
Benefits and Limitations of Artificial Neural Networks in Process Chromatography Design and Operation


Abstract
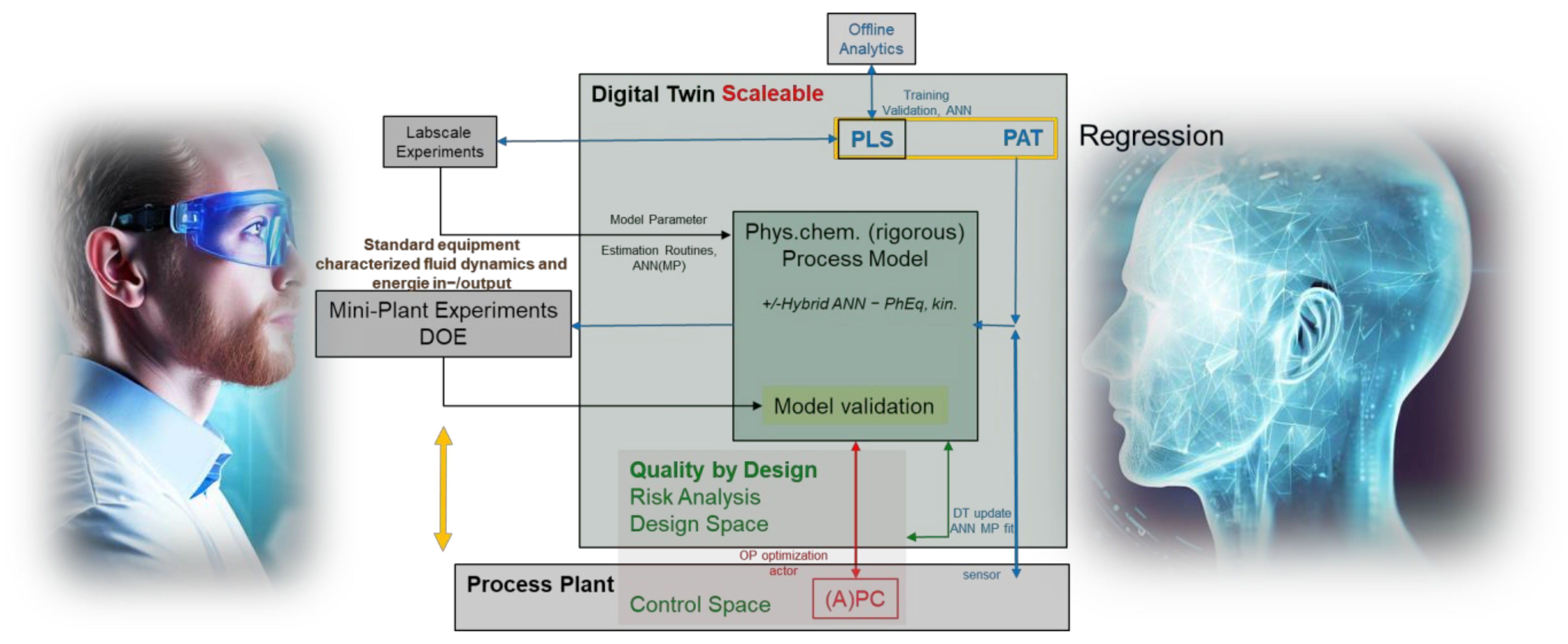
:1. Introduction
2. Materials and Methods
2.1. Chromatography Modeling
2.2. Dataset
2.3. ANN Development
3. Results
3.1. Time-Stamp Method (TSM)
3.2. Fit Parameter Method
4. Discussion
5. Conclusion
- ANN can serve as a valuable alternative to regression for PAT data or design and control space data interpolations, but alternative statistical methods have to be checked as unrealistic and inconsistent phenomena could occur based on overfitting;
- The regression of a model parameter for manufacturing data digital twin adjustment to actual reality by ANN is a valid tool. For model parameter determination in process development, alternatives like minimization of the sum of least square errors have been more efficient until now, utilizing about 1–6 chromatograms;
- Machine learning cannot prove root causes mathematically. Therefore, in a regulatory environment, it is of no final use;
- High data amounts are needed, which need to be generated via validated mechanistic models, as experimental setups would be unrealistic efforts;
- Hybrid models with isothermal ANNs can circumvent high data amounts and/or missing process knowledge but still require mechanistic models. No application is known where any known isotherm up to modified SMA does not describe the phenomenon well. Applications based on 1–6 chromatograms are documented, which is the most efficient;
- Standard operation mode data may not supply the necessary information to train ANNs if complex phenomena of buffer and component interference need to be described. Specially designed experimental plans would be needed, which contradict any manufacturing operation tasks;
- The use of machine learning for process development and control presents a contradiction, as it relies on training on ready-to-use validated mechanistic models that are still often used with prejudice in industry;
- Even computationally demanding tasks in process control can be acceptably fulfilled with standard control methods like linearization around the operation point or methods based on deep process comprehension. This leads to economical business case-derived decisions;
- The benefits and effort of machine learning have to be evaluated and compared with alternative methods at each application and project step individually. They are not general problem solvers, and expert knowledge is still needed to evaluate results.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- International Electrotechnical Commission. OPC Unified Architecture, 2020 (IEC TR 62541). Available online: https://webstore.iec.ch/publication/68039 (accessed on 7 February 2023).
- Drath, R.; Horch, A. Industrie 4.0: Hit or Hype? [Industry Forum]. EEE Ind. Electron. Mag. 2014, 8, 56–58. [Google Scholar] [CrossRef]
- Uhlemann, T.H.-J.; Schock, C.; Lehmann, C.; Freiberger, S.; Steinhilper, R. The Digital Twin: Demonstrating the Potential of Real Time Data Acquisition in Production Systems. Procedia Manuf. 2017, 9, 113–120. [Google Scholar] [CrossRef]
- Legner, C.; Eymann, T.; Hess, T.; Matt, C.; Böhmann, T.; Drews, P.; Mädche, A.; Urbach, N.; Ahlemann, F. Digitalization: Opportunity and Challenge for the Business and Information Systems Engineering Community. Bus. Inf. Syst. Eng. 2017, 59, 301–308. [Google Scholar] [CrossRef]
- Sokolov, M.; von Stosch, M.; Narayanan, H.; Feidl, F.; Butté, A. Hybrid modeling—A key enabler towards realizing digital twins in biopharma? Curr. Opin. Chem. Eng. 2021, 34, 100715. [Google Scholar] [CrossRef]
- Sinner, P.; Daume, S.; Herwig, C.; Kager, J. Usage of Digital Twins Along a Typical Process Development Cycle. Adv. Biochem. Eng. Biotechnol. 2021, 176, 71–96. [Google Scholar] [CrossRef]
- Helgers, H.; Hengelbrock, A.; Schmidt, A.; Strube, J. Digital Twins for Continuous mRNA Production. Processes 2021, 9, 1967. [Google Scholar] [CrossRef]
- Udugama, I.A.; Lopez, P.C.; Gargalo, C.L.; Li, X.; Bayer, C.; Gernaey, K.V. Digital Twin in biomanufacturing: Challenges and opportunities towards its implementation. Syst. Microbiol. Biomanuf. 2021, 1, 257–274. [Google Scholar] [CrossRef]
- Sixt, M.; Uhlenbrock, L.; Strube, J. Toward a Distinct and Quantitative Validation Method for Predictive Process Modelling—On the Example of Solid-Liquid Extraction Processes of Complex Plant Extracts. Processes 2018, 6, 66. [Google Scholar] [CrossRef] [Green Version]
- Zobel-Roos, S.; Schmidt, A.; Mestmäcker, F.; Mouellef, M.; Huter, M.; Uhlenbrock, L.; Kornecki, M.; Lohmann, L.; Ditz, R.; Strube, J. Accelerating Biologics Manufacturing by Modeling or: Is Approval under the QbD and PAT Approaches Demanded by Authorities Acceptable without a Digital-Twin? Processes 2019, 7, 94. [Google Scholar] [CrossRef] [Green Version]
- Uhl, A.; Schmidt, A.; Hlawitschka, M.W.; Strube, J. Autonomous Liquid–Liquid Extraction Operation in Biologics Manufacturing with Aid of a Digital Twin including Process Analytical Technology. Processes 2023, 11, 553. [Google Scholar] [CrossRef]
- International CounCil for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use. ICH-Endorsed Guide for ICH Q8/Q9/Q10 Implementation, 6 December. Available online: https://database.ich.org/sites/default/files/Q8_Q9_Q10_Q%26As_R4_Points_to_Consider_0.pdf (accessed on 7 February 2023).
- Uhlenbrock, L.; Jensch, C.; Tegtmeier, M.; Strube, J. Digital Twin for Extraction Process Design and Operation. Processes 2020, 8, 866. [Google Scholar] [CrossRef]
- Carta, G.; Rodrigues, A.E. Diffusion and convection in chromatographic processes using permeable supports with a bidisperse pore structure. Chem. Eng. Sci. 1993, 48, 3927–3935. [Google Scholar] [CrossRef]
- Guiochon, G. Preparative liquid chromatography. J. Chromatogr. A 2002, 965, 129–161. [Google Scholar] [CrossRef]
- Guiochon, G. Fundamentals of Preparative and Nonlinear Chromatography, 2nd ed.; Elsevier Academic Press: Amsterdam, The Netherlands, 2006; ISBN 978-0123705372. [Google Scholar]
- Mollerup, J.M. A Review of the Thermodynamics of Protein Association to Ligands, Protein Adsorption, and Adsorption Isotherms. Chem. Eng. Technol. 2008, 31, 864–874. [Google Scholar] [CrossRef]
- Seidel-Morgenstern, A.; Guiochon, G. Modelling of the competitive isotherms and the chromatographic separation of two enantiomers. Chem. Eng. Sci. 1993, 48, 2787–2797. [Google Scholar] [CrossRef]
- Von Lieres, E.; Schnittert, S.; Püttmann, A.; Leweke, S. Chromatography Analysis and Design Toolkit (CADET). Chem. Ing. Tech. 2014, 86, 1626. [Google Scholar] [CrossRef]
- Beal, L.; Hill, D.; Martin, R.; Hedengren, J. GEKKO Optimization Suite. Processes 2018, 6, 106. [Google Scholar] [CrossRef] [Green Version]
- Zobel-Roos, S.; Mouellef, M.; Siemers, C.; Strube, J. Process Analytical Approach towards Quality Controlled Process Automation for the Downstream of Protein Mixtures by Inline Concentration Measurements Based on Ultraviolet/Visible Light (UV/VIS) Spectral Analysis. Antibodies 2017, 6, 24. [Google Scholar] [CrossRef] [Green Version]
- Mouellef, M.; Vetter, F.L.; Zobel-Roos, S.; Strube, J. Fast and Versatile Chromatography Process Design and Operation Optimization with the Aid of Artificial Intelligence. Processes 2021, 9, 2121. [Google Scholar] [CrossRef]
- Gao, W.; Engell, S. Neural Network-Based Identification of Nonlinear Adsorption Isotherms. IFAC Proc. Vol. 2004, 37, 721–726. [Google Scholar] [CrossRef]
- Brestrich, N.; Briskot, T.; Osberghaus, A.; Hubbuch, J. A tool for selective inline quantification of co-eluting proteins in chromatography using spectral analysis and partial least squares regression. Biotechnol. Bioeng. 2014, 111, 1365–1373. [Google Scholar] [CrossRef] [PubMed]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Bergés, R.; Sanz-Nebot, V.; Barbosa, J. Modelling retention in liquid chromatography as a function of solvent composition and pH of the mobile phase. J. Chromatogr. A 2000, 869, 27–39. [Google Scholar] [CrossRef] [PubMed]
- D’Archivio, A.A.; Incani, A.; Ruggieri, F. Cross-column prediction of gas-chromatographic retention of polychlorinated biphenyls by artificial neural networks. J. Chromatogr. A 2011, 1218, 8679–8690. [Google Scholar] [CrossRef]
- Golubović, J.; Protić, A.; Zečević, M.; Otašević, B.; Mikić, M. Artificial neural networks modeling in ultra performance liquid chromatography method optimization of mycophenolate mofetil and its degradation products. J. Chemom. 2014, 28, 567–574. [Google Scholar] [CrossRef]
- Madden, J.E.; Avdalovic, N.; Haddad, P.R.; Havel, J. Prediction of retention times for anions in linear gradient elution ion chromatography with hydroxide eluents using artificial neural networks. J. Chromatogr. A 2001, 910, 173–179. [Google Scholar] [CrossRef]
- Nagrath, D.; Messac, A.; Bequette, B.W.; Cramer, S.M. A hybrid model framework for the optimization of preparative chromatographic processes. Biotechnol. Prog. 2004, 20, 162–178. [Google Scholar] [CrossRef]
- Pirrung, S.M.; van der Wielen, L.A.M.; van Beckhoven, R.F.W.C.; van de Sandt, E.J.A.X.; Eppink, M.H.M.; Ottens, M. Optimization of biopharmaceutical downstream processes supported by mechanistic models and artificial neural networks. Biotechnol. Prog. 2017, 33, 696–707. [Google Scholar] [CrossRef]
- Marengo, E.; Gianotti, V.; Angioi, S.; Gennaro, M. Optimization by experimental design and artificial neural networks of the ion-interaction reversed-phase liquid chromatographic separation of twenty cosmetic preservatives. J. Chromatogr. A 2004, 1029, 57–65. [Google Scholar] [CrossRef]
- Malenović, A.; Jančić-Stojanović, B.; Kostić, N.; Ivanović, D.; Medenica, M. Optimization of Artificial Neural Networks for Modeling of Atorvastatin and Its Impurities Retention in Micellar Liquid Chromatography. Chromatographia 2011, 73, 993–998. [Google Scholar] [CrossRef]
- Morse, G.; Jones, R.; Thibault, J.; Tezel, F.H. Neural network modelling of adsorption isotherms. Adsorption 2011, 17, 303–309. [Google Scholar] [CrossRef]
- Gobburu, J.V.S.; Shelver, W.L.; Shelver, W.H. Application of Artificial Neural Networks in the Optimization of HPLC Mobile-Phase Parameters. J. Liq. Chromatogr. 2006, 18, 1957–1972. [Google Scholar] [CrossRef]
- Mouellef, M.; Szabo, G.; Vetter, F.L.; Siemers, C.; Strube, J. Artificial Neural Network for Fast and Versatile Model Parameter Adjustment Utilizing PAT Signals of Chromatography Processes for Process Control under Production Conditions. Processes 2022, 10, 709. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, Y. Estimating adsorption isotherm parameters in chromatography via a virtual injection promoting double feed-forward neural network. J. Inverse Ill-Posed Probl. 2020, 30, 693–712. [Google Scholar] [CrossRef]
- Anderson, R.; Biong, A.; Gómez-Gualdrón, D.A. Adsorption Isotherm Predictions for Multiple Molecules in MOFs Using the Same Deep Learning Model. J. Chem. Theory Comput. 2020, 16, 1271–1283. [Google Scholar] [CrossRef]
- Wang, G.; Briskot, T.; Hahn, T.; Baumann, P.; Hubbuch, J. Estimation of adsorption isotherm and mass transfer parameters in protein chromatography using artificial neural networks. J. Chromatogr. A 2017, 1487, 211–217. [Google Scholar] [CrossRef]
- Wang, G.; Briskot, T.; Hahn, T.; Baumann, P.; Hubbuch, J. Root cause investigation of deviations in protein chromatography based on mechanistic models and artificial neural networks. J. Chromatogr. A 2017, 1515, 146–153. [Google Scholar] [CrossRef]
- Mahmoodi, F.; Darvishi, P.; Vaferi, B. Prediction of coefficients of the Langmuir adsorption isotherm using various artificial intelligence (AI) techniques. J. Iran. Chem. Soc. 2018, 15, 2747–2757. [Google Scholar] [CrossRef]
- Narayanan, H.; Seidler, T.; Luna, M.F.; Sokolov, M.; Morbidelli, M.; Butté, A. Hybrid Models for the simulation and prediction of chromatographic processes for protein capture. J. Chromatogr. A 2021, 1650, 462248. [Google Scholar] [CrossRef]
- Narayanan, H.; Luna, M.; Sokolov, M.; Arosio, P.; Butté, A.; Morbidelli, M. Hybrid Models Based on Machine Learning and an Increasing Degree of Process Knowledge: Application to Capture Chromatographic Step. Ind. Eng. Chem. Res. 2021, 60, 10466–10478. [Google Scholar] [CrossRef]
- Subraveti, S.G.; Li, Z.; Prasad, V.; Rajendran, A. Can a computer “learn” nonlinear chromatography?: Physics-based deep neural networks for simulation and optimization of chromatographic processes. J. Chromatogr. A 2022, 1672, 463037. [Google Scholar] [CrossRef] [PubMed]
- Santana, V.V.; Gama, M.S.; Loureiro, J.M.; Rodrigues, A.E.; Ribeiro, A.M.; Tavares, F.W.; Barreto, A.G.; Nogueira, I.B.R. A First Approach towards Adsorption-Oriented Physics-Informed Neural Networks: Monoclonal Antibody Adsorption Performance on an Ion-Exchange Column as a Case Study. ChemEngineering 2022, 6, 21. [Google Scholar] [CrossRef]
- Subraveti, S.G.; Li, Z.; Prasad, V.; Rajendran, A. Physics-Based Neural Networks for Simulation and Synthesis of Cyclic Adsorption Processes. Ind. Eng. Chem. Res. 2022, 61, 4095–4113. [Google Scholar] [CrossRef]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lagaris, I.E.; Likas, A.C.; Papageorgiou, D.G. Neural-network methods for boundary value problems with irregular boundaries. IEEE Trans. Neural Netw. 2000, 11, 1041–1049. [Google Scholar] [CrossRef] [Green Version]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Fausett, L.V. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Prentice Hall: Englewood Cliffs, NJ, USA, 1994; ISBN 0-13-334186-0. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA; London, UK, 2016; ISBN 978-0262035613. [Google Scholar]
- Bolanca, T.; Cerjan-Stefanović, S.; Regelja, M.; Regelja, H.; Loncarić, S. Application of artificial neural networks for gradient elution retention modelling in ion chromatography. J. Sep. Sci. 2005, 28, 1427–1433. [Google Scholar] [CrossRef]
- Natarajan, V.; Bequette, B.W.; Cramer, S.M. Optimization of ion-exchange displacement separations. I. Validation of an iterative scheme and its use as a methods development tool. J. Chromatogr. A 2000, 876, 51–62. [Google Scholar] [CrossRef]
- Langmuir, I. The adsorption of gases on plane surfaces of glass, mica and platinum. J. Am. Chem. Soc. 1918, 40, 1361–1403. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.H.; Yue, B.F.; Ni, J.Y.; Zhou, H.F.; Zhang, Y.K. Application of an artificial neural network in chromatography—Retention behavior prediction and pattern recognition. Chemom. Intell. Lab. Syst. 1999, 45, 163–170. [Google Scholar] [CrossRef]
- Vetter, F.L.; Strube, J. Need for a Next Generation of Chromatography Models—Academic Demands for Thermodynamic Consistency and Industrial Requirements in Everyday Project Work. Processes 2022, 10, 715. [Google Scholar] [CrossRef]
- Nfor, B.K.; Noverraz, M.; Chilamkurthi, S.; Verhaert, P.D.E.M.; van der Wielen, L.A.M.; Ottens, M. High-throughput isotherm determination and thermodynamic modeling of protein adsorption on mixed mode adsorbents. J. Chromatogr. A 2010, 1217, 6829–6850. [Google Scholar] [CrossRef] [PubMed]
- Vetter, F.L.; Zobel-Roos, S.; Strube, J. PAT for Continuous Chromatography Integrated into Continuous Manufacturing of Biologics towards Autonomous Operation. Processes 2021, 9, 472. [Google Scholar] [CrossRef]
- Wilson, E.J.; Geankoplis, C.J. Liquid Mass Transfer at Very Low Reynolds Numbers in Packed Beds. Ind. Eng. Chem. Fund. 1966, 5, 9–14. [Google Scholar] [CrossRef]
- Hunt, S.; Larsen, T.; Todd, R.J. Modeling Preparative Cation Exchange Chromatography of Monoclonal Antibodies. In Preparative Chromatography for Separation of Proteins; Staby, A., Rathore, A.S., Ahuja, S., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2017; pp. 399–427. ISBN 9781119031116. [Google Scholar]
- Schmidt, A.; Helgers, H.; Vetter, F.L.; Juckers, A.; Strube, J. Digital Twin of mRNA-Based SARS-COVID-19 Vaccine Manufacturing towards Autonomous Operation for Improvements in Speed, Scale, Robustness, Flexibility and Real-Time Release Testing. Processes 2021, 9, 748. [Google Scholar] [CrossRef]
- Li, J. Development and evaluation of flexible empirical peak functions for processing chromatographic peaks. Anal. Chem. 1997, 69, 4452–4462. [Google Scholar] [CrossRef]
- Keras. Available online: https://keras.io (accessed on 19 December 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Available online: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf (accessed on 19 December 2021).
- Van Rossum, G. The Python Language Reference; release 3.0.1 [repr.]; Python Software Foundation; SoHo Books: Hampton, NH, USA; Redwood City, CA, USA, 2010; ISBN 1441412697. [Google Scholar]
- Raybaut, P. Spyder-Documentation. 2009. Available online: https://www.spyder-ide.org/ (accessed on 1 April 2023).
- O’Malley, T.; Burzstein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. Keras Tuner. Available online: https://github.com/keras-team/kerastuner (accessed on 1 April 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference of Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/pdf/1412.6980 (accessed on 19 December 2021).
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:1706.02515. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn.Res. 2014, 15, 1929–1958. [Google Scholar]
- Xu, C.; Zhang, Y. Estimating Adsorption Isotherm Parameters in Chromatography via a Virtual Injection Promoting Feed-forward Neural Network. arXiv 2021, arXiv:2102.00389. [Google Scholar]
- Strube, J. Technische Chromatographie: Auslegung, Optimierung, Betrieb und Wirtschaftlichkeit; Zugleich: Dortmund, Universität., Habilitationsschreiben., 1999; Als Manuskript gedruckt; Shaker: Aachen, Germany, 2000; ISBN 3-8265-6897-4. [Google Scholar]
- Zobel-Roos, S. Entwicklung, Modellierung und Validierung von Integrierten Kontinuierlichen Gegenstrom-Chromatographie-Prozessen. Ph.D. Thesis, Technische Universität Clausthal, Clausthal-Zellerfeld, Germany, 2018. [Google Scholar]
- Altenhöner, U.; Meurer, M.; Strube, J.; Schmidt-Traub, H. Parameter estimation for the simulation of liquid chromatography. J. Chromatogr. A 1997, 769, 59–69. [Google Scholar] [CrossRef]
- Wiesel, A.; Schmidt-Traub, H.; Lenz, J.; Strube, J. Modelling gradient elution of bioactive multicomponent systems in non-linear ion-exchange chromatography. J. Chromatogr. A 2003, 1006, 101–120. [Google Scholar] [CrossRef]
- U.S. Department of Health and Human Services. Guidance for Industry PAT-A Framework for Innovative Pharmaceutical Development, Manufacturing, and Quality Assurance; Food and Drug Administration: Rockville, MD, USA, 2004.
- Glassey, J.; Gernaey, K.V.; Clemens, C.; Schulz, T.W.; Oliveira, R.; Striedner, G.; Mandenius, C.-F. Process analytical technology (PAT) for biopharmaceuticals. Biotechnol. J. 2011, 6, 369–377. [Google Scholar] [CrossRef] [Green Version]
- Arabzadeh, V.; Sohrabi, M.R. Artificial neural network and multivariate calibration methods assisted UV spectrophotometric technique for the simultaneous determination of metformin and Pioglitazone in anti-diabetic tablet dosage form. Chemom. Intell. Lab. Syst. 2022, 221, 104475. [Google Scholar] [CrossRef]
- Takahashi, M.B.; Leme, J.; Caricati, C.P.; Tonso, A.; Fernández Núñez, E.G.; Rocha, J.C. Artificial neural network associated to UV/Vis spectroscopy for monitoring bioreactions in biopharmaceutical processes. Bioprocess Biosyst. Eng. 2015, 38, 1045–1054. [Google Scholar] [CrossRef]
- Lunze, J. Regelungstechnik 2: Mehrgrößensysteme, Digitale Regelung; 6., neu bearbeitete Aufl.; Springer: Berlin, Germany, 2010; ISBN 978-3-642-10197-7. [Google Scholar]
- Dittmar, R. Advanced Process Control: PID-Basisregelungen, Vermaschte Regelungsstrukturen, Softsensoren, Model Predictive Control; De Gruyter Oldenbourg: München, Germany; Wien, Austria, 2017; ISBN 978-3-11-049957-5. [Google Scholar]
- Schramm, H.; Kienle, A.; Kaspereit, M.; Seidel-Morgenstern, A. Improved operation of simulated moving bed processes through cyclic modulation of feed flow and feed concentration. Chem. Eng. Sci. 2003, 58, 5217–5227. [Google Scholar] [CrossRef]
- Föllinger, O. Regelungstechnik: Einführung in Die Methoden und Ihre Anwendung; 11., völlig neu bearb. Aufl.; Aktualisierter Lehrbuch-Klassiker; VDE: Berlin, Germany, 2013; ISBN 9783800732319. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Lower Boundary | Upper Boundary |
|---|---|---|
| 1 | ||
| 1 | ||
| 1 | ||
| Parameter | R2 of Component A [−] | R2 of Component B [−] | R2 of Component C [−] | |||
|---|---|---|---|---|---|---|
| Training | Validation | Training | Validation | Training | Validation | |
| 85% | 76% | 81% | 76% | 85% | 74% | |
| 60% | 76% | 68% | 71% | 61% | 74% | |
| 89% | 84% | 85% | 78% | 88% | 84% | |
| 21% | 3% | 27% | 3% | 25% | 1% | |
| 68% | 60% | 47% | 30% | 52% | 19% | |
| 47% | 35% | 48% | 35% | 43% | 23% | |
| 86% | 77% | 79% | 65% | 77% | 68% | |
| Parameter | R2 of Component A [−] | R2 of Component B [−] | R2 of Component C [−] | |||
|---|---|---|---|---|---|---|
| Training | Validation | Training | Validation | Training | Validation | |
| 76% | 66% | 77% | 67% | 75% | 64% | |
| 48% | 40% | 41% | 0% | 31% | 65% | |
| 49% | 29% | 37% | 14% | 27% | 6% | |
| 25% | 9% | 32% | 12% | 29% | 9% | |
| 64% | 49% | 61% | 43% | 57% | 37% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mouellef, M.; Vetter, F.L.; Strube, J. Benefits and Limitations of Artificial Neural Networks in Process Chromatography Design and Operation. Processes 2023, 11, 1115. https://doi.org/10.3390/pr11041115
Mouellef M, Vetter FL, Strube J. Benefits and Limitations of Artificial Neural Networks in Process Chromatography Design and Operation. Processes. 2023; 11(4):1115. https://doi.org/10.3390/pr11041115
Chicago/Turabian StyleMouellef, Mourad, Florian Lukas Vetter, and Jochen Strube. 2023. "Benefits and Limitations of Artificial Neural Networks in Process Chromatography Design and Operation" Processes 11, no. 4: 1115. https://doi.org/10.3390/pr11041115
APA StyleMouellef, M., Vetter, F. L., & Strube, J. (2023). Benefits and Limitations of Artificial Neural Networks in Process Chromatography Design and Operation. Processes, 11(4), 1115. https://doi.org/10.3390/pr11041115