

Forecasting Gas Well Classification Based on a Two-Dimensional Convolutional Neural Network Deep Learning Model

Abstract
:1. Introduction
2. Materials and Methods
2.1. XGBoost Algorithm
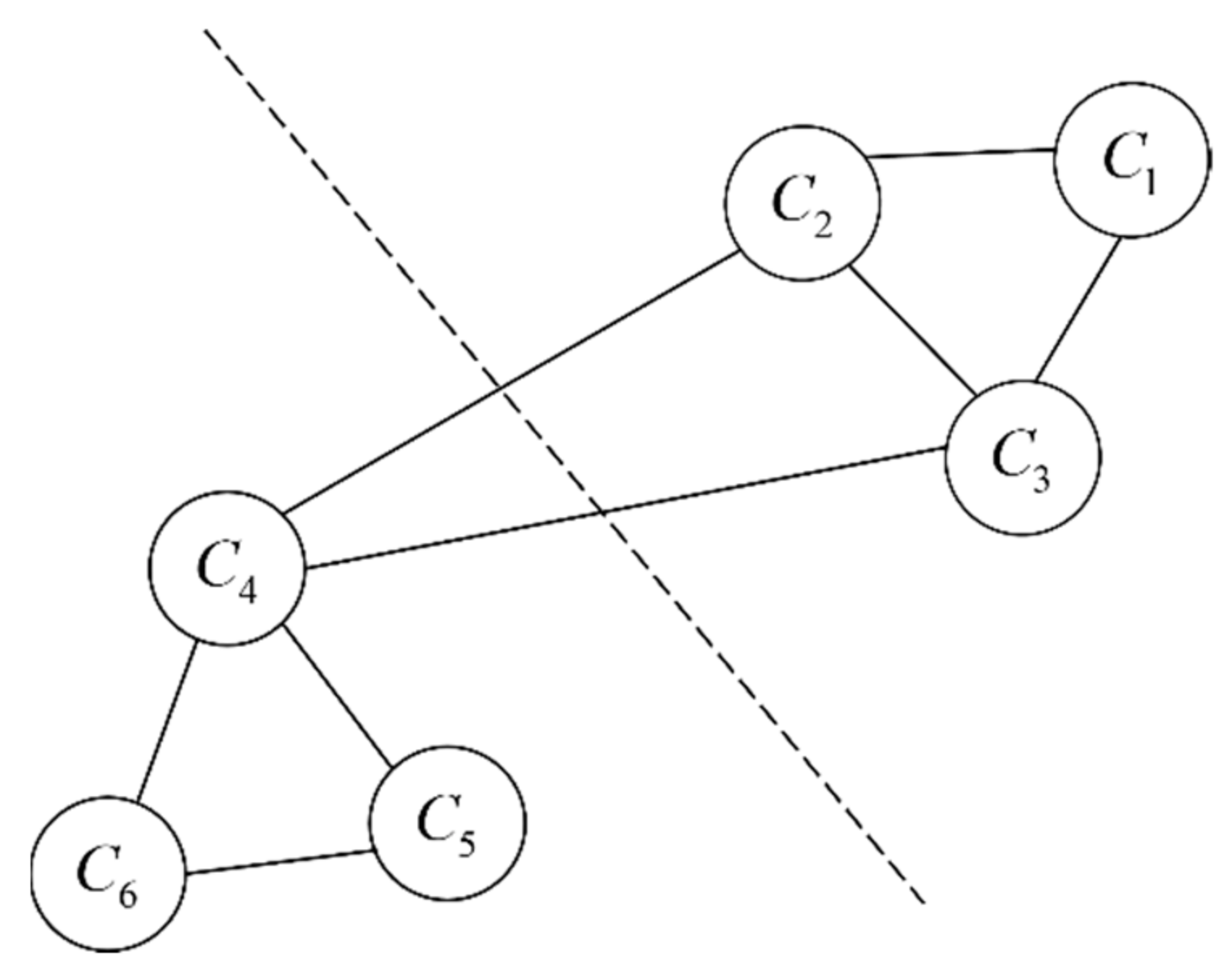
2.2. Spectral Clustering
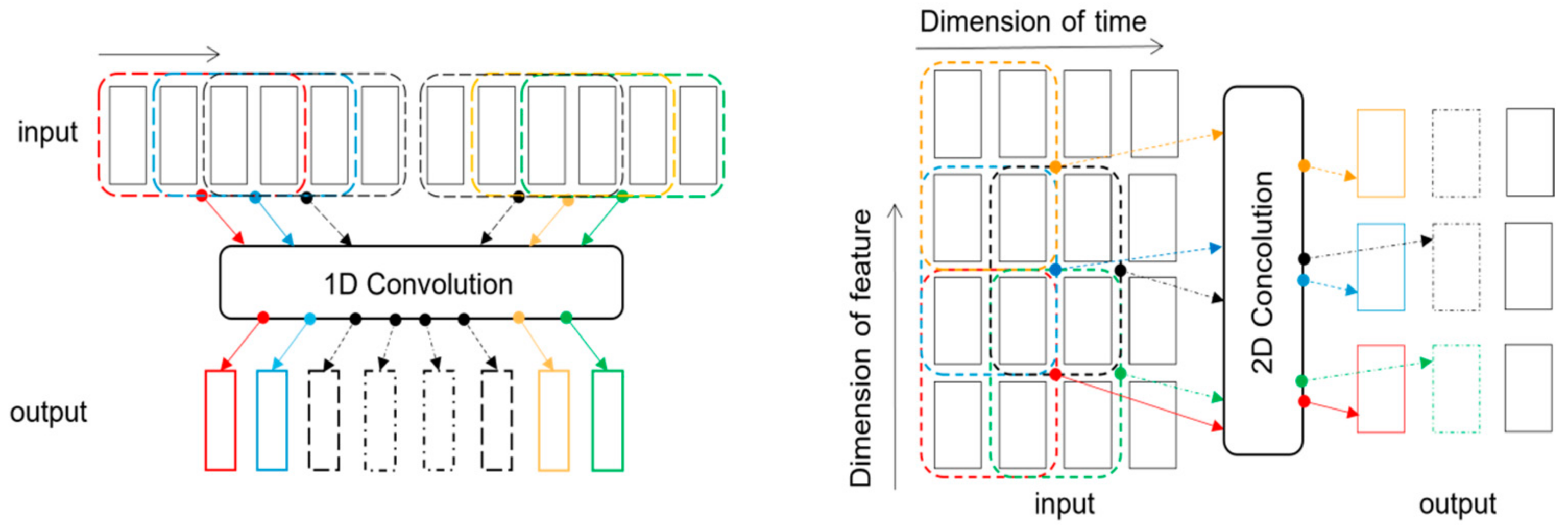
2.3. Convolutional Neural Network
2.3.1. Convolution Layer
2.3.2. Max-Pooling Layer
3. Results
3.1. Data Source
3.2. Selection of Main Control Factors
3.3. Evaluation of Gas Well Types
4. Application
4.1. Model Thinking
4.2. Model Building Steps
- Feature selection of original data
- Classification of gas well types
- Building a 2D-CNN model to predict gas well types
5. Discussion
5.1. Evaluation Performance of The Model
5.2. Parameter Setting and Prediction Process of 2D-CNN Model
- The variance filtering method and the correlation coefficient method are used to select the preliminary features, and then the XGBoost algorithm is used to determine the new gas well development indicators whose feature importance is greater than 0.04. Then, the input data are divided into a training set and a test set, and one_hot code is used to digitize the gas well type of the test set.
- The training set trains the neural network, extracts information via the convolution layer of the 2D-CNN model, learns the characteristics of gas well development, and uses the BPTT algorithm to backpropagate the training error and continuously update the model parameters.
- The Softmax function is used to obtain the classification probability of three types of gas wells. In order to avoid over fitting of the model, the parameters of the model are constantly adjusted through gradient descent to obtain the optimal parameters of the prediction model.
- Judge whether the network epoch reaches the preset 100 times. If yes, run the next step; otherwise repeat step 2.
- The test set verifies the performance of the trained model, calculates the evaluation indexes, and outputs the prediction results of gas well types.
5.3. Predictive Results of Gas Layers Using 2D-CNN Model
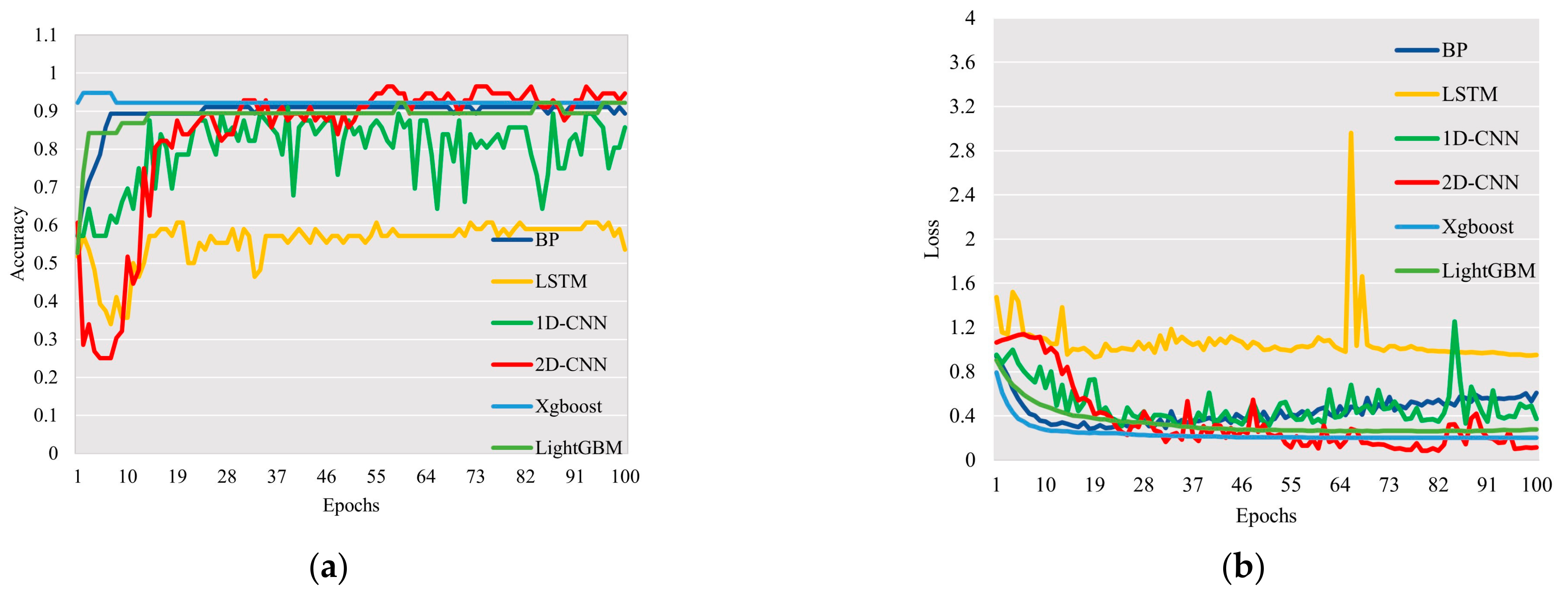
5.4. Comparison with Other Classification Prediction Algorithms
6. Conclusions
- The spectral clustering algorithm is used to classify various gas well types in tight sandstone gas reservoirs, and three gas well types are obtained. Then, the variance filtering method, correlation coefficient method, and XGBoost algorithm are used to select the characteristics of gas well development indicators and determine new gas well development indicators that affect gas well types. A reasonable selection of development indicators is conducive to improving the multi-class prediction effect of gas well types.
- The double-layer 2D-CNN depth learning method is applied to the multi-class prediction of gas well types. The accuracy of the model is 0.99, and the loss value is 0.03, which is superior to the prediction effect of the BP neural network, XGBoost model, LightGBM model, LSTM model, and 1D-CNN model. Because the 2D-CNN model has a deeper calculation depth, which improves the prediction accuracy of the model, the 2D-CNN model is applicable to the research of gas well type prediction.
- According to the multi-class problem of gas well types, a deep learning model based on 2D-CNN model is proposed. The prediction of gas well types with small sample size has good accuracy and effectiveness, and the accuracy will be significantly improved in the prediction problem with large sample size. Therefore, this method provides a new idea for the prediction research of gas well types with large sample size.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kulga, B.; Artun, E.; Ertekin, T. Development of a data-driven forecasting tool for hydraulically fractured, horizontal wells in tight-gas sands. Comput. Geosci. 2017, 103, 99–110. [Google Scholar] [CrossRef]
- Ostojic, J.; Rezaee, R.; Bahrami, H. Production performance of hydraulic fractures in tight gas sands, a numerical simulation approach. J. Pet. Sci. Eng. 2012, 88–89, 75–81. [Google Scholar] [CrossRef]
- Piyush, P.; Kumar, V. Well Testing in Tight Gas Reservoir: Today’s Challenge and Future’s Opportunity. In Proceedings of the the SPE Oil and Gas India Conference and Exhibition, Society of Petroleum Engineers, Mumbai, India, 20–22 January 2010. [Google Scholar] [CrossRef]
- Law, B.; Curtis, J. Introduction to unconventional petroleum systems. AAPG Bull. 2002, 86, 1851–1852. [Google Scholar]
- Qin, W. Research on Financial Risk Forecast Model of Listed Companies Based on Convolutional Neural Network. Sci. Program. 2022, 2022, 3652931. [Google Scholar] [CrossRef]
- Ghulam, A.; Ali, F.; Sikander, R.; Ahmad, A.; Ahmed, A.; Patil, S. ACP-2DCNN: Deep learningbased model for improving prediction of anticancer peptides using two-dimensional convolutional neural network. Chemom. Intel-Ligent Lab. Syst. 2022, 226, 104589. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2018, 47, 312–323. [Google Scholar] [CrossRef]
- Pan, S.; Yang, B.; Wang, S.; Guo, Z.; Wang, L.; Liu, J.; Wu, S. Oil well production prediction based on CNN-LSTM model with self-attention mechanism. Energy 2023, 284, 128701. [Google Scholar] [CrossRef]
- Chen, Z.; Yu, W.; Liang, J.-T.; Wang, S.; Liang, H.-C. Application of statistical machine learning clustering algorithms to improve EUR predictions using decline curve analysis in shale-gas reservoirs. J. Pet. Sci. Eng. 2021, 208, 109216. [Google Scholar] [CrossRef]
- Wanjun, H.; Wenhe, X.; Yongjie, L.; Jiang, J.; Gao, L.I.; Yijian, C. An intelligent identification method of safety risk while drilling in gas drilling. Pet. Explor. Dev. 2022, 49, 428–437. [Google Scholar]
- Zhu, L.; Zhou, X.; Zhang, C. Rapid identification of high-quality marine shale gas reservoirs based on the oversampling method and random forest algorithm. Artif. Intell. Geosci. 2021, 2, 76–81. [Google Scholar] [CrossRef]
- Tyagi, P.; Sharma, A.; Semwal, R.; Tiwary, U.S.; Varadwaj, P.K. XGBoost odor prediction model: Finding the structure-odor relationship of odorant molecules using the extreme gradient boosting algorithm. J. Biomol. Struct. Dyn. 2023, 1–12. [Google Scholar] [CrossRef]
- Sun, M.; Yang, J.; Yang, C.; Wang, W.; Wang, X.; Li, H. Research on prediction of PPV in open-pit mine used RUN-XGBoost model. Heliyon 2024, 10, e28246. [Google Scholar] [CrossRef]
- Pan, Q.; Zhang, C.; Wei, X.; Wan, A.; Wei, Z. Assessment of MV XLPE cable aging state based on PSO-XGBoost algorithm. Electr. Power Syst. Res. 2023, 221, 109427. [Google Scholar] [CrossRef]
- Yang, M.; Liu, L.; Cui, Y.; Su, X. Ultra-Short-Term Multistep Prediction of Wind Power Based on Representative Unit Method. Math. Probl. Eng. 2018, 2018, 1936565. [Google Scholar] [CrossRef]
- Lee, K.B.; Cheon, S.; Kim, C.O. A Convolutional Neural Network for Fault Classification and Diagnosis in Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2017, 30, 135–142. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Le Roux, N.; Bach, F.; Ponce, J.; LeCun, Y. Ask the locals: Multi-way local pooling for image recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2651–2658. [Google Scholar]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A bidirectional LSTM deep learning approach for intrusion detection. Expert Syst. Appl. 2021, 185, 115524. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y.; Han, J.; He, J.; Sun, J.; Zhou, T. Intelligent Hazard-Risk Prediction Model for Train Control Systems. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4693–4704. [Google Scholar] [CrossRef]
- Kuppusamy, S.; Thangavel, R. Deep Non-linear and Unbiased Deep Decisive Pooling Learning–Based Opinion Mining of Customer Review. Cogn. Comput. 2023, 15, 765–777. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Geological Factors | Engineering Factors |
|---|---|---|
| 1 | The middle of the interval (m) | Well type |
| 2 | Initial formation pressure (MPa) | Casing inner diameter (mm) |
| 3 | Original formation temperature (°C) | Tubing outer diameter (mm) |
| 4 | Effective porosity (%) | Tubing depth (m) |
| 5 | Permeability (10−3 μm2) | Thickness of perforation (m) |
| 6 | Initial gas saturation (%) | Fracturing fluid flowback rate (%) |
| 7 | Gas relative density | Total amount of sand added in fracturing (m3) |
| 8 | Salinity of formation water (mg/L) | Casing depth (m) |
| 9 | Shaliness (%) | Cumulative days of production |
| 10 | Skin factor | |
| 11 | Effective fracture half-length (m) |
| Layers | Layer Type | Parameter | Output Size |
|---|---|---|---|
| 1 | input layer | - | (None, 16) |
| 2 | dense | the activation function is relu | (None, 256) |
| 3 | reshape | - | (None, 16, 16, 1) |
| 4 | conv2D | four convolution kernels with the size of 2 2, step size is 2 2, the filling method is same | (None, 8, 8, 4) |
| 5 | batch_normalization | - | (None, 8, 8, 4) |
| 6 | max_pooling2D | pooling kernel size is 2 2, step size is 1 1, the filling method is same | (None, 8, 8, 4) |
| 7 | conv2D_1 | two convolution kernels with the size of 4 4, step size is 2 2, the filling method is same | (None, 4, 4, 2) |
| 8 | batch_normalization_1 | - | (None, 4, 4, 2) |
| 9 | max_pooling2D_1 | Pooling kernel size is 1 1, the filling method is same | (None, 4, 4, 2) |
| 10 | dropout | p = 0.5 | (None, 4, 4, 2) |
| 11 | flatten | - | (None, 32) |
| 12 | dense_1 | the activation function is relu | (None, 16) |
| 13 | dense_2 | the activation function is softmax | (None, 3) |
| Type of Gas Well | Precision | Recall | F1 Score |
|---|---|---|---|
| High productive wells | 1.00 | 0.98 | 0.99 |
| Inferior wells | 1.00 | 1.00 | 1.00 |
| Medium productive wells | 0.96 | 1.00 | 0.98 |
| Average value | 0.99 | 0.99 | 0.99 |
| Evaluating Indicator | BP | XGBoost | LightGBM | LSTM | 1D-CNN | 2D-CNN |
|---|---|---|---|---|---|---|
| Accuracy | 0.89 | 0.92 | 0.92 | 0.61 | 0.86 | 0.99 |
| Value of loss | 0.61 | 0.20 | 0.28 | 0.97 | 0.37 | 0.03 |
| Average precision | 0.87 | 0.93 | 0.92 | 0.39 | 0.83 | 0.99 |
| Average recall | 0.94 | 0.89 | 0.91 | 0.53 | 0.83 | 0.99 |
| Average F1 score | 0.89 | 0.91 | 0.91 | 0.29 | 1.14 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, C.; Jia, Y.; Qu, Y.; Zheng, W.; Hou, S.; Wang, B. Forecasting Gas Well Classification Based on a Two-Dimensional Convolutional Neural Network Deep Learning Model. Processes 2024, 12, 878. https://doi.org/10.3390/pr12050878
Zhao C, Jia Y, Qu Y, Zheng W, Hou S, Wang B. Forecasting Gas Well Classification Based on a Two-Dimensional Convolutional Neural Network Deep Learning Model. Processes. 2024; 12(5):878. https://doi.org/10.3390/pr12050878
Chicago/Turabian StyleZhao, Chunlan, Ying Jia, Yao Qu, Wenjuan Zheng, Shaodan Hou, and Bing Wang. 2024. "Forecasting Gas Well Classification Based on a Two-Dimensional Convolutional Neural Network Deep Learning Model" Processes 12, no. 5: 878. https://doi.org/10.3390/pr12050878
APA StyleZhao, C., Jia, Y., Qu, Y., Zheng, W., Hou, S., & Wang, B. (2024). Forecasting Gas Well Classification Based on a Two-Dimensional Convolutional Neural Network Deep Learning Model. Processes, 12(5), 878. https://doi.org/10.3390/pr12050878