Fault Identification Using Fast k-Nearest Neighbor Reconstruction



Abstract
:1. Introduction
2. Methods
2.1. Fault Detection Method Based on kNN Rule
- Off-Line Model building
- Find k nearest neighbors for each sample, , in the normalized NOC data set by using Euclidean distance.where is the distance between and its jth nearest neighbor.
- Calculate the average kNN distance (it may not be a rigorous mathematical distance) of the sampleHere, is the average squared distance between sample and its k nearest neighbors. The average kNN distance is used as the detection index.
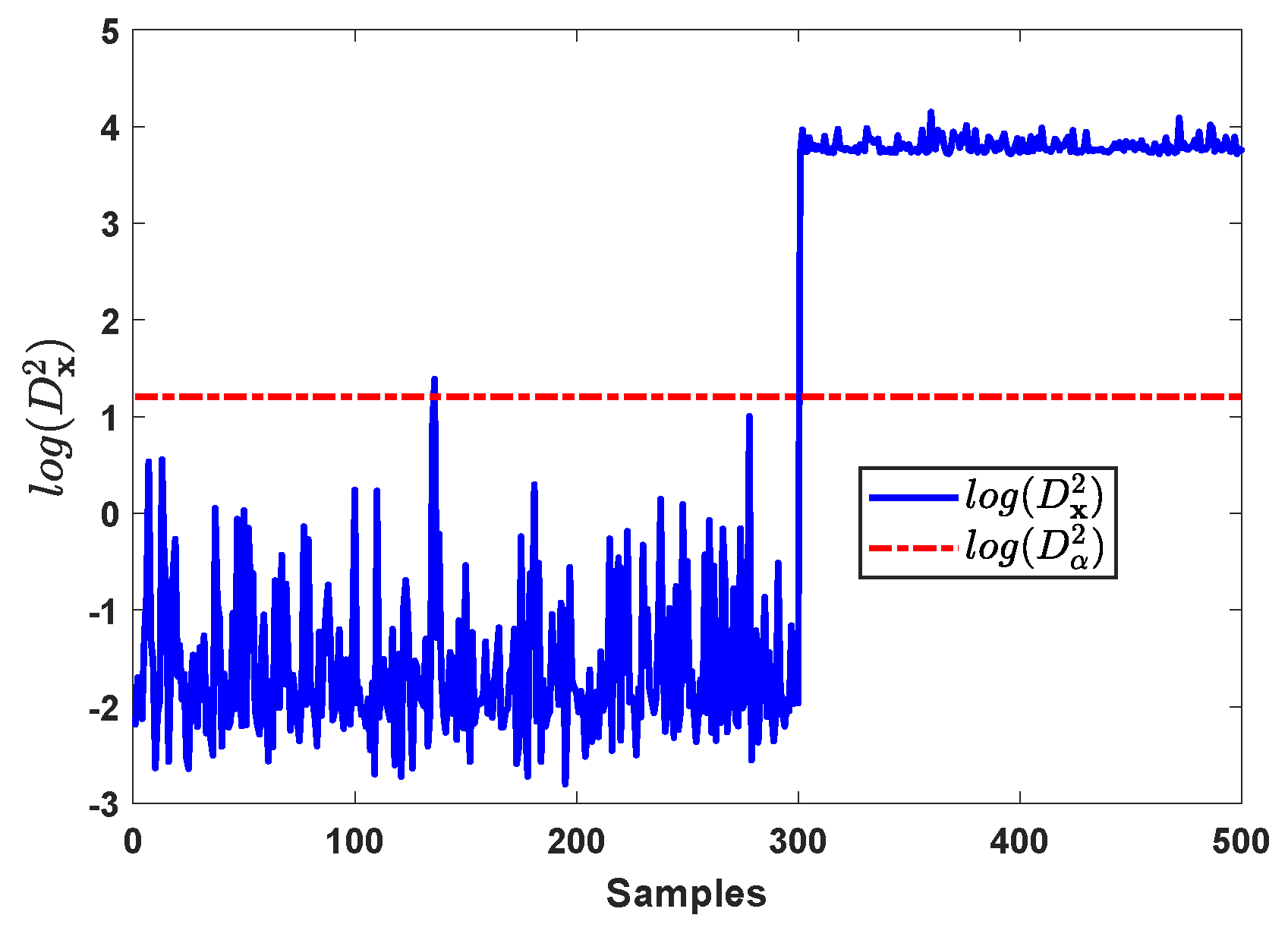
- Determine the detection thresholdThe threshold with significance level can be determined by the -empirical quartile of [16]where is the ranking of in ascending order. takes the integer part from .
- Online monitoringWhen a normalized online sample is obtained, e.g., ,
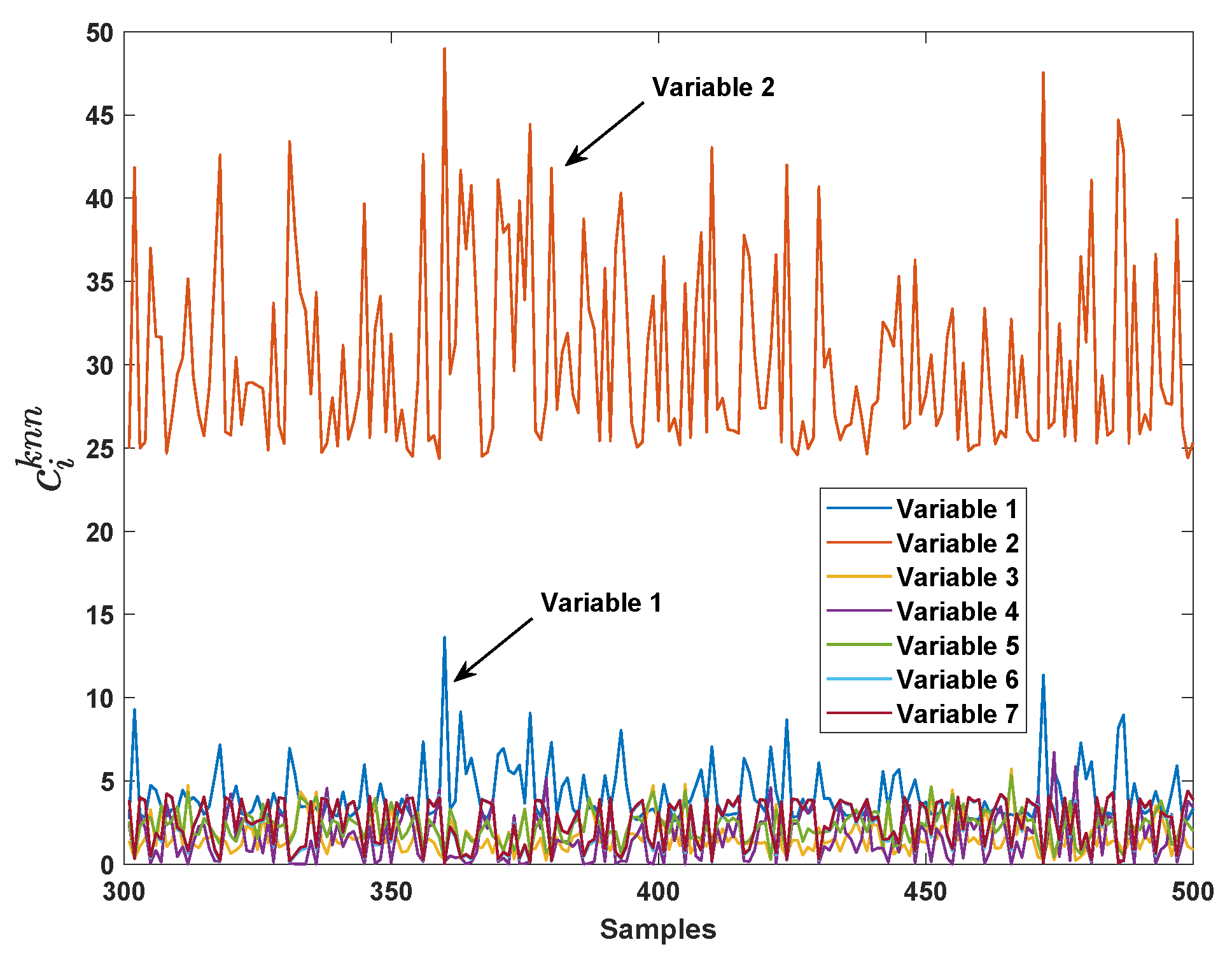
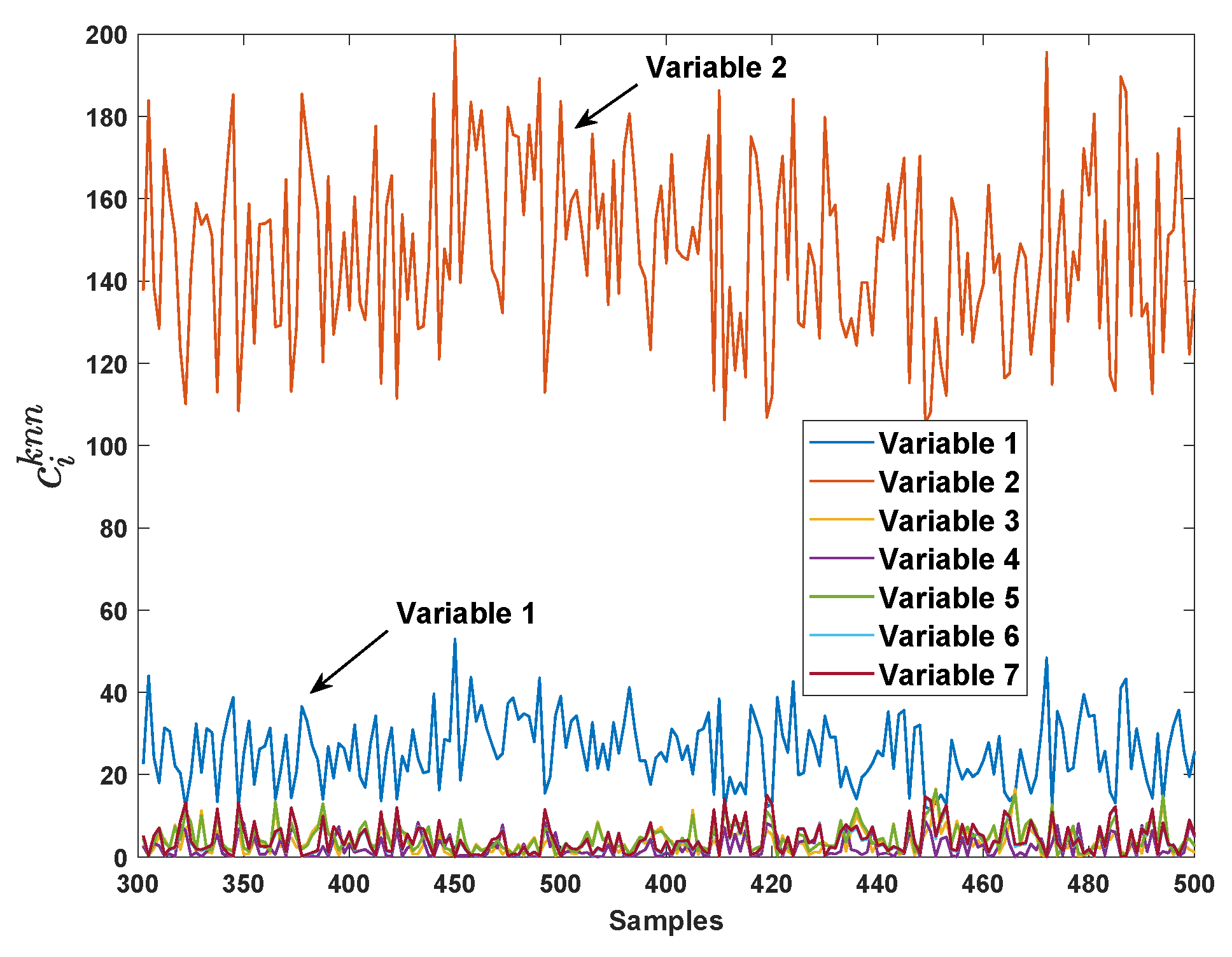
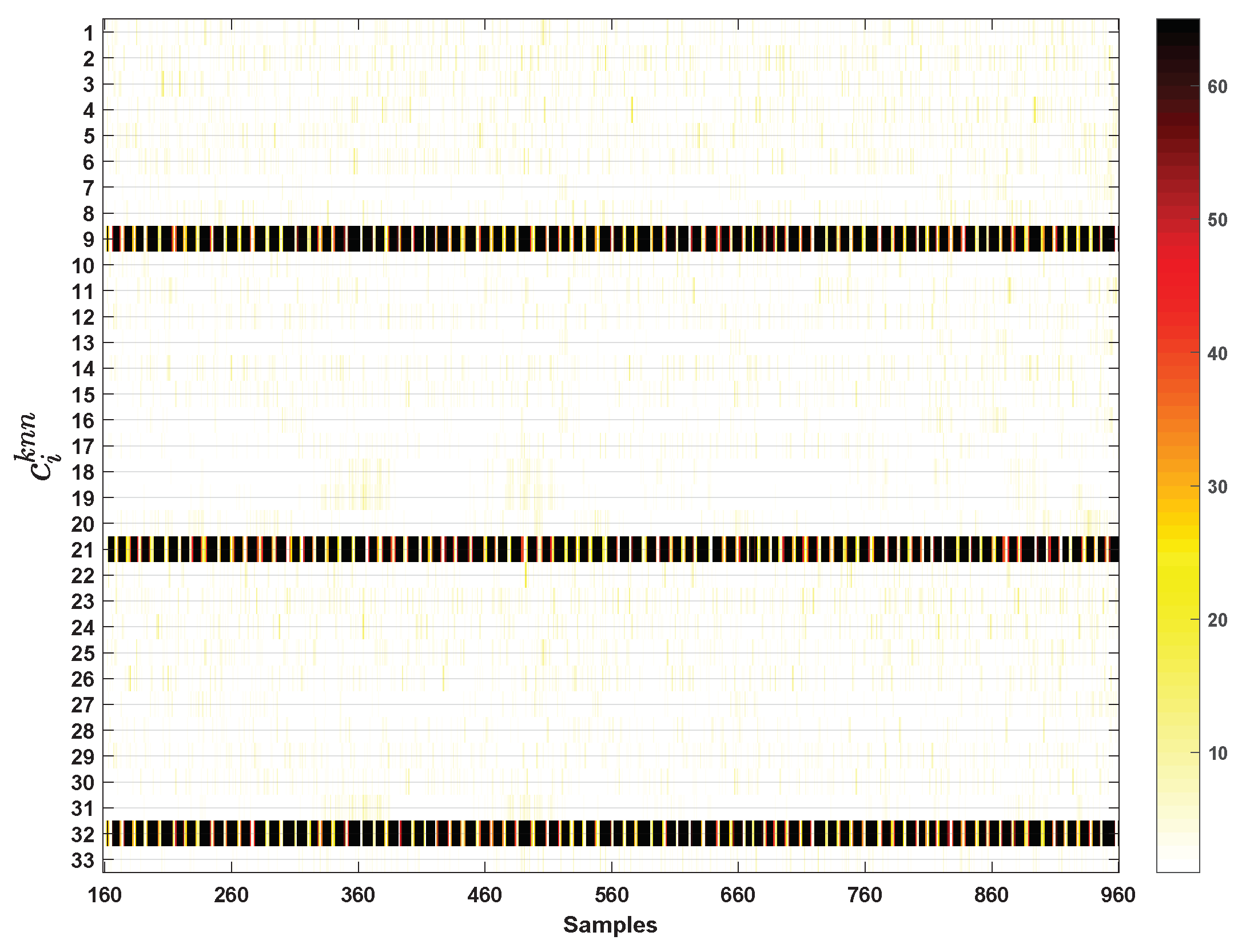
2.2. Variable Contribution by kNN
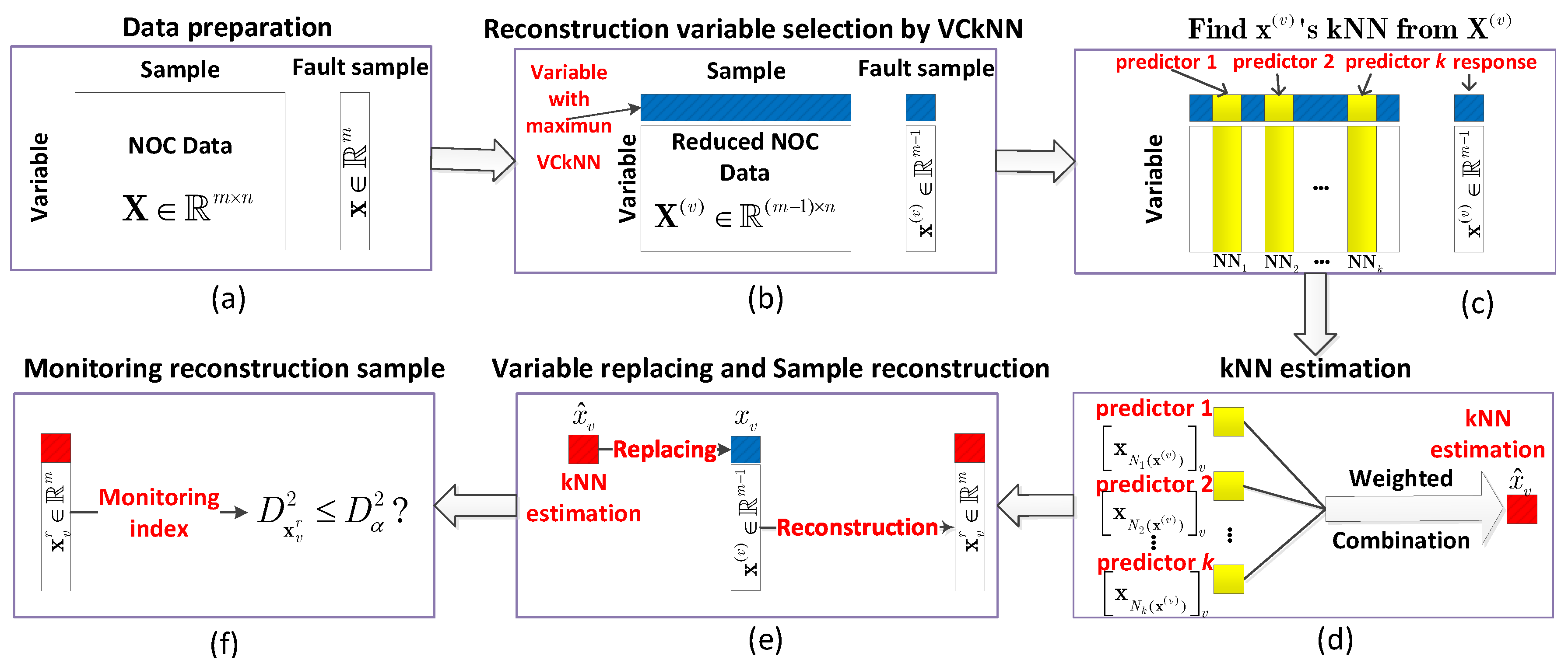
3. The Proposed Method for Fault Variable Identification by kNN Reconstruction
- Calculate the ranking of VCkNN forwhere is the variable with i-th largest contribution.
- Divide the data into two partsAdd into candidate variable set and divide the NOC data and fault sample according to the candidate setwhere is the cardinality of set v.
- Find ’s kNN, , from the reduced NOC data
- Predict the variables in set vwhere is the normalized weight obtained from the negative exponential distance between and its l-th nearest neighbor from . is the label of ’s lth nearest neighbor in reduced training set . represents the -th entry of the sample .
- Obtain reconstruction sampleReconstructing the fault sample by replacing its entries with their estimations .
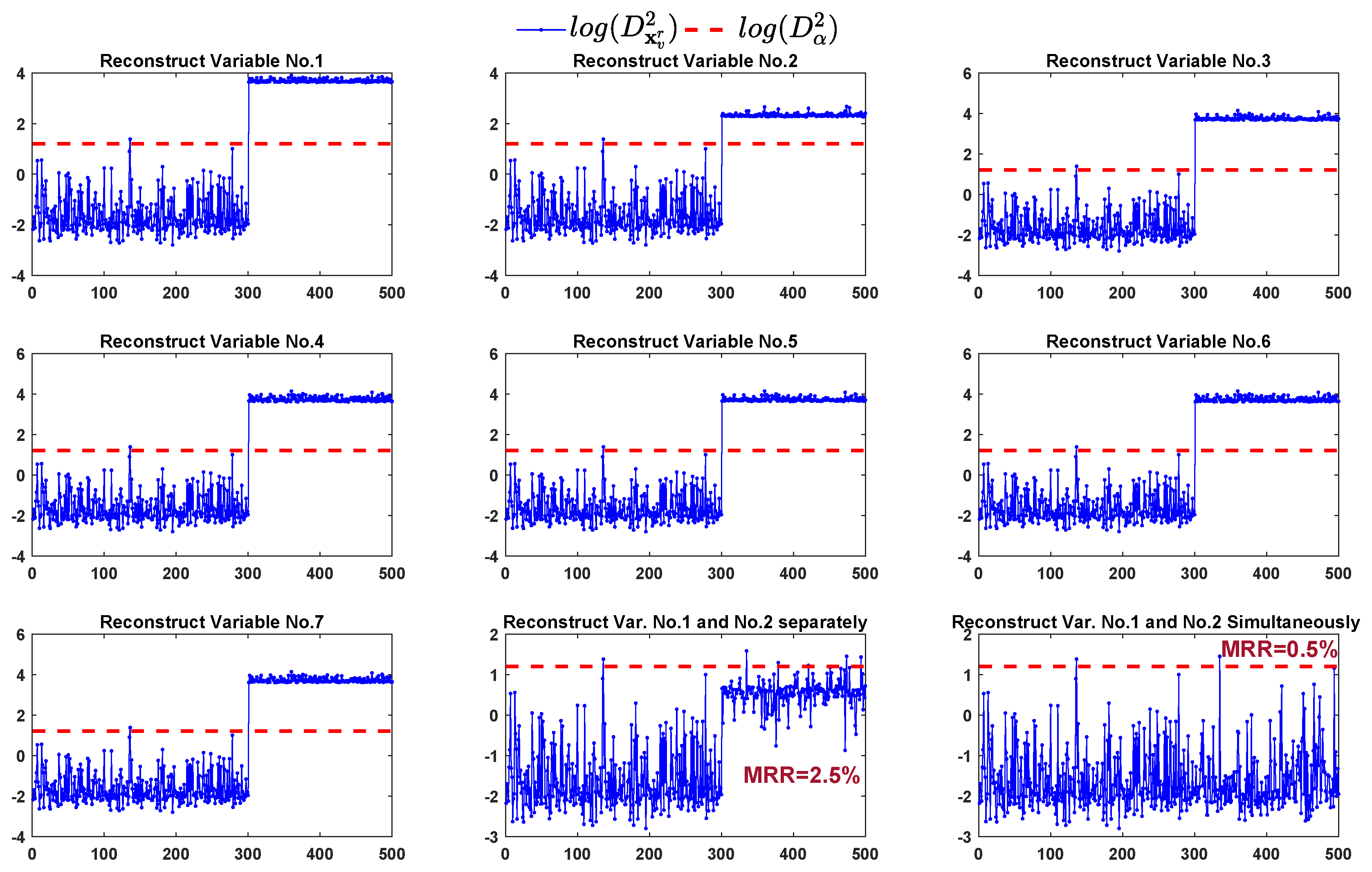
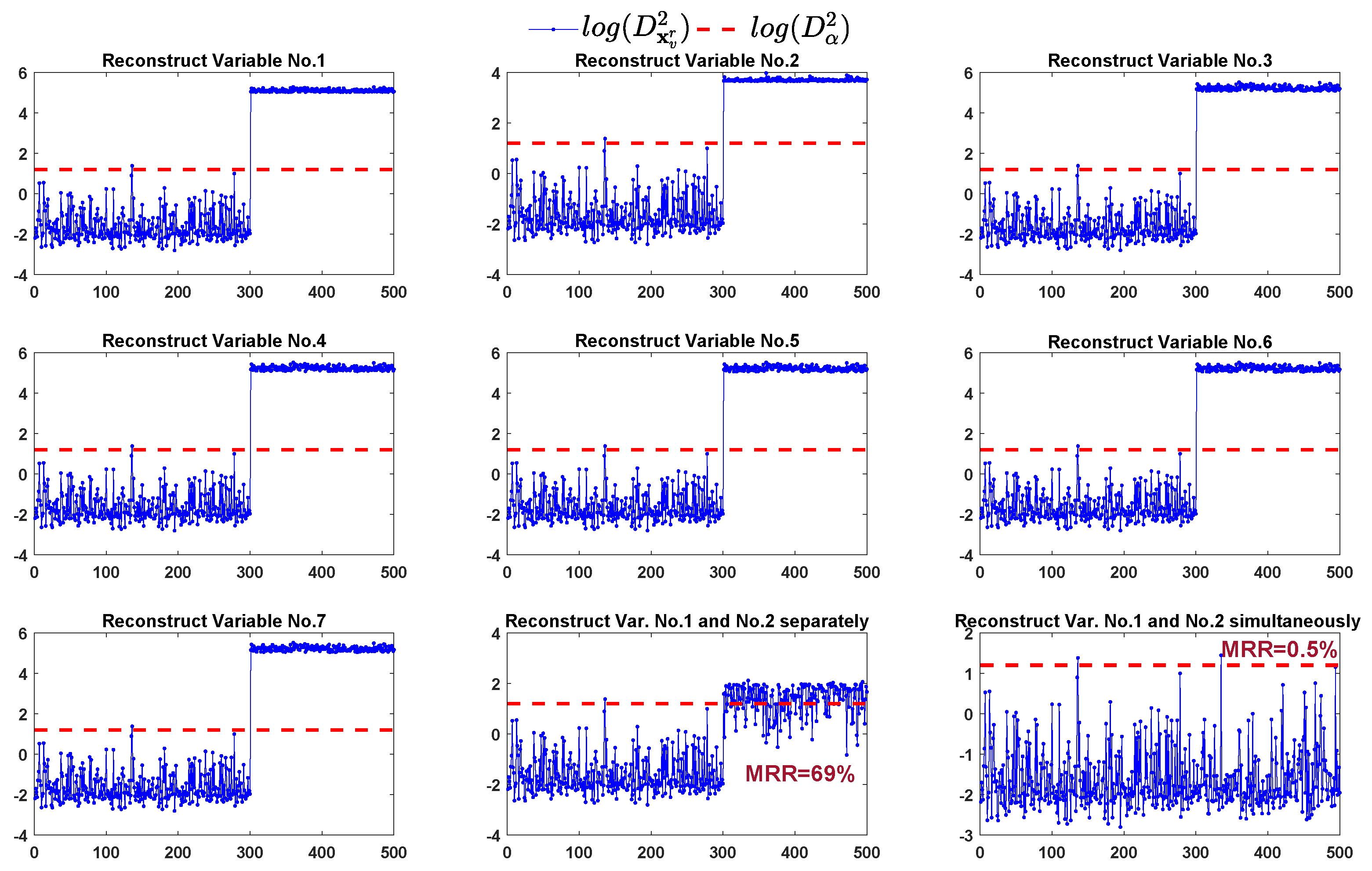
- Faulty variables identificationCalculating detection index of the reconstructed sample using Equation (2), . If , then the faulty variables are determined as those variables in set v; otherwise, return to step 2 and .
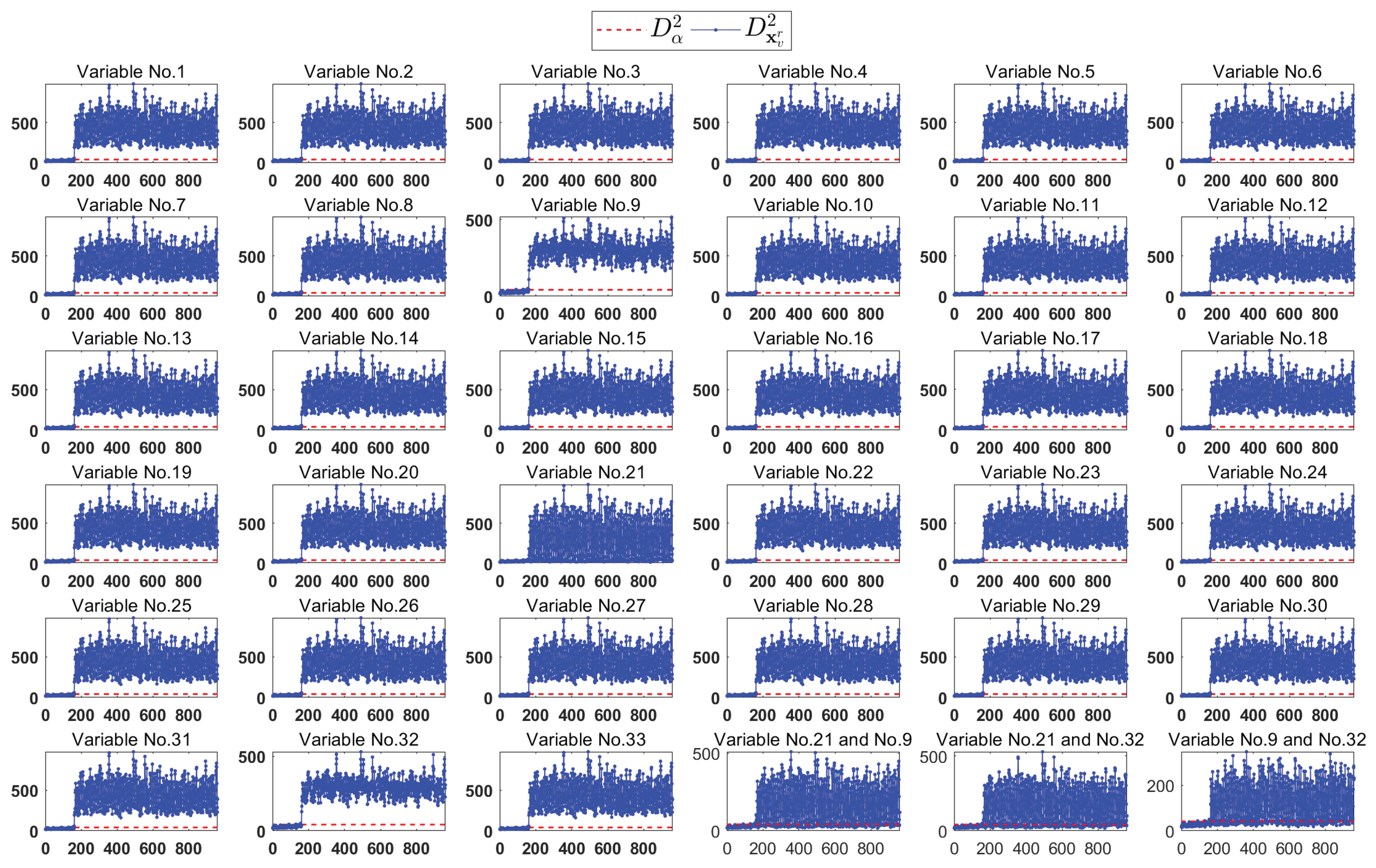
4. Results
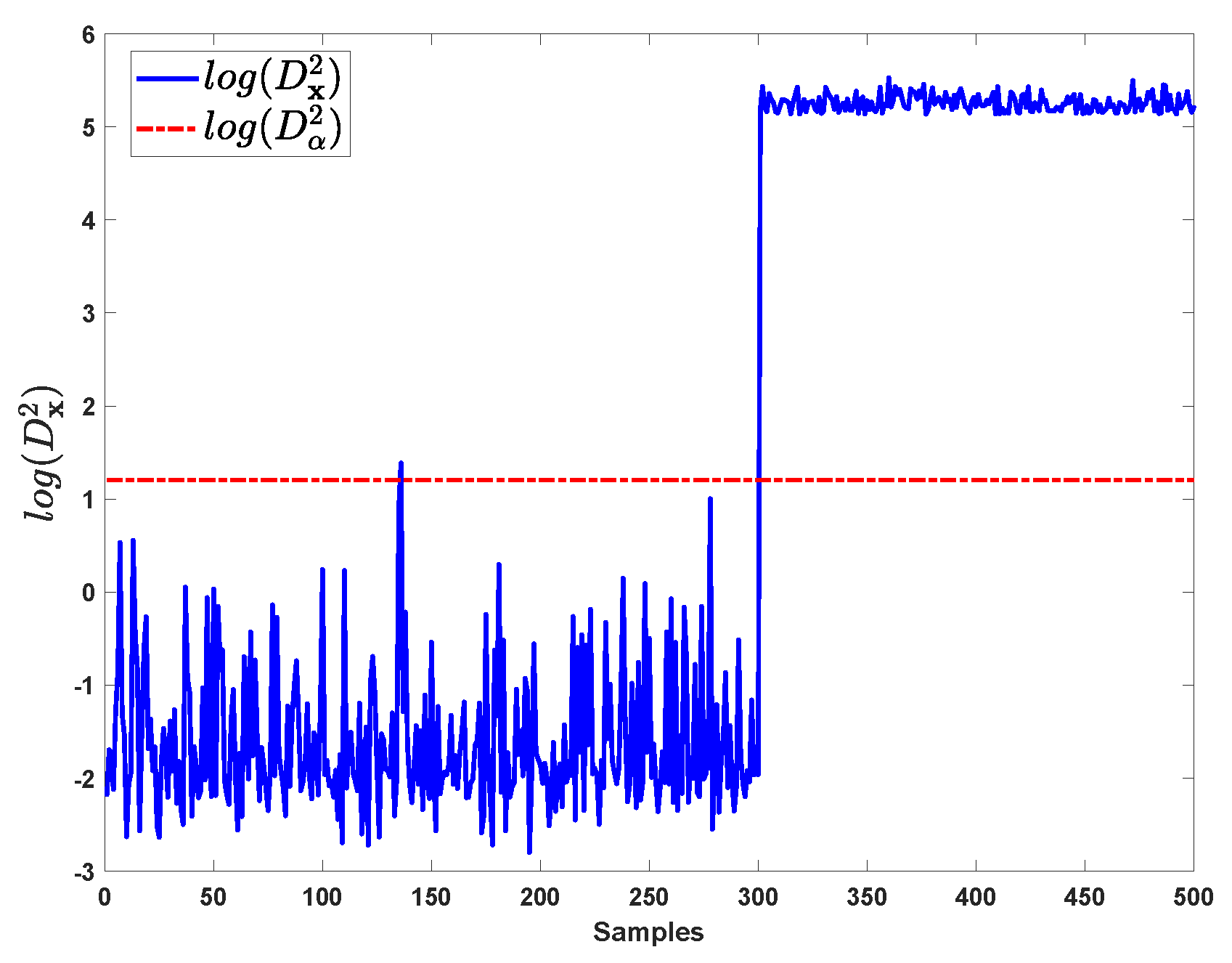
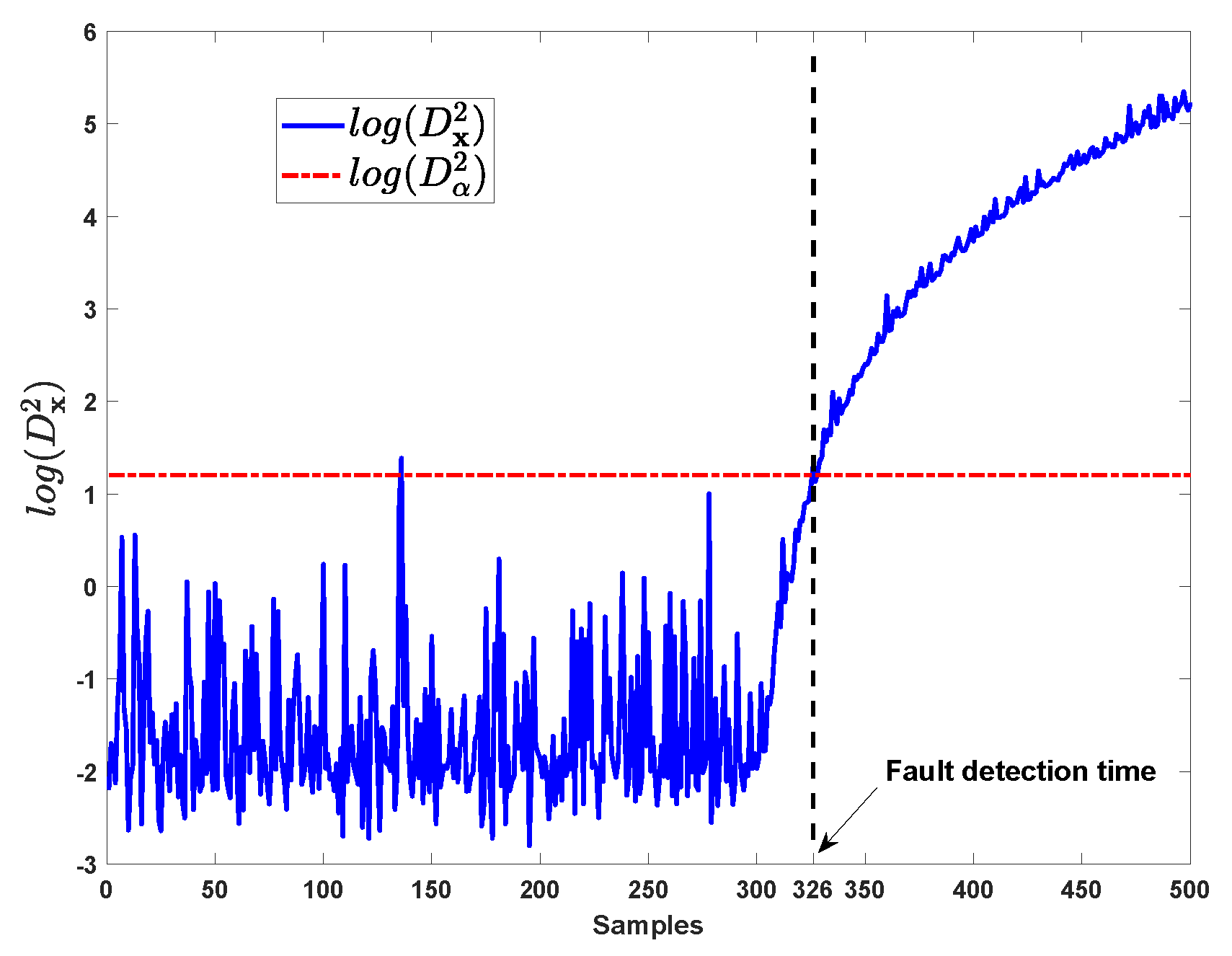
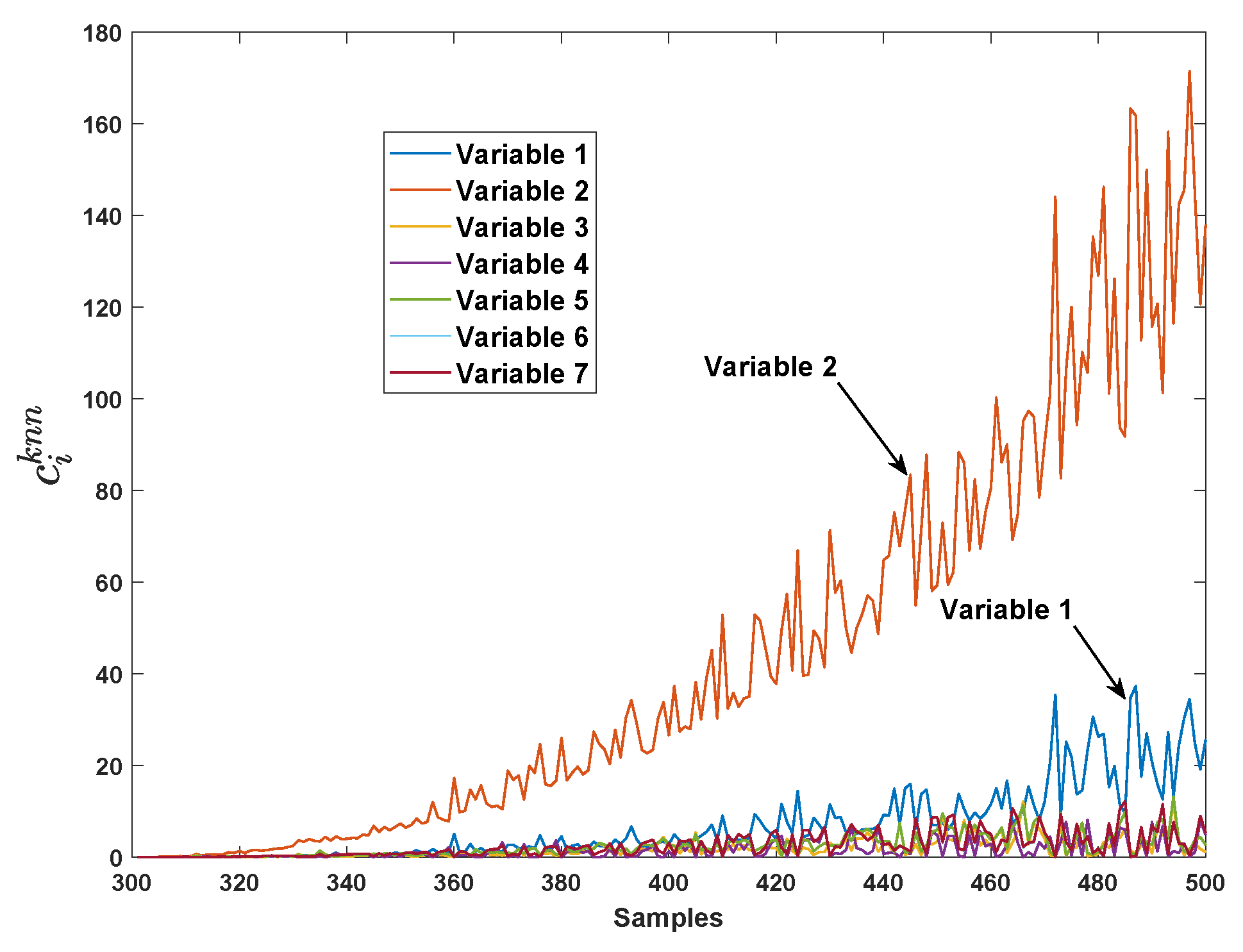
4.1. Numerical Simulation
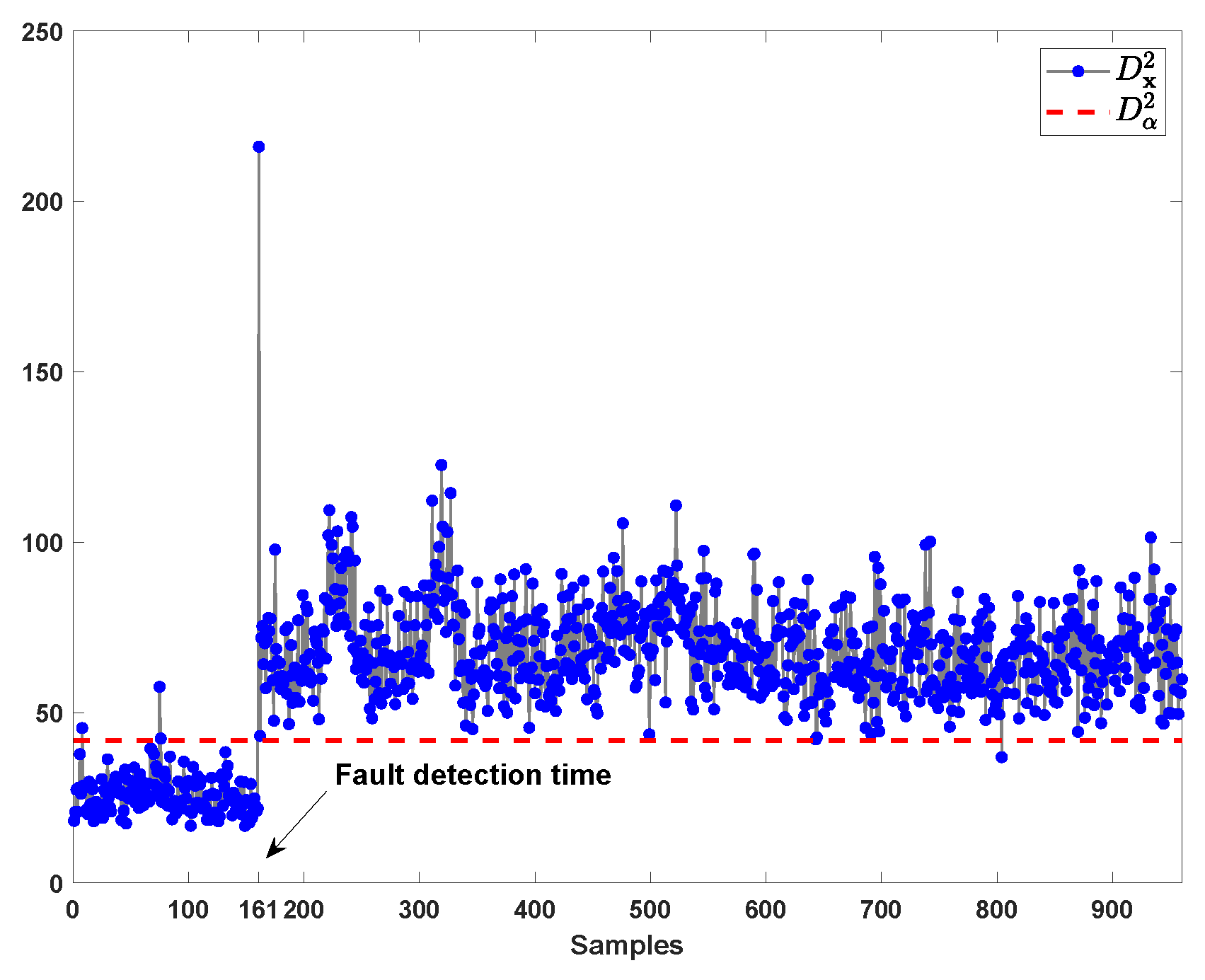
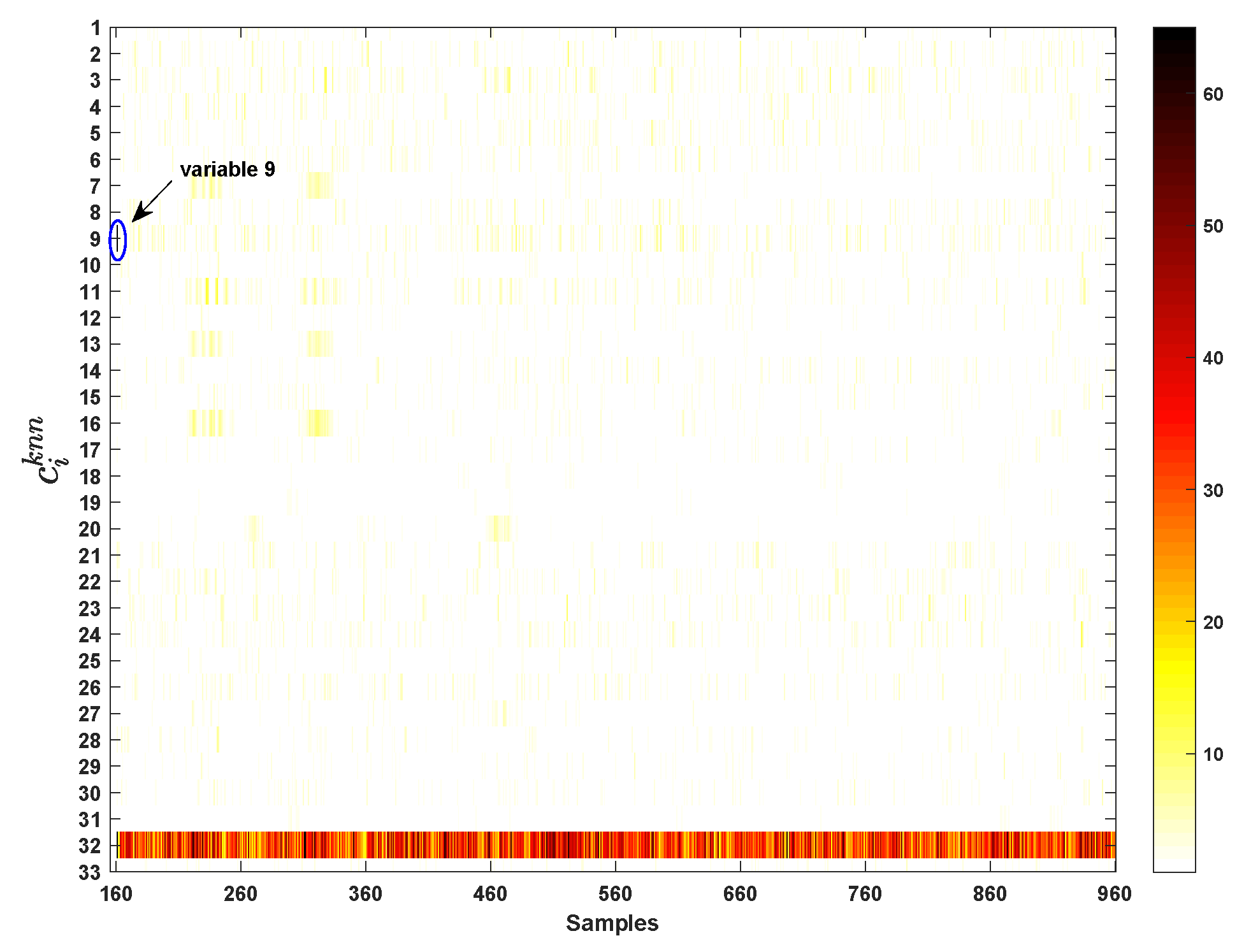
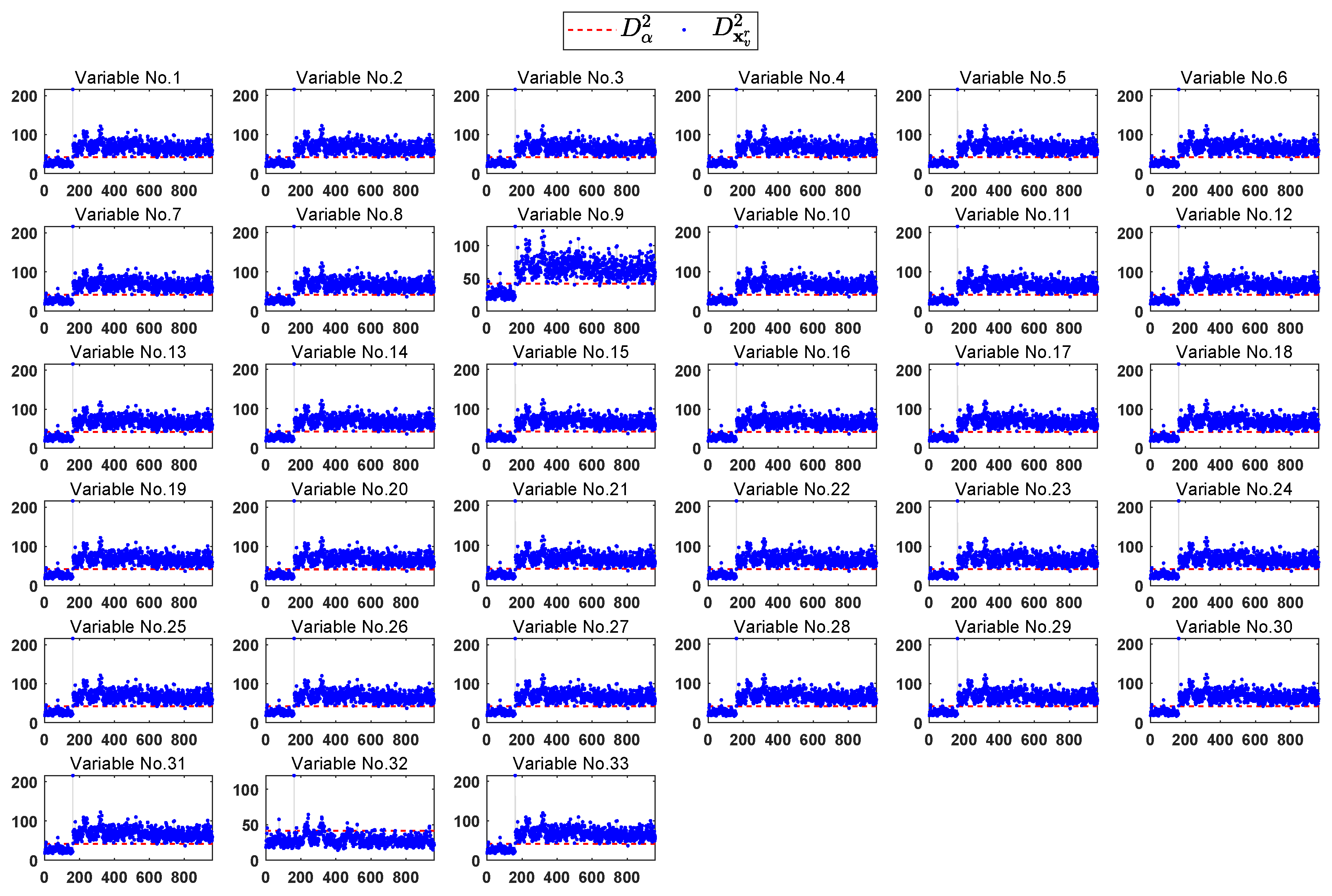
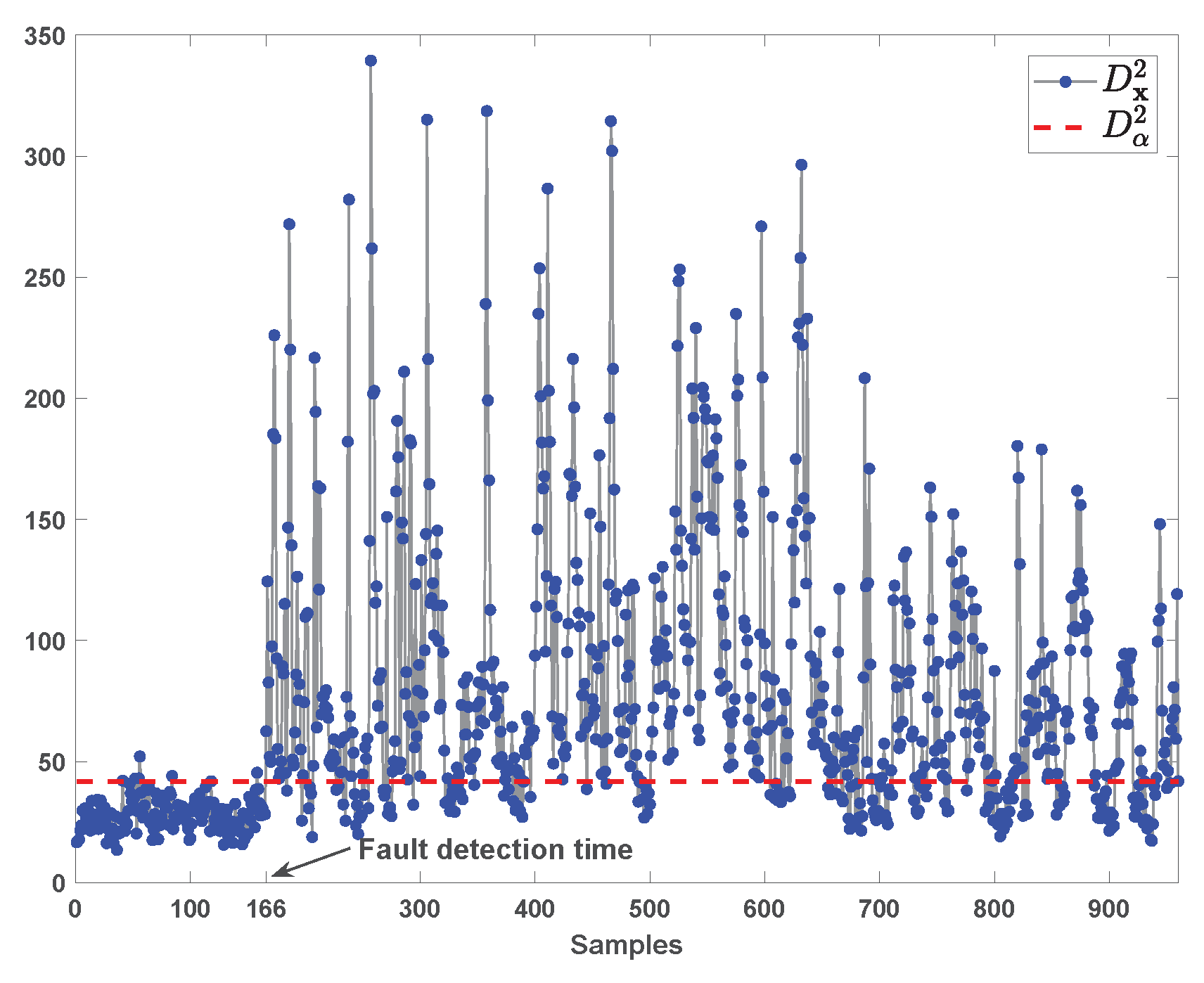
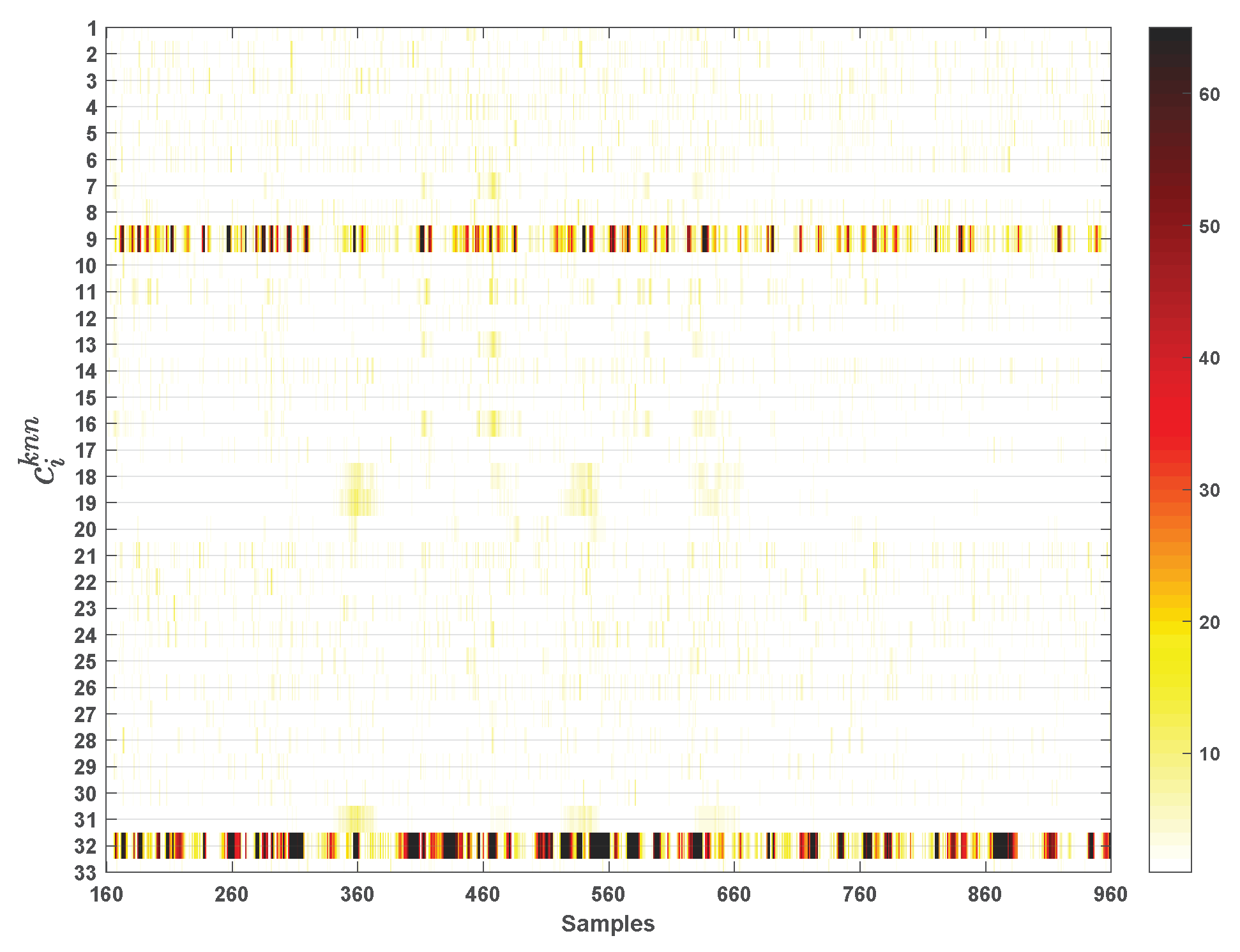
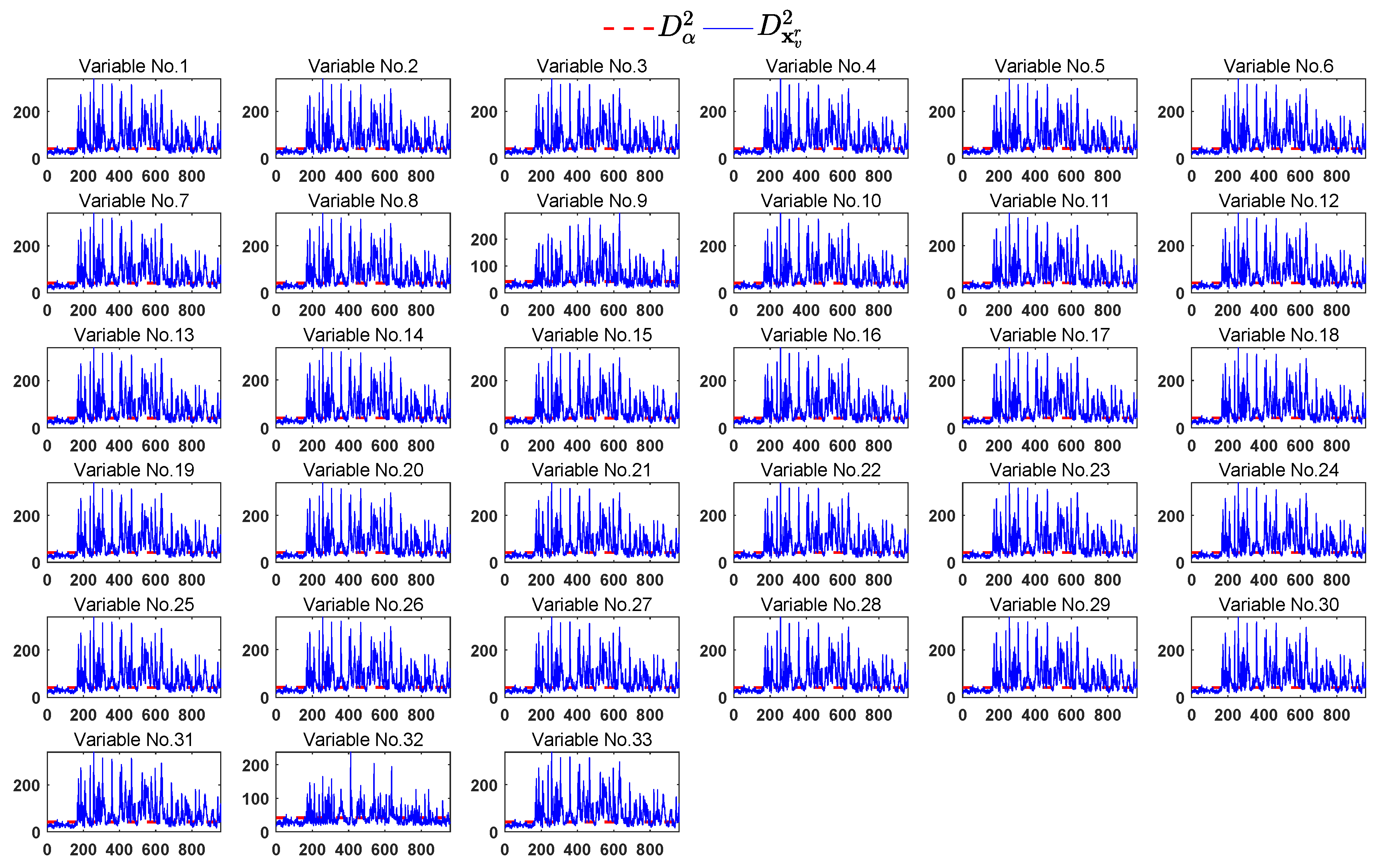
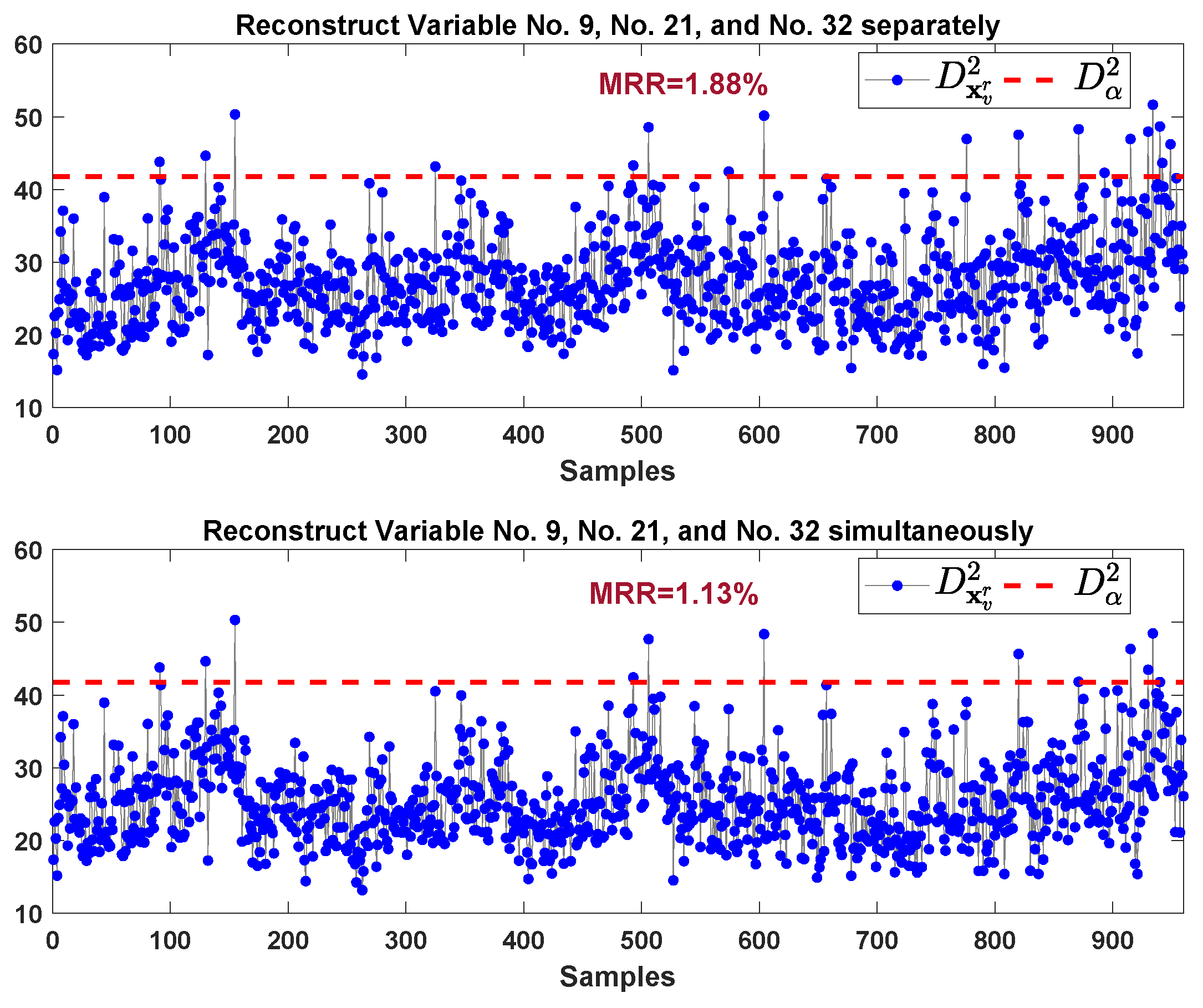
4.2. TE Process
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| kNN | k Nearest Neighbor |
| VCkNN | Variable Contribution by kNN |
| MSPM | Multivariate Statistical Process Monitoring |
| FD-kNN | Fault Detection based on kNN |
| NOC | Normal Operation Condition |
| FVI-kNN | Fault Variable Identification based on kNN |
| MRI | Maximum Reduction In Detection Index |
| IFVI-kNN | Improved FVI-kNN |
| MRR | Missing Reconstruction Ratio |
| TE | Tennessee Eastman |
References
- He, Q.P.; Wang, J.; Shah, D. Feature Space Monitoring for Smart Manufacturing via Statistics Pattern Analysis. Comput. Chem. Eng. 2019. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Ding, S.X.; Huang, B. Data Mining and Analytics in the Process Industry: The Role of Machine Learning. IEEE Access 2017, 5, 20590–20616. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Gao, F. Review of recent research on data-based process monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.; Xie, X.; Luo, H. A Review on Basic Data-Driven Approaches for Industrial Process Monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6418–6428. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Fault detection using the k-nearest neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2007, 20, 345–354. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, J.; Xu, Y. Monitoring of processes with multiple operating modes through multiple principle component analysis models. Ind. Eng. Chem. Res. 2004, 43, 7025–7035. [Google Scholar] [CrossRef]
- Qin, Y.; Zhao, C.; Zhang, S.; Gao, F. Multimode and Multiphase Batch Processes Understanding and Monitoring Based on between-Mode Similarity Evaluation and Multimode Discriminative Information Analysis. Ind. Eng. Chem. Res. 2017, 56, 9679–9690. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, C.; Gao, F. Two-directional concurrent strategy of mode identification and sequential phase division for multimode and multiphase batch process monitoring with uneven lengths. Chem. Eng. Sci. 2018, 178, 104–117. [Google Scholar] [CrossRef]
- Lee, J.M.; Yoo, C.; Choi, S.W.; Vanrolleghem, P.A.; Lee, I.B. Nonlinear process monitoring using kernel principal component analysis. Chem. Eng. Sci. 2004, 59, 223–234. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Process monitoring based on independent component analysis-principal component analysis (ICA-PCA) and similarity factors. Ind. Eng. Chem. Res. 2007, 46, 2054–2063. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C. Robust Monitoring and Fault Isolation of Nonlinear Industrial Processes Using Denoising Autoencoder and Elastic Net. IEEE Trans. Control Syst. Technol. 2019. [Google Scholar] [CrossRef]
- Zhao, C.; Huang, B. A Full-condition Monitoring Method for Nonstationary Dynamic Chemical Processes with Cointegration and Slow Feature Analysis. AIChE J. 2018, 64, 1662–1681. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Large-scale semiconductor process fault detection using a fast pattern recognition-based method. IEEE Trans. Semicond. Manuf. 2010, 23, 194–200. [Google Scholar] [CrossRef]
- Verdier, G.; Ferreira, A. Adaptive Mahalanobis Distance and k-Nearest Neighbor Rule for Fault Detection in Semiconductor Manufacturing. IEEE Trans. Semicond. Manuf. 2011, 24, 59–68. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X. Diffusion maps based k-nearest-neighbor rule technique for semiconductor manufacturing process fault detection. Chemom. Intell. Lab. Syst. 2014, 136, 47–57. [Google Scholar] [CrossRef]
- Zhou, Z.; Wen, C.L.; Yang, C.J. Fault Detection Using Random Projections and k-Nearest Neighbor Rule for Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2015, 28, 70–79. [Google Scholar] [CrossRef]
- Zhou, Z.; Wen, C.; Yang, C. Fault Isolation Based on k-Nearest Neighbor Rule for Industrial Processes. IEEE Trans. Ind. Electron. 2016, 63, 2578–2586. [Google Scholar] [CrossRef]
- Miller, P.; Swanson, R.E.; Heckler, C.E. Contribution plots: A missing link in multivariate quality control. Appl. Math. Comput. Sci. 1998, 8, 775–792. [Google Scholar]
- Dunia, R.; Qin, S.J.; Edgar, T.F.; McAvoy, T.J. Identification of faulty sensors using principal component analysis. AIChE J. 1996, 42, 2797–2812. [Google Scholar] [CrossRef]
- Yue, H.H.; Qin, S.J. Reconstruction-based fault identification using a combined index. Ind. Eng. Chem. Res. 2001, 40, 4403–4414. [Google Scholar] [CrossRef]
- Alcala, C.F.; Qin, S.J. Reconstruction-based contribution for process monitoring. Automatica 2009, 45, 1593–1600. [Google Scholar] [CrossRef]
- Alcala, C.F.; Qin, S.J. Analysis and generalization of fault diagnosis methods for process monitoring. J. Process Control 2011, 21, 322–330. [Google Scholar] [CrossRef]
- Westerhuis, J.A.; Gurden, S.P.; Smilde, A.K. Generalized contribution plots in multivariate statistical process monitoring. Chemom. Intell. Lab. Syst. 2000, 51, 95–114. [Google Scholar] [CrossRef]
- Mnassri, B.; Adel, E.; Mostafa, E.; Ouladsine, M. Generalization and analysis of sufficient conditions for PCA-based fault detectability and isolability. Annu. Rev. Control 2013, 37, 154–162. [Google Scholar] [CrossRef]
- Mnassri, B.; Adel, E.M.E.; Ouladsine, M. Reconstruction-based Contribution approaches for improved fault diagnosis using principal component analysis. J. Process Control 2015, 33, 60–76. [Google Scholar] [CrossRef]
- Wang, G.; Liu, J.; Li, Y. Fault diagnosis using kNN reconstruction on MRI variables. J. Chemom. 2015, 29, 399–410. [Google Scholar] [CrossRef]
- Zhou, Z.; Lei, J.; Ge, Z.; Xu, X. Fault variables recognition using improved k-nearest neighbor reconstruction. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 5562–5565. [Google Scholar] [CrossRef]
- He, B.; Yang, X.; Chen, T.; Zhang, J. Reconstruction-based multivariate contribution analysis for fault isolation: A branch and bound approach. J. Process Control 2012, 22, 1228–1236. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Wang, W. Efficient faulty variable selection and parsimonious reconstruction modelling for fault isolation. J. Process Control 2016, 38, 31–41. [Google Scholar] [CrossRef]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Russell, E.L.; Chiang, L.H.; Braatz, R.D. Data-Driven Techniques for Fault Detection and Diagnosis in Chemical Processes; Springer: London, UK, 2000. [Google Scholar] [CrossRef]
- Russell, E.; Chiang, L.; Braatz, R. Tennessee Eastman Problem Simulation Data. Available online: http://web.mit.edu/braatzgroup/links.html (accessed on 27 April 2015).
- He, Q.P.; Qin, S.J.; Wang, J. A new fault diagnosis method using fault directions in Fisher discriminant analysis. AIChE J. 2005, 51, 555–571. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Fault Detection Time | MRR(%) | Reconstruction Times Required | ||
|---|---|---|---|---|---|
| FVI-kNN | Proposed Method | FVI-kNN | Proposed Method | ||
| case 1 | 301st | 2.5 | 0.5 | 8(28) a | 2 |
| case 2 | 301st | 69 | 0.5 | 8(28) | 2 |
| case 3 | 326th | 25 | 0.5 | 8(28) | 2 |
| Faults | Fault Detection Time | MRR(%) | Reconstruction Times Required | ||
|---|---|---|---|---|---|
| FVI-kNN | Proposed Method | FVI-kNN | Proposed Method | ||
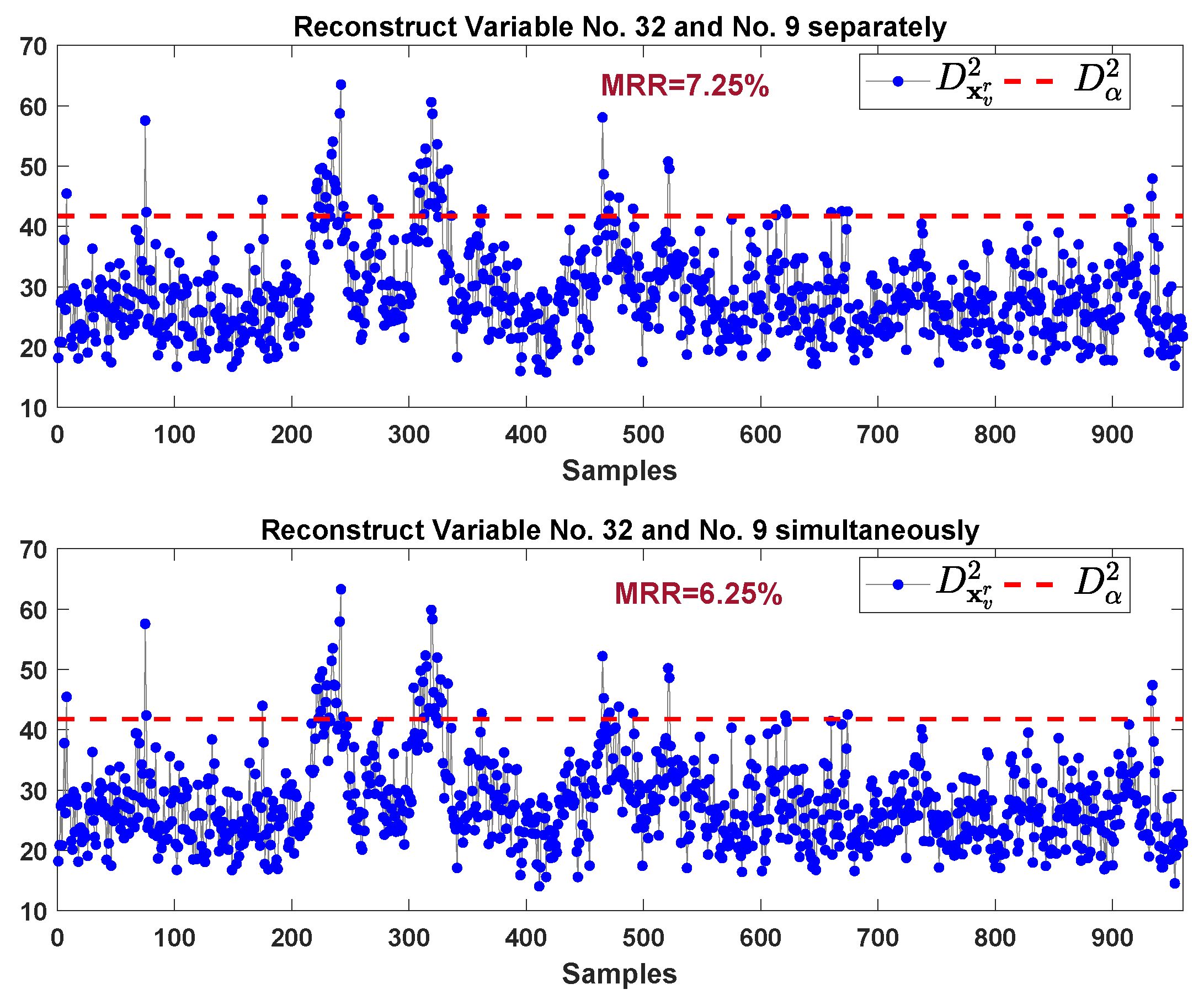
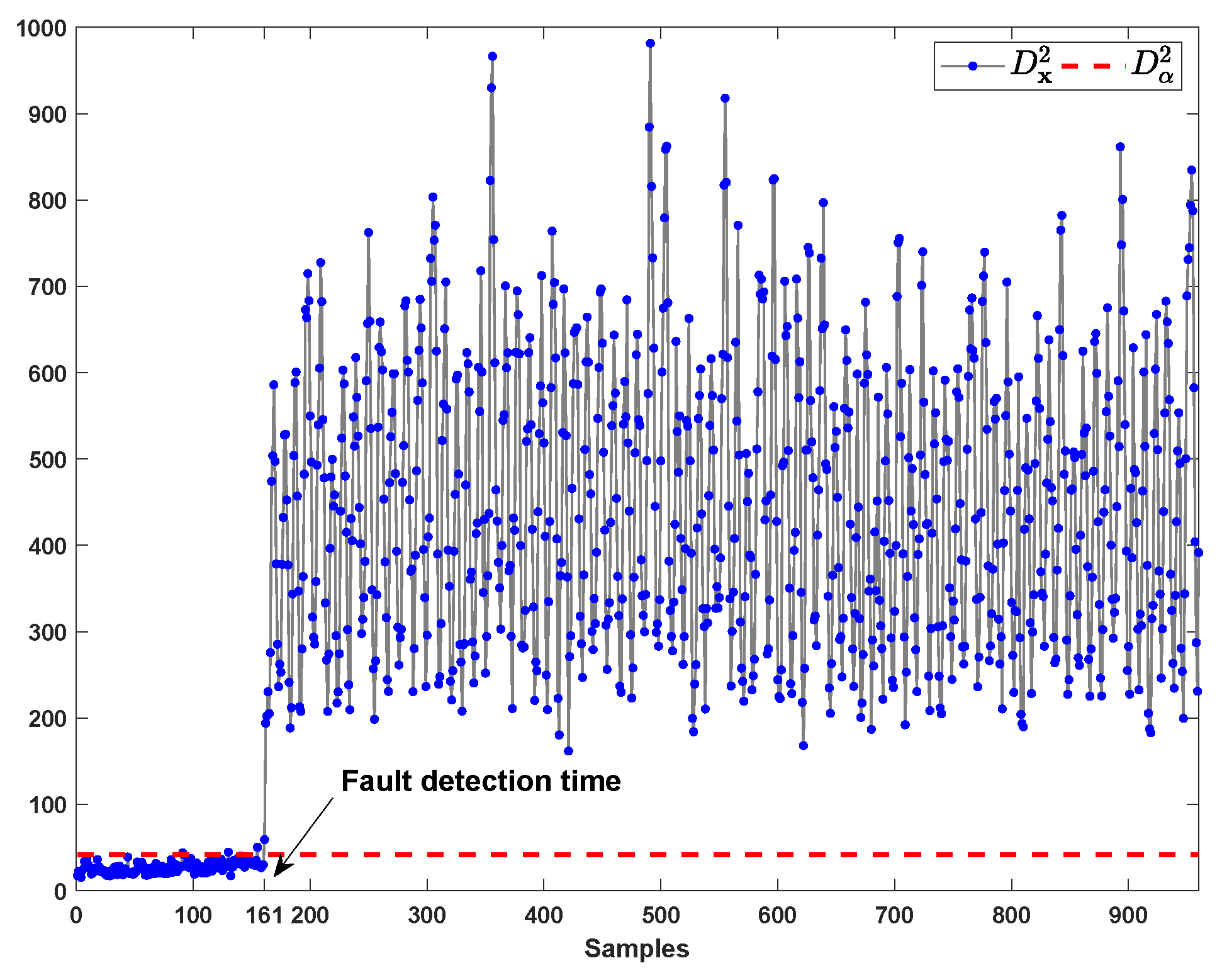
| Fault 1 | 161st | 7.25 | 6.25 | 34(528) a | 2 |
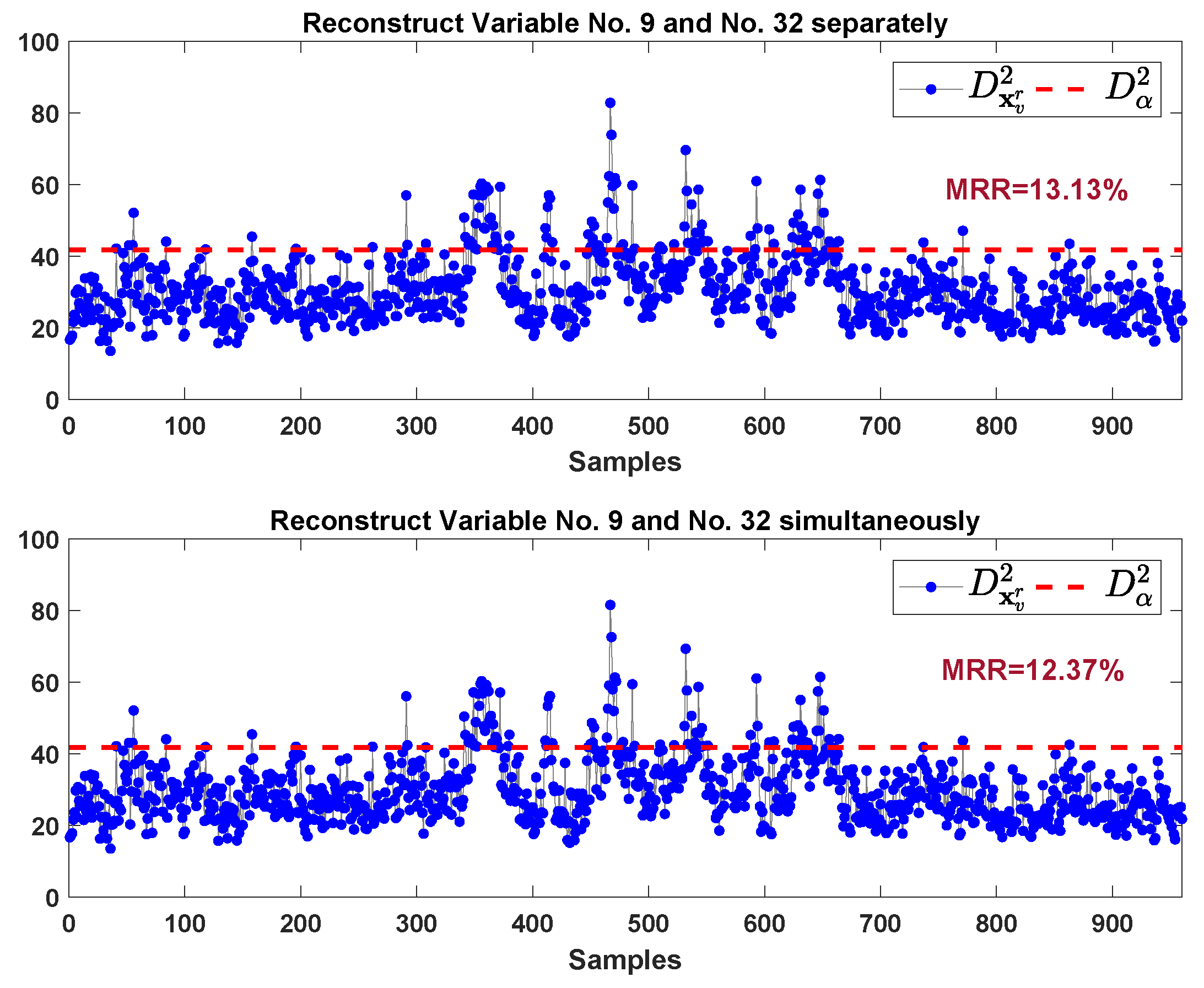
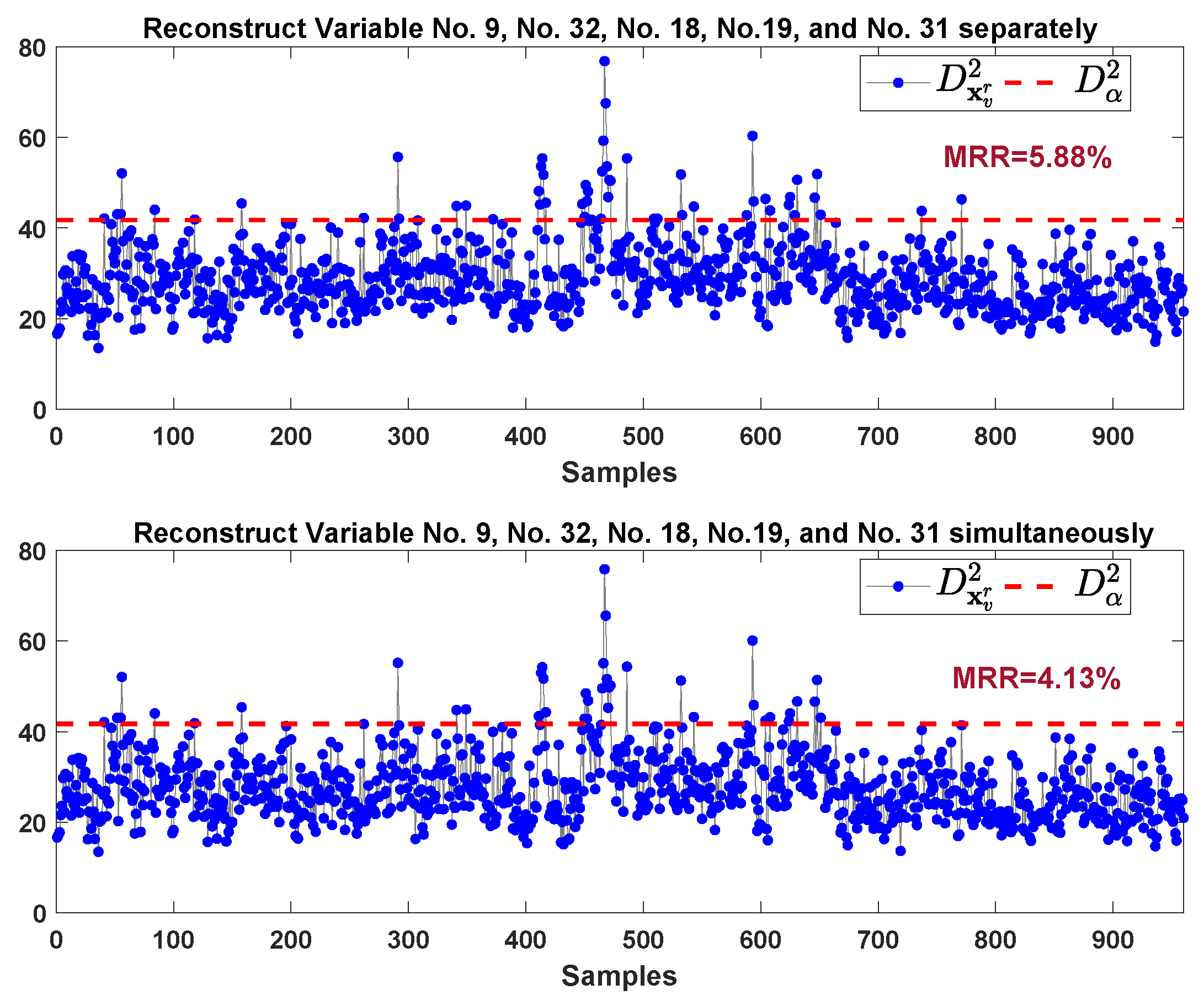
| Fault 11 | 166th | 5.88 | 4.13 | 40,922(237,336) | 5 |
| Fault 14 | 161st | 1.88 | 1.13 | 529(5456) | 3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Li, Z.; Cai, Z.; Wang, P. Fault Identification Using Fast k-Nearest Neighbor Reconstruction. Processes 2019, 7, 340. https://doi.org/10.3390/pr7060340
Zhou Z, Li Z, Cai Z, Wang P. Fault Identification Using Fast k-Nearest Neighbor Reconstruction. Processes. 2019; 7(6):340. https://doi.org/10.3390/pr7060340
Chicago/Turabian StyleZhou, Zhe, Zuxin Li, Zhiduan Cai, and Peiliang Wang. 2019. "Fault Identification Using Fast k-Nearest Neighbor Reconstruction" Processes 7, no. 6: 340. https://doi.org/10.3390/pr7060340
APA StyleZhou, Z., Li, Z., Cai, Z., & Wang, P. (2019). Fault Identification Using Fast k-Nearest Neighbor Reconstruction. Processes, 7(6), 340. https://doi.org/10.3390/pr7060340