
Drone Elevation Control Based on Python-Unity Integrated Framework for Reinforcement Learning Applications


Abstract
:1. Introduction
1.1. Related Work
1.1.1. Existing Platforms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Platform | Programming Language | Communication Protocol | Environment Creation | Comment |
|---|---|---|---|---|
| OpenAI Gym [25] | Python | ___ | Very Complex | So limited environments, without low possibility for creation |
| Unity ML-Agents [33] | C# | ___ | Easy | Hard programing language, and very hard to adding or developing algorithms |
| PyBullet [39] | Python | TCP (or) UDP | Complex | Complexity of environment creation on Gazebo, is high [47] |
| DART [48] | C++ (or) Python | UDP | Complex | Complexity of environment creation on Gazebo, is high [47]. Also, the communication protocol need to be enhanced |
| MuJoCo [57] | C (or) C++ (or) Python | ___ | Complex | There is a limited number of environment, and the environment creation is very complicated |
| RaiSim [60] | C++ | ___ | Complex | Complexity of environment creation. In addition, doesn’t have suitable libraries for aerial applications [67] |
| Isaac [68] | C (or) Python | ___ | Medium Complex | Not suitable for algorithms implementation and developments, due to failure cases [69] |
| AirSim [73] | C++ (or) Python (or) C++ (or) Java | ___ | Complex | There is limited number of available environments, and only two drones’ type [73,75] |
| Proposed Work | Python | UDP | Easy | The online resources is widely spread, the algorithms implementation and development is allowable, and suitable for infinite number of applications |
1.1.2. Communication Protocol
1.2. Contributions and Proposed Approach
2. Methodology
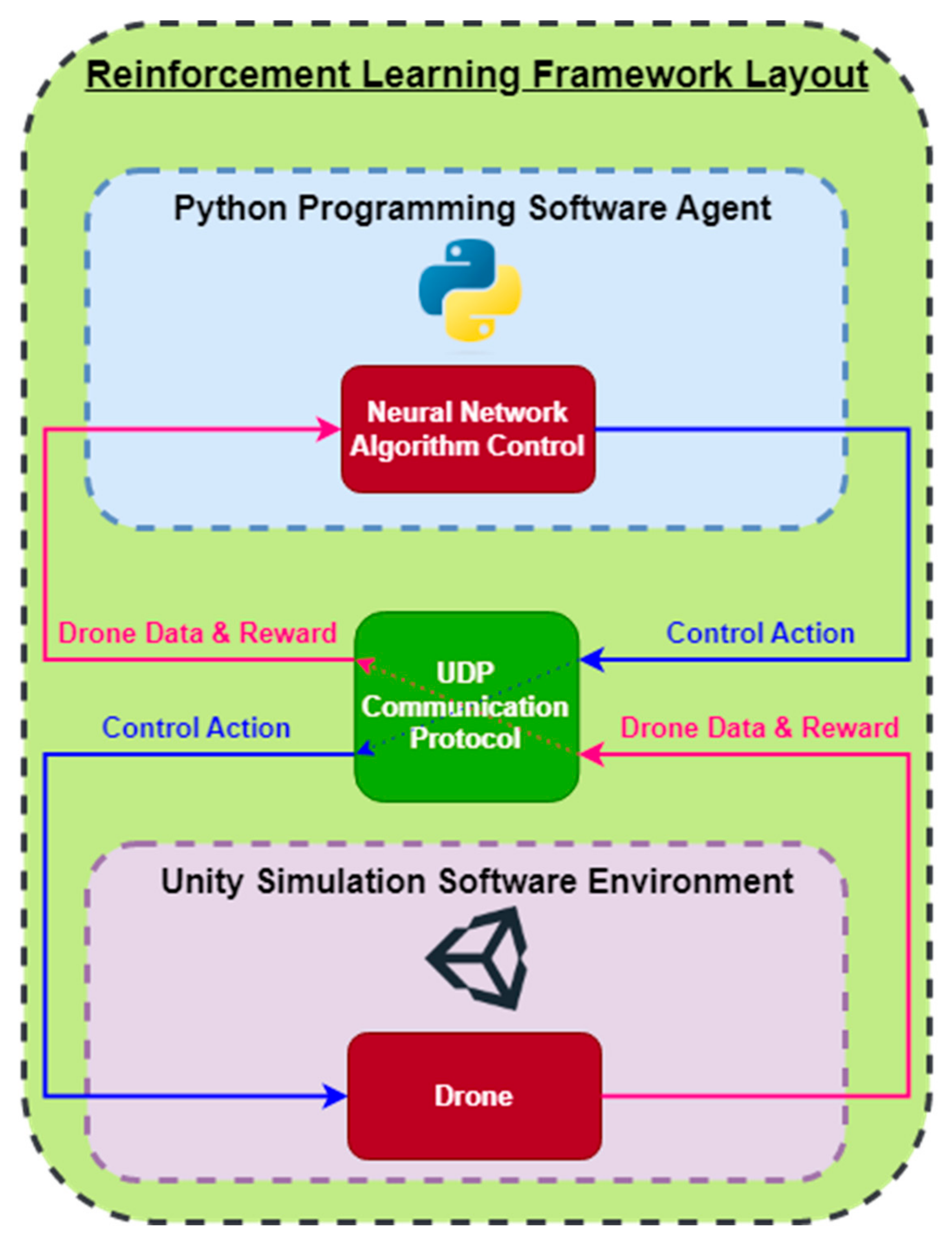
2.1. The Proposed Framework
2.2. The Drone
2.3. Reinforcement Learning (RL) Agent Algorithms
| Algorithm 1. Vanilla Policy Gradient (Pseudocode) |
| Randomly initialize policy network trainable parameter |
| for do |
| 1. Collect a set of drone data by applying the current policy |
| 2. At each time step in each trajectory, compute the return (R) |
| 3. Update the policy, using a policy gradient method |
| 4. Insert the policy gradient output into ADAM optimizer |
| end for |
| Algorithm 2. Actor-Critic Algorithm (Pseudocode) |
| Randomly initialize networks trainable parameters for value and for policy |
| for do |
| 1. Apply an action |
| 2. Collect the data of reward and next state |
| 3. Update the policy network parameters: |
| 4. Calculate the advantage at time t |
| 5. Compute the correction (TD error) for action-value at time t: and use it to update the parameters of value network: |
| 6. Insert the policy gradient output into ADAM optimizer |
| 7. Update and |
| end for |
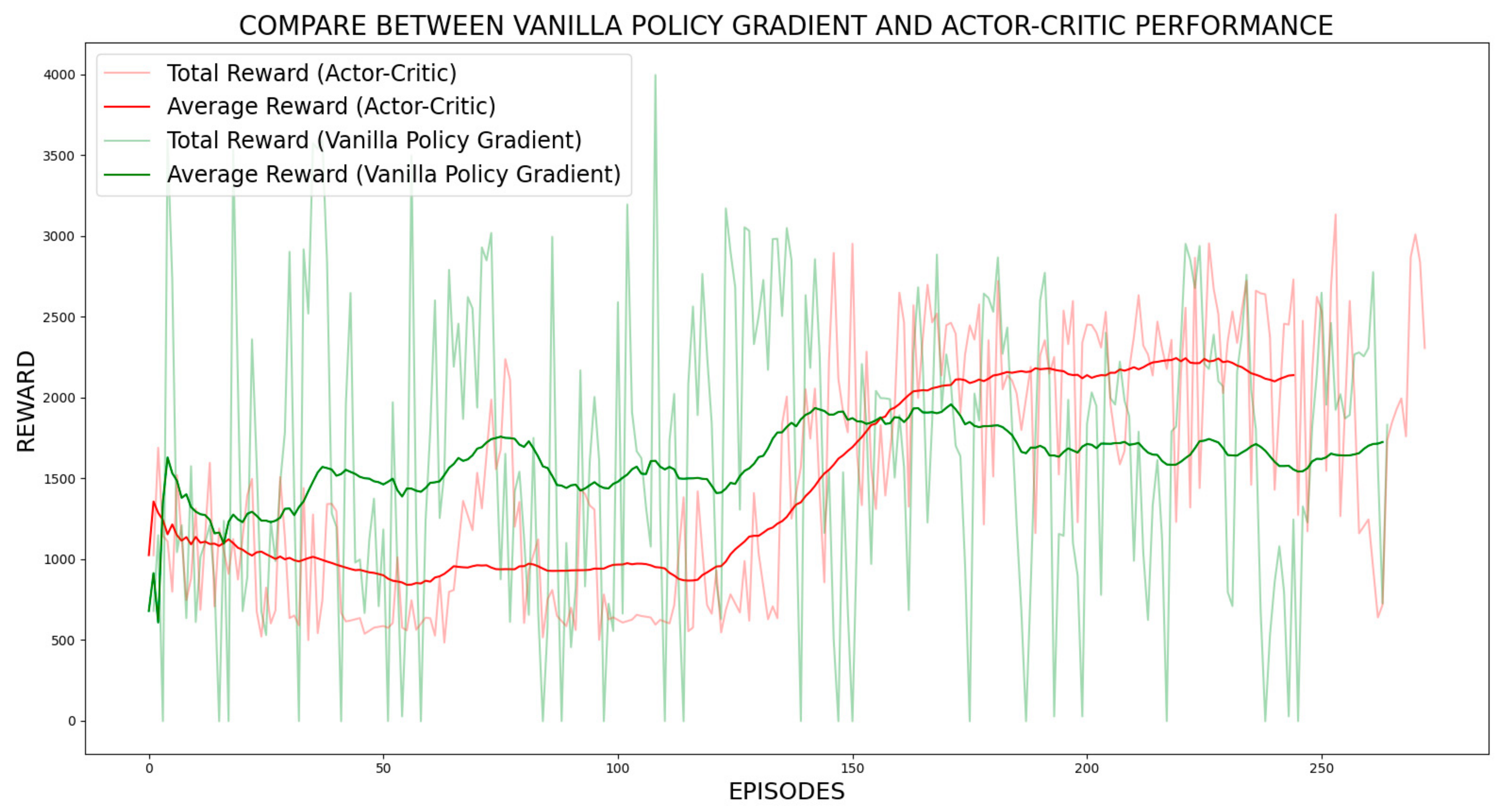
3. Results and Discussion
4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Symbol | Description | Units |
| a | Produced Action from Agent | __ |
| A(s,a) | The Advantage Function | __ |
| A2C | Actor-Critic | __ |
| AI | Artificial Intelligence | __ |
| E | Error Signal for Quadcopter Elevation | Meter (m) |
| Eπθ[R] | Expected Return from Environment | __ |
| F1 | Quadcopter Thrust Force from Motor 1 | Newton (N) |
| F2 | Quadcopter Thrust Force from Motor 2 | Newton (N) |
| F3 | Quadcopter Thrust Force from Motor 3 | Newton (N) |
| F4 | Quadcopter Thrust Force from Motor 4 | Newton (N) |
| g | Gravitational Acceleration | Meter/Square Second (m/s2) |
| IP | Internet Protocol | __ |
| m | Quadcopter Mass | Kilogram (Kg) |
| ML | Machine Learning | __ |
| NN | Neural Network | __ |
| P | Action Probability Distribution | __ |
| P(a|πθ(s)) | Probability of Action Based on Specific Policy | __ |
| Q(s,a) | The Action Value Function | __ |
| r | The Current Step Reward from Environment | __ |
| R(a) | Return from Environment | __ |
| RL | Reinforcement Learning | __ |
| s | Quadcopter States Data | Meter (m) |
| TCP | Transmission Control Protocol | __ |
| UDP | User Datagram Protocol | __ |
| V(s) | The State Value Function | __ |
| VPG | Vanilla Policy Gradient | __ |
| w | Trainable Parameters for Value Neural Network | __ |
| X | Quadcopter Position in X Axis | Meter (m) |
| Y | Quadcopter Position in Y Axis | Meter (m) |
| Y’ | The Measured Quadcopter Position in Y Axis from The Unity Environment | Meter (m) |
| Z | Quadcopter Position in Z Axis | Meter (m) |
| ∅ | Quadcopter Rotation Angle Around X Axis | Degree |
| α | Learning Rate for The Neural Network | __ |
| γ | The Discount Factor for Total Return | __ |
| θ | Trainable Parameters for Policy Neural Network | __ |
| πθ(s) | The Policy Between States and Actions | __ |
| ψ | Quadcopter Rotation Angle Around Z Axis | Degree |
| Ө | Quadcopter Rotation Angle Around Y Axis | Degree |
References
- Li, Y. Reinforcement Learning Applications. arXiv 2019, arXiv:1908.06973. [Google Scholar] [CrossRef]
- Norgeot, B.; Glicksberg, B.S.; Butte, A.J. A call for deep-learning healthcare. Nat. Med. 2019, 25, 14–15. [Google Scholar] [CrossRef]
- Komorowski, M.; Celi, L.A.; Badawi, O.; Gordon, A.C.; Faisal, A.A. The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nat. Med. 2018, 24, 1716–1720. [Google Scholar] [CrossRef]
- Li, C.Y.; Liang, X.; Hu, Z.; Xing, E.P. Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems 2018 (NIPS 2018), Montréal, Canada, 3–8 December 2018; pp. 1537–1547. [Google Scholar]
- Ling, Y.; Hasan, S.A.; Datla, V.; Qadir, A.; Lee, K.; Liu, J.; Farri, O. Diagnostic Inferencing via Improving Clinical Concept Extraction with Deep Reinforcement Learning: A Preliminary Study. In Proceedings of the 2nd Machine Learning for Healthcare Conference (PMLR), Boston, MA, USA, 18–19 August 2017; Volume 68, pp. 271–285. [Google Scholar]
- Peng, Y.-S.; Tang, K.-F.; Lin, H.-T.; Chang, E.Y. REFUEL: Exploring Sparse Features in Deep Reinforcement Learning for Fast Disease Diagnosis. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 7333–7342. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aytar, Y.; Pfaff, T.; Budden, D.; Paine, T.; Wang, Z.; Freitas, N. Playing hard exploration games by watching YouTube. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- García-Sánchez, P.; Georgios, N. Yannakakis and Julian Togelius: Artificial Intelligence and Games. Genet. Program. Evolvable Mach. 2018, 20, 143–145. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Chang, C.; Chen, Z.; Tan, B.; Gašić, M.; Yu, K. Policy Adaptation for Deep Reinforcement Learning-Based Dialogue Management. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15 April 2018; pp. 6074–6078. [Google Scholar]
- Hudson, D.A.; Manning, C.D. Compositional Attention Networks for Machine Reasoning. In Proceedings of the International Conference on Learning Representations) ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, X.; Lapata, M. Sentence Simplification with Deep Reinforcement Learning. In Proceedings of the Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- He, J.; Chen, J.; He, X.; Gao, J.; Li, L.; Deng, L.; Ostendorf, M. Deep Reinforcement Learning with a Natural Language Action Space. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1621–1630. [Google Scholar]
- Li, D.; Zhao, D.; Zhang, Q.; Chen, Y. Reinforcement Learning and Deep Learning based Lateral Control for Autonomous Driving. IEEE Comput. Intell. 2018, 14. [Google Scholar] [CrossRef]
- Pérez-Gil, Ó.; Barea, R.; López-Guillén, E.; Bergasa, L.M.; Gómez-Huélamo, C.; Gutiérrez, R.; Díaz-Díaz, A. Deep reinforcement learning based control for Autonomous Vehicles in CARLA. Multimed. Tools Appl. 2022, 81, 3553–3576. [Google Scholar] [CrossRef]
- Lange, S.; Riedmiller, M.; Voigtländer, A. Autonomous Reinforcement Learning on Raw Visual Input Data in a Real world application. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012. [Google Scholar]
- O’Kelly, M.; Sinha, A.; Namkoong, H.; Duchi, J.; Tedrake, R. Scalable End-to-End Autonomous Vehicle Testing via Rare-event Simulation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 9849–9860. [Google Scholar]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Deisenroth, M.P. A Survey on Policy Search for Robotics. Found. Trends Robot. 2011, 2, 1–142. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning. In Proceedings of the ICRA, Singapore, 16 September 2017. [Google Scholar]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Steinweg, M.; Kaufmann, E.; Scaramuzza, D. Autonomous Drone Racing with Deep Reinforcement Learning. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Hwangbo, J.; Sa, I.; Siegwart, R.; Hutter, M. Control of a Quadrotor with Reinforcement Learning. IEEE Robot. Autom. Lett. 2017, 2, 99. [Google Scholar] [CrossRef] [Green Version]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- Beysolow, T. Applied Reinforcement Learning with Python With OpenAI Gym, Tensorf low, and Keras; Apress Media LLC: San Francisco, CA, USA, 2019. [Google Scholar]
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision Transformer: Reinforcement Learning via Sequence Modeling. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS), Virtual-Only, 6–14 December 2021. [Google Scholar]
- Peng, X.B.; Kumar, A.; Zhang, G.; Levine, S. Advantage Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, Y.-J.; Chang, H.-Y.; Lin, Y.-J.; Wu, P.-W.; Wang, Y.-C.F. Deep Reinforcement Learning for Playing 2.5D Fighting Games. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Fujimoto, S.; Hoof, H.v.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning (ICML-18), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Plappert, M.; Andrychowicz, M.; Ray, A.; McGrew, B.; Baker, B.; Powell, G.; Schneider, J.; Tobin, J.; Chociej, M.; Welinder, P.; et al. Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research. arXiv 2018, arXiv:1802.09464. [Google Scholar]
- Matthew Hausknecht, P.S. Deep Recurrent Q-Learning for Partially Observable MDPs. In Proceedings of the Conference on ArtificialIntelligence (AAAI-15), Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Majumder, A. Deep Reinforcement Learning in Unity with Unity ML Toolkit; Apress Media LLC: San Francisco, CA, USA, 2021. [Google Scholar]
- Cao, Z.; Lin, C.-T. Reinforcement Learning from Hierarchical Critics. In Proceedings of the IEEE Transactions on Neural Networks and Learning Systems, Casablanca, Morocco, 14 May 2021. [Google Scholar]
- Song, Y.; Wojcicki, A.; Lukasiewicz, T.; Wang, J.; Aryan, A.; Xu, Z.; Xu, M.; Ding, Z.; Wu, L. Arena: A General Evaluation Platform and Building Toolkit for Multi-Agent Intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence: Multiagent Systems, Stanford, CA, USA, 21–23 March 2022; pp. 7253–7260. [Google Scholar]
- Juliani, A.; Berges, V.-P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A General Platform for Intelligent Agents. arXiv 2018, arXiv:1809.02627. [Google Scholar]
- Booth, J.; Booth, J. Marathon Environments: Multi-Agent Continuous Control Benchmarks in a Modern Video Game Engine. In Proceedings of the AAAI Workshop on Games and Simulations for Artificial Intelligence, Honolulu, HI, USA, 29 January 2019. [Google Scholar]
- Koenig, N.; Howard, A. Design and Use Paradigms for Gazebo, An Open-Source Multi-Robot Simulator. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Coumans, E.; Bai, Y. PyBullet Quickstart Guide. 2016. Available online: https://docs.google.com/document/d/10sXEhzFRSnvFcl3XxNGhnD4N2SedqwdAvK3dsihxVUA/edit# (accessed on 14 March 2023).
- Breyer, M.; Furrer, F.; Novkovic, T.; Siegwart, R.; Nieto, J. Comparing Task Simplifications to Learn Closed-Loop Object Picking Using Deep Reinforcement Learning. In Proceedings of the Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Zeng, A.; Song, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. TossingBot: Learning to Throw Arbitrary Objects with Residual Physics. IEEE Trans. Robot. 2019, 36, 1307–1319. [Google Scholar] [CrossRef]
- Choromanski, K.; Pacchiano, A.; Parker-Holder, J.; Tang, Y.; Jain, D.; Yang, Y.; Iscen, A.; Hsu, J.; Sindhwani, V. Provably Robust Blackbox Optimization for Reinforcement Learning. In Proceedings of the 3rd Conference on Robot Learning (CoRL), Osaka, Japan, 30 October–1 November 2019. [Google Scholar]
- Peng, X.B.; Abbeel, P.; Levine, S.; van de Panne, M. DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills. ACM Trans. Graph. 2018, 37, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.B.; Coumans, E.; Zhang, T.; Lee, T.-W.; Tan, J.; Levine, S. Learning Agile Robotic Locomotion Skills by Imitating Animals. In Proceedings of the Robotics: Science and Systems, Corvalis, OR, USA, 12–16 July 2020. [Google Scholar]
- Singla, A.; Bhattacharya, S.; Dholakiya, D.; Bhatnagar, S.; Ghosal, A.; Amrutur, B.; Kolathaya, S. Realizing Learned Quadruped Locomotion Behaviors through Kinematic Motion Primitives. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-Real: Learning Agile Locomotion For Quadruped Robots. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Pyo, Y.; Cho, H.; Jung, R.; Lim, T. ROS Robot Programming from the Basic Concept to Practical Programming and Robot Application; ROBOTIS: Seoul, Republic of Korea, 2017. [Google Scholar]
- Lee, J.; Grey, M.X.; Ha, S.; Kunz, T.; Jain, S.; Ye, Y.; Srinivasa, S.S.; Stilman, M.; Liu, C.K. DART: Dynamic Animation and Robotics Toolkit. J. Open Source Softw. 2018, 3, 500. [Google Scholar] [CrossRef]
- Paul, S.; Chatzilygeroudis, K.; Ciosek, K.; Mouret, J.-B.; Osborne, M.A.; Whiteson, S. Alternating Optimisation and Quadrature for Robust Control. In Proceedings of the AAAI Conference on ArtificialIntelligence., New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yu, W.; Tan, J.; Liu, C.K.; Turk, G. Preparing for the Unknown: Learning a Universal Policy with Online System Identification. In Proceedings of the 13th Robotics: Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar]
- Chatzilygeroudis, K.; Mouret, J.-B. Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Yu, W.; Liu, C.K.; Turk, G. Multi-task Learning with Gradient Guided Policy Specialization. CoRR Abs 2017, 5, 257–270. [Google Scholar] [CrossRef]
- Chatzilygeroudis, K.; Vassiliades, V.; Mouret, J.-B. Reset-free Trial-and-Error Learning for Robot Damage Recovery. Robot. Auton. Syst. 2016, 100, 14. [Google Scholar] [CrossRef]
- Kumar, V.C.V.; Ha, S.; Liu, C.K. Learning a Unified Control Policy for Safe Falling. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Clegg, A.; Yu, W.; Erickson, Z.; Tan, J.; Liu, C.K.; Turk, G. Learning to Navigate Cloth using Haptics. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Clegg, A.; Yu, W.; Tan, J.; Kemp, C.C.; Turk, G.; Liu, C.K. Learning Human Behaviors for Robot-Assisted Dressing. arXiv 2017, arXiv:1709.07033. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Nachum, O.; Norouzi, M.; Xu, K.; Schuurmans, D. Trust-PCL: An Off-Policy Trust Region Method for Continuous Control. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 24–28 September 2018. [Google Scholar]
- Wu, Y.; Mansimov, E.; Liao, S.; Grosse, R.; Ba, J. Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hwangbo, J.; Lee, J.; Hutter, M. Per-Contact Iteration Method for Solving Contact Dynamics. IEEE Robot. Autom. Lett. 2018, 3, 895–902. [Google Scholar] [CrossRef]
- Carius, J.; Ranftl, R.; Farshidian, F.; Hutter, M. Constrained stochastic optimal control with learned importance sampling: A path integral approach. Int. J. Rob. Res. 2022, 41, 189–209. [Google Scholar] [CrossRef] [PubMed]
- Tsounis, V.; Alge, M.; Lee, J.; Farshidian, F.; Hutter, M. DeepGait: Planning and Control of Quadrupedal Gaits using Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning Quadrupedal Locomotion over Challenging Terrain. Sci Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef]
- Lee, J.; Hwangbo, J.; Hutter, M. Robust Recovery Controller for a Quadrupedal Robot using Deep Reinforcement Learning. arXiv 2019, arXiv:1901.07517. [Google Scholar]
- Shi, F.; Homberger, T.; Lee, J.; Miki, T.; Zhao, M.; Farshidian, F.; Okada, K.; Inaba, M.; Hutter, M. Circus ANYmal: A Quadruped Learning Dexterous Manipulation with Its Limbs. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Kang, D.; Hwangho, J. Physics engine benchmark for robotics applications RaiSim vs. Bullet vs. ODE vs. MuJoCo vs. DartSim. RaiSim Platf. 2018. Available online: https://leggedrobotics.github.io/SimBenchmark/ (accessed on 14 March 2023).
- Wang, Z. Learning to Land on Flexible Structures; KTH: Stockholm, Sweden, 2022. [Google Scholar]
- Corporation, N. Nvidia Isaac Sim. Available online: https://developer.nvidia.comisaac-sim (accessed on 14 March 2023).
- Audonnet, F.P.; Hamilton, A.; Aragon-Camarasa, G. A Systematic Comparison of Simulation Software for Robotic Arm Manipulation using ROS2. In Proceedings of the 22nd International Conference on Control, Automation and Systems (ICCAS), BEXCO, Busan, Republic of Korea, 27–30 November 2022. [Google Scholar]
- Monteiro, F.F.; Vieira-e-Silva, A.L.B.; Teixeira, J.M.X.N.; Teichrieb, V. Simulating real robots in virtual environments using NVIDIA’s Isaac SDK. In Proceedings of the XXI Symposium on Virtual and Augmented Reality, Natal, Brazil, 28–31 October 2019. [Google Scholar]
- Makoviychuk, V.; Wawrzyniak, L.; Guo, Y.; Lu, M.; Storey, K.; Macklin, M.; Hoeller, D.; Rudin, N.; Allshire, A.; Handa, A.; et al. Isaac Gym: High Performance GPU Based Physics Simulation For Robot Learning. arXiv 2021, arXiv:2108.10470. [Google Scholar] [CrossRef]
- Rojas, M.; Hermosilla, G.; Yunge, D.; Farias, G. An Easy to Use Deep Reinforcement Learning Library for AI Mobile Robots in Isaac Sim. Appl. Sci. 2022, 12, 8429. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the Field and Service Robotics conference (FSR), Zurich, Switzerland, 12–15 September 2017. [Google Scholar]
- Shin, S.-Y.; Kang, Y.-W.; Kim, Y.-G. Obstacle Avoidance Drone by Deep Reinforcement Learning and Its Racing with Human Pilot. Appl. Sci. 2019, 9, 5571. [Google Scholar] [CrossRef] [Green Version]
- Park, J.-H.; Farkhodov, K.; Lee, S.-H.; Kwon, K.-R. Deep Reinforcement Learning-Based DQN Agent Algorithm for Visual Object Tracking in a Virtual Environmental Simulation. Appl. Sci. 2022, 12, 3220. [Google Scholar] [CrossRef]
- Wu, T.-C.; Tseng, S.-Y.; Lai, C.-F.; Ho, C.-Y.; Lai, Y.-H. Navigating Assistance System for Quadcopter with Deep Reinforcement Learning. In Proceedings of the 1st International Cognitive Cities Conference (IC3), Okinawa, Japan, 7–9 August 2018. [Google Scholar]
- Anwar, A.; Raychowdhury, A. Autonomous Navigation via Deep Reinforcement Learning for Resource Constraint Edge Nodes using Transfer Learning. arXiv 2019, arXiv:1910.05547. [Google Scholar] [CrossRef]
- Yoon, I.; Anwar, M.A.; Joshi, R.V.; Rakshit, T.; Raychowdhury, A. Hierarchical Memory System With STT-MRAM and SRAM to Support Transfer and Real-Time Reinforcement Learning in Autonomous Drones. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 485–497. [Google Scholar] [CrossRef]
- Tanenbaum, A.S. Computer Networks Tanenbaum; Pearson Education: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Peterson, L.L.; Davie, B.S. ComputerNetworks: A Systems Approach; Morgan Kaufmann: Burlington, NJ, USA, 2012. [Google Scholar]
- Grooten, B.; Wemmenhove, J.; Poot, M.; Portegies, J. Is Vanilla Policy Gradient Overlooked? Analyzing Deep Reinforcement Learning for Hanabi. In Proceedings of the ALA(Adaptive and Learning Agents Workshop at AAMAS), Auckland, New Zealand, 9–10 May 2022. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems (NIPS-99), Cambridge, MA, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Two-Way Communication between Python 3 and Unity (C#)-Y. T. Elashry. Available online: https://github.com/Siliconifier/Python-Unity-Socket-Communication (accessed on 14 March 2023).
- Unity Asset Store. Available online: https://assetstore.unity.com/packages/3d/vehicles/air/simple-drone-190684#description (accessed on 14 March 2023).
- Sketchfab Platform for Ready 3D Models. Available online: https://sketchfab.com/3d-models/airport-c26922efb90c44988522d4638ad5d217 (accessed on 14 March 2023).
- Schulman, J. Optimizing Expectations: From Deep Reinforcement Learning to Stochastic Computation Graphs; EECS Department, University of California: Berkeley, CA, USA, 2016. [Google Scholar]
- Abbass, M.A.B.; Hamdy, M. A Generic Pipeline for Machine Learning Users in Energy and Buildings Domain. Energies 2021, 14, 5410. [Google Scholar] [CrossRef]
- Abbass, M.A.B.; Sadek, H.; Hamdy, M. Buildings Energy Prediction Using Artificial Neural Networks. Eng. Res. J. EJR 2021, 171, 12. [Google Scholar]
- A Video Link for Actor-Critic Algorithm to Control Drone. Available online: https://youtu.be/OyNK6QSuMuU (accessed on 14 March 2023).
- A Video Link for Vanilla Policy Gradient Algorithm to Control Drone. Available online: https://youtu.be/r-DKqIC1bGI (accessed on 14 March 2023).
- A Video Link for Overall Python-Unity Integrated Platform in Runtime. Available online: https://youtu.be/ZQzC05qr_q0 (accessed on 14 March 2023).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbass, M.A.B.; Kang, H.-S. Drone Elevation Control Based on Python-Unity Integrated Framework for Reinforcement Learning Applications. Drones 2023, 7, 225. https://doi.org/10.3390/drones7040225
Abbass MAB, Kang H-S. Drone Elevation Control Based on Python-Unity Integrated Framework for Reinforcement Learning Applications. Drones. 2023; 7(4):225. https://doi.org/10.3390/drones7040225
Chicago/Turabian StyleAbbass, Mahmoud Abdelkader Bashery, and Hyun-Soo Kang. 2023. "Drone Elevation Control Based on Python-Unity Integrated Framework for Reinforcement Learning Applications" Drones 7, no. 4: 225. https://doi.org/10.3390/drones7040225
APA StyleAbbass, M. A. B., & Kang, H. -S. (2023). Drone Elevation Control Based on Python-Unity Integrated Framework for Reinforcement Learning Applications. Drones, 7(4), 225. https://doi.org/10.3390/drones7040225