

HeLoDL: Hedgerow Localization Based on Deep Learning



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
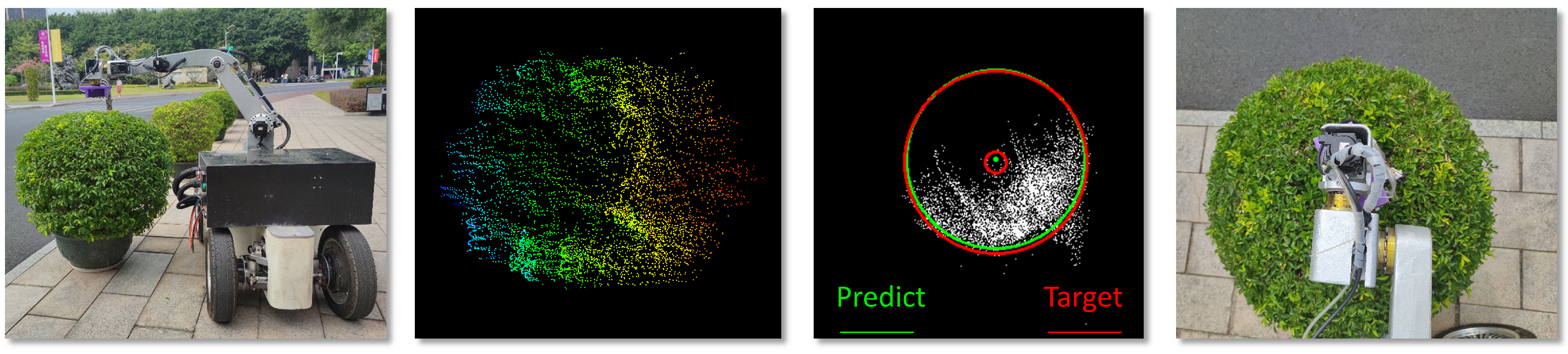
3.1. Materials
3.2. Problem Formulation
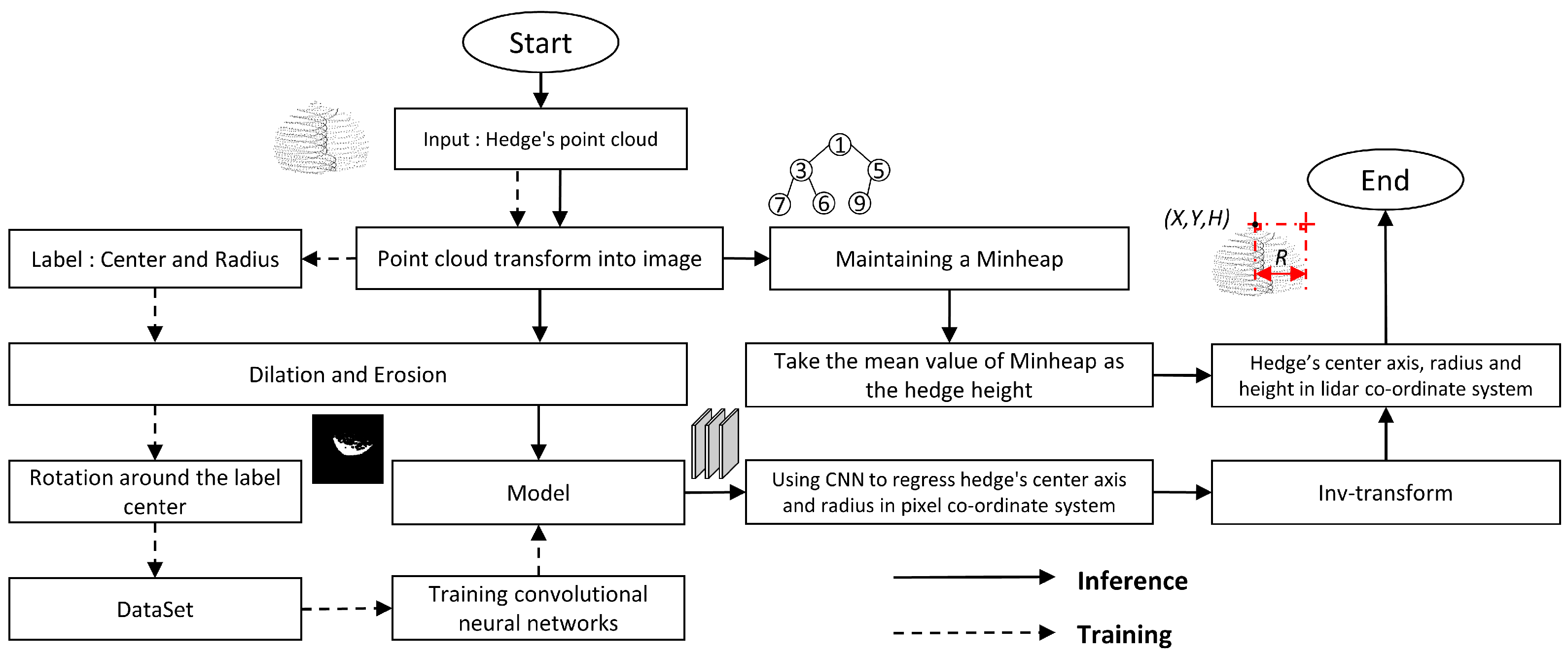
3.3. Pipeline of
3.3.1. Extract the Height Information of Hedge
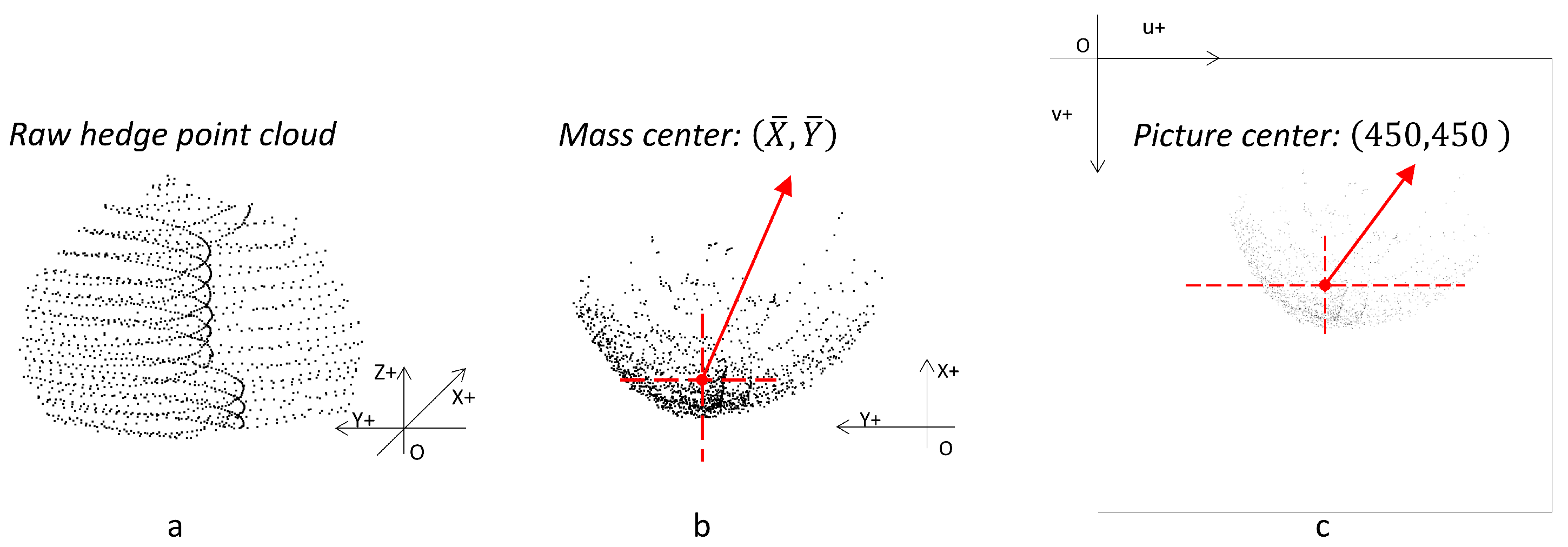
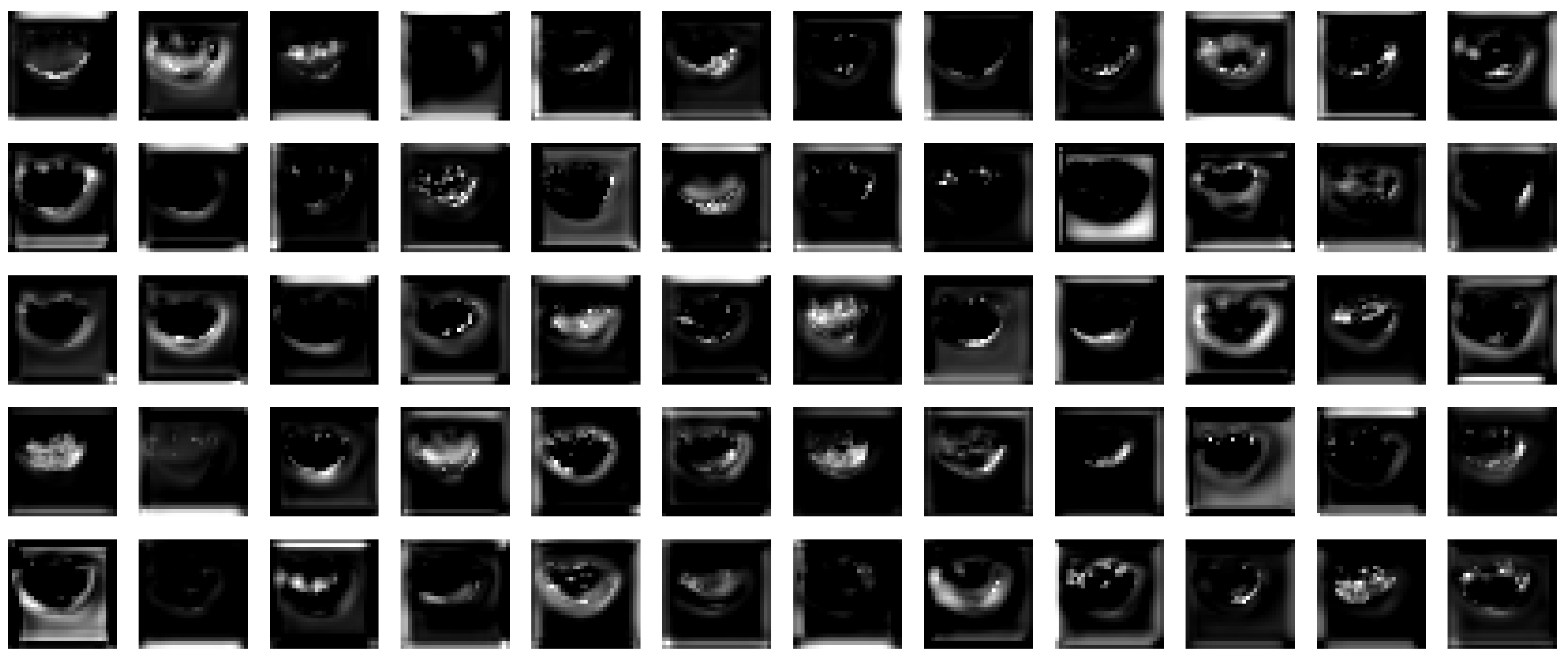
3.3.2. Transform Point Cloud Information into Image Information
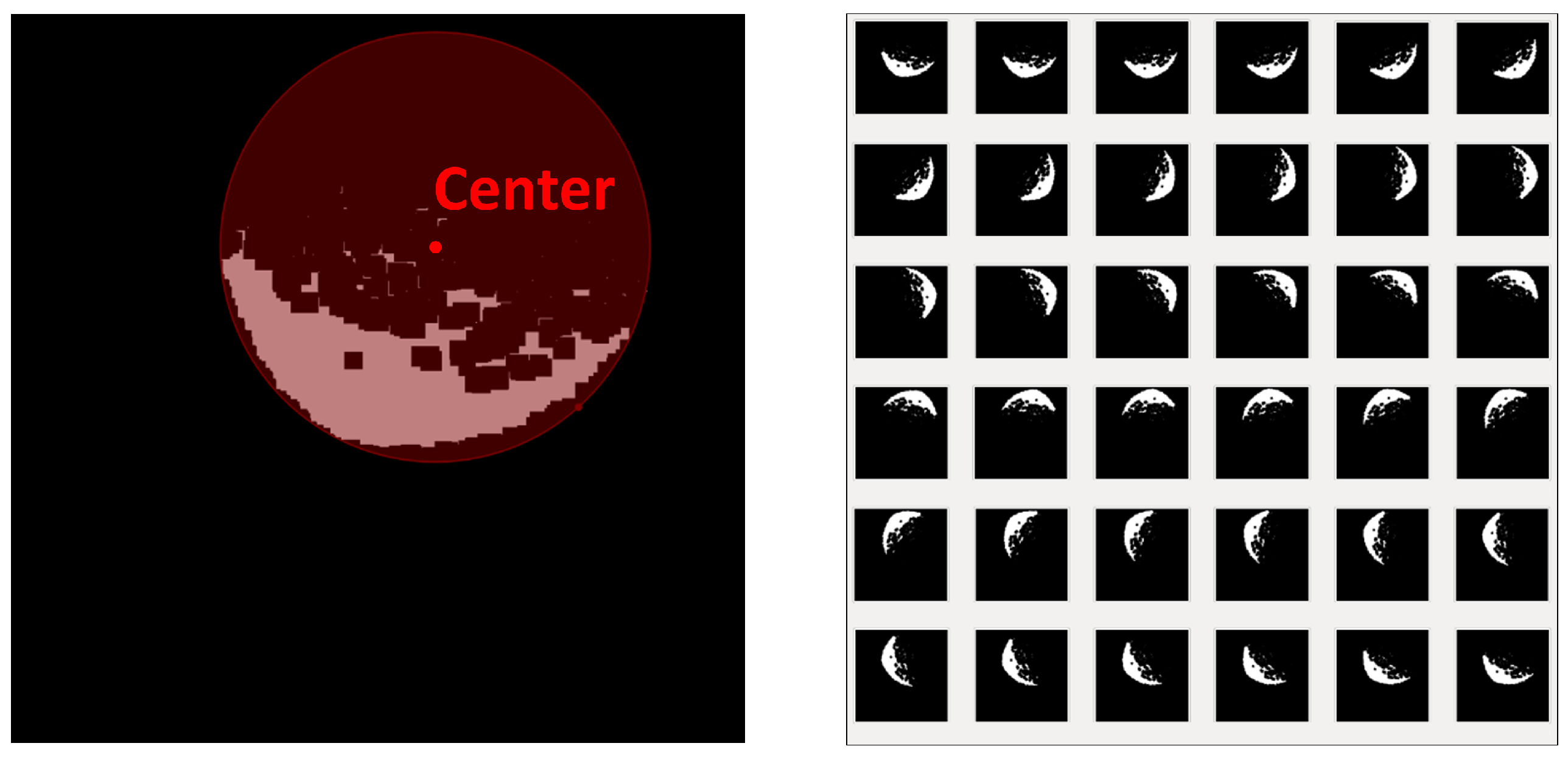
3.3.3. Morphological Operation
3.3.4. Rotation Operation
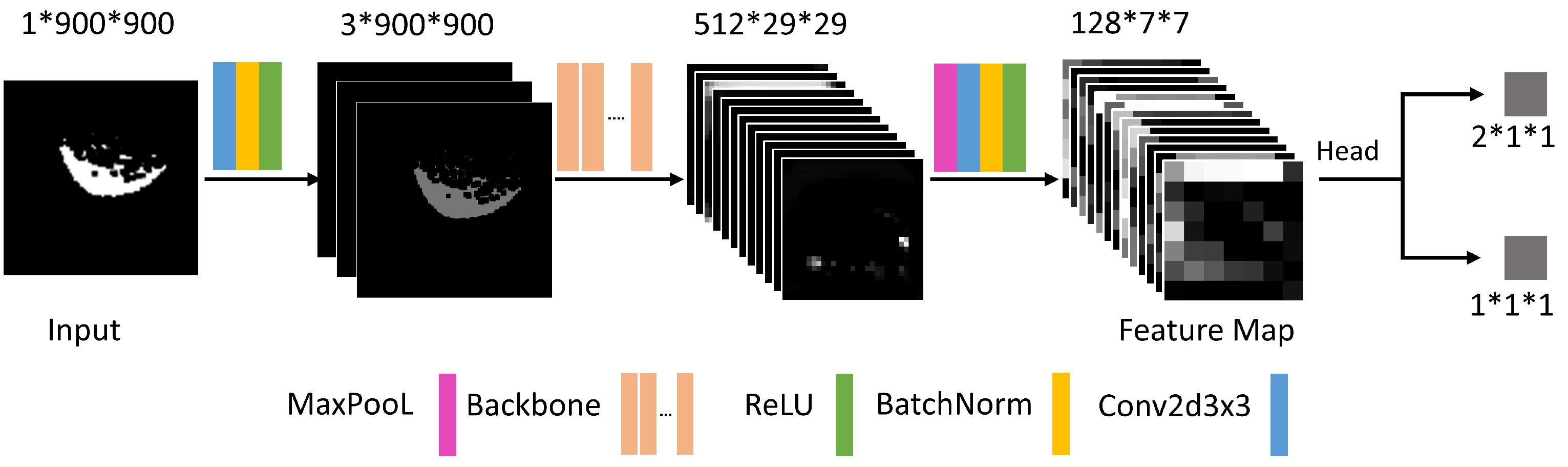
3.3.5. Using CNN to Regress Center Axis (u, v) and Radius r
3.3.6. Training and Inference
4. Results
4.1. Evaluation Index
4.1.1. Evaluation Index Related to Center Axis and Radius
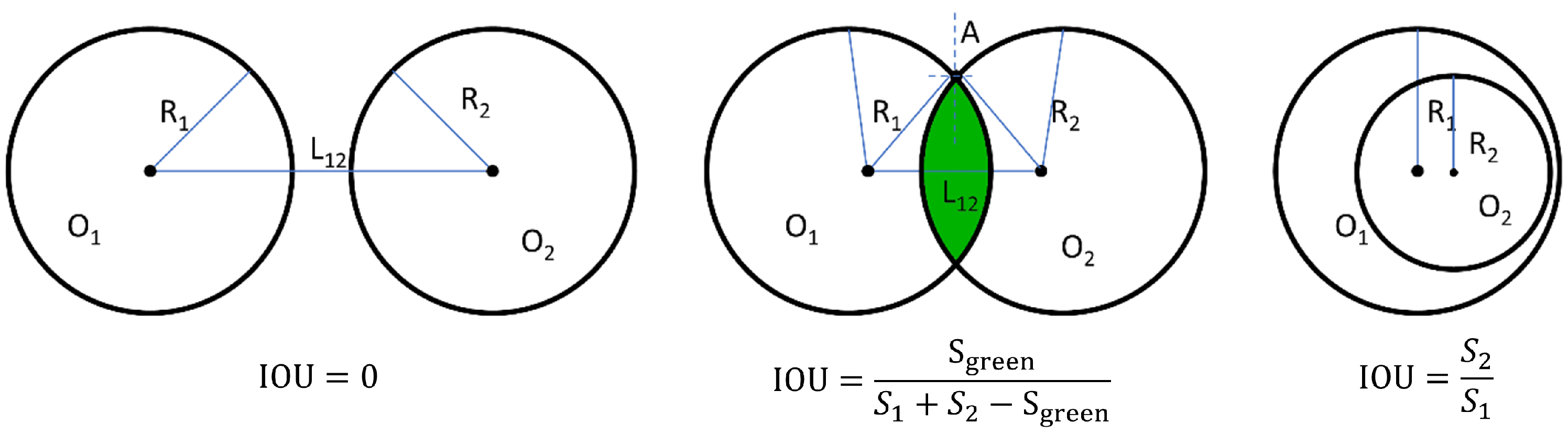
4.1.2. OIoU
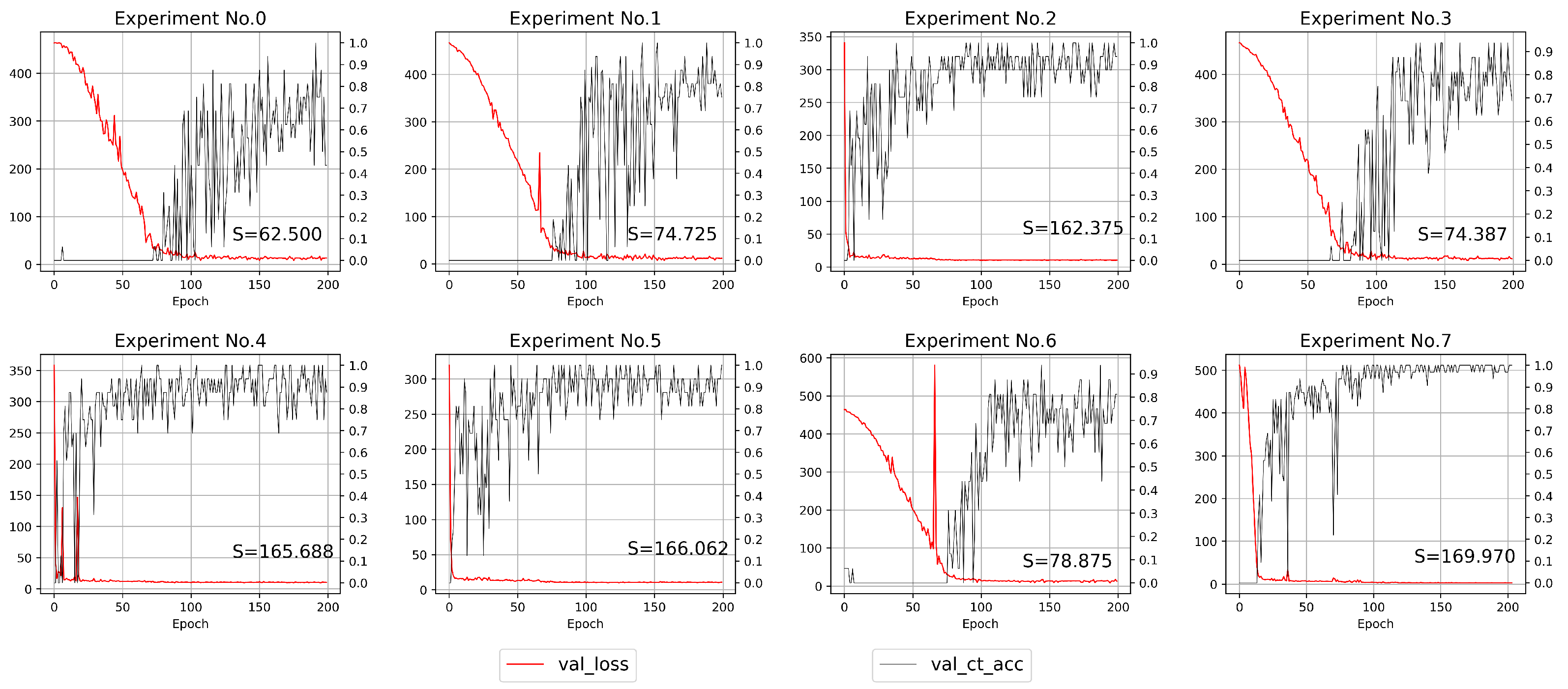
4.2. Experimental Results
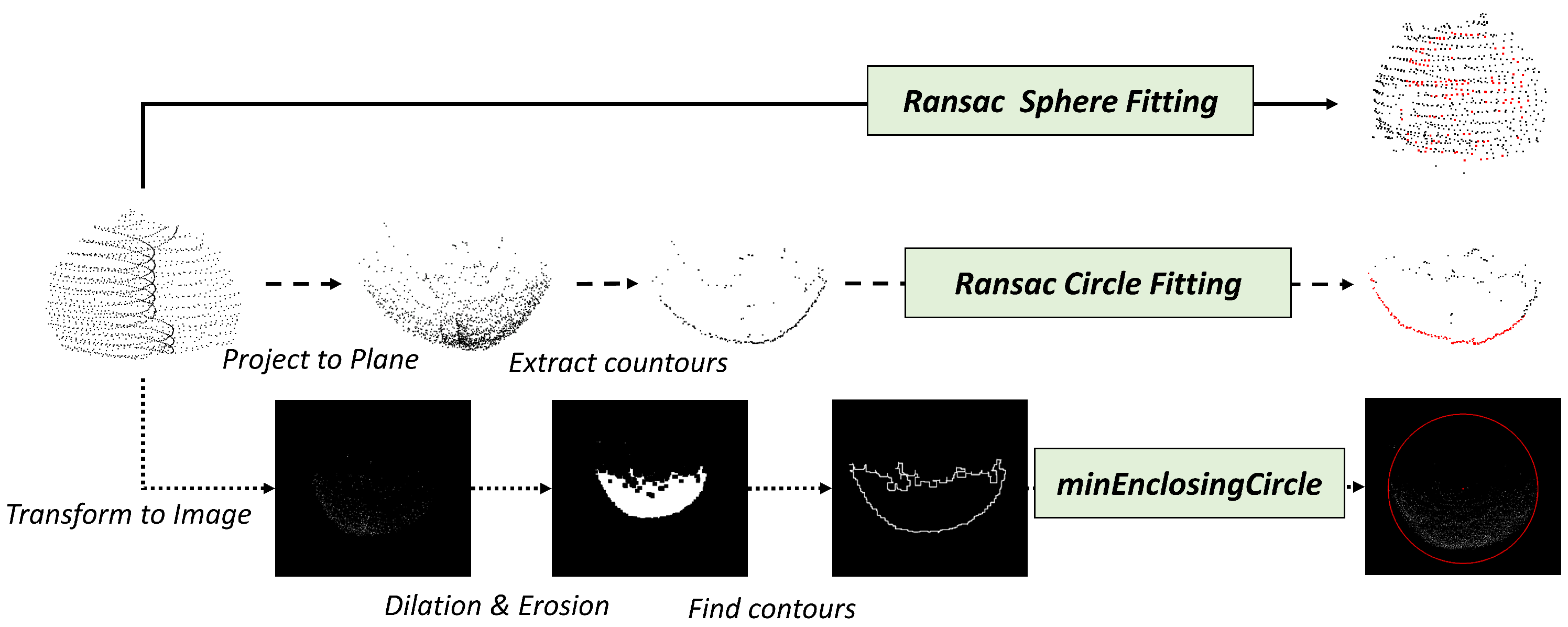
4.3. Comparative Experiment
4.3.1. The Effect of Different Backbones
4.3.2. Ablation Study
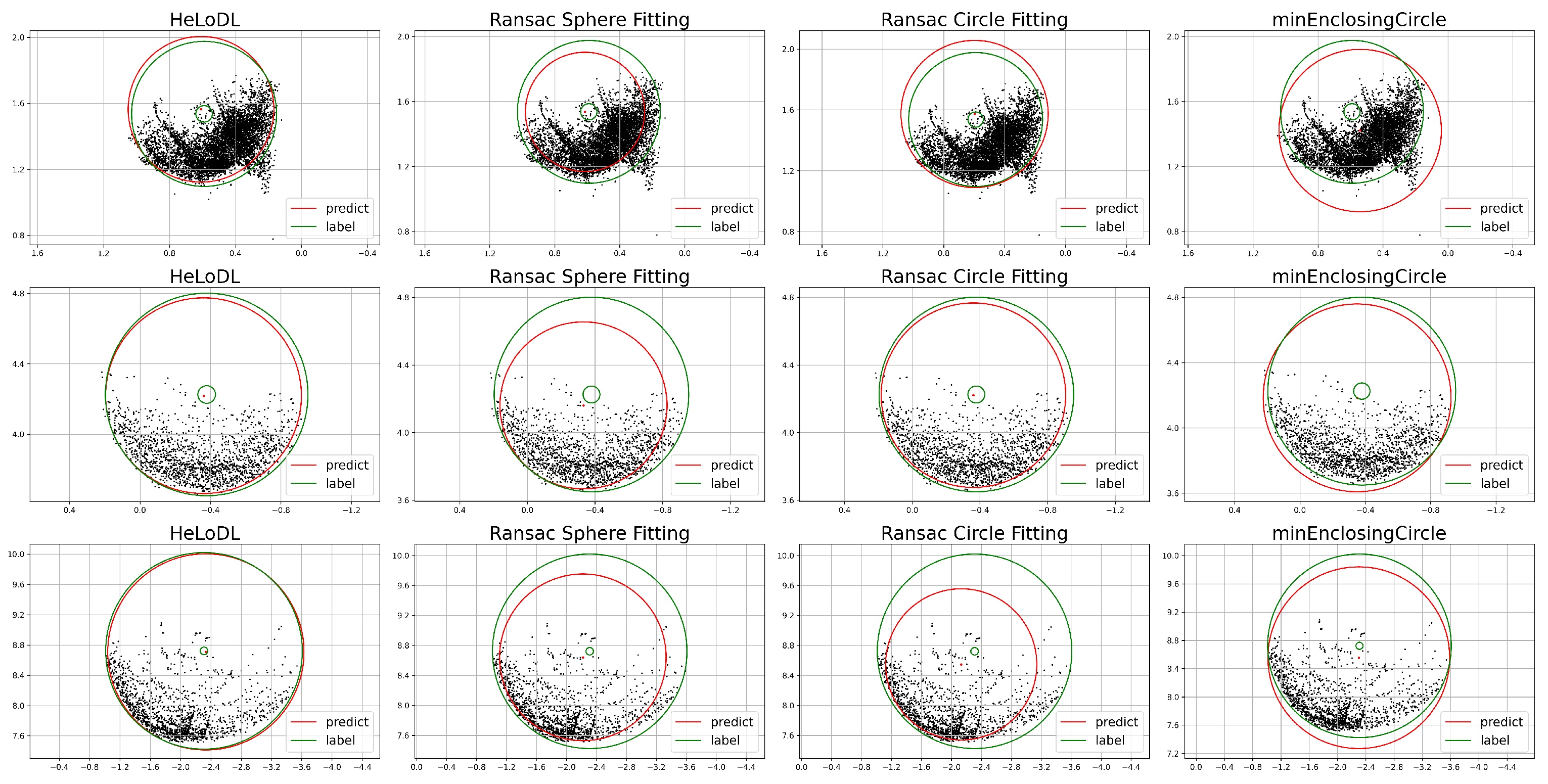
4.4. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Xu, E.; Zhang, J.; Meng, Y.; Wei, J.; Dong, Z.; Wei, H. AdaHC: Adaptive Hedge Horizontal Cross-Section Center Detection Algorithm. Comput. Electron. Agric. 2022, 192, 106582. [Google Scholar]
- Cao, M.; Ye, C.; Doessel, O.; Liu, C. Spherical parameter detection based on hierarchical Hough transform. Pattern Recognit. Lett. 2006, 27, 980–986. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar]
- Ogundana, T.; Coggrave, C.R.; Burguete, R.; Huntley, J.M. Fast Hough transform for automated detection of spheres in three-dimensional point clouds. Opt. Eng. 2007, 46, 051002. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christian, S.; Scott, R.; Cheng-Yang, F.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Ge, R.; Ding, Z.; Hu, Y.; Wang, Y.; Chen, S.; Huang, L.; Li, Y. Afdet: Anchor free one stage 3d object detection. arXiv 2020, arXiv:2006.12671. [Google Scholar]
- Zhang, F.; Guan, C.; Fang, J.; Bai, S.; Yang, R.; Torr, P.H.; Prisacariu, V. Instance segmentation of LIDAR point clouds. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9448–9455. [Google Scholar]
- Williams, J.W.J. Algorithm 232: Heapsort. Commun. ACM 1964, 7, 347–348. [Google Scholar]
- Hough, P.V.C. Machine Analysis of Bubble Chamber Pictures. Conf. Proc. C 1959, 590914, 554–558. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar]
- Kimme, C.; Balard, D.; Sklansky, J. Finding circles by an array of accumulators. Commun. ACM 1975, 18, 120–122. [Google Scholar] [CrossRef]
- Grbić, R.; Grahovac, D.; Scitovski, R. A method for solving the multiple ellipses detection problem. Pattern Recognit. 2016, 60, 824–834. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics & Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for point-cloud shape detection. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2007; Volume 26, pp. 214–226. [Google Scholar]
- Wang, L.; Shen, C.; Duan, F.; Lu, K. Energy-based automatic recognition of multiple spheres in three-dimensional point cloud. Pattern Recognit. Lett. 2016, 83, 287–293. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Dewez, T.J.B.; Girardeau-Montaut, D.; Allanic, C.; Rohmer, J. FACETS: A Cloudcompare Plugin To Extract Geological Planes From Unstructured 3D Point Clouds. In Proceedings of the 23rd Congress of the International-Society-for-Photogrammetry-and-Remote-Sensing (ISPRS), Prague, Czech Republic, 12–19 July 2016; Volume 41, pp. 799–804. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2569–2578. [Google Scholar]
- Wei, H.; Xu, E.; Zhang, J.; Meng, Y.; Wei, J.; Dong, Z.; Li, Z. BushNet: Effective semantic segmentation of bush in large-scale point clouds. Comput. Electron. Agric. 2022, 193, 106653. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Hedge’s Point Cloud | Projected Image | Augmented Data |
|---|---|---|---|
| Training set | 334 | 334 | 12,024 |
| Validation set | 115 | 115 | 4140 |
| Testing set | 115 | 115 | \ |
| Method | (%) | (cm) | (cm) | (%) | (ms) |
|---|---|---|---|---|---|
| Sphere Fitting | 36.522 | 7.091 | 6.935 | 73.775 | 16.603 |
| Circle Fitting | 61.739 | 4.398 | 5.458 | 83.689 | 13.132 |
| minEnclosingCircle | 28.696 | 2.430 | 9.265 | 80.914 | 13.509 |
| 90.435 | 1.635 | 2.712 | 92.654 | 12.727 |
| Backbone | (%) | (cm) | (cm) | OIoU (%) | (ms) | (hours) | Gflops | Parameters (millions) | Memory (M) |
|---|---|---|---|---|---|---|---|---|---|
| ResNet18 | 83.482 | 1.865 | 3.314 | 91.045 | 11.384 | 16.255 | 30.115 | 11.794 | 445.205 |
| ResNet34 | 90.435 | 1.635 | 2.712 | 92.654 | 12.727 | 26.352 | 60.732 | 21.893 | 641.014 |
| ResNet50 | 90.435 | 1.565 | 2.694 | 92.465 | 16.493 | 43.164 | 68.115 | 25.893 | 1818.297 |
| ShuffleNet_v2_x0_5 | 65.224 | 2.573 | 5.559 | 87.364 | 15.103 | 8.261 | 0.792 | 1.543 | 212.841 |
| ShuffleNet_v2_x1_0 | 79.132 | 2.114 | 3.691 | 90.062 | 14.844 | 11.943 | 2.583 | 2.455 | 370.992 |
| ShuffleNet_v2_x1_5 | 76.527 | 2.452 | 3.687 | 89.674 | 15.213 | 15.697 | 5.132 | 3.684 | 510.53 |
| Experimental Serial Number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Transfer Learning | ✘ | ✔ | ✘ | ✘ | ✔ | ✘ | ✔ | ✔ |
| Rotation operation | ✘ | ✘ | ✔ | ✘ | ✔ | ✔ | ✘ | ✔ |
| Morphological operation | ✘ | ✘ | ✘ | ✔ | ✘ | ✔ | ✔ | ✔ |
| Experimental Serial Number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| (cm) | 2.980 | 2.494 | 1.849 | 2.688 | 1.816 | 1.720 | 2.196 | 1.635 |
| (cm) | 4.696 | 5.060 | 2.959 | 4.941 | 2.815 | 2.785 | 4.237 | 2.712 |
| OIoU (%) | 88.022 | 88.084 | 91.767 | 88.311 | 91.699 | 92.200 | 89.815 | 92.654 |
| (%) | 71.304 | 72.174 | 86.957 | 74.783 | 87.826 | 88.696 | 76.522 | 90.435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, Y.; Zhai, X.; Zhang, J.; Wei, J.; Zhu, J.; Zhang, T. HeLoDL: Hedgerow Localization Based on Deep Learning. Horticulturae 2023, 9, 227. https://doi.org/10.3390/horticulturae9020227
Meng Y, Zhai X, Zhang J, Wei J, Zhu J, Zhang T. HeLoDL: Hedgerow Localization Based on Deep Learning. Horticulturae. 2023; 9(2):227. https://doi.org/10.3390/horticulturae9020227
Chicago/Turabian StyleMeng, Yanmei, Xulei Zhai, Jinlai Zhang, Jin Wei, Jihong Zhu, and Tingting Zhang. 2023. "HeLoDL: Hedgerow Localization Based on Deep Learning" Horticulturae 9, no. 2: 227. https://doi.org/10.3390/horticulturae9020227
APA StyleMeng, Y., Zhai, X., Zhang, J., Wei, J., Zhu, J., & Zhang, T. (2023). HeLoDL: Hedgerow Localization Based on Deep Learning. Horticulturae, 9(2), 227. https://doi.org/10.3390/horticulturae9020227