
A New Visual Inertial Simultaneous Localization and Mapping (SLAM) Algorithm Based on Point and Line Features


Abstract
:1. Introduction
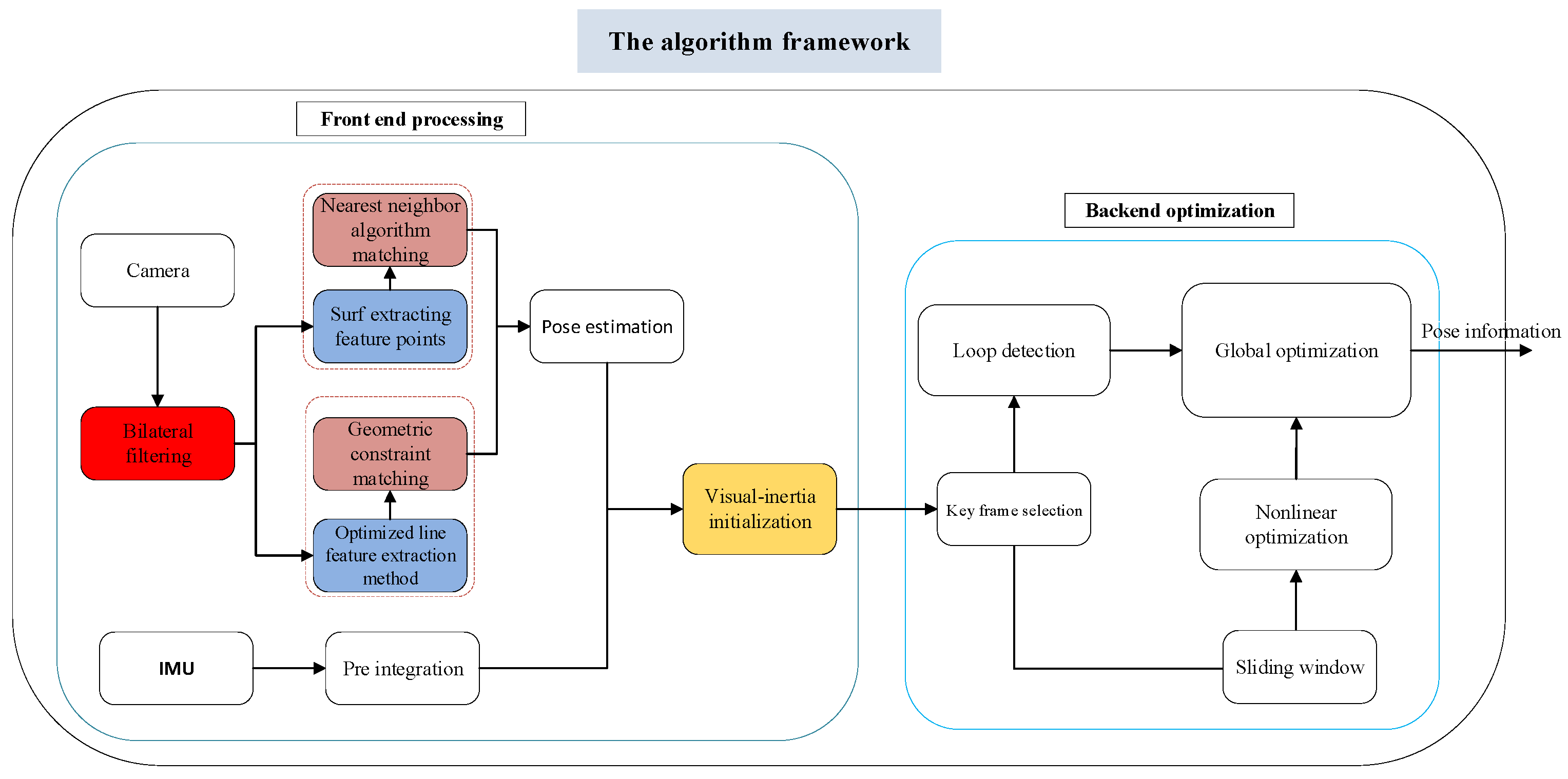
2. The Algorithm Framework
- (1)
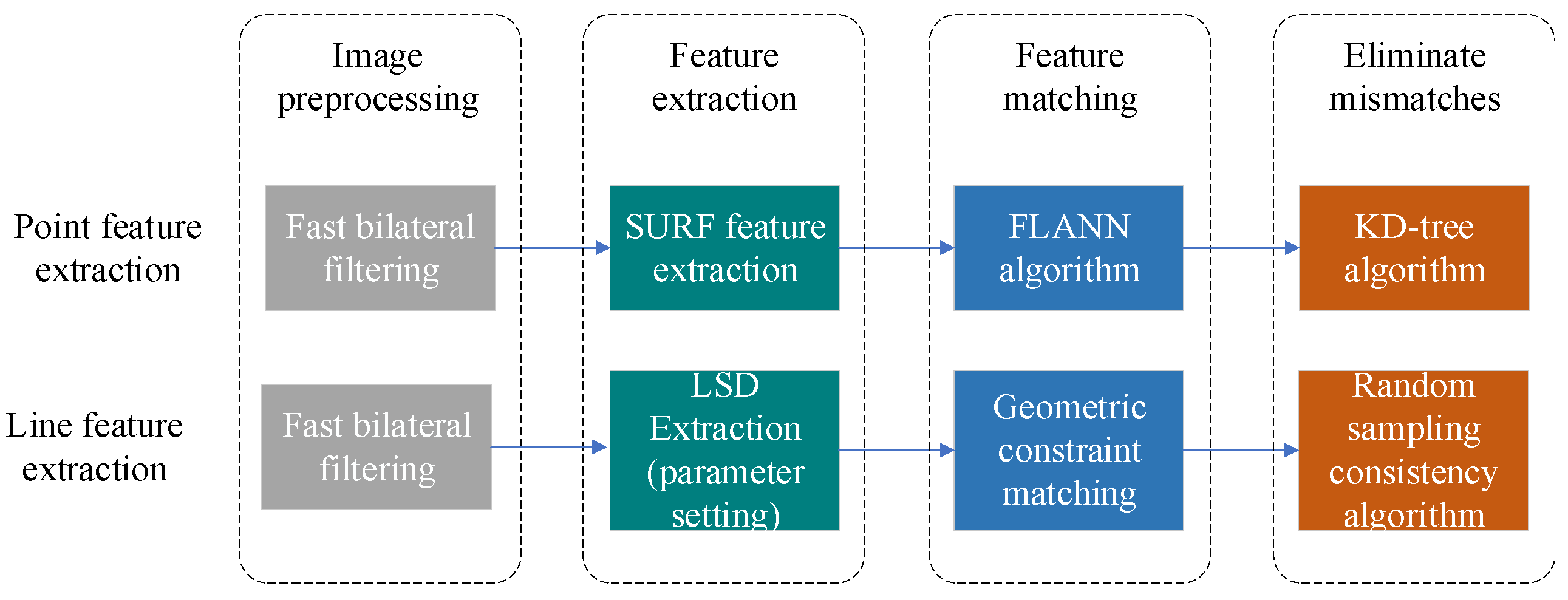
- The SURF algorithm can extract stable features even at the circumstances of translation, rotation and perspective change, so this paper uses the SURF algorithm to extract point features. The traditional optical flow tracking method is not suitable for the environment with drastic light changes. The matching algorithm used in this paper is the fast nearest-neighbor algorithm (FLNN) [20], which can link to the SURF parameters.
- (2)
- In terms of online feature extraction and matching, LSD algorithm was initially proposed to describe the contour of the object, which is not suitable for line segment positioning in space. Therefore, the parameters of LSD algorithm need to be adjusted, and an adaptive line segment constraint method is proposed to greatly reduce the time required for line feature matching. Based on the work of Gomez-Ojed [21], a constraint method of pole-geometry and point-line affine invariants is proposed to improve the speed of line feature processing.
- (3)
- Point-line feature SLAM based on nonlinear optimization has the defects of long inertial initialization time and poor stability. In this paper, a step-by-step joint initialization [21] method is used to improve stability and reduce initialization time.
3. Front End Processing
3.1. The Image Processing
- (1)
- Using the point features of the first image as the training set and the point features of the second image as the query set, the Euclidean distances between all the point features in the training set and the point features in the query set are obtained.
- (2)
- By comparing Euclidean distances, the closest and second closest points of Euclidean distance between each point feature of training set and point feature of query set are preserved, and the remaining matches are discarded. Euclidean distance is:
- (3)
- If the nearest Euclidean distance and the sub-nearest Euclidean distance satisfy Formula (6) keep the matching pair, otherwise delete the matching pair. Wherein, ratio is the threshold for judging the difference between the matching pair of the nearest Euclidean distance and the matching pair of the sub-nearest Euclidean distance (0 < ratio < 1). The larger the ratio, the more matching pairs, and the lower the matching accuracy. The smaller the ratio value, the fewer matching pairs, and the higher matching accuracy. Through experiments, it is found that when the ratio is 0.6, the number of point feature matching can reach 150, and the error of matching is small.
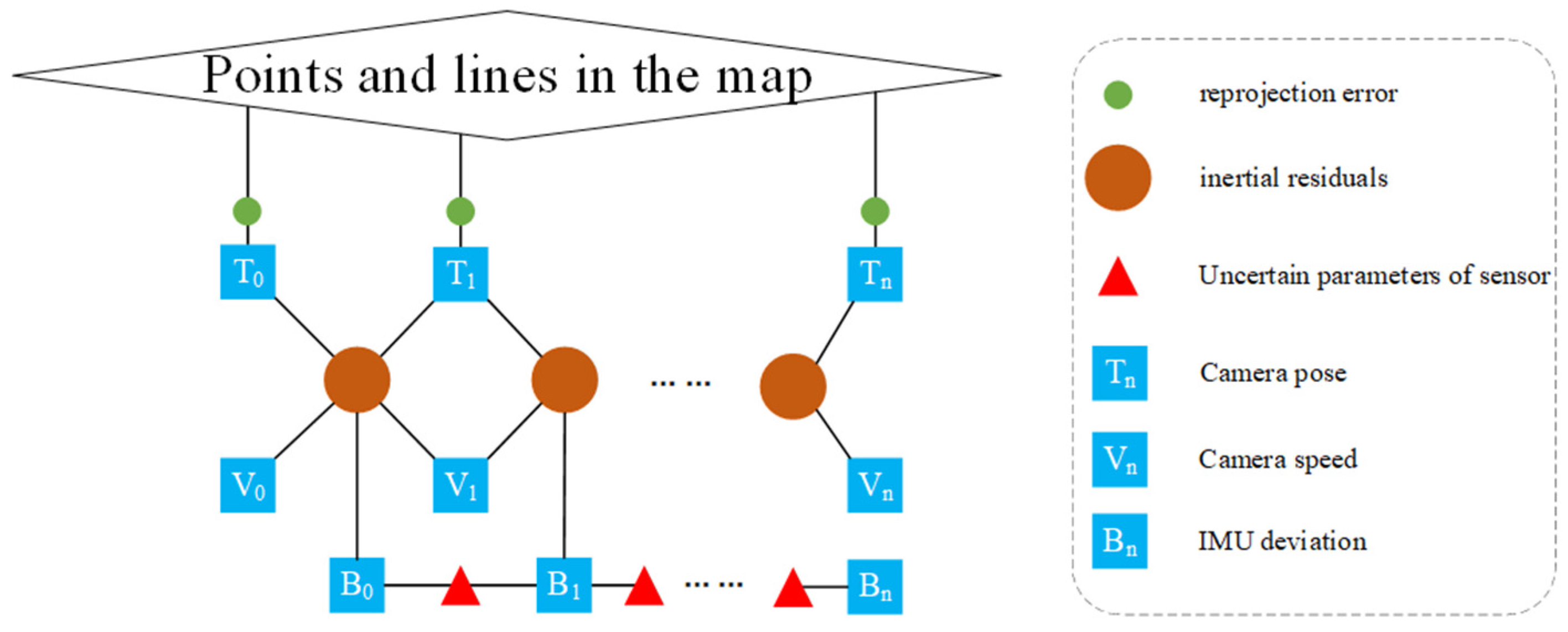
3.2. Visual-Inertia Initialization
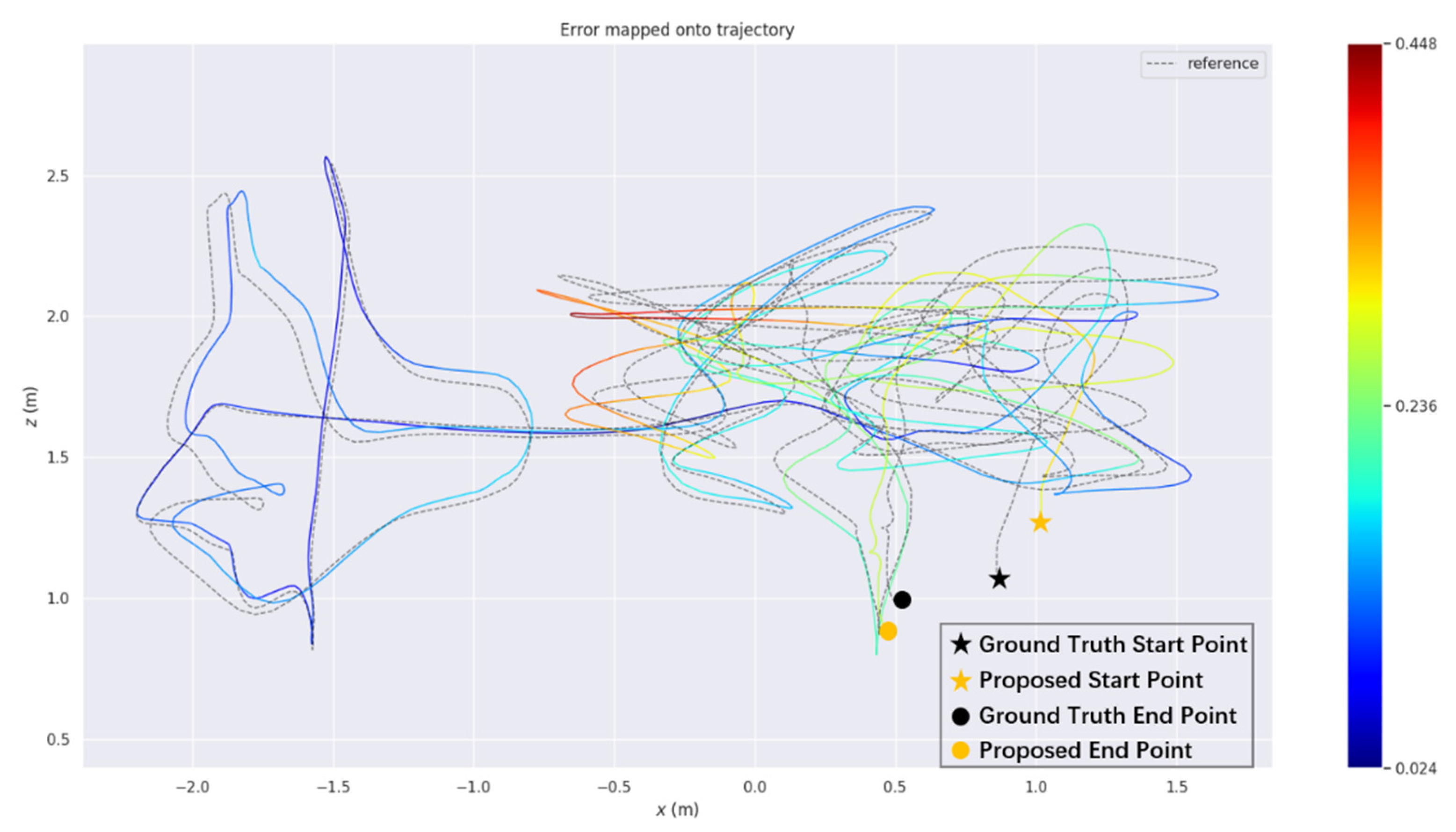
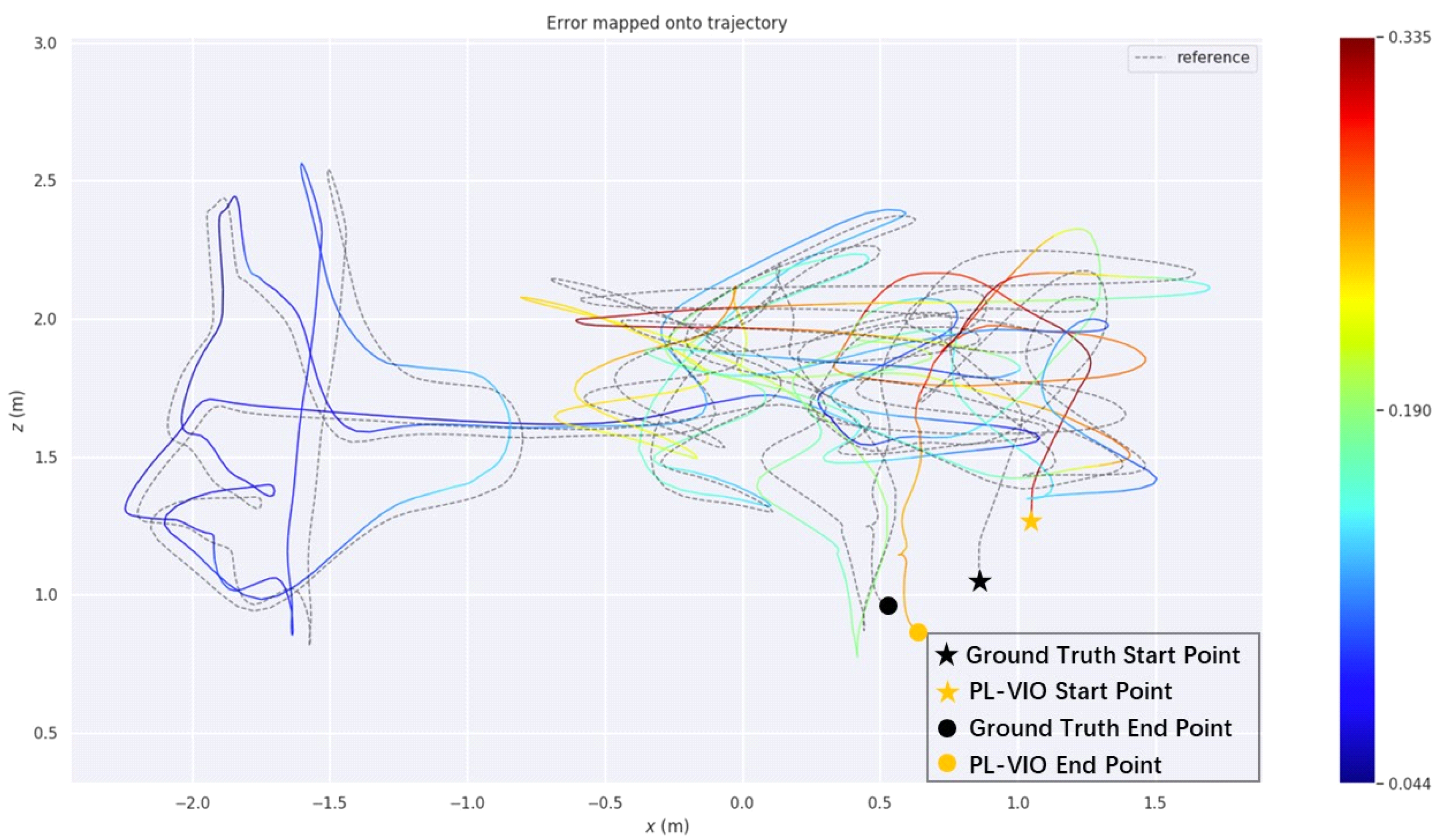
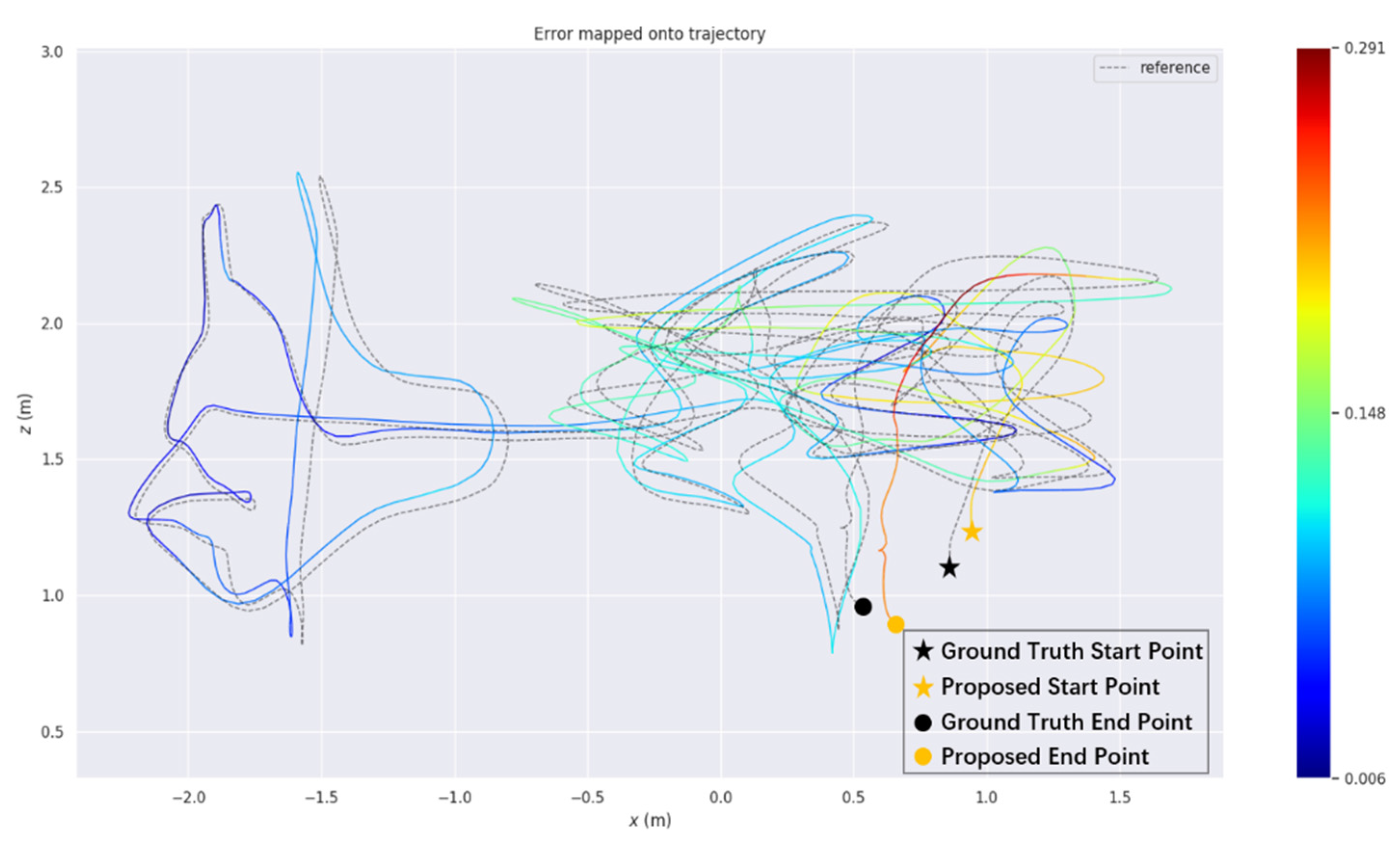
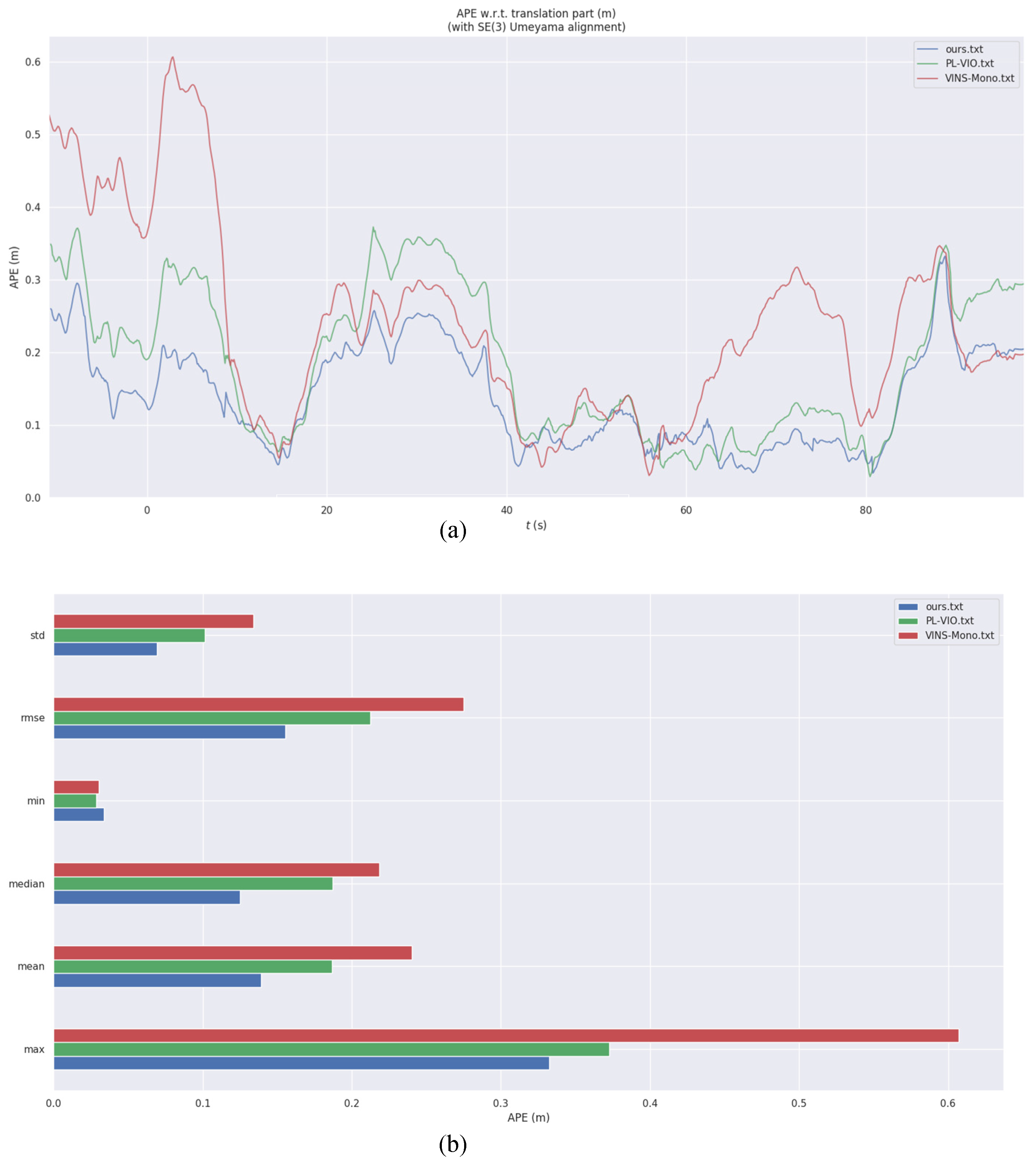
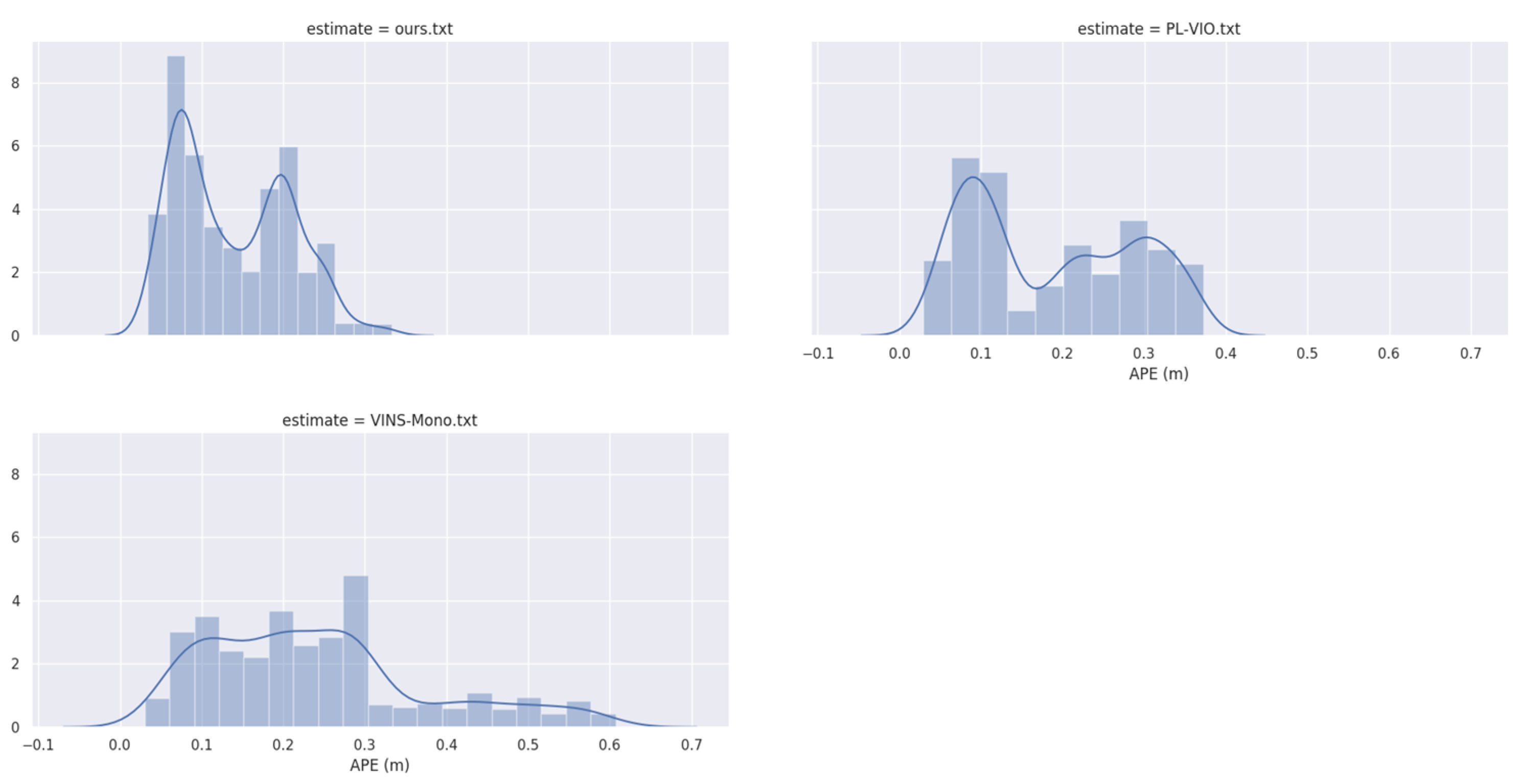
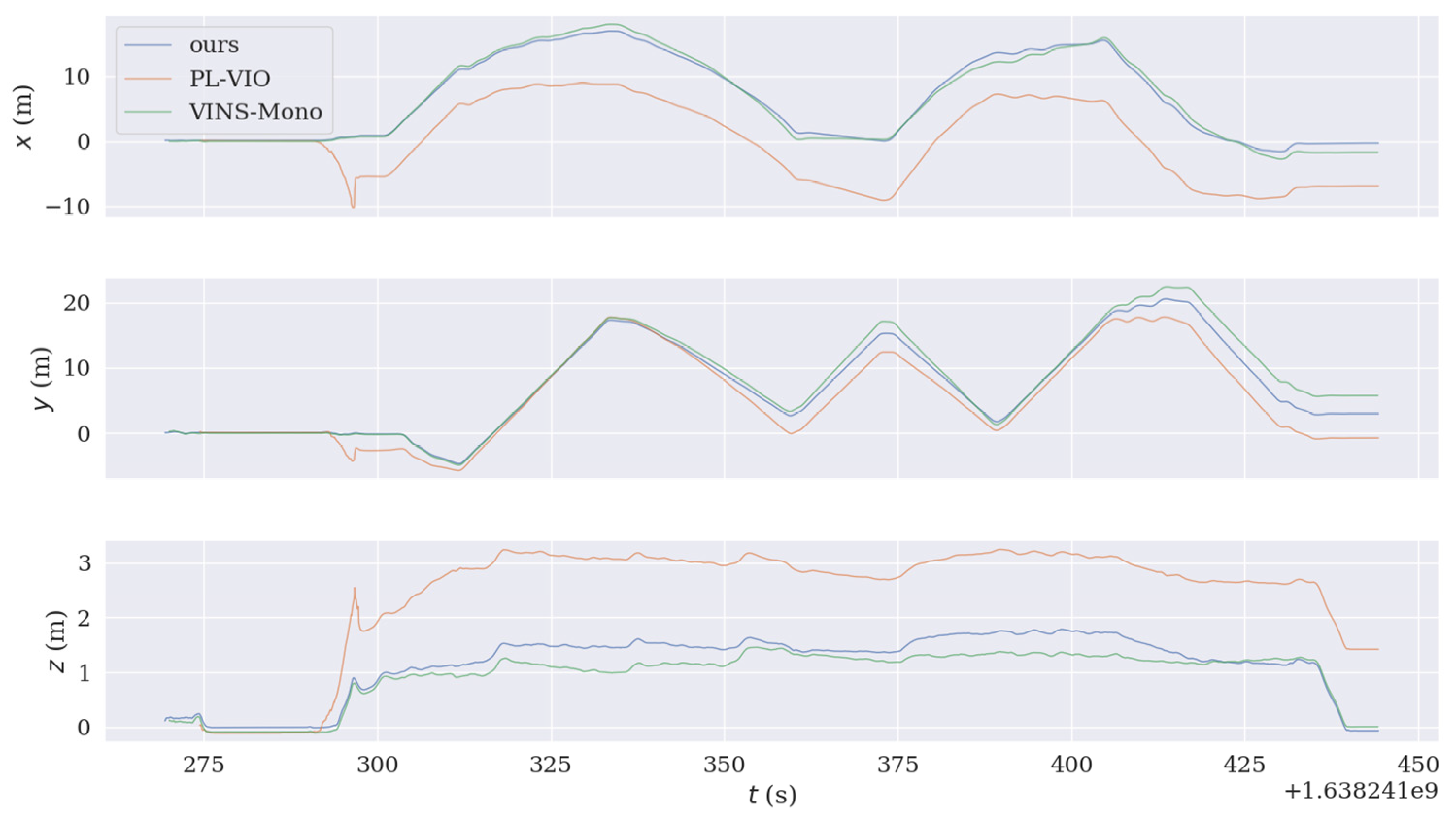
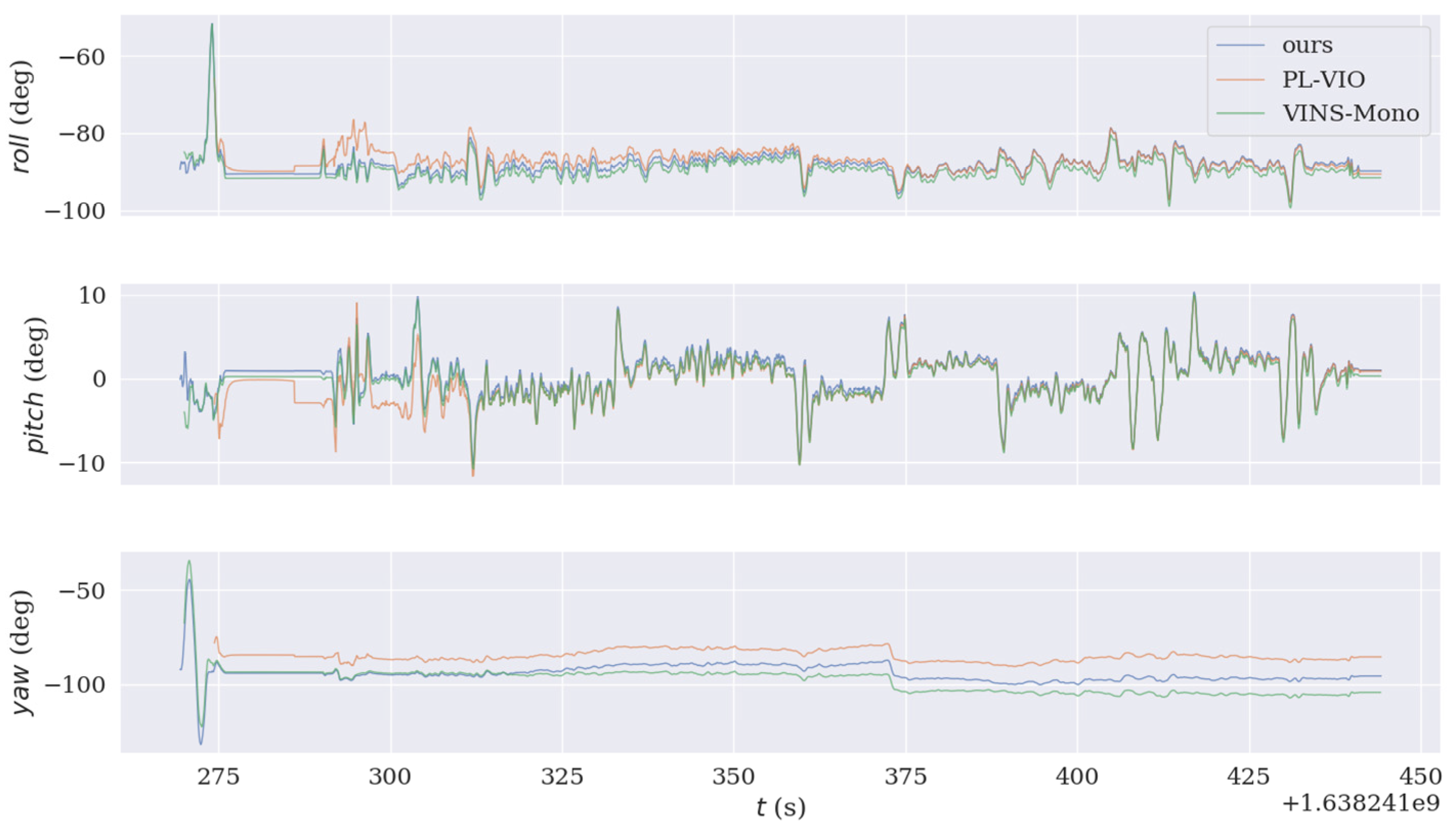
4. Experimental Results and Their Analysis
Actual Scene Experiment
5. Conclusions
- (1)
- Adding bilateral filtering algorithm to SLAM front-end image preprocessing module can effectively reduce image noise and the difficulty of point-line feature extraction.
- (2)
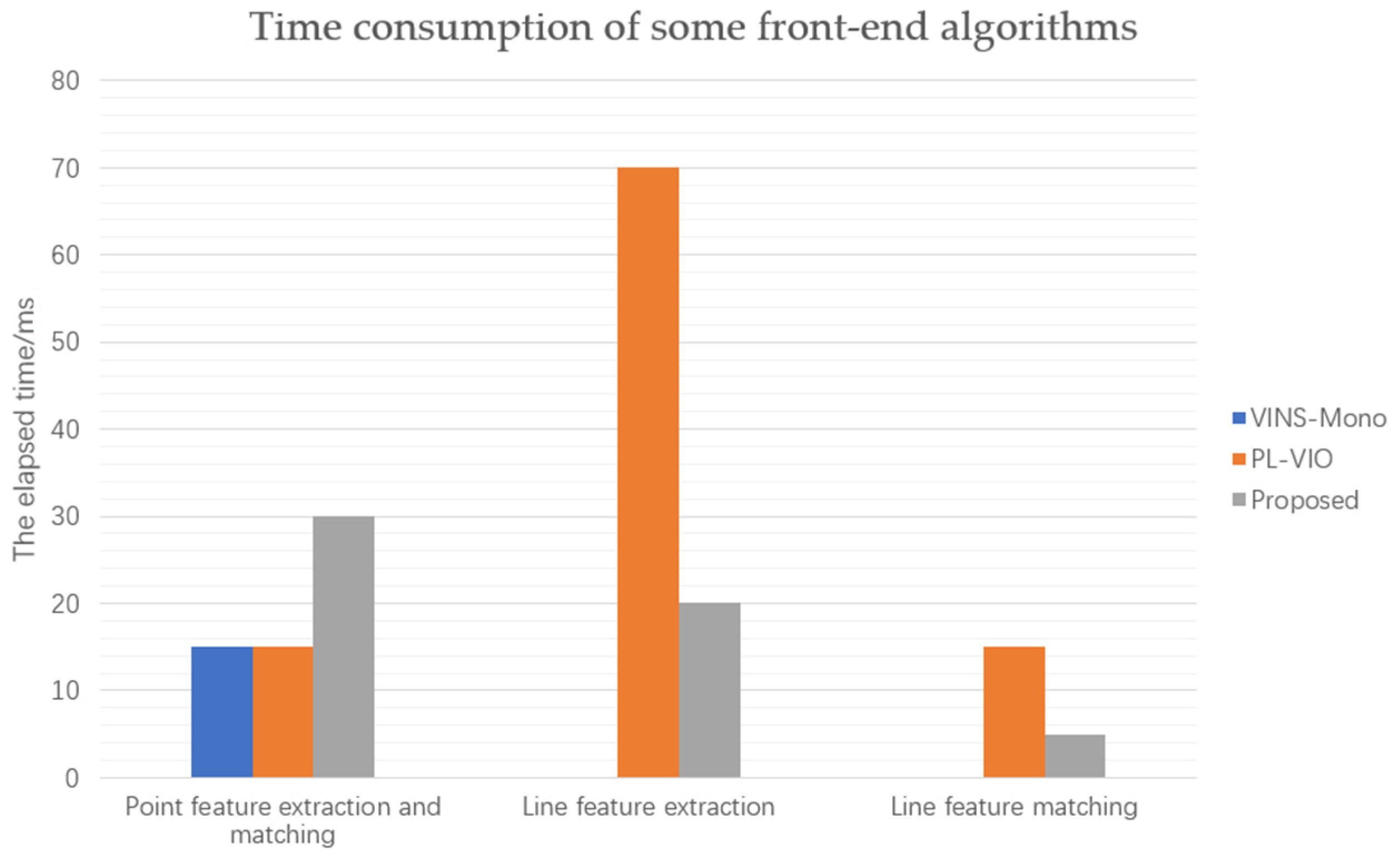
- Aiming at the problem of image blur when the camera moves, SURF algorithm and FLANN matching algorithm are adopted. Although the overall consumption time of processing point features is slightly increased, the positioning accuracy is significantly improved.
- (3)
- The parameters of LSD line feature extraction algorithm are selected, and the extraction speed is increased by 3 times by using length suppression strategy line feature. A line feature matching method based on geometric constraints is proposed, and the matching time of line segments is reduced by 66.66%.
- (4)
- The step joint initialization method greatly reduces the initialization time, improves accuracy and makes the location trajectory smoother.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Latif, Y.; Doan, A.D.; Chin, T.J.; Reid, I. Sprint: Subgraph place recognition for intelligent transportation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5408–5414. [Google Scholar]
- Bryson, M.; Sukkarieh, S. Building a Robust Implementation of Bearing-only Inertial SLAM for a UAV. J.-Ournal Field Robot. 2010, 24, 113–143. [Google Scholar] [CrossRef] [Green Version]
- Geneva, P.; Eckenhoff, K.; Huang, G. A Linear-Complexity EKF for Visual-Inertial Navigation with Loop Clo-sures. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- 4. Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2016, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Burdziakowski, P. Towards precise visual navigation and direct georeferencing for MAV using ORB-SLAM2. In Proceedings of the Baltic Geodetic Congress (BGC Geomatics), Gdansk, Poland, 22–25 June 2017; pp. 394–398. [Google Scholar]
- Aguilar, W.G.; Rodríguez, G.A.; Álvarez, L.; Sandoval, S.; Quisaguano, F.J.; Limaico, A. Visual SLAM with a RGB-D camera on a quadrotor UAV using on-board processing. In International Work-Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2017; pp. 596–606. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2003, 20, 91–110. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International conference on computer vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Vakhitov, A.; Funke, J.; Moreno-Noguer, F. Accurate and Linear Time Pose Estimation from Points and Lines. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Cham, Switzerland, 2016; pp. 583–599. [Google Scholar]
- Zuo, X.; Xie, X.; Liu, Y.; Huang, G. Robust Visual SLAM with point and line features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1775–1782. [Google Scholar]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the IEEE international conference on robotics and automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. Pl-VIO: Tightly-coupled monocular visual–inertial odometry using point and line features. Sensors 2018, 18, 1159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wen, H.; Tian, J.; Li, D. PLS-VIO: Stereo Vision-inertial Odometry Based on Point and Line Features. In Proceedings of the IEEE International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Vientiane, Laos, 23–23 May 2020; pp. 1–7. [Google Scholar]
- Fu, Q.; Wang, J.; Yu, H.; Ali, I.; Guo, F.; He, Y.; Zhang, H. PL-VINS: Real-Time Monocular Visual-Inertial SLAM with Point and Line. arXiv 2020, arXiv:2009.07462. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the IEEE Sixth International Conference on Computer Vision, Bombay, India, 4–7 January 1998; pp. 839–846. [Google Scholar]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A fast line segment detector with a false detection co-ntrol. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Muja, M.; Lowe, D.G. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. In Proceedings of the International Conference on Computer Vision Theory & Application Vissapp, Lisboa, Portugal, 5–8 February 2009; Volume 2, pp. 331–340. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Chaudhury, K.N.; Sage, D.; Unser, M. Fast O (1) bilateral filtering using trigonometric range kernels. IEEE Trans. Image Process. 2011, 20, 3376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial | VINS-Mono | PL-VIO | Ours |
|---|---|---|---|
| MH_01_easy | 0.355 | 0.129 | 0.145 |
| MH_02_easy | 0.343 | 0.183 | 0.150 |
| MH_03_medium | 0.558 | 0.262 | 0.218 |
| MH_04_difficult | 0.595 | 0.377 | 0.224 |
| MH_05_difficult | 0.587 | 0.283 | 0.257 |
| V1_01_easy | 0.359 | 0.166 | 0.085 |
| V1_03_difficult | 0.529 | 0.221 | 0.148 |
| V2_01_easy | 0.280 | 0.109 | 0.128 |
| V2_02_medium | 0.546 | 0.174 | 0.150 |
| V2_03_difficult | 0.572 | 0.319 | 0.183 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Liu, C.; Li, J.; Pang, M.; Wang, M. A New Visual Inertial Simultaneous Localization and Mapping (SLAM) Algorithm Based on Point and Line Features. Drones 2022, 6, 23. https://doi.org/10.3390/drones6010023
Zhang T, Liu C, Li J, Pang M, Wang M. A New Visual Inertial Simultaneous Localization and Mapping (SLAM) Algorithm Based on Point and Line Features. Drones. 2022; 6(1):23. https://doi.org/10.3390/drones6010023
Chicago/Turabian StyleZhang, Tong, Chunjiang Liu, Jiaqi Li, Minghui Pang, and Mingang Wang. 2022. "A New Visual Inertial Simultaneous Localization and Mapping (SLAM) Algorithm Based on Point and Line Features" Drones 6, no. 1: 23. https://doi.org/10.3390/drones6010023
APA StyleZhang, T., Liu, C., Li, J., Pang, M., & Wang, M. (2022). A New Visual Inertial Simultaneous Localization and Mapping (SLAM) Algorithm Based on Point and Line Features. Drones, 6(1), 23. https://doi.org/10.3390/drones6010023