

A Deep Learning Approach Based on Novel Multi-Feature Fusion for Power Load Prediction

Abstract
:1. Introduction
1.1. Background and Challenges
1.2. Knowledge Gaps
1.3. The Model Proposed in This Work
1.4. Novelty and Contributions
2. Literature Review
3. Methodology
3.1. Time-Varying Filter-Based EMD
3.2. Sample Entropy
3.3. Convolutional Neural Network
3.4. Bi-Directional Long Short-Term Memory
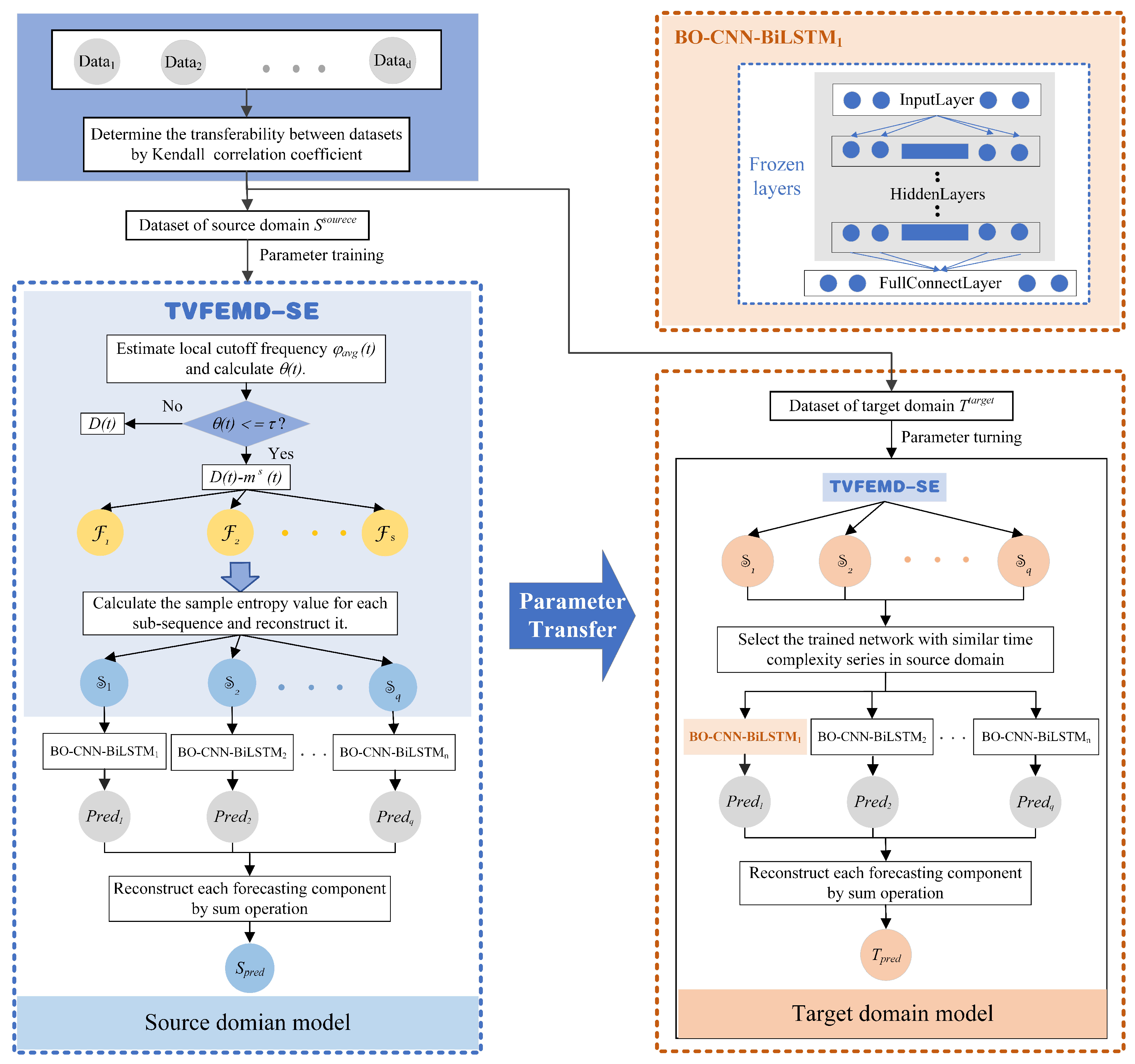
3.5. The Proposed Hybrid Model in This Study
| Algorithm 1 The pseudocode of the proposed model |
Input: Power load datasets: . The initial hyperparameters . Output: Forecasting values: . Accuracy: MAE, , RMSE and MAPE Optimal hyperparameters: .
|
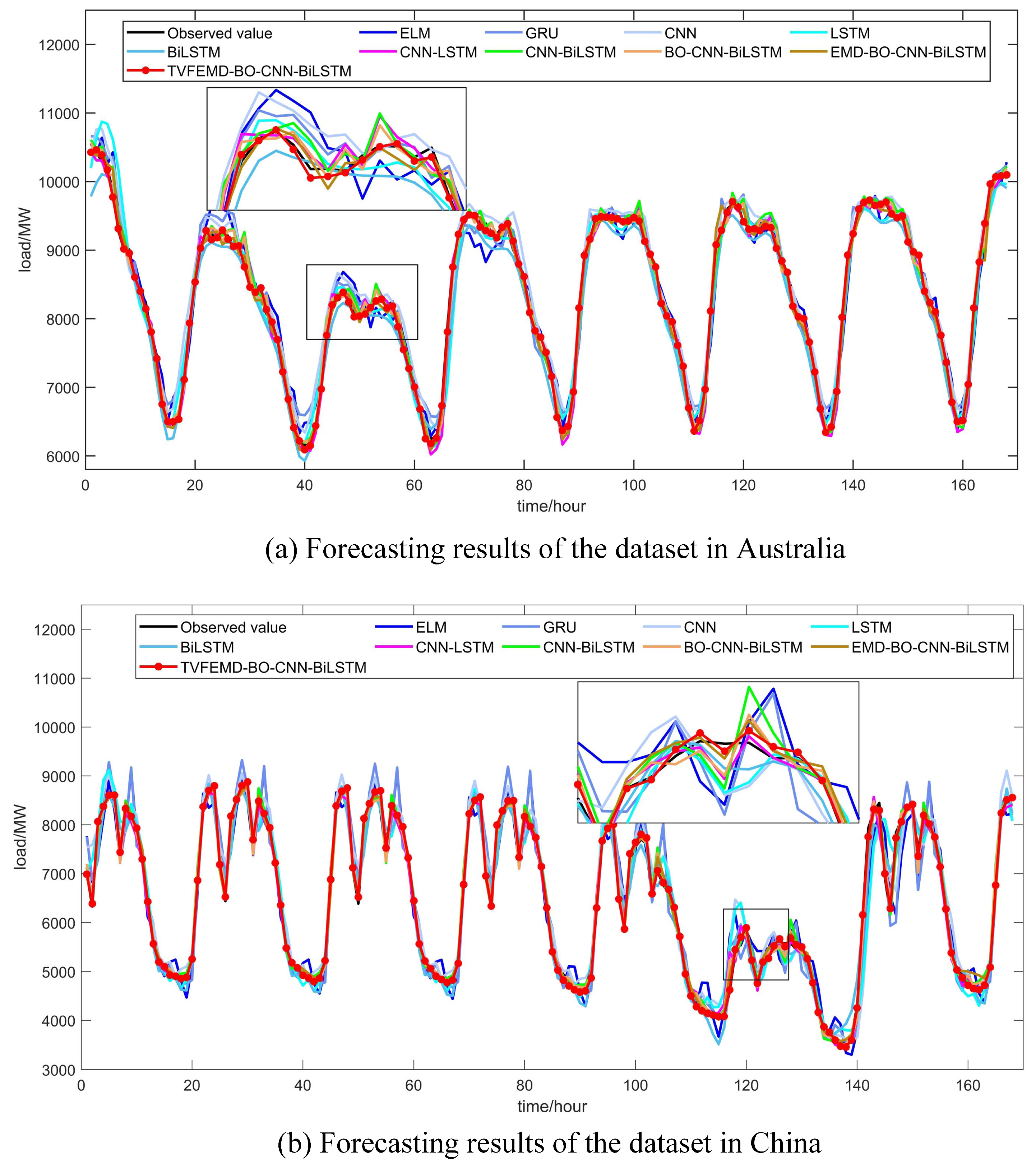
4. Case Studies and Experimental Results
4.1. Data Sources and Descriptions
4.2. Performance Metrics
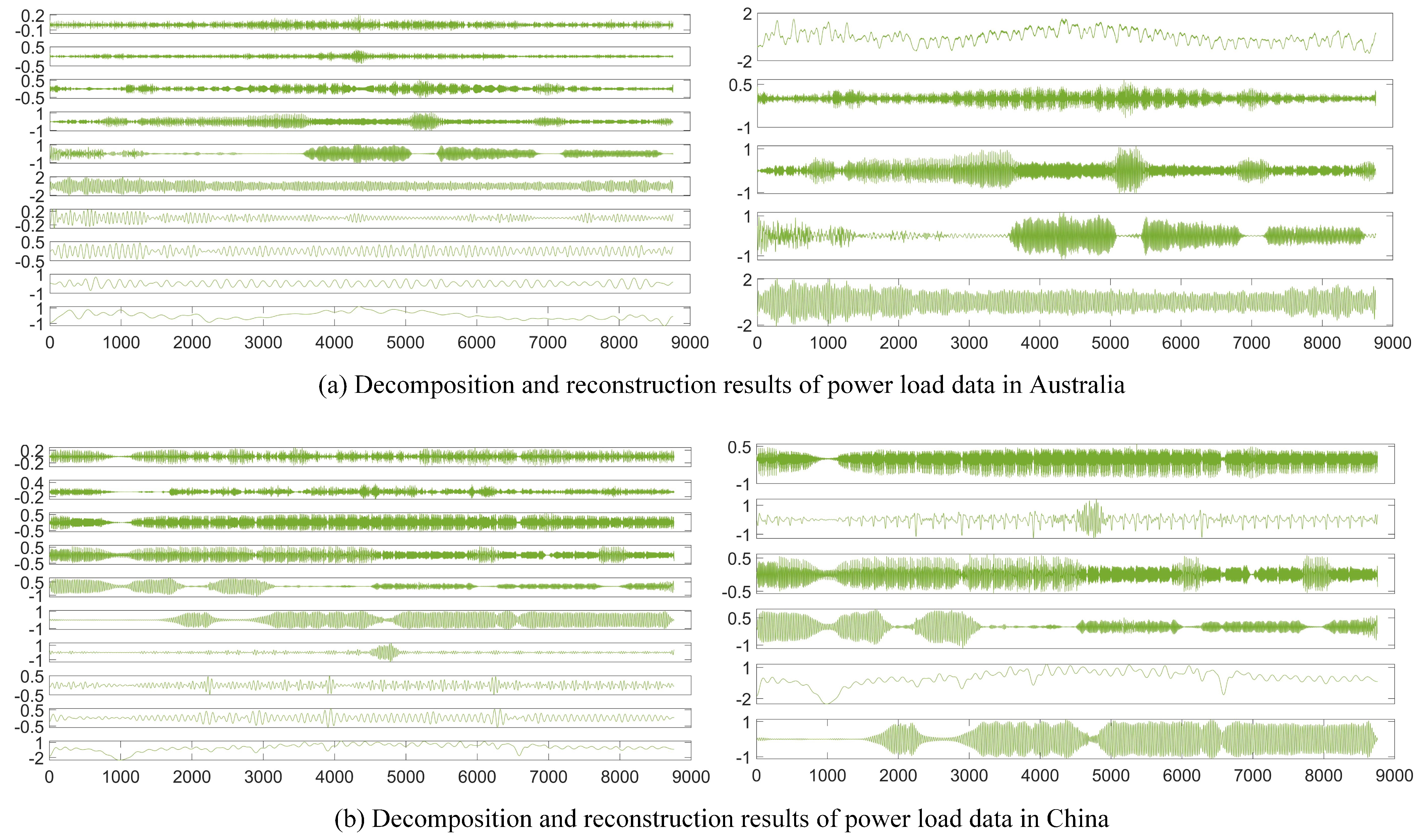
4.3. Experiment I: Online Feature Extraction Process Simulation
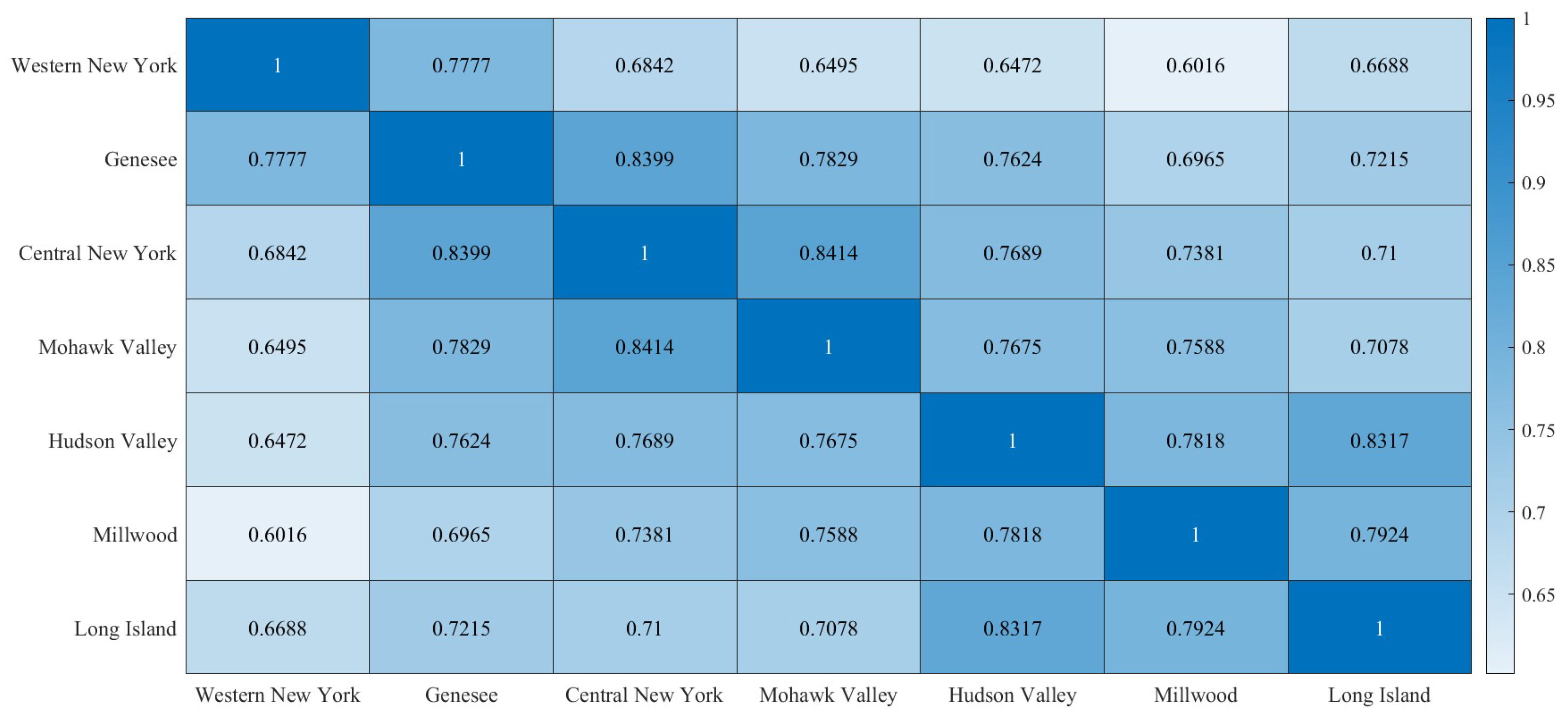
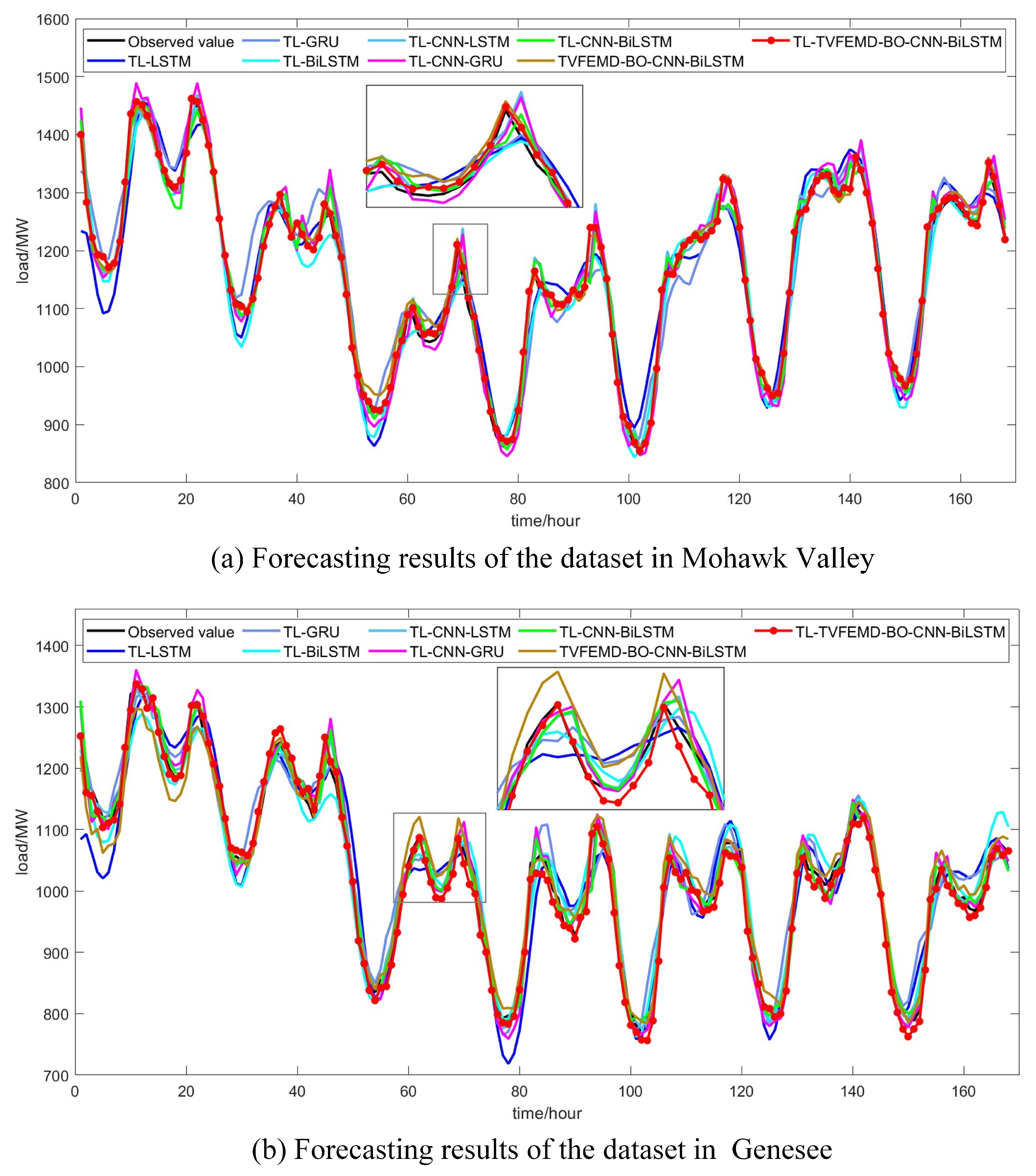
4.4. Experiment II: Transfer Learning Process Simulation
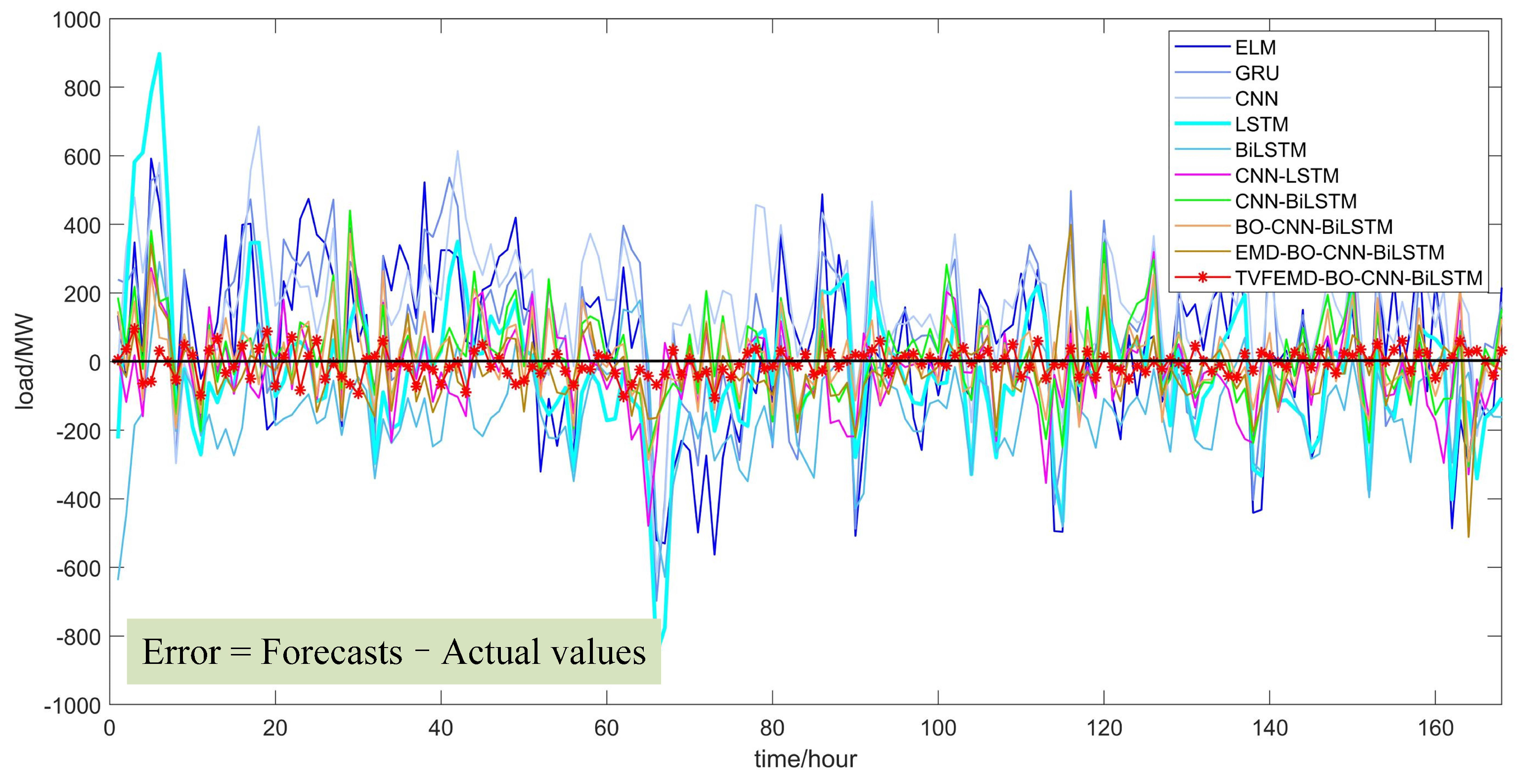
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, X.; Chen, L.; Wang, J.; Liao, L. The impact of disposability characteristics on carbon efficiency from a potential emissions reduction perspective. J. Clean. Prod. 2023, 408, 137180. [Google Scholar] [CrossRef]
- Asanov, M.; Asanova, S.; Safaraliev, M.; Zicmane, I.; Beryozkina, S.; Suerkulov, S. Design methodology of intelligent autonomous distributed hybrid power complexes with renewable energy sources. Int. J. Hydrogen Energy 2023, 48, 31468–31478. [Google Scholar] [CrossRef]
- Pawar, P.; TarunKumar, M.; Vittal K., P. An IoT based Intelligent Smart Energy Management System with accurate forecasting and load strategy for renewable generation. Measurement 2020, 152, 107187. [Google Scholar] [CrossRef]
- Vardhan, B.S.; Khedkar, M.; Srivastava, I.; Patro, S.K. Impact of integrated classifier—Regression mapped short term load forecasting on power system management in a grid connected multi energy systems. Electr. Power Syst. Res. 2024, 230, 110222. [Google Scholar] [CrossRef]
- Telle, J.S.; Upadhaya, A.; Schönfeldt, P.; Steens, T.; Hanke, B.; von Maydell, K. Probabilistic net load forecasting framework for application in distributed integrated renewable energy systems. Energy Rep. 2024, 11, 2535–2553. [Google Scholar] [CrossRef]
- Pramanik, A.S.; Sepasi, S.; Nguyen, T.L.; Roose, L. An ensemble-based approach for short-term load forecasting for buildings with high proportion of renewable energy sources. Energy Build. 2024, 308, 113996. [Google Scholar] [CrossRef]
- Wei, G.; He, J.; Zhang, Y. Application of the Unascertained Number in the Improvement of the Regressive Load Forecasting Model. High Volt. Eng. 2005, 31, 73–75. [Google Scholar]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Liu, Y.; Han, M.; Guo, J.; Liangli, S.U. Short-term electric load forecasting based on DBSCAN-ARIMA method. J. Beijing Inf. Sci. Technol. Univ. 2019, 34, 84–87. [Google Scholar]
- Tang, T.; Jiang, W.; Zhang, H.; Nie, J.; Xiong, Z.; Wu, X.; Feng, W. GM(1,1) based improved seasonal index model for monthly electricity consumption forecasting. Energy 2022, 252, 124041. [Google Scholar] [CrossRef]
- Chen, Y.; Xiao, C.; Yang, S.; Yang, Y.; Wang, W. Research on long term power load grey combination forecasting based on fuzzy support vector machine. Comput. Electr. Eng. 2024, 116, 109205. [Google Scholar] [CrossRef]
- Loizidis, S.; Kyprianou, A.; Georghiou, G.E. Electricity market price forecasting using ELM and Bootstrap analysis: A case study of the German and Finnish Day-Ahead markets. Appl. Energy 2024, 363, 123058. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, Z.; Guo, Y.; Yu, K.; Zhang, J.; Mu, X. Deep Learning Applications in Power System Load Forecasting: A Survey. J. Zhengzhou Univ. Eng. Sci. 2022, 31, 3. [Google Scholar]
- Zhu, L.; Xun, Z.; Wang, Y.; Cui, Q.; Chen, Y.; Lou, J. Short-term Power Load Forecasting Based on CNN-BiLSTM. Power Syst. Technol. 2021, 45, 4532–4539. [Google Scholar]
- Wan, A.; Chang, Q.; AL-Bukhaiti, K.; He, J. Short-term power load forecasting for combined heat and power using CNN-LSTM enhanced by attention mechanism. Energy 2023, 282, 128274. [Google Scholar] [CrossRef]
- Michael, N.E.; Bansal, R.C.; Ismail, A.A.A.; Elnady, A.; Hasan, S. A cohesive structure of Bi-directional long-short-term memory (BiLSTM) -GRU for predicting hourly solar radiation. Renew. Energy 2024, 222, 119943. [Google Scholar] [CrossRef]
- Shao, Z.; Zheng, Q.; Liu, C.; Gao, S.; Wang, G.; Chu, Y. A feature extraction- and ranking-based framework for electricity spot price forecasting using a hybrid deep neural network. Electr. Power Syst. Res. 2021, 200, 107453. [Google Scholar] [CrossRef]
- Mounir, N.; Ouadi, H.; Jrhilifa, I. Short-term electric load forecasting using an EMD-BI-LSTM approach for smart grid energy management system. Energy Build. 2023, 288, 113022. [Google Scholar] [CrossRef]
- Yue, W.; Liu, Q.; Ruan, Y.; Qian, F.; Meng, H. A prediction approach with mode decomposition-recombination technique for short-term load forecasting. Sustain. Cities Soc. 2022, 85, 104034. [Google Scholar] [CrossRef]
- Gao, X.; Guo, W.; Mei, C.; Sha, J.; Guo, Y.; Sun, H. Short-term wind power forecasting based on SSA-VMD-LSTM. Energy Rep. 2023, 9, 335–344. [Google Scholar] [CrossRef]
- Xiong, D.; Fu, W.; Wang, K.; Fang, P.; Chen, T.; Zou, F. A blended approach incorporating TVFEMD, PSR, NNCT-based multi-model fusion and hierarchy-based merged optimization algorithm for multi-step wind speed prediction. Energy Convers. Manag. 2021, 230, 113680. [Google Scholar] [CrossRef]
- Zhang, W.; He, Y.; Yang, S. A multi-step probability density prediction model based on gaussian approximation of quantiles for offshore wind power. Renew. Energy 2023, 202, 992–1011. [Google Scholar] [CrossRef]
- Ye, R.; Dai, Q. A novel transfer learning framework for time series forecasting. Knowl.-Based Syst. 2018, 156, 74–99. [Google Scholar] [CrossRef]
- Li, K.; Li, Z.; Huang, C.; Ai, Q. Online transfer learning-based residential demand response potential forecasting for load aggregator. Appl. Energy 2024, 358, 122631. [Google Scholar] [CrossRef]
- Wei, N.; Yin, C.; Yin, L.; Tan, J.; Liu, J.; Wang, S.; Qiao, W.; Zeng, F. Short-term load forecasting based on WM algorithm and transfer learning model. Appl. Energy 2024, 353, 122087. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, Z.; Wang, Z.; Sun, Y.; Chen, Y. Attention mechanism-based transfer learning model for day-ahead energy demand forecasting of shopping mall buildings. Energy 2023, 270, 126878. [Google Scholar] [CrossRef]
- Yang, Q.; Lin, Y.; Kuang, S.; Wang, D. A novel short-term load forecasting approach for data-poor areas based on K-MIFS-XGBoost and transfer-learning. Electr. Power Syst. Res. 2024, 229, 110151. [Google Scholar] [CrossRef]
- Li, H.; Li, Z.; Mo, W. A time varying filter approach for empirical mode decomposition. Signal Process. 2017, 138, 146–158. [Google Scholar] [CrossRef]
- Richman, J.S.; Randall, M.J. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039. [Google Scholar] [CrossRef]
- Rafi, S.H.; Nahid-Al-Masood; Deeba, S.R.; Hossain, E. A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Michael, N.E.; Hasan, S.; Al-Durra, A.; Mishra, M. Short-term solar irradiance forecasting based on a novel Bayesian optimized deep Long Short-Term Memory neural network. Appl. Energy 2022, 324, 119727. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Watkins, C.; Kuenzel, S. Multi-quantile recurrent neural network for feeder-level probabilistic energy disaggregation considering roof-top solar energy. Eng. Appl. Artif. Intell. 2022, 110, 104707. [Google Scholar] [CrossRef]
- Wang, J.; Wang, H.; Wang, H.; Zhang, Z. Short-term Power Load Prediction of Bidirectional LSTM with ISSA Optimization Attention Mechanism. Proc.-Csu-Epsa 2022, 34, 111–117. [Google Scholar]
- de Almeida, F.A.; Romao, E.L.; Gomes, G.F.; de Freitas Gomes, J.H.; de Paiva, A.P.; Miranda Filho, J.; Balestrassi, P.P. Combining machine learning techniques with Kappa–Kendall indexes for robust hard-cluster assessment in substation pattern recognition. Electr. Power Syst. Res. 2022, 206, 107778. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Australian Dataset | Series | ||||||||||
| Sample entropy | 0.0759 | 0.0414 | 0.0318 | 0.0307 | 0.0172 | 0.0158 | 0.0131 | 0.0107 | 0.0074 | 0.0061 | |
| Reconstruction | |||||||||||
| Chinese Dataset | Series | ||||||||||
| Sample entropy | 0.2572 | 0.1575 | 0.1421 | 0.1103 | 0.0957 | 0.0927 | 0.0902 | 0.0711 | 0.0642 | 0.0517 | |
| Reconstruction |
| Model | Hyperparameter | Range | Australian Dataset | Chinese Dataset |
|---|---|---|---|---|
| Optimization Results | Optimization Results | |||
| CNN | numfilter | [2, 256] | 57 | 64 |
| sizefilter | [2, 4] | 3 | 2 | |
| Dropout | [0.01, 1] | 0.0208 | 0.0122 | |
| BiLSTM | MaxEpoch | [50, 100] | 42 | 16 |
| InitialLearnRate | [0.001, 0.01] | 0.0012 | 0.0016 | |
| LearnRateDropPeriod | [1, 100] | 8 | 5 | |
| LearnRateDropFactor | [0.1, 1] | 0.1010 | 0.1244 |
| Models | Dataset in Australia | Dataset in China | ||||||
|---|---|---|---|---|---|---|---|---|
| MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | |||
| ELM | 2.3704 | 239.4930 | 192.9309 | 0.9550 | 5.5325 | 443.1403 | 345.2088 | 0.9176 |
| CNN | 2.3562 | 234.7214 | 188.2177 | 0.9568 | 4.9592 | 436.0833 | 320.7937 | 0.9202 |
| GRU | 2.2960 | 227.9039 | 185.9117 | 0.9592 | 4.5806 | 403.8322 | 293.3329 | 0.9316 |
| LSTM | 1.8397 | 216.0864 | 152.3165 | 0.9634 | 3.8580 | 360.6637 | 244.0518 | 0.9454 |
| BiLSTM | 1.9120 | 199.7428 | 160.5922 | 0.9687 | 3.2272 | 264.0626 | 199.9038 | 0.9708 |
| CNN-LSTM | 1.2892 | 134.8267 | 104.3219 | 0.9857 | 1.7995 | 157.0683 | 113.3924 | 0.9897 |
| CNN-BiLSTM | 1.2262 | 130.5426 | 102.5207 | 0.9866 | 1.7793 | 153.3386 | 112.1061 | 0.9901 |
| BO-CNN-BiLSTM | 1.1172 | 115.5108 | 93.0379 | 0.9895 | 1.6267 | 142.4330 | 101.9695 | 0.9915 |
| EMD-BO-CNN-BiLSTM | 0.8982 | 99.9201 | 74.0757 | 0.9922 | 1.1496 | 94.4236 | 70.0163 | 0.9963 |
| TVFEMD-BO-CNN-BiLSTM | 0.3893 | 39.3832 | 31.5929 | 0.9988 | 0.8289 | 50.96943 | 64.9864 | 0.9982 |
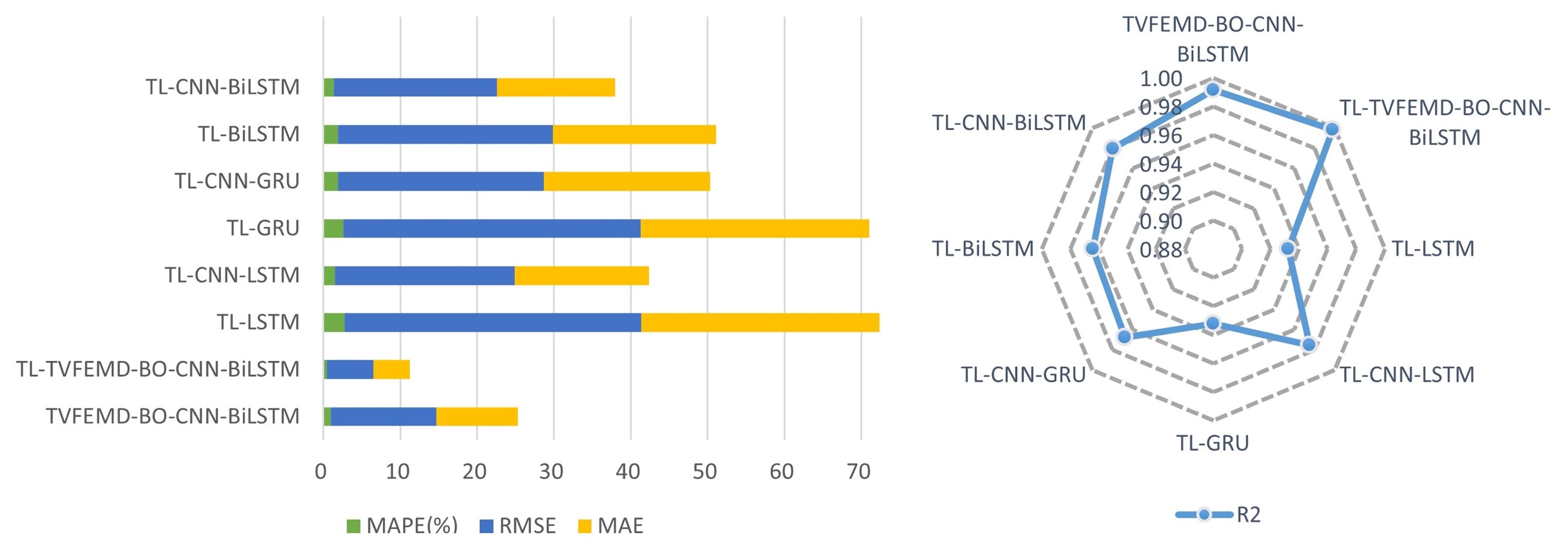
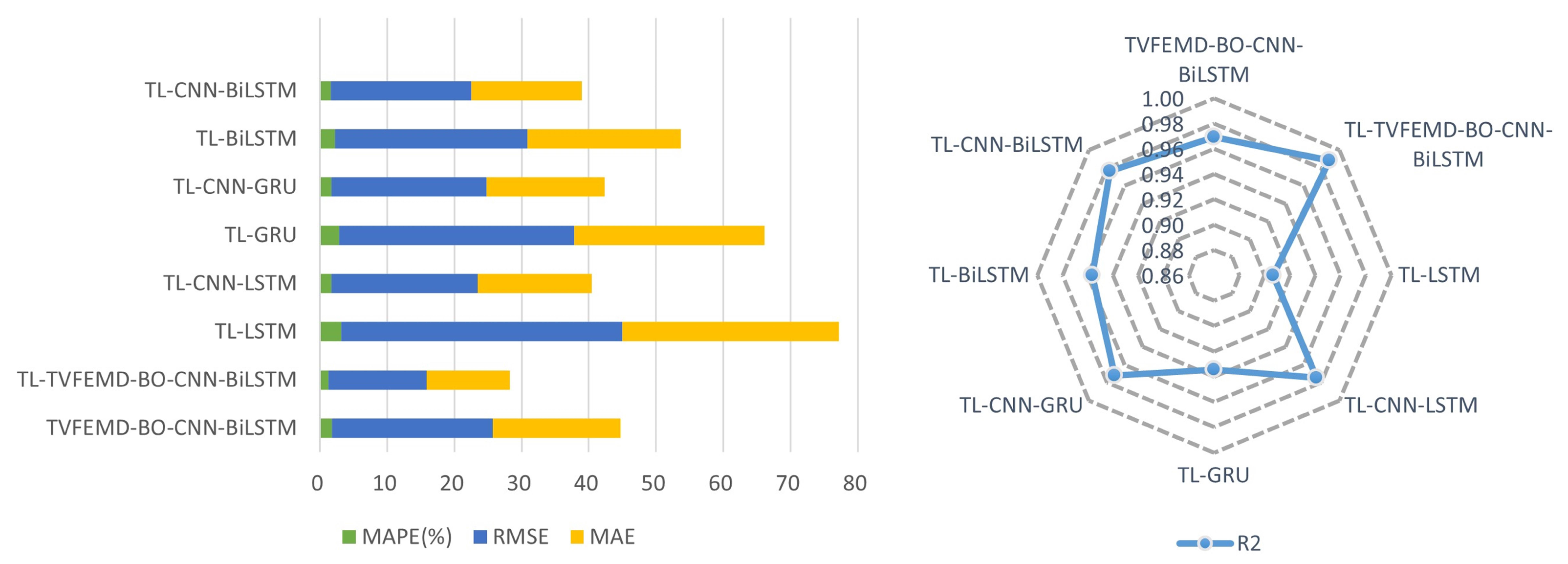
| Models | Dataset in Mohawk Valley | Dataset in Genesee | ||||||
|---|---|---|---|---|---|---|---|---|
| MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | |||
| TL-LSTM | 2.7129 | 38.6663 | 30.9617 | 0.9323 | 3.1507 | 41.8600 | 32.1833 | 0.9066 |
| TL-GRU | 2.5766 | 38.6839 | 29.7569 | 0.9323 | 2.8379 | 35.0285 | 28.2472 | 0.9346 |
| TL-BiLSTM | 1.8608 | 28.0134 | 21.2605 | 0.9645 | 2.2195 | 28.6088 | 22.8857 | 0.9564 |
| TL-CNN-LSTM | 1.4982 | 23.3781 | 17.4889 | 0.9753 | 1.6499 | 21.8287 | 16.993 | 0.9746 |
| TL-CNN-GRU | 1.8703 | 26.8162 | 21.6318 | 0.9674 | 1.7202 | 23.0775 | 17.5707 | 0.9716 |
| TL-CNN-BiLSTM | 1.3157 | 21.2666 | 15.3652 | 0.9795 | 1.6039 | 20.9308 | 16.4696 | 0.9766 |
| TVFEMD-BO-CNN-BiLSTM | 0.9395 | 13.7319 | 10.5835 | 0.9915 | 1.8213 | 23.9374 | 18.9842 | 0.9695 |
| TL-TVFEMD-BO-CNN-BiLSTM | 0.4193 | 6.1317 | 4.6986 | 0.9983 | 1.2256 | 14.6354 | 12.4256 | 0.9886 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, L.; An, R.; Zhang, X. A Deep Learning Approach Based on Novel Multi-Feature Fusion for Power Load Prediction. Processes 2024, 12, 793. https://doi.org/10.3390/pr12040793
Xiao L, An R, Zhang X. A Deep Learning Approach Based on Novel Multi-Feature Fusion for Power Load Prediction. Processes. 2024; 12(4):793. https://doi.org/10.3390/pr12040793
Chicago/Turabian StyleXiao, Ling, Ruofan An, and Xue Zhang. 2024. "A Deep Learning Approach Based on Novel Multi-Feature Fusion for Power Load Prediction" Processes 12, no. 4: 793. https://doi.org/10.3390/pr12040793
APA StyleXiao, L., An, R., & Zhang, X. (2024). A Deep Learning Approach Based on Novel Multi-Feature Fusion for Power Load Prediction. Processes, 12(4), 793. https://doi.org/10.3390/pr12040793