1. Introduction
Given an abstract probability space
and a random variable
, its probability density function
is defined as the Borel measurable and non-negative function that satisfies
for any Borel set
([
1], Ch. 2). In other words,
is the Radon–Nikodym derivative of the probability law
with respect to the Lebesgue measure. When the density function exists, the random variable (its probability law) is said to be absolutely continuous. Examples of absolutely continuous distributions are Uniform, Triangular, Normal, Gamma, etc.
When the probability law of
X is unknown in explicit form but realizations of
X can be drawn, a kernel estimation may be used to reconstruct the probability density function of
X. It is a non-parametric method that uses a finite data sample from
X. If
are independent realizations of
X, then the kernel density estimator takes the form
, where
K is the kernel function and
b is the bandwidth, see [
2].
Kernel density estimation may present slow convergence rate with the number of realizations and may smooth out discontinuity and non-differentiability points of the target density. For certain random variable transformations
, where
U and
V are independent random quantities and
g is a deterministic real function, we will see that there is an alternative estimation method of parametric nature that is based on Monte Carlo simulation. Such approach has been used for certain random differential equations problems, see [
3,
4,
5,
6,
7]. However, a detailed comparison with kernel density estimation, both theoretically and numerically, has not been performed yet. This detailed comparison is the novelty of the present paper. We will demonstrate that the parametric method is more efficient and correctly captures density features. Numerical experiments will illustrate these improvements.
As it shall be seen later (see expression (
2)), our approach relies upon the representation of the probability density via the expectation of a transformation derived through the application of the so-called Random Variable Transformation (RVT) method [
1] (also termed “change of variable formula”, see [
8]). This method depends on the computation of invertible functions with Jacobian determinant. We point out that, when the number of random model parameters is large, it is convenient to apply competitive techniques to carry out computations. In this regard, we here highlight recent contributions that address this important issue in the machine learning setting. In [
8], the authors applied real-valued non-volume preserving (real NVP) transformations to estimate the density when reconstructing natural images on datasets through sampling, log-likelihood evaluation, and latent variable manipulations. Recently, in [
9], the real NVP was improved by combining the so called flow-based generative models. In the machine learning context, these are methods based upon the application of the “change of variable formula”—together with Knothe–Rosenblatt rearrangement.
2. Method
Let be a random variable, where U is a random variable, V is a random variable/vector, and g is a deterministic real function. The aim is to estimate the probability density function of X.
A kernel density estimator takes the form
where
and
are independent realizations of
U and
V, respectively.
Let us see an alternative method when
U and
V are independent. Suppose that
U has an explicit density function
. Suppose also that
is invertible for all
V, where
is the inverse. Then,
where
is the partial derivative with respect to the first variable and
is the expectation operator. Notice that we are not requiring
V to have a probability density.
Indeed, if
denotes the probability law of
V, then the following chain of equalities holds:
We have used the independence, the transformed density function ([
1], Section 6.2.1), and Fubini’s theorem.
To estimate the expectation from (
2) when the probability law of
V is unknown in closed form but realizations of it can be drawn, Monte Carlo simulation may be conducted. For example, the crude Monte Carlo method estimates
by using
where
are independent realizations of
V ([
10], pp. 53–54).
Notice that the structure and the complexity of this estimator are very similar to a kernel one. For (
1), one needs realizations
,
, while (
3) only uses
. Hence, the complexity of drawing realizations of
V affects (
1) and (
3) in exactly the same way. On the other hand, (
1) evaluates
K and
g, while (
3) evaluates
and
h.
By the central limit theorem, the root mean square error of the Monte Carlo estimate (
3) of the mean is
, where
is the standard deviation of the random quantity within the expectation (
2) (which is assumed to be finite). Variance reduction methods may be applied, such as antithetic or control variates, see [
11]. By contrast, the root mean square error of the kernel estimate (
1) is
,
[
2].
The density estimation of thus becomes a parametric problem, as we are estimating the expectation parameter from a population distribution. This is in contrast to kernel density estimation, which is non-parametric because it reconstructs a distribution. Moreover, the method presented here acts pointwise, so discontinuities and non-differentiability points are correctly captured, without smoothing them out.
3. Some Numerical Experiments
In this section, we compare the new parametric method with kernel density estimation numerically. We use the software Mathematica® (Wolfram Research, Inc, Mathematica, Version 12.0, Champaign, IL, USA, 2019).
Example 1. Let
, where
and
are independent random variables. Obviously, the exact density function of
X is known via convolution:
. However, this example allows for comparing the new parametric method with kernel density estimation by calculating exact errors. With
and
, expression (
2) becomes
. From
M realizations, we conduct a kernel density estimation (Gaussian kernel with Silverman’s rule to determine the bandwidth,
, where
is the standard deviation of the sample and
is the interquartile range of the sample), crude Monte Carlo simulation on
, antithetic variates method (
realizations of
V and the sample is completed by changing signs), and control variates method (the control variable here is
V). Let
be the density estimate of
. We consider the error measure
. Numerically, this integral is computed by fixing a large interval
and performing Gauss–Legendre quadrature on it. As
is random, we better consider
. This expectation is estimated by repeating the density estimate several times (we did so 20 times).
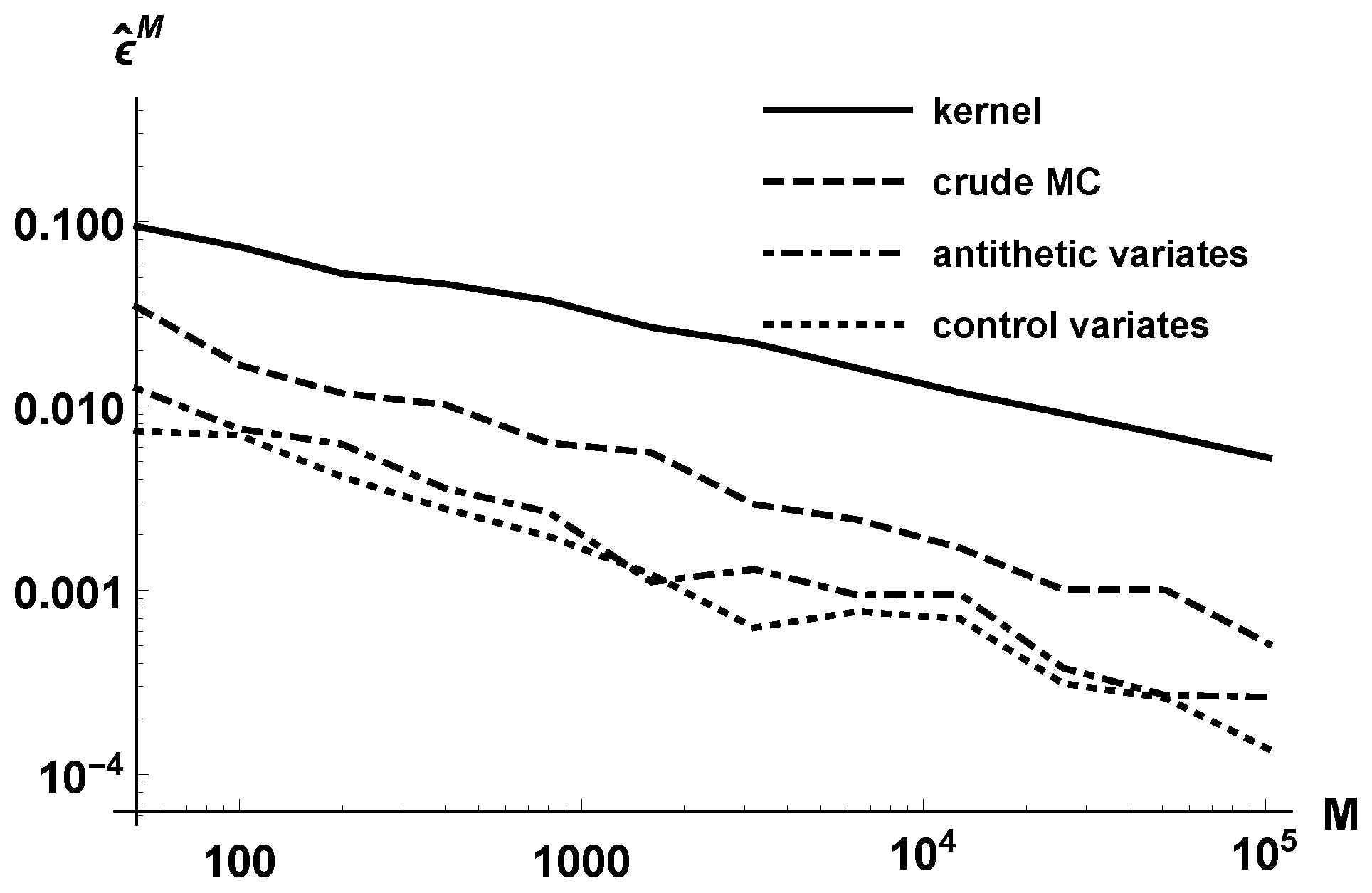
Figure 1 reports the estimated error
in log-log scale, for different orders
M growing geometrically. Observe that the parametric approach is more efficient than the kernel method. Variance reduction methods also allow for lowering the error. The lines corresponding to the three parametric methods have slope
approximately, due to the well-known decrease of the Monte Carlo error.
For example, to achieve an error , the kernel density estimation requires about realizations, while the parametric crude Monte Carlo estimation needs 400 realizations. The antithetic method decreases the number of required realizations to 50–100, and the control variates approach does so even more, to less than 50.
In
Table 1, we present the timings in seconds for achieving root mean square errors less than
and
. We work at the density location
. Observe that the kernel density estimation is the least efficient method, especially as we require smaller errors.
Example 2. Let
, where
and
, being
and
. All of the random variables are assumed to be independent. With
and
, expression (
2) is
. Notice that, despite
V being discrete,
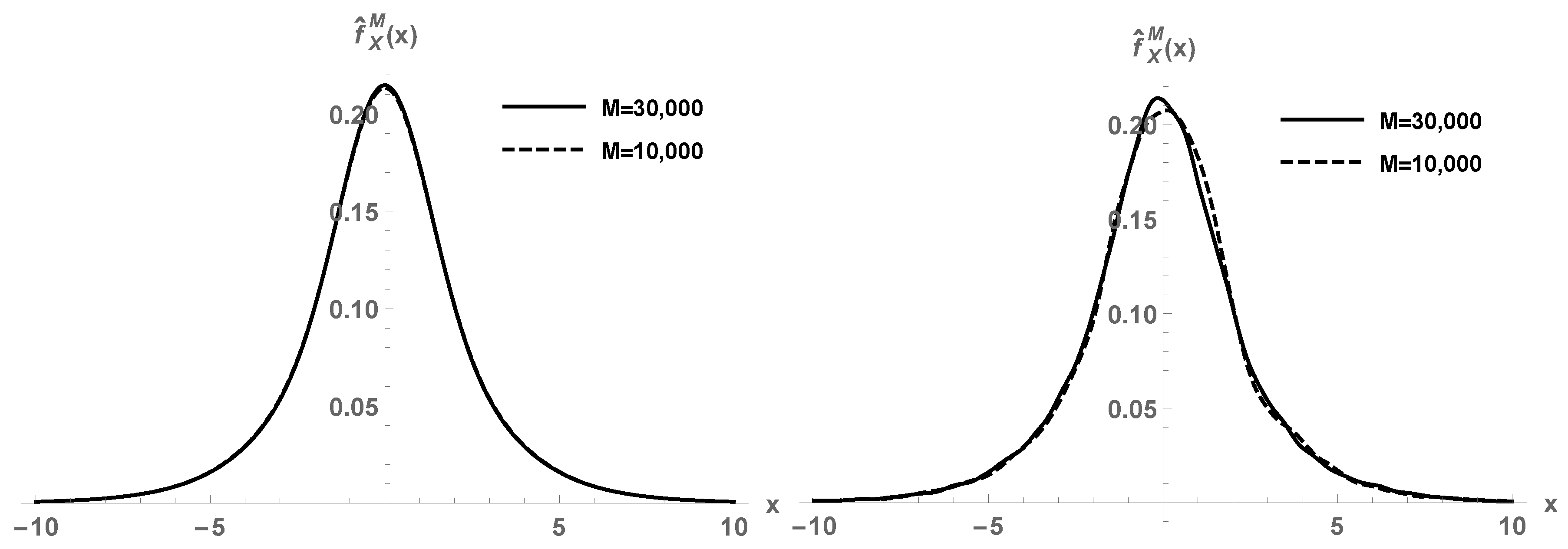
X has a density. This expectation cannot be computed via quadratures, due to the large dimension of the random space. We employ our parametric method using crude Monte Carlo simulation. In
Figure 2, first panel, we depict the estimated density function
using
M realizations. For
and
, we perceive good agreement between the approximations. This is in contrast to the second panel of
Figure 2, where the kernel density estimation does not show convergence yet.
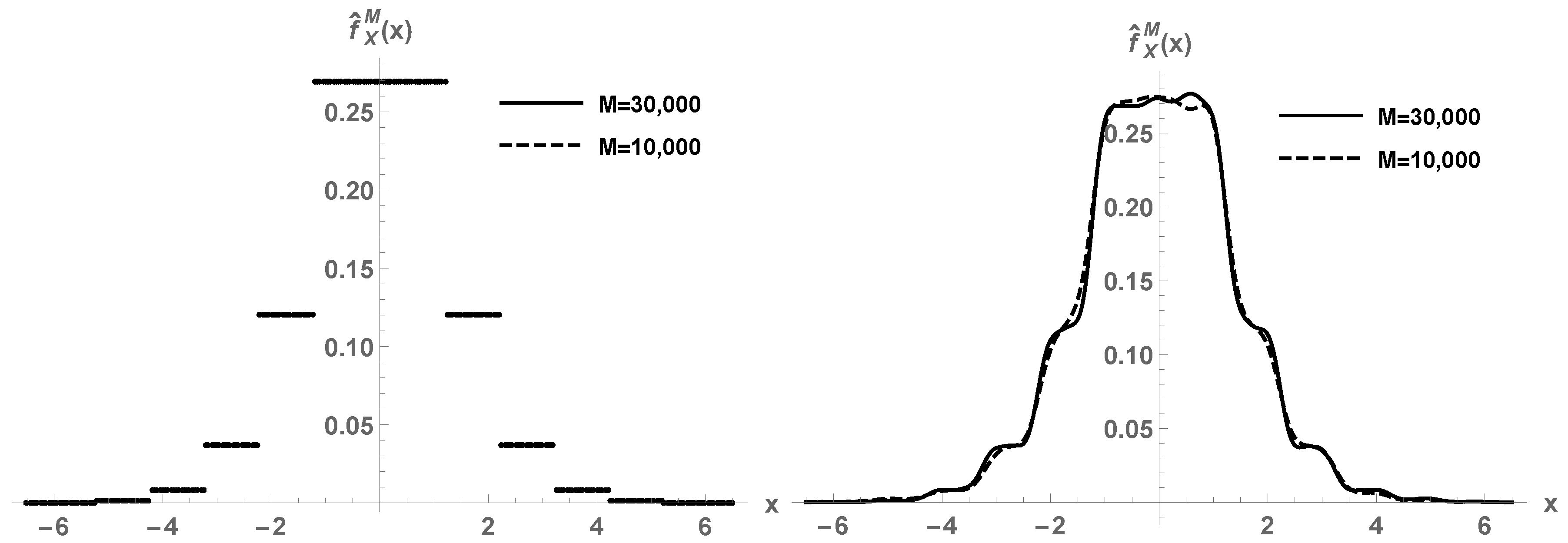
Example 3. Consider the same setting of Example 2 but
(now
is not continuous on
). In
Figure 3, first plot, we show the estimated density function
by the parametric crude Monte Carlo method using
M realizations. The discontinuity points of the target density
are correctly captured. Indeed, the method acts pointwise in
x, so any feature of
will be correctly identified, no matter how rare it is. By contrast, the kernel density estimation smooths out the discontinuities, see the second panel of the figure.
4. Application to Random Differential Equations
A random differential equation problem considers some of the terms in the system (input coefficients, forcing term, initial conditions, etc.) as random variables or stochastic processes [
1]. This is due to errors in measurements of data when trying to model a physical phenomenon, which introduces a variability in the parameters estimation. The solution to the system is then a stochastic process. Its deterministic trajectories are not the main concern. Instead, the study of the statistical content of the solution is the main goal. An important aim is to compute its probability density function. The key idea is that the solution is a transformation of the input random parameters; therefore, the probability density may be estimated as described in this paper whenever the solution is given in closed form. In the notation used in this paper,
U and
V would denote the input random parameters of the system, and
g would be the transformation mapping that relates the output with the inputs. A specific input parameter is selected as
U, with respect to which the mapping
g is easily invertible to obtain
h.
We consider the Ricatti random differential equation
where
and
are independent random variables. The solution to (
4) is given by
By taking
, the density function of
is given by
From
M realizations of
A, say
, the expectation is estimated via crude Monte Carlo simulation:
As seen in the previous sections, this procedure is more efficient and certain than kernel density estimation, expressed as
where the superscript
i denotes the
i-th realization,
.
For a specific numerical example, let us fix
and
.
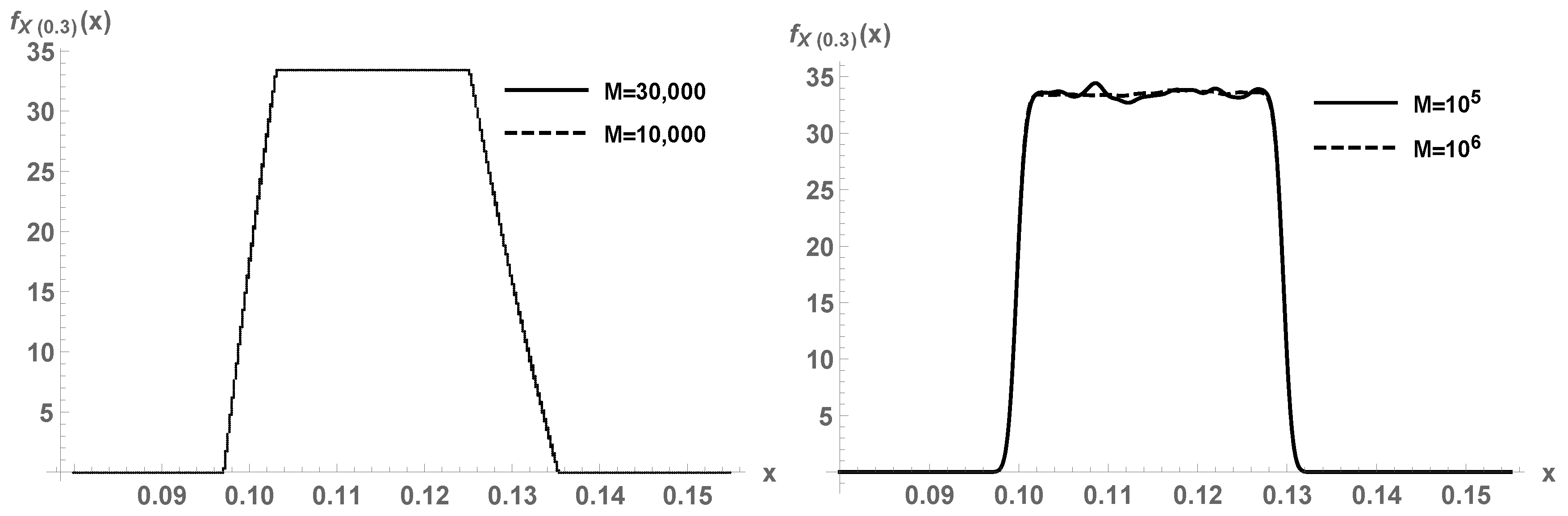
Figure 4, first panel, plots (
5) for a certain number of realizations
M for
A, for time
. A comparison is conducted with kernel density estimation with a Gaussian kernel (second panel). It must be appreciated that the parametric Monte Carlo method (
5) correctly captures the non-differentiability points of the target density.
For another example, let us consider the damped pendulum differential equation with uncertainties:
where
,
,
and
(underdamped case) are constant, the initial position
and the initial velocity
are random variables, and the source/forcing term
is a stochastic process ([
1], Example 7.2). The solution is given by
where
and
. In [
4], the density function of the response
is expressed in terms of an expectation (
2), which is estimated by means of parametric crude Monte Carlo simulation due to the large dimension of the random space. By taking
, one of the formulas derived is
where the superscript
i denotes the
i-th realization,
. Compare (
8) with a kernel density estimation
The expressions and their complexities are very similar, but the convergence of (
8) is faster with
M, as justified in the previous sections.
Let us see a numerical example. We take the upper time
, the damping ratio
and the natural frequency
. Consider
,
and
. The series is understood in
and
is a sequence of independent random variables with
distribution. This is a Karhunen–Loève expansion ([
10], p. 47). It is assumed that
,
, and
Y are independent. By applying (
8) with the sum of
truncated to a finite-term series, we estimate the density function of
. For example, in
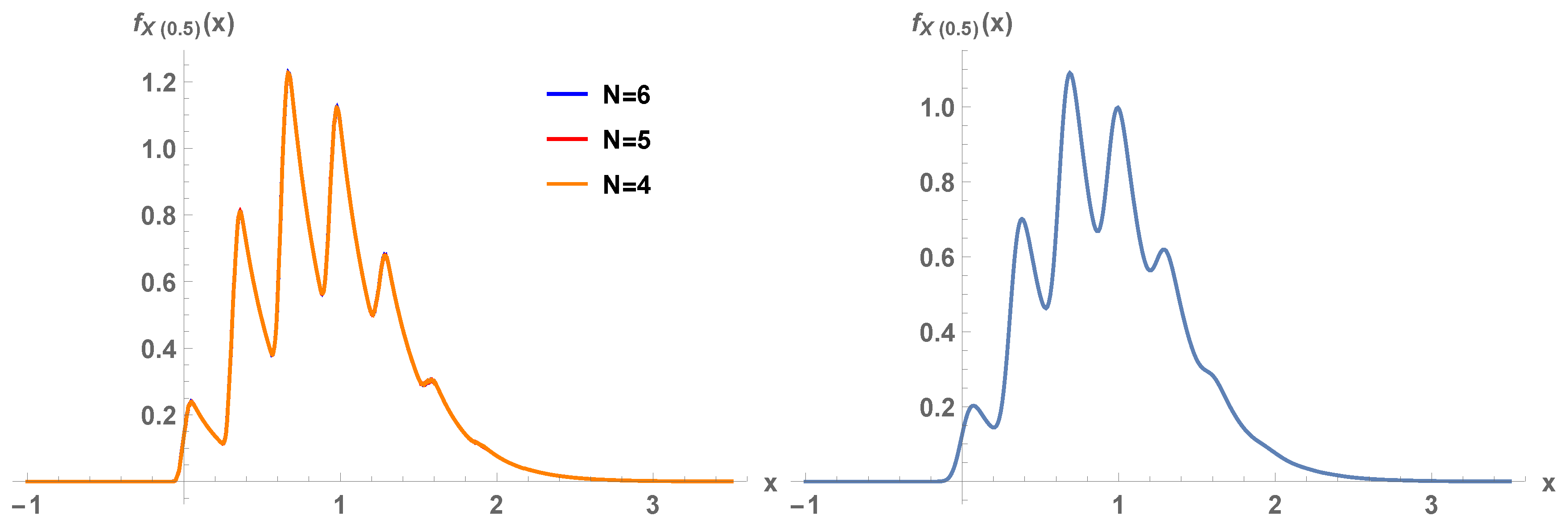
Figure 5, first panel,
is plotted for orders of truncation
, 5, and 6. Overlapping of the graphs is clearly appreciated. The strong oscillations of the density are perfectly captured because the method acts pointwise. In the second panel of the figure, the kernel density estimate with Gaussian kernel is plotted, with
realizations. Although there is apparent agreement between both panels, our parametric Monte Carlo method captures all the peaks while the kernel method smooths them out.
Further applications of the methodology for random differential equations may be consulted in [
3,
4,
5,
6,
7]. The present paper forms the theoretical and computational foundations of the methodology used in those recent contributions.
5. Conclusions
In this paper, we have been concerned with the density estimation of random variables. We have proposed an alternative to kernel density estimation for certain random variable transformations. The alternative is based on the estimation of an expectation parameter via Monte Carlo methods; therefore, it is of parametric nature and improves kernel methods in terms of efficiency. Furthermore, the method captures density features and does not smooth out discontinuity and non-differentiability points of the target density.
As shown here, the solution to some random differential equation problems is an explicit transformation of the input random parameters. The methodology proposed in this paper may be employed to estimate the density function of the closed-form stochastic solution parametrically, instead of relying on kernel estimation.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}