
Systematic Identification and Functional Validation of New snoRNAs in Human Muscle Progenitors



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results
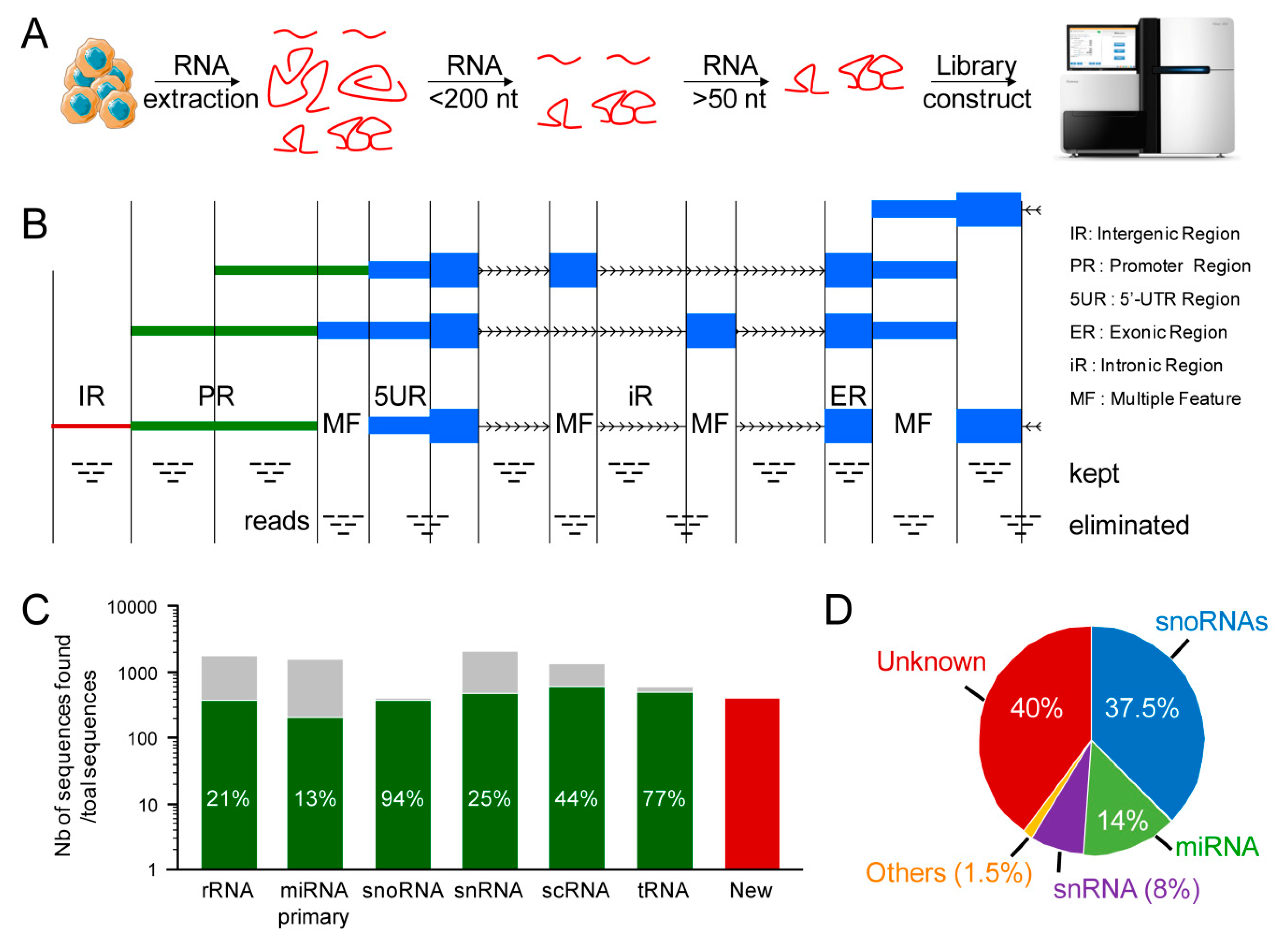
2.1. Discovery of New Unannotated Small Non-Coding RNAs in Human Muscle Cells
2.2. The Vast Majority of Newly Identified snoRNAs Are Genuine snoRNAs
2.2.1. snoRNA Candidates and Their Corresponding Host Genes Are Co-Expressed without Significant Correlation of Their Respective Levels
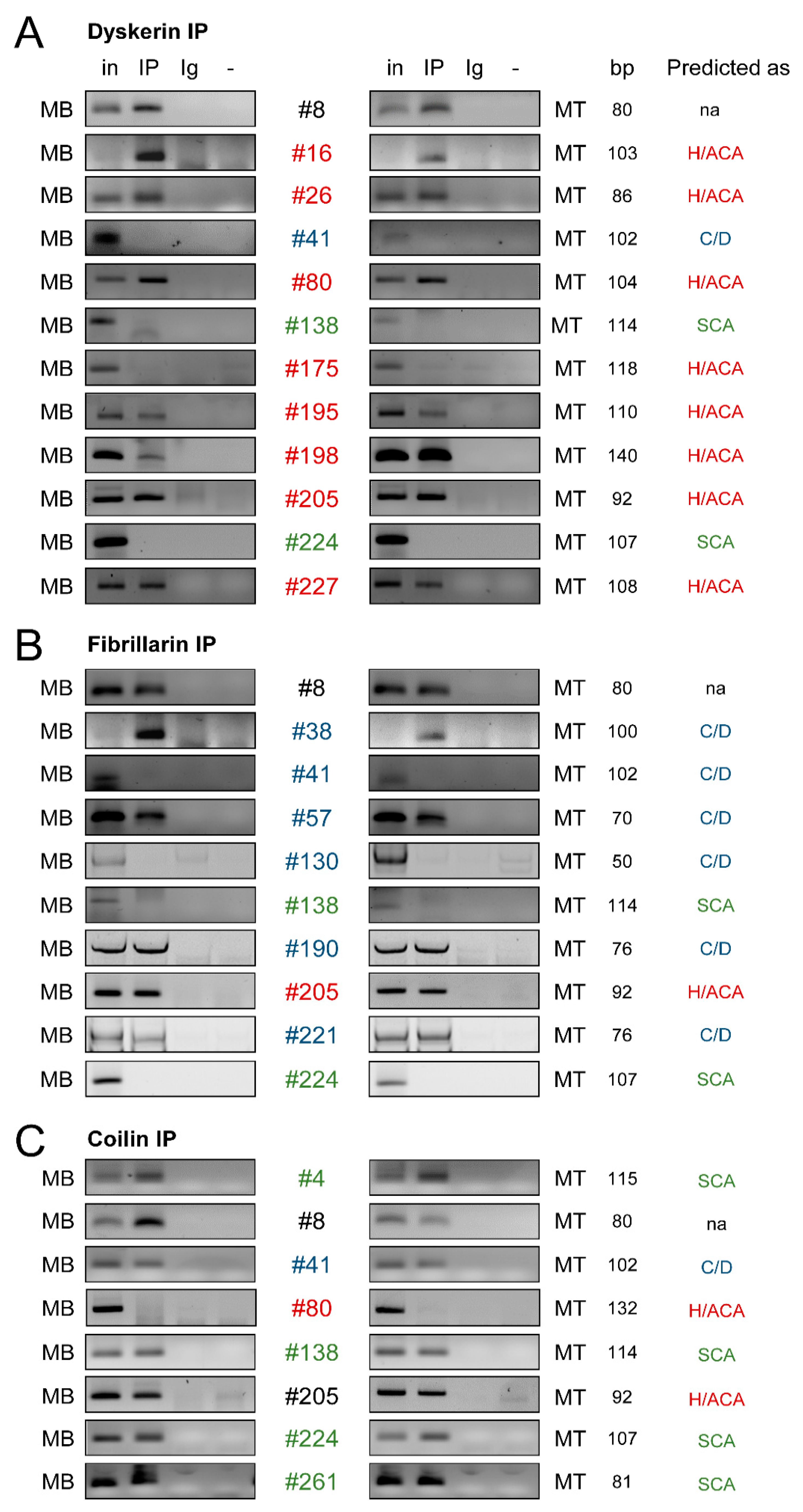
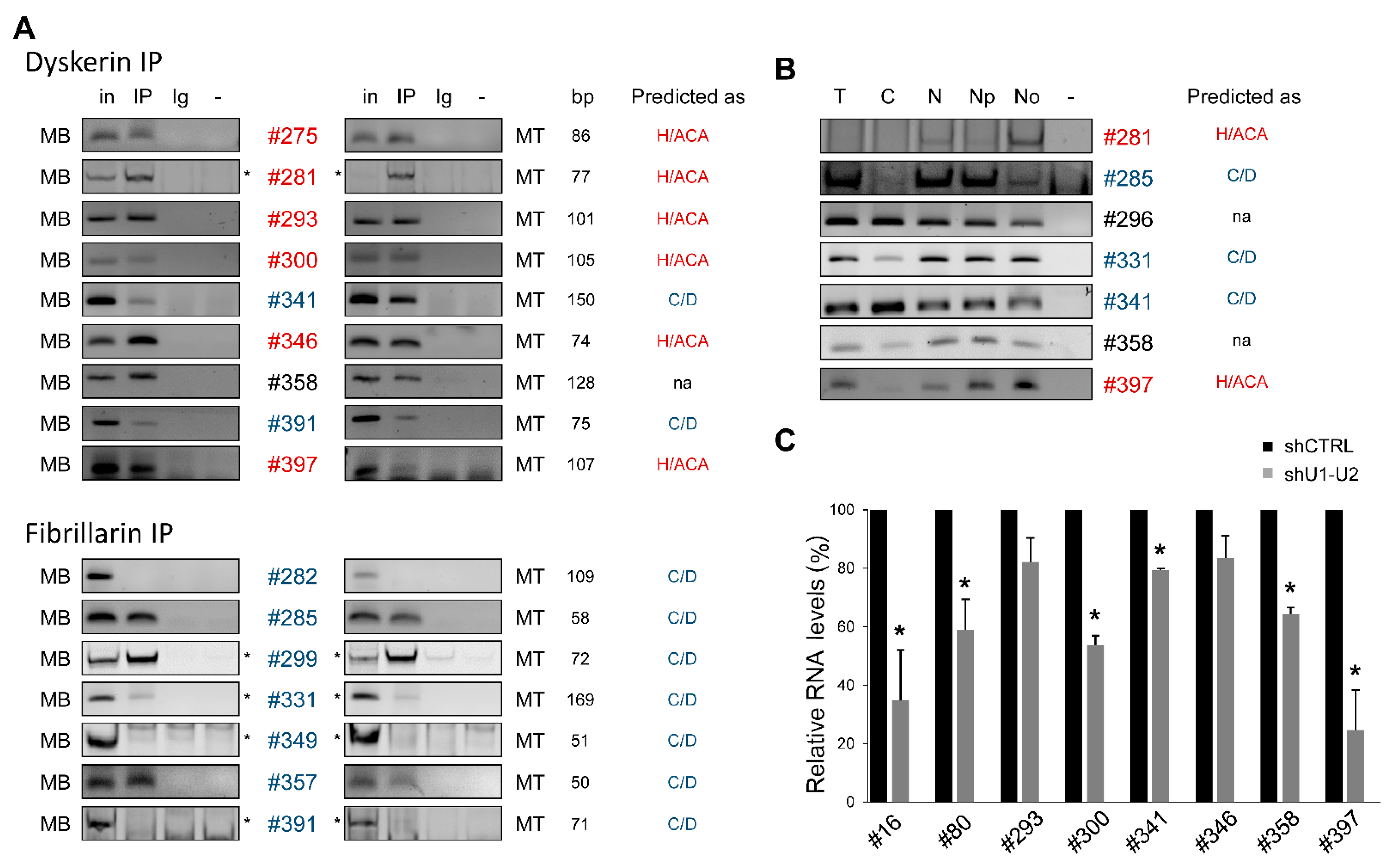
2.2.2. Most of the snoRNA Candidates Associate with Core Proteins of snoRNP Complexes
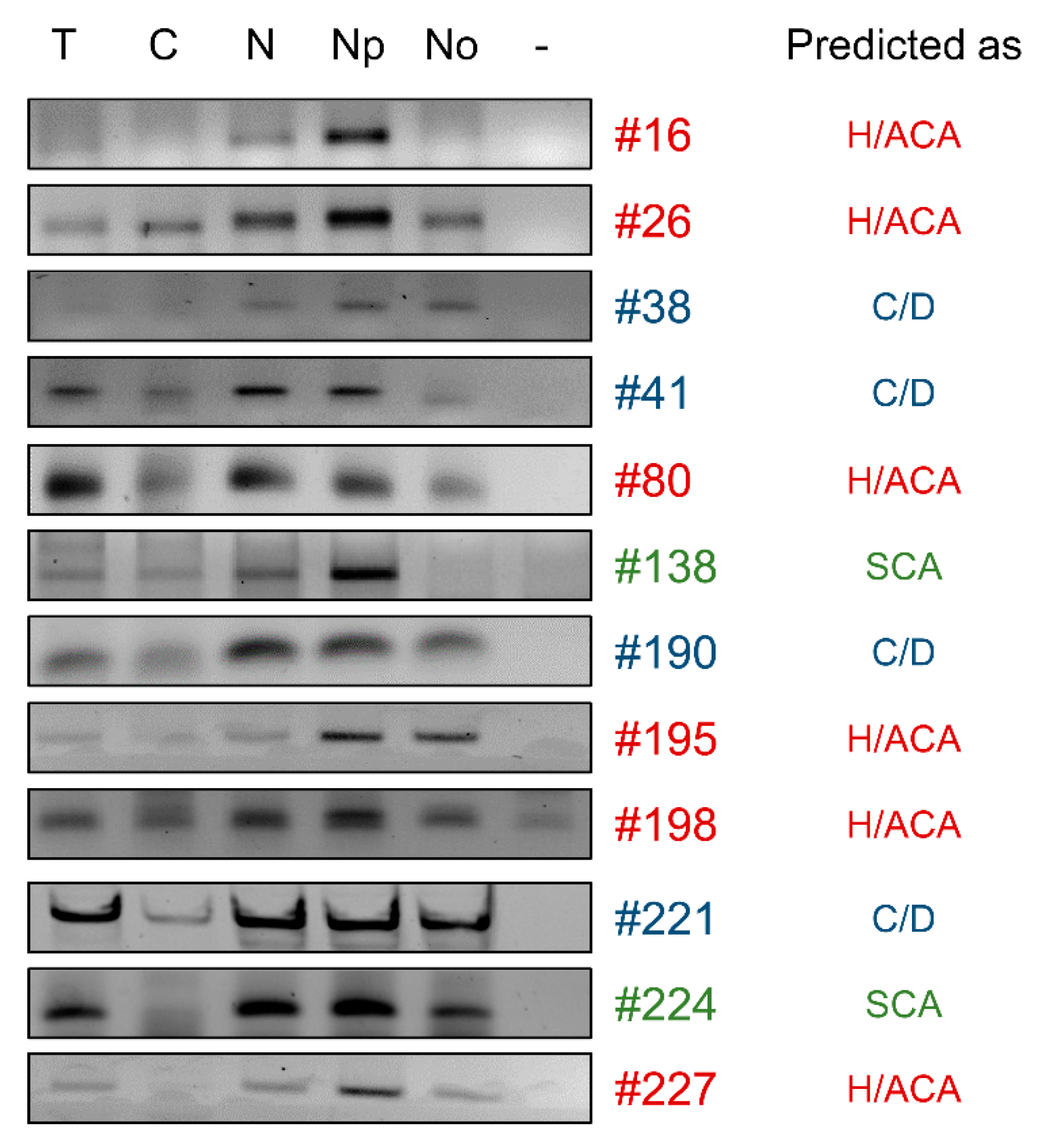
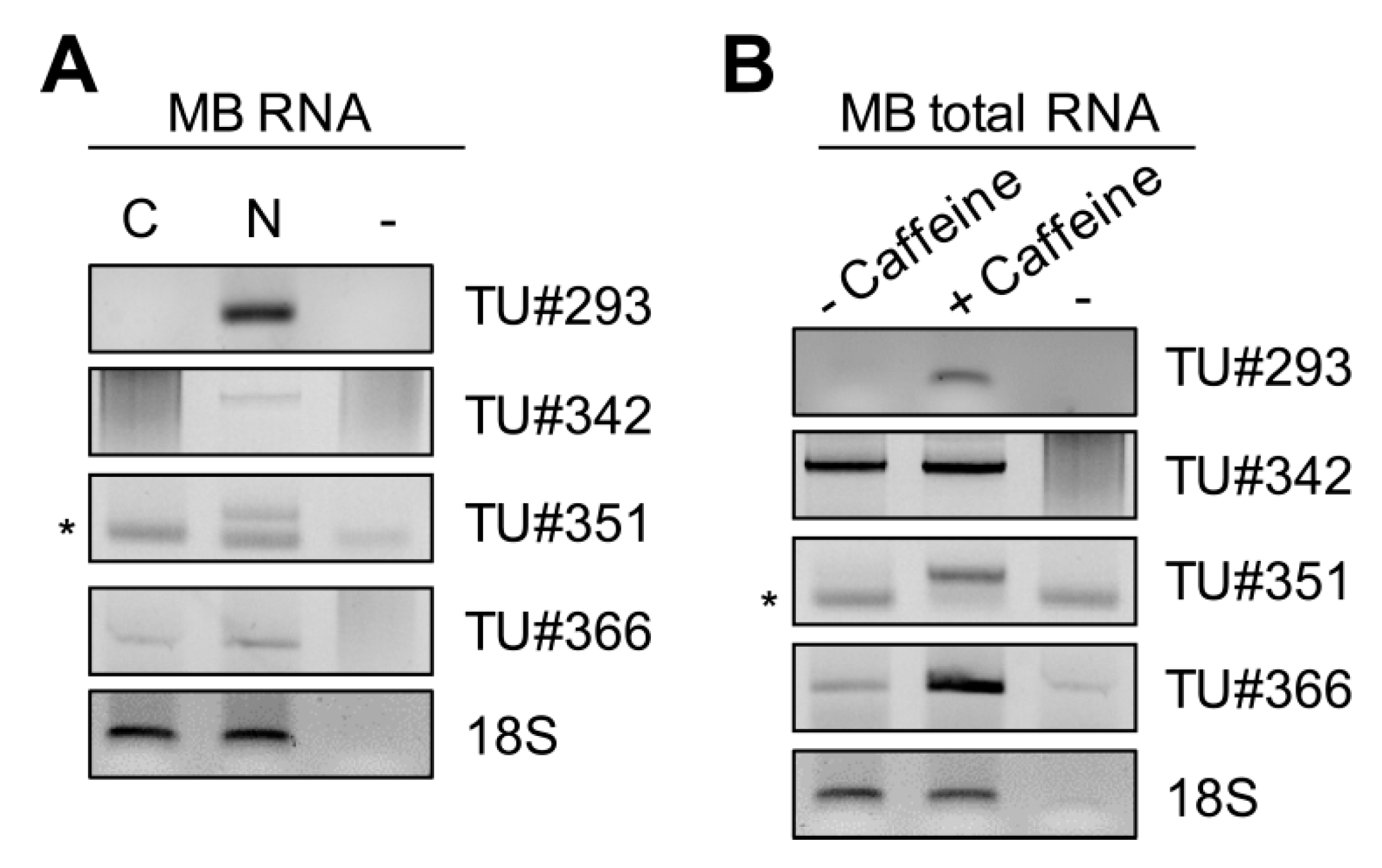
2.2.3. The Majority of snoRNA Candidates Accumulate in Nucleoli
2.2.4. Intergenic snoRNAs as a Hallmark of Yet Unannotated Transcriptional Units
3. Discussion
4. Materials and Methods
4.1. Cell Culture
4.2. RNA-Seq Protocols
4.3. Antibodies
4.4. RNA Preparation
4.5. RT-PCR
4.6. RNA and Protein Immunoprecipitation
4.7. Nucleoli Isolation
4.8. Immunofluorescence Staining on Isolated Nucleoli
4.9. Plasmids and Constructs
4.10. Transfection Experiments
4.11. Inhibition of the Transcription
4.12. Inhibition of the Non-Sense Mediated (NMD) Pathway
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ENCODE Project Consortium. An Integrated Encyclopedia of DNA Elements in the Human Genome. Nature 2012, 489, 57–74. [Google Scholar] [CrossRef]
- Amaral, P.P.; Dinger, M.E.; Mercer, T.R.; Mattick, J.S. The Eukaryotic Genome as an RNA Machine. Science 2008, 319, 1787–1789. [Google Scholar] [CrossRef]
- Hombach, S.; Kretz, M. Non-Coding RNAs: Classification, Biology and Functioning. Adv. Exp. Med. Biol. 2016, 937, 3–17. [Google Scholar] [CrossRef] [PubMed]
- Cech, T.R.; Steitz, J.A. The Noncoding RNA Revolution-Trashing Old Rules to Forge New Ones. Cell 2014, 157, 77–94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubé, F.; Ulveling, D.; Sureau, A.; Forveille, S.; Francastel, C. Short Intron-Derived NcRNAs. Nucleic Acids Res. 2017, 45, 4768–4781. [Google Scholar] [CrossRef] [Green Version]
- Hubé, F.; Francastel, C. Mammalian Introns: When the Junk Generates Molecular Diversity. Int. J. Mol. Sci. 2015, 16, 4429–4452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubé, F.; Velasco, G.; Rollin, J.; Furling, D.; Francastel, C. Steroid Receptor RNA Activator Protein Binds to and Counteracts SRA RNA-Mediated Activation of MyoD and Muscle Differentiation. Nucleic Acids Res. 2011, 39, 513–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubé, F.; Guo, J.; Chooniedass-Kothari, S.; Cooper, C.; Hamedani, M.K.; Dibrov, A.A.; Blanchard, A.A.A.; Wang, X.; Deng, G.; Myal, Y.; et al. Alternative Splicing of the First Intron of the Steroid Receptor RNA Activator (SRA) Participates in the Generation of Coding and Noncoding RNA Isoforms in Breast Cancer Cell Lines. DNA Cell Biol. 2006, 25, 418–428. [Google Scholar] [CrossRef]
- Ulveling, D.; Francastel, C.; Hubé, F. Identification of Potentially New Bifunctional RNA Based on Genome-Wide Data-Mining of Alternative Splicing Events. Biochimie 2011, 93, 2024–2027. [Google Scholar] [CrossRef]
- Wong, J.J.-L.; Ritchie, W.; Ebner, O.A.; Selbach, M.; Wong, J.W.H.; Huang, Y.; Gao, D.; Pinello, N.; Gonzalez, M.; Baidya, K.; et al. Orchestrated Intron Retention Regulates Normal Granulocyte Differentiation. Cell 2013, 154, 583–595. [Google Scholar] [CrossRef] [Green Version]
- St Laurent, G.; Shtokalo, D.; Tackett, M.R.; Yang, Z.; Eremina, T.; Wahlestedt, C.; Urcuqui-Inchima, S.; Seilheimer, B.; McCaffrey, T.A.; Kapranov, P. Intronic RNAs Constitute the Major Fraction of the Non-Coding RNA in Mammalian Cells. BMC Genom. 2012, 13, 504. [Google Scholar] [CrossRef] [Green Version]
- López-Martínez, A.; Soblechero-Martín, P.; de-la-Puente-Ovejero, L.; Nogales-Gadea, G.; Arechavala-Gomeza, V. An Overview of Alternative Splicing Defects Implicated in Myotonic Dystrophy Type I. Genes 2020, 11, 1109. [Google Scholar] [CrossRef]
- Hare, M.P.; Palumbi, S.R. High Intron Sequence Conservation across Three Mammalian Orders Suggests Functional Constraints. Mol. Biol. Evol. 2003, 20, 969–978. [Google Scholar] [CrossRef]
- Mattick, J.S.; Makunin, I.V. Small Regulatory RNAs in Mammals. Hum. Mol. Genet. 2005, 14 (Suppl. S1), R121–R132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kiss, T. SnoRNP Biogenesis Meets Pre-MRNA Splicing. Mol. Cell. 2006, 23, 775–776. [Google Scholar] [CrossRef]
- Richard, P.; Kiss, T. Integrating SnoRNP Assembly with MRNA Biogenesis. EMBO Rep. 2006, 7, 590–592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hansen, T.B. Detecting Agotrons in Ago CLIPseq Data. Methods Mol. Biol. 2018, 1823, 221–232. [Google Scholar] [CrossRef]
- Curtis, H.J.; Sibley, C.R.; Wood, M.J.A. Mirtrons, an Emerging Class of Atypical MiRNA. Wiley Interdiscip. Rev. RNA 2012, 3, 617–632. [Google Scholar] [CrossRef]
- Havens, M.A.; Reich, A.A.; Duelli, D.M.; Hastings, M.L. Biogenesis of Mammalian MicroRNAs by a Non-Canonical Processing Pathway. Nucleic Acids Res. 2012, 40, 4626–4640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berezikov, E.; Chung, W.-J.; Willis, J.; Cuppen, E.; Lai, E.C. Mammalian Mirtron Genes. Mol. Cell. 2007, 28, 328–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bachellerie, J.P.; Cavaillé, J. Guiding Ribose Methylation of RRNA. Trends Biochem. Sci. 1997, 22, 257–261. [Google Scholar] [CrossRef]
- Ganot, P.; Bortolin, M.-L.; Kiss, T. Site-Specific Pseudouridine Formation in Preribosomal RNA Is Guided by Small Nucleolar RNAs. Cell 1997, 89, 799–809. [Google Scholar] [CrossRef] [Green Version]
- Kiss, T.; Fayet, E.; Jády, B.E.; Richard, P.; Weber, M. Biogenesis and Intranuclear Trafficking of Human Box C/D and H/ACA RNPs. Cold Spring Harb. Symp. Quant. Biol. 2006, 71, 407–417. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McKeegan, K.S.; Debieux, C.M.; Boulon, S.; Bertrand, E.; Watkins, N.J. A Dynamic Scaffold of Pre-SnoRNP Factors Facilitates Human Box C/D SnoRNP Assembly. Mol. Cell. Biol. 2007, 27, 6782–6793. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lafontaine, D.L.; Bousquet-Antonelli, C.; Henry, Y.; Caizergues-Ferrer, M.; Tollervey, D. The Box H + ACA SnoRNAs Carry Cbf5p, the Putative RRNA Pseudouridine Synthase. Genes Dev. 1998, 12, 527–537. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Samarsky, D.A.; Fournier, M.J.; Singer, R.H.; Bertrand, E. The SnoRNA Box C/D Motif Directs Nucleolar Targeting and Also Couples SnoRNA Synthesis and Localization. EMBO J. 1998, 17, 3747–3757. [Google Scholar] [CrossRef]
- Jorjani, H.; Kehr, S.; Jedlinski, D.J.; Gumienny, R.; Hertel, J.; Stadler, P.F.; Zavolan, M.; Gruber, A.R. An Updated Human SnoRNAome. Nucleic Acids Res. 2016, 44, 5068–5082. [Google Scholar] [CrossRef]
- Darzacq, X.; Jády, B.E.; Verheggen, C.; Kiss, A.M.; Bertrand, E.; Kiss, T. Cajal Body-Specific Small Nuclear RNAs: A Novel Class of 2’-O-Methylation and Pseudouridylation Guide RNAs. EMBO J. 2002, 21, 2746–2756. [Google Scholar] [CrossRef] [PubMed]
- Verheggen, C.; Lafontaine, D.L.J.; Samarsky, D.; Mouaikel, J.; Blanchard, J.-M.; Bordonné, R.; Bertrand, E. Mammalian and Yeast U3 SnoRNPs Are Matured in Specific and Related Nuclear Compartments. EMBO J. 2002, 21, 2736–2745. [Google Scholar] [CrossRef] [Green Version]
- Meier, U.T. RNA Modification in Cajal Bodies. RNA Biol. 2017, 14, 693–700. [Google Scholar] [CrossRef]
- Mahmoudi, S.; Henriksson, S.; Weibrecht, I.; Smith, S.; Söderberg, O.; Strömblad, S.; Wiman, K.G.; Farnebo, M. WRAP53 Is Essential for Cajal Body Formation and for Targeting the Survival of Motor Neuron Complex to Cajal Bodies. PLoS Biol. 2010, 8, e1000521. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, H.-Y.; Lin, Y.-C.-D.; Li, J.; Huang, K.-Y.; Shrestha, S.; Hong, H.-C.; Tang, Y.; Chen, Y.-G.; Jin, C.-N.; Yu, Y.; et al. MiRTarBase 2020: Updates to the Experimentally Validated MicroRNA-Target Interaction Database. Nucleic Acids Res. 2020, 48, D148–D154. [Google Scholar] [CrossRef] [Green Version]
- Ladewig, E.; Okamura, K.; Flynt, A.S.; Westholm, J.O.; Lai, E.C. Discovery of Hundreds of Mirtrons in Mouse and Human Small RNA Data. Genome Res. 2012, 22, 1634–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boivin, V.; Reulet, G.; Boisvert, O.; Couture, S.; Elela, S.A.; Scott, M.S. Reducing the Structure Bias of RNA-Seq Reveals a Large Number of Non-Annotated Non-Coding RNA. Nucleic Acids Res. 2020, 48, 2271–2286. [Google Scholar] [CrossRef] [PubMed]
- Kishore, S.; Gruber, A.R.; Jedlinski, D.J.; Syed, A.P.; Jorjani, H.; Zavolan, M. Insights into SnoRNA Biogenesis and Processing from PAR-CLIP of SnoRNA Core Proteins and Small RNA Sequencing. Genome Biol. 2013, 14, R45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fafard-Couture, É.; Bergeron, D.; Couture, S.; Abou-Elela, S.; Scott, M.S. Annotation of SnoRNA Abundance across Human Tissues Reveals Complex SnoRNA-Host Gene Relationships. Genome Biol. 2021, 22, 172. [Google Scholar] [CrossRef] [PubMed]
- Bergeron, D.; Fafard-Couture, É.; Scott, M.S. Small Nucleolar RNAs: Continuing Identification of Novel Members and Increasing Diversity of Their Molecular Mechanisms of Action. Biochem. Soc. Trans. 2020, 48, 645–656. [Google Scholar] [CrossRef] [Green Version]
- De Araujo Oliveira, J.V.; Costa, F.; Backofen, R.; Stadler, P.F.; Machado Telles Walter, M.E.; Hertel, J. SnoReport 2.0: New Features and a Refined Support Vector Machine to Improve SnoRNA Identification. BMC Bioinform. 2016, 17, 464. [Google Scholar] [CrossRef]
- Zhang, C. MicroRNomics: A Newly Emerging Approach for Disease Biology. Physiol. Genomics 2008, 33, 139–147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dieci, G.; Preti, M.; Montanini, B. Eukaryotic SnoRNAs: A Paradigm for Gene Expression Flexibility. Genomics 2009, 94, 83–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schattner, P.; Brooks, A.N.; Lowe, T.M. The TRNAscan-SE, Snoscan and SnoGPS Web Servers for the Detection of TRNAs and SnoRNAs. Nucleic Acids Res. 2005, 33, W686–W689. [Google Scholar] [CrossRef] [PubMed]
- Yin, Q.-F.; Yang, L.; Zhang, Y.; Xiang, J.-F.; Wu, Y.-W.; Carmichael, G.G.; Chen, L.-L. Long Noncoding RNAs with SnoRNA Ends. Mol. Cell. 2012, 48, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Andersen, J.S.; Lyon, C.E.; Fox, A.H.; Leung, A.K.L.; Lam, Y.W.; Steen, H.; Mann, M.; Lamond, A.I. Directed Proteomic Analysis of the Human Nucleolus. Curr. Biol. 2002, 12, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Deryusheva, S.; Gall, J.G. ScaRNAs and SnoRNAs: Are They Limited to Specific Classes of Substrate RNAs? RNA 2019, 25, 17–22. [Google Scholar] [CrossRef] [PubMed]
- Machyna, M.; Kehr, S.; Straube, K.; Kappei, D.; Buchholz, F.; Butter, F.; Ule, J.; Hertel, J.; Stadler, P.F.; Neugebauer, K.M. The Coilin Interactome Identifies Hundreds of Small Noncoding RNAs That Traffic through Cajal Bodies. Mol. Cell. 2014, 56, 389–399. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lykke-Andersen, S.; Chen, Y.; Ardal, B.R.; Lilje, B.; Waage, J.; Sandelin, A.; Jensen, T.H. Human Nonsense-Mediated RNA Decay Initiates Widely by Endonucleolysis and Targets SnoRNA Host Genes. Genes Dev. 2014, 28, 2498–2517. [Google Scholar] [CrossRef] [Green Version]
- Ivanov, I.; Lo, K.C.; Hawthorn, L.; Cowell, J.K.; Ionov, Y. Identifying Candidate Colon Cancer Tumor Suppressor Genes Using Inhibition of Nonsense-Mediated MRNA Decay in Colon Cancer Cells. Oncogene 2007, 26, 2873–2884. [Google Scholar] [CrossRef] [Green Version]
- Baldini, L.; Charpentier, B.; Labialle, S. Emerging Data on the Diversity of Molecular Mechanisms Involving C/D SnoRNAs. Noncoding RNA 2021, 7, 30. [Google Scholar] [CrossRef]
- Makarova, J.A.; Kramerov, D.A. SNOntology: Myriads of Novel SnoRNAs or Just a Mirage? BMC Genomics 2011, 12, 543. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leung, Y.Y.; Kuksa, P.P.; Amlie-Wolf, A.; Valladares, O.; Ungar, L.H.; Kannan, S.; Gregory, B.D.; Wang, L.-S. DASHR: Database of Small Human Noncoding RNAs. Nucleic Acids Res. 2016, 44, D216–D222. [Google Scholar] [CrossRef] [Green Version]
- Lestrade, L.; Weber, M.J. SnoRNA-LBME-Db, a Comprehensive Database of Human H/ACA and C/D Box SnoRNAs. Nucleic Acids Res. 2006, 34, D158–D162. [Google Scholar] [CrossRef] [Green Version]
- Warner, W.A.; Spencer, D.H.; Trissal, M.; White, B.S.; Helton, N.; Ley, T.J.; Link, D.C. Expression Profiling of SnoRNAs in Normal Hematopoiesis and AML. Blood Adv. 2018, 2, 151–163. [Google Scholar] [CrossRef] [Green Version]
- McCann, K.L.; Kavari, S.L.; Burkholder, A.B.; Phillips, B.T.; Hall, T.M.T. H/ACA SnoRNA Levels Are Regulated during Stem Cell Differentiation. Nucleic Acids Res. 2020, 48, 8686–8703. [Google Scholar] [CrossRef]
- Falaleeva, M.; Welden, J.R.; Duncan, M.J.; Stamm, S. C/D-Box SnoRNAs Form Methylating and Non-Methylating Ribonucleoprotein Complexes: Old Dogs Show New Tricks. Bioessays 2017, 39, 1600264. [Google Scholar] [CrossRef]
- Sharma, S.; Langhendries, J.-L.; Watzinger, P.; Kötter, P.; Entian, K.-D.; Lafontaine, D.L.J. Yeast Kre33 and Human NAT10 Are Conserved 18S RRNA Cytosine Acetyltransferases That Modify TRNAs Assisted by the Adaptor Tan1/THUMPD1. Nucleic Acids Res. 2015, 43, 2242–2258. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Yang, J.; van Nues, R.; Watzinger, P.; Kötter, P.; Lafontaine, D.L.J.; Granneman, S.; Entian, K.-D. Specialized Box C/D SnoRNPs Act as Antisense Guides to Target RNA Base Acetylation. PLoS Genet. 2017, 13, e1006804. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Zhang, Q.C.; Lee, B.; Flynn, R.A.; Smith, M.A.; Robinson, J.T.; Davidovich, C.; Gooding, A.R.; Goodrich, K.J.; Mattick, J.S.; et al. RNA Duplex Map in Living Cells Reveals Higher-Order Transcriptome Structure. Cell 2016, 165, 1267–1279. [Google Scholar] [CrossRef] [Green Version]
- Bratkovič, T.; Božič, J.; Rogelj, B. Functional Diversity of Small Nucleolar RNAs. Nucleic Acids Res. 2020, 48, 1627–1651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Youssef, O.A.; Safran, S.A.; Nakamura, T.; Nix, D.A.; Hotamisligil, G.S.; Bass, B.L. Potential Role for SnoRNAs in PKR Activation during Metabolic Stress. Proc. Natl. Acad. Sci. USA 2015, 112, 5023–5028. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alisi, A.; Spaziani, A.; Anticoli, S.; Ghidinelli, M.; Balsano, C. PKR Is a Novel Functional Direct Player That Coordinates Skeletal Muscle Differentiation via P38MAPK/AKT Pathways. Cell Signal. 2008, 20, 534–542. [Google Scholar] [CrossRef] [PubMed]
- Michel, C.I.; Holley, C.L.; Scruggs, B.S.; Sidhu, R.; Brookheart, R.T.; Listenberger, L.L.; Behlke, M.A.; Ory, D.S.; Schaffer, J.E. Small Nucleolar RNAs U32a, U33, and U35a Are Critical Mediators of Metabolic Stress. Cell Metab. 2011, 14, 33–44. [Google Scholar] [CrossRef] [Green Version]
- Holley, C.L.; Li, M.W.; Scruggs, B.S.; Matkovich, S.J.; Ory, D.S.; Schaffer, J.E. Cytosolic Accumulation of Small Nucleolar RNAs (SnoRNAs) Is Dynamically Regulated by NADPH Oxidase. J. Biol. Chem. 2015, 290, 11741–11748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Balkom, B.W.M.; Eisele, A.S.; Pegtel, D.M.; Bervoets, S.; Verhaar, M.C. Quantitative and Qualitative Analysis of Small RNAs in Human Endothelial Cells and Exosomes Provides Insights into Localized RNA Processing, Degradation and Sorting. J. Extracell. Vesicles 2015, 4, 26760. [Google Scholar] [CrossRef] [PubMed]
- Kufel, J.; Grzechnik, P. Small Nucleolar RNAs Tell a Different Tale. Trends Genet 2019, 35, 104–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jády, B.E.; Ketele, A.; Kiss, T. Human Intron-Encoded Alu RNAs Are Processed and Packaged into Wdr79-Associated Nucleoplasmic Box H/ACA RNPs. Genes Dev. 2012, 26, 1897–1910. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bouchard-Bourelle, P.; Desjardins-Henri, C.; Mathurin-St-Pierre, D.; Deschamps-Francoeur, G.; Fafard-Couture, É.; Garant, J.-M.; Elela, S.A.; Scott, M.S. SnoDB: An Interactive Database of Human SnoRNA Sequences, Abundance and Interactions. Nucleic Acids Res. 2020, 48, D220–D225. [Google Scholar] [CrossRef] [PubMed]
- Castle, J.C.; Armour, C.D.; Löwer, M.; Haynor, D.; Biery, M.; Bouzek, H.; Chen, R.; Jackson, S.; Johnson, J.M.; Rohl, C.A.; et al. Digital Genome-Wide NcRNA Expression, Including SnoRNAs, across 11 Human Tissues Using PolyA-Neutral Amplification. PLoS ONE 2010, 5, e11779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, J.; Funk, W.D.; Wang, S.S.; Weinrich, S.L.; Avilion, A.A.; Chiu, C.P.; Adams, R.R.; Chang, E.; Allsopp, R.C.; Yu, J. The RNA Component of Human Telomerase. Science 1995, 269, 1236–1241. [Google Scholar] [CrossRef]
- Li, T.; Zhou, X.; Wang, X.; Zhu, D.; Zhang, Y. Identification and Characterization of Human SnoRNA Core Promoters. Genomics 2010, 96, 50–56. [Google Scholar] [CrossRef] [Green Version]
- Clark, M.B.; Amaral, P.P.; Schlesinger, F.J.; Dinger, M.E.; Taft, R.J.; Rinn, J.L.; Ponting, C.P.; Stadler, P.F.; Morris, K.V.; Morillon, A.; et al. The Reality of Pervasive Transcription. PLoS Biol. 2011, 9, e1000625, discussion e1001102. [Google Scholar] [CrossRef] [Green Version]
- Tisseur, M.; Kwapisz, M.; Morillon, A. Pervasive Transcription-Lessons from Yeast. Biochimie 2011, 93, 1889–1896. [Google Scholar] [CrossRef]
- Zhu, C.-H.; Mouly, V.; Cooper, R.N.; Mamchaoui, K.; Bigot, A.; Shay, J.W.; Di Santo, J.P.; Butler-Browne, G.S.; Wright, W.E. Cellular Senescence in Human Myoblasts Is Overcome by Human Telomerase Reverse Transcriptase and Cyclin-Dependent Kinase 4: Consequences in Aging Muscle and Therapeutic Strategies for Muscular Dystrophies. Aging Cell 2007, 6, 515–523. [Google Scholar] [CrossRef] [PubMed]
- Ellington, A.; Pollard, J.D. Purification of Oligonucleotides Using Denaturing Polyacrylamide Gel Electrophoresis. Curr. Protoc. Mol. Biol. 2001, 2, Unit2.12. [Google Scholar] [CrossRef] [PubMed]
- Janas, M.M.; Khaled, M.; Schubert, S.; Bernstein, J.G.; Golan, D.; Veguilla, R.A.; Fisher, D.E.; Shomron, N.; Levy, C.; Novina, C.D. Feed-Forward Microprocessing and Splicing Activities at a MicroRNA-Containing Intron. PLoS Genet. 2011, 7, e1002330. [Google Scholar] [CrossRef] [PubMed] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bogard, B.; Francastel, C.; Hubé, F. Systematic Identification and Functional Validation of New snoRNAs in Human Muscle Progenitors. Non-Coding RNA 2021, 7, 56. https://doi.org/10.3390/ncrna7030056
Bogard B, Francastel C, Hubé F. Systematic Identification and Functional Validation of New snoRNAs in Human Muscle Progenitors. Non-Coding RNA. 2021; 7(3):56. https://doi.org/10.3390/ncrna7030056
Chicago/Turabian StyleBogard, Baptiste, Claire Francastel, and Florent Hubé. 2021. "Systematic Identification and Functional Validation of New snoRNAs in Human Muscle Progenitors" Non-Coding RNA 7, no. 3: 56. https://doi.org/10.3390/ncrna7030056
APA StyleBogard, B., Francastel, C., & Hubé, F. (2021). Systematic Identification and Functional Validation of New snoRNAs in Human Muscle Progenitors. Non-Coding RNA, 7(3), 56. https://doi.org/10.3390/ncrna7030056