
Outlier Detection in Dynamic Systems with Multiple Operating Points and Application to Improve Industrial Flare Monitoring


Abstract
:1. Introduction
2. Methodology
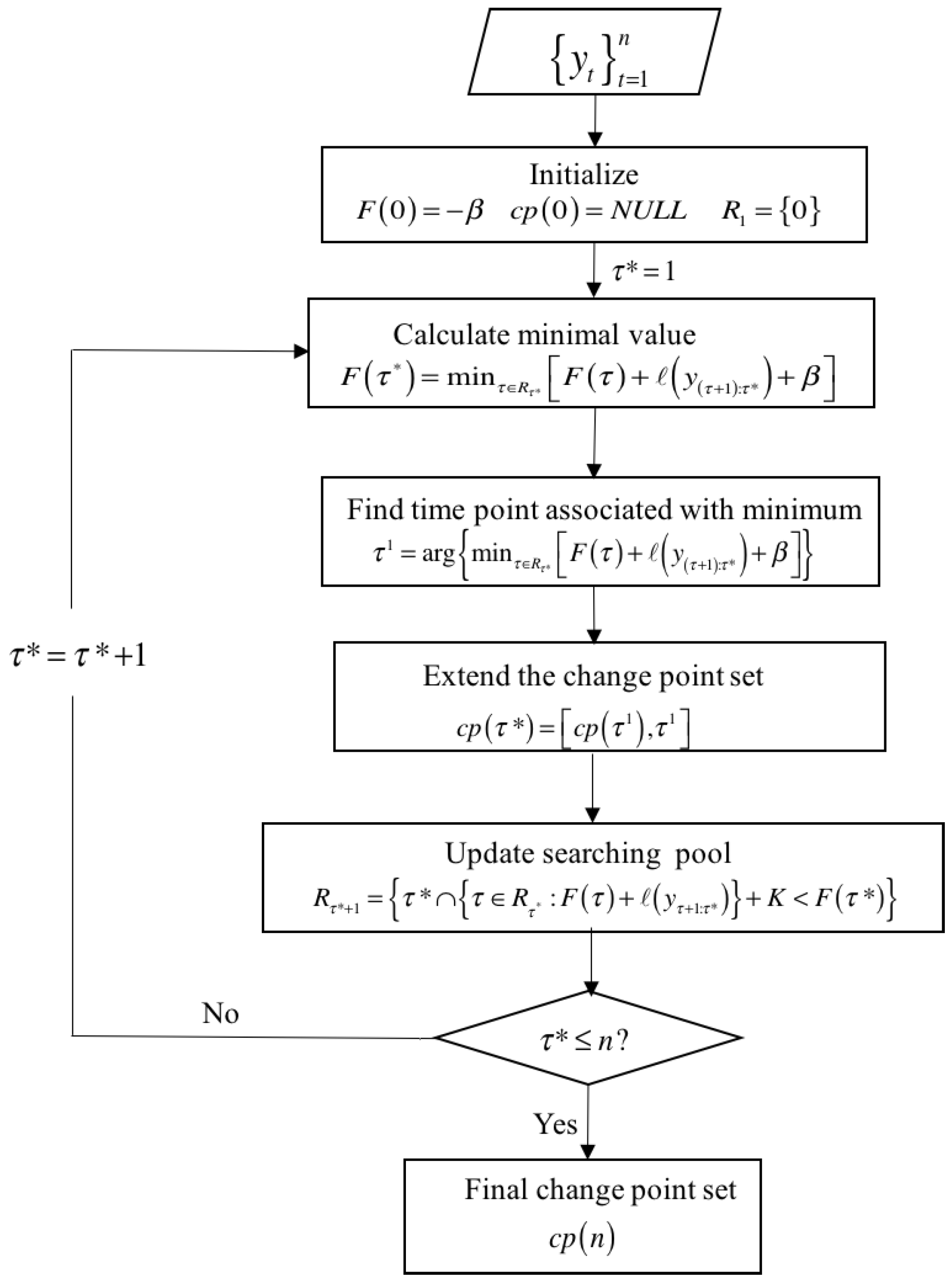
2.1. Pruned Exact Linear Time (PELT) Method
2.2. Time Series Kalman Filter (TSKF)
- Data partition: partition the data set into M subsets .
- Pre-whitening: for each subset , pre-whiten the data using the reweighed minimum covariance determinant estimator [16], and centralize the data with robust center .
- Model fitting: based on the preliminary clean data ,
- Outlier detection: for each subset :
- 4.1
- Reformat:where
- 4.2
- Predict:
- 4.3
- Update:
- 4.4
- Detect:
- 4.4.1.
- Set .
- 4.4.2.
- Find a number of n observations whose Mahalanobis distance .
- 4.4.3.
- Calculate the percentage of normal data:
- 4.4.4.
- If , stop; otherwise, increase by .
- 4.4.5.
- The outliers correspond to observations with Mahalanobis distance .
- 4.5
- Replace: replace the outliers with neighboring normal values.
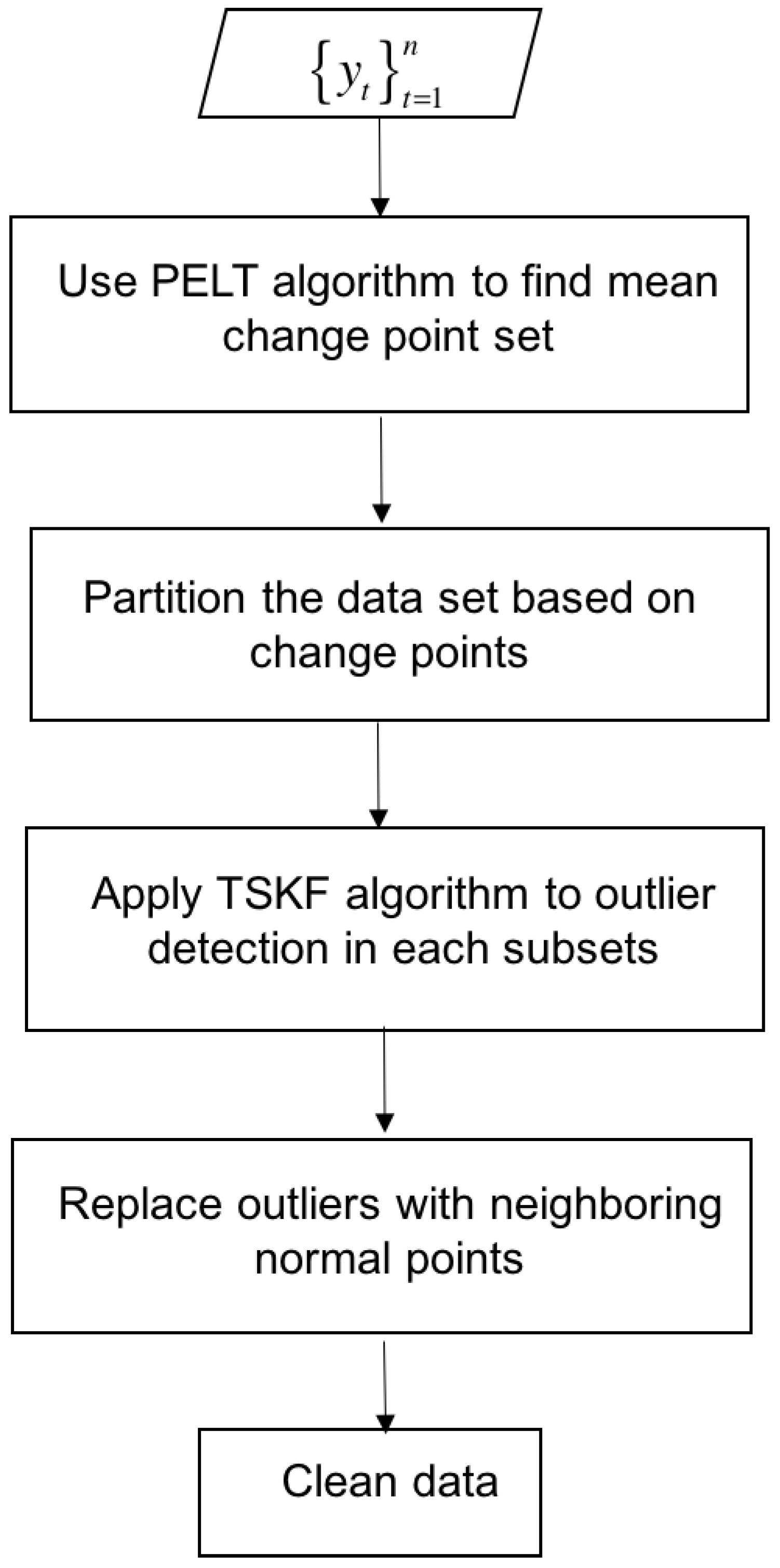
2.3. An Integrated Method for Outlier Detection in a Dynamic Data Set with Multiple Operating Points
2.4. Partial Least Squares Discriminant Analysis (PLS-DA)
3. Case Studies
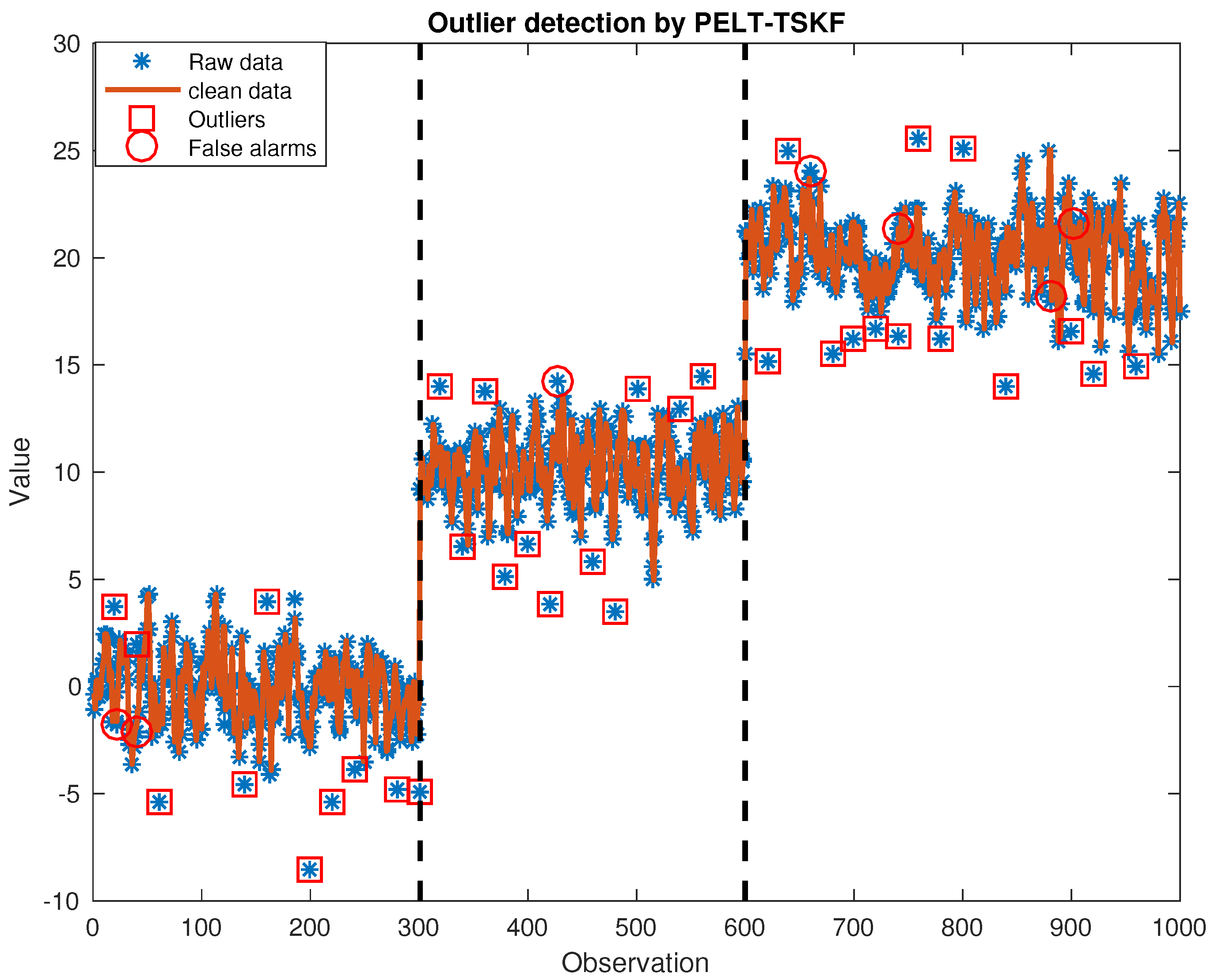
3.1. Simulated Case Study
3.2. Application of PELT-TSKF to PLS-DA Case Studies
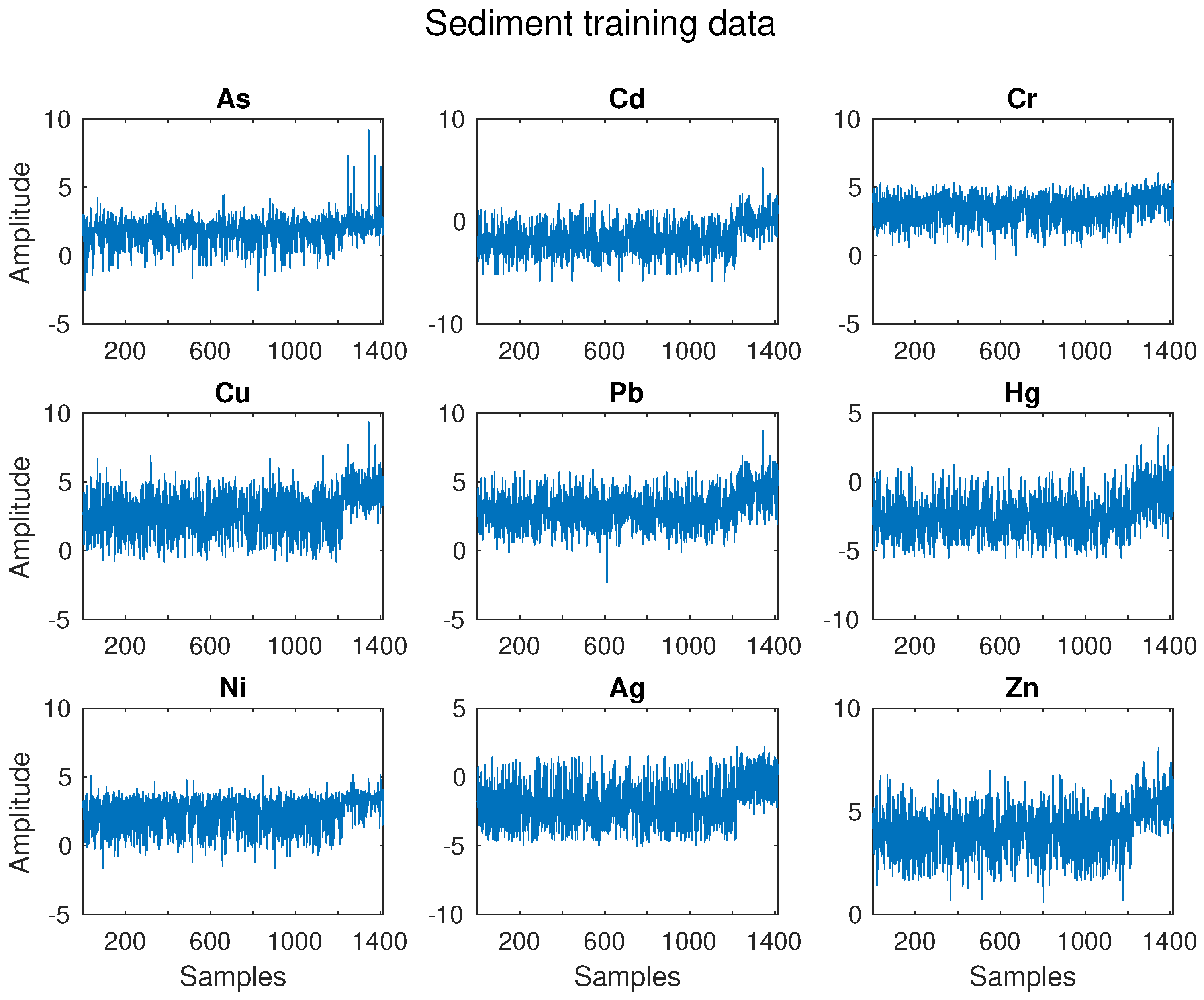
3.2.1. Sediment Toxicity Detection
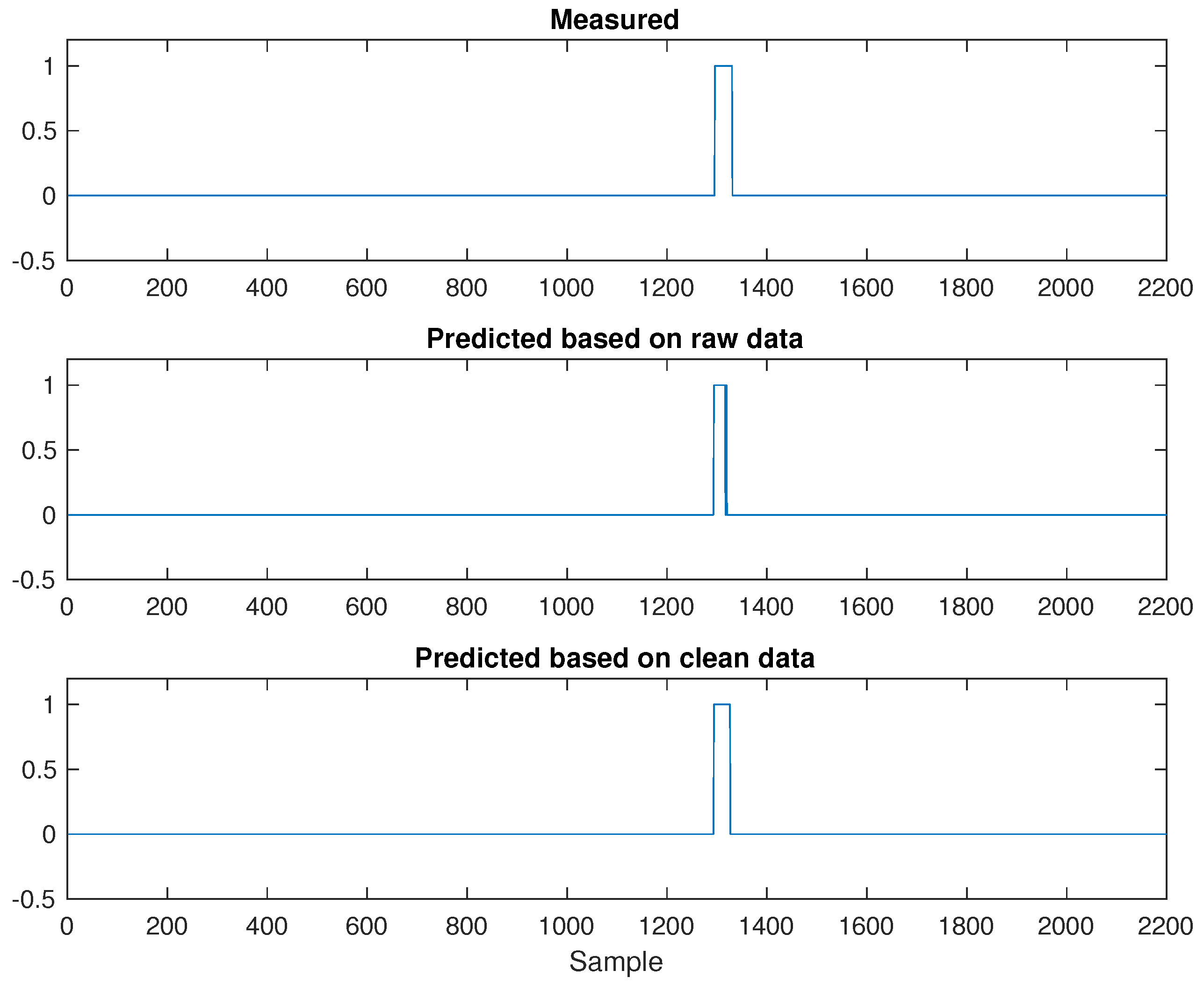
3.2.2. Industrial Flare Monitoring
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| TSKF | time series Kalman filter |
| PELT | pruned exact linear time |
| PLS-DA | partial least squares discriminant analysis |
| GESD | general extreme studentized deviate |
| ARMA | autoregressive moving average |
| NER | non-error rate |
| Sn | toxicity sensitivity |
| Sp | non-toxicity specificity |
References
- Davis, J.; Edgar, T.; Porter, J.; Bernaden, J.; Sarli, M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance. Comput. Chem. Eng. 2012, 47, 145–156. [Google Scholar] [CrossRef]
- Torres, V.M.; Herndon, S.; Kodesh, Z.; Allen, D.T. Industrial flare performance at low flow conditions. 1. study overview. Ind. Eng. Chem. Res. 2012, 51, 12559–12568. [Google Scholar] [CrossRef]
- Bader, A.; Baukal, C.E., Jr.; Bussman, W. Selecting the proper flare systems. Chem. Eng. Prog. 2011, 107, 45–50. [Google Scholar]
- Xu, S.; Lu, B.; Baldea, M.; Edgar, T.F.; Wojsznis, W.; Blevins, T.; Nixon, M. Data cleaning in the process industries. Rev. Chem. Eng. 2015, 31, 453–490. [Google Scholar] [CrossRef]
- Hodge, V.J.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef]
- Daszykowski, M.; Kaczmarek, K.; Heyden, Y.V.; Walczak, B. Robust statistics in data analysis—A review: Basic concepts. Chemometr. Intell. Lab. Syst. 2007, 85, 203–219. [Google Scholar] [CrossRef]
- Singh, A. Outliers and robust procedures in some chemometric applications. Chemometr. Intell. Lab. Syst. 1996, 33, 75–100. [Google Scholar] [CrossRef]
- Dielman, T.E. Least absolute value regression: Recent contributions. J. Stat. Comput. Simul. 2005, 75, 263–286. [Google Scholar] [CrossRef]
- Jaeckel, L.A. Estimating regression coefficients by minimizing the dispersion of the residuals. Ann. Math. Stat. 1972, 43, 1449–1458. [Google Scholar] [CrossRef]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Rousseeuw, P.; Yohai, V. Robust regression by means of S-estimators. In Robust and Nonlinear Time Series Analysis; Springer-Verlag: New York, NY, USA, 1984; pp. 256–272. [Google Scholar]
- Davies, L.; Gather, U. The identification of multiple outliers. J. Am. Stat. Assoc. 1993, 88, 782–792. [Google Scholar] [CrossRef]
- Rosner, B. Percentage points for a generalized ESD many-outlier procedure. Technometrics 1983, 25, 165–172. [Google Scholar] [CrossRef]
- Hampel, F.R. A general qualitative definition of robustness. Ann. Math. Stat. 1971, 42, 1887–1896. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis (Behavior Science); Pearson: London, UK, 1977. [Google Scholar]
- Rousseeuw, P.J.; Driessen, K.V. A fast Algorithm for the minimum covariance determinant estimator. Technometrics 1999, 41, 212–223. [Google Scholar] [CrossRef]
- Allan, J.; Carbonell, J.; Doddington, G.; Yamron, J.; Yang, Y. Topic detection and tracking pilot study final report. In Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop, Pittsburgh, PA, USA, 8–11 February 1998; pp. 194–218. [Google Scholar]
- Knorr, E.M.; Ng, R.T. Algorithms for mining distance based outliers in large datasets. In Proceedings of the International Conference on Very Large Data Bases; Gupta, A., Shmueli, O., Widom, J., Eds.; Morgan Kaufmann: New York, NY, USA, 1998; pp. 392–403. [Google Scholar]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer-Verlag: London, UK, 2001. [Google Scholar]
- Kourti, T.; MacGregor, J.F. Process analysis, monitoring and diagnosis, using multivariate projection methods. Chemometr. Intell. Lab. Syst. 1995, 28, 3–21. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the ICDM Conference, Pisa, Italy, 15–19 December 2008. [Google Scholar]
- Xu, S.; Baldea, M.; Edgar, T.F.; Wojsznis, W.; Blevins, T.; Nixon, M. An improved methodology for outlier detection in dynamic datasets. AIChE J. 2015, 61, 419–433. [Google Scholar] [CrossRef]
- Kay, S.M. Modern Spectral Estimation: Theory and Application; Prentice Hall: Bergen County, NJ, USA, 1988. [Google Scholar]
- Dunia, R.; Edgar, T.F.; Blevins, T.; Wojsznis, W. Multistate analytics for continuous processes. J. Process Control 2012, 22, 1445–1456. [Google Scholar] [CrossRef]
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal detection of changepoints with a linear computational cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]
- Jackson, B.; Sargle, J.D.; Barnes, D.; Arabhi, S.; Alt, A.; Gioumousis, P.; Gwin, E.; Sangtrakulcharoen, P.; Tan, L.; Tsai, T.T. An algorithm for optimal partitioning of data on an interval. IEEE Signal Process. Lett. 2005, 12, 105–108. [Google Scholar] [CrossRef]
- Scott, A.J.; Knott, M. A cluster analysis method for grouping means in the analysis of variance. Biometrics 1974, 30, 507–512. [Google Scholar] [CrossRef]
- Auger, I.E.; Lawrence, C.E. Algorithms for the optimal identification of segment neighborhoods. Bull. Math. Biol. 1989, 51, 39–54. [Google Scholar] [CrossRef] [PubMed]
- Adams, R.P.; MacKay, D.J.C. Bayesian Online Changepoint Detection. 2007. Available online: http://arxiv.org/abs/0710.3742 (accessed on 3 March 2017).
- Lai, T.L.; Xing, H. Sequential Change-Point Detection When the Pre- and Post-Change Parameters are Unknown. Seq. Anal. 2010, 29, 162–175. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least squares: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Wold, S.; Sjostrom, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Brereton, R.G. Chemometrics for Pattern Recognition; John Wiley and Sons: Chichester, UK, 2009. [Google Scholar]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Method 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Brereton, R.G.; Lloyd, G.R. Partial least squares discriminant analysis: Taking the magic away. J. Chemom. 2014, 28, 213–225. [Google Scholar] [CrossRef]
- Pérez, N.F.; Ferré, J.; Boqué, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Alvarez-Guerra, M.; Ballabio, D.; Amigo, J.M.; Viguri, J.R.; Bro, R. A chemometric approach to the environmental problem of predicting toxicity in contaminated sediments. J. Chemom. 2010, 24, 379–386. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case No. | Amp | PELT-GESD (*) | PELT-TSKF (**) | Isolation Forest | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.3 | −0.3 | 4 | 0.27 | 53.87 | 0.82 | 84.29 | 2.00 | 64.40 |
| 2 | 0.3 | −0.3 | 5 | 0.35 | 88.44 | 0.47 | 91.42 | 1.76 | 69.23 |
| 3 | 0.3 | −0.5 | 4 | 0.27 | 39.73 | 0.98 | 80.63 | 2.22 | 60.19 |
| 4 | 0.3 | −0.5 | 5 | 0.29 | 75.40 | 0.65 | 87.60 | 1.95 | 65.44 |
| 5 | 0.5 | −0.3 | 4 | 0.29 | 37.60 | 0.99 | 80.56 | 2.40 | 56.63 |
| 6 | 0.5 | −0.3 | 5 | 0.28 | 69.19 | 0.69 | 86.69 | 2.01 | 64.25 |
| 7 | 0.5 | −0.5 | 4 | 0.29 | 25.90 | 1.22 | 75.71 | 2.73 | 49.98 |
| 8 | 0.5 | −0.5 | 5 | 0.30 | 69.98 | 0.68 | 87.08 | 2.45 | 55.69 |
| Non-Toxic (Class 1) | Toxic (Class 2) | Total | |
|---|---|---|---|
| Training set | 1218 | 195 | 1413 |
| Test set | 406 | 65 | 471 |
| Total | 1624 | 260 | 1884 |
| NER (*) | Sn | Sp | |
|---|---|---|---|
| Raw data | 0.792 | 0.846 | 0.783 |
| Clean data | 0.847 | 0.877 | 0.842 |
| Observations | Variables | |
|---|---|---|
| Flare training set 1 | 10,800 | 132 |
| Flare testing set 1 | 2200 | 132 |
| Flare training set 2 | 44,998 | 132 |
| Flare testing set 2 | 30,000 | 132 |
| (/%) | (/%) | |
|---|---|---|
| Flare 1 raw data | 62.86 | 0.092 |
| Flare 1 clean data | 88.47 | 0.092 |
| Flare 2 raw data | 100 | 0.18 |
| Flare 2 clean data | 100 | 0.16 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Lu, B.; Bell, N.; Nixon, M. Outlier Detection in Dynamic Systems with Multiple Operating Points and Application to Improve Industrial Flare Monitoring. Processes 2017, 5, 28. https://doi.org/10.3390/pr5020028
Xu S, Lu B, Bell N, Nixon M. Outlier Detection in Dynamic Systems with Multiple Operating Points and Application to Improve Industrial Flare Monitoring. Processes. 2017; 5(2):28. https://doi.org/10.3390/pr5020028
Chicago/Turabian StyleXu, Shu, Bo Lu, Noel Bell, and Mark Nixon. 2017. "Outlier Detection in Dynamic Systems with Multiple Operating Points and Application to Improve Industrial Flare Monitoring" Processes 5, no. 2: 28. https://doi.org/10.3390/pr5020028
APA StyleXu, S., Lu, B., Bell, N., & Nixon, M. (2017). Outlier Detection in Dynamic Systems with Multiple Operating Points and Application to Improve Industrial Flare Monitoring. Processes, 5(2), 28. https://doi.org/10.3390/pr5020028