Multimode Operating Performance Visualization and Nonoptimal Cause Identification



Abstract
:
1. Introduction
2. Visual Monitoring Model for Operating Performance of Multimode Process
2.1. Multimode Data Recognition Based on Subtractive Clustering
- (1)
- For offline data, the data are normalized with the mean and standard deviation. For convenience of description, it is still indicated by .
- (2)
- Each data point is considered as a potential cluster center, and a measure of the potential of data point is defined as:where and (5 < < 15) is a positive constant, which defines the radius of the neighborhood and affects the number of clusters. Data points outside this radius have minimal influence on the potential. The data point with many neighboring data points have a high potential value. After the potential of every data point has been computed, the data point with the highest potential is selected as the first cluster center.
- (3)
- Let be the location of the first cluster center and be its potential value. Then, the potential of each data point can be updated by the following formula:where and is a positive constant, generally defined as [19]. Then, the data point corresponding to the maximum value in is selected as the second cluster center and iterated through the above formula until the cluster centers are obtained, so that , (0 < < 0.5) is a small fraction and its size determines the number of cluster centers. As increases, the number of cluster centers will decrease.
- (4)
- After each cluster center is obtained, different datasets are divided by calculating the similarity between each data point and each cluster center. The calculation formula is as follows:
- (5)
- The larger is, the closer the data point is to the cluster center. According to the maximum similarity of each data point corresponding to the cluster center, all data are divided into datasets, and a similarity threshold (0.5 < < 1) is set. When the maximum similarity corresponding to the data point is less than , it is considered to be transition mode data and is removed from the dataset. In this way, only datasets that contain a steady-state process of different operating modes are obtained. In this paper, the values of , , and are determined in Section 4.1.
2.2. Feature Extraction of Multimode Data
2.3. Visualization of Different Operation Mode Features
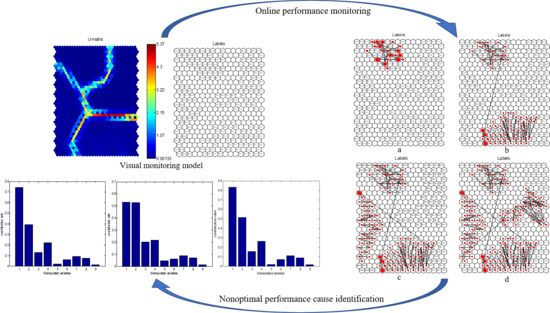
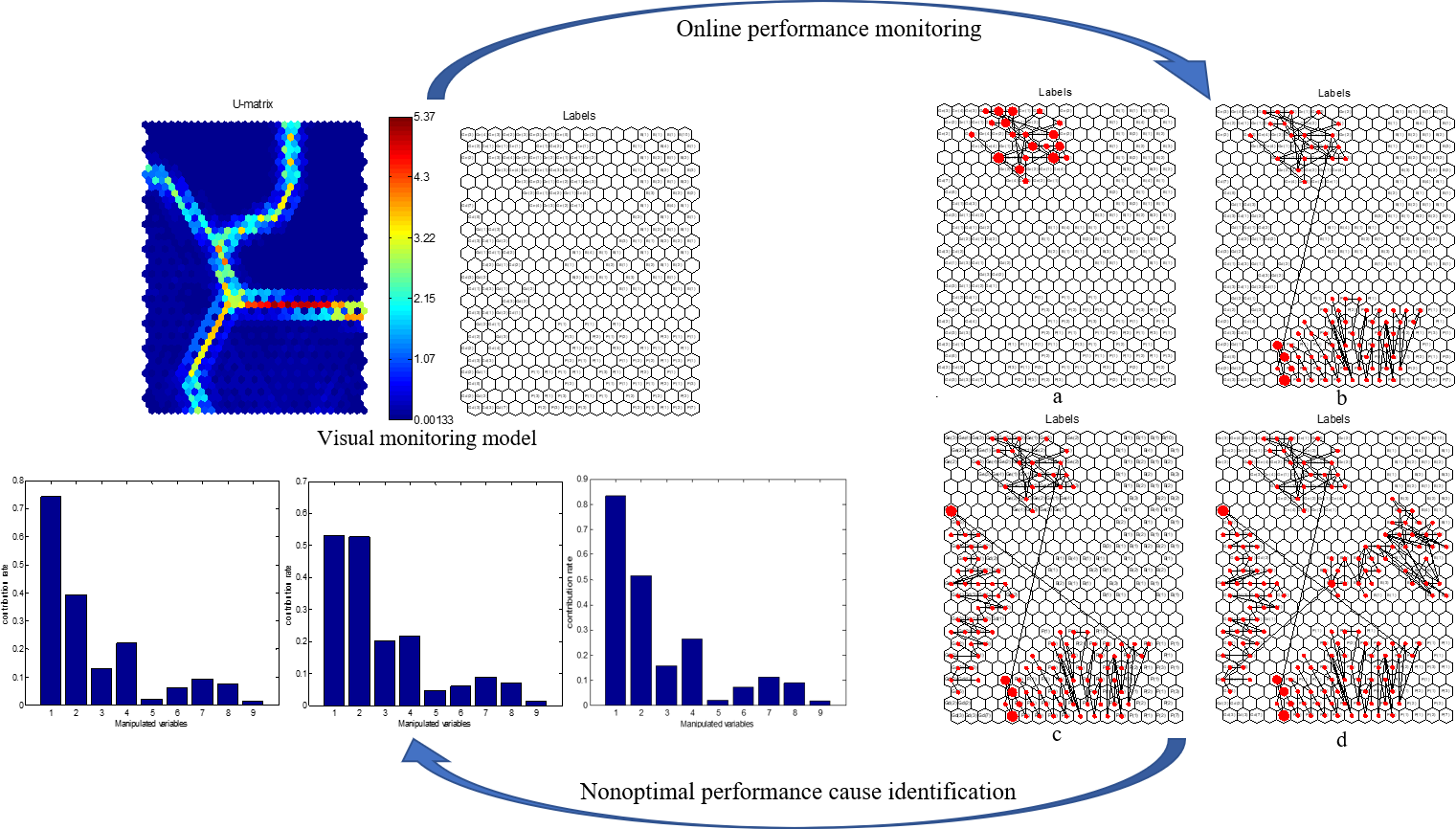
2.4. Realization of Visual Monitoring Process for Multimode Operating Performance
- (1)
- The collected historical data in the normal running state of the production process are normalized to the value of [0, 1].
- (2)
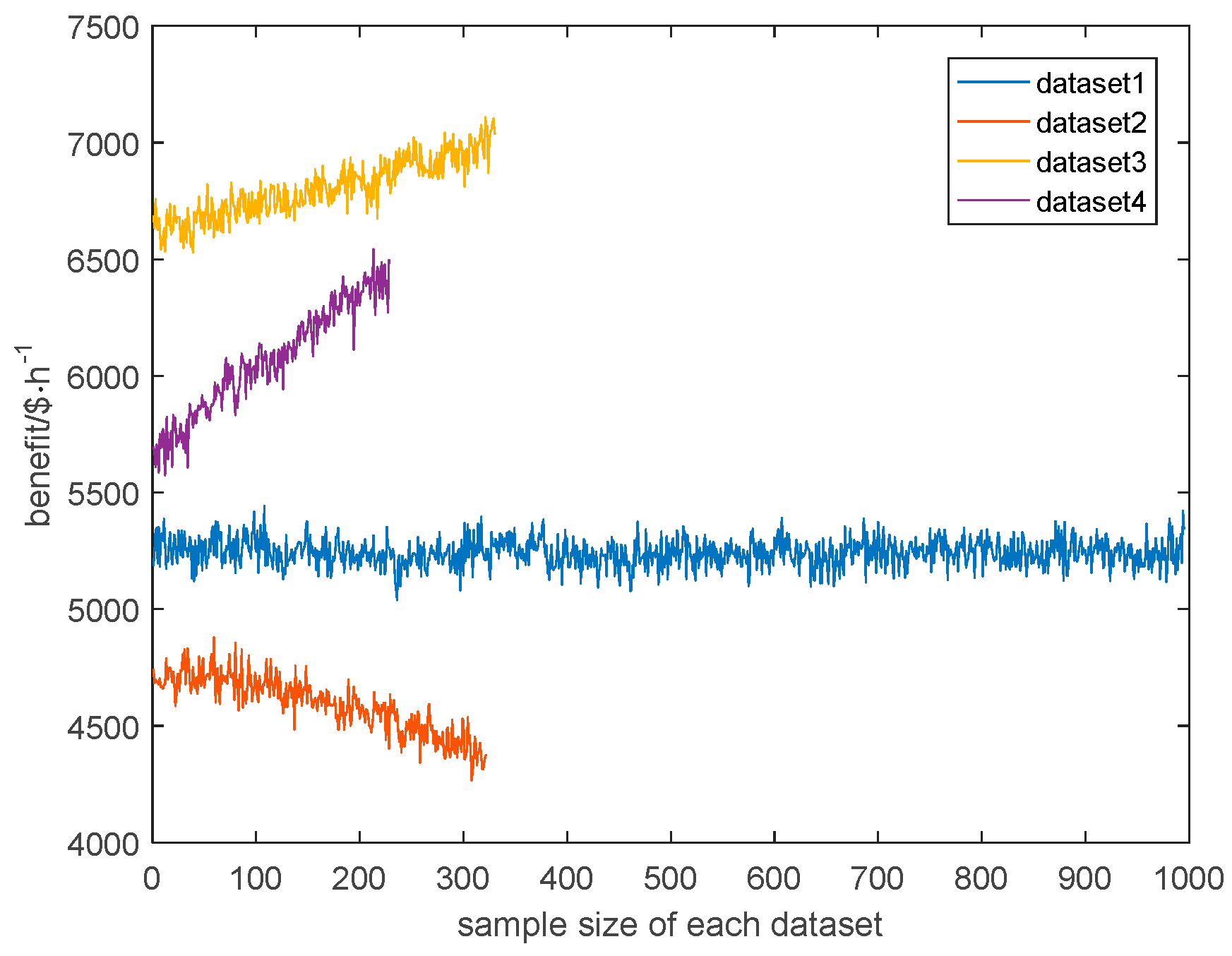
- Through subtractive clustering, different cluster centers are obtained according to Equations (1) and (2), and then all data are classified according to Equation (3), and the transition process data are eliminated. The economic benefits of the classified datasets are then calculated based on the process knowledge to determine the performance grade of each dataset (e.g., optimal, average, or poor).
- (3)
- The common variable correlation subspace between each dataset classified in step (2) is extracted by the MsPCA algorithm using Equations (4)–(6). Then, the amplitudes of all datasets on is calculated according to Equation (7), and the sub-vectors that make their amplitudes different from are obtained. Finally, the unique feature vectors related to the performance grade of each dataset are obtained by Equations (10) and (11).
- (4)
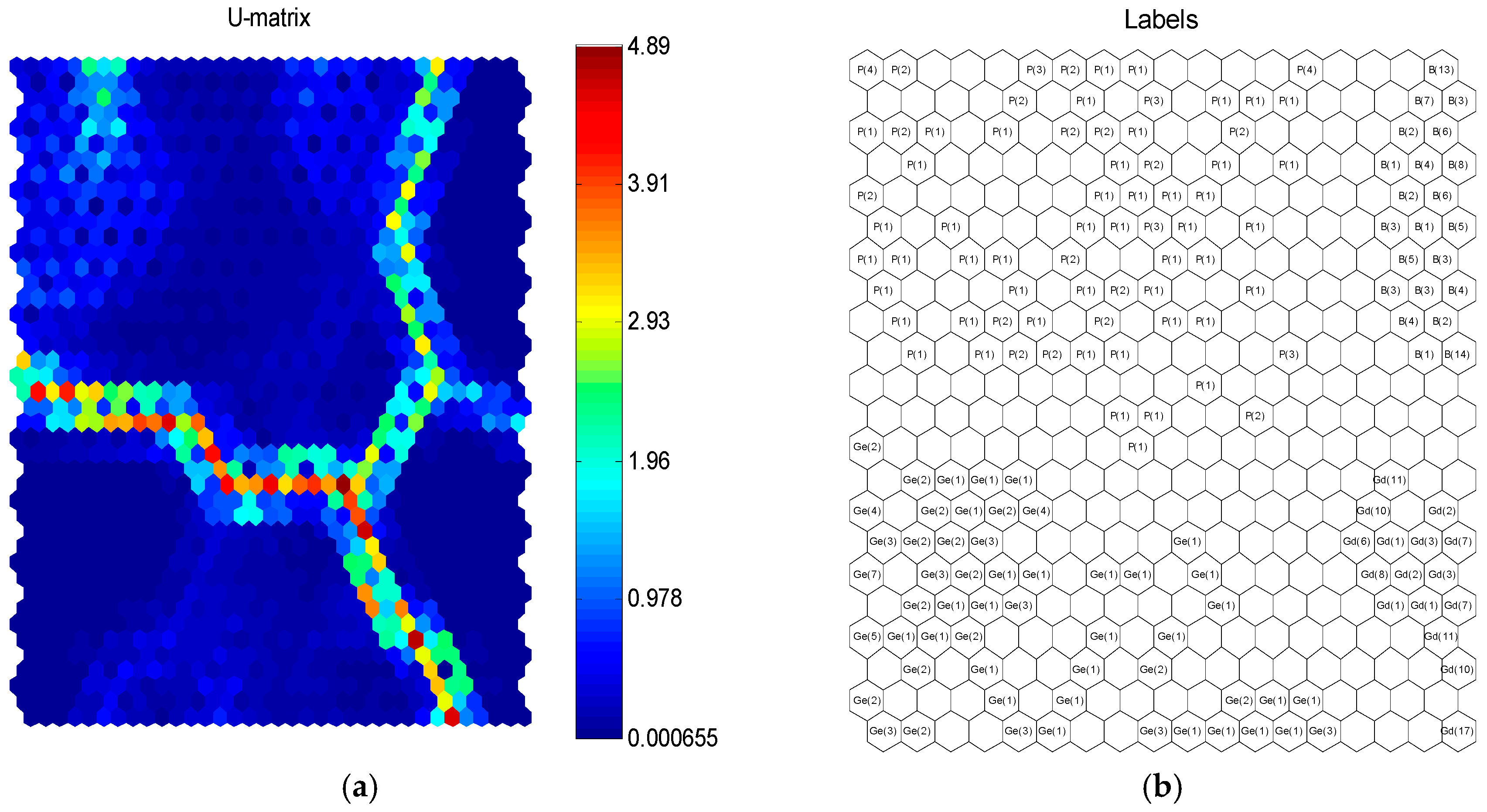
- The unique feature vectors in step (3) are trained on the SOM. First, the number of neurons is determined by Equation (12), and weights are initialized using as the input of SOM. Then, winning neurons are selected according to Equation (13), and weights are updated according to Equations (14) and (15) until . Finally, the training results are displayed on a 2D grid, and a visual monitoring model is obtained so that the multimode operating performance can be monitored in real time according to the model.
3. Online Process Operating Performance Assessment and Nonoptimal Cause Identification
3.1. Online Process Operating Performance Assessment Method
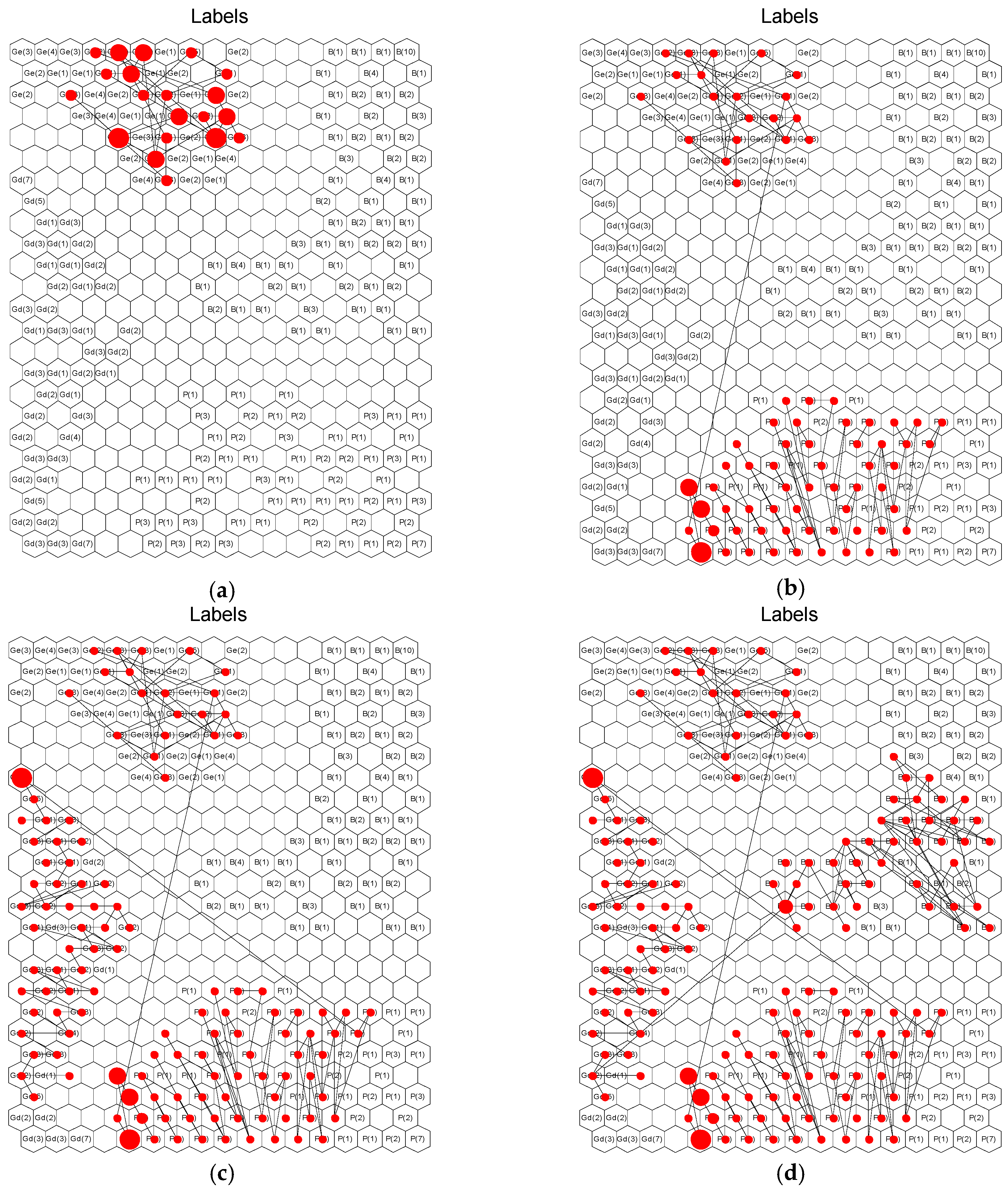
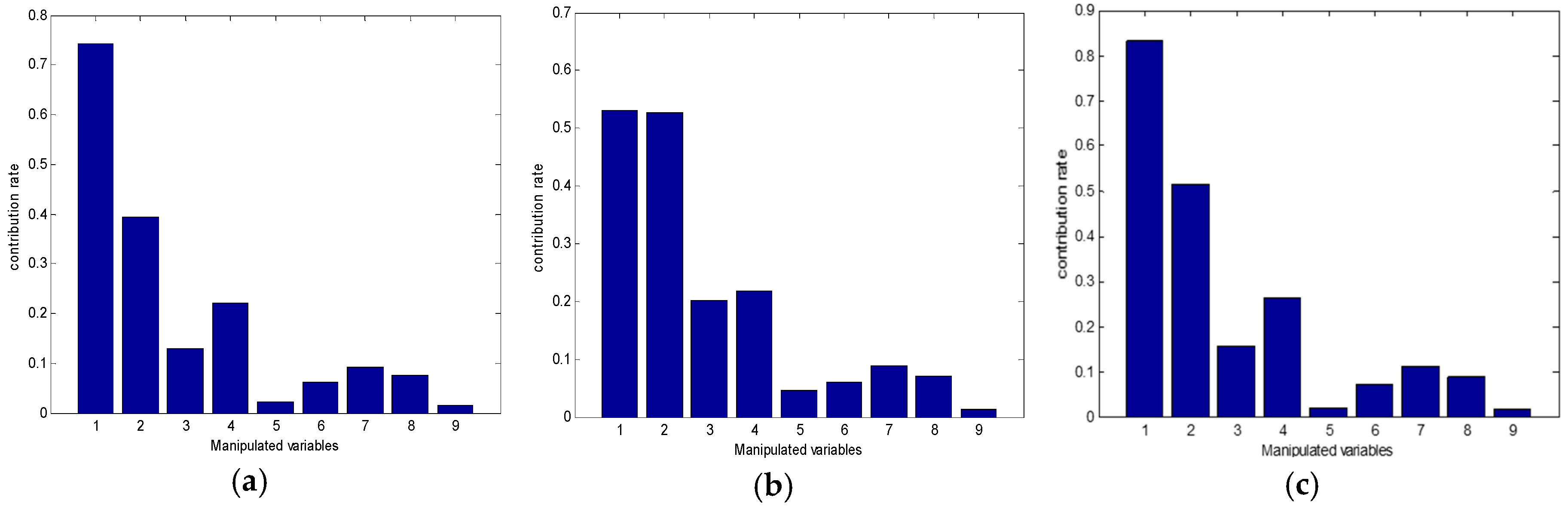
3.2. Nonoptimal Cause Identification Method
4. Simulation Study of Tennessee Eastman Process
4.1. Process Description and Experimental Setting
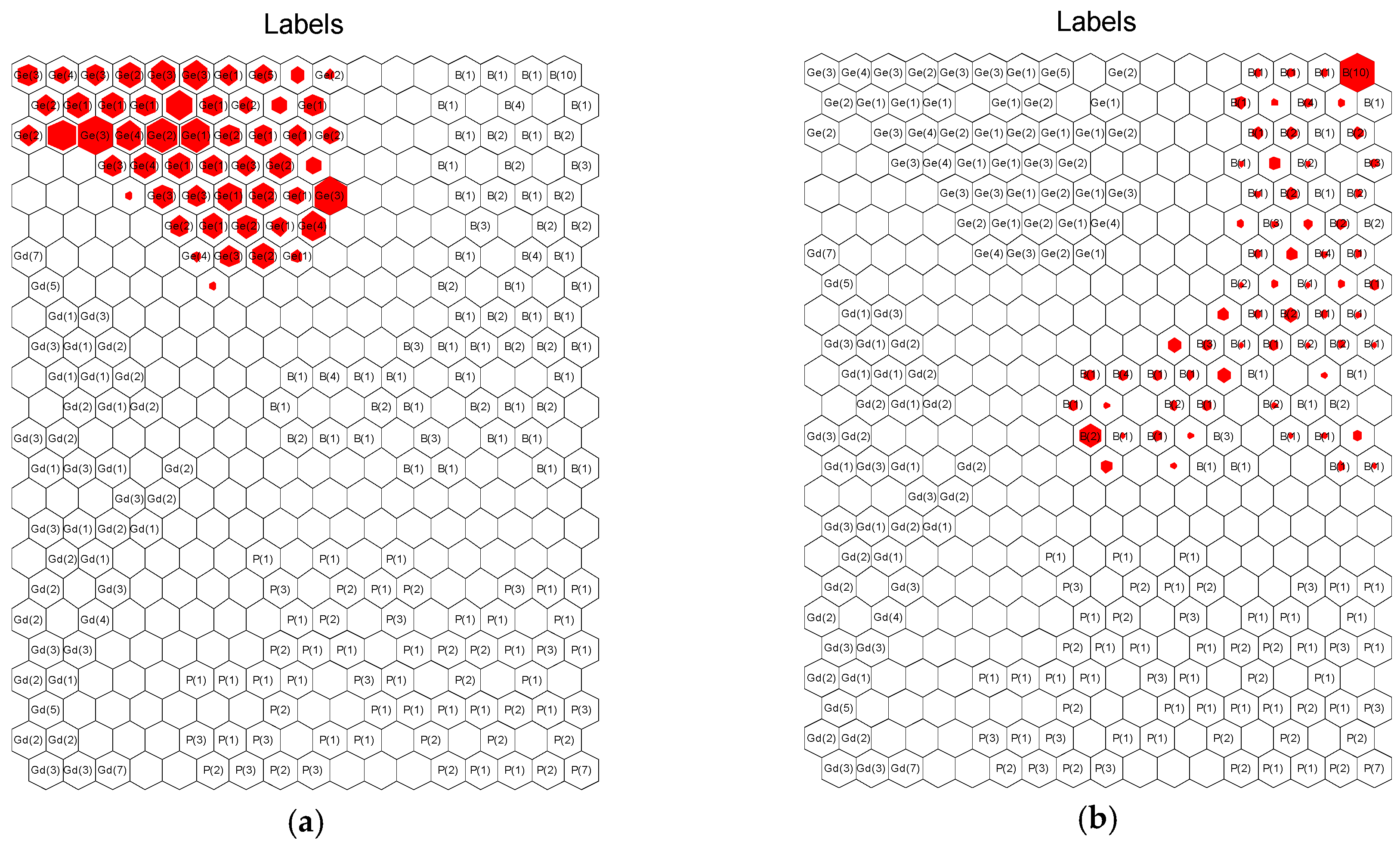
4.2. Multimode Process Data Classification, Recognition, and Visualization Model Establishment
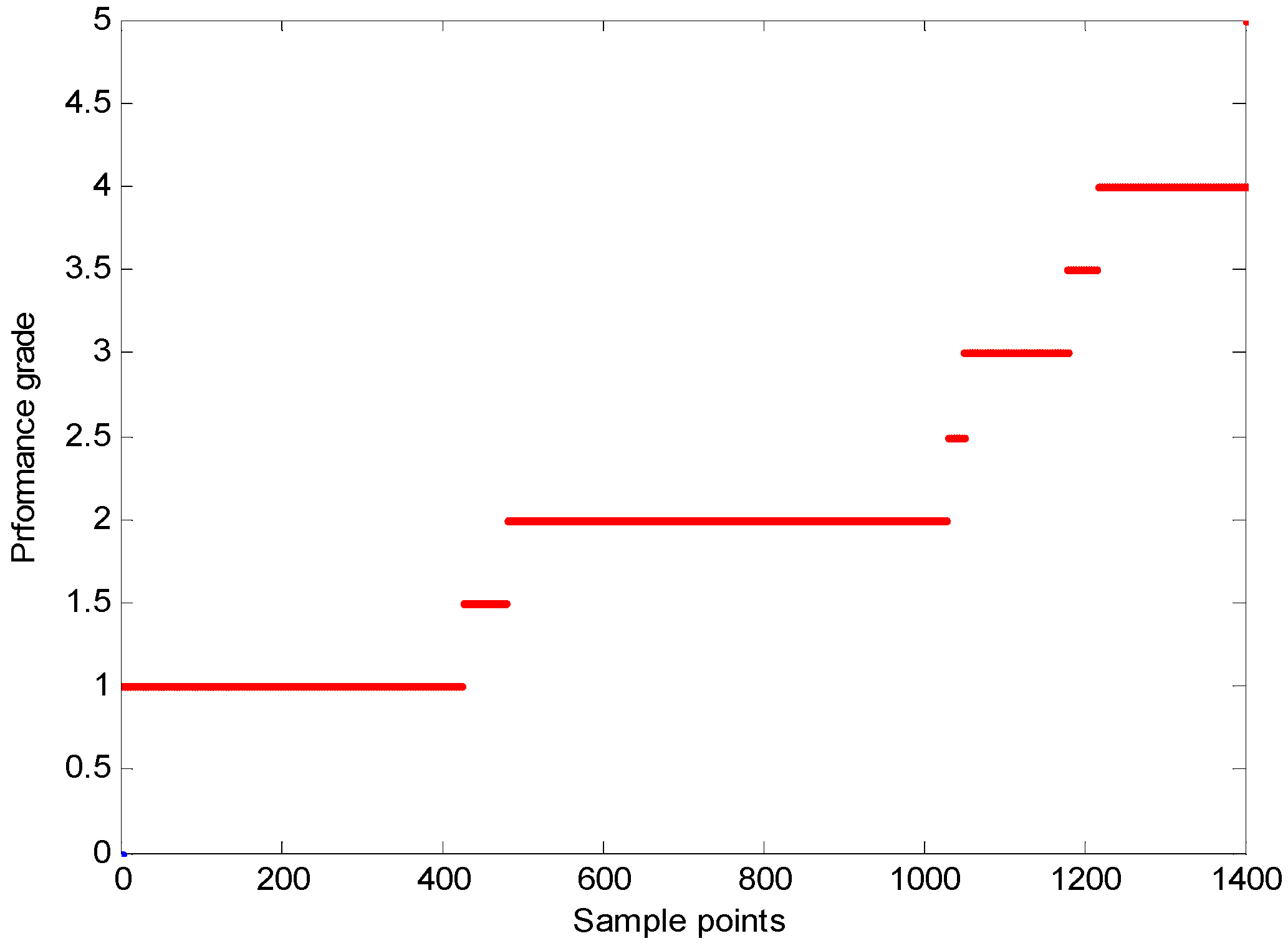
4.3. Online Process Performance Assessment and Variable Weight Identification of Nonoptimal Causes
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hwang, J.H.; Roh, M.I.; Lee, K.Y. Determination of the optimal operating conditions of the dual mixed refrigerant cycle for the LNG FPSO topside liquefaction process. Comput. Chem. Eng. 2013, 49, 25–36. [Google Scholar] [CrossRef]
- Peng, X.; Tang, Y.; Du, W.; Qian, F. Multimode Process Monitoring and Fault Detection: A Sparse Modeling and Dictionary Learning Method. IEEE Trans. Ind. Electron. 2017, 64, 4866–4875. [Google Scholar] [CrossRef]
- Wang, K.; Du, W.L.; Qian, F. Non-Gaussian process fault detection based on wavelet kernel clustering. CIESC J. 2011, 62, 427–432. [Google Scholar]
- Lee, J.M.; Qin, S.J.; Lee, I.B. Fault detection and diagnosis based on modified independent component analysis. AIChE J. 2010, 52, 3501–3514. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Process Monitoring Based on Independent Component Analysis-Principal Component Analysis (ICA-PCA) and Similarity Factors. Ind. Eng. Chem. Res. 2007, 46, 2054–2063. [Google Scholar] [CrossRef]
- Ma, L.L.; Xu, F.F.; Wang, J.Z. A fault diagnosis method based on improved kernel Fisher. CIESC J. 2017, 68, 1041–1048. [Google Scholar]
- Du, W.; Tian, Y.; Qian, F. Monitoring for Nonlinear Multiple Modes Process Based on LL-SVDD-MRDA. IEEE Trans. Autom. Sci. Eng. 2014, 11, 1133–1148. [Google Scholar] [CrossRef]
- Dunteman, G.H. Principal Component Analysis; SAGE Publication Ltd.: London, UK, 1989. [Google Scholar]
- Stefan, L. A User’s Guide to Principal Components. Technometrics 1993, 35, 83–85. [Google Scholar]
- Wang, X.Z. Data Mining and Knowledge Discovery for Process Monitoring and Control; Springer: London, UK, 1999. [Google Scholar]
- Wold, S. Nonlinear partial least squares modelling II. Spline inner relation. Chemom. Intell. Lab. Syst. 1992, 14, 71–84. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, H.; Qin, S.J. Decentralized Fault Diagnosis of Large-Scale Processes Using Multiblock Kernel Partial Least Squares. IEEE Trans. Ind. Inform. 2010, 6, 3–10. [Google Scholar] [CrossRef]
- Macgregor, J.F.; Yu, H.; Salvador, G.M. Data-based Latent Variable Methods for Process Analysis, Monitoring and Control. Comput. Chem. Eng. 2005, 29, 1217–1223. [Google Scholar] [CrossRef]
- Ye, L.; Liu, Y.; Fei, Z. Online Probabilistic Assessment of Operating Performance Based on Safety and Optimality Indices for Multimode Industrial Processes. Ind. Eng. Chem. Res. 2009, 48, 10912–10923. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, F.; Niu, D. A two-step basis vector extraction strategy for multiset variable correlation analysis. Chemom. Intell. Lab. Syst. 2011, 107, 147–154. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Zhou, D. Geometric properties of partial least squares for process monitoring. Automatica 2010, 46, 204–210. [Google Scholar] [CrossRef]
- Zhou, D.; Gang, L.; Qin, S.J. Total projection to latent structures for process monitoring. AIChE J. 2010, 56, 168–178. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Zhou, D. Output Relevant Fault Reconstruction and Fault Subspace Extraction in Total Projection to Latent Structures Models. Ind. Eng. Chem. Res. 2010, 49, 9175–9183. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, F.; Chang, Y. Online Fuzzy Assessment of Operating Performance and Cause Identification of Nonoptimal Grades for Industrial Processes. Ind. Eng. Chem. Res. 2013, 52, 18022–18030. [Google Scholar] [CrossRef]
- Liu, Y.; Chang, Y.; Wang, F. Online process operating performance assessment and nonoptimal cause identification for industrial processes. J. Process Control 2014, 24, 1548–1555. [Google Scholar] [CrossRef]
- Song, B.; Tan, S.; Shi, H.B. Time-space locality preserving coordination for multimode process monitoring. Chemom. Intell. Lab. Syst. 2016, 151, 190–200. [Google Scholar] [CrossRef]
- Xu, Y.Y.; Yang, J.; Tan, S.; Shi, H.B. Multimode process monitoring method based on local features. J. East China Univ. Sci. Technol. (Nat. Sci. Ed.) 2017, 43, 260–265. [Google Scholar]
- Li, Z.; Fang, H.; Huang, M. Data-driven bearing fault identification using improved hidden Markov model and self-organizing map. Comput. Ind. Eng. 2018, 116, 37–46. [Google Scholar] [CrossRef]
- Gu, F.; Cheung, Y.M. Self-Organizing Map-Based Weight Design for Decomposition-Based Many-Objective Evolutionary Algorithm. IEEE Trans. Evol. Comput. 2018, 22, 211–225. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. IEEE Proc. ICNN 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Henao, N.; Agbossou, K.; Kelouwani, S. Approach in Nonintrusive Type I Load Monitoring Using Subtractive Clustering. IEEE Trans. Smart Grid 2015, 8, 812–821. [Google Scholar] [CrossRef]
- Du, Y.P.; Wang, Z.L.; Wang, X. Performance assessment method of chemical process based on multi-space total projection of latent structures. CIESC J. 2018, 69, 1014–1020. [Google Scholar]
- Vesanto, J. Data Exploration Process Based on the Self-Organizing Map. Ph.D. Thesis, Helsinki University of Technology, Helsinki, Finland, 16 May 2002. [Google Scholar]
- Yew, S.N.; Rajagopalan, S. Multivariate Temporal Data Analysis Using Self-Organizing Maps. 1. Training Methodology for Effective Visualization of Multistate Operations. Ind. Eng. Chem. Res 2008, 47, 7744–7757. [Google Scholar]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Ricker, N.L. Optimal steady-state operation of the Tennessee Eastman challenge process. Comput. Chem. Eng. 1995, 19, 949–959. [Google Scholar] [CrossRef]
- Ricker, N.L. Decentralized Control of the Tennessee Eastman Challenge Process. J. Process Control 1996, 6, 205–221. [Google Scholar] [CrossRef]
- Li, M.Y.; Du, W.L.; Qian, F. Performance recognition method based on multi-index and multi-layer DAE-SOM algorithm. CIESC J. 2018, 69, 769–778. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | G/H Mass Ratio | Production Rate |
|---|---|---|
| 1 | 50/50 | 7038 kg/h G and 7038 kg/h H |
| 2 | 10/90 | 1408 kg/h G and 12,669 kg/h H |
| 3 | 90/10 | 10,000 kg/h G and 1111 kg/h H |
| 4 | 50/50 | maximum production rate |
| 5 | 10/90 | maximum production rate |
| 6 | 90/10 | maximum production rate |
| Manipulated Variables (%) | Mode 1 (50/50) | Mode 2 (10/90) | Mode 3 (90/10) | Mode 4 (50/50) | Mode 5 (10/90) | Mode 6 (90/10) |
|---|---|---|---|---|---|---|
| D Feed | 62.935 | 12.637 | 89.130 | 100.000 | 13.098 | 100.000 |
| E Feed | 53.147 | 96.216 | 8.381 | 86.715 | 100.000 | 9.438 |
| A Feed | 26.248 | 30.421 | 19.114 | 49.477 | 32.009 | 21.543 |
| A+C Feed | 60.566 | 56.092 | 51.368 | 96.595 | 58.155 | 57.640 |
| Recycle valve | 1.000 | 1.000 | 77.621 | 1.000 | 1.000 | 71.166 |
| Purge valve | 25.770 | 44.347 | 9.501 | 48.742 | 47.095 | 10.654 |
| Separate valve | 37.266 | 35.799 | 29.146 | 60.960 | 37.422 | 32.685 |
| Stripper valve | 46.444 | 42.865 | 39.425 | 74.522 | 44.491 | 44.251 |
| Steam valve | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Reactor coolant | 35.992 | 25.257 | 35.550 | 60.794 | 26.070 | 40.538 |
| Condenser coolant | 12.431 | 12.907 | 99.000 | 35.534 | 14.115 | 99.000 |
| Agitator speed | 100.000 | 100.000 | 100.000 | 100.000 | 100.000 | 100.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ying, Y.; Li, Z.; Yang, M.; Du, W. Multimode Operating Performance Visualization and Nonoptimal Cause Identification. Processes 2020, 8, 123. https://doi.org/10.3390/pr8010123
Ying Y, Li Z, Yang M, Du W. Multimode Operating Performance Visualization and Nonoptimal Cause Identification. Processes. 2020; 8(1):123. https://doi.org/10.3390/pr8010123
Chicago/Turabian StyleYing, Yuhui, Zhi Li, Minglei Yang, and Wenli Du. 2020. "Multimode Operating Performance Visualization and Nonoptimal Cause Identification" Processes 8, no. 1: 123. https://doi.org/10.3390/pr8010123
APA StyleYing, Y., Li, Z., Yang, M., & Du, W. (2020). Multimode Operating Performance Visualization and Nonoptimal Cause Identification. Processes, 8(1), 123. https://doi.org/10.3390/pr8010123