1. Introduction
Polymethyl methacrylate (PMMA) is an important industrial polymer with widespread applications ranging from plastics to electronics. PMMA production occurs via a specific recipe in a batch process in order to ensure the optimal product quality. The key parameter to determining product quality is the molecular weight distribution of PMMA. However, measuring the entire molecular weight is a long, complex procedure; therefore, the number and weight average molecular weights are used as outcome measures instead. These quality variables are measured at the end of the batch and, as such, must be controlled tightly.
In order to achieve good quality control of the PMMA process, it is important to develop a process model capable of handling batch data. Batch processes are unique in that they tend towards the low volume production of high value products, as this allows for poor quality batches to be discarded [
1]. Each discarded batch represents a significant loss in revenue, motivating the need for advanced batch control approaches and, fundamentally, the development of accurate quality models. Recent advances in computing technology have led to increased amounts of historical data being available, making data-driven modeling a viable choice for model identification [
2,
3,
4,
5,
6,
7]. However, these techniques still have challenges when dealing with nonlinear processes and scenarios where data is missing, as is the case with quality variables.
An important consideration when identifying data-driven models is the choice of input and output variables. While the distinction is typically based on variables that are controlled in comparison to those that are measured, the batch process also introduces a separate type of output variable: quality variables. Quality variables are still considered to be outputs from the process, however, they are not measured continuously, nor are they always measured online. Quality measurements are often calculated based on the regular measured outputs or are determined by separate analyses of the batch. This difference is an important consideration for data driven modeling techniques, as one assumption that is prevalent in process modeling scenarios is that the inputs and outputs are sampled at a single and uniform sampling rate. In practice, industrial processes often have different sampling rates for input and output variables. Additionally, processes record quality measurements at an even slower rate compared to traditional inputs and outputs. This leads to scenarios where inputs and outputs have some missing values due to differences in sampling rates, whereas quality measurements are available at extremely low frequencies. This presents a challenge to traditional data driven modeling approaches that require complete data sets to identify a model.
When attempting to model industrial batch processes using data containing missing observations, a common data-driven technique used is partial least squares (PLS) [
8]. In this technique, process data from multiple batches is taken and projected into two lower dimensional subspaces (latent variable space). This ensures that the relationship between the correlated input and output space variables is maintained and is characterized by the independent latent variables [
9]. PLS techniques are capable of handling missing data since they utilize the covariant structure between the input and output variables from the original variable space. This inherent ability is one of the key properties that makes PLS techniques suitable for modeling batch processes. The application of PLS techniques to batch process modeling has been previously explored and one successful approach is to utilize batchwise unfolding of the data [
9,
10,
11]. Process data from each batch is unfolded into a single PLS observation that is subsequently related to quality variables. This approach can be applied to on-line process data by utilizing data imputation techniques to make predictions on the missing data observations. While this approach has been well-documented in handling industrial batch data, it requires batch alignment in order to account for varying batch duration. Furthermore, the approach identifies a time-varying model and, since PLS inherently does not distinguish between input and output variables, it has limited applicability in traditional model predictive control and scenarios where batch duration is a decision variable.
Another technique that is suitable for building process models is subspace identification [
5,
6,
7,
12], which has been appropriately modified for handling batch data using Hankel matrices [
1]. Note that subspace identification is different from PLS because it explicitly distinguishes between input and output variables [
5,
6,
7,
12]. Subspace identification consists of two distinct steps: identifying a state trajectory from historical input and output batch data, and determining the system matrices using a least squares solution. To achieve these outcomes, subspace identification utilizes a range of techniques from canonical variate analysis [
13,
14], numerical algorithms [
15] and multivariate output error state space algorithms [
16]. One common technique to subspace identification is singular value decomposition (SVD) of the matrices [
5,
6]. However, SVD requires matrices to be full-rank, making it unsuitable for handling batch data with missing observations [
17].
One way to handle the problem of missing data with subspace identification is through a lifting technique [
18]. The prevalent assumption is that all the inputs are sampled at one frequency and all the outputs are sampled at another frequency. A model can then be derived using the grouped inputs and outputs wherever the sampling frequencies align. This process involves computed control moves over the larger sampling interval instead of every sampling instance. Lifting has many advantages, including the ability to convert a multi-rate system into a single rate system, but the key benefits lie in model predictive control. However, this process is unsuited for the quality control problem, as quality measurements are not frequent enough to provide sufficient excitation for modeling. These measurements are only available at percentages less than 10%, making a single rate system impractical. Thus, a modeling approach that can use the lower frequency sampling rate of the inputs and outputs is required. The previous work [
19] developed a technique for handling missing data in subspace identification approach with a focus on solving the problem of random missing data. The present work recognizes that the missing data subspace approach can be applied to the broader quality measurement induced missing data problem. Thus, the present manuscript provides a solution for instances where the low frequency of quality measurements in relation to other online measurements results in a missing data problem (as in the simulated PMMA process example).
To overcome these challenges and model the PMMA process, the current paper focuses on a recent modification to subspace identification [
20] that treats nonuniform sampling rate data as a missing data problem. Specifically, the addition of PCA and PLS steps to the subspace identification approach permits accounting for the missing quality measurements. While the use of PCA and PLS techniques is not a novel introduction to model identification (see [
21,
22]), the reduced latent variable space is marginally affected by missing data, thus allowing for the treatment of nonuniform sampling problems as a case of randomly missing data. The first step is to use latent variable methods (PCA followed by PLS) to identify a reduced dimensional space for the variables which accounts for missing observations. The second step replaces SVD with PCA to identify the states of the system, whereupon traditional subspace approaches can be utilized. The rest of the paper is organized as follows: Section Preliminaries presents the Polymethyl Methacrylate (PMMA) process, followed by a review of traditional subspace identification. The next subsection presents the Subspace Identification approach that can readily handle missing data issues. In the results section, identification and validation results for the PMMA process are presented. Finally, concluding remarks are made.
3. PMMA Model Identification
Two case studies are considered for the PMMA process, where the output data is lost in storage (thus, the PI controller is able to run in the closed-loop using the available temperature measurements. Note that the approach and implementation readily holds for the situation where the measurements would simply be unavailable at random times, and would need a change in how the PI controller is implemented). Case 1 contains training data with 30% random missing output data and quality data measurements retained at intervals of 1 in every 10, 20 and 30 time steps, respectively. Case 2 contains training data with quality measurement available every 10 time steps and random missing output data ranging from 5% up to 30%. Thus, the effects of both lower frequency of quality measurement availability and increasing missing data are independently investigated.
Remark 2. The key difference between data imputation approaches and the missing data approach is that imputation can lead to inconsistency between the imputed data (in terms of the model structure implied) and the model structure being identified. Thus, in the comparison case study, where linear interpolation techniques are utilized, it is seen that linear interpolation is not consistent with the type of model ultimately being identified (linear time invariant dynamic model), resulting in the inability to capture the process trends sufficiently, leading to poor model performance. The success of the approach is based on the format of the data-blocks, which guarantees a high degree of covariance due to batch unfolding of the Hankel matrices and the temporal nature of the data.
3.1. Model Identification
For each case, 15 training batches under proportional integral (PI) control are generated from the PMMA process and are used to identify two subspace models. To compare the present approach against existing results, first a model is identified using traditional subspace identification with linear interpolation of the measured outputs to determine missing values in the training batches and, subsequently, the proposed approach using PCA/PLS techniques to handle infrequent quality sampling is implemented. The two models are then validated against a new set of 15 batches (under PI control) that are also modified to have missing data similar to the training batches to determine the validation error.
Remark 3. Note that the number of states and lags are a user specified parameter. The choice is based on the best training fit defined as the lowest error between the predictions and the process outputs. The states and lags used are specific to the present implementation and future work will explore further the relationship between the number of states and model quality.
3.2. State Observer
After identifying the state space model an important consideration before utilizing it for online predictions is to ensure that the model states converge with the process. This approach utilizes the Luenberger observer, which updates the states using feedback from the outputs weighted using a gain matrix L in the following method:
To handle missing outputs when the model is run with a new batch, this approach uses linear interpolation until the process outputs converge within a tolerance of 0.1% or until 40 min have passed (the sampling instance when this occurs is denoted by c). After that, the model is run online and is used to predict the process outputs. The model’s effectiveness can then be determined based on the prediction error until the end of the batch. The error is determined by the sum of the difference between each available process output () and model prediction () for the duration that the models are used for prediction (i.e., after the Luenberger observer has converged).
This value is then normalized by the number of process outputs available to account for differences in batch duration as well as missing observations. The validation error for each batch is calculated as:
where
k is the batch index,
c is the index when the Luenberger observer converges and
s is the batch length.
3.3. Case 1: Missing Quality Data
In this case, the amount of missing quality data was varied to retain quality measurements in intervals of 10, 20 and 30 sampling times, resulting in missing data percentages of 90%, 95% and 97%, respectively. The reason for doing this is to test the utility of the approach for situations where the quality measurements may take longer times to be obtained. Additionally, output data from the training batches are randomly deleted to obtain a missing data percentage of 30%. Both the missing data approach and the traditional subspace approach were then used to develop a subspace model. To handle the missing measurements, the traditional subspace identification approach uses linear interpolation in order to have a full rank matrix. The two models are then validated against validation batches where both output and quality data entries were removed, similar to training batches.
Table 2 shows the average validation error of the traditional subspace model and missing data approach from modeling 15 validation batches. The missing data approach consistently has a lower error compared to the traditional subspace model.
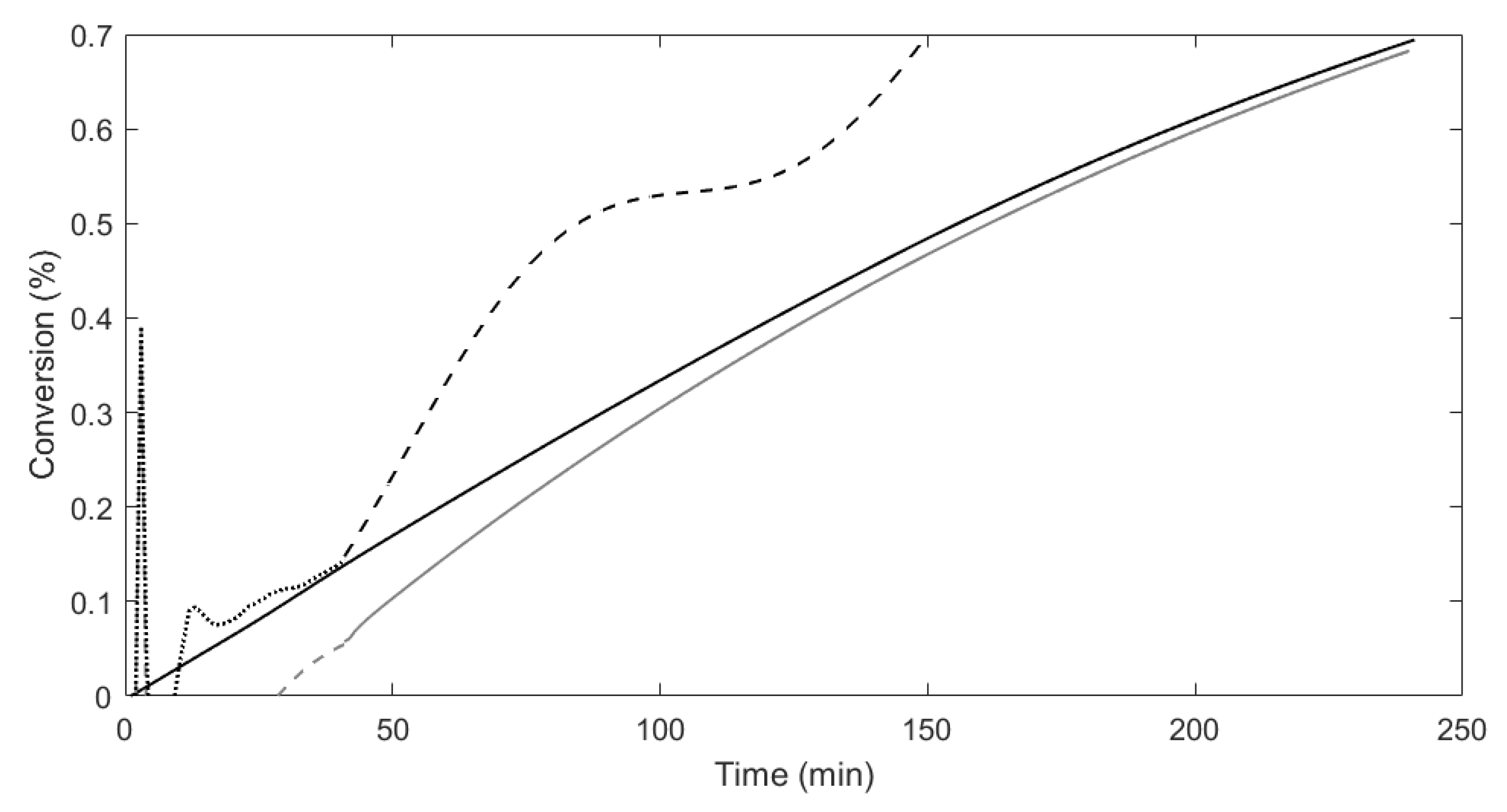
Figure 1 shows the predictions for reactant conversion from the proposed approach, traditional approach, as well as the output estimates using the Luenberger observer for the first 40 time-steps from both models compared to the true process for one batch.
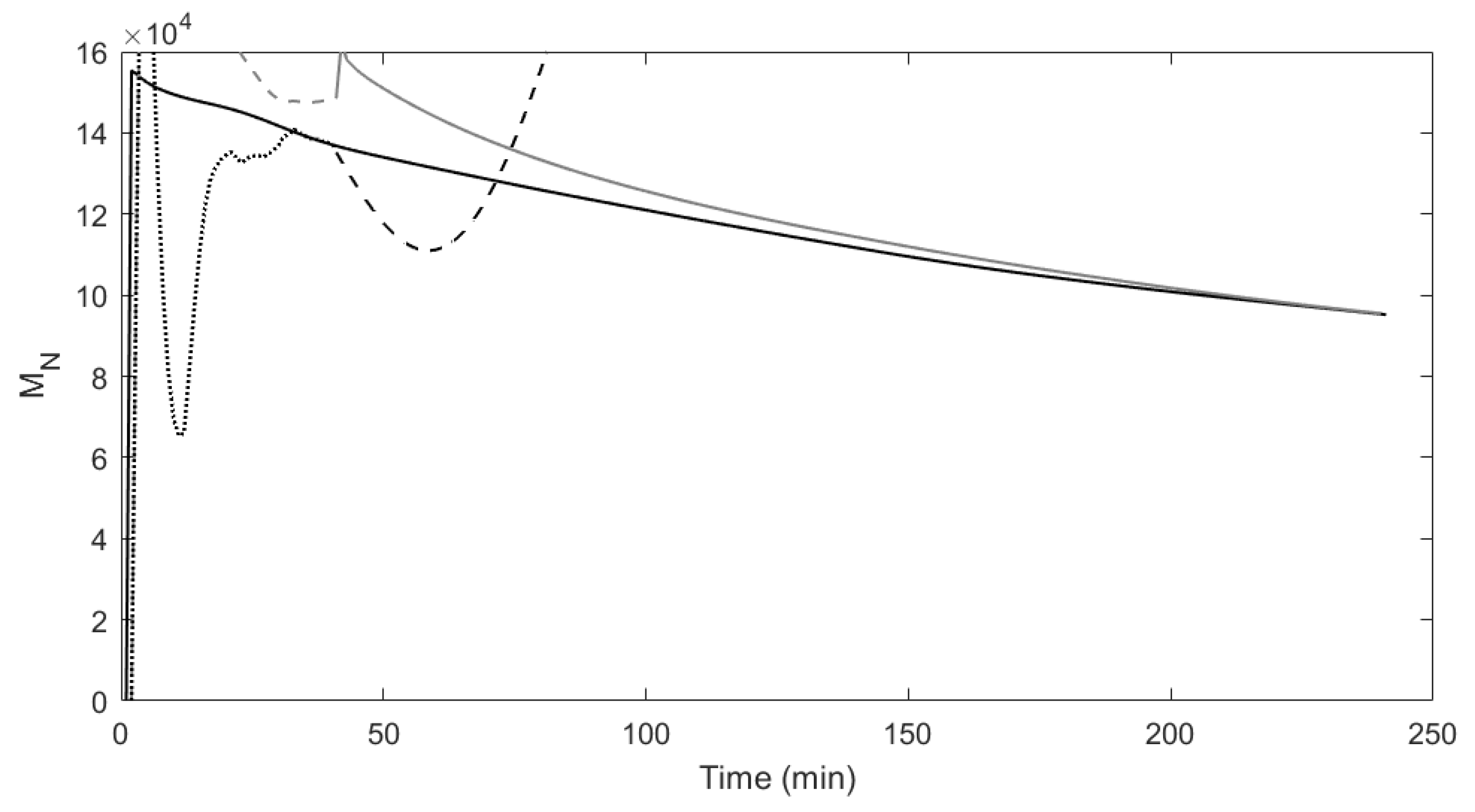
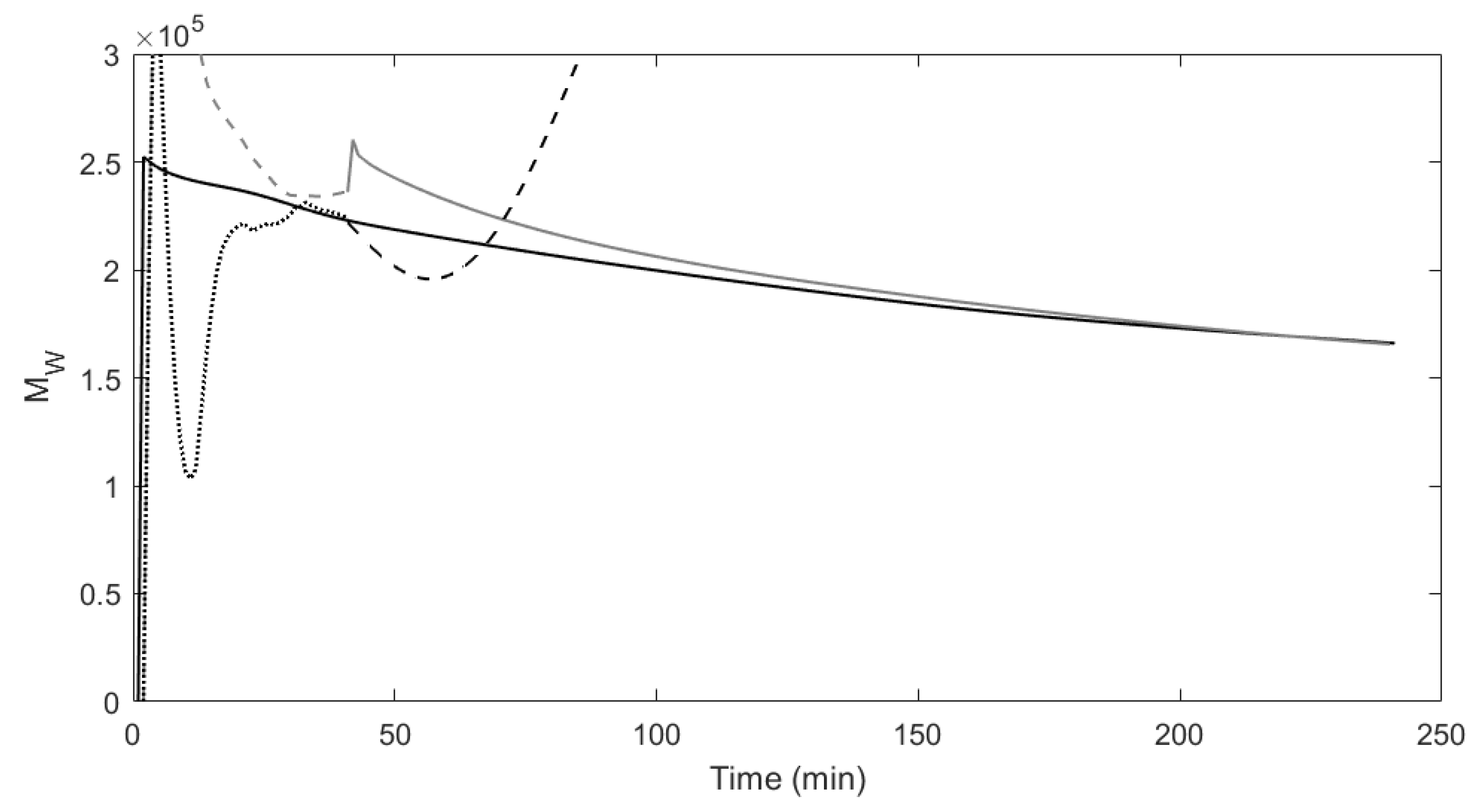
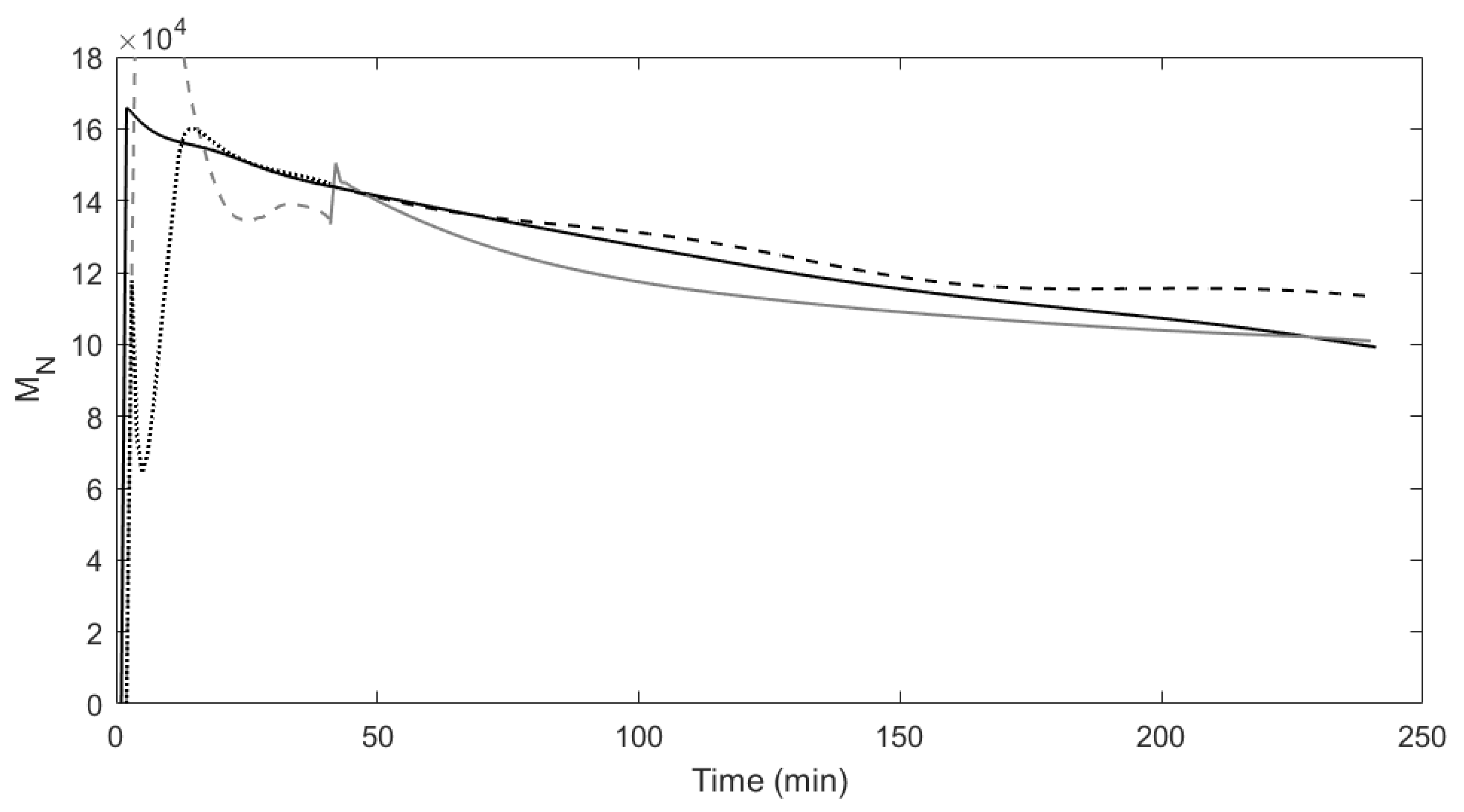
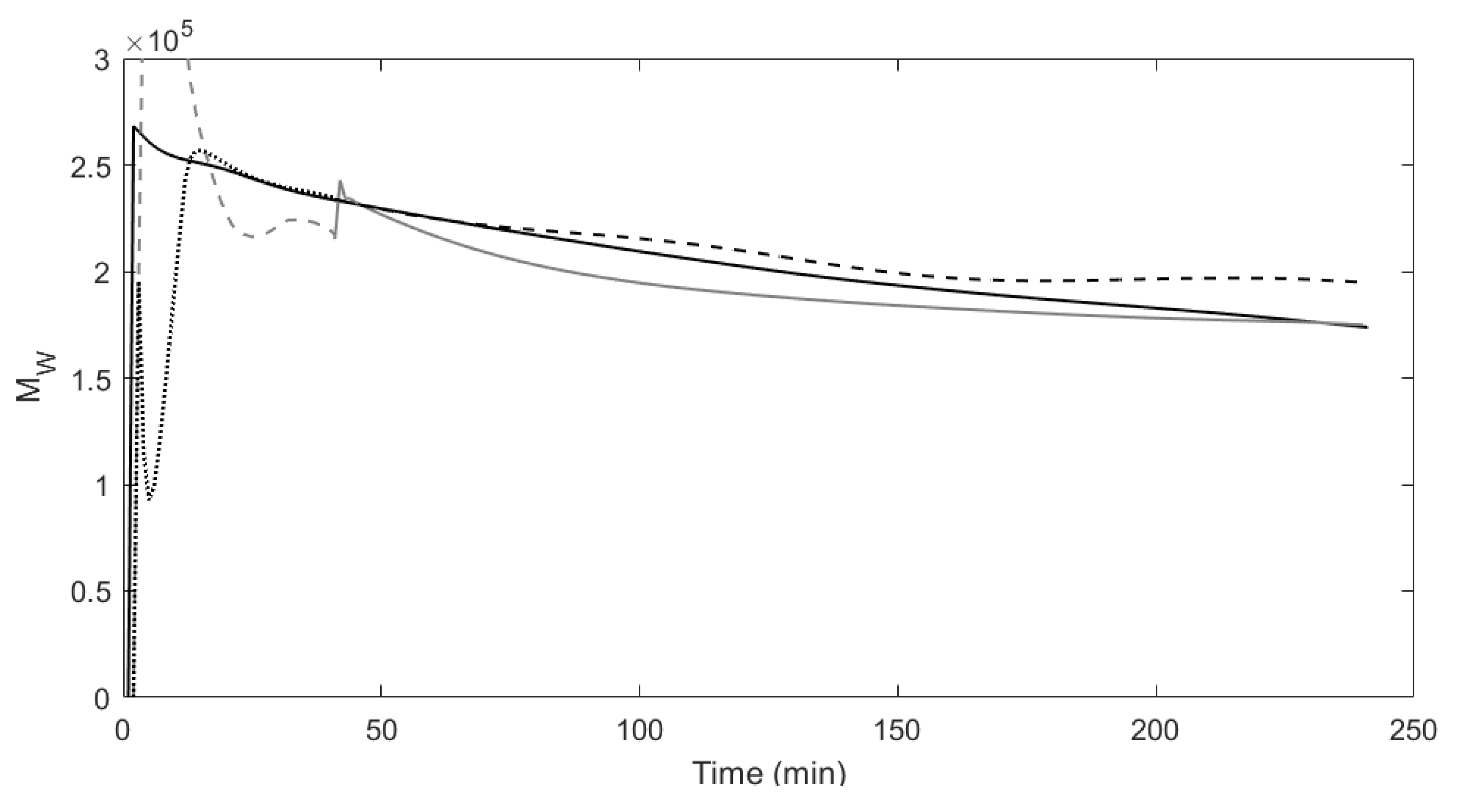
Figure 2 and
Figure 3 show the predictions for the number average molecular weight and weight average molecular weight from both models compared to the true process. Looking at each of the model predictions, the three figures clearly show how the missing data approach is able to more accurately model the true process in comparison to the traditional subspace identification.
3.4. Case 2: Random Missing Output Data
In this case, the output data from training batches is randomly deleted in order to achieve missing data percentages from 5% up to 30% while every tenth quality variable measurement is kept (90% missing outputs). The missing data approach is then compared against traditional subspace identification with linear interpolation. The models are then validated against validation batches with both output and quality data entries removed in a similar manner to training batches.
Table 3 shows the average validation error in predicting quality variable data for 15 batches from the traditional subspace identification and missing data approach. In comparison to the traditional subspace approach, the missing data approach is able to consistently make more accurate predictions.
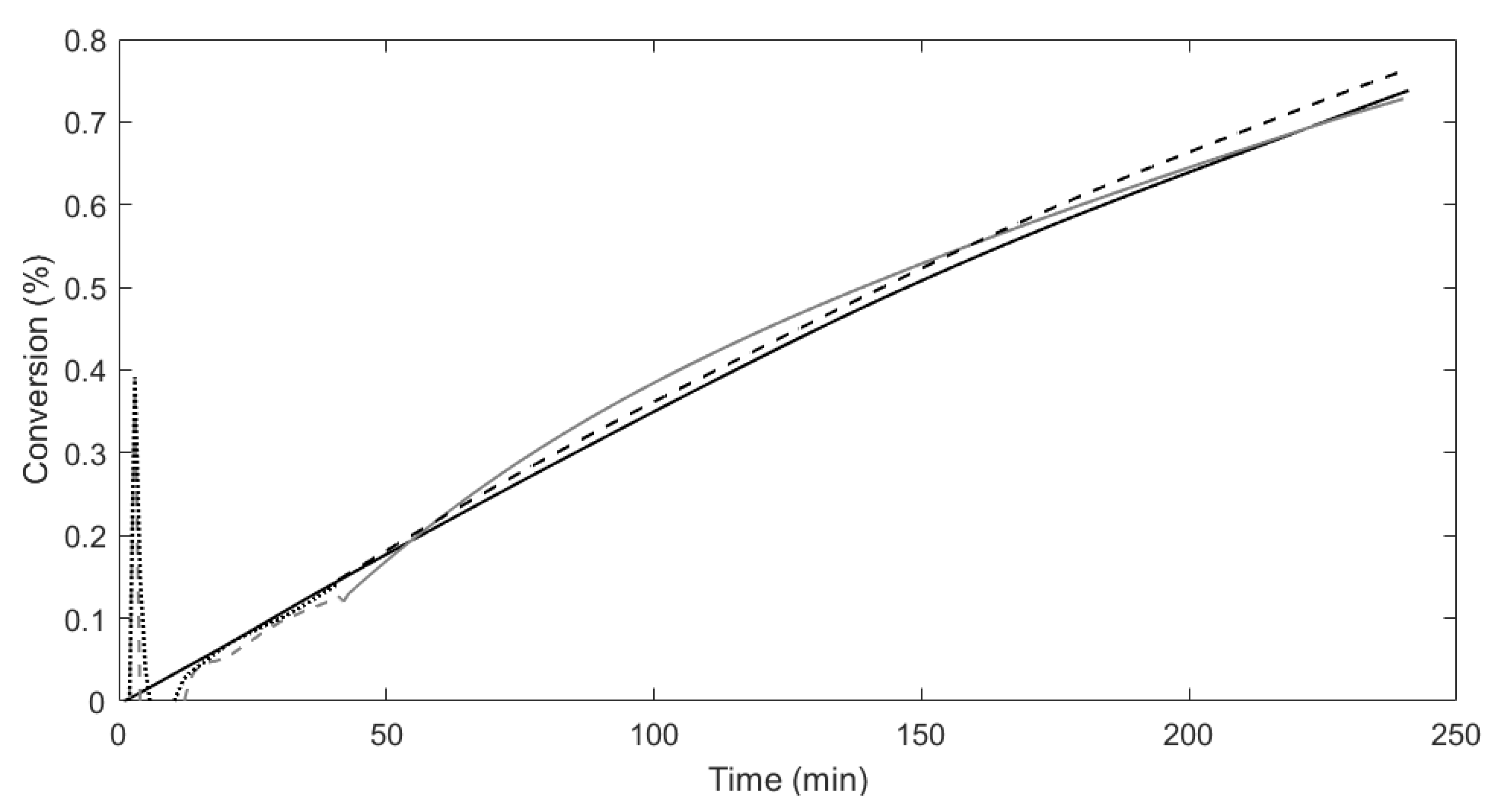
Figure 4 shows the conversion predictions made by the proposed approach, traditional subspace approach, as well as the predictions from the Luenberger observer for the first 40 time-steps for both models compared to the true process for one validation batch.
Figure 5 and
Figure 6 show the predictions for number average molecular weight and weight average molecular weight from both models compared to the true process. The three graphs clearly show that the proposed approach is able to more accurately model and predict the process data compared to traditional subspace identification.
Remark 4. Note that while the subspace identification approach itself is not a novel introduction, its application to the batch quality problem is. Quality variables are different from missing data scenarios since they are available at a much lower frequency than traditional outputs and they contain more important process information. Modeling the intermittent quality measurements along with the process outputs is a difficult task, given the large differences in data frequency. However, a singular model is desirable for control. This paper demonstrates how missing data algorithms can be adjusted to include quality variables for accurate process modeling.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}