1. Introduction
Information and Communication Technologies (ICT) and Intelligent Data Analytical Technologies (IDAT) have become the new trend for various industries’ development [
1,
2,
3]. Following this trend, ICT and IDAT are increasingly implemented in multiple industries [
4,
5,
6]. Load Monitoring is one of the ICT and IDAT implementation cases in the power system, and it can disaggregate the whole electricity consumption signal into the signals of appliances in a residential, commercial, or industrial building. Load monitoring can identify appliances and report consumers consumption patterns to improve consumer behavior [
7]. Furthermore, finding the detailed electricity consumption patterns of the customers helps energy suppliers to efficiently plan and operate power system networks.
Traditional load monitoring equipment is intrusive, that is, a sensor with communication function is installed for one monitoring equipment in the total load, and then, the power consumption information is received through the network for real-time monitoring. This method requires a large number of sensors, which increases installation and maintenance costs. Unlike it, non-intrusive load monitoring (NILM) installs a smart meter at the user’s entrance to obtain the total current and terminal voltage. NILM can apply digital signal chemistry to the collected data, and then use algorithms to analyze and extract the power consumption information of various types of indoor appliances. The advantages of this method are as follows: low installation cost, little interference to users, and flexible application. Therefore, non-intrusive load monitoring technology has received widespread attention from scholars in recent years.
NILM was first proposed by Hart for residential load decomposition [
8]. The operating states of appliances are divided into steady and transient. Therefore, the load monitoring methods can perform load decomposition based on steady or transient characteristics. The transient characteristics mainly include the change of the current or voltage waveform at the moment when the appliance starts. The duration of transient characteristics is short and unique, which can improve the recognition between loads. However, the transient feature extraction needs complex hardware, and the transient process of the load is affected by conditions such as grid voltage fluctuations, and the aging of electrical equipment. Steady-state load characteristics such as current harmonics [
9], power harmonics [
10,
11], and current waveforms [
12,
13,
14] have been successively applied to NILM. Steady-state characteristics are generally obtained by index quantification. They are less affected by noise, but the probability of similarity of the single steady-state characteristics of the load increases when the number of loads rises. In order to distinguish multiple appliances, a new load characteristic that is V-I trajectory has been developed for NILM in recent years. The V-I trajectory is plotted based on the steady-state voltage and current, and it is used to express appliances’ electrical characteristics. The V-I trajectory in conjunction with many popular classification algorithms can offer better or generally comparable overall precision of prediction, robustness, and reliability [
15]. In short, the V-I trajectory has advantages as a currently popular feature.
Based on different load characteristics, a variety of load identification algorithms have been proposed in NILM [
16,
17]. With the development of machine learning, the system results from the learning process can deliver the optimal predictive performance for appliance loads. Therefore, machine learning techniques have become a popular choice for NILM, since they showed significant disaggregation performance; in particular, Factorial Hidden Markov models (FHMMs) [
18,
19,
20], Neural Networks (NN) [
21,
22,
23,
24], graph-based signal processing [
25], Support Vector Machines (SVM) [
26], k-Nearest Neighbours [
26], and Decision Trees [
27] have been successfully employed for NILM. Specifically, Reference [
28] proposed a NILM algorithm based on features of the V-I trajectory. Ten V-I trajectory features were quantified based on physical significance, which accurately represented those appliances that had multiple built-in modes with distinct power consumption profiles, and the support vector machine multi-classification algorithm was employed for load identification. Reference [
29] proposed a NILM algorithm based on the joint use of active and reactive power in the Additive Factorial Hidden Markov Models framework. In particular, in the proposed approach, the appliance model was represented by a bivariate Hidden Markov Model whose emitted symbols are the joint active-reactive power signals. The disaggregation was performed by means of an alternative formulation of the Additive Factorial Approximate Maximum a Posteriori (AFAMAP) algorithm for dealing with the bivariate HMM models. Reference [
30] proposed an experimental design process for the application of energy disaggregation using multi-label classification. This paper took the electrical parameters of the current (I), real power (P), reactive power (Q), and power factor (PF) at every one-minute and employed RAndom k-labELsets (RAkEL) with Decision Tree as the multi-label classification algorithm together with the right model parameter configuration.
However, it is worth noting that most classification algorithms described in the literature cannot identify unidentified appliances in the consumer environment. In these algorithms, the unidentified appliance will be assigned a label and power consumption. They correspond to the identified appliance which have the most similar features. This leads to confusion between the identification of identified appliances and unidentified appliances. At the same time, the accuracy of appliance identification is reduced. Therefore, the household power consumption that is fed back to consumers and the power department is inaccurate.
Considering that the V-I trajectory is an image feature, its application enables NILM to be transformed into image retrieval. With the explosive growth of data in real applications like image retrieval, approximate nearest neighbor (ANN) search [
31] has become a hot research topic in recent years. Due to its fast query speed and low memory cost, hashing [
32] has become one of the most popular and effective techniques among existing ANN techniques. Existing hashing methods can be divided into data-independent methods and data-dependent methods. In data-independent methods, the hash function is typically randomly generated. It is independent of any training data. The representative data-independent methods include locality-sensitive hashing (LSH) [
33] and its variants. Data-dependent methods try to learn the hash function from some training data, and they are also called learning to hash (L2H) [
34] methods. Compared with data-independent methods, L2H methods can achieve comparable or better accuracy with shorter hash codes. Representative learning to hash methods include fast supervised hashing (FastH) [
35], supervised discrete hashing (SDH) [
36], column-sampling based discrete supervised hashing (COSDISH) [
37], and column generation hashing (CGHash) [
38].
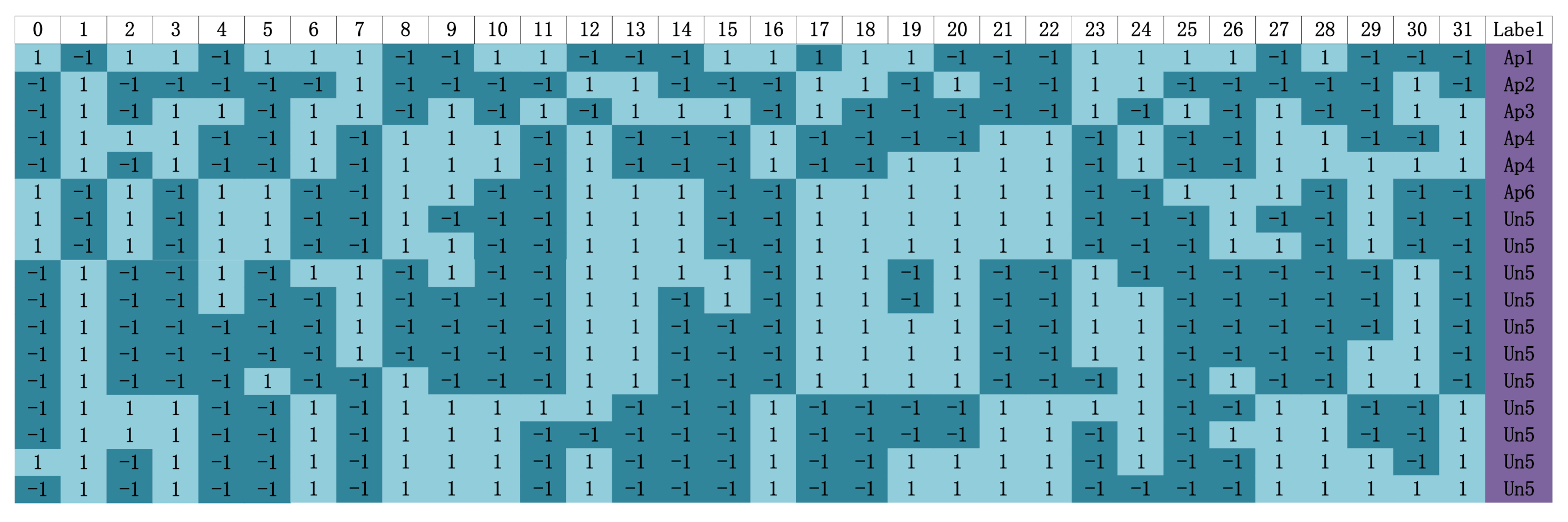
Therefore, this paper proposes a V-I trajectory enabled deep pairwise-supervised hashing (DPSH) method for NILM. It contains simultaneous feature learning and hash-code learning. DPSH encodes the V-I trajectory images of identified appliances into compact binary hash codes. According to different coding results, we can identify various identified appliances in the environment, and DPSH can detect previously unidentified appliances in an automated way. When there is an unidentified appliance, DPSH will encode the V-I trajectory images of this appliance into brand new hash codes, which are different from other identified appliances. Thence, our proposed method can provide a scalable solution to energy monitoring for contemporary unidentified appliances.
The main contributions of this paper can be summarized as follows:
Firstly, to the best of our knowledge, DPSH which can perform simultaneous feature learning and hash-code learning for applications with pairwise labels is first applied to NILM. This method transfers appliance identification to approximate nearest neighbor search, and improves the identification accuracy of identified appliances.
Secondly, the majority of the NILM approaches are sensitive to the replacement and addition of appliances in the house, and thus require regular retraining. In this paper, the focus lies on creating a classification algorithm that is able to detect unidentified appliances. Therefore, the algorithm can be resilient against the replacement and addition of appliances in the house. If an unidentified appliance is detected, labeling and retraining are requested to restore the identified environment and then identify the next unidentified appliance.
Thirdly, this paper also reflects the retraining results of our proposed method after identifying the unidentified appliance. The results show that the identification accuracy of DPSH can be restored to a high level through retraining, and when the next unidentified appliance appears, DPSH can still recognize it. In other words, DPSH maintains high sustainability. Experiments on public datasets show that DPSH can outperform the benchmark method to achieve state-of-the-art performance in NILM.
This paper is organized as follows.
Section 2 defines some symbols and issues in DPSH method.
Section 3 explains the model and learning process of DPSH method as well as how it can be used for load disaggregation.
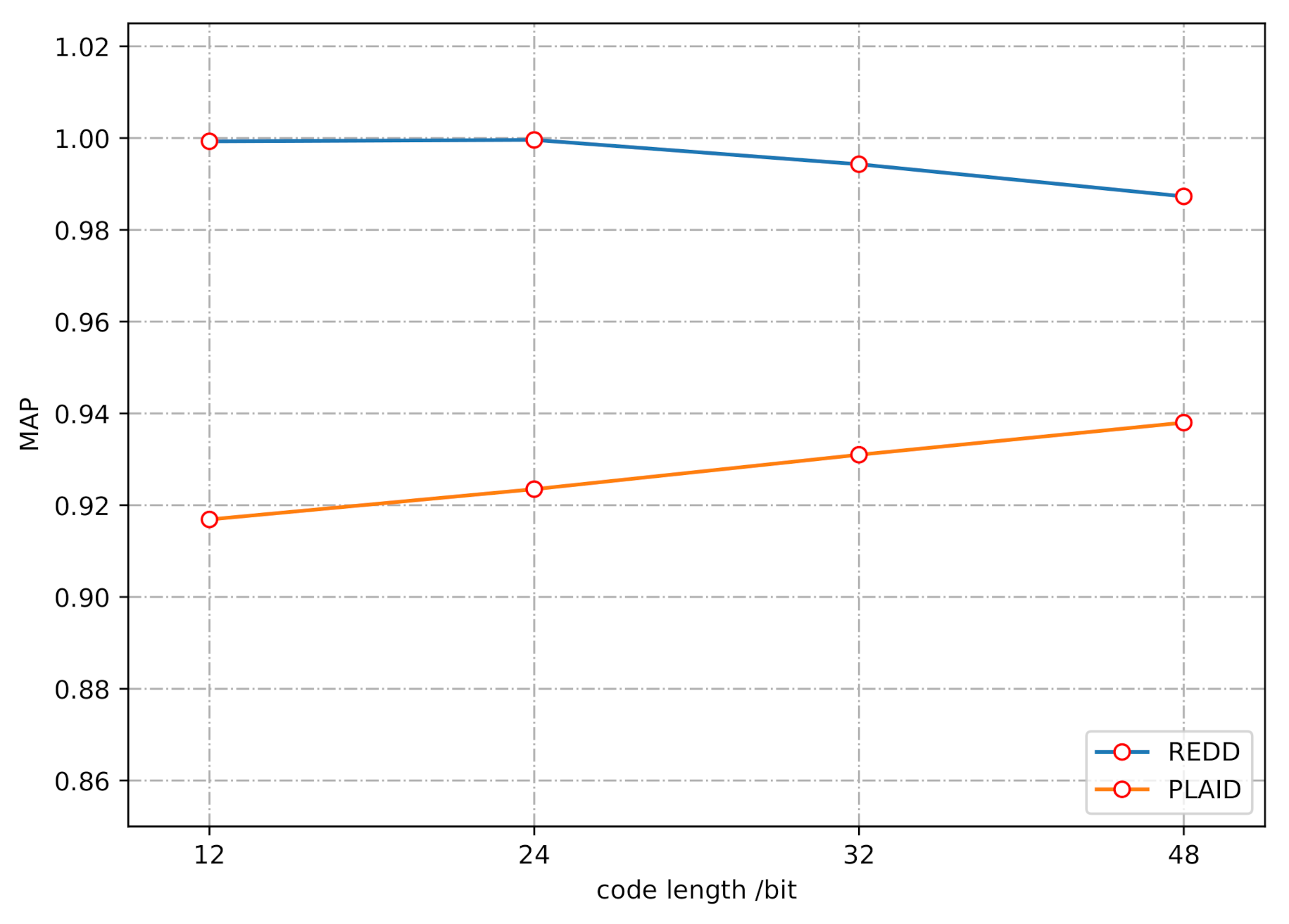
Section 4 introduces benchmark datasets, the input of network, performance metrics, and selection of code length. The experimental results on publicly available datasets are presented in
Section 5 to evaluate the performance of the proposed DPSH method for NILM. Moreover, the conclusions are given in
Section 6.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}