1. Introduction
Solid propulsion systems can generate strong forces within an extremely short time after ignition; however, controlling the thrust is challenging. Therefore, it is necessary to design a suitable propellant grain configuration. Grain design involves the process of obtaining a set of configuration variables that can satisfy the desired burning surface area profile with burning time, which is referred to as burn-back analysis. Each configuration variable affects the area profile, and it is difficult to predict changes to the area profile because of the complicated effects of the modified variables [
1]. Therefore, sufficient design experience is required and a redesign, based on the existing data, is necessary to modify the configuration variables to obtain the area profile [
2]. However, because the correlation between the configuration variable and the area profile is not clearly identified, it is difficult to modify the configuration variable; this significantly impedes solid propellant grain design.
Previous studies have mainly addressed this problem by applying optimization techniques rather than correlation analysis [
1,
2,
3]. However, because grain design is a multivariable nonlinear problem, it is extremely difficult to achieve an optimum design. Optimization techniques are divided into deterministic and stochastic methods [
4], based on whether the method incorporates probabilistic factors. The deterministic method has good search performance for the optimum solution but easily converges on the local solution. The stochastic method exhibits high performance for global solutions but has difficulty converging to an optimum solution. Optimum grain design requires the advantages of both methods. Nisar and Guozhu used deterministic methods to design wagon wheel geometries [
3], and Kamran used stochastic methods to design cylinder and star geometries [
5]. However, the single optimization technique is impractical because of the disadvantages associated with each method. To overcome this problem, a hybrid optimization technique that links two optimization techniques was studied. Raza and Liang used two stochastic methods to design wagon wheel grains [
6] and Oh et al. confirmed that stochastic and deterministic methods can be combined to utilize the strengths of both techniques [
1]. However, hybrid optimization techniques also lack universality and flexibility. Recent studies consider hyper-heuristic optimization [
7], which uses various optimization techniques; the most feasible result is to use a new starting point for these techniques. As research progresses, the possibility of developing an optimum design that satisfies the requirements has increased. However, considering the time and cost of using multi-optimization techniques, this is not practical.
Another issue that requires investigation is utilizing stored data. Solid propulsion systems have been designed in various configurations for decades. Usually, defense research institutes or companies possess large amounts of design and experimental data. However, the optimum design study does not use stored data directly because it includes a burn-back analysis process. Large amounts of new data generated during the optimization process are stored but are not used in the subsequent design.
The saved data contained correlations between the configuration variables and the area profile. Using these correlations, grain design can be performed easily and directly. Currently, general grain design involves a stochastic approach––similar to the genetic algorithm––that randomly generates a set of configuration variables and uses the most suitable result. If the research proceeds successfully, a design model that directly calculates the feasible set of configuration variables would be developed. Despite these advantages, the correlation has not been studied because grain design is a nonlinear problem; as such, analysis is extremely difficult because each configuration variable has a complicated effect on the area profile.
Machine learning is a useful technique that can address this type. This technique is used in a variety of fields because it can obtain meaningful information from stored data [
8,
9]. However, no study has thus far been performed on grain design. Therefore, in this study, a fundamental investigation of grain design using machine learning was conducted. The goal of this study was to apply and validate machine learning instead of a burn-back analysis in the design process. The classification method and optimization techniques were applied to obtain the configuration variables with a neutral area profile for a star grain, which is generally used as a solid propellant [
10]. The database including a set of configuration variables and area profiles was constructed to be used for machine learning. Classes were designated as satisfying the design objectives (Class 1) and others (Class −1). Support vector machine (SVM) is applied as a machine learning method that can learn complicated boundaries, and the Gaussian kernel-based SVM is adopted to classifies the class. The machine learning-based design method is confirmed as suitable for grain configuration design.
2. Grain Optimum Design
2.1. Optimum Design Process
The optimum design involves three steps, as shown in
Figure 1 [
1]. The first step is grain design. This is the process of obtaining a set of configuration variables suitable for the objective and a new set is created to better meet the requirements using design experience or an optimization technique. The second step is the process of obtaining the area profile of the designed grain, which requires fast and accurate analysis technology owing to the large calculation cost. This is the grain burn-back analysis step. The third step is to assess objective levels. If the level does not satisfy the requirement, the grain will be redesigned.
The optimization technique corresponding to the first step was the main target of previous studies. The set of configuration variables determines the initial grain configuration, and the initial configuration determines the area profile. Therefore, a correlation exists between the configuration variable and the area profile. However, because the influence of each configuration variable on the area profile is complicated, the correlation cannot be easily understood. Therefore, the optimum grain design is classified as a multivariable nonlinear optimization problem.
The third step is to define the objective of the optimum design. For a grain with a neutral burning surface area profile, the standard deviation can be used to define the objective. The difference between the average surface area (
) of the grain and the grain burn-back analysis result (
) was calculated at 0.01 mm intervals and the dimensionless standard deviation (
) was obtained using Equation (1). The smaller the size of the standard deviation, the closer is the area profile to the neutral profile, and when a grain configuration smaller than the objective standard deviation is designed, the grain design is considered complete.
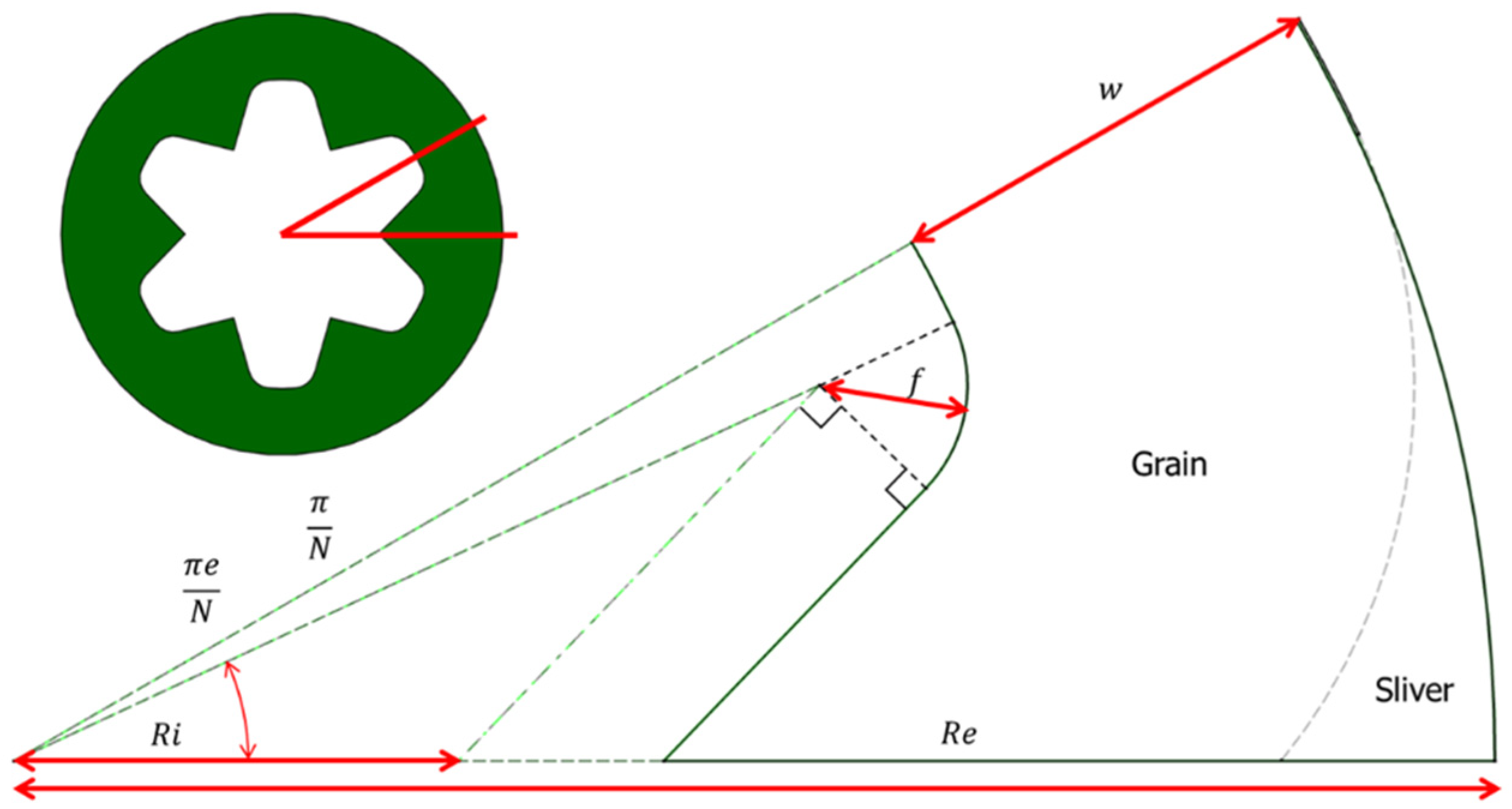
Figure 2 and
Table 1 present the configuration variables of the star grain.
2.2. Grain Burn-Back Analysis Technique
In the second step, burn-back analysis is the process of determining an area profile. In the conventional process, the area profile is calculated by entering the configuration variables generated by the optimization technique into the grain-burn-back analysis. Grain burn-back analysis techniques can be classified into three types. The simplest technique is the analytical method [
11,
12], which analyzes the structure of the lines and surfaces that constitute the grain configuration. The analysis result is obtained via equations that can calculate the line and area [
11]. Because analytical methods use equations, the surface area can be immediately obtained. However, the analysis of complicated configurations is extremely difficult; thus, limited 2-D configurations are usually analyzed using this technique. The drafting method uses a computer-aided design (CAD) program [
10,
13]. CAD can create and edit 3-D configurations and can also measure the area. It can be used to analyze the burning surface area of complicated 3-D grains. However, this method requires considerable time and manpower, or a complicated macro. The numerical method discretizes the grain configuration and analyzes the motion of the surface [
14,
15]. This method stores surface position information in a 3-D coordinate system. The burning surface area is analyzed by updating the position information in the numerical method. This method is not suitable for optimum design because it requires the most computation time among the three types.
2.3. Necessity for New Grain Design
Grain burn-back analysis should be executed rapidly because large amounts of grain configurations are generated during the optimum design process. Therefore, a previous study used an analytical method, and the optimum design target was limited to configurations that could be geometrically analyzed, such as slots and stars. It is necessary to use a different burn-back analysis method for optimizing the design of the complicated 3-D configurations used in propulsion systems. However, because automation is difficult with a long burn-back analysis time, it is difficult to apply the existing optimal design process. In this regard, this study developed a new grain design method and confirmed its feasibility.
Machine learning can acquire meaningful information from data. If the correlation between the configuration variable and area profile can be learned using machine learning, the performance of the newly designed grain can be predicted with high accuracy.
Figure 3 shows the grain design process using machine learning. The database consists of stored data, such as a set of configuration variables and classes. A large amount of information is organized into databases and high-quality information is obtained through data mining; machine learning is then used to identify and evaluate meaningful patterns. The model is the result of machine learning and it calculates the margin of a set of configuration variables. The margin predicts the class of a set of configuration variables.
This study was conducted to determine whether machine learning is an appropriate method for grain design. The goal of grain design was to obtain a neutral burning surface area profile, which is called briefly the neutral profile in this study. The neutral profile was defined as having a standard deviation of ≤0.5. Class 1 was neutral and Class −1 was non-neutral, as listed in
Table 2.
This study had two goals. The first was to create a model that can predict whether it is neutral. By creating a classification model from the saved data, we can verify whether the area profile is neutral without performing a burn-back analysis. Another goal was to modify the non-neutral shape to a neutral shape using the model. When the grain shape designed in consideration of various conditions is a non-neutral type, it is necessary to change it to a neutral-type through as few variable changes as possible. The database was constructed and a classification model was created using data mining and SVM. After checking the accuracy of the classification model, an arbitrary set of configuration variables was modified to a neutral configuration by using an optimization technique.
5. Conclusions
A fundamental study on grain design using machine learning was conducted. In this study, a new design method for machine learning was developed using stored data for grain design. The database for the burning surface area and configuration variables was constructed using analytic burn-back analysis and the standard deviation was calculated. The analysis results were defined as class 1 if it satisfied the requirement and class −1 if it did not. The SVM learned the condition that satisfied the requirements and obtained the classification model. This model separates the two classes using hyperplanes, enabling the margin of the new set of configuration variables to be calculated. It was confirmed that the grain can be designed without additional analysis using the stored data. The classification model obtained via machine learning performed classification with high accuracy, verifying that it can replace burn-back analysis.
It was verified that machine learning is an effective method for optimizing grain design. Through this design process, it has been confirmed that the complicated effects of the configuration variables can be learned through machine learning and that the result is very useful. However, since the study was conducted at a fundamental level, there are some supplements. Although it satisfies the objective, it is necessary to perform an additional optimum design of the standard deviation. In the case of real grain design, there are various requirements—such as average area and burn time—but, in this study, only the standard deviation was learned and it is necessary to analyze whether the amount of sample data is adequate.
Further studies are required to develop a general method of grain design. Various topics were identified, such as the feasible size of the database, classification of multiple classes according to the average burning surface area, the use of multiple models for requirements, and training using randomly generated data. In a subsequent study, a practical grain design process has been considered and a study that will apply machine learning to the entire grain design process has been planned.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}