
The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk

 ,
,
Abstract
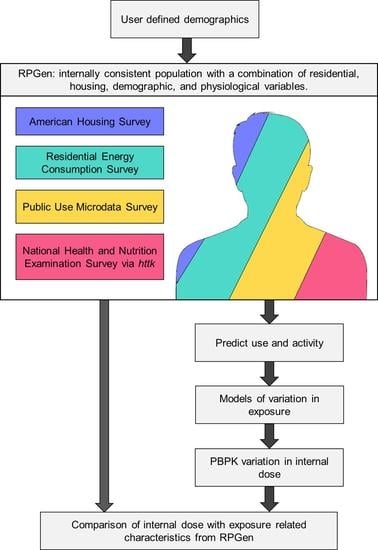
:
1. Introduction
2. Methods
2.1. Setting
2.2. Region
2.3. Income
2.4. House Type
2.5. Family Category
2.6. Population Assembly
2.7. Role of RPGen
2.8. Toluene Exposure for Homeowners and Non-Homeowners Case Example
3. Results
3.1. RPGen Capabilities
3.2. Toluene Case Study Results
4. Discussion
4.1. Limitations
4.1.1. Geographic Resolution
4.1.2. Exposure Pathways
4.1.3. Other Data Limitations
4.2. Case Study Discussion
4.3. Other Exposure Models
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dennis, K.K.; Auerbach, S.S.; Balshaw, D.M.; Cui, Y.; Fallin, M.D.; Smith, M.T.; Miller, G.W. The importance of the biological impact of exposure to the concept of the exposome. Environ. Health Perspect. 2016, 124, 1504–1510. [Google Scholar] [CrossRef] [Green Version]
- Wild, C.P. Complementing the genome with an “exposome”: The outstanding challenge of environmental exposure measurement in molecular epidemiology. Cancer Epidemiol. Prev. Biomark. 2005, 14, 1847–1850. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wild, C.P. The exposome: From concept to utility. Int. J. Epidemiol. 2012, 41, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Rappaport, S. What is the Exposome? Center for Exposure Biology: Berkley, CA, USA, 2013; Available online: https://www.healthandenvironment.org/docs/ExposomeRappaportslides.pdf (accessed on 10 November 2021).
- Vermeulen, R.; Schymanski, E.L.; Barabási, A.-L.; Miller, G.W. The exposome and health: Where chemistry meets biology. Science 2020, 367, 392–396. [Google Scholar] [CrossRef] [PubMed]
- National Resource Council. Science and Decisions: Advancing Risk Assessment; National Academies Press: Washington, DC, USA, 2009. [Google Scholar]
- National Resource Council. Exposure Science in the 21st Century: A Vision and a Strategy; National Academies Press: Washington, DC, USA, 2012. [Google Scholar]
- National Academies of Sciences & Medicine. Using 21st Century Science to Improve Risk-Related Evaluations; National Academies Press: Washington, DC, USA, 2017. [Google Scholar]
- Cushman-Roisin, B. Environmental Transport and Fate; University Lecture; Thayer School of Engineering Dartmouth College: Oak Ridge, TN, USA, 2012. [Google Scholar]
- Vallero, D.A. Air Pollution Calculations: Quantifying Pollutant Formation, Transport, Transformation, Fate and Risks; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Mackay, D.; Shiu, W.-Y.; Lee, S.C. Handbook of Physical-Chemical Properties and Environmental Fate for Organic Chemicals; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- US Environmental Protection Agency. Guidance for Reporting on the Environmental Fate and Transport of the Stressors of Concern in Problem Formulations. 2017. Available online: https://www.epa.gov/pesticide-science-and-assessing-pesticide-risks/guidance-reporting-environmental-fate-and-transport (accessed on 15 October 2021).
- Hemond, H.F.; Fechner, E.J. Chemical Fate and Transport in the Environment; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Ali, N. Polycyclic aromatic hydrocarbons (PAHs) in indoor air and dust samples of different Saudi microenvironments; health and carcinogenic risk assessment for the general population. Sci. Total Environ. 2019, 696, 133995. [Google Scholar] [CrossRef] [PubMed]
- Wambaugh, J.F.; Setzer, R.W.; Reif, D.M.; Gangwal, S.; Mitchell-Blackwood, J.; Arnot, J.A.; Cohen-Hubal, E. High-throughput models for exposure-based chemical prioritization in the ExpoCast project. Environ. Sci. Technol. 2013, 47, 8479–8488. [Google Scholar] [CrossRef]
- Csiszar, S.A.; Meyer, D.E.; Dionisio, K.L.; Egeghy, P.; Isaacs, K.K.; Price, P.S.; Vallero, D. Conceptual framework to extend life cycle assessment using near-field human exposure modeling and high-throughput tools for chemicals. Environ. Sci. Technol. 2016, 50, 11922–11934. [Google Scholar] [CrossRef]
- Fantke, P.; Ernstoff, A.S.; Huang, L.; Csiszar, S.A.; Jolliet, O. Coupled near-field and far-field exposure assessment framework for chemicals in consumer products. Environ. Int. 2016, 94, 508–518. [Google Scholar] [CrossRef] [Green Version]
- Csiszar, S.A.; Ernstoff, A.S.; Fantke, P.; Jolliet, O. Stochastic modeling of near-field exposure to parabens in personal care products. J. Expo. Sci. Environ. Epidemiol. 2017, 27, 152–159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Arnot, J.A.; Wania, F. Model for screening-level assessment of near-field human exposure to neutral organic chemicals released indoors. Environ. Sci. Technol. 2014, 48, 12312–12319. [Google Scholar] [CrossRef]
- Mitchell, J.; Arnot, J.A.; Jolliet, O.; Georgopoulos, P.G.; Isukapalli, S.; Dasgupta, S.; Hubal, E.A.C. Comparison of modeling approaches to prioritize chemicals based on estimates of exposure and exposure potential. Sci. Total Environ. 2013, 458, 555–567. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isaacs, K.K.; Glen, W.G.; Egeghy, P.; Goldsmith, M.-R.; Smith, L.; Vallero, D.; Özkaynak, H.K. SHEDS-HT: An integrated probabilistic exposure model for prioritizing exposures to chemicals with near-field and dietary sources. Environ. Sci. Technol. 2014, 48, 12750–12759. [Google Scholar] [CrossRef]
- Procedures for Chemical Risk Evaluation Under the Amended Toxic Substances Control Act, EPA-HQ-OPPT-2016-0654 C.F.R. 2017. Available online: https://www.federalregister.gov/documents/2017/07/20/2017-14337/procedures-for-chemical-risk-evaluation-under-the-amended-toxic-substances-control-act (accessed on 1 October 2021).
- Fantke, P.; Charles, R.; de Alencastro, L.F.; Friedrich, R.; Jolliet, O. Plant uptake of pesticides and human health: Dynamic modeling of residues in wheat and ingestion intake. Chemosphere 2011, 85, 1639–1647. [Google Scholar] [CrossRef]
- Isaacs, K.K.; Dionisio, K.; Phillips, K.; Bevington, C.; Egeghy, P.; Price, P.S. Establishing a system of consumer product use categories to support rapid modeling of human exposure. J. Expo. Sci. Environ. Epidemiol. 2020, 30, 171–183. [Google Scholar] [CrossRef]
- Sliwinski, M.J. Approaches to modeling intraindividual and interindividual facets of change for developmental research. Handb. Life-Span Dev. 2011, 1, 25. [Google Scholar]
- Price, P.S.; Chaisson, C.F. A conceptual framework for modeling aggregate and cumulative exposures to chemicals. J. Expo. Sci. Environ. Epidemiol. 2005, 15, 473–481. [Google Scholar] [CrossRef]
- Finley, B.; Proctor, D.; Scott, P.; Harrington, N.; Paustenbach, D.; Price, P. Recommended distributions for exposure factors frequently used in health risk assessment. Risk Anal. 1994, 14, 533–553. [Google Scholar] [CrossRef] [PubMed]
- Moya, J.; Phillips, L.; Schuda, L.; Wood, P.; Diaz, A.; Lee, R.; Blood, P. Exposure Factors Handbook, 2011 edition; US Environmental Protection Agency: Washington, DC, USA, 2011.
- Huang, L.; Ernstoff, A.; Fantke, P.; Csiszar, S.A.; Jolliet, O. A review of models for near-field exposure pathways of chemicals in consumer products. Sci. Total Environ. 2017, 574, 1182–1208. [Google Scholar] [CrossRef] [Green Version]
- Dionisio, K.L.; Frame, A.M.; Goldsmith, M.-R.; Wambaugh, J.F.; Liddell, A.; Cathey, T.; Fantke, P. Exploring consumer exposure pathways and patterns of use for chemicals in the environment. Toxicol. Rep. 2015, 2, 228–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Washington, A.L. The Interoperability of US Federal Government Information: Interoperability. In Big Data: Concepts, Methodologies, Tools, and Applications; IGI Global: Fairfax, VI, USA, 2016; pp. 210–228. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2009; Available online: https://www.R-project.org/ (accessed on 10 November 2021).
- East, A.; Price, P.; Dawson, D.; Dionisio, K.; Isaacs, K.; Hubal, E.A.C.; Vallero, D. The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk. Available online: https://cfpub.epa.gov/si/si_public_record_Report.cfm?dirEntryId=350496&Lab=CCTE (accessed on 30 December 2020).
- US Energy Information Administration. RECS (Residential Energy Consumption Survey). 2015. Available online: https://www.eia.gov/consumption/residential/reports.php (accessed on 10 November 2021).
- US Census Bureau. American Housing Survey Technical Documentatation. 2019. Available online: https://www.census.gov/programs-surveys/ahs/tech-documentation.html (accessed on 10 November 2021).
- US Census Bureau. Public Use Microdata Sample (PUMS). 2020. Available online: https://www.census.gov/programs-surveys/acs/microdata.html (accessed on 10 November 2021).
- Pearce, R.G.; Setzer, R.W.; Strope, C.L.; Wambaugh, J.F.; Sipes, N.S. Httk: R package for high-throughput toxicokinetics. J. Stat. Softw. 2017, 79, 1. [Google Scholar] [CrossRef] [Green Version]
- Wambaugh, J. High-Throughput Toxicokinetics (HTTK) R Package. In Proceedings of the Computational Toxicology Community of Practice Webinar, Durham, NC, USA, 27 June 2019. [Google Scholar]
- Office of Management and Budget. Standards for Metropolitan and Micropolitan Statistical Areas. 2010. Available online: https://www.federalregister.gov/documents/2010/06/28/2010-15605/2010-standards-for-delineating-metropolitan-and-micropolitan-statistical-areas (accessed on 1 October 2021).
- Graham, S.E.; Langstaff, J.; Hader, J.D.; Glen, G.; Levasseur, J. Estimating Fine-Scale Temporal and Spatial Characteristics of SO2 Exposures Using US EPA’s Air Pollutants Exposure (APEX) Model. In Proceedings of the ISEE Conference Abstracts, Ottawa, ON, Canada, 26–30 August 2018. [Google Scholar]
- Ring, C.L.; Pearce, R.G.; Setzer, R.W.; Wetmore, B.A.; Wambaugh, J.F. Identifying populations sensitive to environmental chemicals by simulating toxicokinetic variability. Environ. Int. 2017, 106, 105–118. [Google Scholar] [CrossRef]
- Isaacs, K. SHEDS-HT (Version v0.1.8): GitHub. 2019. Available online: https://github.com/HumanExposure/SHEDSHTRPackage/releases/tag/v0.1.8 (accessed on 10 November 2021).
- Breen, M.S.; Schultz, B.D.; Sohn, M.D.; Long, T.; Langstaff, J.; Williams, R.; Smith, L. A review of air exchange rate models for air pollution exposure assessments. J. Expo. Sci. Environ. Epidemiol. 2014, 24, 555–563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Egeghy, P.P.; Hubal, E.A.C.; Tulve, N.S.; Melnyk, L.J.; Morgan, M.K.; Fortmann, R.C.; Sheldon, L.S. Review of pesticide urinary biomarker measurements from selected US EPA children’s observational exposure studies. Int. J. Environ. Res. Public Health 2011, 8, 1727–1754. [Google Scholar] [CrossRef] [PubMed]
- US Environmental Protection Agency. ExpoBox: A Toolbox for Exposure Assessors 2019. Available online: https://www.epa.gov/expobox (accessed on 10 November 2021).
- Congressional Budget Office, The Distribution of Household Income. 2014. Available online: https://www.cbo.gov/publication/53597 (accessed on 10 November 2021).
- Sheldon, L.S.; Cohen Hubal, E.A. Exposure as part of a systems approach for assessing risk. Environ. Health Perspect. 2009, 117, 1181–1194. [Google Scholar] [CrossRef] [PubMed]
- Egeghy, P.P.; Sheldon, L.S.; Isaacs, K.K.; Özkaynak, H.; Goldsmith, M.-R.; Wambaugh, J.F.; Buckley, T.J. Computational exposure science: An emerging discipline to support 21st-century risk assessment. Environ. Health Perspect. 2016, 124, 697–702. [Google Scholar] [CrossRef] [Green Version]
- McNally, K.; Cotton, R.; Hogg, A.; Loizou, G. PopGen: A virtual human population generator. Toxicology 2014, 315, 70–85. [Google Scholar] [CrossRef]
- Grefenstette, J.J.; Brown, S.T.; Rosenfeld, R.; DePasse, J.; Stone, N.T.; Cooley, P.C.; Sriram, A. FRED (A Framework for Reconstructing Epidemic Dynamics): An open-source software system for modeling infectious diseases and control strategies using census-based populations. BMC Public Health 2013, 13, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Meng, H.; Zhang, X.; Xiao, J.; Zhang, Y.; Lin, W.; Li, Z. A simple physical-activity-based model for managing children’s activities against exposure to air pollutants. J. Environ. Manag. 2021, 279, 111823. [Google Scholar] [CrossRef]
- Teeguarden, J.G.; Tan, Y.-M.; Edwards, S.W.; Leonard, J.A.; Anderson, K.A.; Corley, R.A.; Tanguay, R.L. Completing the Link between Exposure Science and Toxicology for Improved Environmental Health Decision Making: The Aggregate Exposure Pathway Framework; ACS Publications: Washington, DC, USA, 2016. [Google Scholar]
- Cohen Hubal, E.A.; Richard, A.; Aylward, L.; Edwards, S.; Gallagher, J.; Goldsmith, M.-R.; Kavlock, R. Advancing exposure characterization for chemical evaluation and risk assessment. J. Toxicol. Environ. Health Part B 2010, 13, 299–313. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Class | Input Parameters | Default |
|---|---|---|---|
| Run.name | Character | Name of output folder containing pophouse.csv | User input required |
| Num.persons | Numeric | Number of individuals (rows) in output | User input required |
| Min.age | Numeric | Number from 0 to 99 | 0 |
| Max.age | Numeric | Number from 0 to 99 | 99 |
| Gender | Character | M = Male F = Female | MF |
| Ethnicity | Comma separated characters | N = non-Hispanic, M = Mexican-American, O = Other | NMO |
| Regions | Comma separated numerics | 1 = West, 2 = Mid-West, 3 = South, 4 = North West | 1234 |
| Race | Comma separated numerics | W = White, B = African American, N = Native American, A = Asian American, P = Pacific Islander, O = Other or Mixed | WBNAPO |
| States | Comma seperated numerics | FIPS Codes in RPGen User Guide (Available in GitHub repository) | All contiguous US Codes within specified regions. |
| Survey | Source | Date of Data Collection | Number of Records |
|---|---|---|---|
| Residential Energy Consumption Survey (RECS) | US Energy Information Association: https://www.eia.gov/consumption/residential/data/2015/ | 2015 | 5686 |
| American Housing Survey (AHS) | US Census Bureau: https://www.census.gov/programs-surveys/ahs/data.html | 2017 | 57,972 |
| Public Use Microdata Survey (PUMS) | US Census Bureau: https://www.census.gov/programs-surveys/acs/data/pums.html | 2014–2018 | 15,094,428 |
| National Health and Nutrition Examination Survey (NHANES) | US CDC: https://wwwn.cdc.gov/nchs/nhanes/Default.aspx | 2007–2008, 2009–2010, 2011–2012 | 24,546 |
| Setting | Region | House Type | Family Category | Income Category |
|---|---|---|---|---|
| Urban | Northeast | Stand Alone | 1 Adult, 0 Children | 1 |
| Rural | Midwest | Multi Structure | 2+ Adults, 0 Children | 2 |
| South | Other | 1 Adult, 1+ Children | 3 | |
| West | 2+ Adults, 1+ Children |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
East, A.; Dawson, D.; Glen, G.; Isaacs, K.; Dionisio, K.; Price, P.S.; Hubal, E.A.C.; Vallero, D.A. The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk. Toxics 2021, 9, 303. https://doi.org/10.3390/toxics9110303
East A, Dawson D, Glen G, Isaacs K, Dionisio K, Price PS, Hubal EAC, Vallero DA. The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk. Toxics. 2021; 9(11):303. https://doi.org/10.3390/toxics9110303
Chicago/Turabian StyleEast, Alexander, Daniel Dawson, Graham Glen, Kristin Isaacs, Kathie Dionisio, Paul S. Price, Elaine A. Cohen Hubal, and Daniel A. Vallero. 2021. "The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk" Toxics 9, no. 11: 303. https://doi.org/10.3390/toxics9110303
APA StyleEast, A., Dawson, D., Glen, G., Isaacs, K., Dionisio, K., Price, P. S., Hubal, E. A. C., & Vallero, D. A. (2021). The Residential Population Generator (RPGen): Parameterization of Residential, Demographic, and Physiological Data to Model Intraindividual Exposure, Dose, and Risk. Toxics, 9(11), 303. https://doi.org/10.3390/toxics9110303