


A Novel Adversarial Detection Method for UAV Vision Systems via Attribution Maps
Abstract
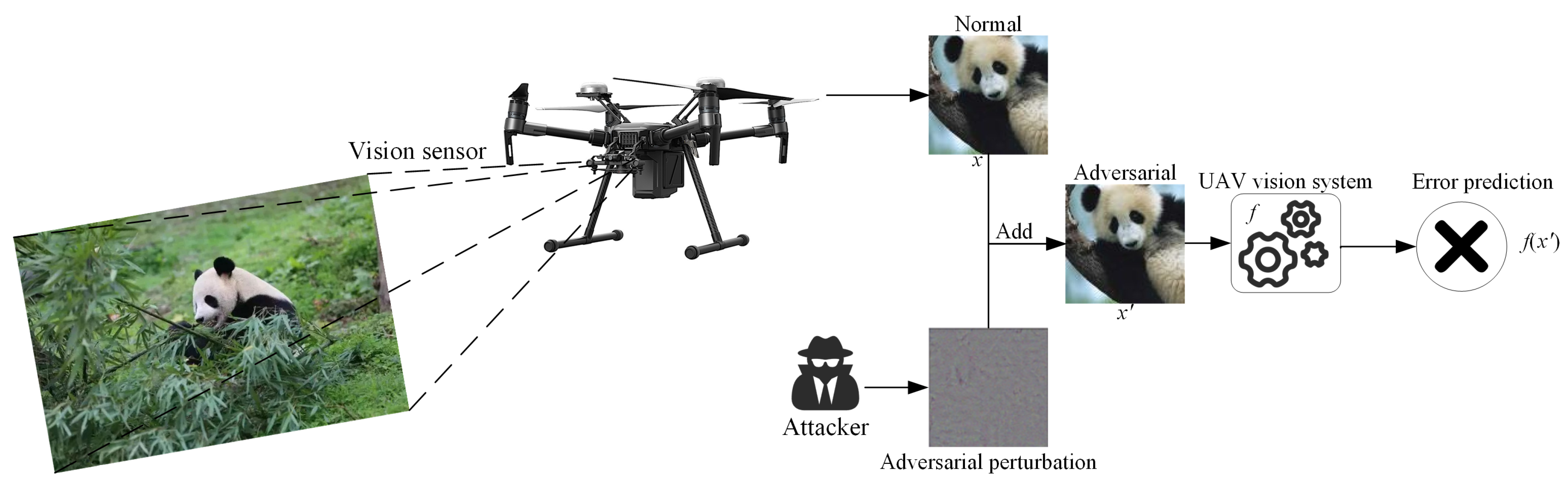
:1. Introduction
2. Related Works
2.1. Adversarial Attacks
2.2. Adversarial Example-Detection Technology
2.3. Model Visualization Methods
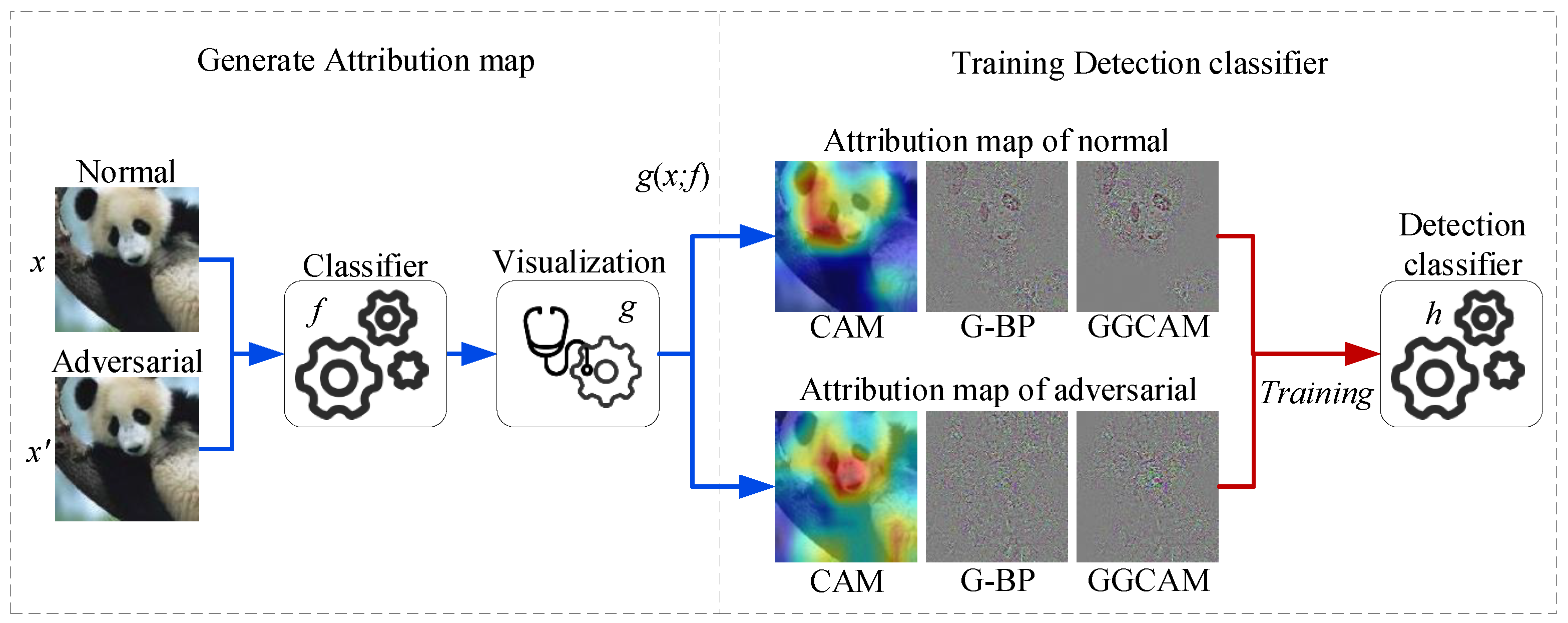
3. Methodology
4. The Proposed Method
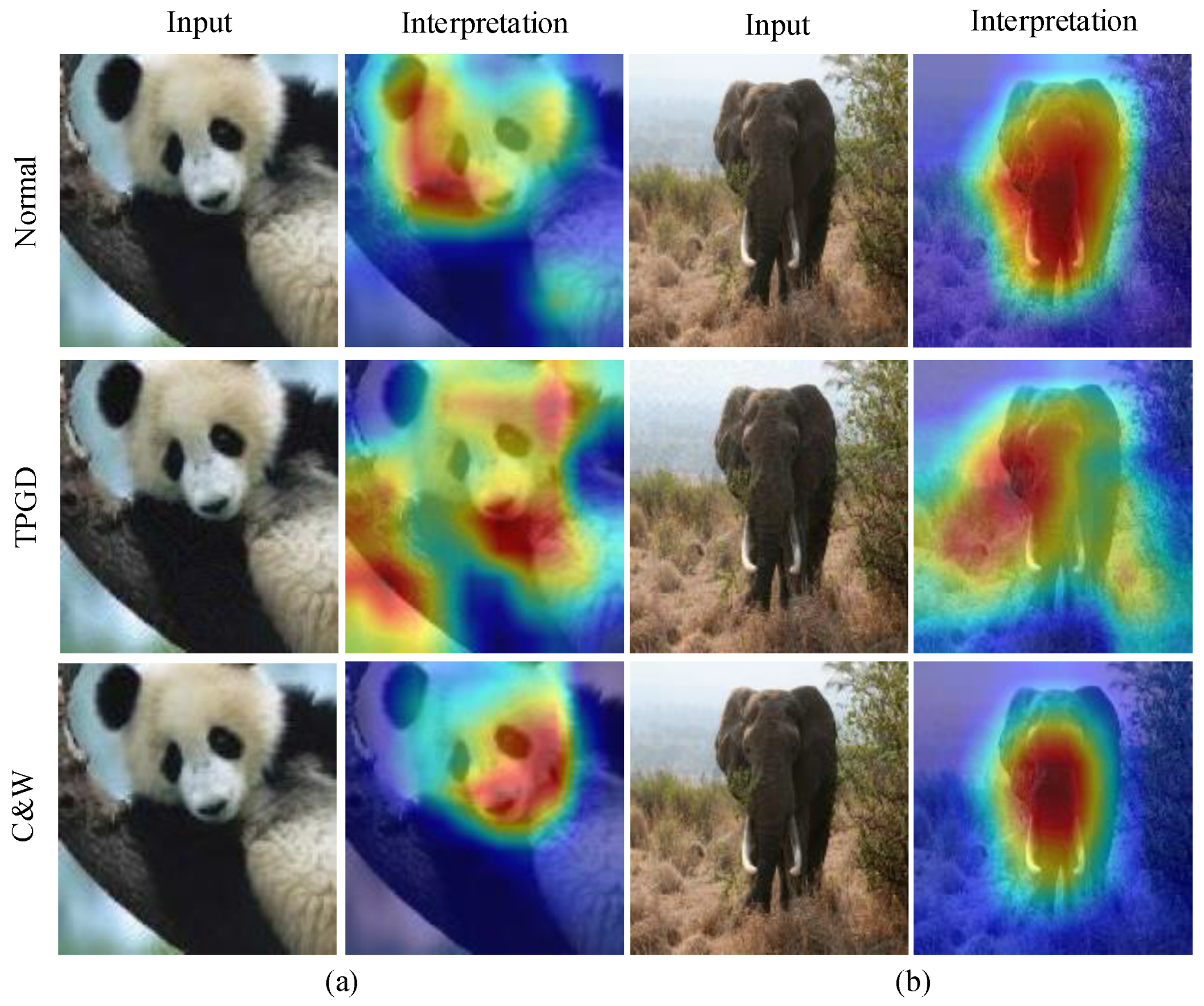
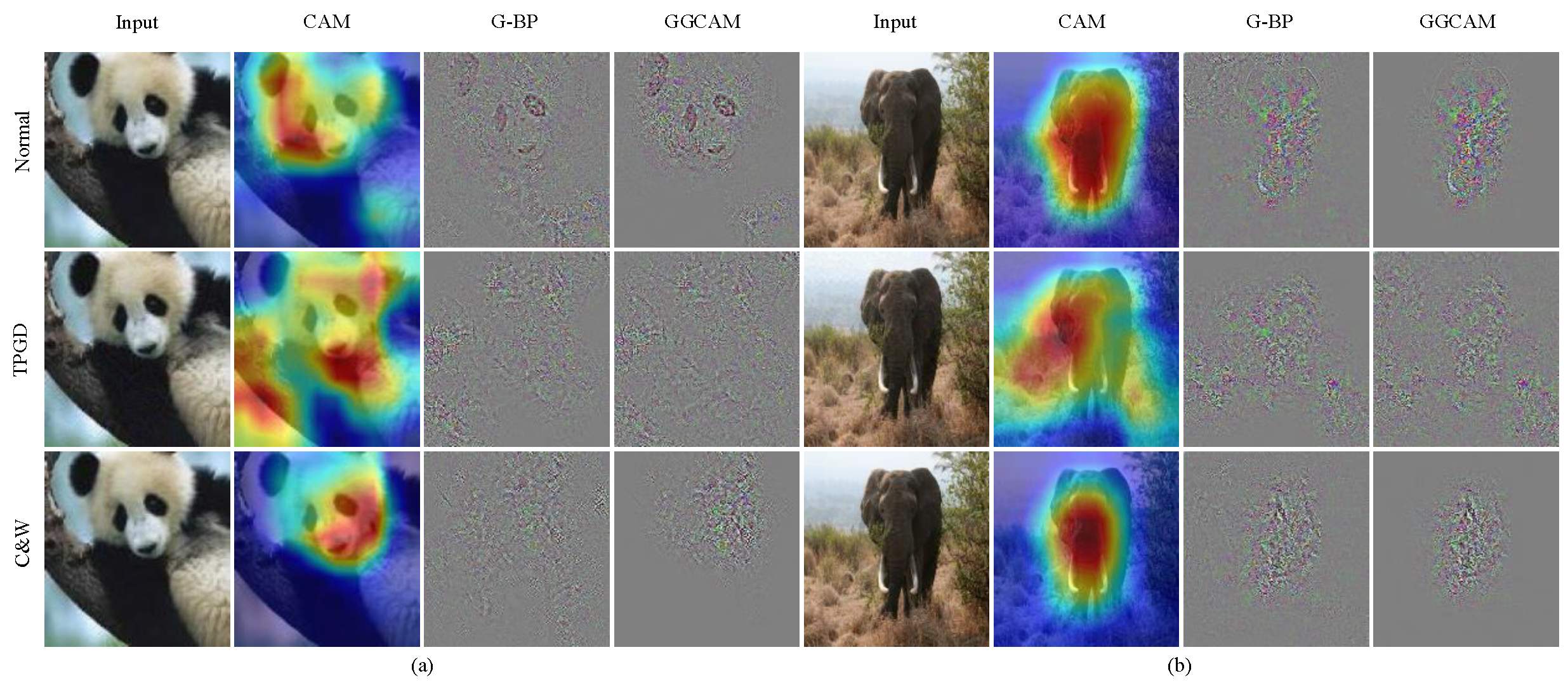
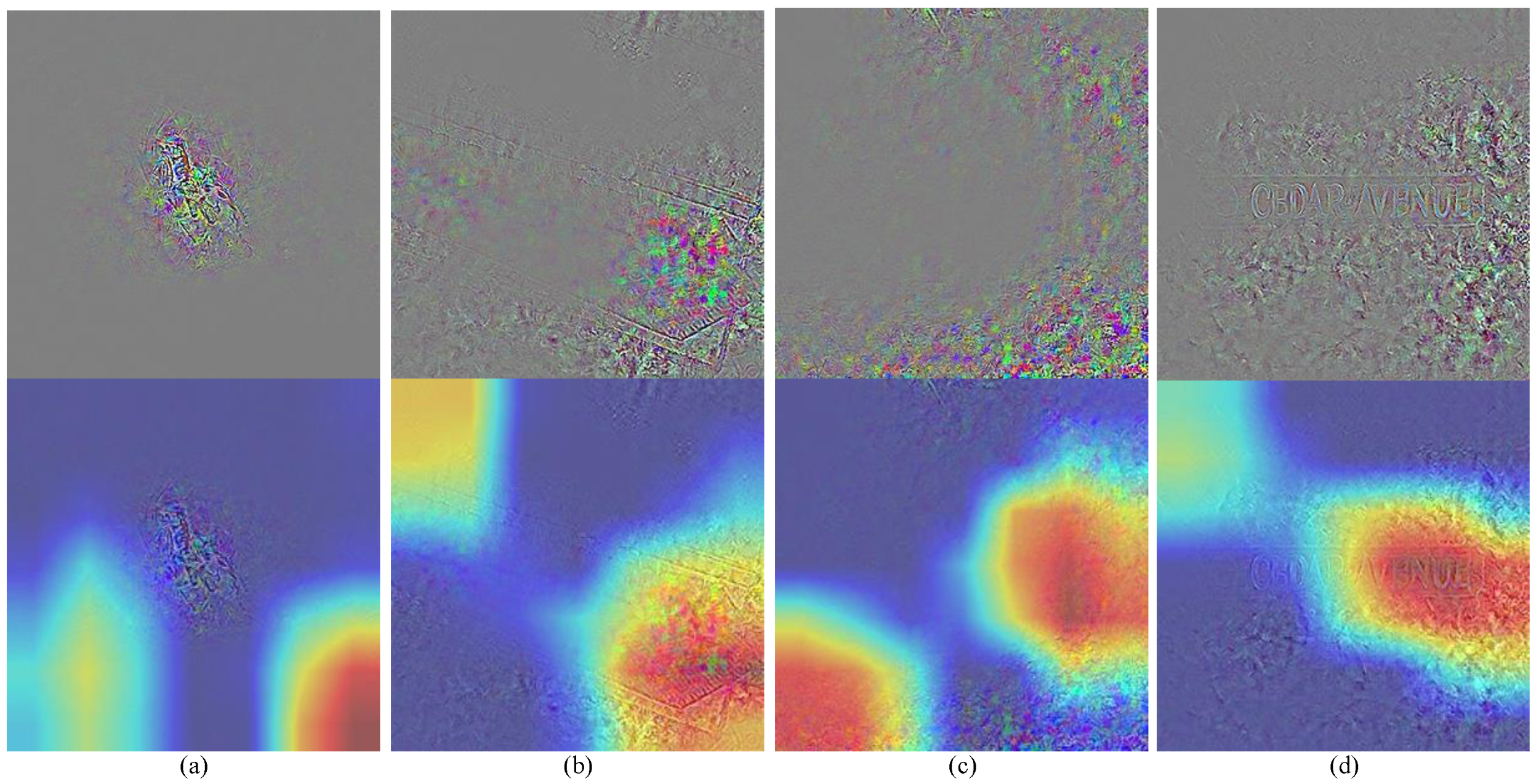
4.1. The Generation of an Attribution Map
4.2. Adversarial Detection Classifier
5. Experiment
5.1. Dataset and Models
5.1.1. Training Sets and Validation Sets
5.1.2. Test Sets
5.2. Performance Metrics
5.3. Experiments Using EfficientNet-B0
5.4. Experiments Using ResNe50
5.5. Comparisons with State-of-the-Art Methods
5.6. Discussion
6. Limitation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hadi, H.J.; Cao, Y.; Nisa, K.U.; Jamil, A.M.; Ni, Q. A comprehensive survey on security, privacy issues and emerging defence technologies for UAVs. J. Netw. Comput. Appl. 2023, 213, 103607. [Google Scholar] [CrossRef]
- Mason, E.; Yonel, B.; Yazici, B. Deep learning for radar. In Proceedings of the 2017 IEEE Radar Conference (RadarConf), Seattle, WA, USA, 8–12 May 2017; IEEE: New York, NY, USA, 2017; pp. 1703–1708. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Qian, F.; Yue, Y.; He, Y.; Yu, H.; Zhou, Y.; Tang, J.; Hu, G. Unsupervised seismic footprint removal with physical prior augmented deep autoencoder. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–20. [Google Scholar] [CrossRef]
- Tang, J.; Xiang, D.; Zhang, F.; Ma, F.; Zhou, Y.; Li, H. Incremental SAR automatic target recognition with error correction and high plasticity. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 1327–1339. [Google Scholar] [CrossRef]
- Wang, L.; Yang, X.; Tan, H.; Bai, X.; Zhou, F. Few-shot class-incremental SAR target recognition based on hierarchical embedding and incremental evolutionary network. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Vint, D.; Anderson, M.; Yang, Y.; Ilioudis, C.; Di Caterina, G.; Clemente, C. Automatic target recognition for low resolution foliage penetrating SAR images using CNNs and GANs. Remote Sens. 2021, 13, 596. [Google Scholar] [CrossRef]
- Qian, F.; He, Y.; Yue, Y.; Zhou, Y.; Wu, B.; Hu, G. Improved Low-Rank Tensor Approximation for Seismic Random Plus Footprint Noise Suppression. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Du, M.; Sun, Y.; Sun, B.; Wu, Z.; Luo, L.; Bi, D.; Du, M. TAN: A Transferable Adversarial Network for DNN-Based UAV SAR Automatic Target Recognition Models. Drones 2023, 7, 205. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, Q.; Liu, J.; Hou, R.; Wang, X.; Li, Y. Adversarial attacks on deep-learning-based SAR image target recognition. J. Netw. Comput. Appl. 2020, 162, 102632. [Google Scholar] [CrossRef]
- Shafahi, A.; Najibi, M.; Xu, Z.; Dickerson, J.; Davis, L.S.; Goldstein, T. Universal adversarial training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5636–5643. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by random network distillation. arXiv 2018, arXiv:1810.12894. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Early methods for detecting adversarial images. arXiv 2016, arXiv:1608.00530. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv 2017, arXiv:1702.04267. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–24 May 2017; IEEE: New York, NY, USA, 2017; pp. 39–57. [Google Scholar]
- Gong, Z.; Wang, W.; Ku, W.S. Adversarial and clean data are not twins. arXiv 2017, arXiv:1704.04960. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- He, W.; Li, B.; Song, D. Decision boundary analysis of adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, Z.; Liu, Q.; Zhou, S. GGCAD: A Novel Method of Adversarial Detection by Guided Grad-CAM. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Nanjing, China, 25–27 June 2021; Springer: New York, NY, USA, 2021; pp. 172–182. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. In Proceedings of the International Conference on Machine Learning, Jinan, China, 26–28 May 2018; pp. 284–293. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Wu, W.; Su, Y.; Chen, X.; Zhao, S.; King, I.; Lyu, M.R.; Tai, Y.W. Boosting the transferability of adversarial samples via attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1161–1170. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4312–4321. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2730–2739. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 2484–2493. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; IEEE: New York, NY, USA, 2020; pp. 1277–1294. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Yang, J.; Jiang, Y.; Huang, X.; Ni, B.; Zhao, C. Learning black-box attackers with transferable priors and query feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 12288–12299. [Google Scholar]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial examples are not bugs, they are features. arXiv 2019, arXiv:1905.02175. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 839–847. [Google Scholar]
- Goyal, Y.; Feder, A.; Shalit, U.; Kim, B. Explaining classifiers with causal concept effect (cace). arXiv 2019, arXiv:1907.07165. [Google Scholar]
- Narendra, T.; Sankaran, A.; Vijaykeerthy, D.; Mani, S. Explaining deep learning models using causal inference. arXiv 2018, arXiv:1811.04376. [Google Scholar]
- Harradon, M.; Druce, J.; Ruttenberg, B. Causal learning and explanation of deep neural networks via autoencoded activations. arXiv 2018, arXiv:1802.00541. [Google Scholar]
- Tabacof, P.; Valle, E. Exploring the space of adversarial images. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: New York, NY, USA, 2016; pp. 426–433. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Zhang, X.; Wang, N.; Shen, H.; Ji, S.; Luo, X.; Wang, T. Interpretable deep learning under fire. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Berkeley, CA, USA, 12–14 August 2020. [Google Scholar]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; El Ghaoui, L.; Jordan, M. Theoretically principled trade-off between robustness and accuracy. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7472–7482. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Croce, F.; Hein, M. Minimally distorted adversarial examples with a fast adaptive boundary attack. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2196–2205. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: New York, NY, USA, 2020; pp. 484–501. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.; Bailey, J. Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv 2020, arXiv:1801.02613. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Adv. Neural Inf. Process. Syst. 2018, 31, 7167–7177. [Google Scholar]
- Deng, Z.; Yang, X.; Xu, S.; Su, H.; Zhu, J. Libre: A practical bayesian approach to adversarial detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 972–982. [Google Scholar]
- Zhang, S.; Liu, F.; Yang, J.; Yang, Y.; Li, C.; Han, B.; Tan, M. Detecting Adversarial Data by Probing Multiple Perturbations Using Expected Perturbation Score. arXiv 2023, arXiv:2305.16035. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Resolution | Channels | Layers |
|---|---|---|---|---|
| 1 | 32 | 1 | ||
| 2 | 16 | 1 | ||
| 3 | 24 | 2 | ||
| 4 | 40 | 2 | ||
| 5 | 80 | 3 | ||
| 6 | 112 | 3 | ||
| 7 | 192 | 4 | ||
| 8 | 320 | 1 | ||
| 9 | 1280 | 1 |
| Attack | Type | Class | Number |
|---|---|---|---|
| C&W | Training | Normal | 32,000 |
| Adv | 17,616 | ||
| Validation | Normal | 8000 | |
| Adv | 4403 |
| Type | Class | Number |
|---|---|---|
| Test set | Normal | 10,000 |
| C&W | 4977 | |
| BIM | 9825 | |
| FGSM | 9193 | |
| PGD | 9823 | |
| AutoAttack | 9562 |
| Type | Number | EfficientNet-B0 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CAM | GGCAM | G-BP | ||||||||
| Recall | Precision | Accuracy | Recall | Precision | Accuracy | Recall | Precision | Accuracy | ||
| Normal | 10,000 | 94.40% | 95.61% | 93.37% | 99.36% | 99.79% | 99.43% | 99.64% | 99.77% | 99.61% |
| C&W | 4977 | 91.30% | 89.03% | 93.40% | 99.58% | 98.73% | 99.43% | 99.54% | 99.28% | 99.60% |
| BIM | 9825 | 94.44% | 94.31% | 94.42% | 99.57% | 99.35% | 99.47% | 99.59% | 99.63% | 99.64% |
| FGSM | 9193 | 95.28% | 93.99% | 94.82% | 98.64% | 99.30% | 99.02% | 98.91% | 99.61% | 99.29% |
| PGD | 9823 | 94.37% | 94.30% | 94.39% | 99.65% | 99.35% | 99.51% | 99.60% | 99.63% | 99.62% |
| AutoAttack | 9562 | 93.60% | 94.11% | 94.01% | 99.51% | 99.33% | 99.43% | 99.55% | 99.62% | 99.60% |
| Average Accuracy | 94.06% | 99.38% | 99.56% | |||||||
| Type | Number | ResNe50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CAM | GGCAM | G-BP | ||||||||
| Recall | Precision | Accuracy | Recall | Precision | Accuracy | Recall | Precision | Accuracy | ||
| Normal | 10,000 | 94.21% | 95.20% | 92.96% | 99.47% | 99.64% | 99.41% | 99.63% | 99.92% | 99.70% |
| C&W | 4977 | 90.46% | 88.60% | 92.96% | 99.28% | 98.94% | 99.41% | 99.84% | 99.26% | 99.70% |
| BIM | 9825 | 91.80% | 93.97% | 93.01% | 99.44% | 99.46% | 99.45% | 99.62% | 99.62% | 99.63% |
| FGSM | 9193 | 92.05% | 93.60% | 93.17% | 98.06% | 99.42% | 98.80% | 99.11% | 99.60% | 99.38% |
| PGD | 9823 | 91.99% | 93.98% | 93.11% | 98.97% | 99.46% | 99.22% | 99.16% | 99.62% | 99.40% |
| AutoAttack | 9562 | 91.68% | 93.80% | 92.97% | 98.82% | 99.44% | 99.16% | 99.70% | 99.61% | 99.66% |
| Average Accuracy | 93.03% | 99.24% | 99.58% | |||||||
| Methods | Attacks | Average Accuracy | |||
|---|---|---|---|---|---|
| FGSM | C&W | BIM | PGD | ||
| KD | 70.99% | 94.13% | 97.97% | 97.20% | 93.19% |
| LID | 89.12% | 95.28% | 98.08% | 97.50% | 95.82% |
| MD | 87.86% | 96.09% | 98.35% | 97.73% | 95.18% |
| LiBRe | 98.89% | 90.39% | 92.69% | 95.30% | 87.24% |
| S-N | 98.28% | 89.69% | 72.08% | 89.74% | 87.45% |
| EPS-N | 99.87% | 99.78% | 92.15% | 99.78% | 97.90% |
| CAM(ours) | 93.17% | 92.96% | 93.01% | 93.11% | 93.03% |
| GGCAM(ours) | 98.80% | 99.41% | 99.45% | 99.22% | 99.24% |
| G-BP(ours) | 99.38% | 99.70% | 99.63% | 99.62% | 99.58% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Liu, Q.; Wu, C.; Zhou, S.; Yan, Z. A Novel Adversarial Detection Method for UAV Vision Systems via Attribution Maps. Drones 2023, 7, 697. https://doi.org/10.3390/drones7120697
Zhang Z, Liu Q, Wu C, Zhou S, Yan Z. A Novel Adversarial Detection Method for UAV Vision Systems via Attribution Maps. Drones. 2023; 7(12):697. https://doi.org/10.3390/drones7120697
Chicago/Turabian StyleZhang, Zhun, Qihe Liu, Chunjiang Wu, Shijie Zhou, and Zhangbao Yan. 2023. "A Novel Adversarial Detection Method for UAV Vision Systems via Attribution Maps" Drones 7, no. 12: 697. https://doi.org/10.3390/drones7120697
APA StyleZhang, Z., Liu, Q., Wu, C., Zhou, S., & Yan, Z. (2023). A Novel Adversarial Detection Method for UAV Vision Systems via Attribution Maps. Drones, 7(12), 697. https://doi.org/10.3390/drones7120697