A Siamese Neural Network for Non-Invasive Baggage Re-Identification





Abstract
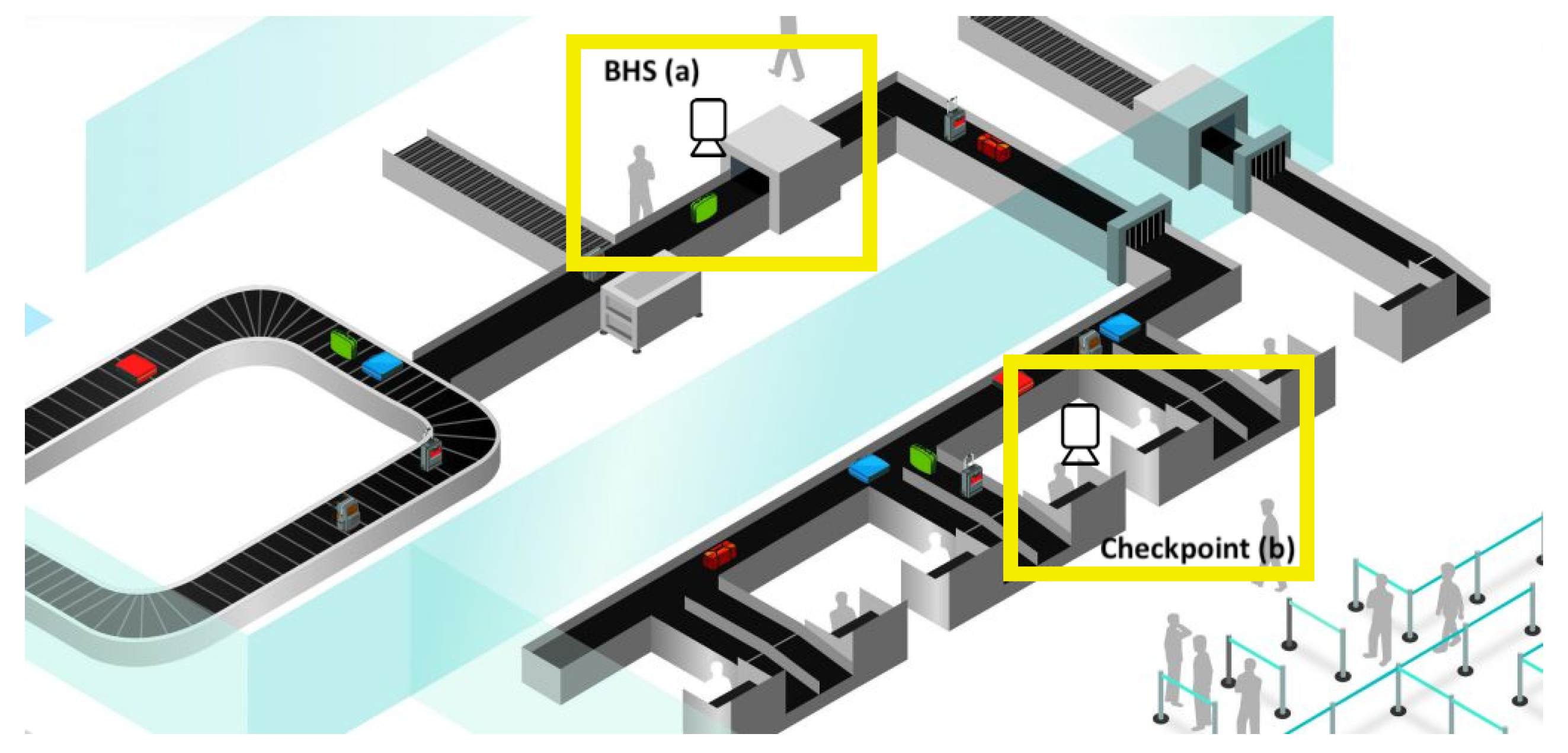
:1. Introduction
- tags accidentally fall off during check-in/check-out procedures, and/or transfer process;
- passengers deliberately remove tags; and,
- in presence of metallic baggage: in this case, the RFID technology could work in a wrong way producing false positives and/or false negatives.
2. Related Work
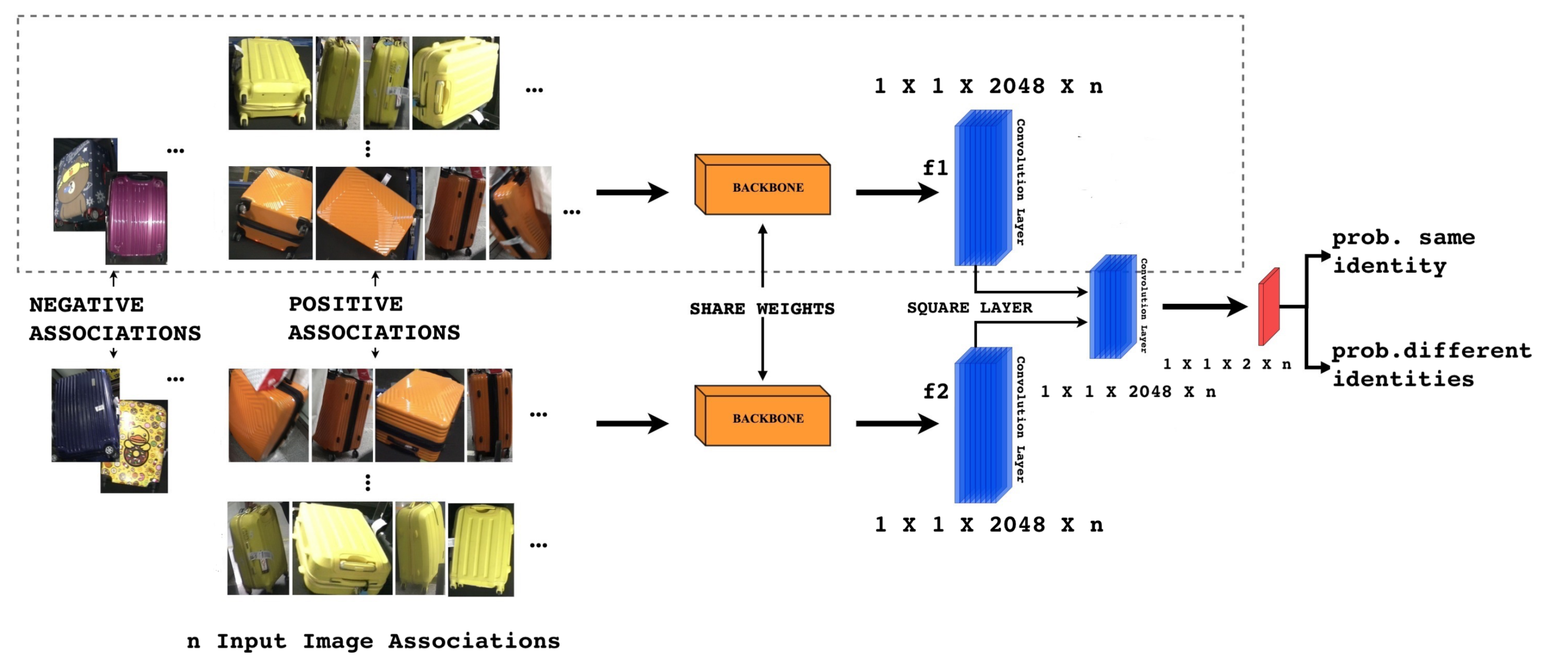
3. Proposed System
3.1. Network Fine-Tuning
3.2. Similarity Loss
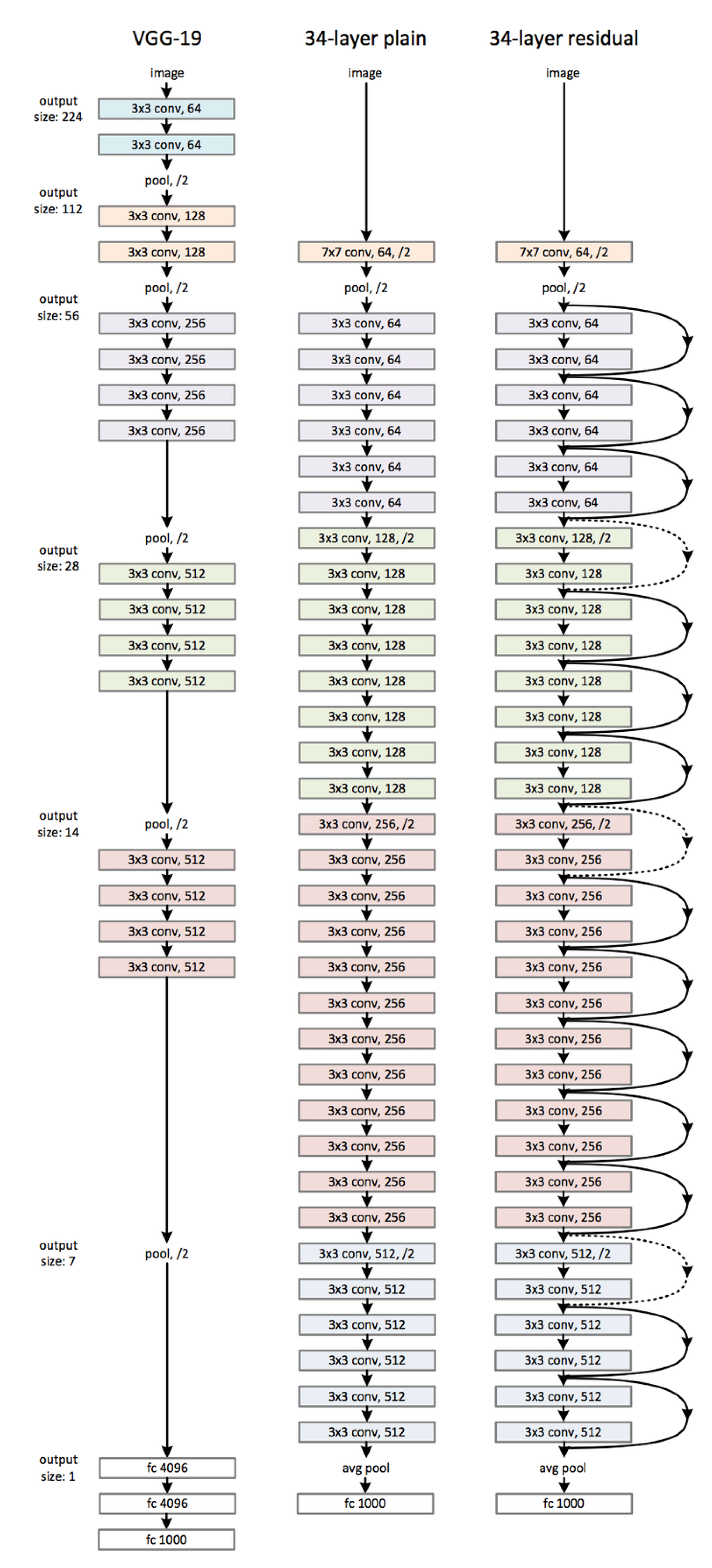
3.3. Backbone
3.3.1. ResNet
- for the same output feature map size, the layers have the same number of filters; and,
- if the feature map size is halved, the number of filters is doubled, so as to preserve the time complexity per layer.
- the shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; and,
- the projection shortcut is used to match dimensions (done by convolutions).
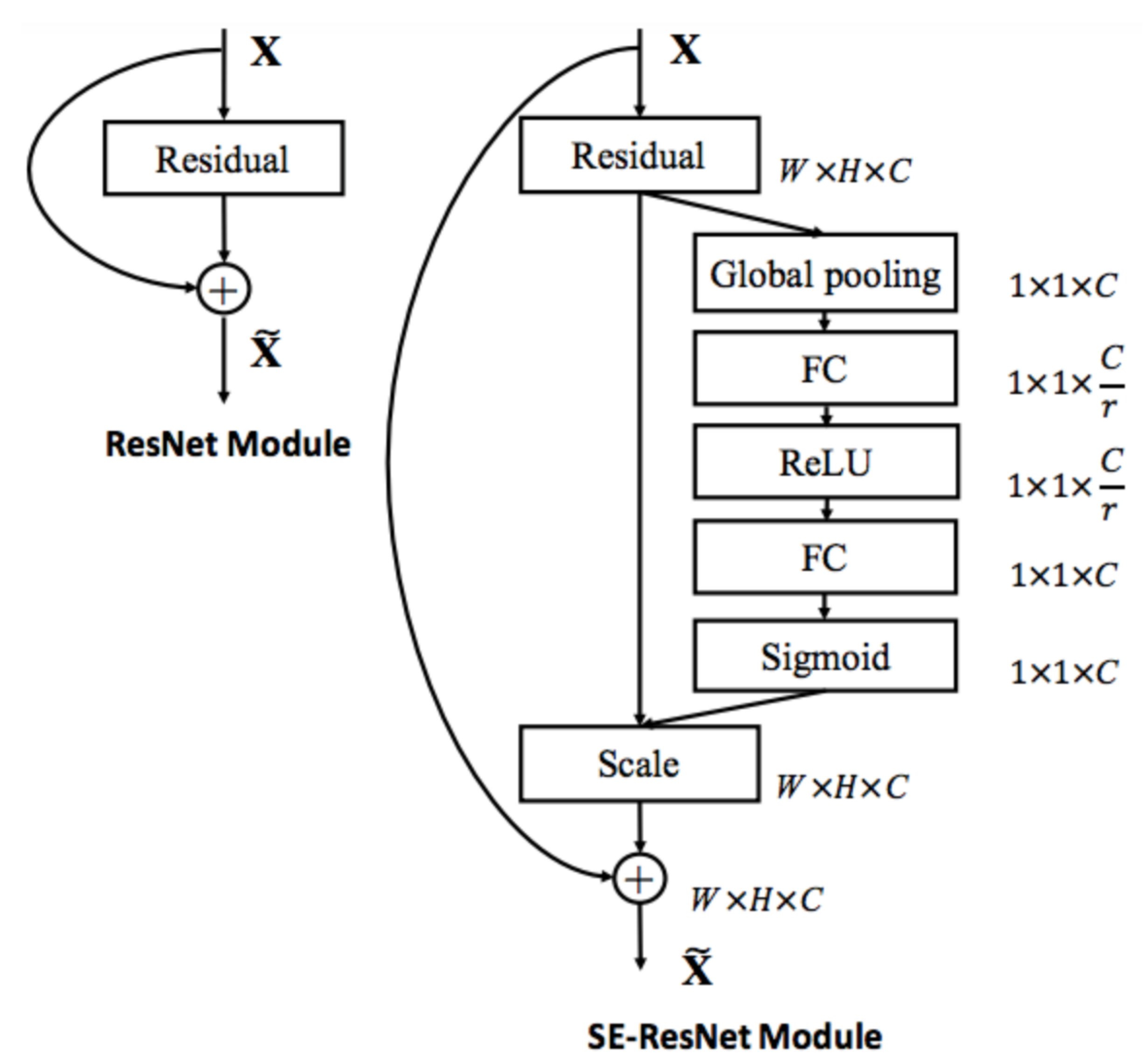
3.3.2. SENet
- the function is given an input convolutional block and the current number of channels it has;
- we squeeze each channel to a single numeric value using average pooling;
- A fully connected layer followed by a ReLU function adds the necessary nonlinearity. Its output channel complexity is also reduced by a certain ratio;
- a second fully connected layer followed by a Sigmoid activation gives each channel a smooth gating function; and,
- at last, we weight each feature map of the convolutional block based on the result of our side network.
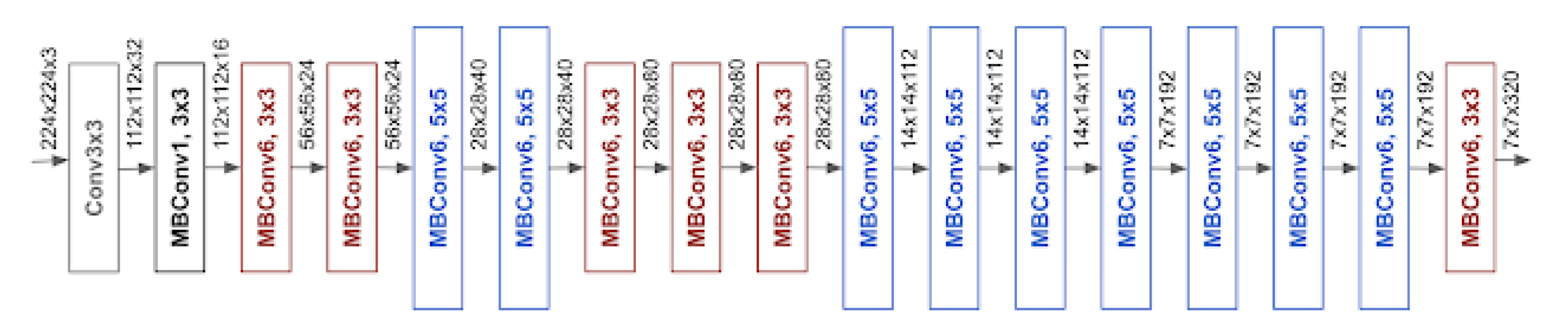
3.3.3. EfficientNet
4. Experimental Results
4.1. MVB Dataset
4.2. Implementation Details
4.3. Comparison with Other Datasets
- Market1501 [32] contains 32.668 annotated bounding boxes of 1.501 identities. Images of each identity are captured by at most six cameras. According to the dataset setting, the training set contains 12,936 cropped images of 751 identities and testing set contains 19.732 cropped images of 750 identities.
- CUHK03 dataset [14] is composed by 14.097 cropped images of 1.467 identities collected in the CUHK campus. Each identity is observed by two camera views and has 4.8 images in average for each view. Following the setting of the dataset, the dataset is partitioned into a training set of 1367 persons and a testing set of 100 persons.
5. Conclusions and Future Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.; Li, D.; Wu, J.; Sun, Y.; Zhang, L. MVB: A Large-Scale Dataset for Baggage Re-Identification and Merged Siamese Networks. In PRCV 2019: Pattern Recognition and Computer Vision, Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xi’an, China, 8–11 November 2019; Springer: Berlin, Germany, 2019. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.; Hicks, S.L.; Torr, P.H.S. Struck: Structured Output Tracking with Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bashir, R.M.S.; Shahzad, M.; Fraz, M. VR-PROUD: Vehicle re-identification using progressive unsupervised deep architecture. Pattern Recognit. 2019, 90, 52–65. [Google Scholar] [CrossRef]
- Kuma, R.; Weill, E.; Aghdasi, F.; Sriram, P. Vehicle re-identification: An efficient baseline using triplet embedding. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–9. [Google Scholar]
- Zhu, J.; Zeng, H.; Huang, J.; Liao, S.; Lei, Z.; Cai, C.; Zheng, L. Vehicle re-identification using quadruple directional deep learning features. IEEE Trans. Intell. Transp. Syst. 2019, 21, 410–420. [Google Scholar] [CrossRef]
- Yang, J.; Wang, M.; Li, M.; Zhang, J. Enhanced Deep Feature Representation for Person Search; Computer Vision; Yang, J., Hu, Q., Cheng, M.M., Wang, L., Liu, Q., Bai, X., Meng, D., Eds.; Springer: Singapore, 2017; pp. 315–327. [Google Scholar]
- Wu, L.; Shen, C.; Van den Hengel, A. Deep Linear Discriminant Analysis on Fisher Networks: A Hybrid Architecture for Person Re-identification. Pattern Recognit. 2016, 65, 238–250. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the ECCV (7), Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1249–1258. [Google Scholar]
- Jin, H.; Wang, X.; Liao, S.; Li, S.Z. Deep person re-identification with improved embedding and efficient training. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 261–267. [Google Scholar]
- Wu, D.; Zheng, S.J.; Zhang, X.P.; Yuan, C.A.; Cheng, F.; Zhao, Y.; Lin, Y.J.; Zhao, Z.Q.; Jiang, Y.L.; Huang, D.S. Deep learning-based methods for person re-identification: A comprehensive review. Neurocomputing 2019, 337, 354–371. [Google Scholar] [CrossRef]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep Metric Learning for Person Re-identification. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Wu, L.; Shen, C.; Van den Hengel, A. PersonNet: Person Re-identification with Deep Convolutional Neural Networks. arXiv 2016, arXiv:1601.07255. [Google Scholar]
- Köstinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.; Bischof, H. Large Scale Metric Learning from Equivalence Constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 1988–1996. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. A Discriminatively Learned CNN Embedding for Person Reidentification. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 14. [Google Scholar] [CrossRef]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR’14, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1386–1393. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Ding, S.; Lin, L.; Wang, G.; Chao, H.Y. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognit. 2015, 48, 2993–3003. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Shen, C.; Van den Hengel, A. Deep Recurrent Convolutional Networks for Video-based Person Re-identification: An End-to-End Approach. arXiv 2016, arXiv:1606.01609. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in Vitro. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3774–3782. [Google Scholar]
- Lavi, B.; Serj, M.F.; Ullah, I. Survey on Deep Learning Techniques for Person Re-Identification Task. arXiv 2018, arXiv:1807.05284. [Google Scholar]
- Yi, D.; Lei, Z.; Li, S.Z. Deep Metric Learning for Practical Person Re-Identification. arXiv 2014, arXiv:1407.4979. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level Factorisation Net for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2109–2118. [Google Scholar]
- Spagnolo, P.; Filieri, F.; Distante, C.; Mazzeo, P.L.; D’Ambrosio, P. A new annotated dataset for boat detection and re-identification. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | h × w | lr | Batch Size | |
|---|---|---|---|---|
| ResNet50 [27] | 0.05 | 64 | ||
| SENet [28] | 0.05 | 32 | ||
| EfficientNet-b5 [29] | 0.05 | 64 |
| Backbone | Rank1 (%) | Rank5 (%) | Rank10 (%) | mAP |
|---|---|---|---|---|
| ResNet50 [27] | 64.82 | 85.26 | 90.68 | 61.65 |
| SENet [28] | 67.49 | 85.26 | 90.68 | 63.58 |
| EfficientNet-b5 [29] | 69.10 | 85.74 | 90.68 | 63.11 |
| Architecture | Rank1 (%) |
|---|---|
| Proposed | 69.10 |
| MVB [1] | 50.19 |
| Method | mAP | Rank-1 |
|---|---|---|
| RESNET50 | 86.78 | 98.85 |
| SENet | 84.91 | 96.64 |
| EfficientNet-b5 | 89.92 | 98.85 |
| Market1501 Dataset [32] | CUHK03 Dataset [14] | |||
|---|---|---|---|---|
| Method | Rank1(%) | mAP (%) | Rank1(%) | mAP |
| CNN embedding (CaffeNet [19]) | 62.14 | 39.61 | 59.80 | 65.80 |
| CNN embedding (VGG16 [19]) | 70.16 | 47.45 | 71.8 | 76.5 |
| CNN embedding (ResNet-50 [19]) | 79.51 | 59.87 | 83.4 | 86.4 |
| Ours (ResNet-50) | 77.13 | 58.42 | 79.8 | 78.2 |
| Ours (SENet) | 82.53 | 71.18 | 82.8 | 89.3 |
| Ours (EfficientNet-b5) | 85.79 | 80.92 | 89.6 | 89.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazzeo, P.L.; Libetta, C.; Spagnolo, P.; Distante, C. A Siamese Neural Network for Non-Invasive Baggage Re-Identification. J. Imaging 2020, 6, 126. https://doi.org/10.3390/jimaging6110126
Mazzeo PL, Libetta C, Spagnolo P, Distante C. A Siamese Neural Network for Non-Invasive Baggage Re-Identification. Journal of Imaging. 2020; 6(11):126. https://doi.org/10.3390/jimaging6110126
Chicago/Turabian StyleMazzeo, Pier Luigi, Christian Libetta, Paolo Spagnolo, and Cosimo Distante. 2020. "A Siamese Neural Network for Non-Invasive Baggage Re-Identification" Journal of Imaging 6, no. 11: 126. https://doi.org/10.3390/jimaging6110126
APA StyleMazzeo, P. L., Libetta, C., Spagnolo, P., & Distante, C. (2020). A Siamese Neural Network for Non-Invasive Baggage Re-Identification. Journal of Imaging, 6(11), 126. https://doi.org/10.3390/jimaging6110126