This section first proposes the system architecture in
Section 2.1 and the evolutionary method in
Section 2.2. Then, a set of experiments are presented in
Section 2.3 where organoleptic properties of a selection of beers are used along with a real-world in-stock inventory to evaluate the proposed approach by “reverse manufacturing” these commercial beers from their target organoleptic properties which are obtained from publicly available data.
2.1. System Architecture
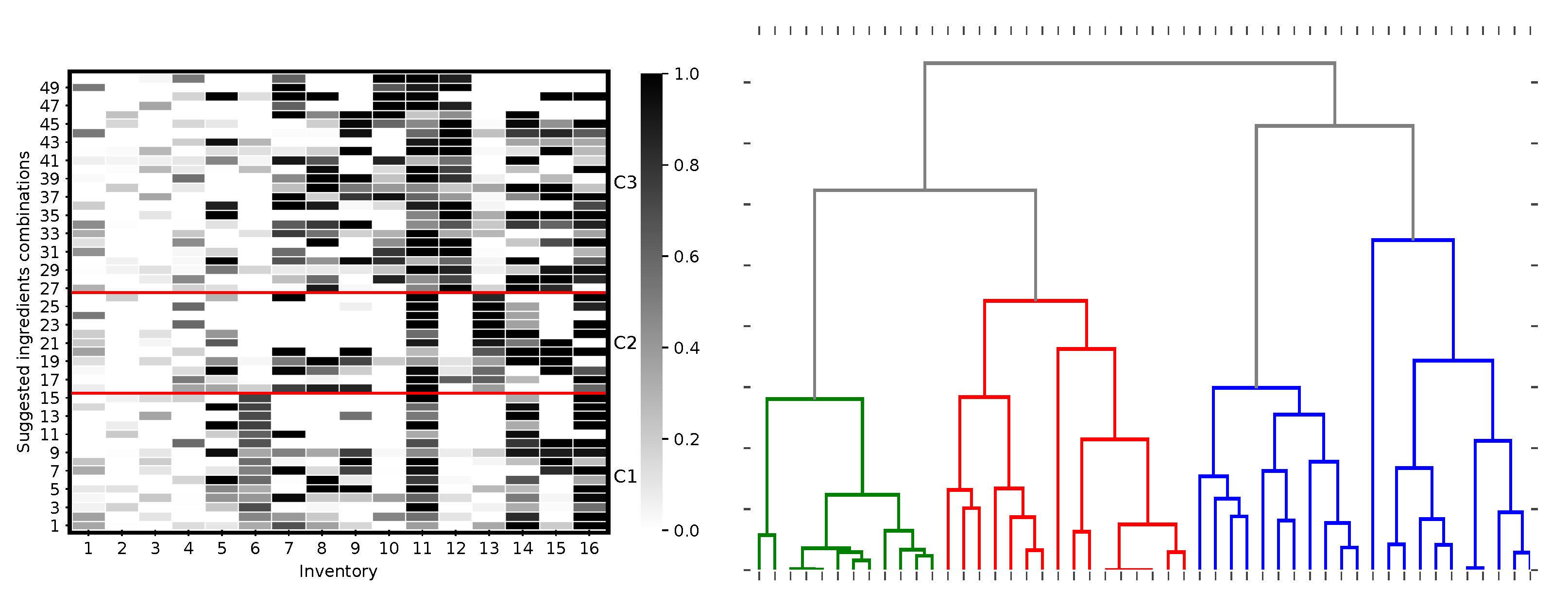
In the first instance, evolutionary modelling is able to accommodate a complex set of variables and optimisation parameters. Our population-based algorithm takes an inventory of existing ingredients and their weights (see
Table 1) along with a desired set of organoleptic properties for a number of brands (see
Table 2) and returns optimal ingredient lists and their associated amounts which facilitate the production of the target product.
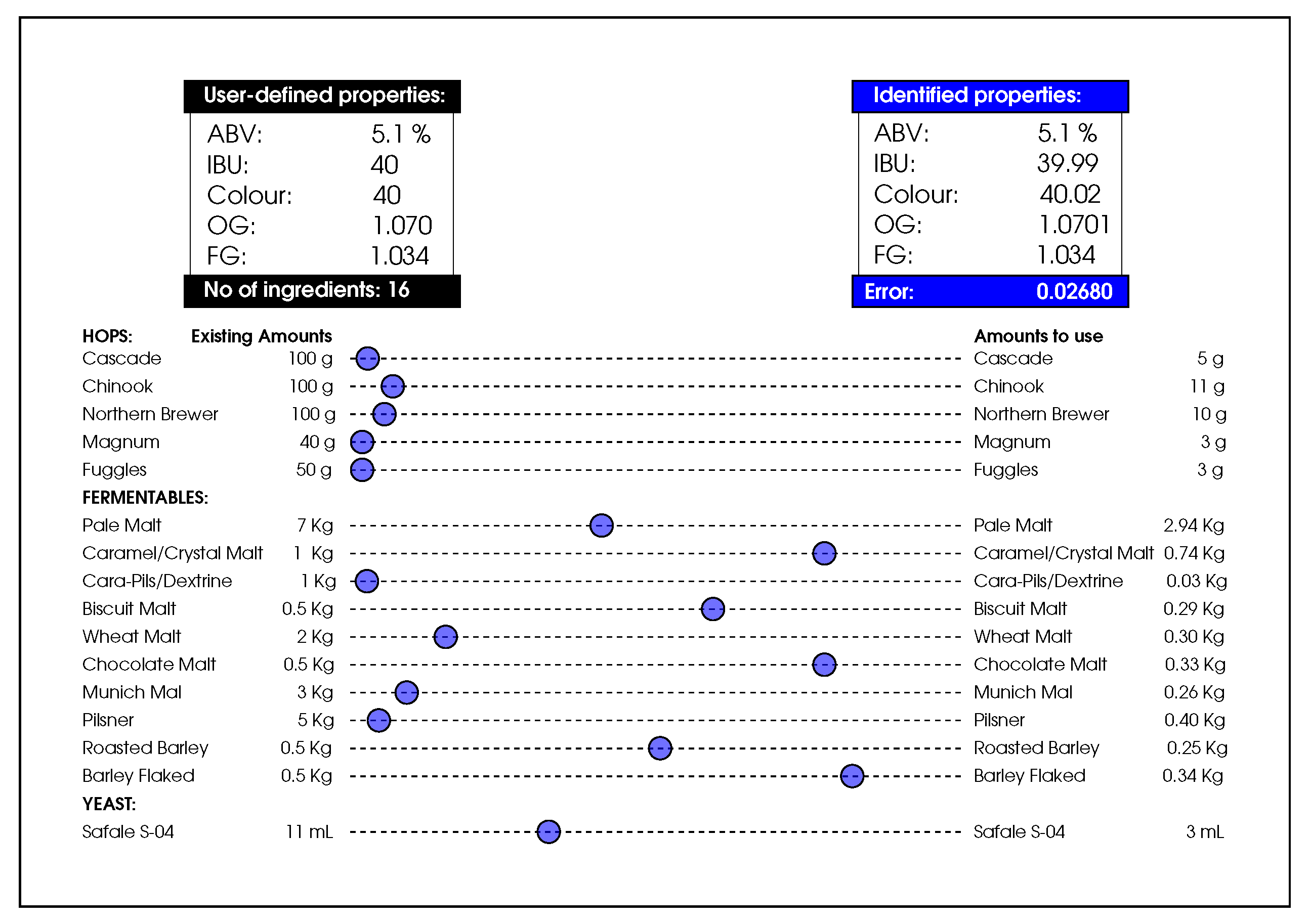
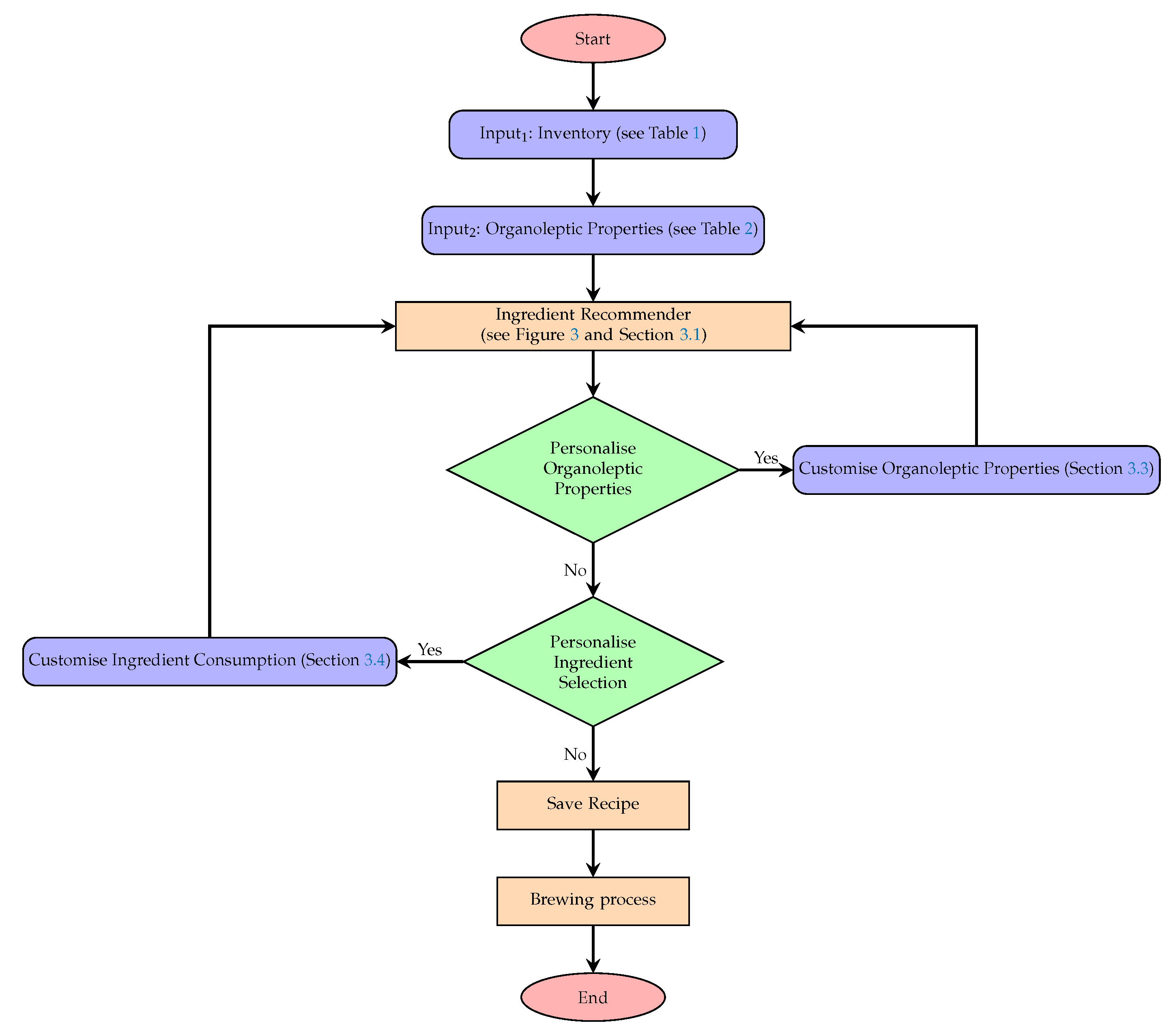
Figure 1 provides a schematic view of the brewing process optimisation where the list of ingredients are provided on the left, along with their weights in the inventory. The organoleptic properties are provided by the user (in the top-left corner), reflecting their preferences. The system output, recommending the recipe of the best matching users’ preferences, is shown on the right along with their corresponding organoleptic properties. The underlying processes guiding the system are illustrated in
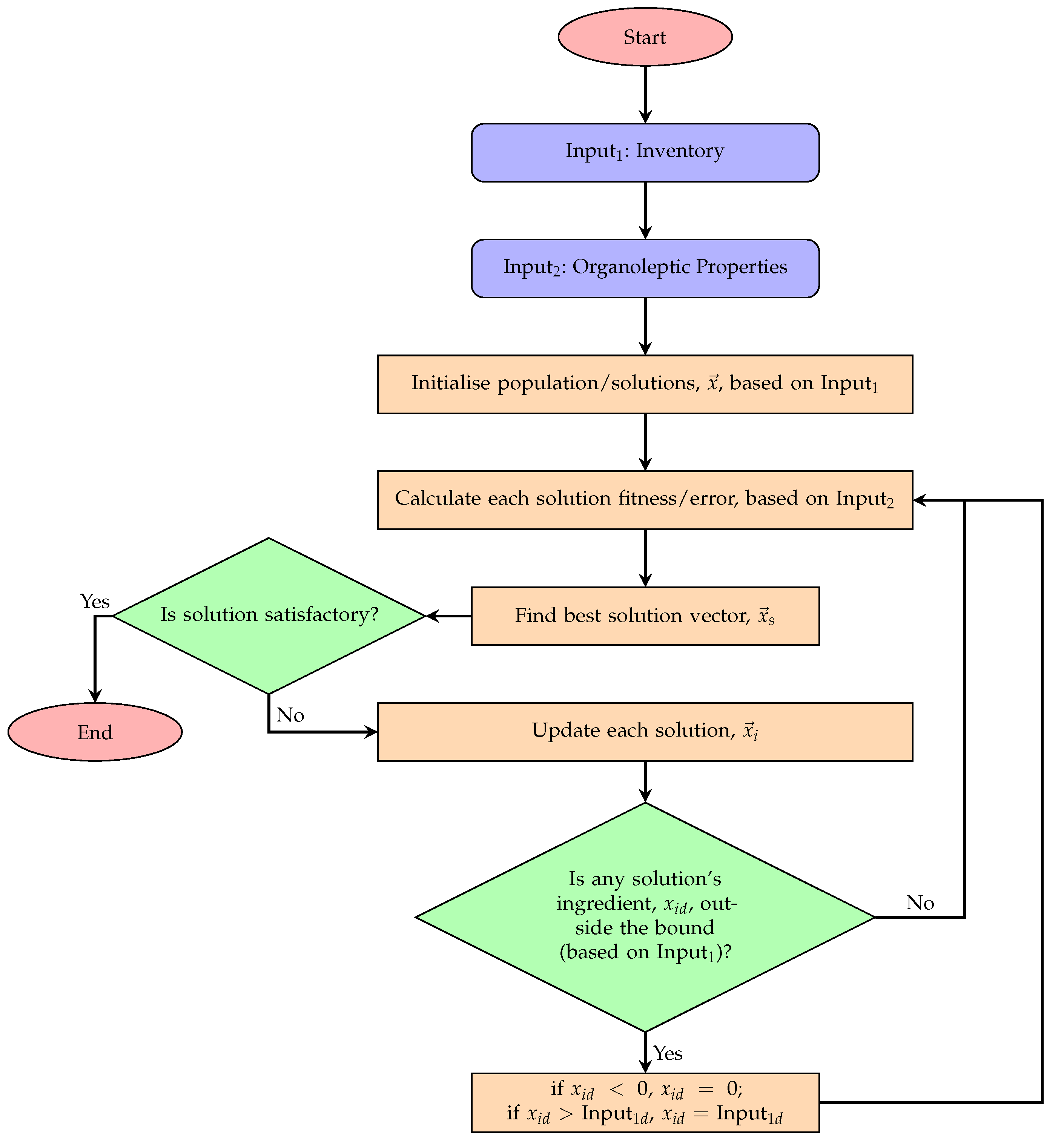
Figure 2, along with pointers to various experiments in the paper which evaluates different proposed features.
The formulas which allow the simulation of the fermentation process are provided in
Appendix A.1. As previously mentioned, this process modelling component is primarily used to determine fitness functions rather than to directly guide optimisation itself.
2.2. Population-Based Optimiser
The algorithm used in this work is a population-based optimiser, dispersive flies optimisation (DFO) [
4], which unlike many other evolutionary algorithms, uses a minimalist set of vector/parameters [
18,
19]. In a preliminary study conducted recently [
20], DFO has been used alongside other well-known population-based optimisers, including: particle swarm optimisation (PSO) [
21], as one of the most well-known population-based algorithms, and differential evolution (DE) [
22], a well-known and efficient evolutionary computation method. It has been demonstrated that DFO has outperformed these algorithms and is used as the optimiser in this work. This algorithm belongs to the broad family of swarm intelligence and evolutionary computation techniques and has been applied to a diverse set of problems including: medical imaging [
23], solving diophantine equations [
24], PID speed control of DC motor [
25], optimising machine learning algorithms [
26,
27], training deep neural networks for false alarm detection in intensive care units [
28], computer vision and quantifying symmetrical complexities [
29], identifying animation key points from medialness maps [
30], and the analysis of autopoiesis in computational creativity [
31].
In this algorithm, the position vector (candidate solution (each solution is a vector whose length is equal to the number of existing ingredients, and each value in the vector represents the amount used from each ingredient.)) of each member of the population (the collection of candidate solutions) is defined as:
where
i represents the
i’th individual (i.e.,
i’th solution),
t is the current time step,
D is the problem dimensionality (i.e., the number of ingredients), and
N is the population size (i.e., the number of candidate solutions used for information exchange and communication, as is explained). For continuous problems,
(or a subset of
, which is the case of this problem, where
is between 0 and the existing amount of the
d’th ingredient).
In the first iteration, where
, the
d’th component (or ingredient) of the
i’th candidate solution is initialised as:
where
and
is the maximum amount available to use for the
d’th ingredient (see
Table 1).
Components of the solution vectors are independently updated in each iteration, taking into account: current individual’s solution; current individual’s best neighbouring solution (consider ring topology, where individuals have left and right neighbours, each holding a solution vector); and the best solution vector in the swarm.
The update equation is
where
: d’th ingredient of the i’th solution at time step t;
: d’th ingredient of the solution vector held by ’s best neighbouring individual (in ring topology) in at time step t;
: d’th ingredient of the swarm’s best solution vector at time step t;
: generated afresh for each ingredient and for each solution update.
The optimisation process avoids local minima through a sampling-based restart mechanism. As a sampling mechanism, the individual ingredients’ amounts of the solution vectors are reset if a random number generated from a uniform distribution on the unit interval is less than the disturbance or restart threshold, .
Elitism is used for DFO, which essentially keeps the best found solution in each iteration intact, while updating other solutions in the population. In this work, if the updated amount of an ingredient is outside the feasible boundaries, its value is clamped to the edges (i.e., to either 0 or the maximum existing amount of that particular ingredient). Algorithm 1 provides an overview of the process in which the algorithm performs the optimisation task, and
Figure 3 illustrates the steps taken as part of the ingredient recommendation process. The algorithm’s source code is available on:
http://github.com/mohmaj/DFO (accessed on 6 January 2022).
| Algorithm 1: Dispersive Flies Optimisation (DFO) |
![Foods 11 00351 i001]() |
2.3. Experiment Setup
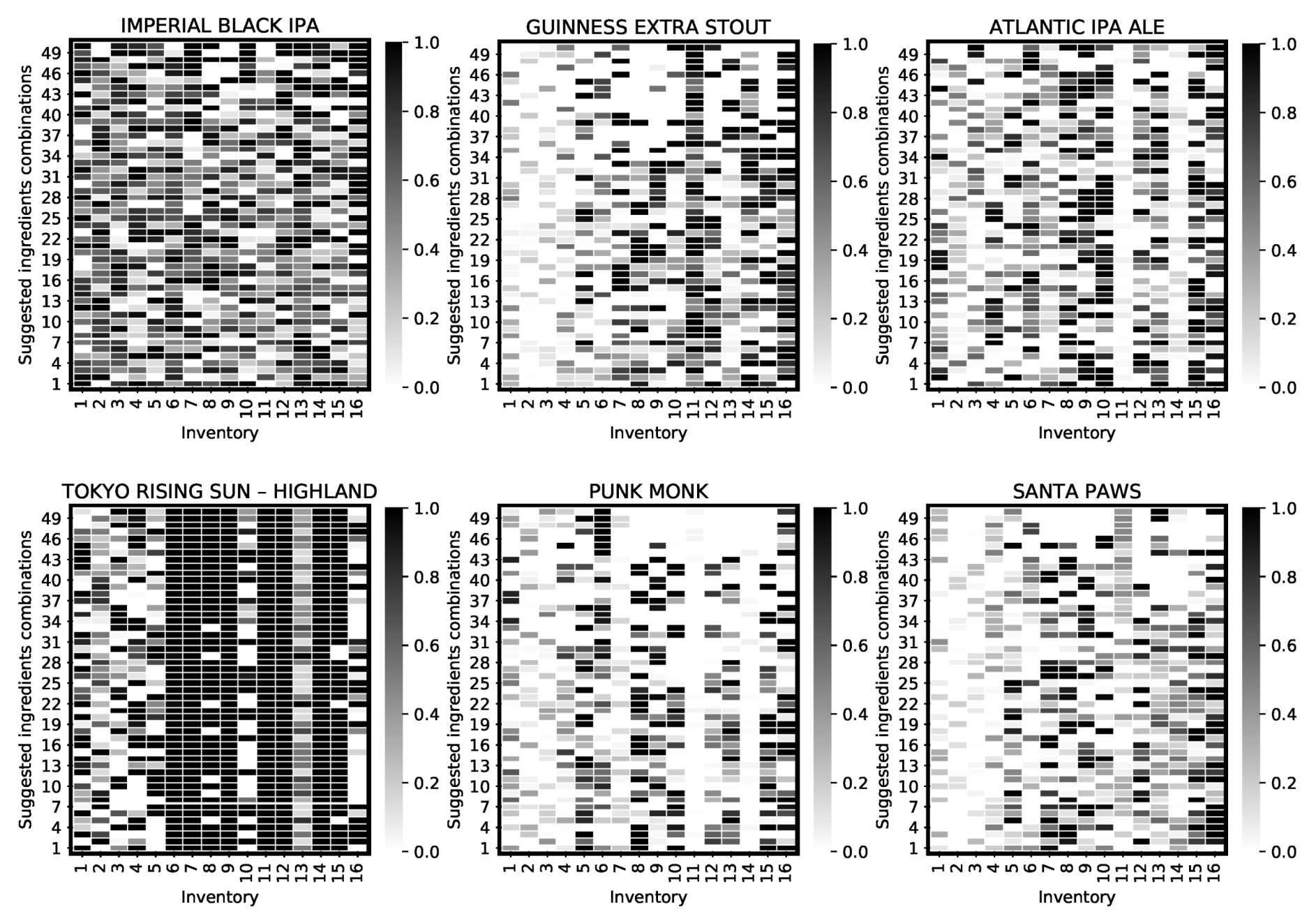
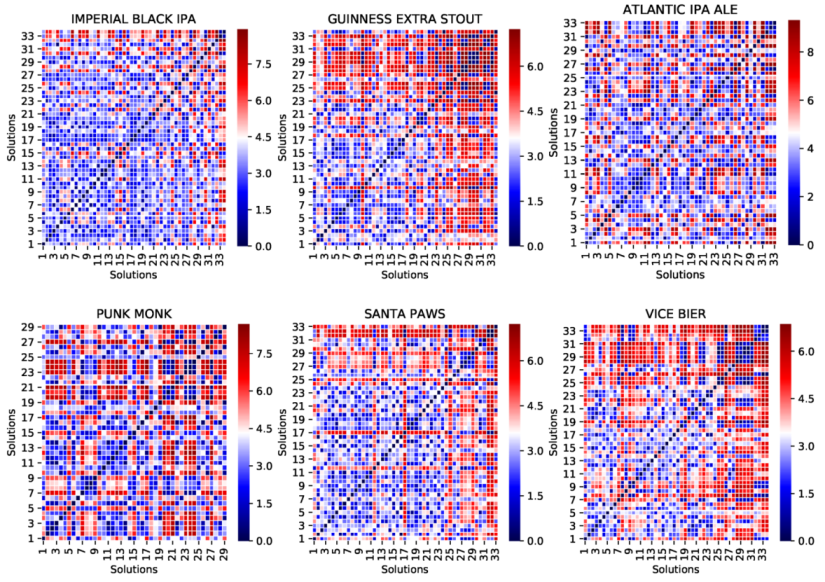
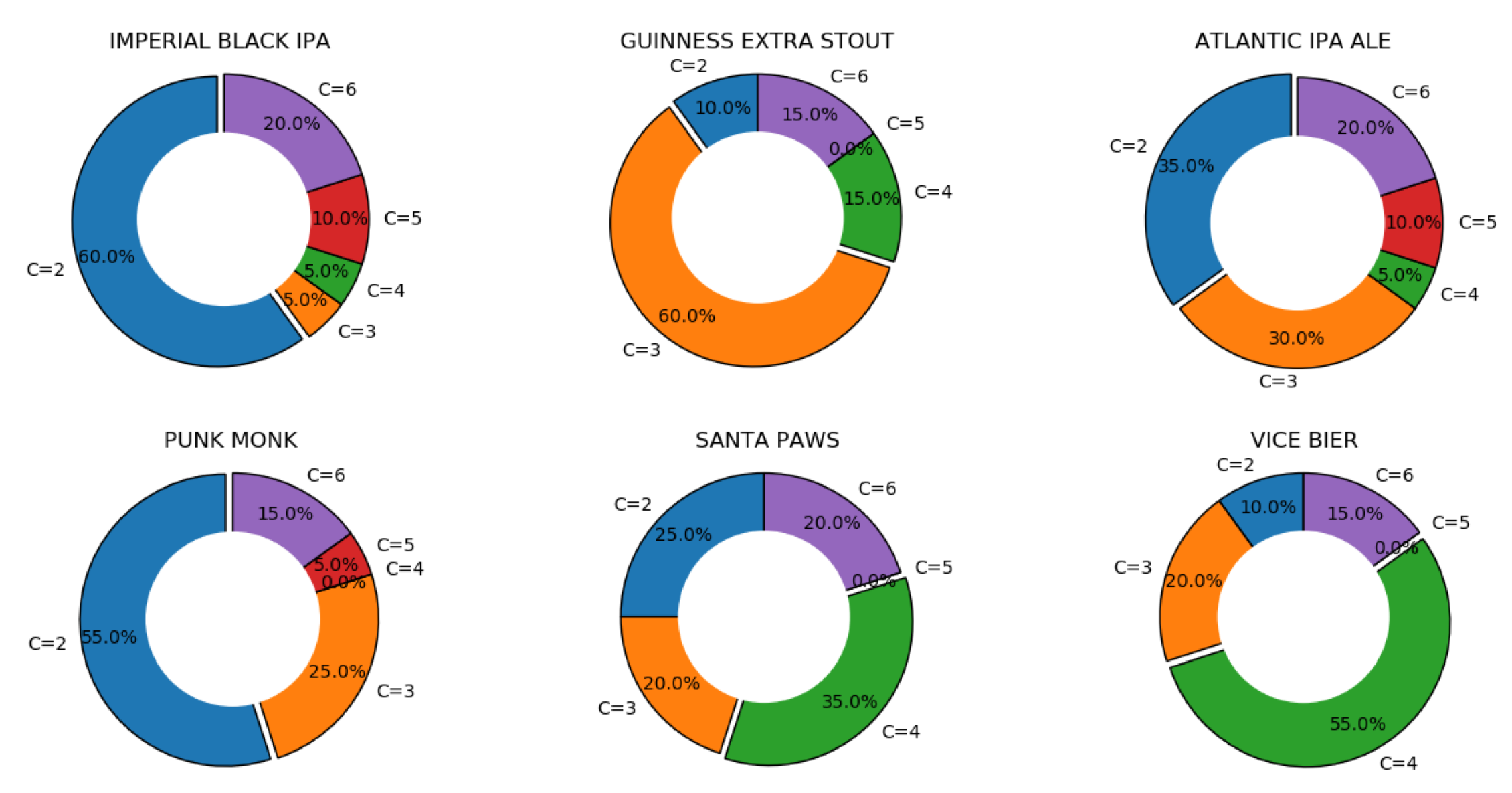
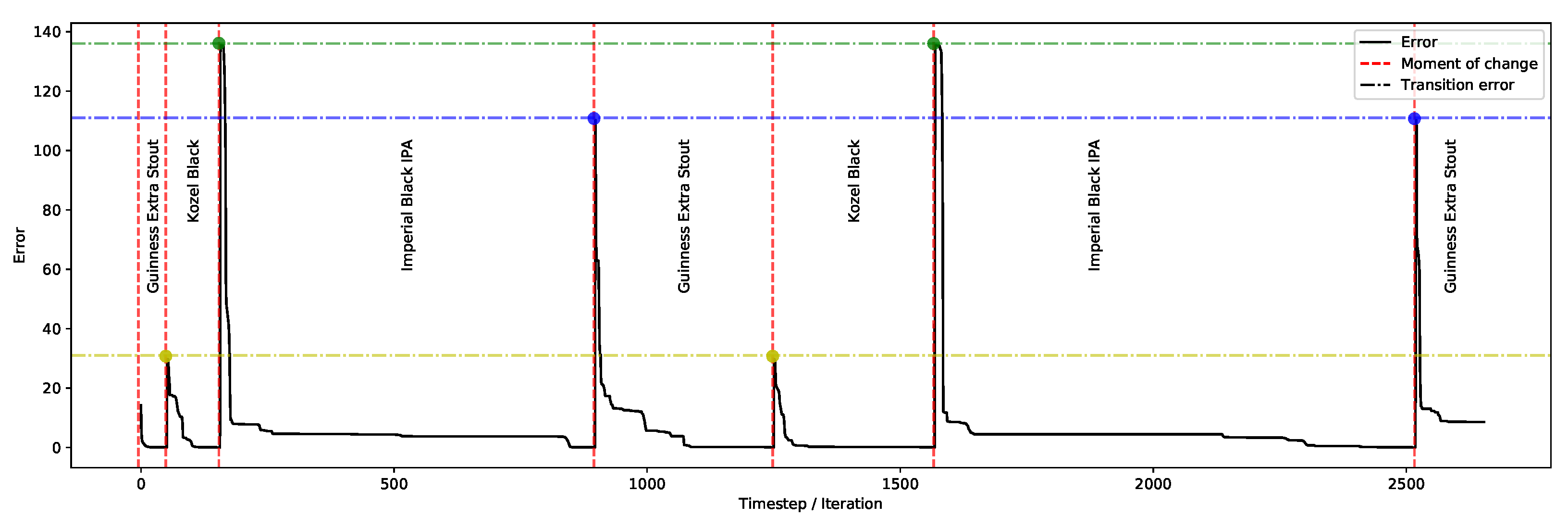
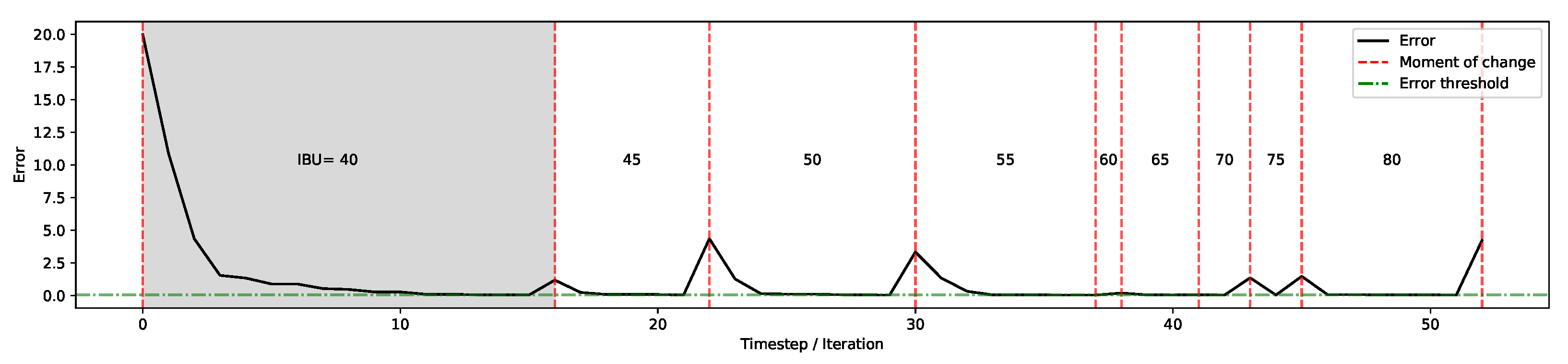
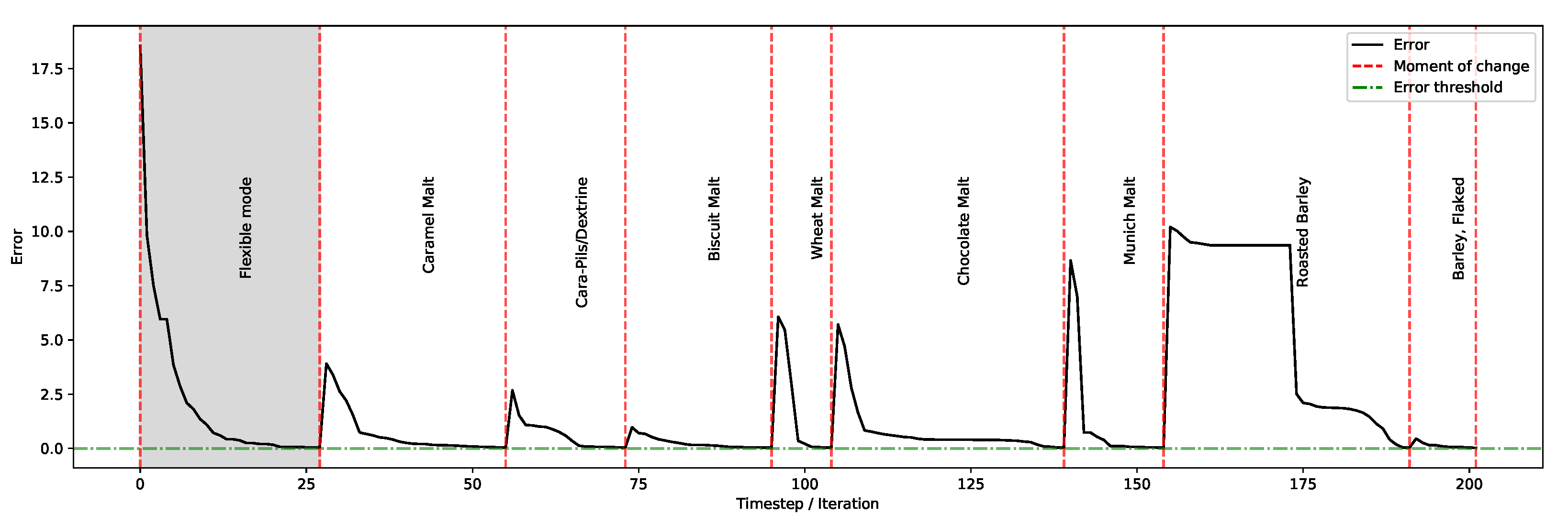
The first set of experiments gives an indication on the overall performance of the system on each product when generating solutions (whose diversity and distinctness are demonstrated in subsequent sections). This is then followed by analysing the behaviour of the algorithm in terms of improvements throughout the process. Then, the next set of experiments evaluates some practical features of the system, showing in particular its adaptability towards: (1) drastic, on-the-fly changes in organoleptic properties, (2) gradual changes in organoleptic properties during the optimisation process, and (3) system’s ability to accept real-time user-preference on the balance of ingredients’ consumption while preserving the user-defined organoleptic properties.
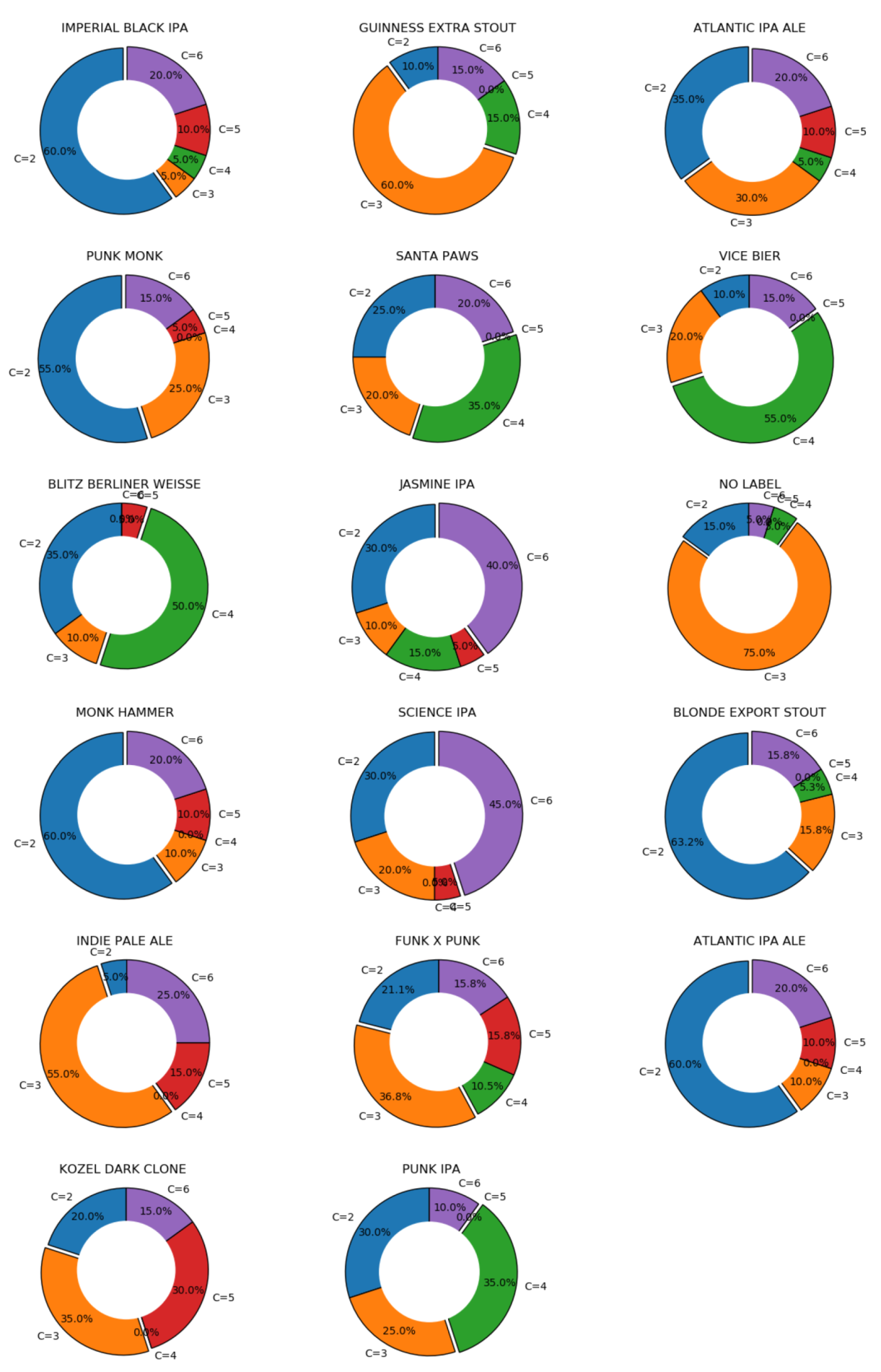
In order to set up the simulation experiments, we first adopted an inventory of ingredients, along with organoleptic properties of twenty-two existing commercial beers which were used as benchmarks. In these experiments, the population size for the DFO algorithm was set to 50, and the termination criterion was set to reaching 50,000 function evaluation or FEs (a counter which is incremented when a solution vector’s quality is evaluated) or reaching the error , which is defined next. There were 50 independent runs for each experiment, and the results are summarised over these independent simulations.
2.4. Performance Measures
The performance measures used in this paper are (a) error: representing the proximity to optimal solutions (this metric is used to steer the optimisation process); (b) efficiency: the speed of convergence to optimal solutions; (c) reliability: the consistency of the algorithm over a number of trials in reaching the optimal solutions; and (d) diversity: novelty of solutions and their uniqueness measured by their distance from each other.
Error is defined by the quality of the solution in terms of its closeness to the optimum position (i.e., minimisation).
where
is the list of ingredients and
is the number of properties, with
: ABV,
: IBU,
: Colour,
: OG, and
: FG (where the relevant equations are provided in
Appendix A.1).
represents the desired value provided by the brewers (in this case from
Table 2), whose distance is measured against the value of the solution generated by the system.
Efficiency is defined as the number of function evaluations before reaching a specified error, and
reliability is the percentage of trials where the specified error of
is reached.
where
n is the number of trials in the experiment and
is the number of successful trials. Additionally,
diversity is used to measure the ability to explore the solution space towards producing multiple solutions. There are various approaches to measure diversity. The average distance around the population centre is shown to be a robust measure in the presence of outliers [
32]:
where
N is the population size and
is the average value of ingredient (or dimension)
d over all solutions in the population. The experiment setup for this proof of principle work is based on simulating a realistic small-scale brewery, where the brewer’s
efficiency is set to 58% (this refers to the efficiency of equipment in extracting sugars from malts during the mashing stage; efficiency is higher for larger-scale industrial setups), boil size of 24 L, batch size of 20 L, and boil time are set to 60 min.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












