
Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset



Abstract
:1. Introduction
2. Review of Related Works
2.1. Methods of Transfer Learning
- Self-tuning transfer learning [16]: this method combines semi-supervised learning (SSL) with transfer learning. The SSL creates a pseudo-labeled dataset by exploring the latent structure of an unlabeled dataset which is then used to fine-tune the base model. The self-tuning transfer learning (STTL) algorithm enables a joint exploration of labeled and unlabeled datasets to create a larger dataset for transfer learning of a pretrained base model. However, since a model is as good as its labeled data, this method could introduce inaccurately labeled data into the dataset, which significantly limits its use in a medical scenario.
- Adversarial fine-tuning [17]: this method provides a fine-tuning technique for adversarial training (AT). AT introduces adversarial attacks into deep learning data, making the model robust to noise. However, training AT from scratch (just like any other deep learning method) incurs a high computational cost and, when using few data, could result in extreme overfitting. Adversarial fine-tuning (AFT) presents a transfer learning method in AT by optimizing the learning rate. Using a slow to fast learning rate scheduling during AT [17] demonstrates a significant reduction in computational cost and improved model accuracy. This method was applied to skin cancer detection in [18] to achieve an improved sensitivity of +5.67% but a slight improvement (+0.78%) in accuracy compared to other methods [18].
- Intra fine-tuning [19]: while transfer learning can be achieved regardless of the problem domain of the base model, the intra fine-tuning (IFT) method is applied in a non-distance dataset, i.e., intra-domain. Compared to a transfer learning from ImageNet, IFT showed a significant reduction in computational time but no improvement in training and validation accuracy [19].
- Image-specific fine-tuning [20]: this method provides image-specific adaptation to unseen object classes, i.e., zero-shot learning for image segmentation. Like STTL, this method also explores both supervised and unsupervised labeling approaches for image bounding boxes. Moreover, it uses a weighted loss function for interaction-based uncertainty in the fine-tuning process to limit the effect of the inaccurate label.
- Learning to Reweight [21]: this method uses meta-learning to reassign weights to the deep learning model on the basis of the direction of their gradient flow. A meta gradient descent step was performed on each mini-batch example to minimize the loss and validated on the validation set. The authors claimed that the method needs no additional hyperparameter tuning and is robust to class imbalance. Although this method has not been applied to computer vision, it reportedly achieved a boost improvement in natural language processing.
2.2. Mammogram Classification Using Transfer Learning
3. Materials and Methods
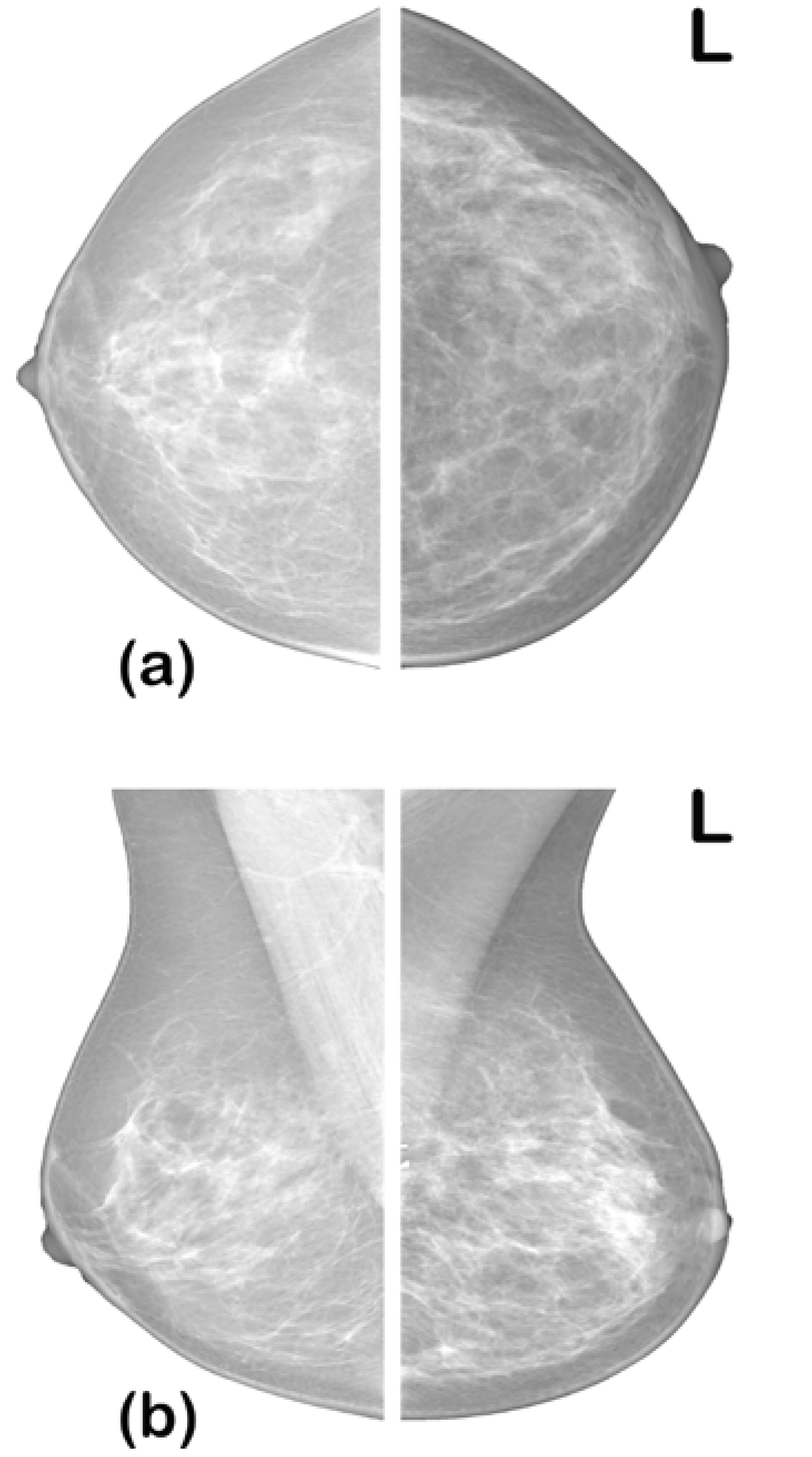
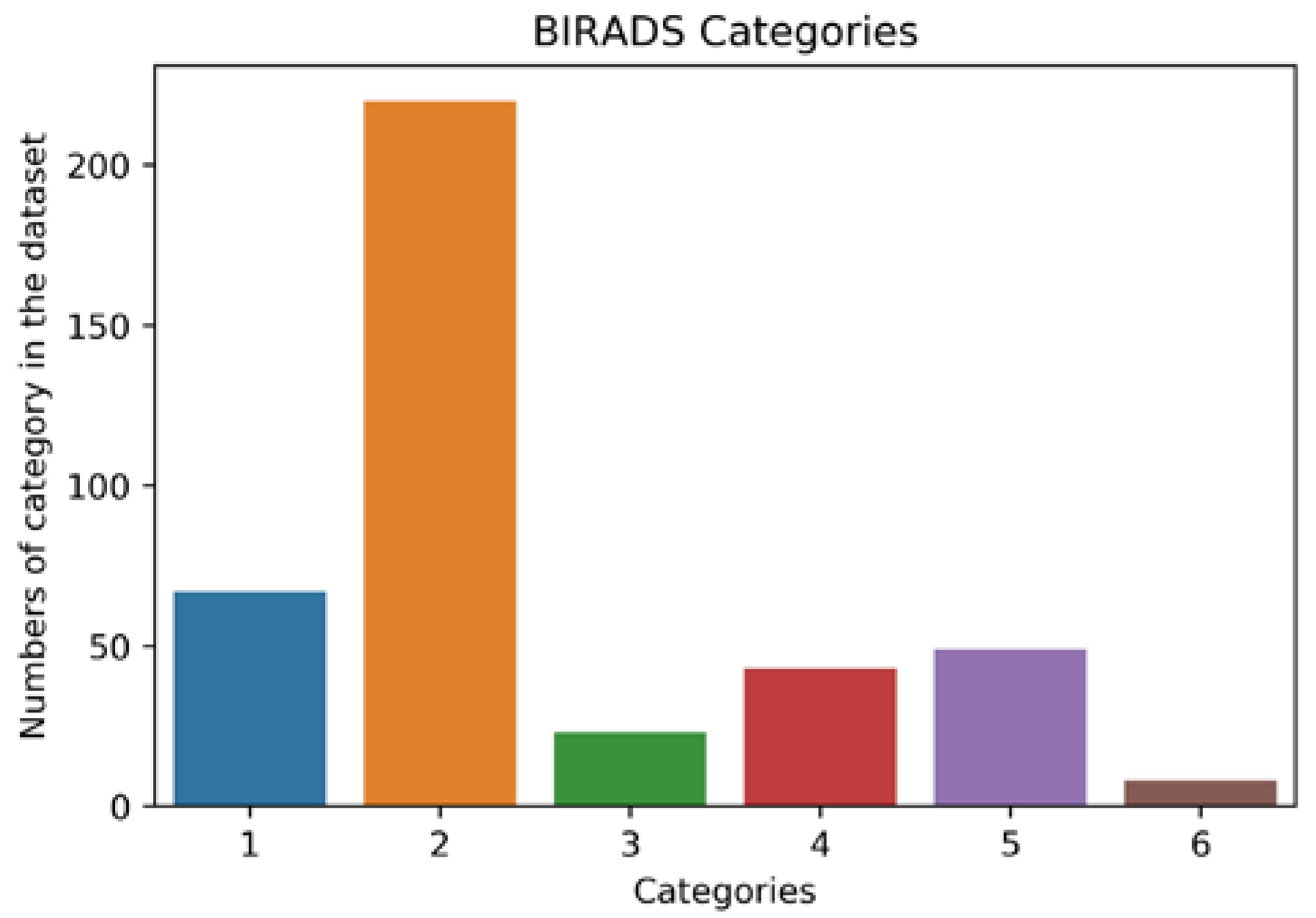
3.1. Dataset
3.2. Data Augmentation
| Pseudocode 1: Data augmentation algorithm. | |
| Input: Dataset, list of augmentation transformations) | |
| Output: Augmented Dataset | |
| Step 1: | Randomly select an image from |
| Step 2: | Randomly select an augmentation transformation from |
| Step 3: | Randomly select the parameter for |
| Step 4: | Apply the augmentation transformation on the image using the parameter |
| Step 5: | Save the image in the augmented dataset |
3.3. CNN Model Architecture
3.4. Discriminative Fine-Tuning and Mixed-Precision Training
Discriminative Learning Rate
| Algorithm 1: Discriminative fine-tuning algorithm. | ||||||
| 1: | Procedure DFT | |||||
| 2: | Input: | minimum learning rate, : maximum learning rate, : minimum momentum, : maximum momentum, : size of dataset, batch_size) | ||||
| 3: | Output: | Network parameters) | ||||
| 4: | ||||||
| 5: | //κ determines how rapidly the learning rate increase or reduces | |||||
| while | ||||||
| 6: | for in each iteration do: | |||||
| 7: | for in each layer do: | |||||
| 8: | //increase learning rate per layer | |||||
| 9: | //increasing the momentum per layer | |||||
| 10: | ||||||
| 11: | //update the layer parameters | |||||
| 12: | end for | |||||
| 13. | end for | |||||
| 14. | end while | |||||
| 15. | while | |||||
| 16. | for t in each iteration do: | |||||
| 17. | for in each layer do: | |||||
| 18. | //increase learning rate per layer | |||||
| 19. | //increasing the momentum per layer | |||||
| 20. | ||||||
| 21. | //update the layer parameters | |||||
| 22. | end for | |||||
| 23. | end for | |||||
| 24. | end while | |||||
| 25. | end Procedure | |||||
3.5. Experiment Setup
4. Results
5. Discussion of Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berrino, F.; Lutz, J.; de Angelis, R.; Rachet, B.; Gatta, G. Cancer survival in five continents: A worldwide population-based study (concord). Lancet Oncol. 2008, 9, 730–756. [Google Scholar]
- Ly, D.; Forman, D.; Ferlay, J.; Brinton, L.A.; Cook, M.B. An international comparison of male and female breast cancer incidence rates. Int. J. Cancer 2013, 132, 1918–1926. [Google Scholar] [CrossRef] [Green Version]
- Adedigba, A.P.; Adeshina, S.A.; Aibinu, A.M. Deep learning-based mammogram classification using small dataset. In Proceedings of the 2019 15th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 10–12 December 2019; pp. 1–6. [Google Scholar]
- Hela, B.; Hela, M.; Kamel, H.; Sana, B.; Najla, M. Breast cancer detection: A review on mammograms analysis techniques. In Proceedings of the 10th International Multi-Conferences on Systems, Signals & Devices 2013 (SSD13), Hammamet, Tunisia, 18–21 March 2013; pp. 1–6. [Google Scholar]
- Dheeba, J.; Singh, N.A.; Selvi, S.T. Computer-aided detection of breast cancer on mammograms: A swarm intelligence optimized wavelet neural network approach. J. Biomed. Inform. 2014, 49, 45–52. [Google Scholar] [CrossRef] [PubMed]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. Inbreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dhungel, N.; Carneiro, G.; Bradley, A.P. Automated mass detection in mammograms using cascaded deep learning and random forests. In Proceedings of the 2015 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Adelaide, SA, Australia, 23–25 November 2015; pp. 1–8. [Google Scholar]
- Zhou, Z.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J. Fine-tuning convolutional neural networks for biomedical image analysis: Actively and incrementally. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7340–7351. [Google Scholar]
- Selvi, C.; Suganthi, M. A novel enhanced gray scale adaptive method for prediction of breast cancer. J. Med. Syst. 2018, 42, 221. [Google Scholar] [CrossRef]
- Adeshina, S.A.; Adedigba, A.P.; Adeniyi, A.A.; Aibinu, A.M. Breast cancer histopathology image classification with deep convolutional neural networks. In Proceedings of the 2018 14th International Conference on Electronics Computer and Computation (ICECCO), Kaskelen, Kazakhstan, 29 November–1 December 2018; pp. 206–212. [Google Scholar]
- Lotter, W.; Sorensen, G.; Cox, D. A multi-scale CNN and curriculum learning strategy for mammogram classification. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 169–177. [Google Scholar]
- Zhang, R.; Zhang, H.; Chung, A.C. A unified mammogram analysis method via hybrid deep supervision. In Image Analysis for Moving Organ, Breast, and Thoracic Image; Springer: Cham, Switzerland, 2018; pp. 107–115. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Wang, X.; Gao, J.; Long, M.; Wang, J. Self-tuning for data-efficient deep learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10738–10748. [Google Scholar]
- Jeddi, A.; Shafiee, M.J.; Wong, A. A simple fine-tuning is all you need: Towards robust deep learning via adversarial fine-tuning. arXiv 2020, arXiv:2012.13628. [Google Scholar]
- Zunair, H.; Hamza, A.B. Melanoma detection using adversarial training and deep transfer learning. Phys. Med. Biol. 2020, 65, 135005. [Google Scholar] [CrossRef]
- Dif, N.; Elberrichi, Z. A new intra fine-tuning method between histopathological datasets in deep learning. Int. J. Serv. Sci. Manag. Eng. Technol. 2020, 11, 16–40. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Vercauteren, T. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to reweight examples for robust deep learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4334–4343. [Google Scholar]
- Xi, P.; Shu, C.; Goubran, R. Abnormality detection in mammography using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rome, Italy, 11–13 June 2018; pp. 1–6. [Google Scholar]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.; Han, E.Y.; Jacobs, N.; Han, Q.; Wang, X.; Liu, J. Classification of whole mammogram and tomosynthesis images using deep convolutional neural networks. IEEE Trans. Nanobiosci. 2018, 17, 237–242. [Google Scholar] [CrossRef]
- Tsochatzidis, L.; Lena, C.; Ioannis, P. Deep learning for breast cancer diagnosis from mammograms—A comparative study. J. Imaging 2019, 5, 37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Feng, Y.; Zhang, L.; Wang, Z.; Lv, Q.; Yi, Z. Deep adversarial domain adaptation for breast cancer screening from mammograms. Med. Image Anal. 2021, 73, 102147. [Google Scholar] [CrossRef] [PubMed]
- Jabeen, K.; Muhammad, A.K.; Majed, A.; Usman, T.; Yu-Dong, Z.; Ameer, H.; Artūras, M.; Robertas, D. Breast Cancer Classification from Ultrasound Images Using Probability-Based Optimal Deep Learning Feature Fusion. Sensors 2022, 22, 807. [Google Scholar] [CrossRef] [PubMed]
- Zebari, D.A.; Dheyaa, A.B.; Diyar, Q.Z.; Mazin, A.M.; Habibollah, H.; Nechirvan, A.Z.; Robertas, D.; Rytis, M. Breast Cancer Detection Using Mammogram Images with Improved Multi-Fractal Dimension Approach and Feature Fusion. Appl. Sci. 2021, 11, 12122. [Google Scholar] [CrossRef]
- Adedigba, A.P.; Adeshina, S.A.; Aina, O.E.; Aibinu, A.M. Optimal hyperparameter selection of deep learning models for COVID-19 chest X-ray classification. Intell.-Based Med. 2021, 5, 100034. [Google Scholar] [CrossRef]
- Milanfar, P. A tour of modern image filtering: New insights and methods, both practical and theoretical. IEEE Signal Process. Mag. 2012, 30, 106–128. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50× fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.J.; Bulatov, Y.; Ibarz, J.; Arnoud, S.; Shet, V. Multi-digit number recognition from street view imagery using deep convolutional neural networks. arXiv 2013, arXiv:1312.6082. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Adeshina, S.A.; Adedigba, A.P. Automatic Prognosis of COVID-19 from CT Scan using Super-convergence CNN Algorithm. In Proceedings of the 2021 1st International Conference on Multidisciplinary Engineering and Applied Science (ICMEAS), Abuja, Nigeria, 15–16 July 2021; pp. 1–6. [Google Scholar]
- Adedigba, A.P.; Adeshina, S.A. Deep Learning-based Classification of COVID-19 Lung Ultrasound for Tele-operative Robot-assisted diagnosis. In Proceedings of the 2021 1st International Conference on Multidisciplinary Engineering and Applied Science (ICMEAS), Abuja, Nigeria, 15–16 July 2021; pp. 12–18. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed precision training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Aina, O.E.; Adeshina, S.A.; Adedigba, A.P.; Aibinu, A.M. Classification of Cervical Intraepithelial Neoplasia (CIN) using fine-tuned convolutional neural networks. Intell.-Based Med. 2021, 5, 100031. [Google Scholar] [CrossRef]
- Shi, P.; Wu, C.; Zhong, J.; Wang, H. Deep learning from small dataset for BI-RADS density classification of mammography images. In Proceedings of the 2019 10th International Conference on Information Technology in Medicine and Education (ITME), Qingdao, China, 23–25 August 2019; pp. 102–109. [Google Scholar]
- Carneiro, G.; Nascimento, J.; Bradley, A.P. Automated analysis of unregistered multi-view mammograms with deep learning. IEEE Trans. Med. Imaging 2017, 36, 2355–2365. [Google Scholar] [CrossRef]
- Al-Antari, M.A.; Han, S.M.; Kim, T.S. Evaluation of deep learning detection and classification towards computer-aided diagnosis of breast lesions in digital X-ray mammograms. Comput. Methods Programs Biomed. 2020, 196, 105584. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Diagnosis | Description |
|---|---|---|
| 0 | No findings | The mammogram does not provide sufficient information or findings are inconclusive. Follow-up examination may be recommended. |
| 1 | Negative | No BC traces or findings, although routine screening is recommended. |
| 2 | Benign | Confirmation of benign finding; routine screening is recommended. |
| 3 | Probably benign | Findings that have high probability (>0.98) of being benign; 6 month interval follow-up is recommended. |
| 4 | Suspicious abnormality | Probable (0.3–0.94) malignant growth; a biopsy is recommended. |
| 5 | Highly suspicious of malignancy | Abnormal growth that has high probability (≥0.95) of being malignant; doctor’s decision should be sought. |
| 6 | Proven cancer | Biopsy-confirmed malignant growth. |
| Reference | Method | Dataset | Limitations |
|---|---|---|---|
| [22], 2018 | Traditional feature extraction | CBIS-DDSM | High computational demand and long training episode (8 h) |
| [23], 2019 | Gradual fine-tuning with episodes of learning rate annealing schedules | CBIS-DDSM | High computational demand and long training episode (99 epochs) |
| [24], 2018 | Traditional fine-tuning | CBIS-DDSM | High computational demand, low AUC, and overfitting |
| [25], 2019 | Traditional fine-tuning | CBIS-DDSM | High computational demand, low AUC, and overfitting |
| [26], 2021 | Deep adversarial domain adaptation | CBIS-DDSM | Complex algorithm with high computational demand and long training episode (400 epochs) |
| [27], 2022 | Feature extraction plus feature selection using twin algorithms: reformed differential evaluation and reformed gray wolf algorithm. | Breast ultrasound images | Long training episodes and additional computation burden introduced by feature selection algorithms |
| [28], 2021 | Multifractal dimension feature extraction, feature reduction using GA, and classification using ANN | DDSMMini-MIASINBreastbreast cancer digital repository | Not end-to-end trained; each algorithm introduced computational bottlenecks that aggregated to high computational demandNot compatible with SOTA CNN models |
| Model Name | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|
| AlexNet | 98.88 | 98.84 | 98.82 |
| SqueezeNet | 97.19 | 97.16 | 97.04 |
| VGG | 99.28 | 99.3 | 99.15 |
| ResNet | 99.5 | 99.7 | 99.5 |
| DenseNet | 99.8 | 99.82 | 99.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adedigba, A.P.; Adeshina, S.A.; Aibinu, A.M. Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset. Bioengineering 2022, 9, 161. https://doi.org/10.3390/bioengineering9040161
Adedigba AP, Adeshina SA, Aibinu AM. Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset. Bioengineering. 2022; 9(4):161. https://doi.org/10.3390/bioengineering9040161
Chicago/Turabian StyleAdedigba, Adeyinka P., Steve A. Adeshina, and Abiodun M. Aibinu. 2022. "Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset" Bioengineering 9, no. 4: 161. https://doi.org/10.3390/bioengineering9040161
APA StyleAdedigba, A. P., Adeshina, S. A., & Aibinu, A. M. (2022). Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset. Bioengineering, 9(4), 161. https://doi.org/10.3390/bioengineering9040161