
Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping



Abstract
:1. Introduction
2. Layered Multiscale kMC Modeling of a Batch Pulp Digester
- (
- (
- (
3. Surrogate Model Development and MPC Design
3.1. LSTM-ANN Network Training
3.2. LSTM-ANN-Based Model Predictive Controller Design
4. Results and Discussion
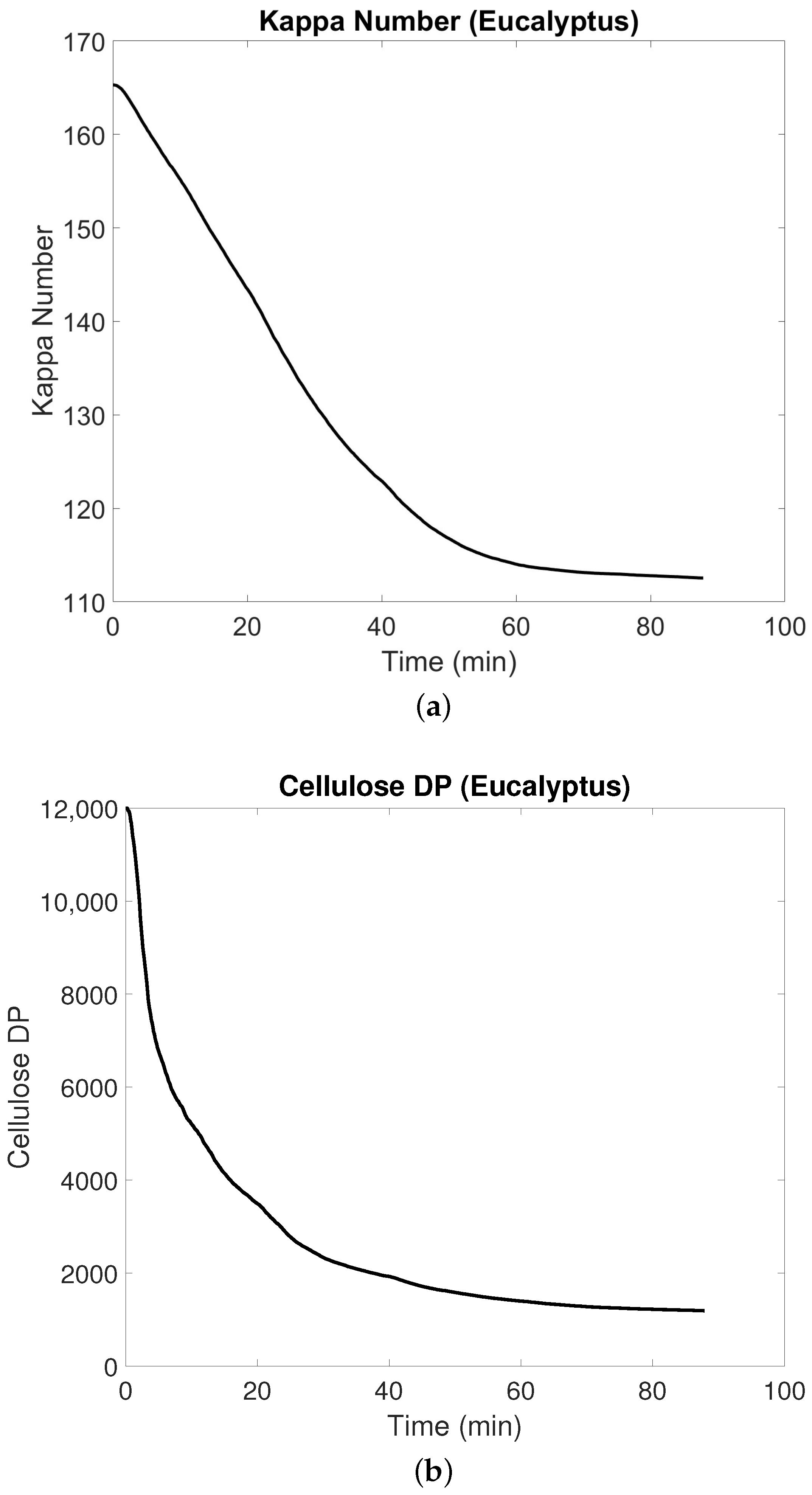
4.1. Multiscale Model
4.2. LSTM-ANN Model
4.3. LSTM-ANN-Based MPC
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- VDP-Facts about Paper 2022. Available online: https://papertoexport.com/paper-consumption-worldwide-from-2020-to-2030-2/ (accessed on 10 January 2023).
- Tsai, W.H.; Lai, S.Y. Green production planning and control model with ABC under industry 4.0 for the paper industry. Sustainability 2018, 10, 2932. [Google Scholar] [CrossRef] [Green Version]
- Pätäri, S.; Tuppura, A.; Toppinen, A.; Korhonen, J. Global sustainability megaforces in shaping the future of the European pulp and paper industry towards a bioeconomy. For. Policy Econ. 2016, 66, 38–46. [Google Scholar] [CrossRef]
- Lawrence, A.; Karlsson, M.; Thollander, P. Effects of firm characteristics and energy management for improving energy efficiency in the pulp and paper industry. Energy 2018, 153, 825–835. [Google Scholar] [CrossRef]
- Singh, A.K.; Bilal, M.; Iqbal, H.M.; Meyer, A.S.; Raj, A. Bioremediation of lignin derivatives and phenolics in wastewater with lignin modifying enzymes: Status, opportunities and challenges. Sci. Total Environ. 2021, 777, 145988. [Google Scholar] [CrossRef] [PubMed]
- Choi, H.K.; Kwon, J.S.I. Modeling and control of cell wall thickness in batch delignification. Comput. Chem. Eng. 2019, 128, 512–523. [Google Scholar] [CrossRef]
- Choi, H.K.; Kwon, J.S.I. Multiscale modeling and multiobjective control of wood fiber morphology in batch pulp digester. AIChE J. 2020, 66, e16972. [Google Scholar] [CrossRef]
- Li, J.; Gellerstedt, G. On the structural significance of the kappa number measurement. Nord. Pulp Pap. Res. J. 1998, 13, 153–158. [Google Scholar] [CrossRef]
- Hart, P.W.; Colson, G.W.; Antonsson, S.; Hjort, A. Impact of impregnation on high kappa number hardwood pulps. BioResources 2011, 6, 5139–5150. [Google Scholar]
- Alves, A.; Santos, A.; da Silva Perez, D.; Rodrigues, J.; Pereira, H.; Simoes, R.; Schwanninger, M. NIR PLSR model selection for Kappa number prediction of maritime pine Kraft pulps. Wood Sci. Technol. 2007, 41, 491–499. [Google Scholar] [CrossRef]
- Gurnagul, N.; Page, D.H.; Paice, M.G. The effect of cellulose degradation on the strength of wood pulp fibres. Nord. Pulp Pap. Res. J. 1992, 7, 152–154. [Google Scholar] [CrossRef]
- Karak, T.; Bhagat, R.; Bhattacharyya, P. Municipal solid waste generation, composition, and management: The world scenario. Crit. Rev. Environ. Sci. Technol. 2012, 42, 1509–1630. [Google Scholar] [CrossRef]
- Haile, A.; Gelebo, G.G.; Tesfaye, T.; Mengie, W.; Mebrate, M.A.; Abuhay, A.; Limeneh, D.Y. Pulp and paper mill wastes: Utilizations and prospects for high value-added biomaterials. Bioresour. Bioprocess. 2021, 8, 1–22. [Google Scholar] [CrossRef]
- Fang, Z.; Li, B.; Liu, Y.; Zhu, J.; Li, G.; Hou, G.; Zhou, J.; Qiu, X. Critical role of degree of polymerization of cellulose in super-strong nanocellulose films. Matter 2020, 2, 1000–1014. [Google Scholar] [CrossRef]
- De Silva, R.; Byrne, N. Utilization of cotton waste for regenerated cellulose fibres: Influence of degree of polymerization on mechanical properties. Carbohydr. Polym. 2017, 174, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, M.; Ferreira, P.; Figueiredo, M. Cellulose depolymerisation and paper properties in E. globulus kraft pulps. Cellulose 2000, 7, 359–368. [Google Scholar] [CrossRef]
- Rasi, M. Permeability properties of paper materials. In Research Report/Department of Physics; University of Jyväskylä: Jyväskylä, Finland, 2013. [Google Scholar]
- Abdelmouleh, M.; Boufi, S.; Belgacem, M.N.; Dufresne, A.; Gandini, A. Modification of cellulose fibers with functionalized silanes: Effect of the fiber treatment on the mechanical performances of cellulose–thermoset composites. J. Appl. Polym. Sci. 2005, 98, 974–984. [Google Scholar] [CrossRef]
- Gustafson, R.R.; Sleicher, C.A.; McKean, W.T.; Finlayson, B.A. Theoretical model of the kraft pulping process. Ind. Eng. Chem. Process Des. Dev. 1983, 22, 87–96. [Google Scholar] [CrossRef] [Green Version]
- Andersson, N.; Wilson, D.I.; Germgård, U. An improved kinetic model structure for softwood kraft cooking. Nord. Pulp Pap. Res. J. 2003, 18, 200–209. [Google Scholar] [CrossRef]
- Christensen, T. A mathematical Model of the Kraft Pulping Process; Purdue University: West Lafayette, IN, USA, 1982. [Google Scholar]
- Bhartiya, S.; Dufour, P.; Doyle III, F.J. Fundamental thermal-hydraulic pulp digester model with grade transition. AIChE J. 2003, 49, 411–425. [Google Scholar] [CrossRef] [Green Version]
- Choi, H.K.; Kwon, J.S.I. Multiscale modeling and control of Kappa number and porosity in a batch-type pulp digester. AIChE J. 2019, 65, e16589. [Google Scholar] [CrossRef]
- Son, S.H.; Choi, H.K.; Kwon, J.S.I. Multiscale modeling and control of pulp digester under fiber-to-fiber heterogeneity. Comput. Chem. Eng. 2020, 143, 107117. [Google Scholar] [CrossRef]
- Pahari, S.; Bhadriraju, B.; Akbulut, M.; Kwon, J.S.I. A slip-spring framework to study relaxation dynamics of entangled wormlike micelles with kinetic Monte Carlo algorithm. J. Colloid Interface Sci. 2021, 600, 550–560. [Google Scholar] [CrossRef] [PubMed]
- Andersen, M.; Panosetti, C.; Reuter, K. A practical guide to surface kinetic Monte Carlo simulations. Front. Chem. 2019, 7, 202. [Google Scholar] [CrossRef] [PubMed]
- Son, S.H.; Choi, H.K.; Kwon, J.S.I. Application of offset-free Koopman-based model predictive control to a batch pulp digester. AIChE J. 2021, 67, e17301. [Google Scholar] [CrossRef]
- Son, S.H.; Choi, H.K.; Moon, J.; Kwon, J.S.I. Hybrid Koopman model predictive control of nonlinear systems using multiple EDMD models: An application to a batch pulp digester with feed fluctuation. Control Eng. Pract. 2022, 118, 104956. [Google Scholar] [CrossRef]
- Dobbelaere, M.R.; Plehiers, P.P.; Van de Vijver, R.; Stevens, C.V.; Van Geem, K.M. Machine learning in chemical engineering: Strengths, weaknesses, opportunities, and threats. Engineering 2021, 7, 1201–1211. [Google Scholar] [CrossRef]
- Venkatasubramanian, V. The promise of artificial intelligence in chemical engineering: Is it here, finally? AIChE J. 2018, 65, 466–478. [Google Scholar] [CrossRef] [Green Version]
- Bhadriraju, B.; Narasingam, A.; Kwon, J.S.I. Machine learning-based adaptive model identification of systems: Application to a chemical process. Chem. Eng. Res. Des. 2019, 152, 372–383. [Google Scholar] [CrossRef]
- Pahari, S.; Moon, J.; Akbulut, M.; Hwang, S.; Kwon, J.S.I. Estimation of microstructural properties of wormlike micelles via a multi-scale multi-recommendation batch bayesian optimization. Ind. Eng. Chem. Res. 2021, 60, 15669–15678. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Thompson, M.L.; Kramer, M.A. Modeling chemical processes using prior knowledge and neural networks. AIChE J. 1994, 40, 1328–1340. [Google Scholar] [CrossRef]
- Prasad, V.; Bequette, B.W. Nonlinear system identification and model reduction using artificial neural networks. Comput. Chem. Eng. 2003, 27, 1741–1754. [Google Scholar] [CrossRef]
- Jeon, B.K.; Kim, E.J. LSTM-based model predictive control for optimal temperature set-point planning. Sustainability 2021, 13, 894. [Google Scholar] [CrossRef]
- Wu, Z.; Rincon, D.; Luo, J.; Christofides, P.D. Machine learning modeling and predictive control of nonlinear processes using noisy data. AIChE J. 2021, 67, e17164. [Google Scholar] [CrossRef]
- Shah, P.; Sheriff, M.Z.; Bangi, M.S.F.; Kravaris, C.; Kwon, J.S.I.; Botre, C.; Hirota, J. Deep neural network-based hybrid modeling and experimental validation for an industry-scale fermentation process: Identification of time-varying dependencies among parameters. Chem. Eng. J. 2022, 441, 135643. [Google Scholar] [CrossRef]
- Choi, H.K.; Kwon, J.S.I. Multiscale modeling and control of fiber length in pulp digester. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 4343–4348. [Google Scholar]
- Jung, J.; Choi, H.K.; Son, S.H.; Kwon, J.S.I.; Lee, J.H. Multiscale modeling of fiber deformation: Application to a batch pulp digester for model predictive control of fiber strength. Comput. Chem. Eng. 2022, 158, 107640. [Google Scholar] [CrossRef]
- Irle, M.A.; Barbu, M.C.; Reh, R.; Bergland, L.; Rowell, R.M. 10 Wood Composites. Handb. Wood Chem. Wood Compos. 2012, 321–411. [Google Scholar] [CrossRef]
- Van Loon, L.; Glaus, M. Review of the kinetics of alkaline degradation of cellulose in view of its relevance for safety assessment of radioactive waste repositories. J. Environ. Polym. Degrad. 1997, 5, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Pavasars, I.; Hagberg, J.; Borén, H.; Allard, B. Alkaline degradation of cellulose: Mechanisms and kinetics. J. Polym. Environ. 2003, 11, 39–47. [Google Scholar] [CrossRef]
- Kim, D.; Kim, M.; Kim, W. Wafer edge yield prediction using a combined long short-term memory and feed-forward neural network model for semiconductor manufacturing. IEEE Access 2020, 8, 215125–215132. [Google Scholar] [CrossRef]
- Kowsher, M.; Tahabilder, A.; Sanjid, M.Z.I.; Prottasha, N.J.; Uddin, M.S.; Hossain, M.A.; Jilani, M.A.K. LSTM-ANN & BiLSTM-ANN: Hybrid deep learning models for enhanced classification accuracy. Procedia Comput. Sci. 2021, 193, 131–140. [Google Scholar]
- Makris, D.; Kaliakatsos-Papakostas, M.; Karydis, I.; Kermanidis, K.L. Combining LSTM and feed forward neural networks for conditional rhythm composition. In Proceedings of the International Conference on Engineering Applications of Neural Networks; Springer: Athens, Greece, 2017; pp. 570–582. [Google Scholar]
- Feng, C.; Chang, L.; Li, C.; Ding, T.; Mai, Z. Controller optimization approach using LSTM-based identification model for pumped-storage units. IEEE Access 2019, 7, 32714–32727. [Google Scholar] [CrossRef]
- Schwedersky, B.B.; Flesch, R.C.; Dangui, H.A. Practical nonlinear model predictive control algorithm for long short-term memory networks. IFAC-PapersOnLine 2019, 52, 468–473. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]
- Shah, P.; Sheriff, M.Z.; Bangi, M.S.F.; Kravaris, C.; Kwon, J.S.I.; Botre, C.; Hirota, J. Multi-rate observer design and optimal control to maximize productivity of an industry-scale fermentation process. AIChE Journal 2022, 69, e17946. [Google Scholar] [CrossRef]
- Narasingam, A.; Kwon, J.S. Development of local dynamic mode decomposition with control: Application to model predictive control of hydraulic fracturing. Comput. Chem. Eng. 2017, 106, 501–511. [Google Scholar] [CrossRef]
- Pahari, S.; Moon, J.; Akbulut, M.; Hwang, S.; Kwon, J.S.I. Model predictive control for wormlike micelles (WLMs): Application to a system of CTAB and NaCl. Chem. Eng. Res. Des. 2021, 174, 30–41. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. LSTM and GRU neural networks as models of dynamical processes used in predictive control: A comparison of models developed for two chemical reactors. Sensors 2021, 21, 5625. [Google Scholar] [CrossRef] [PubMed]
- Yunpeng, L.; Di, H.; Junpeng, B.; Yong, Q. Multi-step ahead time series forecasting for different data patterns based on LSTM recurrent neural network. In Proceedings of the 2017 14th web information systems and applications conference (WISA), Liuzhou, China, 11–12 November 2017; pp. 305–310. [Google Scholar]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Khiari, R.; Mhenni, M.; Belgacem, M.; Mauret, E. Chemical composition and pulping of date palm rachis and Posidonia oceanica–A comparison with other wood and non-wood fibre sources. Bioresour. Technol. 2010, 101, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Mishra, S. Bleaching of Cellulosic Paper Fibres with Ozone-Effect on the Fibre Properties; Institut Polytechnique de Grenoble: Grenoble, France, 2010. [Google Scholar]
- Mansouri, S.; Khiari, R.; Bendouissa, N.; Saadallah, S.; Mhenni, F.; Mauret, E. Chemical composition and pulp characterization of Tunisian vine stems. Ind. Crop. Prod. 2012, 36, 22–27. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Probabilities | Depolymerization Mechanism |
|---|---|
| Peeling-off (Null event) | |
| Stopping (Null event) | |
| Cellulose chain scission event |
| Species | Cellulose | Kappa Number | ||
|---|---|---|---|---|
| Experiment | Model | Experiment | Model | |
| Eucalyptus | 1399 | 1342 | 8.7 | 11.4 |
| Date Palm Rachis | 1203 | 1174 | 54 | 52.6 |
| Pinus Radiata | 1423 | 1368 | 10.6 | 10.8 |
| Mean error | 4% | Mean error | 8% | |
| Serial No. | Layers | Nodes | Batch Size | Dropout Rate | Kappa | |
|---|---|---|---|---|---|---|
| 1 | 2 | 20 | 16 | 0.2 | 0.942 | 0.884 |
| 2 | 2 | 40 | 32 | 0.4 | 0.957 | 0.901 |
| 3 | 3 | 40 | 16 | 0.5 | 0.995 | 0.985 |
| 4 | 3 | 20 | 32 | 0.2 | 0.982 | 0.944 |
| 5 | 3 | 40 | 32 | 0 | 0.998 | 0.992 |
| 6 | 3 | 10 | 16 | 0 | 0.975 | 0.954 |
| 7 | 3 | 40 | 16 | 0.8 | 0.926 | 0.895 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, P.; Choi, H.-K.; Kwon, J.S.-I. Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping. Processes 2023, 11, 809. https://doi.org/10.3390/pr11030809
Shah P, Choi H-K, Kwon JS-I. Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping. Processes. 2023; 11(3):809. https://doi.org/10.3390/pr11030809
Chicago/Turabian StyleShah, Parth, Hyun-Kyu Choi, and Joseph Sang-Il Kwon. 2023. "Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping" Processes 11, no. 3: 809. https://doi.org/10.3390/pr11030809
APA StyleShah, P., Choi, H. -K., & Kwon, J. S. -I. (2023). Achieving Optimal Paper Properties: A Layered Multiscale kMC and LSTM-ANN-Based Control Approach for Kraft Pulping. Processes, 11(3), 809. https://doi.org/10.3390/pr11030809