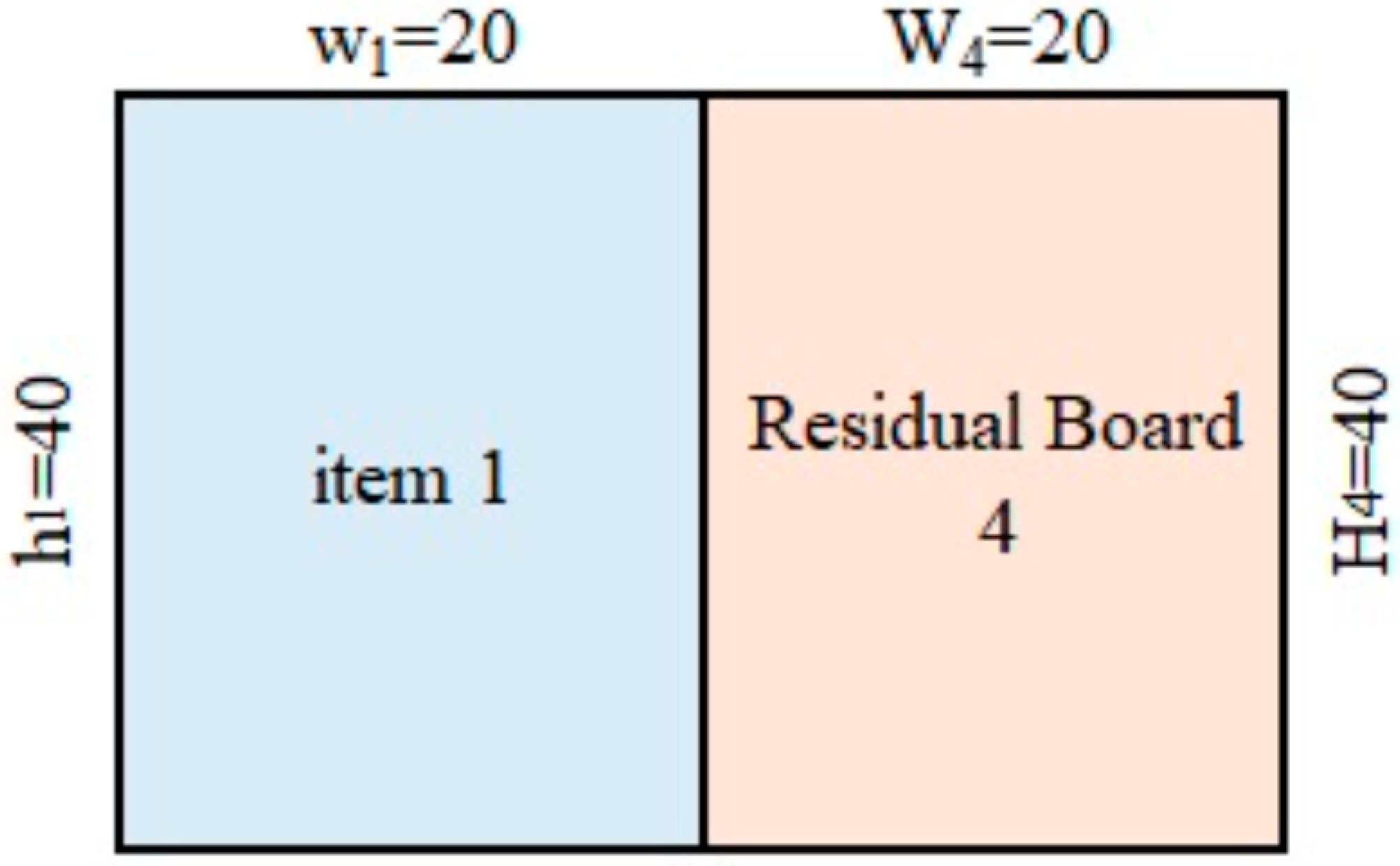
Then, we proceed by cutting board (a) to produce item 1 with
and a residual board with
. This generates the variable
and means that item 1 is cut from initial board 0. In addition to the
variable, a parameter
is generated and means that a new board of type 4 is created (see
Figure 2). The same step is applied to obtain item 2 with
. In
Figure 1, a vertical cut of board (b) will generate
and a parameter
. Then, a residual board type 5 is generated with
. The same process generates for item 3 a variable
and a parameter
.
For all the generated residual boards, a step for fitting items into residual boards is applied. For example, consider board type 4
, which is generated in cutting phase 1. It is applicable to cut item 2 and to generate
and parameter
(see
Figure 3). All of these generations related to cuts and residual boards could be implemented by using the algorithm in [
21]. This algorithm is used by [
11] to only generate right residual boards, while in [
21] they generate both top and right residual boards.
3.4. The Model of Mrad [28]
Mrad [
28] extended the model introduced in Ref. [
22] and used the graph technique in Ref. [
23] to solve the 2D-SCP, where the items are cut through two stages. In the first stage, the strip is cut into shelves, denoted by
for each item
k. In the second stage, each shelf is cut to produce the required items. Clearly, for each shelf
, a subset of items
could be cut. Thus, the cutting of items in set
could be presented as a path in a specific graph as introduced in Ref. [
23]. For each shelf
, a graph
is constructed where
is the set of vertices and
is the set of arcs. Actually, any path in
, between nodes 0 and
W, represents a sequence of no-overlapping items, which total width is less than or equal to
W. This path amounts to a cutting pattern. Algorithm 1 is used to build the graphs
. Interestingly, the following simple breaking-symmetry rules significantly reduce the size of the graphs:
The items are ordered according to a decreasing order of their widths.
In each shelf, any path must include an item with the same height as the shelf.
The number of occurrences of an item in a path cannot exceed its own demand.
| Algorithm 1. Graph Construction Algorithm |
| Let M be a matrix with W + 1 rows and columns. Where is the number of items in the set . M[i][j] takes 0 if it is allowed to build an arc representing item j and starting from node i and 1 otherwise. |
| 1: M[i][j] 0 |
| 2: |
| 3: |
| 4: |
| 5: M[i][j] 1 |
| 6: end for |
| 7: end for |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: r 0 |
| 13: do |
| 14: if M[][i] = 0 do |
| 15: |
| 16: M[][i]=1 |
| 17: |
| 18: end if |
| 19: |
| 20: |
| 21: end while |
| 22: |
| 23: |
| 24: |
| 25: |
| 26:
|
| 27:
|
| 28: end if |
| 29: end for |
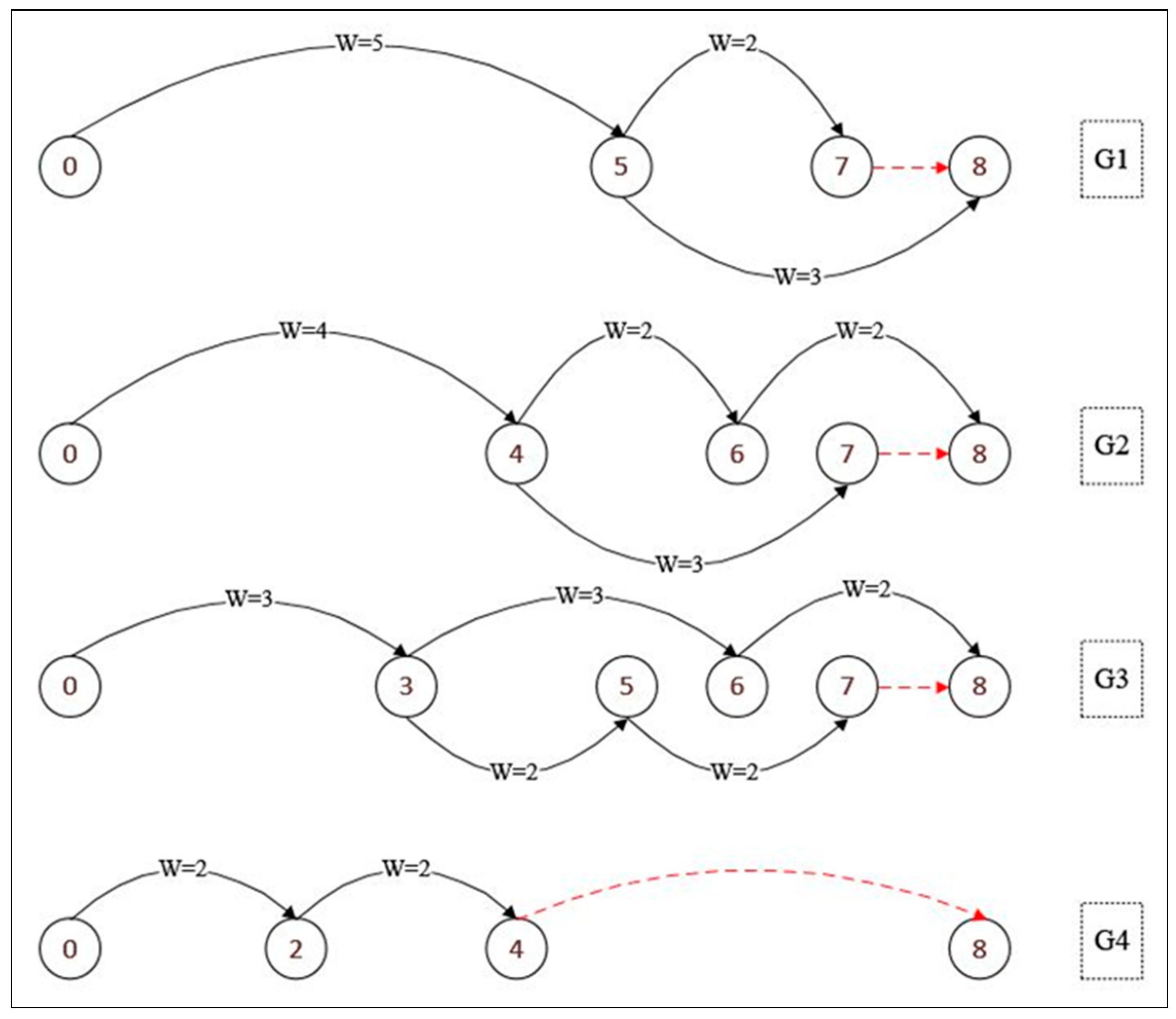
Example 2. Consider a strip with width W = 8 and infinite height H, and a set of four items I1 (7, 5, 2), I2 (6, 4, 1), I3 (5, 3, 2) and I4 (4, 2, 2) (where I (h, w, d) denotes an item I of height h, width w and demand d). Four shelves 1, 2, 3 and 4 are then required to be used in the second stage. Figure 4 depicts the corresponding four graphs G1, G2, G3 and G4, generated by Algorithm 1. In each graph, each non-dashed arc represents an associated item. Dashed arcs represent dummy items (waste material) and are added in order to respect the path between the source node and the target node. For a given shelf k, denote by the set of different item heights in . Let be an integer variable associated to each arc (a,b) ∈ that takes the number of items of width (b−a) and height ∈ placed at position from the beginning of shelf k. This variable represents the flow on the arc associated to the item of height in the graph . For example, for shelf 3, we have and Consider the arc (5,7) in graph , then the variable (resp. ) denotes the number of items of width 8 − 6 = 2 and height 5 (resp. 4) placed at position 6 from the beginning of shelf 3.
Consider the decision variable
that represents the total flow on the graph corresponding to the
. The arc flow-based mathematical formulation of the 2D-SCP is the following:
The objective function (23) consists of minimizing the total height used from the strip. Constraints (24) correspond to the flow conservation equality. That is, the value of the flow leaving each node b ∈ {1,2, …, W − 1} in any graph must be equal to the value of the flow entering this node. In addition, the flow leaving node 0 must be equal to the flow entering node W. Constraints (25) imply that the demand of each item should be satisfied, i.e., the total number of cut items of j ∈ {1, …, n} from any (k = 1, …, n) should be larger than or equal to the demand of this item. This mathematical formulation is strongly related to the structure of the proposed graphs and presents the strip-cutting problem as a minimum cost multi-flow problem with uncapacitated arcs and additional demand constraints. The model (23)–(27) is denoted by Arc_Flow.
4. Application of the Graph Compression Technique to the 2D-SCP
In this section, we introduce the graph compression technique that we applied to the arc flow-based model for the 2D-SCP. Our experimental results showed a substantial improvement of the performance of this model through applying this technique.
The graph compression method is introduced by Ref. [
33] to decrease the resulting large size graphs related to the arc-flow formulation of the one-dimensional packing and cutting problems. It proved a substantial saving in the computational effort required to solve hard packing problems. Based on Ref. [
33], the implementation of graph compression on HARD4 instances in Ref. [
34] leads to 97% and 95% reduction in the number of nodes and arcs, respectively. Thus, the reduction of graph size can significantly hit the time needed by MIP solvers.
The graph compression requires at least two stages: Breaking Symmetry and Compression. In the first stage, the symmetry of the existing graph is broken. In fact, graphs delivered by Algorithm 1 may include different paths that represent the same cutting pattern. Example 3 explains the occurrence of similar cutting patterns.
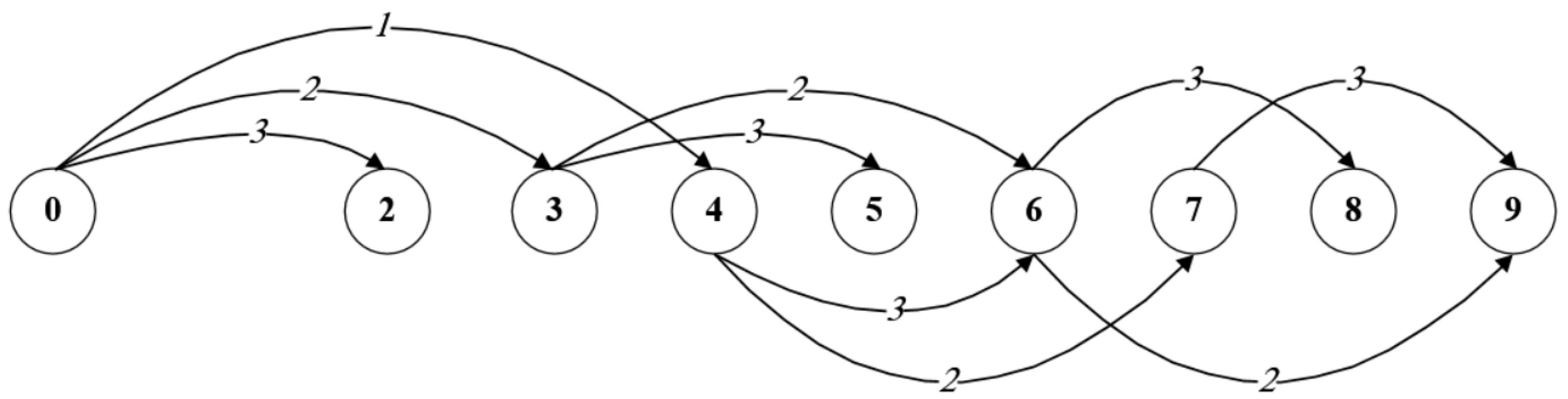
Example 3. Consider a strip with width W = 9 and infinite height H, and a set of three items I1 (5, 4, 1), I2 (5, 3, 3) and I3 (3, 2, 1) (using the same notations of Example 2). Figure 5 shows the graph corresponding to h = 5 (without dummy arcs). Clearly, the two paths 0-4-6-9 and 0-4-7-9 represent the same cutting pattern.
An easy way to break symmetry is to devote a level to each item. Then, the so-called level graph is built in a manner that only arcs related to a given item are added in its level. Each path in the level graph is devoted to a different pattern (see Example 4). Once the level graph is ready, the second step (compression step) can be applied. For that purpose, we introduce for each node
u the so-called labeling function
which amounts to the length of the longest path between nodes 0 and
. Let
denote the size of the item represented by the arc (
u,
v),
T denote the node representing the width of the strip
W in the last level of the level graph, and
S denote the source node representing 0 in the first level. Then, the formula of
is given by the following equation:
Now, each node u in the level graph is translated to the node in the compressed graph. Moreover, each arc (u,v) in the level graph will be replaced by (,) in the compressed graph. Interestingly, the nodes having the same label can be combined into one single node leading to a substantial reduction of the graph size. Indeed, if = then the two nodes u and v will be represented by only one node in the compressed graph and the arc (u,v) will not be considered in the compressed graph. In addition, many different arcs in the level graph may be represented by only one arc in the compressed graph. Thus, the number of arcs and nodes will be potentially reduced.
It is worth noting that the recursive function (28) is applied on the nodes of the level graph after being sorted in the decreasing topological order. Once the compressed graph is obtained, a second round of compression can be applied. In this case, the reverse topological order of the compressed graph is considered and the following recursive function
is used:
Since the arc-flow formulation of the 2D-SCP requires n different graphs (one graph for each shelf), then the compression is applied on each graph independently. The resulting graphs with a reduced size will potentially require less variables and constraints in the formulation. Consequently, the solving time can be enhanced. Example 4 is illustrating the breaking symmetry and the main compression step on the graph of each shelf in the case of the 2D-SCP. For the sake of simplicity, we only considered the first compression round.
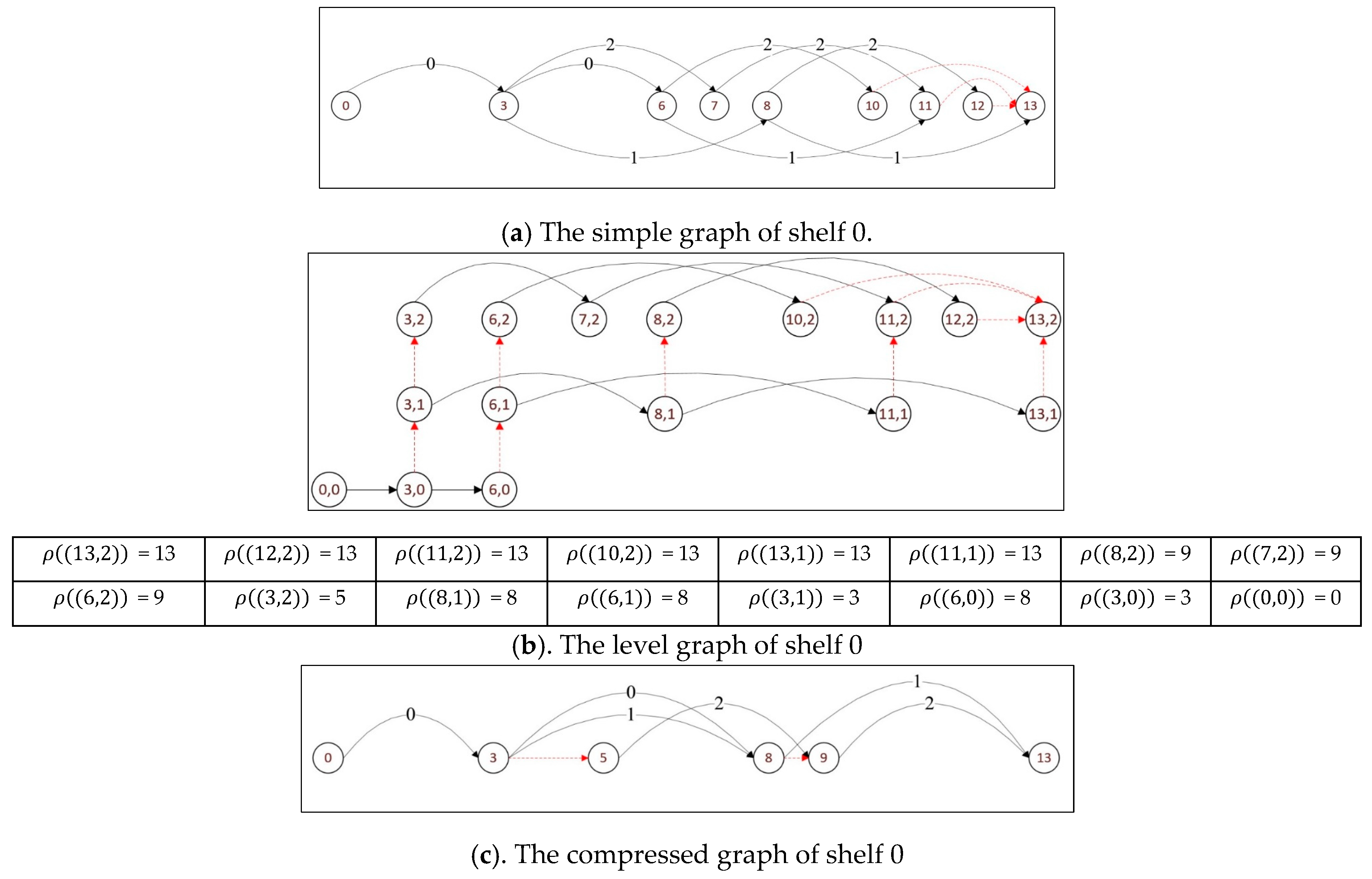
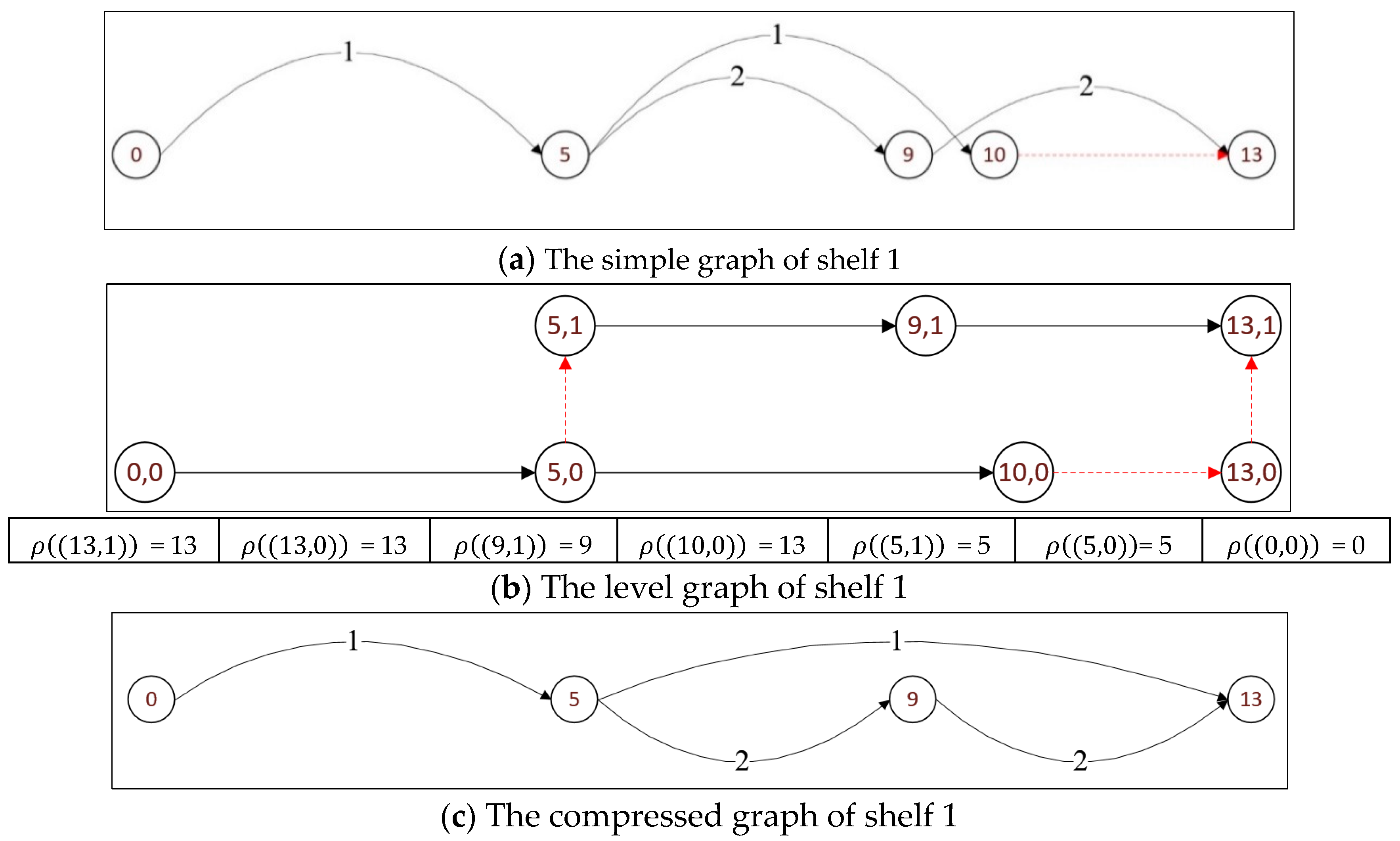
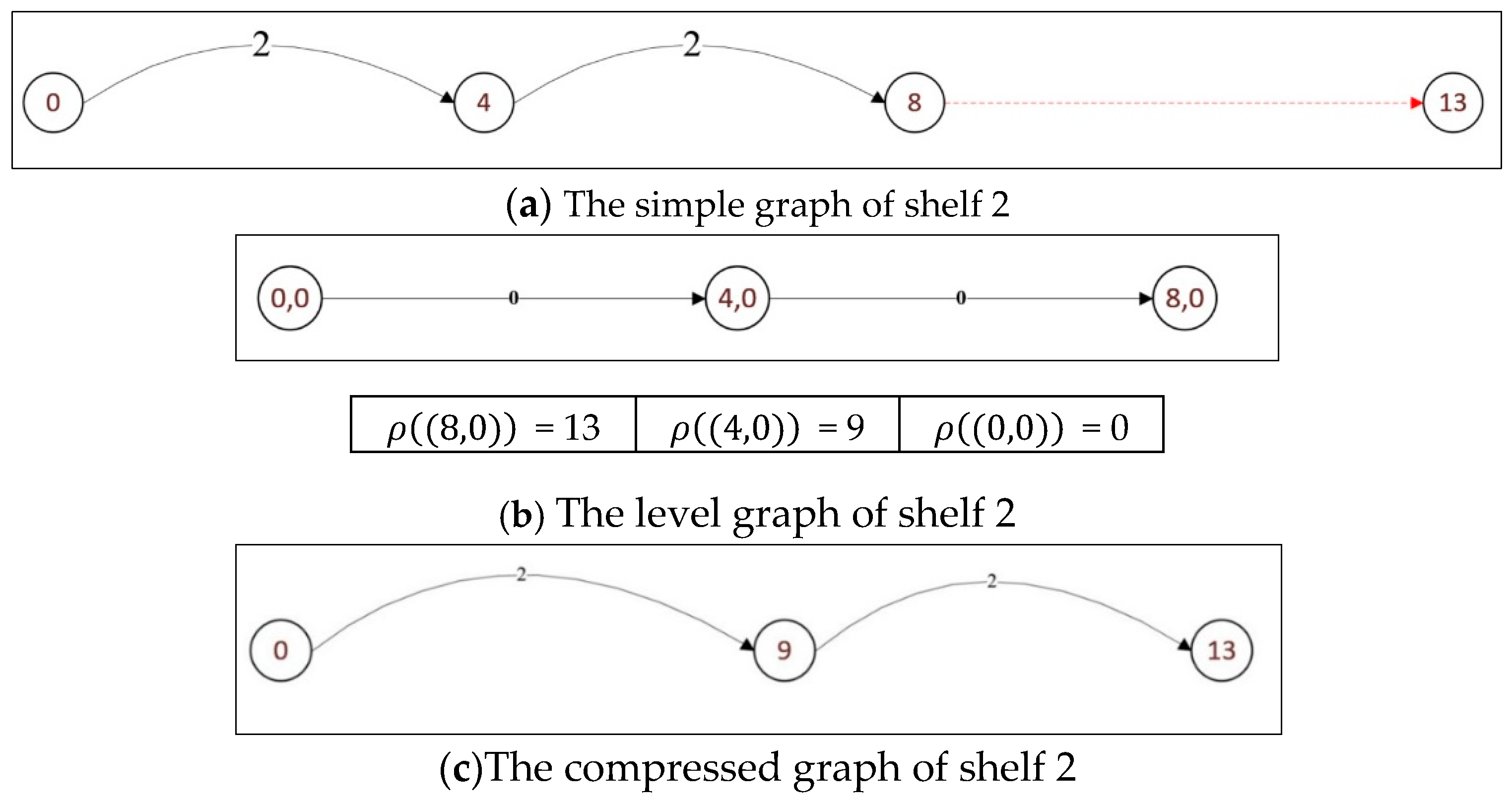
Example 4. Consider an instance with a roll of width and three items to be cut as shown in Table 2. Algorithm 1 is applied to construct the graph related to each resulting strip. Figure 6, Figure 7 and Figure 8 display the simple graph, the level graph and compressed graph for shelves 0, 1 and 2, respectively. 5. Computational Experiments
5.1. The Benchmark Instances
We assessed the three models
M1
ineq,
M2
ineq and
M3 as well as the proposed arc-flow formulation with graph compression for the two-dimensional strip-cutting problem. We considered the five sets of benchmark instances, utilized by Ref. [
11], to evaluate the performance of the mentioned models. We describe these sets as follows:
Set 1 consists of 21 instances proposed by Ref. [
35]. These are distributed in seven categories C1… C7 and three types P1, P2, P3. All the item demands are equal to one. The number of items and the strip width for each problem are shown in
Table 3.
Set 2 consists of 16 instances with unitary item demands, three of them (cgcut1, cgcut2, cgcut3) were used by Ref. [
36] for the two-dimensional cutting stock problem. The remaining 13 instances (gcut1,…, gcut13) are proposed by Ref. [
37] for the non-guillotine two-dimensional cutting problem.
Set 3 consists of 500 instances that are divided into 10 classes. Each class includes 50 instances where for each value of
there are 10 generated instances. Berkey and Wang [
16] introduced the first six classes, while the remaining four classes were presented in Ref. [
38]. The structure of instances and values of
and
are uniformly distributed in the listed intervals as shown in
Table 4. All the item demands are equal to one.
Set 4 contains 20 instances (ATP30,…, ATP49) that are used by Ref. [
28].
Set 5 includes 43 instances from real-world settings presented in Refs. [
21,
22].
All the models described in this paper have been coded using Cplex Concert technology under C++ environment and solved using IBM ILog Cplex 12.9 solver. All computational experiments have been carried out on a desktop with Intel (R) Core (TM) i7 4930 K CPU 3.4 GHz processor with 32 GB of memory under Windows environment. A time limit of 3600 s has been set for all the models.
5.2. Impact of the Graph Compression
The impact of graph compression on the five sets of instances has been assessed according to the following criteria:
Size reduction: it reflects the impact of the graph compression on the number of variables of the generated mathematical model. It is computed as , where n1 and n2 represent the number of variables corresponding to the non-compressed and compressed graphs, respectively.
Time ratio: it represents the ratio of the CPU time of the non-compressed model over the one of the compressed model. It indicates the impact of the graph compression on increasing/decreasing the running time.
Gap improvement: it represents the percentage gap improvement for unsolved instances. The gap is equal to , where UB and LB denote the best found upper and lower bounds, respectively. The gap improvement is computed as , where gap1 and gap2 represent the gaps obtained by the non-compressed and compressed models, respectively.
Table 5 shows the results of the graph compression impact over the five sets of instances according to the three mentioned criteria. From this table, we can see that the most significant impact is observed for Set 5 in terms of model size reduction and time ratio. Indeed, the compressed model was, on average, 60.32% smaller and 2.11 faster than the non-compressed one. Sets 1 and 3 are the least impacted ones with respect to these criteria. On the other hand, the graph compression substantially reduced the gap for the unsolved instances where some of them have been solved to optimality in Sets 3 and 4.
5.3. Comparison with the State-of-the-Art Mathematical Models
In this section, we present a comparison of the performance of the presented mathematical models in terms of percentage of solved instances (i.e., solved to optimality within the time limit of 3600 s), average computation time, average gap of unsolved instances, and performance of the linear relaxation. The latter criterion is assessed by computing the percentage of times the linear relaxation of each model equals the maximum value over all the linear relaxations of the four ones.
Table 6,
Table 7,
Table 8 and
Table 9 depict the results of the four models in terms of these criteria for each of the five sets of instances. From these tables, we observe that the compressed model provides the best results in all criteria for Sets 4 and 5 (non-unitary item demands). Moreover, it yields the second best results for Sets 1–3 (unitary item demands) in terms of percentage of solved instances and average computation time. In particular, the average computation time of our model is drastically better than those of the state-of-the-art models in Set 5. Indeed, it is 41.24 times faster than the second fastest model. Moreover,
Table 9 shows that the linear relaxation of the compressed model outperforms the three other ones in all of the five sets.
From
Table 6 and
Table 7, it can be observed that Set 4 is by far the hardest set to solve. Indeed, none of its instances has been solved by the models of the literature. The only model that makes it feasible to solve 20% of the instances is the proposed compressed model. Interestingly, by using this model we were able to substantially improve the upper/lower bounds of these hard benchmark instances, as will be detailed in the next section.
5.4. New Results for Open Benchmark Instances
In this section, we present new found upper and lower bounds for 24 unsolved benchmark instances of the two-dimensional strip cutting problem.
Table 10 shows the details of these results where
UBlit (and, respectively,
LBlit) denotes the best obtained upper (and, respectively, lower) bound in the literature [
11], and
UBnew (and, respectively,
LBnew) denotes the upper (and, respectively, lower) bound obtained by the proposed compressed model. The gap improvement is computed for each instance by
, where
Devlit =
UBlit−LBlit and
Devnew =
UBnew−LBnew. The asterisk symbol indicates that the new obtained upper/lower bound reaches the optimum.
Interestingly, all of the upper/lower bounds of the hardest set of instances (namely Set 4) have been improved (except one upper bound for instance ATP 48). Moreover, optimality was reached for four of them. Moreover, the four open benchmark instances of Set 5 have all been solved to optimality. Furthermore, we can appreciate the dramatic improvement of the gap for the displayed instances since it equals 69.82%, on average, reaching more than 96% for some unsolved ones.




 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}