
Grape-Bunch Identification and Location of Picking Points on Occluded Fruit Axis Based on YOLOv5-GAP



Abstract
:1. Introduction
2. Materials and Methods
2.1. Test Environment
2.2. Image and Data Collection
2.3. Grape-Bunch Detection Algorithm
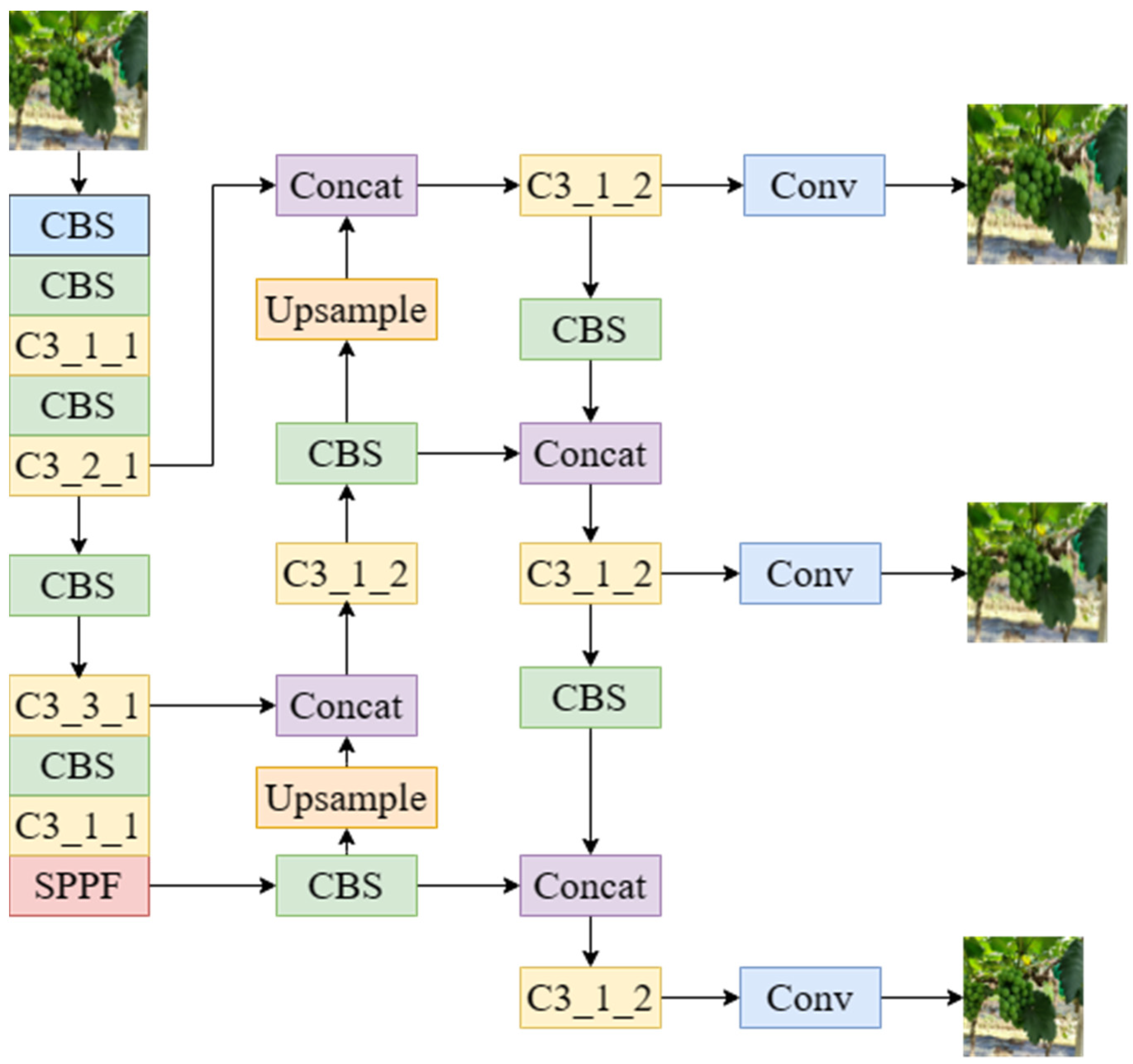
2.3.1. YOLOv5 Algorithm
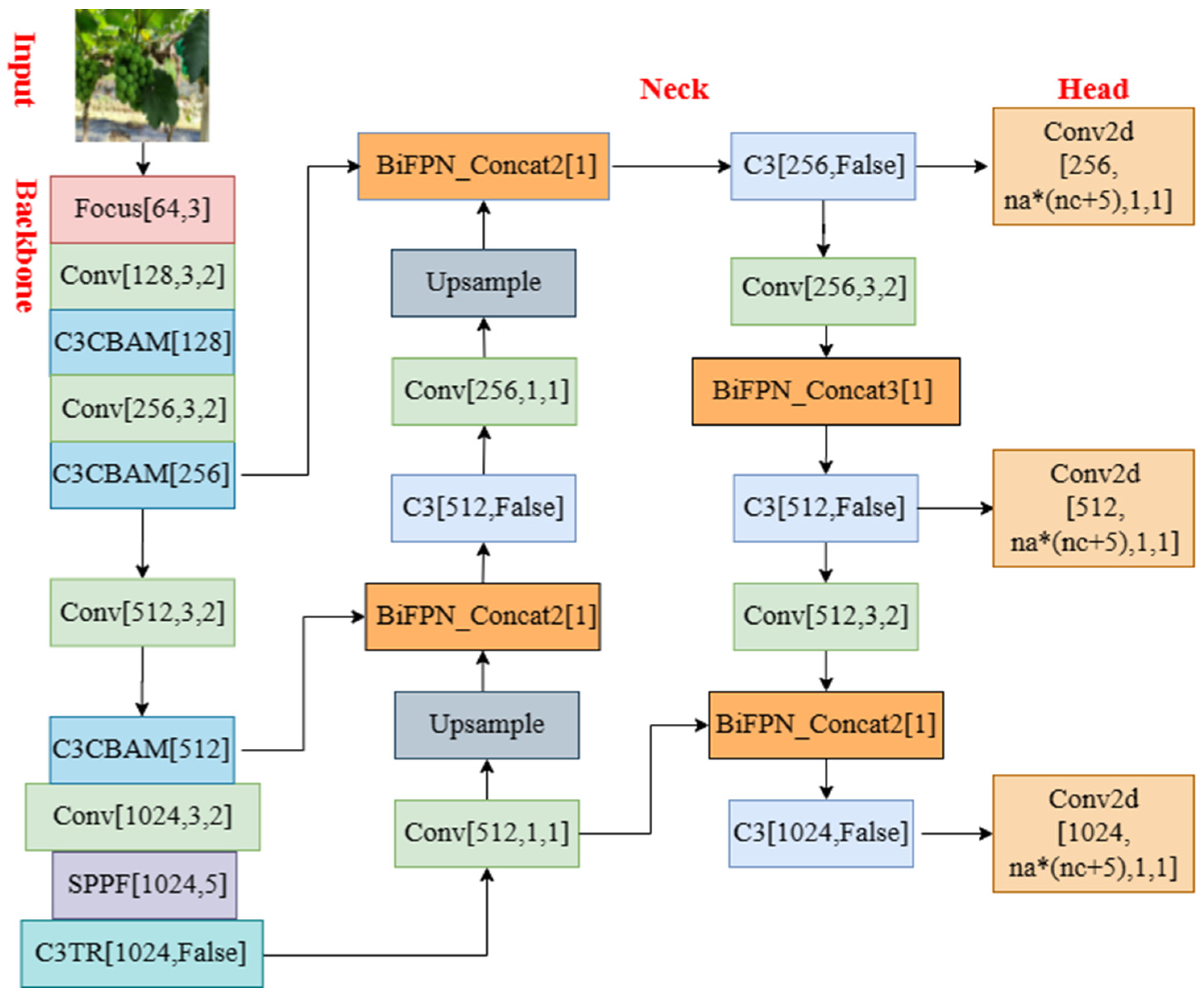
2.3.2. Improved YOLOv5 Grape-Detection Algorithm
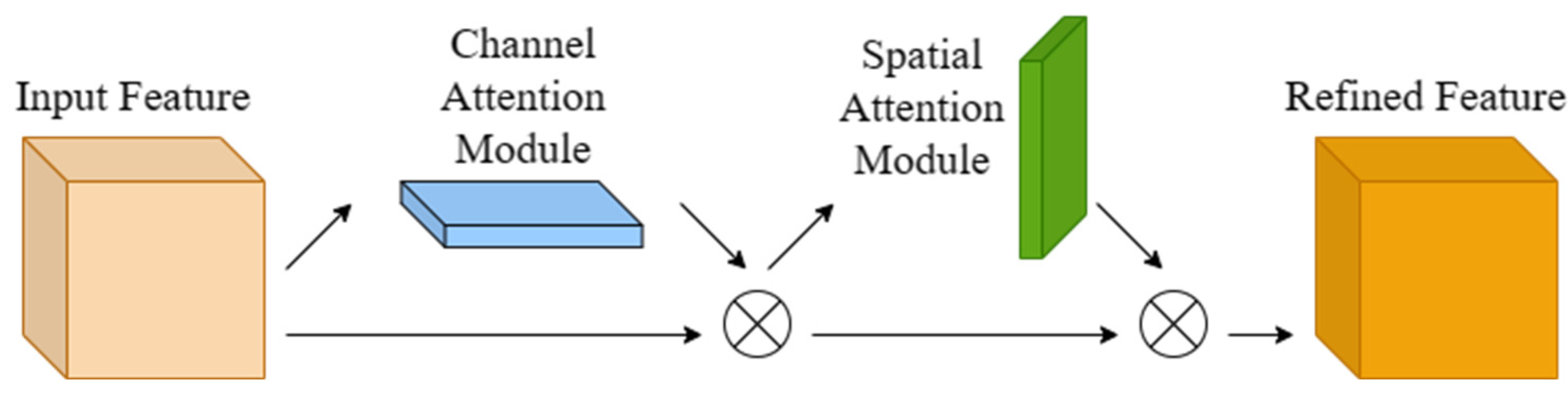
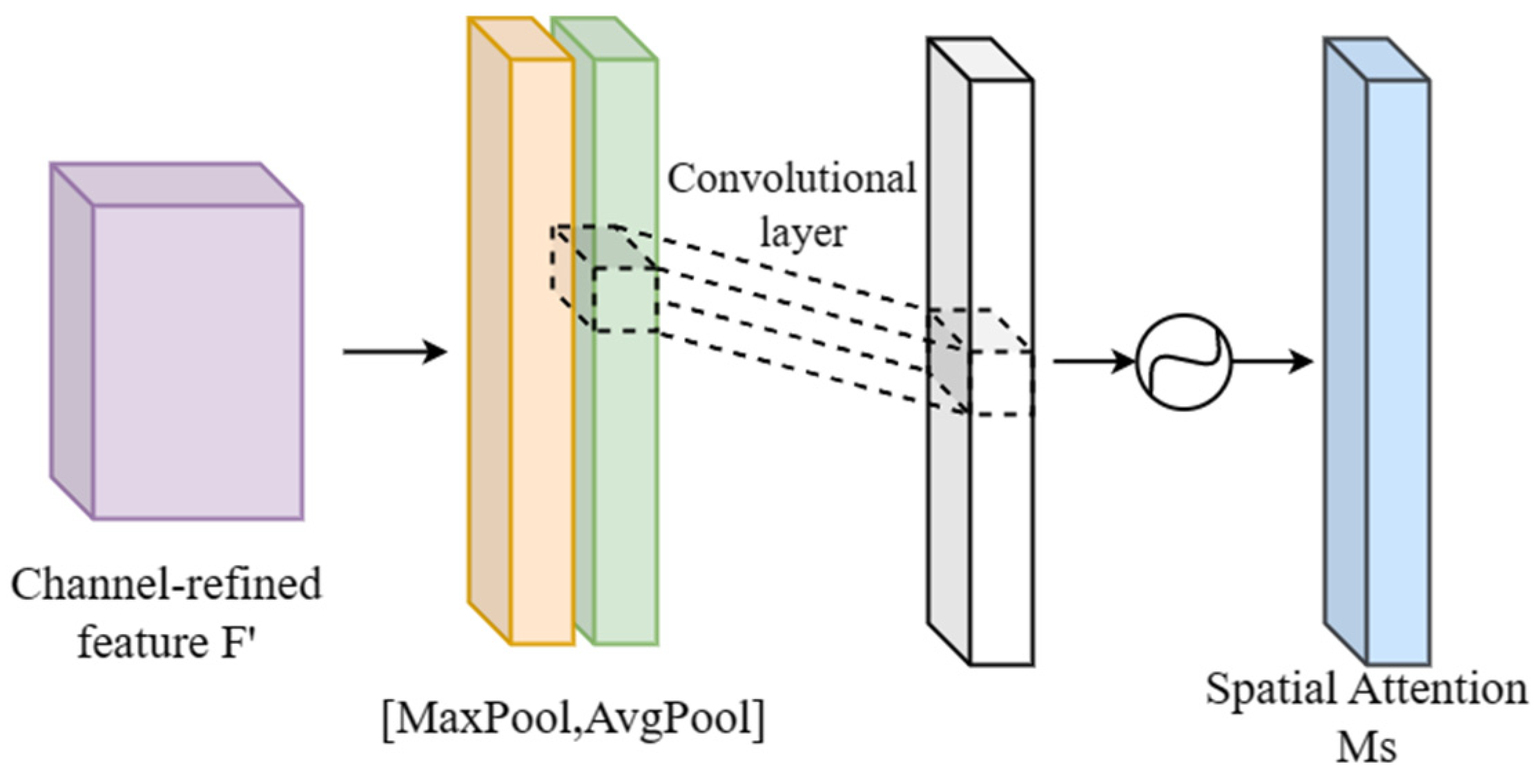
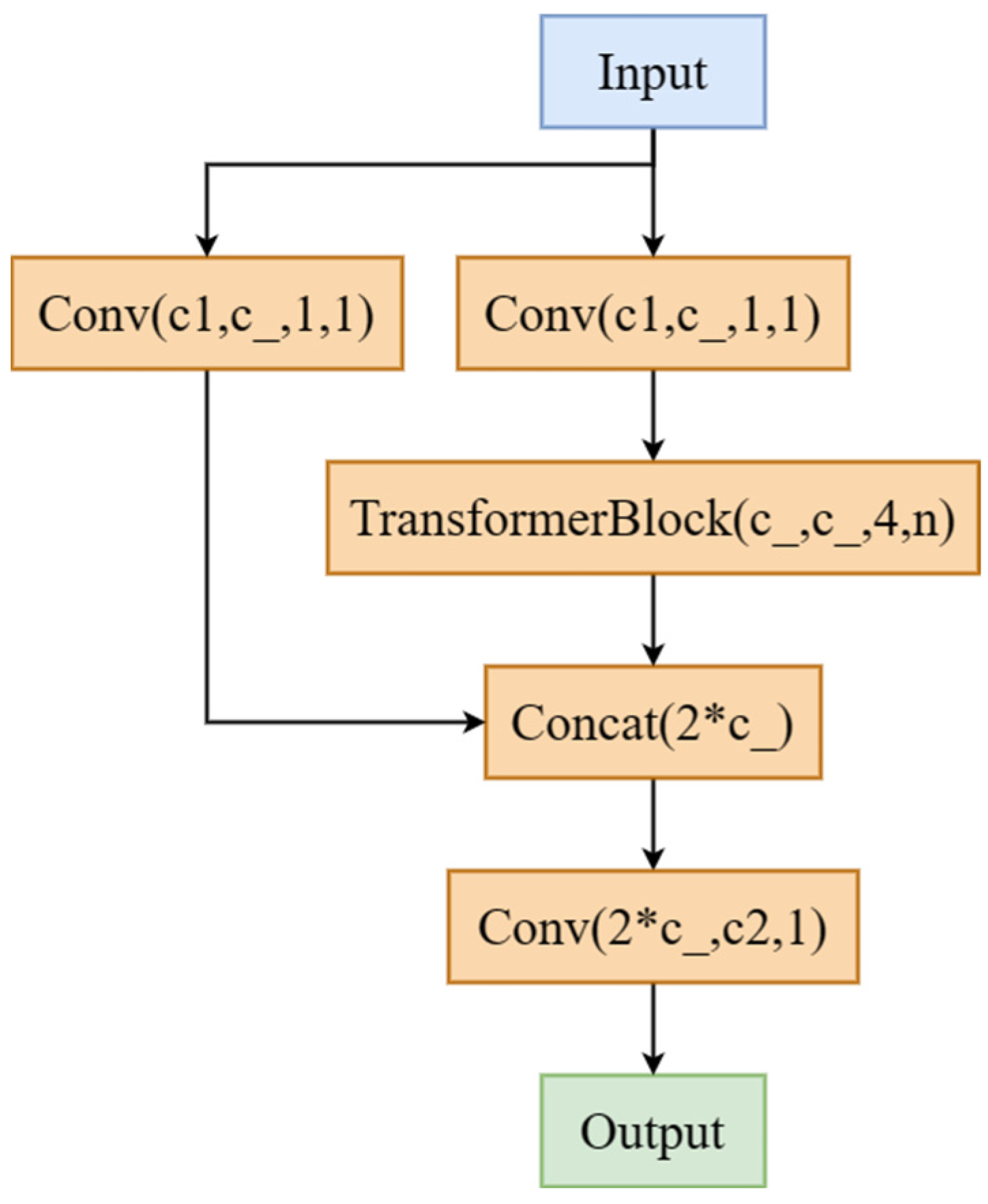
2.3.3. Improvement of Backbone Network Structure
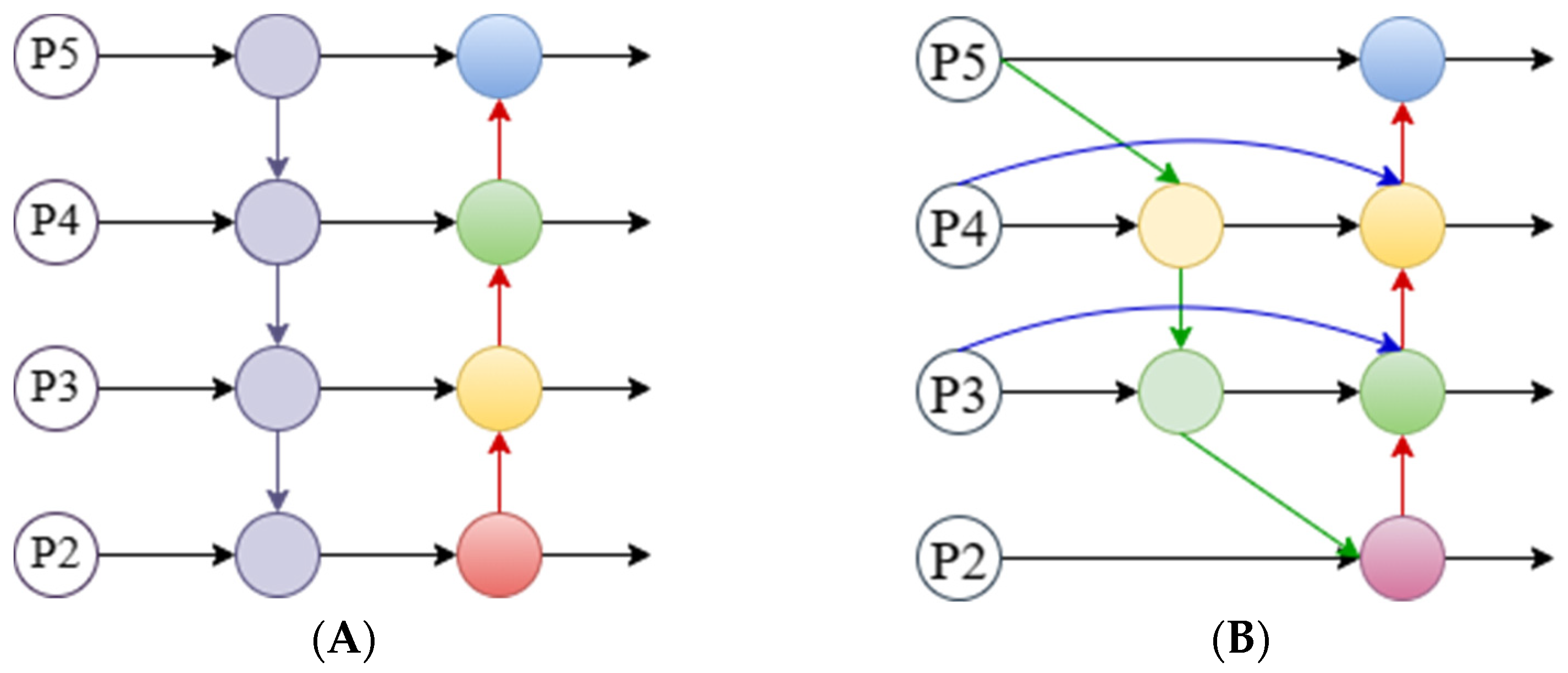
2.3.4. Improvement of Feature Fusion Method
2.3.5. Improvement of Activation Function
2.4. Model Training
2.5. Picking-Point Positioning
2.5.1. Image Segmentation
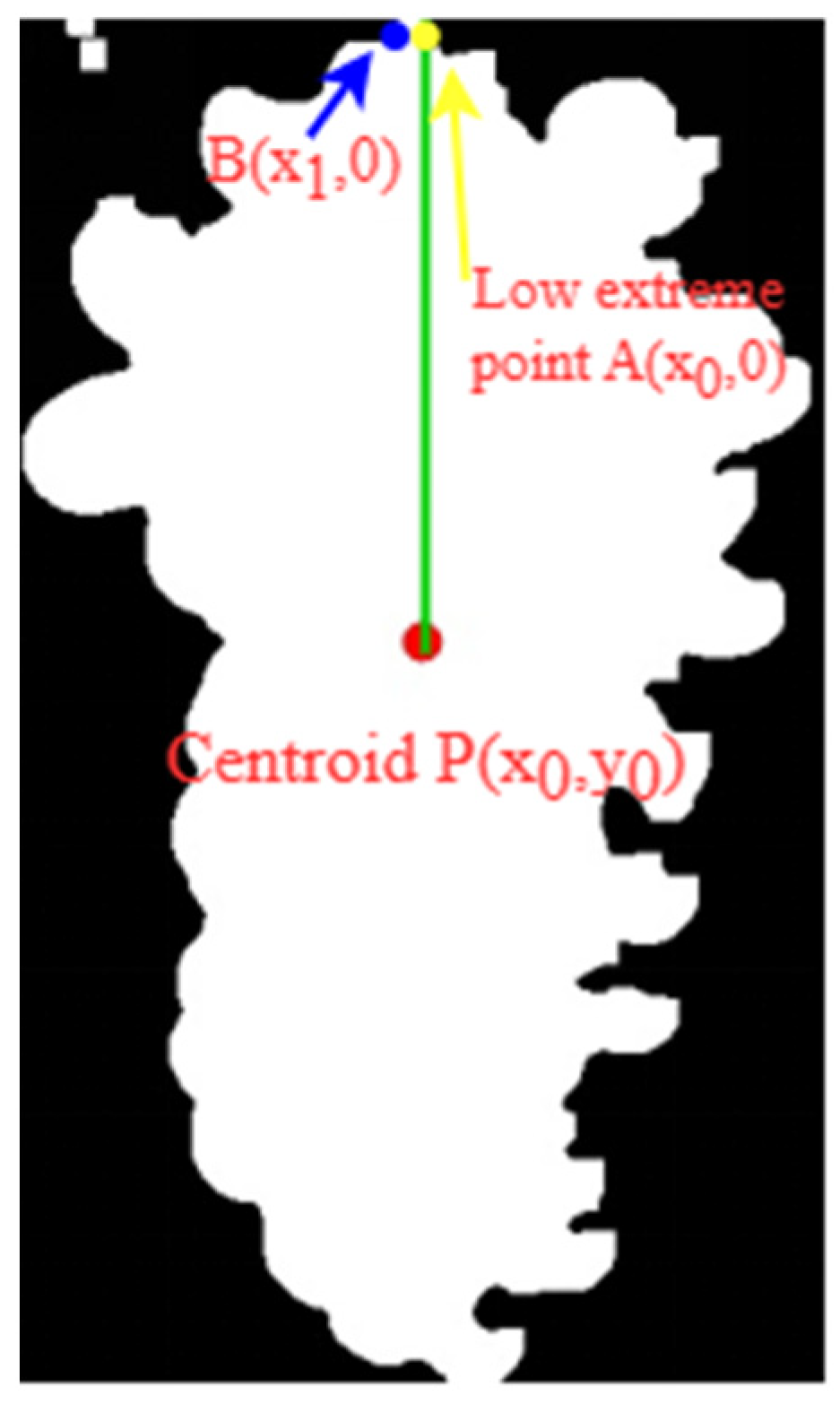
2.5.2. Geometric Calculation of Picking-Point Position
3. Results
3.1. Algorithm Evaluation Indicators
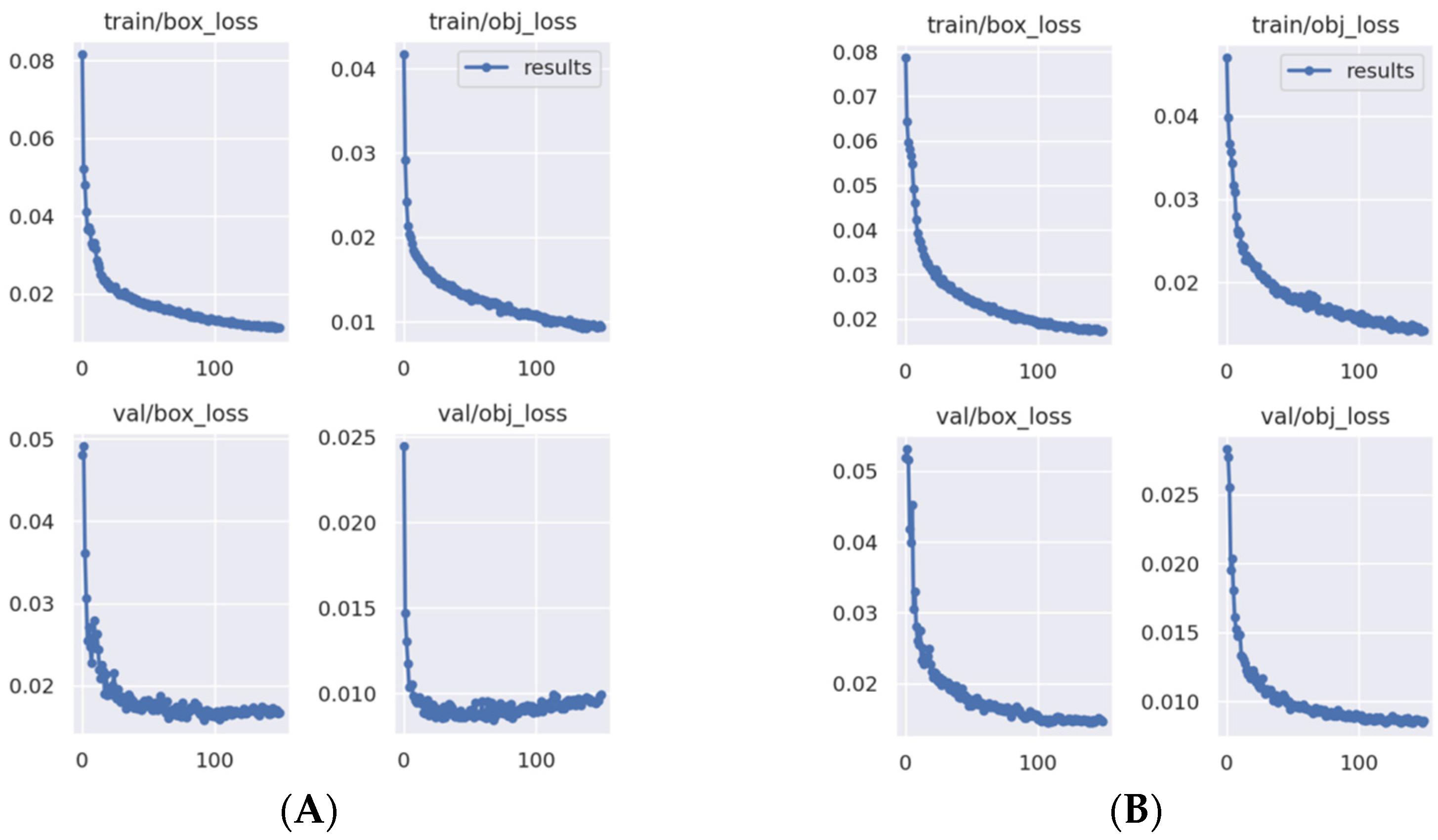
3.2. Algorithm Training Results
3.3. Ablation Test Results and Analysis
3.4. Comparative Test Results and Analysis
3.5. Comparison of Test Results
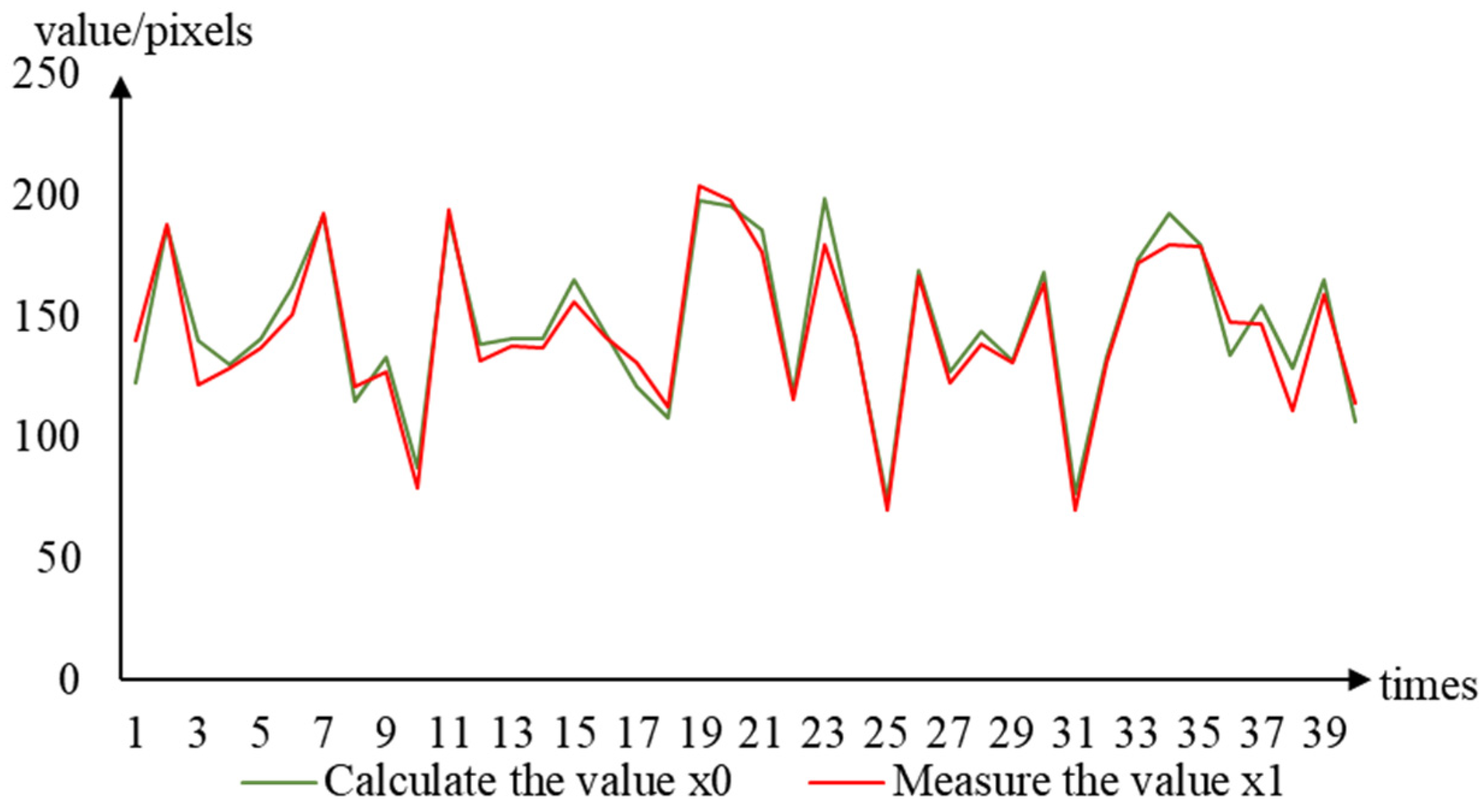
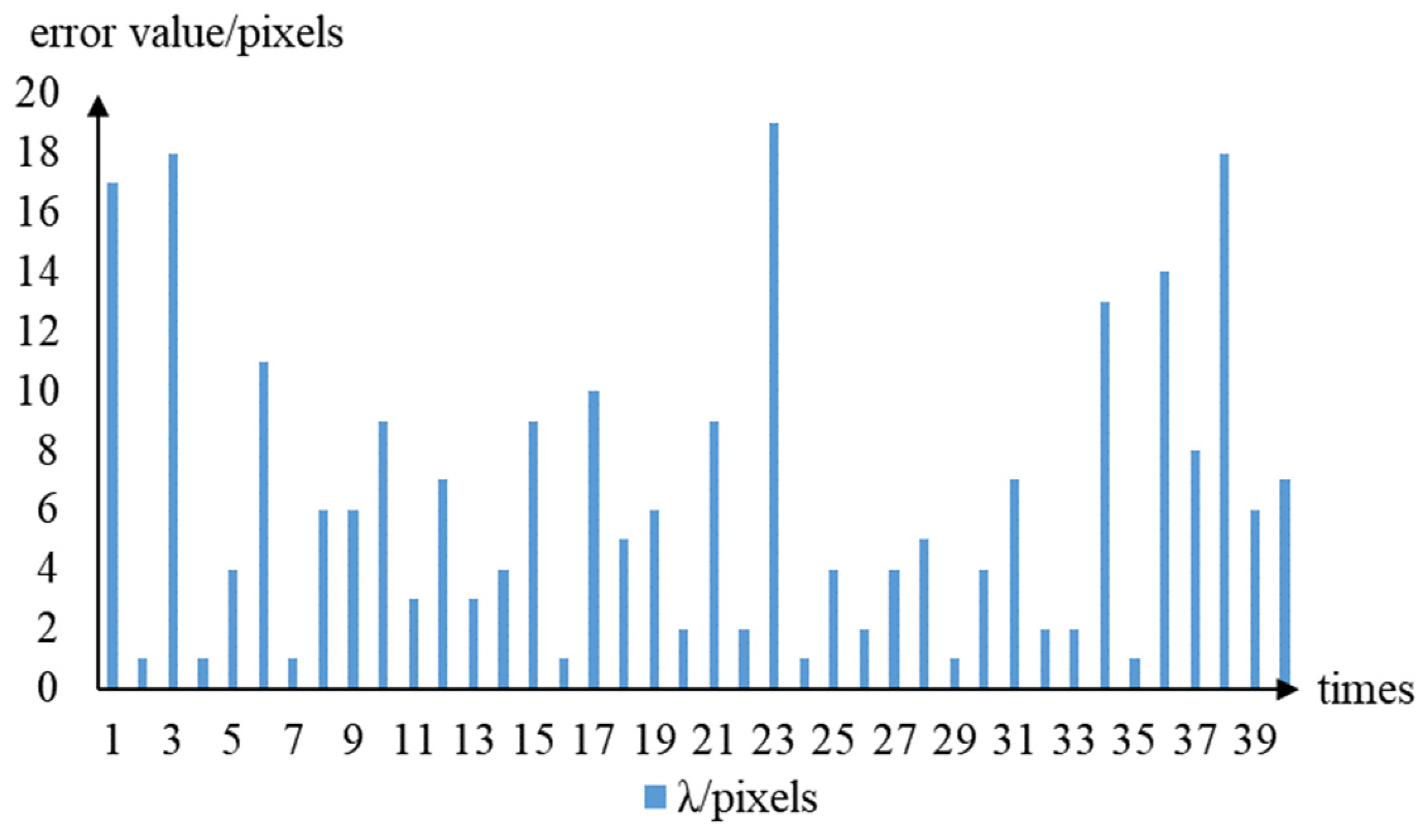
3.6. Picking-Point Positioning-Error Test
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, S.; Zou, X.; Zhou, X.; Xiang, Y.; Wu, M. Study on fusion clustering and improved yolov5 algorithm based on multiple occlusion of camellia oleifera fruit. Comput. Electron. Agric. 2023, 206, 107706. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel visual crack width measurement based on backbone double-scale features for improved detection automation. Eng. Struct. 2023, 274, 115158. [Google Scholar] [CrossRef]
- Tang, Y.; Zhou, H.; Wang, H.; Zhang, Y. Fruit detection and positioning technology for a camellia oleifera c. Abel orchard based on improved yolov4-tiny model and binocular stereo vision. Expert Syst. Appl. 2023, 211, 118573. [Google Scholar] [CrossRef]
- Bac, C.W.; Hemming, J.; van Henten, E.J. Stem localization of sweet-pepper plants using the support wire as a visual cue. Comput. Electron. Agric. 2014, 105, 111–120. [Google Scholar] [CrossRef]
- Kalampokas, Τ.; Vrochidou, Ε.; Papakostas, G.A.; Pachidis, T.; Kaburlasos, V.G. Grape stem detection using regression convolutional neural networks. Comput. Electron. Agric. 2021, 186, 106220. [Google Scholar] [CrossRef]
- Tang, Y.; Qiu, J.; Zhang, Y.; Wu, D.; Cao, Y.; Zhao, K.; Zhu, L. Optimization strategies of fruit detection to overcome the challenge of unstructured background in field orchard environment: A review. Precis. Agric. 2023, 24, 1–37. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Ai, P.; Chen, Z.; Yang, Z.; Zou, X. Rachis detection and three-dimensional localization of cut off point for vision-based banana robot. Comput. Electron. Agric. 2022, 198, 107079. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-target recognition of bananas and automatic positioning for the inflorescence axis cutting point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef]
- Fu, L.; Wu, F.; Zou, X.; Jiang, Y.; Lin, J.; Yang, Z.; Duan, J. Fast detection of banana bunches and stalks in the natural environment based on deep learning. Comput. Electron. Agric. 2022, 194, 106800. [Google Scholar] [CrossRef]
- Peng, H.; Huang, B.; Shao, Y.; Li, Z.; Zhang, C.; Chen, Y.; Xiong, J. General improved SSD model for picking object recognition of multiple fruits in natural environment. Trans. Chin. Soc. Agric. Eng. 2018, 34, 155–162. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Detection of Apple Lesions in Orchards Based on Deep Learning Methods of CycleGAN and YOLOV3-Dense. J. Sens. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Zhao, K.; Yan, W.Q. Fruit Detection from Digital Images Using CenterNet. In Geometry and Vision; ISGV 2021. Communications in Computer and Information Science; Nguyen, M., Yan, W.Q., Ho, H., Eds.; Springer: Cham, Switzerland, 2021; Volume 1386. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Burks, T.F.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Kataoka, T. Fruit detection system and an end effector for robotic harvesting of Fuji apples. Agric Eng Int CIGR J. 2010, 12, 203–210. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Xiong, J.; He, Z.; Lin, R.; Liu, Z.; Bu, R.; Yang, Z.; Peng, H.; Zou, X. Visual positioning technology of picking robots for dynamic litchi clusters with disturbance. Comput. Electron. Agric. 2018, 151, 226–237. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Ye, M.; Feng, W.; Li, G. Vision-based extraction of spatial information in grape clusters for harvesting robots. Biosyst. Eng. 2016, 151, 90–104. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Lu, Q.; Chen, X.; Zhang, P.; Zou, X. A vision methodology for harvesting robot to detect cutting points on peduncles of double overlapping grape clusters in a vineyard. Comput. Ind. 2018, 99, 130–139. [Google Scholar] [CrossRef]
- Luo, L.; Liu, W.; Lu, Q.; Wang, J.; Wen, W.; Yan, D.; Tang, Y. Grape berry detection and size measurement based on edge image processing and geometric morphology. Machines 2021, 9, 233. [Google Scholar] [CrossRef]
- Luo, L.; Zou, X.; Wang, C.; Chen, X.; Yang, Z.; Situ, W. Recognition method for two overlaping and adjacent grape clusters based on image contour analysis. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 2017, 48, 15–22. [Google Scholar]
- Chen, M.; Tang, Y.; Zou, X.; Huang, Z.; Zhou, H.; Chen, S. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM. Comput. Electron. Agric. 2021, 187, 106237. [Google Scholar] [CrossRef]
- Wang, H.; Lin, Y.; Xu, X.; Chen, Z.; Wu, Z.; Tang, Y. A Study on Long–Close Distance Coordination Control Strategy for Litchi Picking. Agronomy 2022, 12, 1520. [Google Scholar] [CrossRef]
- Thiago, T.; Leonardo, S.; de Souza, L.; Santos, A.A.D.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar]
- Hanwen, K.; Chao, C. Fast implementation of real-time fruit detection in apple orchards using deep learning. Comput. Electron. Agric. 2019, 168, 105108. [Google Scholar]
- Kang, H.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based 3D fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Li, J.; Tang, Y.; Zou, X.; Lin, G.; Wang, H. Detection of Fruit-Bearing Branches and Localization of Litchi Clusters for Vision-Based Harvesting Robots. IEEE Access 2020, 8, 117746–117758. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep Fruit Detection in Orchards. arXiv 2016, arXiv:1610.03677. [Google Scholar]
- Bargoti, S.; Underwood, J.P. Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards(Article). J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Delpiano, J.; Vougioukas, S.; Cheein, F.A. Comparison of convolutional neural networks in fruit detection and counting: A comprehensive evaluation. Comput. Electron. Agric. 2020, 173, 105348. [Google Scholar] [CrossRef]
- Häni, N.; Roy, P.; Isler, V. A comparative study of fruit detection and counting methods for yield mapping in apple orchards. J. Field Robot. 2020, 37, 263–282. [Google Scholar] [CrossRef]
- Stein, M.; Bargoti, S.; Underwood, J. Image Based Mango Fruit Detection, Localisation and Yield Estimation Using Multiple View Geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef] [PubMed]
- Parico, A.I.B.; Ahamed, T. Real Time Pear Fruit Detection and Counting Using YOLOv4 Models and Deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Liao, H.; Yeh, I.; Wu, Y.; Chen, P.; Hsieh, J. CSPNet: A new backbone that can enhance learning capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bapat, K. Find the Center of a Blob (Centroid) Using OpenCV (C++/Python). Available online: https://learnopencv.com/find-center-of-blob-centroid-using-opencv-cpp-python/ (accessed on 11 April 2023).
- Hripcsak, G.; Rothschild, A.S. Agreement, the f-measure, and reliability in information retrieval. J. Am. Med. Inform. Assoc. 2005, 12, 296–298. [Google Scholar] [CrossRef] [PubMed]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| Operating system | Ubuntu 20.04.1 LTS |
| Deep learning framework | Pytorch 1.9.1 |
| Programming language | Python 3.8 |
| GPU accelerated environment | CUDA 11.1 |
| GPU | NVIDIA GeForce GTX 2080 SUPER |
| CPU | Intel(R) Core(TM) i7-10700K @ 3.80 GHz × 16 |
| Module | Number | Arguments | Params |
|---|---|---|---|
| Focus | 1 | [3, 32, 3] | 4656 |
| Conv | 1 | [32, 64, 3, 2] | 20,816 |
| C3CBAM | 1 | [64, 64, 1] | 20,130 |
| Conv | 1 | [64, 128, 3, 2] | 78,480 |
| C3CBAM | 3 | [128, 128, 3] | 116,310 |
| Conv | 1 | [128, 256, 3, 2] | 304,400 |
| C3CBAM | 3 | [256, 256, 3] | 423,670 |
| Conv | 1 | [256, 512, 3, 2] | 1,215,008 |
| SPPF | 1 | [512, 512, 5] | 700,208 |
| C3TR | 1 | [512, 512, 1, False] | 1,235,264 |
| Algorithm | Abbreviation | Precision (%) | Recall (%) | Average Precision (%) | Fβ Score | Weight Size/M |
|---|---|---|---|---|---|---|
| YOLOv5 | A | 81.94 | 92.60 | 90.79 | 0.9025 | 13.7 |
| YOLOv5 + Focus | B | 82.55 | 93.79 | 91.67 | 0.9130 | 13.7 |
| YOLOv5 + Focus + CBAM | C | 79.01 | 94.67 | 92.32 | 0.9103 | 13.2 |
| YOLOv5 + Focus + CBAM + TR | D | 81.33 | 94.08 | 91.94 | 0.9122 | 13.2 |
| YOLOv5 + Focus + CBAM + TR + BiFPN | E | 81.79 | 94.97 | 92.98 | 0.9200 | 13.3 |
| YOLOv5 + Focus + CBAM + TR + BiFPN + Meta-ACON | F | 80.05 | 97.34 | 95.13 | 0.9331 | 14.2 |
| Algorithm | Resolution | Precision (%) | Recall (%) | Average Precision (%) | Fβ Score | Weight Size/M |
|---|---|---|---|---|---|---|
| YOLOv4 | 640 × 640 | 90.32 | 69.98 | 79.00 | 0.7328 | 244 |
| YOLOv5 | 640 × 640 | 81.94 | 92.60 | 90.79 | 0.9025 | 13.7 |
| YOLOv7 | 640 × 640 | 78.43 | 94.67 | 92.78 | 0.9091 | 71.3 |
| YOLOv5-GAP | 640 × 640 | 80.05 | 97.34 | 95.13 | 0.9331 | 14.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Wu, F.; Wang, M.; Chen, Z.; Li, L.; Zou, X. Grape-Bunch Identification and Location of Picking Points on Occluded Fruit Axis Based on YOLOv5-GAP. Horticulturae 2023, 9, 498. https://doi.org/10.3390/horticulturae9040498
Zhang T, Wu F, Wang M, Chen Z, Li L, Zou X. Grape-Bunch Identification and Location of Picking Points on Occluded Fruit Axis Based on YOLOv5-GAP. Horticulturae. 2023; 9(4):498. https://doi.org/10.3390/horticulturae9040498
Chicago/Turabian StyleZhang, Tao, Fengyun Wu, Mei Wang, Zhaoyi Chen, Lanyun Li, and Xiangjun Zou. 2023. "Grape-Bunch Identification and Location of Picking Points on Occluded Fruit Axis Based on YOLOv5-GAP" Horticulturae 9, no. 4: 498. https://doi.org/10.3390/horticulturae9040498
APA StyleZhang, T., Wu, F., Wang, M., Chen, Z., Li, L., & Zou, X. (2023). Grape-Bunch Identification and Location of Picking Points on Occluded Fruit Axis Based on YOLOv5-GAP. Horticulturae, 9(4), 498. https://doi.org/10.3390/horticulturae9040498